Анастасия Никонорова, бизнес-аналитик CityLife, поделилась с блогом Нетологии опытом в создании портрета целевой аудитории: с примерами и разбором главных ошибок.
Принято считать, что ключевая задача маркетинга — привлечение и удержание клиентов. И главный вопрос, который стоит перед большинством специалистов по маркетингу — это не то, какой инструмент следует выбрать, а то, как определить потребности клиентов и правильно сегментировать покупателей так, чтобы сделать предложение, от которого они не смогут отказаться.

Главный метод определения целевой аудитории в современном маркетинге — сегментация. Сегментация — это разделение клиентов на группы по заданным параметрам.
Во-первых, чтобы понимать, кто ваш клиент, какие у него потребности, и на основании этого правильно позиционировать компанию.
Во-вторых, чтобы выстраивать уникальные механики взаимодействия с каждым из клиентов, повышать конверсию из предложения в покупку и общую лояльность клиентов.
Если вы предлагаете клиенту то, что ему потенциально интересно, то его лояльность бренду и компании увеличивается вне зависимости от того, совершил ли он покупку по этому предложению или нет.
По данным Website builder, 44% людей, получавших таргетированные письма, совершили как минимум одну покупку по содержащимся в них предложениям.
В большинстве случаев сегментации подвергается текущая клиентская база. Но при создании нового бизнеса или отсутствии сбора данных сегментацию можно провести по результатам опросов существующих или потенциальных клиентов.
Многие воспринимают данные опросов только как качественный метод исследования, уступающий анализу покупательского поведения. На самом деле оба вида анализа (на основании опросов и истории покупок) должны использоваться в вашем бизнесе в равной мере, так как они преследуют различные цели.
Анализ результатов опросов используется для приоритезации задач бизнеса, создания вектора коммуникации с потребителями либо корректировки коммуникационной стратегии. Анализ истории покупок — для создания рекламных кампаний, построения механик программы лояльности и геймификации, изменения фокусировок маркетинга.
Например, даже профессиональный аналитик (только если он дополнительно не учился на психолога) не сможет понять лучше самого клиента, что клиенту действительно надо.
Да, данные о покупках могут показать, что клиенты уходят, что снижается средний чек, но понять, за счет чего это происходит и чего не хватает потребителям, — можно лишь с помощью обратной связи.
При этом важно учитывать, что при проведении опроса погрешность могут внести психологические аспекты поведения. Во-первых, так как вы заинтересовались мнением человека, он попытается вас отблагодарить, давая ответы, потенциально угождающие вам. Во-вторых, на результат может значительно повлиять неправильная постановка вопроса или же ваша собственная склонность к подтверждению своей точки зрения.
В этом материале я постаралась отойти от стандартных методов сегментации рынка, которые приносят мало пользы на практике, и описала только те из них, которые мы сами используем при создании стратегий программ лояльности.
Сегментацию можно проводить даже в Excel, для более сложной аналитики и большого объема данных можно использовать методы машинного обучения, языки Python, R, Scala, набирающий популярность Julia и другие.
Динамические показатели — те, что формируются на основании поведения пользователя относительно других пользователей: RFM-кластеризация, размер среднего чека, частота покупок и так далее. Границы сегментов, сформированных на основании поведения, динамические и меняются при совершении каждой новой покупки.
1. Определить цель сегментации:
2. Выбрать один из методов сегментации или создать собственный алгоритм вычисления.
3. Понять, какие данные необходимы:
4. Обработать и подготовить данные:
Выше я говорила о том, что данные опросов, как и количественные данные, можно сегментировать, но прежде их надо обработать:
Другой вопрос — какое количество клиентов опрашивать для получения точных данных. Один из вариантов — посчитать величину, используя для этого стандартные калькуляторы, введя в поиске «размер выборки». Но на самом деле это не так просто, подобные калькуляторы позволяют узнать размер выборки только по одному вопросу, на который будет всего два варианта ответа. Но в большинстве случаев анкета предполагает сбор большего количества данных.
Есть стандартные статистические формулы, которые используются для расчетов, но они предполагают, что вы уже знаете, в каком диапазоне будут находиться ответы.
Очевидно, что чем больше людей будет опрошено, тем точнее будет результат. Выборка на самом деле слабо зависит от генеральной совокупности, у вас может быть 5 тысяч клиентов или 5 миллионов, но по одинаковому числу параметров вам потребуется опросить одинаковое количество респондентов.
Давайте теперь разберем несколько методологий проведения сегментации.
RFM-анализ — это анализ по трем показателям:
Часто при проведении RFM-анализа клиентов по каждому из параметров делят на группы по равным интервалам от минимального до максимального значения. Например, давность (recency) последней покупки до 1 недели, до 2 недель, до 3 недель.
Мы определяем границы кластеров с помощью вычисления суммы и разности среднего значения со среднеквадратичным отклонением, таким образом, получаем в кластере r2f2m2 наибольшее количество пользователей.
Индексы 1 и 3 в рамках RFM-анализа характеры для исключительных клиентов с различными особенностями поведения. Так, клиенты кластера r1m3 (при любом значении f) — это покупатели, которые ранее были доходны для компании, но перестали совершать покупки, причину чего необходимо выяснить с помощью опросов.
Кластер r3f3m1 является потенциальным для увеличения LTV (monetary), так как клиенты проявляют лояльность, но при этом совершают покупки на небольшие суммы. В такой ситуации следует предложить покупателям скидку при покупке на сумму от N рублей, либо порекомендовать сопутствующие товары на основании истории их покупок.
