От переводчика: в статье, которую я предлагаю вашему вниманию, авторы исследовали кодовую базу LLVM/Clang с помощью инструмента анализа кода CppDepend, позволяющего вычислять различные метрики кода и анализировать большие проекты с целью улучшения качества кода.
Время доказало, что Clang является таким же зрелым компилятором C и C++, как GCC и компилятор от Microsoft, но то, что делает его особенным, это то, что это не просто компилятор. Это инфраструктура для создания инструментов. Благодаря тому, что его архитектура основана на использовании библиотек, повторное использование и интеграция функциональности в ваш проект делается более просто и гибко.

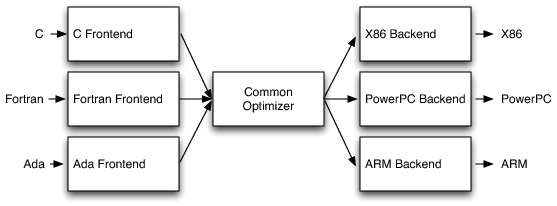
Как и многие другие компиляторы, Clang состоит из трёх фаз:
Фронтенд, который делает парсинг исходного кода, проверяет ошибки, и строит зависящее от языка абстрактное синтаксическое дерево (AST), представляющее входной код.
Оптимизатор: его целью является оптимизация AST, сгенерированного фронтендом.
Бэкенд: генерирует финальный код, исполняемый машиной, зависит от целевой машины.

Самое большое отличие состоит в том, что Clang основан на LLVM, а основной идеей LLVM является использование промежуточного представления (IR), которое является чем-то вроде байткода для Java.
LLVM IR разработан для поддержки промежуточных стадий анализа и преобразования, которые находятся в оптимизирующей стадии компилятора. Он разработан с учётом множества специфических требований, включая поддержку «лёгких» рантаймовых оптимизаций, межпроцедурных/межфункциональных оптимизаций, анализа программы в целом, агрессивных структурных преобразований, и т.п. Самым важным аспектом, однако, является то, что промежуточное представление само по себе является первоклассным языком с хорошо определённой семантикой.
С такой структурой мы можем повторно использовать большую часть компилятора для создания других компиляторов, например, вы можете заменить фронтенд для поддержки других языков.
Очень интересно залезть внутрь этой мощной игрушки и посмотреть, как она спроектирована и реализована. Разработчики на C++ могут изучить много хороших практик из этой кодовой базы.
Давайте «просветим рентгеном» исходный код, использовав CppDepend и CQLinq, чтобы понять некоторые решения разработчиков.
Главной концепцией при разработке clang-а стало использование библиотек. Различные части фронтенда могут быть явно разделены на различные библиотеки, которые могут быть совместно использованы для различных целей. Такой подход поощряет использование хороших интерфейсов и облегчает задачу новым разработчикам (поскольку им нужно будет понять только маленькую часть общей картины).
DSM (Dependency Structure Matrix), матрица структуры зависимостей — это компактный способ представления зависимостей между компонентами. Непустая ячейка матрицы содержит число. Это число выражает силу связи, представленную ячейкой. Сила связи может быть выражена как число членов/методов/полей/типов и пространств имён, вовлечённых в связь.
