Количество данных, которые получает наш мониторинг выросло настолько, что для их обработки мощности только человеческого разума уже не хватает. Поэтому мы надрессировали искусственный интеллект помогать нам искать аномалии в полученных данных. И теперь у нас есть Кибер-Оракул.

1. Постановка задачи и мотивация
Здравствуйте, меня зовут Иван Хозяинов, я работаю в ITSumma. Компания занимается поддержкой и администрированием большого количества сайтов, основная задача — оперативно реагировать на происшествия и предотвращать их. Для этого у нас есть штат дежурных администраторов и система мониторинга, которая собирает важные показатели с серверов и сохраняет эти данные в общую базу.
Система мониторинга отправляет оповещение, когда достигнуто предельное значение одного из важных параметров. Какие параметры считать важными и какие именно значения будут для них предельными решают дежурные системные администраторы, когда настраивают мониторинг. Но ведь бывает явно странное поведение, которое проходит мимо системы мониторинга, потому что предельные значения не были достигнуты.

Рис.1 Система мониторинга
Чтобы заметить такие аномалии, надо постоянно просматривать огромный объем данных, физических возможностей человека для этого просто не хватит. Поэтому на помощь приходит всегда бодрое компьютерное железо и математика. Про задачу поиска аномалий в накопленном массиве данных о жизни серверов я и хочу вам рассказать.
2. История вопроса
Задача поиска аномалий достаточно общая и она интуитивно понятна: мы ищем что-то необычное среди данных. Тема будоражит сознание, поэтому логично, что существуют коммерческие продукты, которые этим занимаются, например http://anomaly.io и http://grokstream.com.
Но вернемся к самой задаче. Будем считать, что данные представлены набором измерений и каждое измерение представлено набором параметров, например текущие показания Load Average для CPU, HDD Free Space и т.д. С точки зрения математики это можно представить в виде вектор-функции:
Где t — это время, а n — количество измеряемых параметров.
Существует множество статей на тему математических формализаций и подходов к ее решению. В обзорной статье [1] приводится классификация для типов аномалий:
- точечная — это когда конкретное измерение выбивается из общей картины: так называемый выброс или outlier
- коллективная — когда совокупность измерений аномальна относительно всего набора данных, даже когда каждое измерение не выбивается из общей картины: например, кардиограмма, где красным выделена коллективная аномалия из-за аритмии (рис. 2)

Рис. 2. Аномалия на кардиограмме - контекстуальная — в этом случае аномалия определяется с учетом контекста: например, низкая температура зимой — это нормально, а вот летом это уже будет аномалия (рис. 3). Хотя, смотря где — зависит от контекста

Рис. 3. Сезонность может задавать контекст: t2 — аномалия, а t1 — нет
Нахождение точечной аномалии чаще всего сводится к нахождению математического ожидания и стандартного отклонения, а затем все, что выбивается за определенный порог после стандартного отклонения, считается аномалией. Но все становится интереснее с контекстуальными и коллективными аномалиями.
В качестве контекста для временных рядов чаще всего выступает сезонность (англ. Seasonality) и тренды. Для фильтрации сезонности может использоваться экспоненциальное сглаживание Хольта-Винтера [2] [3]. Но пока этот контекст, как и тренды, мы затрагивать не будем. Так же в качестве контекста могут выступать дополнительные данные вроде логов на сервере [4]. Пока этого касаться тоже не будем, а посмотрим на возможность находить коллективные аномалии, вроде колебаний и пиков. Среди публикаций можно найти подсказки насчет использования нейронных сетей [3] и конкретных архитектур при поиске аномалий во временных рядах [5]. Попробуем максимально учесть рекомендации, хотя грабли все равно ожидаемо будут.
3. Выбор инструментов
Первое, что нам необходимо — это выбор программных и математических инструментов. В качестве математического инструмента будем использовать наивные формулы для детектирования сильных колебаний на графике, типа такой:
На идейном уровне это означает сумму всех возможных колебаний за определенный промежуток времени
Так как функция у нас дискретная, то и формула соответственно будет выглядеть как-то так:
Теперь можно определить порог и это будет готовый детектор всяких всплесков. Но определять будем не самостоятельно, а поручим это нейронной сети.
