
Есть прекрасная поговорка «И на старуху бывает проруха». Её можно сделать девизом индустрии: даже хорошо продуманная многоуровневая система защиты от потери данных может пасть жертвой непредвиденного бага или человеческой ошибки. Увы, такие истории не редкость, и сегодня мы хотим рассказать о двух случаях из нашей практики, когда всё пошло не так. Shit happens, как говаривал старина Форрест Гамп.
Случай первый: баги вездесущи
У одного нашего заказчика использовалась система резервирования, спроектированная с целью защиты от аппаратного сбоя. Для обеспечения высокой доступности функционирования уровней инфры и приложений использовалось кластерное решение на базе ПО Veritas Cluster Server. Резервирование данных достигалось с помощью синхронной репликации средствами внешних дисковых массивов. Перед обновлением системы или отдельных ее компонент всегда проводилось длительное тестирование на стенде в соответствии с рекомендациями производителя ПО.
Cистема грамотная, распределенная по нескольким площадкам на случай потери одного дата-центра целиком. Казалось бы, всё хорошо, решение по резервированию прекрасное, автоматизация настроена, ничего страшного произойти не может. Система работала уже много лет, и никаких проблем не возникало — при сбоях всё отрабатывало штатно.
Но вот настал тот миг, когда упал один из серверов. При переключении на резервную площадку обнаружили, что одна из крупнейших файловых систем недоступна. Долго разбирались и выяснили, что мы наступили на программный баг.
Оказалось, незадолго до этих событий накатили обновление системного софта: разработчик добавил новые фичи для повышения производительности. Но одна из этих фич глюканула, и в результате оказались повреждены блоки данных одного из дата-файлов БД. Он весил всего 3 Гб, но вся беда в том, что его пришлось восстанавливать из бэкапа. А последний полный бэкап системы был… почти неделю назад.
Для начала заказчику пришлось достать всю базу из бэкапа недельной давности, а затем применить все архивные логи за неделю. На то, чтобы достать несколько терабайт c лент, ушла куча времени, потому что СРК фактически зависит от текущей нагрузки, свободных приводов и ленточных накопителей, которые в самый нужный момент могут оказаться занятыми другим восстановлением и записью очередного бэкапа.
В нашем случае всё оказалось ещё хуже. Беда не приходит одна, ага. Восстановление из полного бэкапа прошло достаточно быстро, потому что были выделены и ленточки, и приводы. А вот бэкапы архив-логов оказались на одной ленте, так что запустить параллельное восстановление в несколько потоков не получилось. Мы сидели и ждали, пока система находила на ленте нужную позицию, считывала данные, перематывала, снова искала нужную позицию, и так раз за разом по кругу. А поскольку СРК была автоматизированная, то на восстановление каждого файла генерировалось отдельное задание, оно попадало в общую очередь и ожидало в ней освобождения необходимых ресурсов.
В общем, несчастные 3 гигабайта мы восстанавливали 13 часов.
После этой аварии заказчик пересмотрел систему резервирования и задумался над ускорением работы СРК. Решили отказаться от лент, рассмотрели вариант с программной СХД и применением различных распределенных файловых систем. У заказчика уже были на тот момент виртуальные библиотеки, но их количество увеличили, внедрили программные комплексы дедупликации и локального хранения данных для ускорения доступа.
Случай второй: человеку свойственно ошибаться
Вторая история более прозаичная. Подход к построению систем распределенного резервирования был стандартизирован в то время, когда никто не предполагал наличие низкоквалифицированных кадров за консолью управления сервера.
На высокую утилизацию файловой системы сработала система мониторинга, дежурный инженер решил навести порядок и почистить файловую систему на сервере с базой данных. Инженер находит журнал аудита базы данных — как ему кажется! — и удаляет его файлы. Но нюанс в том, что сама база данных тоже называлась «AUDIT». В результате дежурный инженер заказчика перепутал каталоги и лихо удалил саму базу данных.
Но база данных в этот момент работала, и свободное место на диске после удаления не увеличилось. Инженер начал искать другие возможности уменьшить объем файловой системы – нашел их и успокоился, при этом никому не рассказав о проделанном.
