В достижении последнего одну из ключевых ролей играет правильный выбор накопителя для хранения данных. И к этой задаче у нас совершенно особый подход. Сегодня мы познакомим вас с методами, которые используем для классификации устройств хранения данных в рабочих станциях серии Dell Precision. Эта информация будет полезна тем, кто хочет разобраться в параметрах производительности самих рабочих станций и подсистем хранения.

Почему важна производительность накопителей?
Рабочие станции оснащаются наиболее быстрыми компонентами, доступными для клиентских систем. Когда дело доходит до хранилища, важно, чтобы профессиональные приложения не тратили большую часть времени, ожидая, когда завершится операция подсистемы хранения. Такие простои существенно снижают общие показатели производительности рабочей станции.
Классификация устройств хранения и уровни производительности
Даже если устройства хранения имеют одинаковую емкость, они могут отличаться форм-фактором, физическим электрическим соединением, протоколом доступа и, конечно, уровнем производительности —спецификациями, определяющими быстродействие таких устройств. Это особенно важно для твердотельных накопителей (SSD), характеристики которых могут быть принципиально разными в зависимости от внутренней архитектуры и применяемой флеш-памяти.
До того, как технология SSD стала основной, производительность жесткого диска часто определялась так называемыми спецификациями «тыла». Пользователь мог просто перевернуть накопитель и посмотреть на характеристики: скорость вращения, емкость кэш-памяти, среднее время поиска, а также значения пропускной способности и количество пластин внутри накопителя. Эти спецификации не всегда напрямую связаны с характеристиками работы отдельных приложений, но дают некоторую основу для сравнения разных дисков в экосистеме HDD.

Что же касается SSD, без использования определенных систематических методов сравнить производительность нескольких моделей будет очень сложно. Твердотельные накопители могут предусматривать в спецификациях какую-то описательную информацию, но сопоставлять SSD-интерфейсы, типы флеш-памяти и модели контроллера флеш-памяти с производительностью приложений не слишком рационально.
Что же касается SSD, без использования определенных систематических методов сравнить производительность нескольких моделей будет очень сложно. Твердотельные накопители могут предусматривать в спецификациях какую-то описательную информацию, но сопоставлять SSD-интерфейсы, типы флеш-памяти и модели контроллера флеш-памяти с производительностью приложений не слишком рационально.
SSD имеют существенные преимущества перед традиционными жесткими дисками, однако без какой-либо систематической оценки быстродействия бывает сложно сравнить друг с другом разные модели твердотельных накопителей. Классифицируя устройства хранения данных по результатам измерений производительности, Dell поднимает эффективность эксплуатации профессиональных рабочих станций.

SSD M.2 в ноутбуке Dell XPS 13 9365
Методы измерения
Измерения производительности необходимы для дифференциации твердотельных накопителей. Но что нужно измерять? По логике, чтение и запись — как случайные, так и последовательные. Если руководствоваться некоторыми из наиболее популярных тестов для клиентов, можно было бы сделать вывод о том, что следует измерять только пиковую производительность — максимально возможные значения пропускной способности или операций ввода-вывода в секунду (IOPS).