В качестве языка для прототипирования был выбран Python, сервера баз данных Clickhouse от компании Яндекс с довольно удобным использованием его из Python. Для работы с нейронными сетями был выбран фреймворк Tensorflow от Google. Считать все будем на двух GPU Nvidia GTX1080, потратив драгоценные мощности не на майнинг, а на настоящие исследовательские задачи.
С точки зрения математики нейронная сеть — это функция:
где Y — ответ на вопрос, а X — входные данные. Функция достаточно сложная, но её можно обучать, например, методом обратного распространения ошибки.
4. Подготовка данных
Недавно на хабре была опубликована неплохая статья на тему нейронных сетей, где отдельно выделен пункт препроцессинга. Хотелось бы дополнить, что помимо нормализации данных, на этом этапе можно еще озаботиться пополнением данных (например, интерполяцией), чтобы не было никаких пропусков. В идеальном мире измерения должны приходить с серверов и писаться в базу каждые 15 секунд, но в реальном мире какие-то метрики по различным причинам могут не доходить или доходить невовремя, поэтому требуется как-то восполнять эту пропущенную информацию различными допущениями. Например, мы хотим узнать изменение параметра Load Average для CPU, и в базе это будет выглядеть условно так:
| Время | 0:13 | 0:14 | 0:47 | 1:53 | 2:00 |
| Load Average | 1.73 | 1.8 | 1.6 | 1.5 | 1.48 |
Представим, что каждые 15 секунд — это одна единица времени t. Тогда, если совершить достаточно простое заполнение массива, то все будет выглядить так:
| t | 1 | 2 | 3 | 4 | 5 |
| x(t) | 1.8 | -- | -- | 1.5 | 1.48 |
Конечно, можно построить линейную интерполяцию, но тогда время предварительной обработки данных может вырастать в разы (не говоря уже о более сложных способах), что критично для больших объемов данных. Даже, казалось бы, простое дополнение с учетом таких допущений может также сильно замедлить процесс подготовки данных:
| t | 1 | 2 | 3 | 4 | 5 |
| x(t) | 1.8 | 1.7 | 1.6 | 1.5 | 1.48 |
Поэтому в итоговом варианте был выбран самый тупой способ из возможных (он же и самый быстрый) — если значение пропущено, то берем ближайшее предыдущее.:
| t | 1 | 2 | 3 | 4 | 5 |
| x(t) | 1.8 | 1.8 | 1.8 | 1.5 | 1.48 |
Итак, у нас есть какая-то функция и можно начать формировать тензоры для обучения. С точки зрения программы на python, тензоры — это просто многомерные массивы.
5. Что было сделано сначала и как делать не стоит
Согласно одному из законов Кларка: «Любая достаточно развитая технология неотличима от магии». А учитывая, что нейронная сеть достаточно сложна для понимания за счет своей объективной структурной сложности и способна на невероятные вещи, то можно начать испытывать некоторое благоговение перед этим инструментом и совершать опрометчивые поступки.
С самого начала захотелось попытаться обучить нейронную сеть на всех существующих данных, разделив примерно таким образом: 90% для данных, которые мы будем считать нормальными. И 10% данных просто для проверки — вдруг там будет что-то аномальное. Ну и наоборот, выбрать самый скучный период жизни сервера в 10%, где ничего не происходит и после обучения проверить на оставшихся 90% данных.
Хотелось верить, что если сделать достаточно много слоев и загнать туда все данные, она сама выделит контексты и все сможет, если брутфорсом перебрать достаточное количество архитектур. Но для начала попробуем как это работает на простых функциях типа синусов-косинусов с небольшими изменениями.
В качестве входа на нейронную сеть подавался набор данных в логарифмическом масштабе или проще говоря так: текущее показание, 15 секунд назад, минуту назад, пять минут назад, полчаса и так далее до недели. Казалось, что это поможет выявить сезонность. После небольшого успеха на простой синусоиде — настало время прототипов.