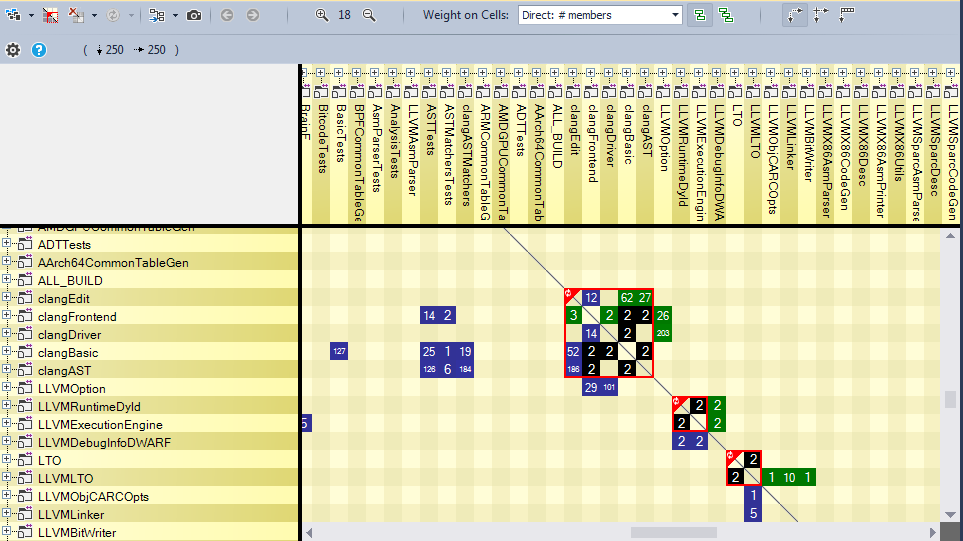
Этот граф зависимостей показывает нам библиотеки, которые clang использует напрямую.
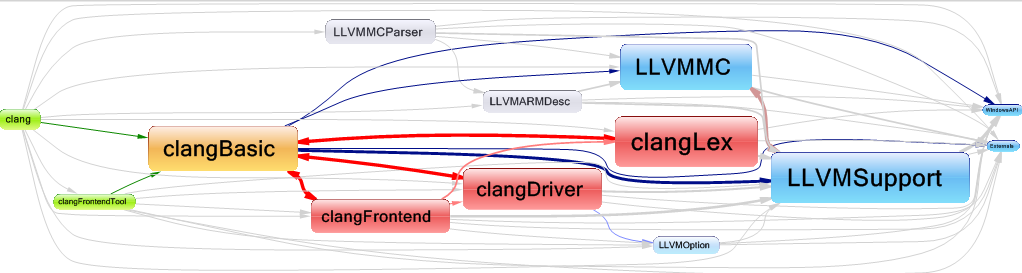
Как мы можем видеть, здесь существует три циклических зависимости между библиотеками clangBasic/clangFrontEnd, clangBasic/clangDriver и clangBasic/clangLex. Рекомендуется удалять любые циклические зависимости между библиотеками, чтобы код был более читаемым и простым в поддержке.
Почему clangFrontend использует библиотеку clangBasic?
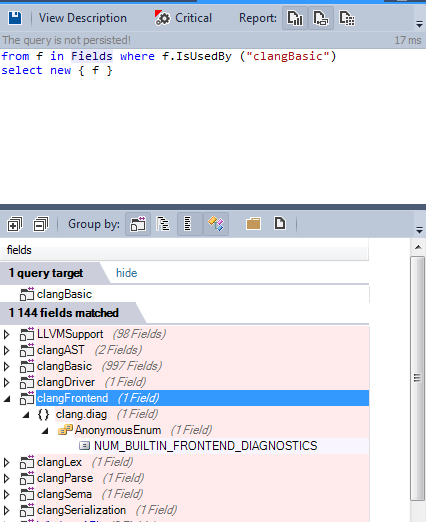
Только одно поле enum является причиной циклической зависимости, код может быть отрефакторен, и зависимость может быть легко устранена.
В С++ пространства имён используются для придания модульности коду, и в LLVM/clang они используются по трём главным причинам:
Многие пространства имён содержат только перечисления, как показано в следующем CQLinq запросе.
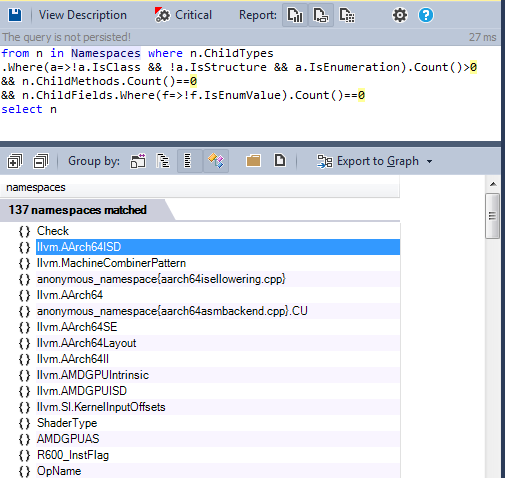
В большом проекте нельзя гарантировать, что два различных перечисления не будут называться одинаково. Проблема была разрешена в С++11, с использованием классов перечислений, которые подразумевают использование значений перечисления вместе с именем перечисления. Код может быть отрефакторен в ближайшем будущем с использованием классов перечислений С++11.