Эталонное тестирование для классификации накопителей по производительности
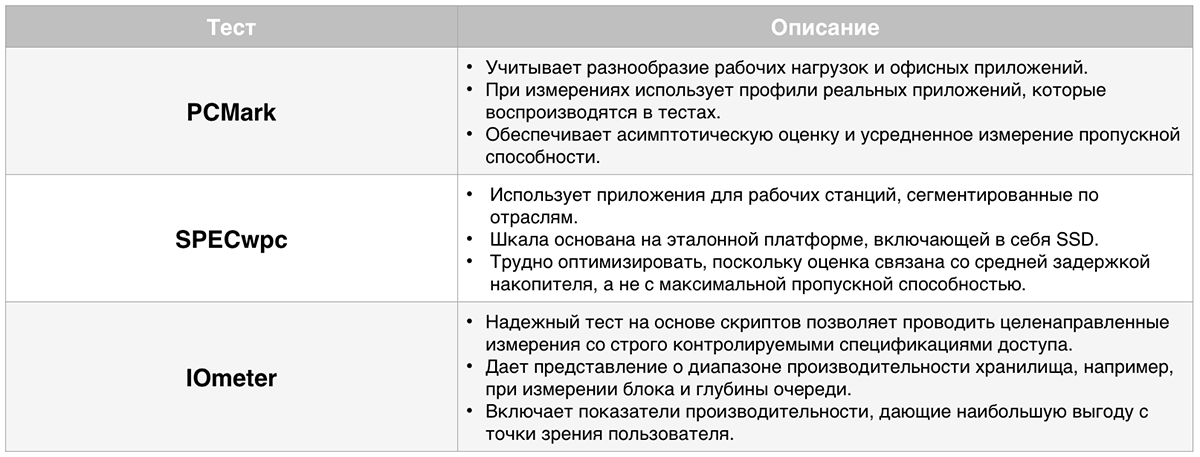
Пиковые значения и методы, которые используются для их измерения, могут соответствовать или не соответствовать тому или иному профессиональному приложению. Это особенно касается тестов, измеряющих максимальную производительность при идеальных условиях — например, значительной глубине очереди операций ввода-вывода, ожидающих выполнения в конвейере хранилища.
Чтобы соответствовать широкому спектру приложений рабочих станций и моделей использования, наши методы классификации хранилищ включают в себя несколько разных типов измерений. Они отражают как прикладные, так и синтетические характеристики.

Кластерный анализ
Результаты измерений производительности различных SSD используются в кластерном анализе. При этом применяется ряд алгоритмов кластеризации, в том числе центроидных и основанных на плотности, с последующим сравнением результатов.