При помощи RFM-сегментации можно строить значительно более эффективную политику взаимодействия с клиентами, чем отправка писем всей клиентской базе. Для этого анализа вам потребуются необходимые показатели по клиентам, Excel и 30 минут работы.
Цель кластерного анализа — объединить клиентов в группы по схожим параметрам. Наиболее популярный метод визуализации анализа — иерархическое дерево, каждый последовательный уровень которого — сужающиеся факторы различия.
Мы чаще всего используем одну из разновидностей кластерного анализа — k-means.
Алгоритм анализа следующий.
Назначить число кластеров k, на которое будут делиться составляющие кластеризации. Число k либо задается вручную (удобно определять количество кластеров на основании древовидной кластеризации), либо вычисляется как оптимальное значение с помощью машинного обучения.
После этого k произвольных точек назначаются центрами кластеров, и измеряется расстояние между назначенными центрами и всеми остальными точками внутри кластеризации. Принадлежность точки к кластеру определяется определением наименьшего расстояния до одного из k-центров.
Следующий шаг — выбор новых центров, их координаты будут равны среднему значению координат точек внутри кластера. Снова проводится распределение точек по k-кластерам, и операция повторяется до тех пор, пока значения расстояний внутри кластеров не повторятся, это означает, что достигнуто оптимальное деление.
После того, как кластеры сформированы, необходимо понять, по каким параметрам точки в кластерах наиболее схожи, то есть какие из особенностей поведения пользователей являются систематическими. Один из лайфхаков быстрого их определения — построение боксплотов (ящиков с усами), где значениями выступают показатели каждого клиента по выбранному показателю. Они сразу бросаются в глаза наименьшим размахом значений выборки.
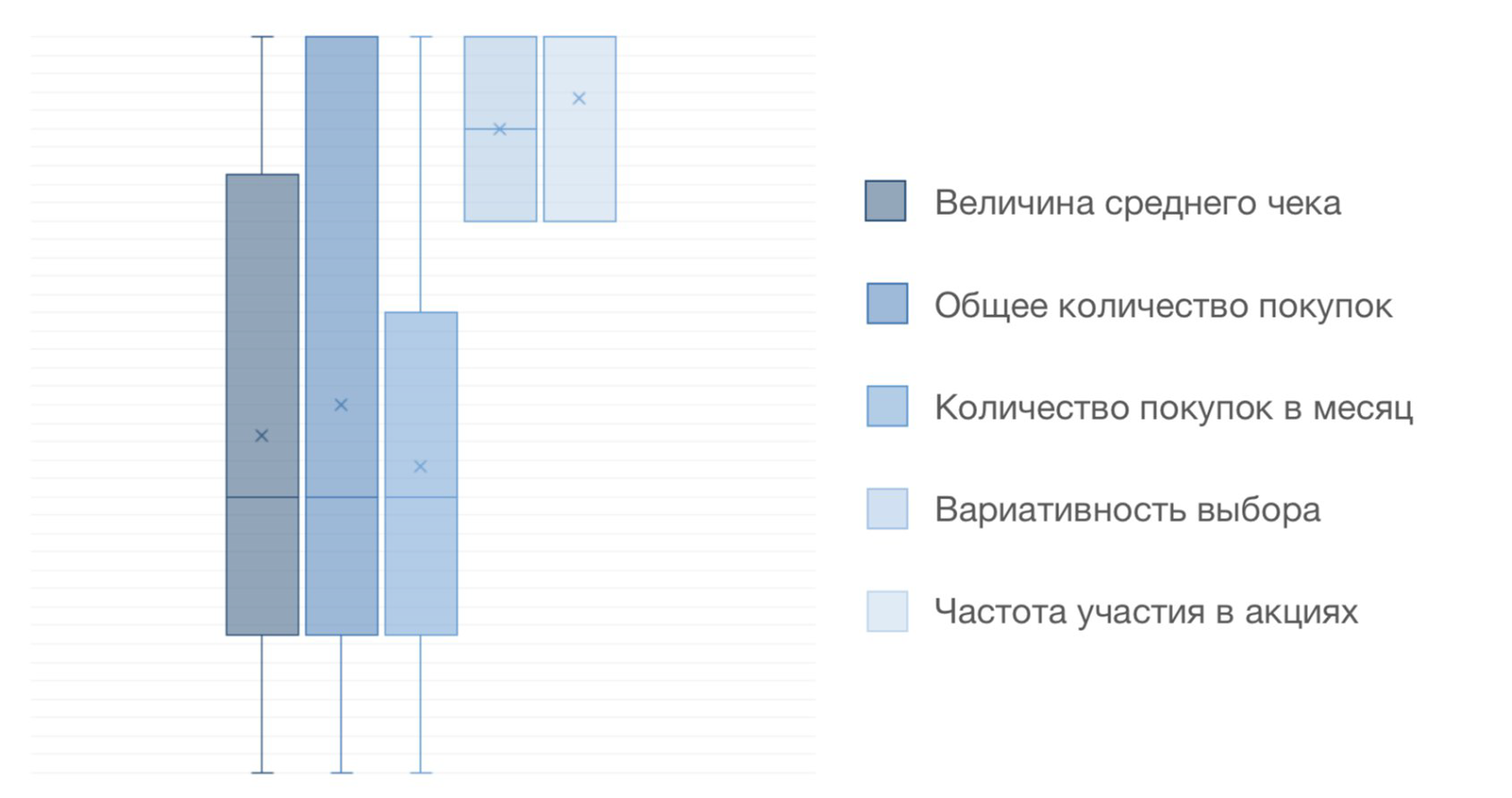
На примере мы видим, что кластер сформирован благодаря схожести клиентов по индексам «Вариативность выбора» и «Частота участия в акциях», что представляет собой яркую особенность поведения. Эта группа является целевой для тестирования новой функциональности приложения, сбора обратной связи. Группа заинтересована в акциях и вводе новых товаров.
