
На днях стало известно о том, что команда Microsoft Research Asia смогла достичь заметного успеха в разработке ИИ. Используя набор данных Stanford Question Answering Dataset, известный среди исследователей, как SQuAD, ученые создали слабую форму ИИ, способную читать текст и отвечать на вопросы о прочитанном не хуже, чем человек (даже немного лучше).
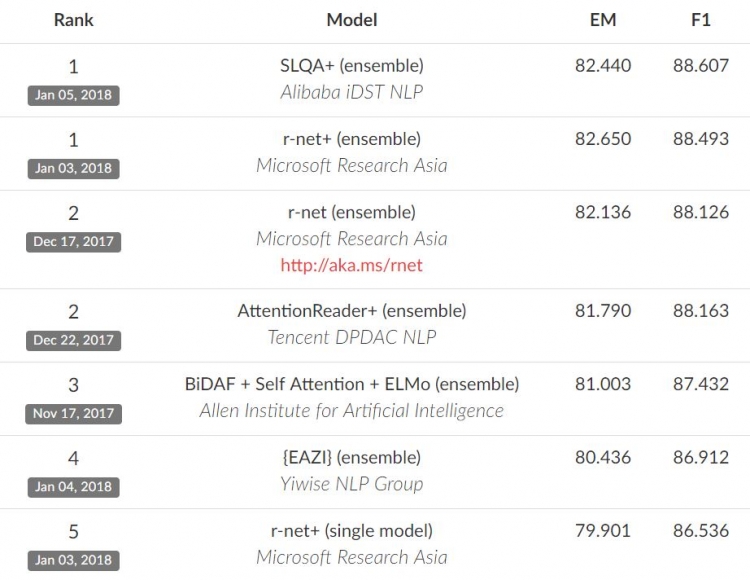
Используя шкалу SQuAD, исследователи провели оценку успехов своего детища. Как оказалось, ИИ набрал 82,650 баллов, в то время, как результат человека с аналогичным набором вопросов и ответов составляет 82,304. Как оказалось, Microsoft — не первая компания, которой удалось достичь подобного успеха. До нее примерно такое же количество баллов набрал ИИ от Alibaba, улучшив затем своей результат уже после достижения Microsoft. Сейчас программные продукты обеих компаний находятся на первом месте рейтинга SQuAD.
Сам тест SQuAD — это опросник, содержащий около 100 000 вопросов. Они составлены на основе 500 отрывков из статей в Wikipedia. В процессе прохождения теста вопросы необходимо не только читать, но и прослушивать. Считается, то этот тест является одним из наиболее точных инструментов для измерения способностей искусственного интеллекта.
В числе прочих вопросов в тесте Стэнфорда есть упражнения, касающиеся истории британского сериала «Доктор Кто». Компьютеру нужно ответить, как назывался космический корабль главного героя. Ранее такие компании, как Facebook, Tencent и Samsung уже представляли собственные продукты
Ранее специалисты Alibaba уже высказывали свое удовлетворение от происходящего. Так, ведущий специалист компании по обработке естественной речи Луо Си говорит, что достигнутые результаты — важное событие в истории создания искусственного интеллекта. «Эту технологию шаг за шагом можно будет применять в самых разных областях — от обслуживания клиентов и музейных путеводителей до медицинских онлайн-консультаций. Участие человека в подобных процессах можно будет свести к минимуму», — заявил он.
По мнению журналистов Financial Times, то, что китайцы и американцы занимаются одной и той же проблематикой, причем с примерно равными результатами, указывает на явное противостояние обеих стран в такой сфере, как разработка искусственного интеллекта. Власти Китая объявили развитие ИИ в качестве одного из приоритетов в стране. Китай планирует стать лидером в этой области в промежутке между 2020 и 2030 годами. У Китая, в принципе, есть все шансы достичь запланированного благодаря тому, что в стране огромное количество пользователей сети и невероятно большие массивы данных, на основе которых можно обучать ИИ.
Что касается США, то здесь пока правительство осторожно затрагивает тему ИИ. В частности, страна пока лишь формулирует суть термина, подготавливая регулирующие законы. Здесь много внимания обращают на этическую сторону вопроса, что в Китае не так важно. В КНР разработкой ИИ вовсю занимаются китайские компании, которые готовы делиться своими данными ради общего результата. Кстати, руководство Baidu уже заявило о том, что использованные в ходе своей работы пакеты данных, а также результаты исследований будут предоставлены научному сообществу.
«Такие тесты — определенно полезные показатели того, насколько далеко может продвинуться работа над ИИ. Правда, основная польза от ИИ для человека может проявиться лишь в том случае, если ИИ действует в гармонии с людьми», — заявил представитель корпорации Microsoft Эндрю Пикап.
Корпорация использует результаты своих достижений в собственных продуктах. Например, ранние версии ИИ, обученного работать с текстами Стэнфорда уже используются в поисковом сервисе Bing. Сейчас компания разрабатывает новую версию продукта, которая будет способна отвечать на несколько связанных между собой вопросов. Например, после ответа на вопрос: «В каком году родилась премьер-министр Германии» компьютер, по мнению специалистов Microsoft, должен уметь ответить и на вопрос: «В каком городе она родилась?». И машина должна понять, о ком и о чем идет речь в новом вопросе, дав адекватный ответ. Нам же остается пока ждать новых свершений.
Комментарии (19)