Вероятно, из-за преимуществ шины PCI Express накопители SSD NVMe формируют четкую группу, отличную от SATA SSD. Это подтвердило наши предыдущие предположения, и мы стали выделять кластеры в каждом из этих интерфейсов.
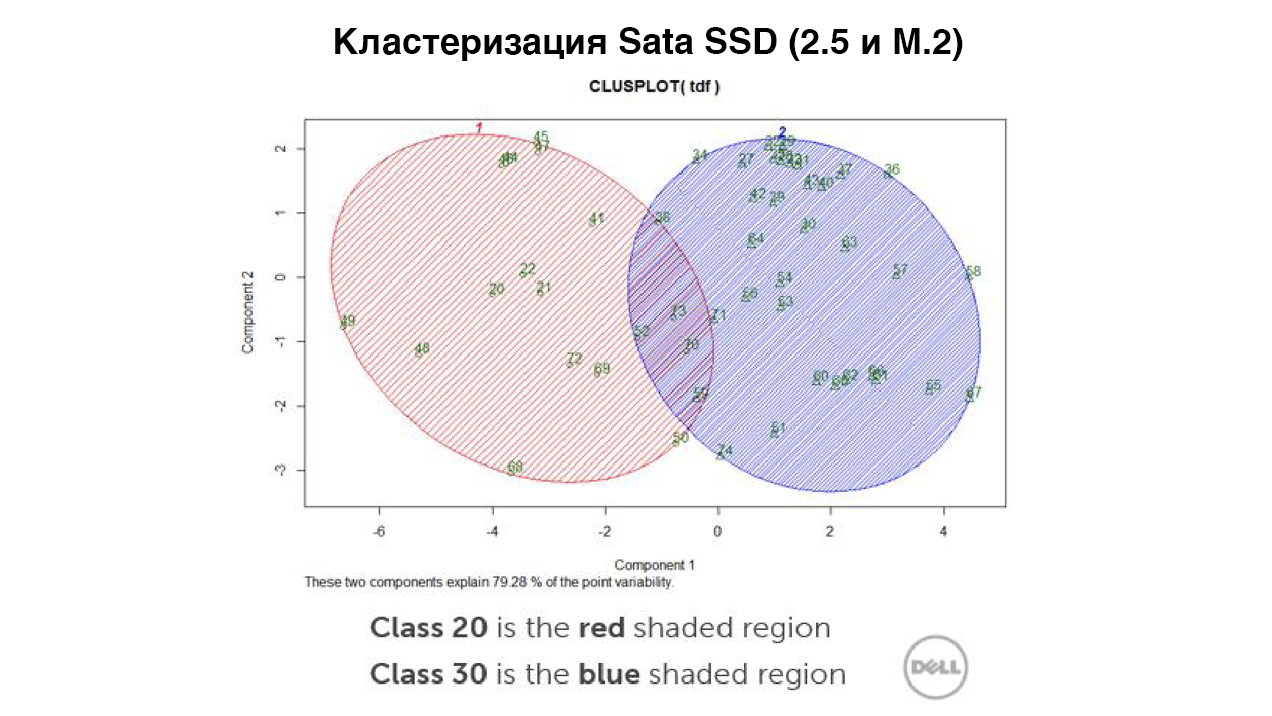
SATA SSD образовали два кластера: «основной», на модулях флеш-памяти TLC, и «высокопроизводительный» — на памяти MLC. Это показывает, что SSD на основе MLC превосходят SSD на TLC. Однако при выполнении некоторых измерений базовые накопители в высокопроизводительном кластере могут иметь такие же (или немногим худшие) характеристики, как и топовый накопитель в другом кластере.
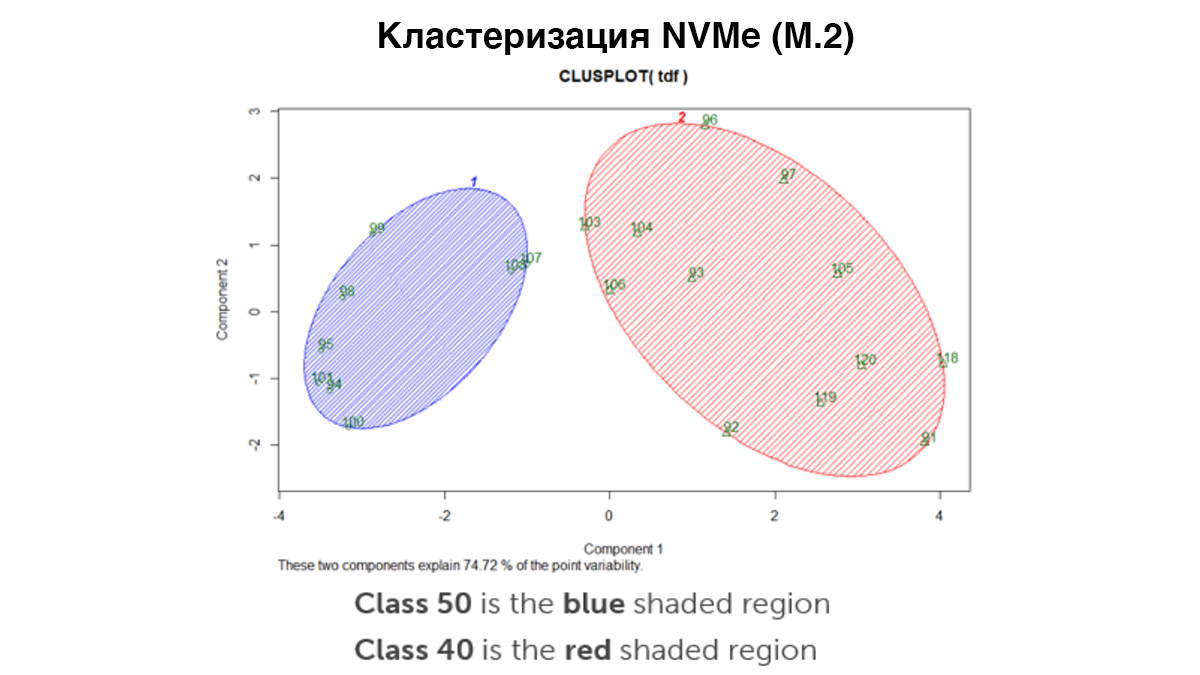
SSD NVMe тоже показали разделение на два кластера, к тому же гораздо более отчетливое, чем их SATA-аналоги форм-факторов 2.5” и М.2. «Основной» кластер образовали накопители SSD на основе TLC, в то время как «кластер высокой производительности» включал MLC и даже несколько SSD на основе SLC (дополнительных высокопроизводительных карт, add-on).