Этот анализ мы проводим на основании большого количества собранных данных, результат используем для проведения таргетированных акций. На практике мы выяснили, что результат сегментации требует тестирования, так как деление на кластеры может кардинально отличаться от месяца к месяцу.
Также данный вид сегментации можно использовать для анализа опросов. Но так как текстовые данные сложно преобразовать в числовые индексы, тем более, если речь идет о тысячах анкетируемых, то мы рекомендуем задавать вопросы формата «Оцените важность/качество/ величину… от 1 до 5».
Подобным образом мы проводили опросы клиентов банка. Первоначально аудитория была разделена на пользователей различных продуктов банка. Для каждого продукта были сформулированы уникальные вопросы по важности факторов выбора, где анкетируемому предлагалось поставить по каждому из факторов оценку от 1 до 5. Часть полученной сегментации представлена ниже:
Владельцы дебетовых карт:
Юридические лица, регулярно совершающие расчетно-кассовые операции:
Анализ ассоциативных правил (анализ рыночной корзины) — анализ, который используется для нахождения устойчивых сочетаний товаров в покупках. Для его вычисления есть множество алгоритмов, первый из них — AIS — был разработан в 1993 году. Для анализа необходима база данных покупок, каждая покупка должна иметь уникальный идентификатор (часто в этой роли выступает номер чека) и позиции, которые входят в него.
Что в этих случаях делать компаниям, которые не входят в сегмент FMCG? Мы предлагаем использовать и используем в собственном бизнесе вместо номера чека уникальный id клиента. Таким образом мы вычисляем устойчивые паттерны в поведении клиентов относительно истории их покупок, на основании которых строим рекомендательную систему.
Допустим, покупки на Aviasales совершили 3 тысячи человек, на Booking — 1 тысяча. Клиентов, которые совершили покупки как на Aviasales, так и на Booking — 500. Объем клиентской базы равен 5 тысячам клиентов.
На основании этих данных высчитываются два показателя: достоверность (confidence) и поддержка (support) правила.
Поддержка — доля клиентов, совершивших транзакции у обоих партнеров от общего числа транзакций, то есть 10%.
Достоверность (мы ее еще называем силой связи) — доля клиентов, совершивших транзакции у обоих партнеров от количества транзакций каждого из них в отдельности.
Достоверность, как вы уже поняли, имеет два значения, в нашем случае для Booking она равна 50%, для Aviasales — 16,7%. Это означает, что клиент вероятнее совершает покупку на Booking и потом совершает на Aviasales, чем наоборот.
Как это применить в маркетинге? Если мы будем создавать акцию для покупателей, то она будет промоутировать Booking, так как после этого клиенты с большой вероятностью совершат покупку на Aviasales. Также мы можем настроить автоматическую рассылку: после совершения покупки на Booking клиенту будет отправляться промокод на следующую покупку Aviasales со скидкой на ограниченный срок. Еще одним методом монетизации может являться введение сочетания этих двух партнеров в формате комбо-набора, при покупке которого будет увеличен общий кэшбэк.
При всей доступности и понятности способов и методов сегментации собственной целевой аудитории многие специалисты по маркетингу допускают ошибки, проделывая эту работу. О семи из них пойдет речь ниже.
Это, по моему мнению, самая большая ошибка, которую можно допускать при сегментации — делать выводы исключительно на основании возраста и пола потребителей. Редко удается найти корреляцию демографических показателей и поведения пользователя. Единственный релевантный пример был получен нами при выявлении закономерности в поведении собственной аудитории. Мы считали отношение клиентов, совершающих транзакции, по возрасту и полу к общему количеству клиентов данного возраста и пола, процент кратно уменьшался для женщин от 35 лет, у мужчин спад был не так значителен. На основании этого было принято решение создавать обучающие видеоролики по совершению онлайн-покупок на Lamoda и Aliexpress.
На самом деле часто приходится встречаться с этой ошибкой. Для одного из наших клиентов — сети продовольственного ритейла — мы с коллегой проводили обучение по аналитике. Буквально с первого взгляда я была приобщена к «поколению Y» и опрошена на предмет того, что может привлечь меня в схожий магазин и заставить начать принимать участие в акциях. Если бы коллеги основывались на моем возрасте и поле, то мне наверняка предложили промо с героями популярных сериалов. Но тогда я возвращалась домой в то время, когда магазины данного формата были закрыты, и с целью экономии времени я заказывала доставку продуктов на дом через интернет-магазин. На основании этого мне стоило предложить готовые наборы товаров, которые я могла забрать по пути домой в одном из пунктов выдачи.
Данные, содержащие ошибочные или критические значения, могут привести к значительным ошибкам в результате сегментации. Например, если не исключить выбросы перед проведением RFM-анализа, будут слишком расширены границы кластеров. Таким образом количество клиентов в кластере r2f2m2 будет не соответствовать действительности, и вы не сможете выделить ключевые сегменты для работы.