Чтобы проще было писать прототипы использовался фреймворк tflearn на базе tensorflow. Как оказалось, там сложнее распределять задачи между GPU и это можно делать только через переменные окружения (https://github.com/tflearn/tflearn/issues/32), в отличие от tensorflow, где можно считать часть задач на одном GPU, часть — на другом в рамках одной программы.
Итак, для каждого сервера — своя нейронная сеть для обучения. После беспорядочного перебора архитектур из фреймворка, стало понятно, что терабайтного винчестера на машине с нейронками недостаточно.
Нейронная сеть для каждого сервера занимала больше 100 МБ и обучалась в среднем 40 минут, не считая предварительной подготовки, которая тоже занимала время. Набор данных для обучения после всей предварительной обработки занимал примерно 5—6 ГБ.
Конечно, было приятно смотреть в консоль и видеть как там что-то происходит. Была вера в волшебную силу этого черного ящика: вдруг брутфорсом получится подобрать волшебные параметры сети, не вникая в происходящее. Как можно догадаться — такой подход оказался неудачным.
6. Что работает сейчас и какой путь скорее всего правильный
Начнем с простых архитектур и многослойного перцептрона. Будем считать, что у нас задача классификации и есть два класса — «аномалия» и «не аномалия». Соответственно, нам нужны обучающие данные, которые требуется самостоятельно подготовить. Такой подход описан в [1] и нам необходимо подготовить наборы данных с «лейблами». Логарифмический масштаб был убран и на вход стал подаваться просто 25-минутный промежуток времени (100 измерений) + значение S из формулы (1).