В итоге для классификации отдельных устройств хранения мы выбрали алгоритм кластеризации на основе центроидов. Несмотря на то, что это создало небольшое перекрытие между накопителями SSD SATA с флеш-памятью MLC и накопителями SSD NVMe с флеш-памятью TLC, такой подход позволил нам упростить систему классификации и получить минимальные показатели производительности высокопроизводительных классов.
Упрощенная система классификации
Чтобы выставить четкие требования поставщикам SSD, важно было установить минимальные рекомендации для «кластеров высокой производительности». Именно на этом этапе были созданы классы хранения.
Накопители класса 20 — обычные SSD SATA, которые можно встретить на многих клиентских платформах. Они подойдут пользователям рабочих станций, которым нужны тихие, быстрые и надежные решения для хранения данных.
 v
vНакопители класса 30 представляют собой самые высокопроизводительные SSD SATA. Когда мы вводили систему классификации, таких моделей на рынке было достаточно много. Сегодня же из-за ряда факторов, включающих рост производительности накопителей на основе TLC, выпускается ограниченное количество SSD класса 30. Если пользователи рабочих станций нуждаются в более широких возможностях, чем могут обеспечить устройства класса 20, стоит обратить внимание на NVMe-накопители.
К классу 40 относятся преимущественно массовые SSD NVMe с флеш-памятью TLC. Здесь представлено значительное количество моделей с самой разной производительностью, поскольку новые поколения приходят на смену старым.

Накопители класса 50 — высокопроизводительные SSD, которые обеспечивают значительный прирост быстродействия по сравнению с классом 40. Многие из них основаны на MLC, но некоторые модели поддерживают более новые и быстрые технологии флеш-памяти, такие как 3D Xpoint. Именно эти накопители мы устанавливаем в рабочих станциях Precision.
Производительность класса 30
Чтобы считаться высокопроизводительным SSD SATA, накопитель должен иметь определенную емкость и соответствовать как минимум 8 из 11 требований, перечисленных в таблице:
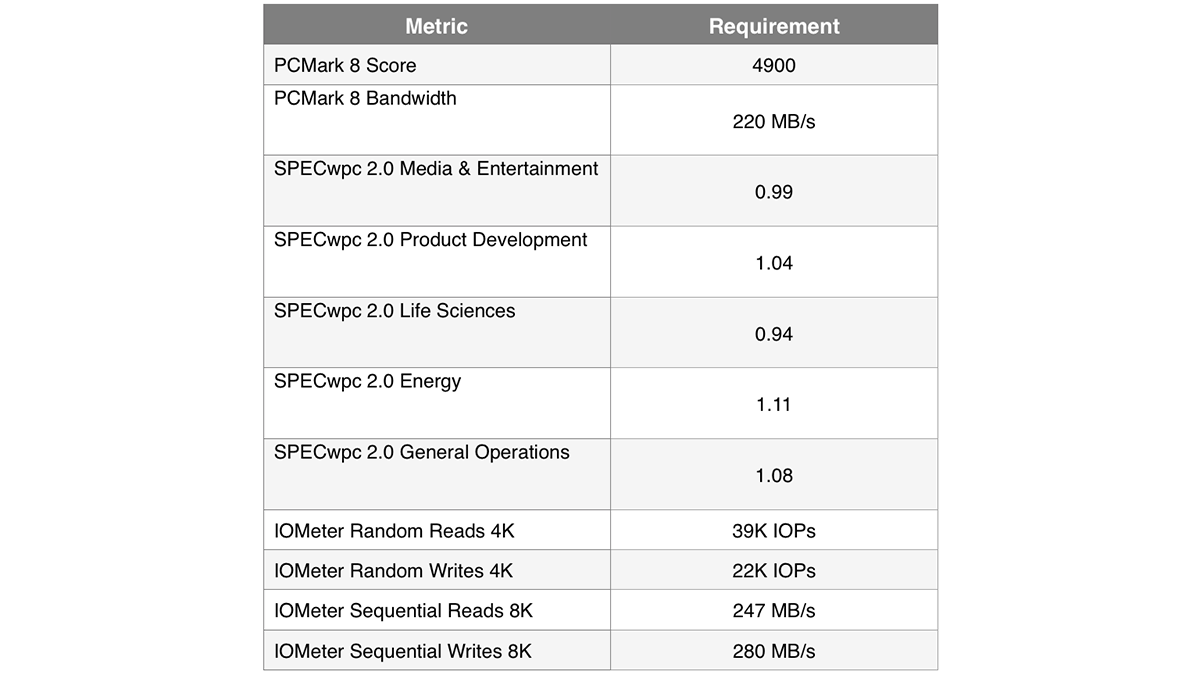
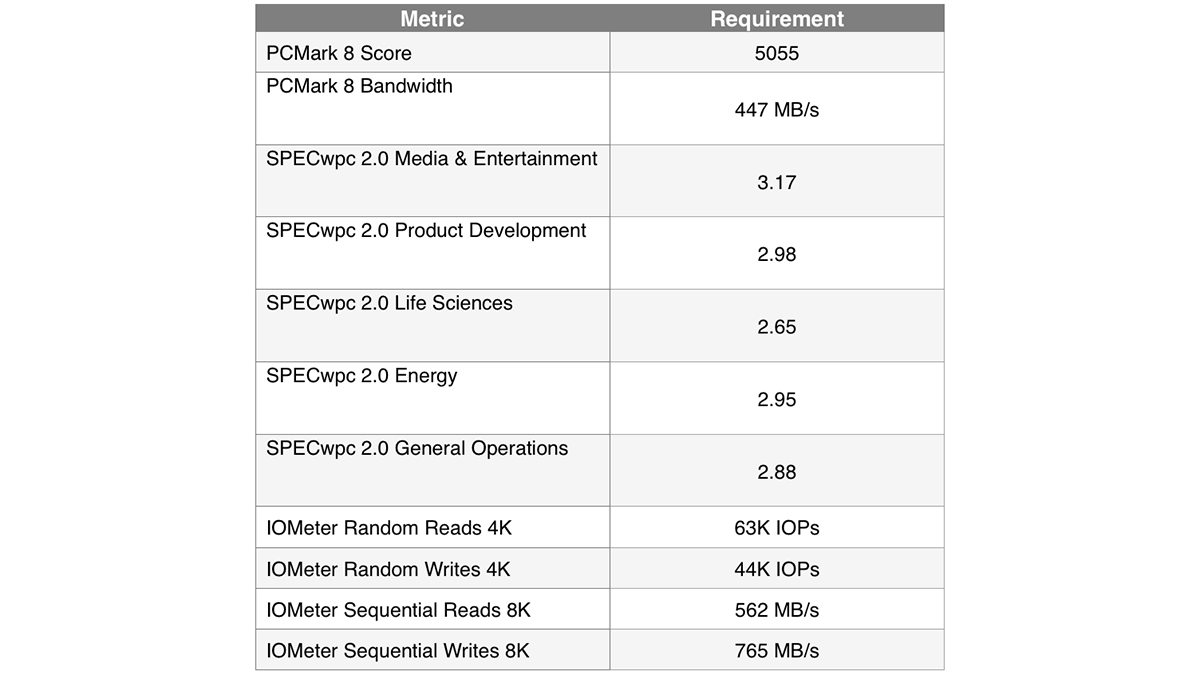
Производительность класса 50
Самой высокопроизводительной может считаться та модель SSD, которая также отвечает по меньшей мере восьми представленным ниже требованиям. Тип подключения в этом случае значения не имеет.
