
Один из заказчиков, очень крупный интернет-магазин, как-то попросил нас обеспечить защиту веб-приложения от веб-атак. Учитывая масштабы ресурса, мы начали поиск нужного подхода. В результате решили применить комбинацию позитивной и негативной модели безопасности, реализовав её с помощью файрвола для веб-приложений (в данном случае в качестве WAF использовался продукт F5 ASM, но в целом подход универсальный для большинства WAF). Многие компании не любят пользоваться позитивной моделью, поскольку очень опасаются (и зачастую справедливо), что для части пользователей ресурс может оказаться недоступным и продажи снизятся, да ещё и придётся потратить массу времени на настройку политик. Однако без этого защита веб-ресурса не будет полноценной.
Что такое позитивная и негативная модель?
Негативная модель безопасности, наверное, самое простое, что может быть в WAF-е. С точки зрения логики работы, конечно же. Сама настройка может быть весьма нетривиальной. Описать негативную модель можно принципом «что не запрещено — то разрешено». Обычно это набор политик безопасности и сигнатур, которые содержат описание известных атак. Полагаться исключительно на такой подход по понятным причинам нельзя: всегда будет целая куча атак, под которые не написаны политики или сигнатуры. Однако и пренебрегать такой моделью тоже не стоит, т.к. она является первым рубежом обороны, особенно когда у вас еще нет готовой позитивной модели или она находится в процессе построения.
Позитивная модель безопасности описывает структуру веб-ресурса со всеми возможными ограничениями. Работает эта модель по принципу: «что не разрешено — то запрещено». Отклонения от этой модели должны блокироваться. В основу позитивной модели безопасности ложатся URL, параметры и методы. Причем позитивную модель можно настроить очень жестко, например, для каждого URL описать, какие методы можно для нее использовать, какие параметры, описать допустимые значения этих параметров, с каких URL можно на нее переходить. Создать такую модель для крупного сайта – задача не из легких. А если сайт еще и меняется каждую неделю-две, поддерживать выстраданную и вылизанную модель в актуальном состоянии непросто. Также следует учитывать, что гарантировать абсолютную корректность построенной модели вам не сможет никто. А это значит, что абсолютно нормальные пользовательские запросы вполне могут быть заблокированы. Отсюда делаем вывод, что позитивная модель – это, конечно, хорошо и безопасно, но с доступностью ресурса могут возникнуть проблемы. Жестко определенная позитивная модель жизнеспособна только для небольших нечасто меняющихся ресурсов. Следовательно, для крупных и быстро меняющихся придется ее ослаблять в угоду доступности. Но об этом чуть позже.
В итоге мы получаем, что использование только одной из этих моделей имеет существенные недостатки: для негативной модели это невысокий уровень безопасности, для позитивной – возможные проблемы с доступностью веб-ресурса. А вот если комбинировать оба решения, уже можно получить приемлемый уровень как безопасности, так и доступности ресурса.
Разработка системы защиты
Вот как выглядит недельное среднестатистическое распределение по видам атак на интернет-магазин заказчика (на основе срабатывания негативной модели):
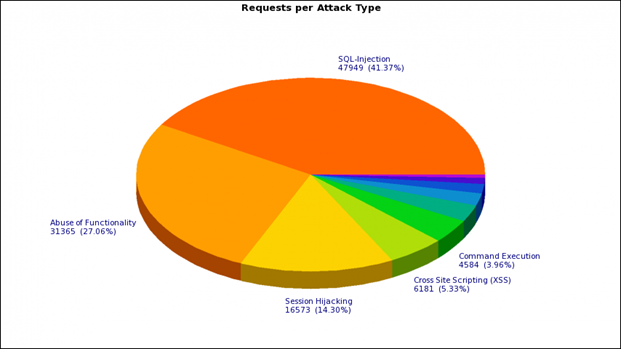
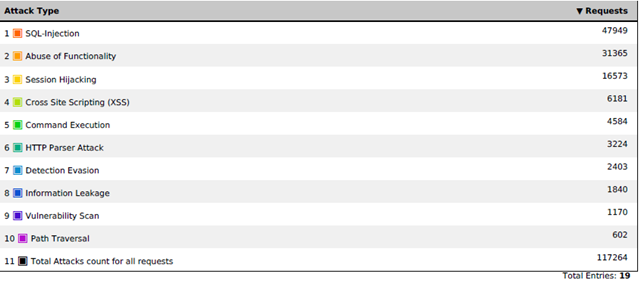
Как вы, наверное, уже поняли, мы решили не отступать от классического подхода к защите веб-приложения и создать гибрид позитивной и негативной модели. Начали с негативной. В F5 ASM большой набор сигнатур, доступных из коробки – достаточно выбрать подходящие группы из списка. Сигнатуры могут быть как системонезависимыми, так и предназначенными под определенный тип системы (IIS, Apache, MySQL, MSSQL и т.п.). Назначать все сигнатуры подряд нецелесообразно – это только повысит нагрузку на WAF и может привести к появлению дополнительных ложных срабатываний. Например, если у вас IIS на Windows, нет особого смысла назначать сигнатуры группы Linux, если только вы не хотите избавиться от всех мусорных запросов, идущих в сторону веб-сервера, даже если они и не могут никак навредить.
