
Почти каждый из нас когда-либо работал в компании, где есть всеми ненавистная "файлопомойка" — шара с тысячами документов без какой-либо структуры. И наверняка у каждого был момент, когда ему нужно было что-то в этой помойке отыскать. "А Василич этот отчёт на шару кидал в прошлом месяце, глянь там" — слышали мы от коллеги, а тот самый Василич на вопрос "А в какой папке?" конечно же отвечал "А х… не помню, в общем, сам ищи". И мы погружались в многочасовой ад — бродили по папкам с документами из 90-х, фотографиями котов, договорами вперемешку с анекдотами и прочим шлаком в надежде найти заветный документ.
Наверняка многие из нас пытались навести в этой шаре порядок, "С меня хватит, сейчас возьму, разгребу всё и разложу по полочкам" — заявляли мы всем, тратили часы, дни и недели своего времени разгребая завалы. А параллельно Василиса Семёновна из бухгалтерии, или тот же Василич снова разбавляли разобранные файлы своими документами, котами, анекдотами и прочим, возвращая привычный хаос на своё место. И так продолжалось до тех пор, пока вы не сдались. И шара обратно превратилась в привычную помойку.
Как быть?
Раз идея заставить всех пользователей поддерживать порядок в шаре потерпела фиаско, значит нужно искать альтернативные подходы. Очевидным выбором с минимальными трудозатратами был бы поисковик, который позволяет выполнять поиск как по названиям и метаданным, так и по содержимому всех файлов в помойке.