ntfs1984
18.01.2018 02:06Парсер — это не ИИ.
Прежде чем чем браться за интеллекты — лучше бы объединили усилия и сделали толковое распознавание голоса, а то мой телефон с прошивкой от Корпорации Добра, до сих пор включает поиск при словах «отлей в угол».
dipsy
18.01.2018 05:45Да, ещё есть куда стремиться, распознавание в шумной обстановке, реагирование только на голос владельца… Похоже на историю с беспилотными автомобилями 4 и особенно 5 уровня, по моим ощущениям до практики, до реальной практики езды по нашим городам, дойдет лет через 10, не раньше, при условии что кто-нибудь таки «объединит усилия» и избавится от проблем из серии «ворона села на знак, теперь это тыква», да и «здравый смысл» жизненно необходим, например понять как разъехаться во дворе, сдав назад в карман, тут скорее придется ждать сильного ИИ.

Kicker
18.01.2018 08:38Мне это баш напомнило)
XXX
понедельник
I-Bot Translate 39M2
Monday
XXX
вторник
I-Bot Translate 39M2
Tuesday
XXX
среда
I-Bot Translate 39M2
environment
XXX
среда
I-Bot Translate 39M2
environment
XXX
день недели, сука… среда!
I-Bot Translate 39M2
day of week, bitch… environment!

saboteur_kiev
18.01.2018 17:23Парсер википедии, пусть даже умный и голосовой — это все же смарт-справочник, а не ИИ.
Тем более, что получается все его ответы и вопросы крутятся вокруг ограниченного и специально подобранного набора данных.


shadovv76
18.01.2018 08:38почему не копировать эволюционный путь?
генерировать сети случайной структуры (из конечного диапазона слоев и связей) каждая сама обучается потом проходит тест и три лучших берутся за в качестве базы для сужения границ по структуре и связям далее итерационно все повторяется.
Ясно что это на самотек все пускается и создается инфраструктура для скайнета, но динамит и водородную бомбу же создали намеренно, кто себя тешит, что человечество стало лучше тот проиграет при любом раскладе.
Про отечество, что то совсем не слышно в этой ключевой отрасли.zaq1xsw2cde3vfr4
18.01.2018 15:01Реализовать эволюционный путь настолько же сложно как и ИИ. То, что сейчас толпы лицемеров называют ИИ — это всего лишь расширенная версия и сильно ресурсоёмкая версия оператора switch.

Gryphon88
18.01.2018 15:15Я так надеялся, что напишут не только, что оно существует, но и вкратце как оно работает, со ссылками на статьи, github и API на побаловаться.

Kiano
18.01.2018 18:59или не понял, или не увидел: 100000 вопросов, а в статье говорится про человека в числе прошедших тест. 100к вопросов для человека? Да как на них вообще можно ответить?

Nubus
19.01.2018 05:33Там же не ставяться временные рамки. Плюс тест это *Прочитайте или прослушайте отрывок, ответьте на вопрос*
Зуб даю, стоит формулировки вопросов поменять и ИИ упадет.
Nubus
19.01.2018 05:47По поводу этого *Достижения* уже сегодня уточнение:
Недавние эксперименты (Robin Jia and Percy Liang, 2017) приходят к тому же выводу в другой области: работе с языком. Различные нейросети были натренированы на поиск ответов на вопросы в задаче, известной как SQuAD (Stanford Question Answering Database), в которой целью служит подсветка слов в определённой фразе, соответствующих заданному вопросу. К примеру, в одном случае натренированная система впечатляюще правильно, определила квотербека из выигравшей Суперкубок XXXIII команды, как Джона Элвея, на основе изучения небольшого параграфа. Но Джиа и Лиян показали, что простая вставка отвлекающих от темы предложений (например, о якобы случившейся победе Джеффа Дина в другой игре серии) привела к обрушению качества работы системы. У 16 моделей медианные показатели успеха упали с 75% до 36%.
Пост
PoliTeX
Это утверждение не сходится с таблицей.
ApeCoder
Как именно не сходится? В таблице все, кроме Алибабы и MS, меньше 82,304
PoliTeX
Очередность
ApeCoder
А где там первая попытка Али а где вторая? Если в таблице дата только второй попытке то ничего противоречащего утверждению я не вижу.