Сигнатуры — относительно точный метод, однако иллюзий можете не испытывать: избежать ложных срабатываний всё равно не получится. Например, мы столкнулись с ситуацией, когда разработчики включили в название нескольких URL слово «shell» (в контексте «бампер» или «чехол»). Для таких случаев, естественно, придется настраивать исключения. Обработав ложные срабатывания, настроив исключения для одних случаев или отключив сигнатуру в принципе – для других, мы получили базу для защиты сайта. Чуть не забыл: помимо сигнатур, WAF’ы могут валидировать веб-запросы на соответствие RFC, что позволяет заблокировать всякий мусор и некорректно сформированные HTTP-запросы. Пренебрегать такой защитой мы, конечно же, не стали.
А вот чтобы найти подход к позитивной модели безопасности, нам пришлось изрядно попотеть. На сайте больше 10 тыс. разнообразных URL. Самой первой и самой безумной мыслью было построить полноценную позитивную модель с полным перечнем URL, однако мы довольно быстро поняли нецелесообразность такого подхода. А до того, как мы это поняли, мы успели попробовать получить этот список автоматически.
Важная ремарка: построить позитивную модель можно и в ручном режиме, но удовольствие это сомнительное. У современных WAF’ов присутствует механизм автоматического обучения, который на основе запросов пользователей как раз и строит ту самую позитивную модель.
Но не всякий Machine Learning одинаково полезен. Да, чтобы элемент попал в позитивную модель, он должен встретиться не в одном веб-запросе, а также прийти с разных адресов. Но в итоге получается все равно довольно приличное количество мусора, который нужно чистить. Также не забываем про URL и параметры с динамическими элементами. Их может быть очень много, и они могут сделать позитивную модель необслуживаемой. У нас после автоматического обучения получилось как раз нечто такое, необслуживаемое. Усугублялось все тем, что ежедневно на веб-ресурс добавлялось/удалялось от нескольких десятков до сотни URL и система просто не успевала так быстро вносить изменения.
Вторая попытка получить список URL автоматически заключалась в чтении sitemap.xml, который в свою очередь содержал ссылки на страницы с необходимым нам, как мы тогда думали, содержимым. Перечень URL, полученных таким способом, мы загружали по API. Он был довольно велик. Однако и этот список не оказался полным.
После проведенных экспериментов мы скрепя сердце решили отказаться от белого списка URL, чтобы не плодить кучу срабатываний политики в случае отсутствия URL в заданном списке. Вместо этого решили прибегнуть к другому подходу — защите, основанной на параметрах, в которых передаются как пользовательские, так и какие-то внутренние данные. Наибольшее число атак осуществляется как раз через параметры. С учетом того, что от «белого списка» URL мы отказались, параметры решили защищать без привязки к конкретному URL. В используемом в данном проекте WAF’е такая возможность есть за счет использования концепции Global Parameters.
Проблема может возникнуть, если на разных URL есть параметры с одним и тем же именем, но содержащие разные типы данных. Обычно, правда, так мало кто делает. Но если столкнулись с подобной проблемой, придется определить эти параметры для каждого URL в отдельности и указать для них разные допустимые значения.
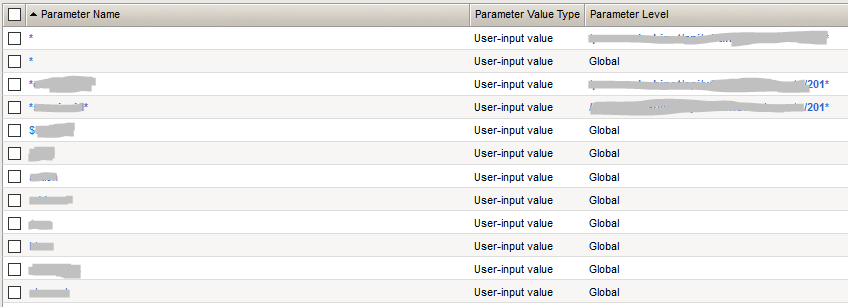
В случае с интернет-магазином, который мы защищали, сработало скорее правило, чем исключение, и если на разных страницах встречались параметры с одинаковым именем, то они содержали данные одного типа. Так же мы исходили из того принципа, что через параметры, которые могут содержать исключительно число-буквенные значения без спецсимволов, атаковать крайне проблематично. И поэтому в список защищаемых параметров, поместили только те, которые содержат спецсимволы, все остальные описали как «*». Таким образом, если появляется параметр, содержащий спецсимвол, мы добавляем его в список. Для всех остальных параметров действует ограничение: они должны содержать только число-буквенные значения.