Когда мы находились на этапе решения данной проблемы для наших клиентов, мы в первую очередь рассмотрели имеющиеся системы для поиска и менеджмента документов, отдавая приоритет open-source решениям. Не вдаваясь в детали поиска и исследования сразу декларирую результат: быстрого, простого и удобного решения для индексации и поиска в шарах, с OCR, тегированием и подсветкой именованных сущностей просто не существовало.
Что дальше? Решение
Поэтому, видя эту проблему во многих компаниях, мы решились на создание своего продукта, конечно же open-source'ного.
В итоге у нас получился Ambar — система для поиска и структуризации документов, которая наконец соответствовала всем нашим требованиям (GitHub), а именно:
- Мгновенный поиск по содержимому документов, в т.ч. изображений
- Тегирование документов, в т.ч. автоматическое (например, помечать все изображения тегом image, или помечать все документы где есть IP адреса тегом ip)
- Поддержка всех офисных форматов (в т.ч. openoffice), pdf с картинками и старых кодировок вроде CP866
- Автоматический сбор и синхронизации документов из шар-помоек
Рассмотрим вариант решения нашей проблемы с помощью Ambar, по шагам:
- Устанавливаете Ambar на линукс сервере: нужен Docker и Ubuntu Server 16.04 и выше (
инструкция по установке на английском) - Настраиваете SMB или FTP краулер (инструкция на английском)
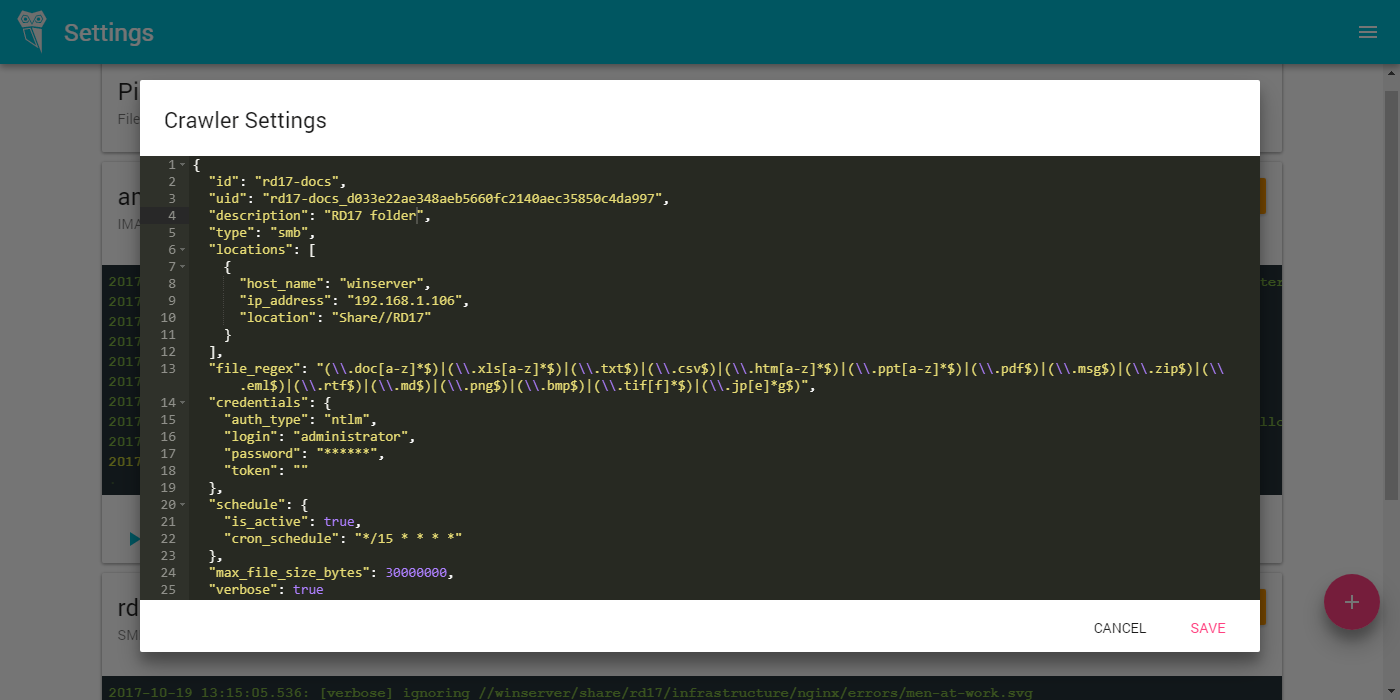
- Наблюдаете за процессом индексации ваших документов на странице статистики
- Используете поиск с тегами и прочими плюшками
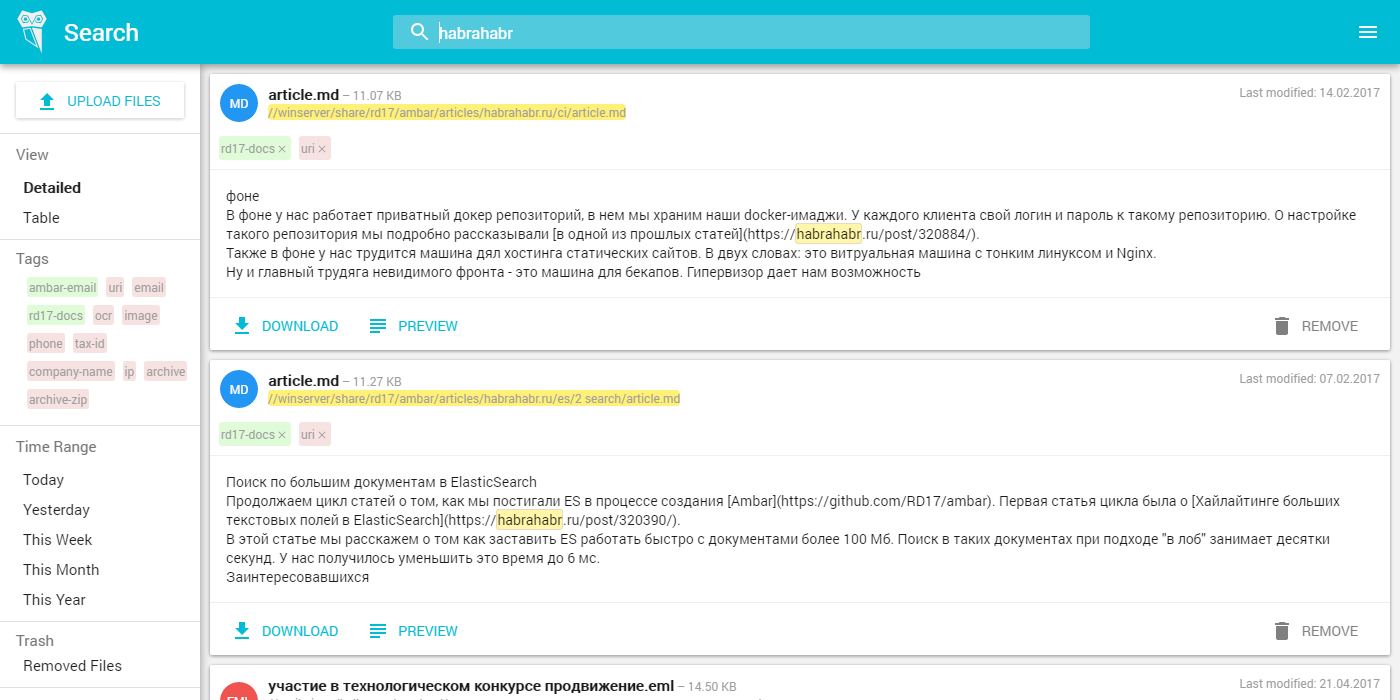
Итог
В этой короткой статье мы поделились нашей болью, связанной с большими файловыми помойками в компаниях и нашим подходом к решению этой проблемы.
Спасибо за внимание!
Комментарии (65)