График функции на которой производилось обучение представлен на рис. 4. На графике данные не нормализованные, но обучение производилось на нормализованных. Кстати, здесь представлена свободная память на одном из серверов — это то, что довольно часто меняется.
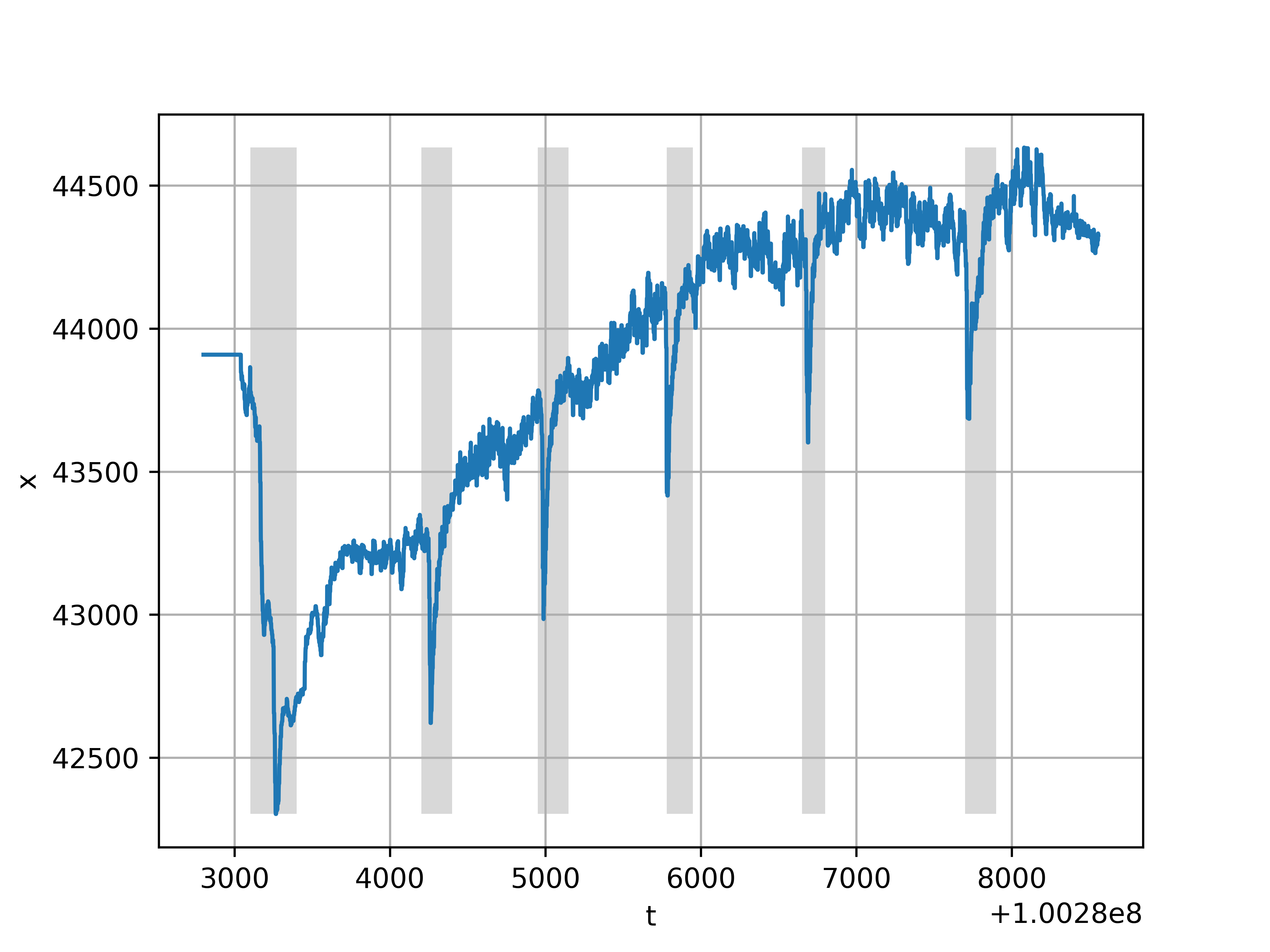
Рис. 4. Обучение с учителем, серым выделены аномалии
Входной слой у нас есть, там будет 101 нейрон, на первом скрытом слое — 55 нейронов, на втором скрытом слое — 1024, на выходе — класс «аномалия», «не аномалия». Архитектура сети была выбрана, можно сказать, случайно, поэтому наверняка возможен лучший вариант.

Рис 5. Обучение перцептрона с двумя скрытыми слоями
Сеть обучалась методом стохастического градиентного спуска Адама с параметром learning_rate = 0.00005, остальные параметры оставлены по умолчанию. В качестве меры была выбрана перекрестная энтропия между выходом нейронной сети и обучающим набором, функция активации — сигмоида или логистическая функция. Так как скрытых слоев два, то это уже можно сказать deep learning.
Поиск аномалий при помощи обученной сети на том же сервере, но за больший промежуток времени — за два дня, видно, что надо избавляться от сезонности (рис. 6).

Рис 6. Результат работы нейронной сети — график посередине, снизу — вход, сверху — интерпретация на ненормализованных данных
Интересно проверить как обученная нейронная сеть на одном параметре (свободная память), будет справляться с другим (load average) на совершенно другом сервере. Результат можно видеть на картинке. За счет того, что данные нормализованы — можно видеть, что «аномалии» находятся и на другом масштабе (рис. 7).