Обновление классификации
Технология хранения данных продолжает развиваться, и система классификации полезна только тогда, когда она совершенствуется вместе с технологиями. Каждые шесть месяцев мы ее пересматриваем и анализируем разницу между классами. Перемещение центров кластеров вверх может влиять на минимальную требуемую производительность: вот почему количество и разнообразие моделей класса 30 сокращается, а класс 40 продолжает расти.
Выводы
Твердотельные накопители обеспечивают значительные преимущества по сравнению с вращающимися жесткими дисками. Но встает вопрос, как отличить высокопроизводительные SSD от их менее производительных эквивалентов. Dell решает эту задачу благодаря своей системе классификации: она позволяет определить минимальные требования к накопителям, которые будут классифицированы как высокопроизводительные.
Комментарии (15)
u010602
11.12.2017 14:50Класс — при этом такие вещи как шифрование на уровне железа и защита от сбоев питания при помощи конденсаторов. Или наличие тротлинга у разных м.2 моделей от самсунга из-за перегрева. Это все конечно же ерунда. Вопросы надежности и стабильности параметров в рабочих станциях видимо совершенно не нужны. Делл стремится пробить дно сохраняя корпоративное лицо уже несколько лет. Выдвигая какие-то мифические «классы», делая вид что они достаточно авторитетны для введения классификации.

amarao
11.12.2017 18:27В вашем анализе отсутсвует два важных момента.
1. Есть большая разница между random write и random write + flush. Большая — это примерно в тридцать раз. Я не шучу.
На первой попавшей ssd я имею 15к IOPS на рандомную запись, и имею около 500 IOPS на рандомную запись с flush'ем. Её можно проверить, если добавить ключ --fsync=1 для fio (бенчмарк надо делать на файловой системе). Это приводит к передаче в устройство команды flush, и это очень тормозит. Все транзакционные системы СУБД, файловые системы, системы управления пакетами/апдейтами используют flush для консистентности, то есть производительность при flush определяет user expirience (на одной софт ставится мгновенно, на второй тупит).
2. Maximum latency. Традицонно, все SSD проигрывают шпиндельным дискам по этому параметру. Лучшее, что я видел — делало 8 секунд пиковую задержку (100% SPAN), худшее — больше 80. Секунд. На одну (самую неудачную) операцию.
u010602
12.12.2017 03:22+1Стабильность производительности у потребительских моделей очень низкая. Стоит смотреть в сторону серверных моделей, я все больше убеждаюсь что только серверные ССД — полноценные продукты. Там и конденсаторы которые позволяют дописать кеш, и стабильные честные показатели. Именно по этому они слегка ниже потребительских моделей, у которых пиковые показатели «дутые» за счет кешей. Я себе купил Intel 750, Intel 3710 и Intel 320. Если хотите могу прогнать на них тесты на максимальную задержку и запись со сбросом кеша, т.к. и самому интересно. Но fio запустить не смогу, т.к. линукса нет и ставить не буду.
Немного материалов на тему, которые дают надежду на стабильность в производительности:
www.anandtech.com/show/6433/intel-ssd-dc-s3700-200gb-review/3
blogs.technet.microsoft.com/filecab/2016/11/18/dont-do-it-consumer-ssdamarao
12.12.2017 13:04К сожалению, даже на топовых серверных SSD производительность «с flush'ем» кратно хуже, чем без него, и многосекундные пиковые latency — тоже норма. Включая «ulrafast PCI-E devices».
u010602
12.12.2017 15:06К сожалению или к счастью, но я не могу найти подтверждение ваших слов в интернете.
Например:
www.storagereview.com/intel_ssd_910_series_enterprise_pcie_review
www.storagereview.com/intel_ssd_dc_p3700_25_nvme_ssd_review
Судя по графику максимальной задержки записи — она не превышает 150мс для некоторых серверных моделей Интела. И разброс очень маленький.