oYASo
19.10.2017 19:56Интересно!
Вопрос скорее концептуальный (идеи, предложения?): как быть с отсканированными документами? Доков много, секретари сканят все пачками в одну папку, не всегда все разбирается — адищенский ад в итоге.
sochix Автор
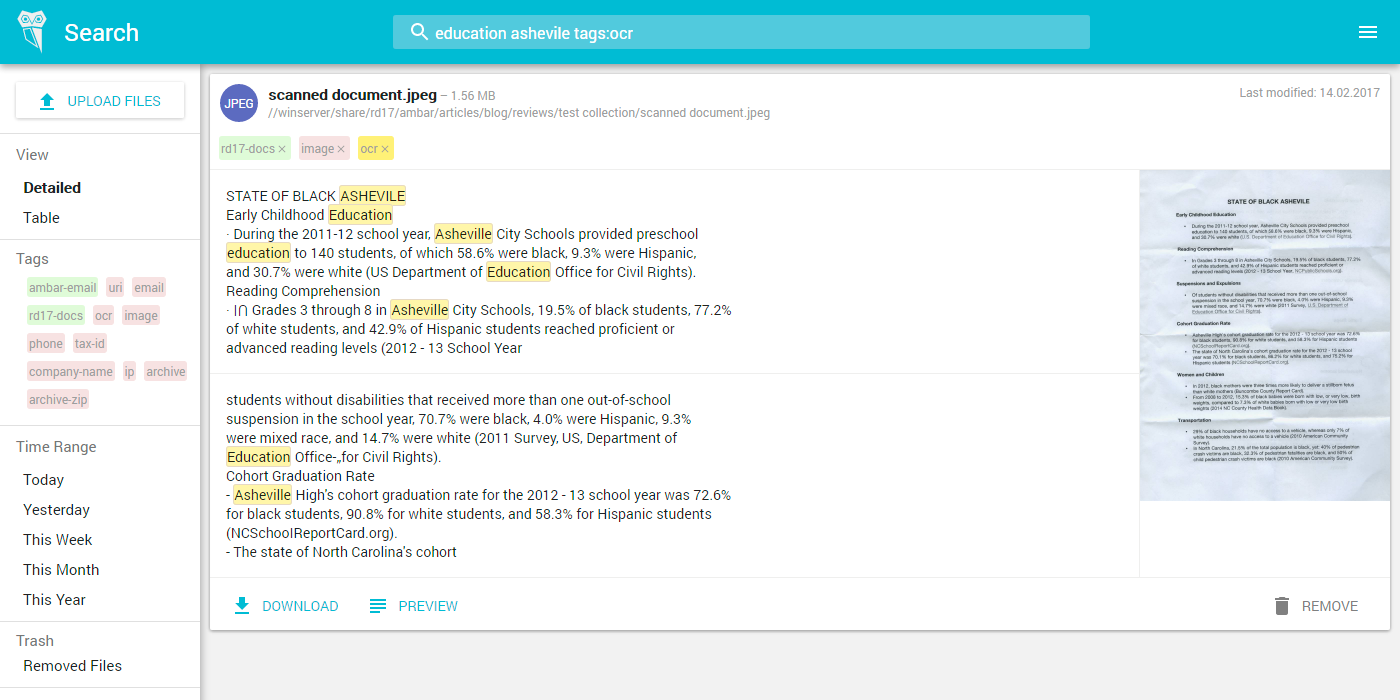
19.10.2017 20:01+1Ну если ваши секретари уже отсканировали все документы то все просто — натравливаете на эту папку Ambar, он автоматически распознает текст со сканов и позволяет по нему искать. Вот скриншот как это выглядит:

muxa_ru
23.10.2017 04:56Прошу прощения за интимный вопрос, а что это вообще за рабочий процесс в котором несколько человек сканят в одну папку?
Просто мы делаем программу для работы с хотфолдерами и мне интересны пользовательские кейсы в этой области.
Если, конечно же, это не секретно.
Заранее спасибо.



gotch
19.10.2017 20:42Без учета разрешений доступа на оригинальные файлы вся эта затея бессмысленна. Прототип, не более.
gotch
20.10.2017 15:57Надо объяснить минусующим. Обычно на файловом сервере настроены четкие разрешения на папки различных отделов, на разные категории документов, или даже используется Dynamic Access Control.
Очень интересная идея сделать полнотекстовый кеш всего и отдавать его же всем.
Как наяву вижу следующие запросы: *парол*, *зарплат*директор*, и так далее.
На дворе 2017 год. И информационная безопасность это не последний, а первый вопрос, который должен быть у разработчика приложений.
Здорово заново изобрести Microsoft Search Server для *nix платформ, но безопасность, господа.
grossws
20.10.2017 19:24Иногда такие системы вполне себе живут в контурной модели безопасности, без всего развлечения с rbac. Для части применений этого вполне достаточно.

aulandsdalen
19.10.2017 21:40Докер-докер-докер-докер-докер. Убунту-убунту-убунту-убунту-убунту.
А если я хочу, например, на macOS развернуть это все? Или на OpenBSD? Или на RHEL? А ничего, говорят мне авторы этого проекта, ставь убунту и разворачивай там докер, потому что это стильно-модно-молодежно.
Нет ничего более идиотского, чем ПО, которое безальтернативно распространяется в виде докер-контейнера.

DrAleck
19.10.2017 23:06Я думаю если вы профинансируете в должной степени разработку, авторы учтут большинство ваших хотелок.
Ded_Banzai
20.10.2017 17:48Так докер можно запустить практически везде. Вот то, что нет отдельного пакета — это действительно хуже.


kisskin
19.10.2017 23:06конечно, хорошо бы права доступа учитывать) и хорошо бы под винду, почему-то мне кажется, что проблема с файло-помойками в большей степени всё же у тех, кто в компьютерах не силён)
realkludge
22.10.2017 23:17Софт ставится на сервере с Linux, а у не сильных в компьютерах клиентов может быть что угодно, в т.ч. и винда.

serafims
20.10.2017 01:57Если файлопомойка стала помойкой — это уже не инструмент, и его надо немножко удалить нахрен.