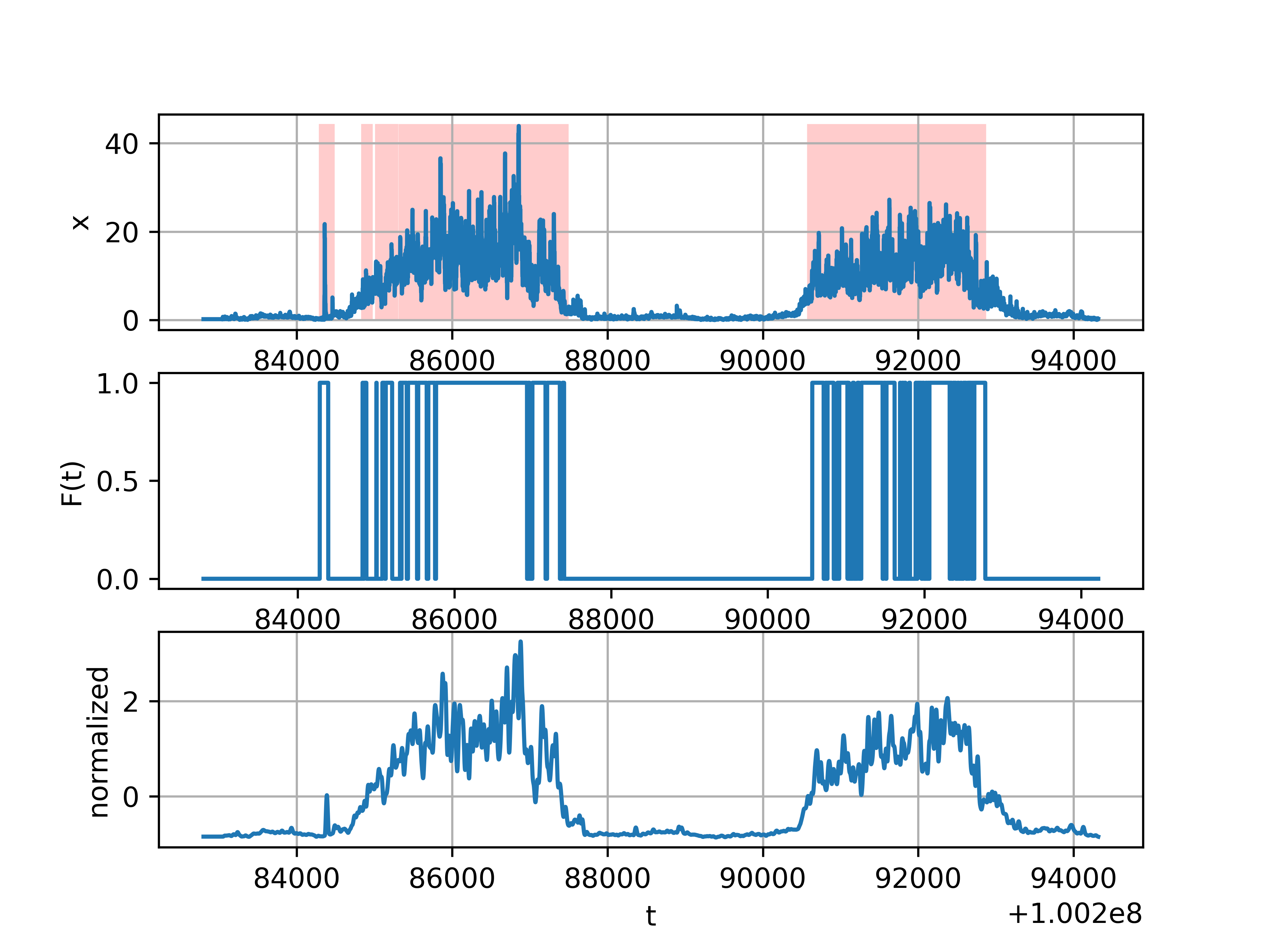
Рис. 7. Результат работы нейронной сети на другом наборе данных
7. Выводы
Наиболее эффективным образом нейронные сети проявили себя после подходящей подготовки данных. Собственно, в [3] упоминается, что «машинное обучение — это мета-инструмент, который можно использовать поверх других инструментов работы с данными». Надеюсь, кому-то этот опыт будет полезен. Спасибо за прочтение, буду рад комментариям.
Литература
[1] http://cucis.ece.northwestern.edu/projects/DMS/publications/AnomalyDetection.pdf — Varun Chandola, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly detection: A survey. ACM Comput. Surv. 41, 3, Article 15 (July 2009), 58 pages.
[2] http://www.imvu.com/technology/anomalous-behavior.pdf Evan Miller. 2007. Aberrant Behavior Detection in Time Series for Monitoring Business-Critical Metrics (DRAFT)
[3] http://www.oreilly.com/webops-perf/free/files/anomaly-detection-monitoring.pdf
Preetam Jinka & Baron Schwartz. 2015. Anomaly detection for monitoring: A statistical approach to time series anomaly detection. O’Reilly.
[4] https://wwЛw.microsoft.com/en-us/research/publication/context-aware-time-series-anomaly-detection-for-complex-systems/ Gupta M., Sharma A.B., Chen H., Jiang G. 2013 Context-Aware Time Series Anomaly Detection for Complex Systems. Proceedings of the SDM Workshop.