Прошло примерно 10 часов, прежде чем от пользователей начали приходить сообщения, что база данных работает медленно, а какие-то операции вообще не проходят. Наши специалисты начали разбираться и выяснили, что файлов-то и нет.
Переключаться на резервную площадку смысла не было, потому что работала синхронная репликация на уровне массива. Все изменения, которые были проделаны на одной стороне, мгновенно отразились на другой. То есть данных не было уже ни на основной площадке, ни на резервной.
Инженера от самоубийства или суда Линча спас опыт наших сотрудников. Дело в том, что файлы базы данных располагались в кроссплатформенной файловой системе vxfs. Благодаря тому, что никто ранее не остановил работу БД, inode удаленных файлов не перешли во freelist, еще не были никем использованы. Если становить приложение и «отпустить» эти файлы, то файловая система доделает «грязное дело», пометит блоки, которые были заняты данными, как свободные, и любое приложение, которое запросит дополнительное место, сможет спокойно их перезаписать.
Чтобы спасти положение, мы на ходу разорвали репликацию. Это не позволило файловой системе на удаленном узле синхронизировать высвобождение блоков. Потом при помощи отладчика файловой системы пробежались по последним изменениям, выяснили, какие inode каким файлам соответствовали, перепривязали их, удостоверились, что файлы базы данных снова появились, и проверили консистентность БД.
Затем предложили заказчику поднять на восстановленных файлах экземпляр базы данных в standby-режиме и таким образом синхронизировать данные на резервной площадке без потери online-данных. Когда всё это было сделано, нам удалось переключиться на резервную площадку без потерь.
По всем расчетам первичный план восстановления при помощи СРК мог растянуться вплоть до недели. В данном случае обошлись деградацией сервиса, а не его полной недоступностью. Человеческая ошибка могла обернуться финансовыми и репутационными потерями, вплоть до потери бизнеса.