Проведение сегментации без учета внешних факторов, влияющих на поведение клиентов, может привести к разрозненным или даже неверным результатам. Например, нельзя проводить анализ на совокупности данных по жителям столицы и регионов, так как существует отличие в уровне жизни и заработных платах, высокий средний чек в регионе может быть в границах среднего для Москвы. Аналогично в течение пяти лет сбора данных у вас наверняка была значительно скорректирована ассортиментная матрица, также менялись экономические условия, что говорит о невозможности их равносильного представления в одном массиве.
Сделать сегментацию и продумать механику взаимодействия с каждым сегментом — еще не вся работа. Необходимо следить за реакцией клиентов, подбирать подходящие каналы коммуникации и тестировать гипотезы.
Мы часто создаем сегментированные рассылки и промопосты в социальных сетях. Например, опытным путем мы выяснили, что клиенты, которые не совершали у нас покупки три месяца, чаще всего скрывали рекламные объявления в социальных сетях, направленные на их возвращение. Но при этом достаточно эффективно для них сработала отправка email-писем с акционным предложением на продление абонентской платы.
Представим, что аналитик провел достаточно сложный кластерный анализ и нашел сегмент клиентов — владельцев кошек — по принципу регулярных покупок кошачьего корма. Он рад и счастлив, идет с этим инсайтом к директору по маркетингу, в итоге компания отправляет рассылку этим клиентам с акцией на новый премиум-корм со скидкой 50%. Но в результате конверсия в переход по ссылке из письма ниже ожидаемой. Все из-за того, что при формирования списка email-аналитик не учел факт, что анализ он проводил по данным за 3 года, и 50% покупателей более года не совершали покупки.
В первом пункте я приводила пример про интернет-магазин продуктов — это был «Утконос». Живя в Москве, я была предельно к нему лояльна, мне нравился их ассортимент, удобное время доставки: они могли доставлять еду даже в 3 ночи. Учитывая мой прежний график, это было весьма кстати, заказы я совершала минимум раз в месяц. Но вот уже 4 месяца я живу в Санкт-Петербурге, а SMS-сообщения от любимого когда-то «Утконоса», осуществляющего доставку продуктов только по Москве, мне продолжают приходить. Отсутствие заказов в течение срока, в четыре раза превышающий мой средний интервал, их не смущает, они тратят впустую бюджет на рассылки, а у меня фактически нет возможности совершить повторный заказ.
Данные сегментации, как и любые другие, имеют свойство устаревать. И скорость этого зависит от особенностей бизнеса. Для ритейла, например, максимальная длительность актуальности сегментации — месяц. Наиболее оптимальное решение — настроить автоматическое обновление или создать BI-дашборд для регулярного контроля показателей, влияющих на результат сегментации. Если такой возможности нет, то сегментацию стоит регулярно обновлять вручную.
Несомненно важно понимать, кто ваши клиенты, но это далеко не единственное применение сегментации. Важно строить коммуникацию с клиентами и в целом маркетинговую политику, используя данные. Разным сегментам должны посылаться разные ключевые сообщения, им интересны разные предложения и товары. Это один из способов существенно улучшить ваш бизнес. Не используя его, вы теряете конкурентное преимущество.
Правильно определять, сегментировать и работать со своей целевой аудиторией — важный навык современного специалиста по маркетингу. В этом материале были рассмотрены цели и задачи сегментации, методологии и виды анализа, главные ошибки при проведении сегментации. Используйте эту информацию, профессионально работайте с собственными покупателями, и успех вашего бизнеса не заставит себя долго ждать. Удачи!
Курсы «Нетологии» по теме:
Бесплатные занятия и программы:
Принято считать, что ключевая задача маркетинга — привлечение и удержание клиентов. И главный вопрос, который стоит перед большинством специалистов по маркетингу — это не то, какой инструмент следует выбрать, а то, как определить потребности клиентов и правильно сегментировать покупателей так, чтобы сделать предложение, от которого они не смогут отказаться.
Главный метод определения целевой аудитории в современном маркетинге — сегментация. Сегментация — это разделение клиентов на группы по заданным параметрам.
Для чего нужно сегментировать аудиторию?
Во-первых, чтобы понимать, кто ваш клиент, какие у него потребности, и на основании этого правильно позиционировать компанию.
Во-вторых, чтобы выстраивать уникальные механики взаимодействия с каждым из клиентов, повышать конверсию из предложения в покупку и общую лояльность клиентов.
Если вы предлагаете клиенту то, что ему потенциально интересно, то его лояльность бренду и компании увеличивается вне зависимости от того, совершил ли он покупку по этому предложению или нет.
По данным Website builder, 44% людей, получавших таргетированные письма, совершили как минимум одну покупку по содержащимся в них предложениям.
В среднем, сегментация повышает open rate на 14,69%, а click rate — на 60%.При проведении исследования 52% опрошенных маркетологов сказали о необходимости сегментации базы данных в email-рассылках, так как индивидуальные предложения приносят в 18 раз больше доходов, чем широковещательные.
Какие данные сегментировать
В большинстве случаев сегментации подвергается текущая клиентская база. Но при создании нового бизнеса или отсутствии сбора данных сегментацию можно провести по результатам опросов существующих или потенциальных клиентов.
Многие воспринимают данные опросов только как качественный метод исследования, уступающий анализу покупательского поведения. На самом деле оба вида анализа (на основании опросов и истории покупок) должны использоваться в вашем бизнесе в равной мере, так как они преследуют различные цели.