[5] https://www.elen.ucl.ac.be/Proceedings/esann/esannpdf/es2015-56.pdf Pankaj Malhotra, Lovekesh Vig, Gautam Shroff, Puneet Agarwal. Long Short Term Memory Networks for Anomaly Detection in Time Series. ESANN 2015 Proceedings.
Ссылки
https://clickhouse.yandex/ — база данных, удобная для хранения и работы с большими объемами однотипных данных
https://github.com/Infinidat/infi.clickhouse_orm – python библиотека для работы с clickhouse
http://tensorflow.org/ — опенсурс-библиотека от Google для работы с нейронными сетями
http://tflearn.org – удобный фреймворк для работы с tensorflow
http://anomaly.io, http://grokstream.com – продукты, занимающиеся детектированием аномалий
Комментарии (24)

little-brother
03.11.2017 14:37Эх, думал будет результат повеселее. Разве средняя нагрузка в норме такого иметь не может?
Отслеживание аномалий и сезонность решаются статическими методами, описанными например тут. Надеялся увидеть решение для «кардиограммы».
Как мне кажется, если бы вы смогли выявлять аномалии в данных мониторинга, то в таком случае надо уже выпускать коробочный продукт.
sairus777
03.11.2017 15:00А Вы решаете какую-то задачу для «кардиограммы»?
little-brother
03.11.2017 17:35Увы, нет :(
Просто разрабатываю свой велосипед для мониторинга и понимаю, что стандартные проверки на выход за пределы критичных интервалов уже отживают — слишком многое они пропускают, как выходящее из строя оборудование, так и подозрительную активность в сети.
На рынке систем мониторинга уже начинают почесываться, напр. DataDog предлагает свой алгоритм, правда на основе статистики, у Prometheus то же похоже что-то есть. Популярный Zabbix в этом плане в аутсайдерах.
Между тем кто-то даже целый бизнес на поиске аномалий строит.

IvanKhozyainov Автор
03.11.2017 16:09Да, вы правы, нагрузка в норме может быть такая, поэтому «аномалия» в кавычках. Следует работать с контекстом и как-то его убирать. Спасибо за интерес, возможно, в будущем результаты будут повеселее.
sairus777
03.11.2017 14:49«это означает сумму всех возможных колебаний» — скорее уж длина кривой
IvanKhozyainov Автор
03.11.2017 16:06Сумма в смысле как сумма Дарбу. Чтобы перейти потом к дискретному выражению. А так — да, все правильно, интеграл — как швейцарский нож: можно и площадь определять и длину кривой :)
sairus777
03.11.2017 14:54Вопросы:
1) Интересно было бы раскрыть — почему был убран «логарифмический масштаб» по времени? Мне кажется, возможные проблемы тут — подобие anti-aliasing и большое количество масштабов. Попробуйте номинальный ряд или геометрическую прогрессию q=2.
2) Пробовали ли Вы дополнять набор данных какими-нибудь интегральными параметрами ряда (среднее, СКО, размах, тренд, % мощности спектра на разных полосах частот и т.д.) — опять же, на разных масштабах/окнах? Как убирали лишние параметры?
3) Нормировка данных — что на что нормировали, на каком окне?
4) Это один временной ряд, или несколько (многомерный ряд)? А с разреженными рядами работали?IvanKhozyainov Автор
03.11.2017 16:061) К логарифмическому масштабу, возможно, стоит вернуться, но с некоторыми допущениями. Например, брать еще соседние значения. Либо использовать какое-то подобие сверток.
2) Да, на мой взгляд эти дополнительные параметры как раз и есть отличный подход. Так как данные уже нормализованы, то среднее и мат. ожидания не думаю, что дадут какой-то эффект. Тренды планируется убирать, в качестве параметра не известно какой. А мощность спектра и использование FFT — да, думаю будет полезно. Думаю, что тут нет лишних параметров, просто их надо как-то еще суметь использовать. Пока не знаю — были эксперименты в песочницы, надо смотреть.
3) Нормировалось за месяц, считалось за сутки. Иногда нормировалось ровно за тот период времени, который считался — например, за неделю и считалось тоже за неделю.