Mendel
20.10.2017 15:26За удаление некоторых помоек весь отдел АСУ удалить могут. Причем физически, а не просто unmount в отделе кадров.
Знавал я одну помойку, стихийно образовавшуюся лет двенадцать назад.
«ШараСекретарь» называется.
Создавалась исключительно с целью файлообмена между начальником одного органа гос.власти с его приемной ибо принтер ставить начальнику было совершенно нецелесообразно, и даже настраивать печать на принтер в приемной не хотелось по соображениям — пусть секретарь допиливает напильником за шефом перед печатью.
(Да, я мог сказать что _Шефу_ не нужно ставить всё самое лучшее, и даже «так» посмотреть на завсклада, чтобы она перестала спорить).
Но блин, я не ожидал что эта папочка превратиться в главную файлопомойку предприятия.
Обнаружив что на этом компе висит больше файлов чем на штатной файлопомойке на большом толстом сервере с рейдом и т.п. я пытался бороться. Пару лет пытался. И ярлыки людям переправлял и разговоры разговаривал. Лет семь назад плюнул я на это дело и тупо переобозвал «Секретаря» в «Приемную» а файлсервер в «Секретарь».
Я там уже лет пять не появлялся, но шара живет…SchmeL
20.10.2017 16:06История примерно такая же, только не у меня. Гос. предприятие, половина ПК личных, так же купленный в складчину qnap. Принес мне как-то друг диск, который в том qnap кто-то форматнул. И ладно, своя же помойка, но начальство грозило лишить премии весь отдел, так как им пользовалось все предприятие и основные БД (ms access) были на нем же.
Админа у них там не было, да и навряд ли кто-то в здравом уме согласился бы там работать на полную ставку.
Dmitry_7
20.10.2017 08:59Какой уродливый костыль, когда есть локальный яндекс-десктоп (его прекратили выпускать лет 10 назад, правда)
ssss41
20.10.2017 10:18идея классная, но без разграничения прав я не представляю, как ее внедрять.
У меня 300ГБ инфы на файловом сервере + у каждого пользователя еще свой профиль, который тоже можно засунуть для поиска инфы (папку Docs + Desktop).
Документы лежат в нужных папках по темам, но все равно их бывает хрен найдешь.
Осталось придумать как подтягивать разграничение по правам доступа и будет готовое решение.

amarao
20.10.2017 12:44Отличный пример применения докера. Просто образцово-показательный. После того, как ломается хотя бы одна из зависимостей, пересобрать золотой образ становится просто невозможно. Я бы сказал, что это гигантская куча антипаттернов системного администрирования.
А проект хороший, да.
GreyCat
20.10.2017 15:03мы решились на создание своего продукта, конечно же open-source'ного.
А проект хороший, да.Только вот он ни разу не "open source", там fair source с "Use Limitation: 1 user". Так что "хороший" при наличии массы разумных open source альтернатив — по-моему, преувеличение.
amarao
20.10.2017 17:32+1Ого. И они используют gpl'ные компоненты во всю без учёта лицензий? Сурово.
GreyCat
20.10.2017 17:36Я не уверен насчет gpl'ных, но там все как-то весьма сурово, да. Как минимум, у них в лицензировании должен быть отдельный (и большой, по идее, учитывая Docker) файлик с кучей всяких лицензий хотя бы на всякое такое. Впрочем, конкретно проект ambar-crawler у них вообще без явно указанной лицензии.