Анализ результатов опросов используется для приоритезации задач бизнеса, создания вектора коммуникации с потребителями либо корректировки коммуникационной стратегии. Анализ истории покупок — для создания рекламных кампаний, построения механик программы лояльности и геймификации, изменения фокусировок маркетинга.
Например, даже профессиональный аналитик (только если он дополнительно не учился на психолога) не сможет понять лучше самого клиента, что клиенту действительно надо.
Да, данные о покупках могут показать, что клиенты уходят, что снижается средний чек, но понять, за счет чего это происходит и чего не хватает потребителям, — можно лишь с помощью обратной связи.
При этом важно учитывать, что при проведении опроса погрешность могут внести психологические аспекты поведения. Во-первых, так как вы заинтересовались мнением человека, он попытается вас отблагодарить, давая ответы, потенциально угождающие вам. Во-вторых, на результат может значительно повлиять неправильная постановка вопроса или же ваша собственная склонность к подтверждению своей точки зрения.
Важные принципы проведения опросов
- Опрашивайте клиентов, у которых уже есть опыт использования вашего продукта или схожего продукта конкурентов.
- Задавайте открытые вопросы. Например, «Сколько бы вы заплатили за этот продукт?» вместо «Вы заплатили бы 100, 200 или 300 рублей?» или «Заплатили бы вы 500 рублей за этот продукт?». В противном случае срабатывает «эффект якоря» и человек будет отталкиваться от обозначенной суммы при ответе.
- Если вопрос относится к проблеме или боли клиента, то спросите, как он ее решает. Если в ответ последует «никак», то приоритет у этой проблемы не так высок, как это описывает интервьюируемый.
- Избегайте обобщений. Вместо формулировки «Как часто вы пользуетесь сервисом?» используете «Сколько раз в месяц вы пользуетесь сервисом?».
- Для подтверждения позитивной позиции клиента попросите его совершить конкретное действие здесь и сейчас: подписаться на группу в соцсетях, заплатить за продукт, оставить контакты. Если он не готов этого совершить, то вряд ли он действительно купит продукт в будущем.
- Задавайте уточняющие вопросы. Если клиент говорит, что часто сталкивается с обозначенной проблемой, спросите, когда он сталкивался с ней в последний раз, после чего ответ может измениться.
Как сегментировать
В этом материале я постаралась отойти от стандартных методов сегментации рынка, которые приносят мало пользы на практике, и описала только те из них, которые мы сами используем при создании стратегий программ лояльности.
Сегментацию можно проводить даже в Excel, для более сложной аналитики и большого объема данных можно использовать методы машинного обучения, языки Python, R, Scala, набирающий популярность Julia и другие.
Существует два крупных типа сегментаций: на основании статических и динамических данных.Статические данные — критерии пользователей, которые не зависят от его действий, не меняются или меняются редко. К показателям статической сегментации относят: пол, возраст, географические данные.
Динамические показатели — те, что формируются на основании поведения пользователя относительно других пользователей: RFM-кластеризация, размер среднего чека, частота покупок и так далее. Границы сегментов, сформированных на основании поведения, динамические и меняются при совершении каждой новой покупки.
Пошаговое руководство проведения сегментации
1. Определить цель сегментации:
- кто будет использовать результаты сегментации;
- для чего они будут использоваться.
2. Выбрать один из методов сегментации или создать собственный алгоритм вычисления.
3. Понять, какие данные необходимы:
- какая часть клиентской базы будет использоваться (активные клиенты; клиенты, совершившие N покупок; покупавшие определенный товар; установившие мобильное приложение; все клиенты);
- выбрать период;
- собрать показатели, необходимые для вычисления.
4. Обработать и подготовить данные:
- собрать данные в один согласованный массив, где одна строка — одно наблюдение, один столбец — одна переменная;
- проверить данные на ошибки и очистить их (убрать пустые или недопустимые значения);
- убрать выбросы по каждому из параметров:
— посчитать стандартное отклонение. Факт его значительного отличия от среднего значения говорит о том, что в выборке присутствуют выбросы;
— вычислить медиану — величину, находящуюся в середине набора данных, упорядоченного по возрастанию или убыванию. Если количество членов нечетное, то она принимает значение суммы двух срединных членов, деленной на два;
— вычислить верхнюю и нижнюю границу квартиля — величин, за пределами которых (выше и ниже соответственно) находится 25% значений;
— все, что лежит выше суммы (разности) верхней (нижней) границы квартиля и межквартильного расстояния, умноженного на 1,5, является выбросами.
Выше я говорила о том, что данные опросов, как и количественные данные, можно сегментировать, но прежде их надо обработать:
- проверка анкеты: если вы выполняете анкетирование не лично, а отдаете на аутсорс или отправляете анкету по email, то первым делом следует проверить качество заполнения и отсутствие пропущенных ответов;
- оцифровать: все анкеты необходимо перевести в электронный вид для продолжения анализа, после этого исправить ошибки, привести ответы на открытые вопросы к единым формулировкам;
- чистка данных — на этом этапе следует повторно проверить данные на отсутствие пропущенных значений, выходы значений за обозначенные пределы. Анкеты с ошибками должны полностью исключаться из анализа.
Другой вопрос — какое количество клиентов опрашивать для получения точных данных. Один из вариантов — посчитать величину, используя для этого стандартные калькуляторы, введя в поиске «размер выборки». Но на самом деле это не так просто, подобные калькуляторы позволяют узнать размер выборки только по одному вопросу, на который будет всего два варианта ответа. Но в большинстве случаев анкета предполагает сбор большего количества данных.