Тогда наши инженеры придумали решение. В 90% систем заказчика работают базы данных Oracle. Мы предложили оставить старую систему резервирования, но дополнить её системой резервирования на уровне приложения. То есть к синхронной репликации средствами массивов добавили еще и программную — средствами Oracle Data Guard. Его единственный недостаток в том, что после failover необходимо проделать ряд мероприятий, автоматизировать которые проблематично. Чтобы их избежать мы реализовали переключение экземпляров между площадками средствами кластерного ПО с подменой конфигов БД.
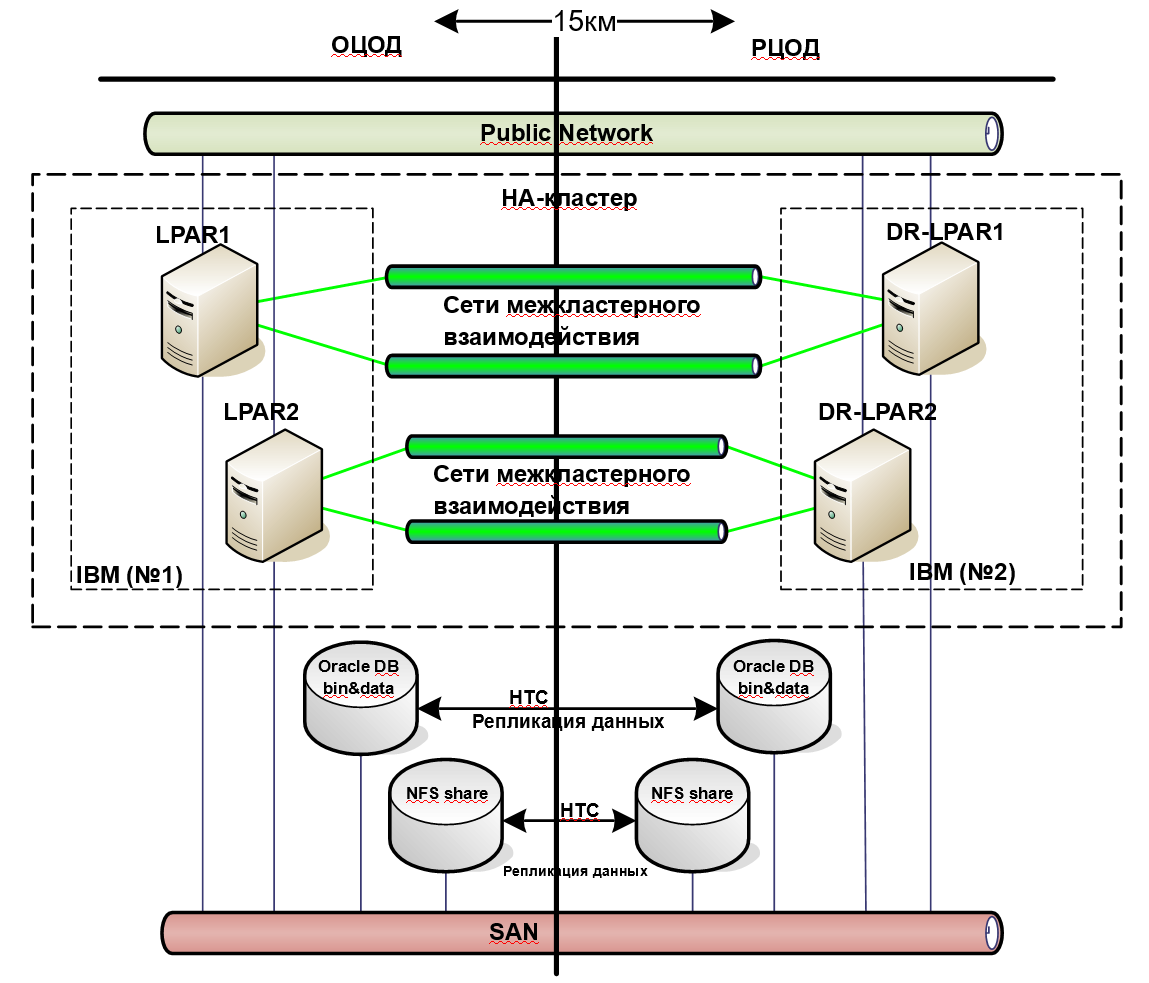
В результате появился дополнительный уровень защиты данных. К тому же новая система резервирования помогла снизить требования к массивам, так что заказчик сэкономил в деньгах, перейдя с массивов уровня Hi-End на СХД среднего уровня.
Вот такой Happy End.
Команда поддержки Enterprise-систем, «Инфосистемы Джет»
Комментарии (14)
ildarz
24.11.2017 15:21Первый случай — скорее все-таки совсем не о программном баге. RTO в систему при проектировании закладывали? Если да и оно меньше 13 часов — проектировщики и эксплуатанты сами себе злобные буратины, что не оттестировали "плохие" сценарии восстановления, если нет или оно больше — тогда о чем вообще разговор. :)
JetHabr Автор
24.11.2017 20:08Оба описанных случая из серии “всё делали правильно, но не оценили возможные риски”. Вероятность программного повреждения данных не рассматривалась заказчиком как риск, ведь решение было массовым, стабильно работало длительное время и таких случаев ранее не было.
По нашему мнению, инфраструктура критичных бизнес-систем должна строиться так, чтобы использование системы резервного копирования в случае повреждения или потери данных было именно резервным средством, а не основным механизмом восстановления доступности бизнес-систем.
Такой подход обусловлен двумя недостатками систем резервного копирования:
- Сложность прогнозирования длительности восстановления данных. Безусловно, система резервного копирования может быть спроектирована под заданные параметры SLA и обеспечивать их в момент своего старта. Однако, как показывает практика, ИТ-инфраструктура любой компании — постоянно изменяющаяся среда, содержащая постоянно растущие объёмы данных. Поэтому спрогнозировать длительность восстановления какой-либо бизнес-системы спустя некоторый промежуток времени достаточно сложно, а в случае массового сбоя, заставляющего восстанавливать множество бизнес-систем (например, при отказе дискового массива) — практически невозможно.