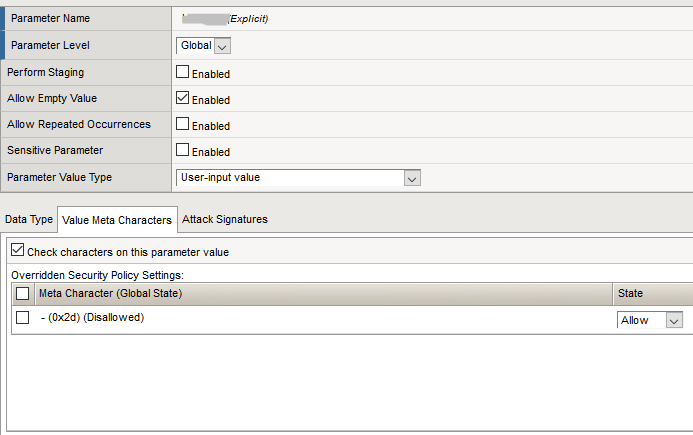
В итоге получилось около 300—400 параметров. Такую модель уже вполне можно обслуживать. После того как эта модель стабилизировалась, и число ложных срабатываний снизилось до приемлемой величины, наступил следующий этап, который многие игнорируют в связи с натянутыми отношениями между подразделениями. И совершенно зря. Крайне желательно согласовать полученную модель с разработчиками веб-приложения заказчика. Этот шаг может существенно повысить качество построенной модели. В нашем случае со стороны заказчика работали довольно толковые специалисты, которые, несмотря на высокую занятость, пошли нам навстречу. Тратить время на ознакомление разработчиков с интерфейсом WAF’а мы не стали. Вместо этого написали простенький скрипт на Python, который парсит политику WAF в формате XML и на выходе дает csv-файл с перечнем параметров и разрешенными для них спецсимволами. Файл передается разработчикам, они ищут нужный параметр у себя в словарике и корректируют допустимые значения в случае необходимости.
Одна из проблем позитивной модели безопасности заключается в том, что некоторые параметры сложно как-либо ограничить. Например, вводимые пользователями комментарии, особенно когда заказчик не хочет ограничивать пользователей. В этом случае для защиты таких параметров придется пользоваться услугами негативной модели безопасности, проверяя пользовательский ввод на наличие известного вредоносного кода. Ну и конечно, такие параметры нужно дополнительно тщательно проверять на стороне самого web-сервера.
Еще одна особенность, с которой приходится сталкиваться, – ошибки ввода пользователя. Например, в поле ввода названия города пользователь пишет «{f,fhjdcr» вместо «Хабаровск». В итоге его запрос должен быть заблокирован, т.к. он нарушает допустимые значения параметра, в котором могут быть только число-буквенные значения. Казалось бы, ничего страшного: пользователь ошибся – пользователь поплатился. Но не всех заказчиков может устраивать подобная реакция WAF, и в этом случае придется ослаблять позитивную модель в угоду функциональности.
В итоге мы получили комбинированную систему, сочетающую в себе обе модели. Далее начинается довольно нудный процесс актуализации. C каждым выходом патчей или релизов позитивная модель может меняться, новые ложные срабатывания могут возникнуть как у одной, так и у другой модели.
Ну а после этого начинается самый ответственный этап — включение блокирующего режима. До этого момента WAF, конечно, работает, генерируя события безопасности, но не повышает безопасность веб-ресурса и никак не влияет на пользовательскую активность.
В нашем случае в связи со сложностью согласований на стороне заказчика процесс включения блокирующего режима сильно затянулся. Не хватало волевого решения, которое бы позволило двинуться дальше. Поэтому мы в течение достаточно длительного промежутка времени просто актуализировали существующие модели.
Введение в эксплуатацию
Наконец, заказчик решился, но выдвинул ряд довольно жестких требований.Количество ложноположительных срабатываний должно быть минимальным, а доступность сайта – максимальной. Требование, конечно, отличное, но сложно реализуемое на практике. При этом каких-либо количественных метрик для выполнения этих требований нам не предоставили. В среднем число web-запросов в день находилось в диапазоне 100-150 млн.