Есть стандартные статистические формулы, которые используются для расчетов, но они предполагают, что вы уже знаете, в каком диапазоне будут находиться ответы.
Очевидно, что чем больше людей будет опрошено, тем точнее будет результат. Выборка на самом деле слабо зависит от генеральной совокупности, у вас может быть 5 тысяч клиентов или 5 миллионов, но по одинаковому числу параметров вам потребуется опросить одинаковое количество респондентов.
Давайте теперь разберем несколько методологий проведения сегментации.
RFM-анализ
RFM-анализ — это анализ по трем показателям:
- Recency — показатель активности, вычисляется как давность последнего действия клиента (покупки, авторизации в личном кабинете, открытия email-рассылки и др.).
- Frequency — количество покупок (других действий) клиента.
- Monetary — Lifetime value, жизненная ценность клиента, равна сумме его покупок или прибыли.
Часто при проведении RFM-анализа клиентов по каждому из параметров делят на группы по равным интервалам от минимального до максимального значения. Например, давность (recency) последней покупки до 1 недели, до 2 недель, до 3 недель.
Мы определяем границы кластеров с помощью вычисления суммы и разности среднего значения со среднеквадратичным отклонением, таким образом, получаем в кластере r2f2m2 наибольшее количество пользователей.
Индексы 1 и 3 в рамках RFM-анализа характеры для исключительных клиентов с различными особенностями поведения. Так, клиенты кластера r1m3 (при любом значении f) — это покупатели, которые ранее были доходны для компании, но перестали совершать покупки, причину чего необходимо выяснить с помощью опросов.
Кластер r3f3m1 является потенциальным для увеличения LTV (monetary), так как клиенты проявляют лояльность, но при этом совершают покупки на небольшие суммы. В такой ситуации следует предложить покупателям скидку при покупке на сумму от N рублей, либо порекомендовать сопутствующие товары на основании истории их покупок.
При помощи RFM-сегментации можно строить значительно более эффективную политику взаимодействия с клиентами, чем отправка писем всей клиентской базе. Для этого анализа вам потребуются необходимые показатели по клиентам, Excel и 30 минут работы.
Кластерный анализ
Цель кластерного анализа — объединить клиентов в группы по схожим параметрам. Наиболее популярный метод визуализации анализа — иерархическое дерево, каждый последовательный уровень которого — сужающиеся факторы различия.
Мы чаще всего используем одну из разновидностей кластерного анализа — k-means.
Алгоритм анализа следующий.
Назначить число кластеров k, на которое будут делиться составляющие кластеризации. Число k либо задается вручную (удобно определять количество кластеров на основании древовидной кластеризации), либо вычисляется как оптимальное значение с помощью машинного обучения.
После этого k произвольных точек назначаются центрами кластеров, и измеряется расстояние между назначенными центрами и всеми остальными точками внутри кластеризации. Принадлежность точки к кластеру определяется определением наименьшего расстояния до одного из k-центров.
Следующий шаг — выбор новых центров, их координаты будут равны среднему значению координат точек внутри кластера. Снова проводится распределение точек по k-кластерам, и операция повторяется до тех пор, пока значения расстояний внутри кластеров не повторятся, это означает, что достигнуто оптимальное деление.
После того, как кластеры сформированы, необходимо понять, по каким параметрам точки в кластерах наиболее схожи, то есть какие из особенностей поведения пользователей являются систематическими. Один из лайфхаков быстрого их определения — построение боксплотов (ящиков с усами), где значениями выступают показатели каждого клиента по выбранному показателю. Они сразу бросаются в глаза наименьшим размахом значений выборки.
На примере мы видим, что кластер сформирован благодаря схожести клиентов по индексам «Вариативность выбора» и «Частота участия в акциях», что представляет собой яркую особенность поведения. Эта группа является целевой для тестирования новой функциональности приложения, сбора обратной связи. Группа заинтересована в акциях и вводе новых товаров.
Этот анализ мы проводим на основании большого количества собранных данных, результат используем для проведения таргетированных акций. На практике мы выяснили, что результат сегментации требует тестирования, так как деление на кластеры может кардинально отличаться от месяца к месяцу.
Также данный вид сегментации можно использовать для анализа опросов. Но так как текстовые данные сложно преобразовать в числовые индексы, тем более, если речь идет о тысячах анкетируемых, то мы рекомендуем задавать вопросы формата «Оцените важность/качество/ величину… от 1 до 5».