Насчет тестов с flush'ем — я про них вообще ни чего найти не могу в интернете.
В общем предложение про проверку вашей гипотезы на доступном мне оборудовании остается в силе. Еще смогу проверить на каком-то OCZ, сата самсунгах(750 и 850) и маленьких(4гб) SLC дисках.amarao
12.12.2017 19:22Для меня проблема с flush'ами стала сюрпризом, когда я готовил диски для ceph'а (который эти флаши использует постоянно). Я даже пол-года ругался с вендором, и они с -цатой попытки выкатили версию, в которой flush'и стали делаться существенно лучше.
тест простой:
fio --name fsync_test --blocksize=4k --ioengine=libaio --iodepth=1 --direct=1 --buffered=0 --rw=randwrite --filename=/mnt/testdrive/test --size 800G --fsync=1
Файловая система — по вкусу.
Да, разумеется, пиковые latency надо мерять с флашами. Без — не смотрел и не интересовался.
Для понимания проблемы, весь OLTP делает flush'и для транзакций: dpkg — делает. rpm — делает. postgres — делает. mariadb — делает. mongo — опционально делает.
u010602
13.12.2017 04:11Я так понимаю это тест вызывает fsync, утилиту характерную для линукс среды. Моих знаний не хватает чтоб понять что есть аналогом этой утилиты в среде Виндовс.
Но есть статья от postgres
The 3rd generation Intel 320 and 710 series drives do not have any of these problems, having added a capacitor to provide battery-backup for flushing the drive cache when power drops.
и ссылаются на такое вот частное исследование
Судя по всему, fsync фактически отключает кеш на запись, и от того идет жуткое падение производительности и износ диска. У моделей с «Enhanced Power Loss Data Protection», или по простому — с конденсаторами, не нужно отключать кеш, т.к. его сохранность гарантируется, все транзакции будут дописаны в случае сбоя.
Не берусь утверждать, но возможно можно настроить СУБД под работу на ССД.amarao
13.12.2017 12:37Не важно, что оно вызывает, важно, что когда операция проходит по блочному стеку проходят команды SYNCHRONIZE CACHE (0x91 или 0x35), которые, цитирую:
SCSI Commands Reference Manual, Rev. A 3.46
SYNCHRONIZE CACHE (10) command
The SYNCHRONIZE CACHE (10) command (see table 140) requests that the device server ensure that the specified logical blocks have their most recent data values recorded in non-volatile cache and/or on the medium, based on the SYNC_NV bit. Logical blocks include user data and, if the medium is formatted with protection information enabled, protection information. Logical blocks may or may not be removed from volatile cache and non-volatile cache as a result of the synchronize cache operation.
Соответственно, flush говорит «сбрось кеш на диск», и это hard requirement для OLTP систем. Если SSD начинает мухлевать и игнорировать этот флаг (продолжая держать несохранённые данные в wb-кеше), то мы имеем eventual corruption в результате выключения питания на долгое время, всяких странных bus reset'ов и т.д.
СУБД (и подобные им системы, наподобие ceph'а) гарантируют консистентность данных только если блочное устройство выполняет сброс кеша по команде.
Более того, они это делают очень часто. ceph, например, делает один flush на каждый iops. (две записи и один flush). То же самое делают системы управления пакетами (dpkg). Насколько я знаю, винда, при установке апдейтов, тоже делает транзакции таким образом (основная причина, почему апдейты такие медленные и унылые).
Таким образом, реальная производительность устройств под нагрузкой должна происходить с учётом производительности flush-операций. Которые могут занимать десятки секунд в неудачные моменты времени. И единицы милисекунды в удачные.
На удивление, жёсткие диски, в этих условиях работают медленее, но равномернее — пиковые latency у HDD редко превышают единицы секунд.