guyfawkes
20.10.2017 14:18А с помощью чего реализовано OCR?
sochix Автор
20.10.2017 14:31Тщательно настроенный tesseract
guyfawkes
20.10.2017 14:51А будут ли выложены исходники того же pipeline?
sochix Автор
20.10.2017 17:50Можем вам лично предоставить, только расскажите что вы с кодом делать хотите.
guyfawkes
20.10.2017 18:17Я поизучать исходники хотел :) Ведь вы описали свое решение как опенсорсное, а самая мякотка (апи и пайплайн) доступны только в виде докер-имейджей.
Mendel
22.10.2017 13:04Ну так и лицензия не свободная. Опенсорс тут чисто в качестве рекламного хода, чтобы завлекать людей на свое фримиум решение. Ничего личного, просто бизнес.
badhop
20.10.2017 14:47Здорово! Google в свое время такие appliance продавал, но они на себе только индекс хранили и умели обходить в том числе пользовательские компьютеры, а тут все таки нужно много места, чтобы копию всех данных хранить.
equand
20.10.2017 15:22Да, проблема появляется, когда захочешь это на NAS поставить. Идея хороша, но реализация хромает (как с сисадминской стороны — докерпомойка, так и с программной — хранение всех файлов в кастомной бд дубликатом)
equand
20.10.2017 15:36Добавлю для создателей:
Крутое решение, только если бы был index only вариант обе эти проблемы были бы решены по большей части. Еще не помешал бы smb вариант, не хотелось бы всем давать админский доступ в малом/среднем бизнесе. А поисковик по документам мастхев.
SchmeL
20.10.2017 16:13В owncloud\nextcloud можно подключить общую шару. Поиск по именам только есть. Обычно этого хватает, шара остается на месте, файлы не синхронизируются.
grossws
20.10.2017 19:31+2Интересно, а вы контрибьютите в проекты, которые используете? Как-то учитываете лицензии проектов, на которые опираетесь?
Например, я не вижу файла с перечислением лицензий зависимостей от слова совсем. Как минимум, часть зависимостей у вас под Apache License v2, но никакого указания этого я не вижу.
Ну и хвалиться тем, что у вас "Поддержка всех офисных форматов (в т.ч. openoffice), pdf с картинками и старых кодировок вроде CP866" довольно глупо, это есть у всех кто использует Apache Tika. Собственно, поддержку cp866/ibm866 я добавлял когда-то ради лексиконовских файлов.
Mendel
22.10.2017 13:19Это коммерческий продукт, с несвободной лицензией дающий лишь ограниченный доступ (фактически фримиум), в котором «открытый код» лишь маркетинговый ход.
Формально они правы, свободная лицензия и открытый код хоть и коррелируют, но не синонимы. Но в целом это некрасиво конечно.
А нарушение чужих лицензий? Ну бывает. Но кто же будет судиться?

reff
21.10.2017 22:13Мгновенно искать по именам файлов умеет everything (voidtools.com). Строит индекс, к себе ничего не копирует, умеет прикидываться http- и ftp-сервером.

VJean
22.10.2017 04:14Он хорош для локального поиска и, увы, windows only. Сканирование и переиндексация сетевой шары на несколько Тб может занять кучу времени.
reff
22.10.2017 12:43Умеет индексировать сетевые диски. Обработка нескольких терабайт не может не занимать кучу времени, чудес не бывает. При использовании NTFS переиндексация осуществляется чуть ли не в реальном времени.
VJean
23.10.2017 03:34Я не отрицал, что не умеет сканировать шары, они добавляются в качестве обычного каталога. Но вот затык в том, что MFT и USN по сети не передаются, от того и низкие скорости. Кроме того, есть еще проблема с NTFS под линуксами: журнал не обновляется и переиндексацию приходится делать по расписанию.
Botkin
Неплохо!
Оно файлы к себе затягивает или просто строит индекс?
Доступ к файлу напрямую осуществляется или проксируется?
Что если у пользователя нет праа на какую-то папку?
sochix Автор
Спасибо!
Ambar затягивает к себе все файлы и хранит у себя
Доступ к файлу через Ambar из его базы данных
В настройках краулера можно указать из под какой учетки ходить. Во время поиска нет разделения файлов по правам
Botkin
Ага. Т.е. доступы не наследуются из ntfs?
но rbac присутствует?
Vinni37
Получается если помойка на терабайт, надо еще терабайт на Ambar выдать?
sochix Автор
Да, получается так. И еще надо добавить место для поискового индекса
Vinni37
Жаль, спасибо за ответ.
borisxm
Использую дома архивариус 3000 — держит только индекс (примерно 20-30% от исходного объема). Из минусов: закрытый, не умеет OCR и под линуксом работает только под вайном.
kudablin_a
угу, например для тектосвых файлов, вроде doc, html, pdf это где-то еще столько же места, сколько сами файлы. Покрайней мере так в recoll.