4) В п. 5 — многомерный, п. 6 — одномерный. Разреженные ряды — это из области преобразований Фурье? Судя по всему — ряды не разреженные, но надо проверять, не могу сказать ничего определенно.sairus777
03.11.2017 17:442) Лишние параметры у вас будут, когда вы одну и ту же смысловую характеристику будете пытаться натягивать на разные формулы. Например, модуль производной похож на СКО — и что, надо ли их оба использовать? Медиана похожа на среднее и на межквантильное среднее. Да и вообще — накапливается слишком много [параметров x способов нормировки x разных масштабов], и с этим надо что-то делать.
3) А нормировать одни масштабы на другие пробовали? Малые на большие, малые на средние, средние на большие?
4) Разреженные ряды — это когда вам лень считать скользящие средние по всем точкам, и вы считаете с неким шагом. Или когда из разных источников разная частота дискретизации.
___
Еще вопрос — инструмент ручной разметки вы сами делали, или есть какие-то готовые тублоксы?IvanKhozyainov Автор
03.11.2017 22:202) Думаю, что ничего страшного в дублировании параметров с точки зрения обучения сети не будет. Если параметры похожи, то на выходе просто могут обучиться вместо w условно говоря 0.5*w. Пока не встречались явные проблемы. Масштаб важно соблюдать, согласен.
3) Ну в каком-то смысле рис. 6 и рис. 7 — это разные масштабы. ИНС вполне может как-то с этим жить.
4) Нет, ряд всегда полный и дополняется какой-то интерполяцией. Быстрее всего просто делать как на последней таблице (если значение пропущено, то берем ближайшее предыдущее)
Если про выбор обучающего набора, то можно использовать небольшие веб-приложения пользуясь js-библиотеками типа www.flotcharts.org/flot/examples/interacting/index.html
Ну либо вручную. Если вопрос про графики, то в основном хватает стандартного matplotlib.
DRVTiny
04.11.2017 18:22+1Я администрирую довольно большую систему мониторинга, меня конечно не могла не заинтересовать Ваша статья. А не могли бы описать use case о том, как, собственно, вы используете полученные данные? Я просто даже не могу себе представить, как бы это могло выглядеть? Нейросеть анализирует данные в реальном времени и сигнализирует об аномалиях? Высылаются отчёты о выявленных аномалиях каждую ночь?
Дело в том, что в конечном-то итоге человек принимает решение о том, что делать со всей поступившей от нейронной сети информацией. У нас, например, тысячи виртуальных машин, серверов заведены как раз-таки в Zabbix — положим, в их «поведении» и правда есть аномалии, мы их даже выявили все в наилучшем виде. А дальше-то что с этим всем делать?IvanKhozyainov Автор
04.11.2017 18:55Спасибо за вопрос. Да, в конечном счете решение принимает человек. Сейчас это просто дополнительная рекомендательная система для того, чтобы выявить то, на что следует обратить внимание. Основная внутренняя разработка — система мониторинга, которая реагирует на пороговые значения, по-прежнему используется. Это ни в коем случае не альтернативное решение.
Основная мотивация для создания этой дополнительной системы в том, что данных действительно много и если есть хороший способ что-то среди них «увидеть» с помощью дополнительного «органа чувств», то это может оказаться полезным.
В данное время система еще в процессе интеграции, поэтому большой опыт использования еще не наработан. Использование в реальном времени требует больше ресурсов, но для некоторых серверов можно сделать исключение, а по остальным уже генерировать отчеты за определенный период.
little-brother
04.11.2017 23:48Об использовании аномалий при мониторинге интересная статья у Мейл.ру была. В их блоге еще есть, но эта, по мне, — самая впечатляющая.
openbsod
04.11.2017 18:23+1Спасибо вам, очень интересная статья. Не рассматривали открытые варианты вида morgoth, banshee — в дополнение к собственной разработке Кибер-Оракула?