UPD: Мне лениво искать, но верьте мне на слово, в SATA поддержка flush'а тоже есть. Я не помню, отдельная это команда, или флаг «write barrier» на WRITE операцию, но они точно есть.u010602
13.12.2017 14:46Спасибо, почитаю как вызывать эти команды под виндой. Но относительно кеша и конденсаторов — они не просто хранят содержимое кеша, они позволяют его сбросить на флеш в случае пропадания питания. Т.е. «values recorded in non-volatile cache» выполняется для ссд с кондером всегда. А состояние кондеров контролируется самодиагностикой и доступно среди смарт параметров.
Тем не менее как реагируют диски на эту команду я не знаю. Может мухлюют а может и нет. Но доки уверяют что можно отключать синхронизацию на таких дисках, можно ли им верить не знаю, наверное нужно делать тесты с выдергиванием дисков.amarao
13.12.2017 15:06Мы спекулируем о потрошках этих устройств. Насколько я понимаю, кеш там довольно ограничен по объёму и под нагрузкой может оказываться, что устройство вынуждено делать какие-то существенные операции даже в режиме «с использованием кеша». (кроме того, там же описывается флаг, который требует скинуть даже non-volatile кеш).
На практике я описываю результаты своих бенчмарков под ceph'ом — и даже самые top grade диски начинают выглядеть довольно умеренно. Flush резко увеличивает max latency.
Что удивительно, это становится заметно только на длинных пробегах. Например, для 730ых интелов на 40Гб span'е max latency = 11ms (block=4k, iodepth=10), а на 400Гб span тот же тест даёт max latency 17 секунд (17000 милисекунд).u010602
13.12.2017 16:49Кеш у 730ых не больше 1гб, т.е. сильно меньше 40гб, и по сути задача кеша исключительно насобирать записей на одну целую страницу, прежде чем ее записывать. Это уже снимает главную проблему и задержек и износа. А сколько если не секрет вы оставляли для over-provisioning в тесте с 730ым? А ваш тест только фиксирует максимальную задержку или так-же считает количество таких событий? Насколько критичный единичный лаг за двойную перезапись накопителя?
Я не знаком с ceph'ом, но постгрес не часто перезаписывает данные, он генерирует кучу новых файлов с патчами. Т.е. если СХД собран на ССД достаточного объема, с ОР в 20%, то двукратных непрерывных перезаписей происходить не будет, и скорее всего не будет 17 секундных лагов.amarao
13.12.2017 18:21На продакшене норма у ceph'а — утилизация дисков <80% (т.е. минимум 20% свободно), на тестах я обычно оставляю 80-160Гб (400 для 480, 800 для 960, etc).
Точное число я не фиксировал, но когда первый раз такое обнаружил, то сделал latency log, по ощущениям, оно очень редко. fio тоже согласно, потому что там идёт <0.1% такого. (Это не отменяет удачно залипшего IO на 17 секунд в продакшене на Самой Важной Транзакции).
postgres имеет журналы ограниченного размера, примерно такие же журналы на ceph'е.
Я воспроизводил эти лаги при IO не на ceph, а просто fsync на файловую систему (я выше показывал пример скрипта). Для меня гигантским сюрпризом было радикальное снижение производительности при переходе с бенчмарков голых блочных устройств (или файловых систем без fsync) на бенчмарк с fsync'ом.
Который я считаю наиболее точным инфимумом для производительности устройства. (В любой другой ситуации устройство будет вести себя лучше).

SlavikF
11.12.2017 21:47Раз уж здесь официальный блог DELL — то можно вас попросить написать статью про Generation 14 of Poweredge? Вроде ещё в прошлом году начали продавать 14е поколение, но особо нигде (по крайней мере здесь) не писали про это.
И если можно — то более техническую, чем маркетинговую статью.
DellEMCTeam Автор
12.12.2017 16:28Добрый день! Как раз недавно в блоге Dell EMC на HH такая статья появилась: habrahabr.ru/company/dellemc/blog/344100
alexkuzko
Все хорошо, но может стоило добавить нормальный список моделей, которые вы относите к тому или иному классу? Иначе это просто голая теория и рекламная шелуха, мол какие мы хорошие, только 50-й класс ставим ;)