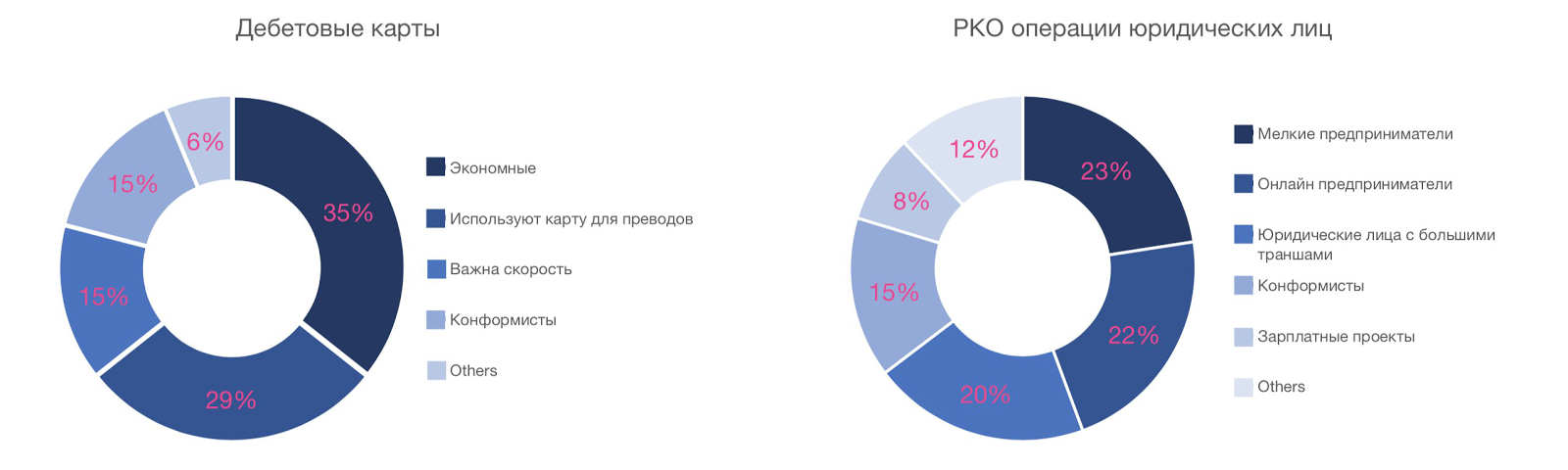
Подобным образом мы проводили опросы клиентов банка. Первоначально аудитория была разделена на пользователей различных продуктов банка. Для каждого продукта были сформулированы уникальные вопросы по важности факторов выбора, где анкетируемому предлагалось поставить по каждому из факторов оценку от 1 до 5. Часть полученной сегментации представлена ниже:
Владельцы дебетовых карт:
- экономные — наивысшие оценки были поставлены фактору «стоимость годового обслуживания»;
- используют карту для переводов — важен размер комиссии за переводы на карты других банков;
- конформисты — оценили важность факторов «репутация бренда» и «отзывы» на 5 из 5, «стоимость обслуживания» — на 4.
Юридические лица, регулярно совершающие расчетно-кассовые операции:
- мелкие предприниматели — основными факторами выбора являются «стоимость открытия счета», «удобство подключения и пользования интернет-сервисами банка», «выгодные тарифы на обслуживание»;
- юридические лица с большими траншами — наиболее важны установленные лимиты кассовых операций и надежность и репутация банка.
Анализ ассоциативных правил
Анализ ассоциативных правил (анализ рыночной корзины) — анализ, который используется для нахождения устойчивых сочетаний товаров в покупках. Для его вычисления есть множество алгоритмов, первый из них — AIS — был разработан в 1993 году. Для анализа необходима база данных покупок, каждая покупка должна иметь уникальный идентификатор (часто в этой роли выступает номер чека) и позиции, которые входят в него.
Что в этих случаях делать компаниям, которые не входят в сегмент FMCG? Мы предлагаем использовать и используем в собственном бизнесе вместо номера чека уникальный id клиента. Таким образом мы вычисляем устойчивые паттерны в поведении клиентов относительно истории их покупок, на основании которых строим рекомендательную систему.
Допустим, покупки на Aviasales совершили 3 тысячи человек, на Booking — 1 тысяча. Клиентов, которые совершили покупки как на Aviasales, так и на Booking — 500. Объем клиентской базы равен 5 тысячам клиентов.
На основании этих данных высчитываются два показателя: достоверность (confidence) и поддержка (support) правила.
Поддержка — доля клиентов, совершивших транзакции у обоих партнеров от общего числа транзакций, то есть 10%.
Достоверность (мы ее еще называем силой связи) — доля клиентов, совершивших транзакции у обоих партнеров от количества транзакций каждого из них в отдельности.
Достоверность, как вы уже поняли, имеет два значения, в нашем случае для Booking она равна 50%, для Aviasales — 16,7%. Это означает, что клиент вероятнее совершает покупку на Booking и потом совершает на Aviasales, чем наоборот.
Как это применить в маркетинге? Если мы будем создавать акцию для покупателей, то она будет промоутировать Booking, так как после этого клиенты с большой вероятностью совершат покупку на Aviasales. Также мы можем настроить автоматическую рассылку: после совершения покупки на Booking клиенту будет отправляться промокод на следующую покупку Aviasales со скидкой на ограниченный срок. Еще одним методом монетизации может являться введение сочетания этих двух партнеров в формате комбо-набора, при покупке которого будет увеличен общий кэшбэк.
Главные ошибки при сегментации аудитории
При всей доступности и понятности способов и методов сегментации собственной целевой аудитории многие специалисты по маркетингу допускают ошибки, проделывая эту работу. О семи из них пойдет речь ниже.
Основываться только на поло-возрастных признаках клиентов
Это, по моему мнению, самая большая ошибка, которую можно допускать при сегментации — делать выводы исключительно на основании возраста и пола потребителей. Редко удается найти корреляцию демографических показателей и поведения пользователя. Единственный релевантный пример был получен нами при выявлении закономерности в поведении собственной аудитории. Мы считали отношение клиентов, совершающих транзакции, по возрасту и полу к общему количеству клиентов данного возраста и пола, процент кратно уменьшался для женщин от 35 лет, у мужчин спад был не так значителен. На основании этого было принято решение создавать обучающие видеоролики по совершению онлайн-покупок на Lamoda и Aliexpress.