- Недостаточная степень гранулярности восстановления данных. Система резервного копирования, как правило, работает с данными бизнес-приложений на достаточно низком уровне. Это приводит к тому, что при повреждении или потере небольшого набора данных, к примеру, при удалении строки в таблице СУБД Oracle, приходится восстанавливать значительный объём данных — в данном случае целиком табличное пространство СУБД. То есть объём данных, который необходимо восстановить из СРК, часто не соответствует объёму данных, которые были потеряны или повреждены при сбое. Как в данном случае.
ildarz
27.11.2017 12:15Вероятность программного повреждения данных не рассматривалась заказчиком как риск, ведь решение было массовым, стабильно работало длительное время и таких случаев ранее не было.
Ну и что? RTO ведь не про риски, а про восстановление системы, в которой УЖЕ произошел сбой. Бэкап на ленты ведь в принципе делался? Делался. Значит, на какие-то сценарии, в которых потребуется восстановление с них, все же закладывались. И, если эти сценарии не оттестировали, это все-таки недоработка при проектирования системы восстановления (что, собственно, и подтвердилось тем, что заказчик решил ее оптимизировать).

danemon
24.11.2017 16:36А можно подробнее про вот это:
… внедрили программные комплексы дедупликации…
я думал что для админа резервного копирования дедупликация как для быка красная тряпка.JetHabr Автор
24.11.2017 20:03Это, скорее, к вопросу о поставленных задачах, ожиданиях и реальности. В контексте оптимизации СРК программно-аппаратные комплексы с дедупликацией позволяют сократить объем передаваемых данных — в случае с БД, в среднем 5:1, — и тем самым ускорить прохождение бэкапов. Как следствие, позволяет чаще запускать бэкапы и сократить RPO. На длительности восстановления это никак не сказывается.
danemon
27.11.2017 17:07На длительности восстановления это никак не сказывается.
Это понятно, но как с надежностью хранения? Если какая-то ошибка попадет условно говоря в первую полную копию, то все остальные Incremental и Differential копии будут бесполезны. Видимо там для надежности пристроены еще несколько велосипедов и педалей.
С железными «СРД» общался пока не так уж многосторонне, да и то самоучкой, поэтому интересуюсь.JetHabr Автор
27.11.2017 17:09Если ошибка затесалась, то дедуп или нет — не имеет значения. Восстанавливаться придется с предыдущего бэкапа в любом случае.
Если мы говорим об ошибке записи и битом блоке во время создания полной копии (или любой другой) и система резервного копирования это пропустила, то следующий бэкап при прохождении листинга файлов увидит несоответствие хранимого блока и того, что на системе. Как следствие получим резервирование данного блока. Противоречия нет:)

resetme
24.11.2017 21:04«И на старуху бывает порнуха» — извиняюсь, но два раза прочитал вот так вот в первой строчке. Я даже подумал, что эта фраза более точно описывает невероятное стечение обстоятельств приведших к утере данных.
besisland
25.11.2017 04:47Бессмыслица какая-то. В пословице речь о том, что даже у старухи может случиться менструация (старорусское слово: проруха).
resetme
25.11.2017 07:43Ни в одном толковом словаре нет такого объяснения этому слову. Этимология не установлена. Что вы упоминаете, есть только в постах обычных пользователей на форумах.
Да, бессмыслица, но такое событие может произойти и со старухой. Это придает изменённой фразе определенную окраску. Есть ненулевая вероятность участия старухи в порнухе, то же самое и с утерей данных. Проще говоря: вероятность утери данных никогда не равна нулю.
idamir
25.11.2017 10:18У нас в конторе на этот случай вывешивали баннер: «И про старуху снимают порнуху» (тогда мы занимались интеграцией продавцов с Amazon, eBay, Buy.com, shop.com и другими площадками).
Dioxin
27.11.2017 09:48Если один оранг… человек смог так сильно все уронить, то налицо ошибка проектирования.
Думать и тестировать все пришедшие в голову сценарии аварий.
Для этого надо принять в команду алармиста-параноика.
mikkisse
Спасибо. Пишите побольше таких интересных историй.