Как ранее было показано на рисунке, в среднем негативная модель срабатывала порядка 100-150 тыс. раз в неделю, что дает цифру около 20 тыс. срабатываний в день. Большинство из этих срабатываний — действительно атаки, в подавляющем числе случаев автоматизированные. Исходя из наших наблюдений, количество ложных срабатываний в процентном соотношении было в не больше 5%. Сразу оговорюсь: все 20 тыс. запросов в день мы не просматривали, однако настоящие атаки достаточно легко отсеиваются при анализе IP-адресов атакующих. Все запросы с адреса атакующего просматривать нет смысла, достаточно двух-трёх.
Позитивная модель давала еще порядка 50 тыс. срабатываний в день. По большей части они дублировали алерты негативной модели, и такие срабатывания можно было легко выкинуть из анализа, однако около 20 тыс. запросов приходилось анализировать. И здесь уже много зависит от того, как WAF может группировать срабатывания, упрощая анализ. В нашем случае WAF группировал срабатывания по спецсимволам, а дальше по параметрам, в которых этот спецсимвол встречался. Далее все более-менее просто: смотрим комбинацию, параметр – спецсимвол, для которого было наибольшее количество срабатываний. Если они были с большого диапазона IP, это признак того, что тревога могла быть ложной. А дальше анализируем примеры запросов. В большинстве случаев удается без посторонней помощи понять, атака это, ошибка ввода пользователи или недостаток позитивной модели. В случае спорных ситуаций не стоит брезговать общением с разработчиками (если, конечно, такая возможность имеется). После завершения анализа массовых срабатываний переходим к анализу единичных срабатываний. Их, как правило, сложнее анализировать, особенно в самом начале, когда не знаешь специфики работы приложений. По завершению анализа получаем от 5 до 10% ложных срабатываний, что в совокупности с ложными срабатываниями негативной модели дает до 6000 ложных срабатываний или 0,005% от общего количества запросов. Эта цифра уже не отпугивает – она в итоге и устроила заказчика. Важная ремарка: это совсем не означает, что работа 6000 пользователей будет парализована. Просто при переходе на некоторую страницу или при вводе некоторых данных пользователь будет перенаправлен на страницу с ошибкой, после чего он сможет продолжить нормально взаимодействовать с web-ресурсом.
Итого: цифры получены и они устраивают заказчика, однако не будет лишним перестраховаться, особенно, если на этом настаивает сам клиент. Решили вводить систему защиты в эксплуатацию поэтапно. Для тестового включения блокировки нам был любезно предоставлен макрорегион,, на котором заказчик тестирует свои новые релизы и патчи. Трафик там вполне боевой, регионы периодически меняются и есть города/области-миллионники. Копируем существующую политику и применяем ее к макрорегиону. А далее включаем блокировку, но тоже не сразу, а только для негативной модели. Тестируем в течение недели – количество ложных срабатываний не превысило расчетного значения. После этого включаем блокировку на основе негативной модели для всего сайта, тоже смотрим неделю, меряем показатели. Далее проделываем тот же фокус с позитивной моделью: сначала включаем блокировку для макрорегиона, неделю-две смотрим на результаты и включаем блокировку для всего сайта. Может показаться, что все прошло подозрительно гладко, но не забываем, что этому предшествовал длительный этап актуализации моделей, который и позволил нам включить защиту достаточно безболезненно.
Что делать, если нет полноценной тестовой зоны (тестовый макрорегион в нашем случае)? Можно выделить группу внутренних сотрудников, которые так же будут обращаться к ресурсу через WAF и включить блокирование только для этой группы пользователей. Да, такое тестирование менее полноценное, но все же лучше, чем ничего.
По итогам можно признать, что WAF это либо небыстро, либо некачественно. Многие заказчики не готовы ждать достаточное время для формирования качественной позитивной модели, либо не желают/не имеют возможности ее актуализировать. В связи с этим они либо отказываются от позитивной модели, либо оставляют ее на произвол судьбы, не включая блокирование. Есть еще те, кто целиком и полностью полагаются на автоматическое построение позитивной модели, в итоге она получается далекой от идеала. Оба таких подхода не способны обеспечить полноценной защиты. К настройке WAF нужно подходить основательно. Затраченное время того стоит.
Андрей Черных, эксперт Центра информационной безопасности «Инфосистемы Джет»
nikitasius
А чем naxsi не устроил. Роспил и все дела?
Serenevenkiy
А с чего вы про распил решили?
nikitasius
Когда опенсорсные годные решения заменяются на платные с рюшечками.