IvanKhozyainov Автор
04.11.2017 19:25Спасибо за отзыв. Да, morgoth от разработчика InfluxDB активно развивается и интересно за этим следить. Но там используются в основном статистические методы, а не нейронные сети. Конечно, кое-что можно оттуда почерпнуть и там прямо в гит-репозитории есть ссылка на статью www.vldb.org/conf/2002/S10P03.pdf
Весь проект написан на Go и больше заточен на использование с инфраструктурой Kapacitor (от того же разработчика).
Второй упоминаемый проект (https://github.com/eleme/banshee) тоже написан на Go, и также использует статистические методы для нахождения первого типа аномалий — точечные (outlier) по метрикам. Там больше заточенность на использование в real-time и это тоже можно сказать коробочное решение.
Про Go написал два раза — не холивара ради (хорошо отношусь и к Go и к Rust), а для подчеркивания того, что это уже почти готовое решение «в коробке» завязанное на определенное окружение. Поэтому использоваться вряд ли будет, хотя на некоторые элементы можно обратить внимание, поэтому за этими проектами стоит следить. Если что-то изменится, то все возможно :)openbsod
04.11.2017 20:09+1Собственно, аналогично — подчеркивать именно Go цели не было. Хотел обратить внимание к тому факту, что в open source сейчас много инструментов, выполняющих похожие функции. Это ничуть не умаляет отличного качества вашей статьи. В том же ClickHouse начали мерджить коммиты с CatBoost ( пока, правда, тренировки нет, с готовой моделью ).
IvanKhozyainov Автор
04.11.2017 20:38В этом смысле правда, хорошее дополнение, про существующие открытые разработки в статье не было упомянуто, только про коммерческие продукты. По простому запросу в гитхабе github.com/search?q=anomaly на текущий момент найдено 1863 репозитория, где есть много чего достойного изучения.
Но многие из существующих решений ищут аномалии по принципу «найти стандартное отклонение, среднее и все, что лежит за пределами трех сигма считать аномалией». Поэтому хотелось посмотреть в сторону фундамента, на котором это все строится — математических моделей. Естественно, что велосипеды изобретать не стоит, но область обширная и интересная — надо изучать и экспериментировать.openbsod
04.11.2017 21:29+1Что ж, в рамках только белой зависти желаю всем такую занятость в которой совпадают возможности и работать, и заниматься настолько интересными проектами. Благодарю вас за references по используемой литературе и infi.clickhouse_orm
IvanKhozyainov Автор
04.11.2017 22:14Спасибо. Рад, что материал оказался полезен.
Надеюсь, что со временем и при помощи автоматизации всей рутины, людям останутся только творческие и интересные задачи :)
Sharapoff
Мне кажется, не те данные вы анализируете этим методом (я про LA и freemem).
IvanKhozyainov Автор
Спасибо за комментарий. Да, вероятно, вы правы, просто графики этих функций привлекли внимание своей активностью. Все остальные графики вроде работы дисков и сетевых интерфейсов вели себя как-то ровнее.
Конечно, есть еще более 30 параметров и на каком-то из серверов, возможно, что-то сработает лучше. Область обширная, эксперименты еще продолжаются, и если подскажете куда стоит посмотреть — буду благодарен.
Sharapoff
Я бы сказал так, что операционные показатели серверов этим методом мониторить плохо (это моё мнение, возможно я что-то не знаю). К примеру, даже на вашем графике по памяти, если будет плавный рост без провалов, то система не будет алярмить, но память закончится :(. Я бы предложил поиграться с обучающими данными, к примеру, брать значения за день, 2, 3 и т.д. в этот момент времени (также можно добавить соседние значения).
Из операционных показателей серверов, наверное, можно анализировать так трафик.
Лучше всего таким образом анализировать бизнес метрики.
IvanKhozyainov Автор
Спасибо за развернутый ответ. Да, в данном случае, если память плавно дойдет до критического значения, то правда — как аномалия это считаться не будет, но тогда просто сработает обычная «грубая» сигнализация по пороговому значению (например, 80%) на что уже будет реакция чтобы память не закончилась :)
Сейчас аномалии — это «дергания» и любые резкие движения, на которые нейронная сеть реагирует, даже если параметры не доходят до порогового значения.
Про бизнес-метрики понял, еще раз спасибо.