На самом деле часто приходится встречаться с этой ошибкой. Для одного из наших клиентов — сети продовольственного ритейла — мы с коллегой проводили обучение по аналитике. Буквально с первого взгляда я была приобщена к «поколению Y» и опрошена на предмет того, что может привлечь меня в схожий магазин и заставить начать принимать участие в акциях. Если бы коллеги основывались на моем возрасте и поле, то мне наверняка предложили промо с героями популярных сериалов. Но тогда я возвращалась домой в то время, когда магазины данного формата были закрыты, и с целью экономии времени я заказывала доставку продуктов на дом через интернет-магазин. На основании этого мне стоило предложить готовые наборы товаров, которые я могла забрать по пути домой в одном из пунктов выдачи.
Не обрабатывать данные
Данные, содержащие ошибочные или критические значения, могут привести к значительным ошибкам в результате сегментации. Например, если не исключить выбросы перед проведением RFM-анализа, будут слишком расширены границы кластеров. Таким образом количество клиентов в кластере r2f2m2 будет не соответствовать действительности, и вы не сможете выделить ключевые сегменты для работы.
Не ограничивать период и географию
Проведение сегментации без учета внешних факторов, влияющих на поведение клиентов, может привести к разрозненным или даже неверным результатам. Например, нельзя проводить анализ на совокупности данных по жителям столицы и регионов, так как существует отличие в уровне жизни и заработных платах, высокий средний чек в регионе может быть в границах среднего для Москвы. Аналогично в течение пяти лет сбора данных у вас наверняка была значительно скорректирована ассортиментная матрица, также менялись экономические условия, что говорит о невозможности их равносильного представления в одном массиве.
Не проводить тестирование
Сделать сегментацию и продумать механику взаимодействия с каждым сегментом — еще не вся работа. Необходимо следить за реакцией клиентов, подбирать подходящие каналы коммуникации и тестировать гипотезы.
Мы часто создаем сегментированные рассылки и промопосты в социальных сетях. Например, опытным путем мы выяснили, что клиенты, которые не совершали у нас покупки три месяца, чаще всего скрывали рекламные объявления в социальных сетях, направленные на их возвращение. Но при этом достаточно эффективно для них сработала отправка email-писем с акционным предложением на продление абонентской платы.
Не учитывать активность клиентов
Представим, что аналитик провел достаточно сложный кластерный анализ и нашел сегмент клиентов — владельцев кошек — по принципу регулярных покупок кошачьего корма. Он рад и счастлив, идет с этим инсайтом к директору по маркетингу, в итоге компания отправляет рассылку этим клиентам с акцией на новый премиум-корм со скидкой 50%. Но в результате конверсия в переход по ссылке из письма ниже ожидаемой. Все из-за того, что при формирования списка email-аналитик не учел факт, что анализ он проводил по данным за 3 года, и 50% покупателей более года не совершали покупки.
В первом пункте я приводила пример про интернет-магазин продуктов — это был «Утконос». Живя в Москве, я была предельно к нему лояльна, мне нравился их ассортимент, удобное время доставки: они могли доставлять еду даже в 3 ночи. Учитывая мой прежний график, это было весьма кстати, заказы я совершала минимум раз в месяц. Но вот уже 4 месяца я живу в Санкт-Петербурге, а SMS-сообщения от любимого когда-то «Утконоса», осуществляющего доставку продуктов только по Москве, мне продолжают приходить. Отсутствие заказов в течение срока, в четыре раза превышающий мой средний интервал, их не смущает, они тратят впустую бюджет на рассылки, а у меня фактически нет возможности совершить повторный заказ.
Не обновлять сегментацию
Данные сегментации, как и любые другие, имеют свойство устаревать. И скорость этого зависит от особенностей бизнеса. Для ритейла, например, максимальная длительность актуальности сегментации — месяц. Наиболее оптимальное решение — настроить автоматическое обновление или создать BI-дашборд для регулярного контроля показателей, влияющих на результат сегментации. Если такой возможности нет, то сегментацию стоит регулярно обновлять вручную.
Использовать сегментацию только с целью определения ЦА
Несомненно важно понимать, кто ваши клиенты, но это далеко не единственное применение сегментации. Важно строить коммуникацию с клиентами и в целом маркетинговую политику, используя данные. Разным сегментам должны посылаться разные ключевые сообщения, им интересны разные предложения и товары. Это один из способов существенно улучшить ваш бизнес. Не используя его, вы теряете конкурентное преимущество.
Правильно определять, сегментировать и работать со своей целевой аудиторией — важный навык современного специалиста по маркетингу. В этом материале были рассмотрены цели и задачи сегментации, методологии и виды анализа, главные ошибки при проведении сегментации. Используйте эту информацию, профессионально работайте с собственными покупателями, и успех вашего бизнеса не заставит себя долго ждать. Удачи!
От редакции
Курсы «Нетологии» по теме:
- очный курс «Директор по онлайн-маркетингу»;
- очный курс «Data Scientist»;
- онлайн-программа «Интернет-маркетинг»;
- онлайн-программа «Веб-аналитика: что нужно знать интернет-специалисту»;
- онлайн-программа «Excel: инструменты работы с данными для маркетологов и аналитиков»;
- онлайн-программа «Big Data: основы работы с большими массивами данных».
Бесплатные занятия и программы:
- программа «Google AdWords: подготовка к сдаче экзамена»;
- программа «Яндекс.Директ: подготовка к сертификации»;
- занятие «Технология формирования современного бренда» — 21 февраля 2017;
- занятие «Как использовать Big Data для вашего бизнеса» — 17 января 2017.