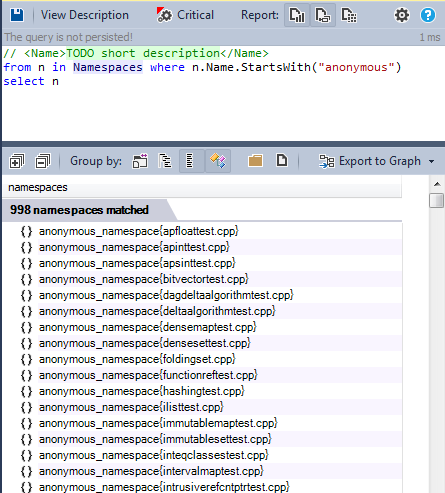
Анонимные пространства имён: Пространства имён без имени, позволяющие избегать создания глобальных статических переменных. Анонимное пространство имён, которое вы создали, будет доступно только в том файле, в котором оно создано. Вот список всех использованных анонимных пространств имён.
Все неанонимные пространства имён:
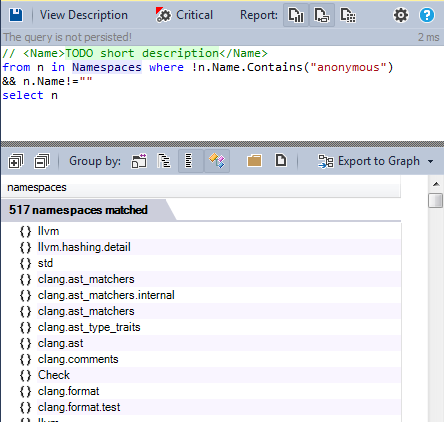
Пространства имён — это хорошее решение для того, чтобы сделать приложение модульным, LLVM/clang определяет более чем 500 пространств имён для обеспечения модульности, чтобы сделать код читаемым и поддерживаемым.
С++ — не просто объектно-ориентированный язык. Бьярн Страуструп указал, что С++ — мультипарадигменный язык. Он поддерживает множество стилей программирования, или парадигм, и объектная ориентация — лишь одна из них. Другие — процедурное программирование и обобщённое программирование.
2.1.1. Глобальные функции
Найдём все глобальные функции, определённые в исходнике LLVM/Clang:
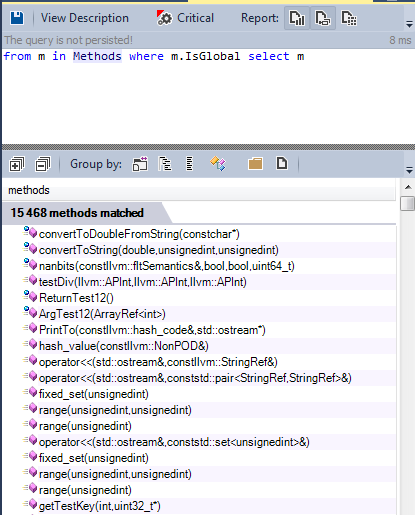
Мы можем разделить эти функции на три категории:
1 – Утилиты: Например, функции преобразования из одного типа в другой.
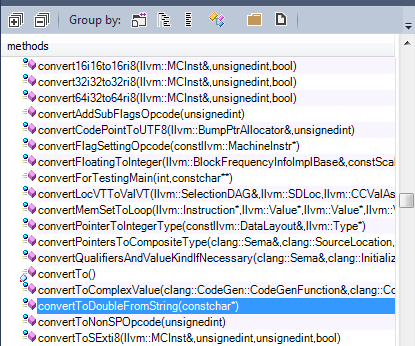
2 – Операторы: определено много операторов, как показывает результат CQLinq:
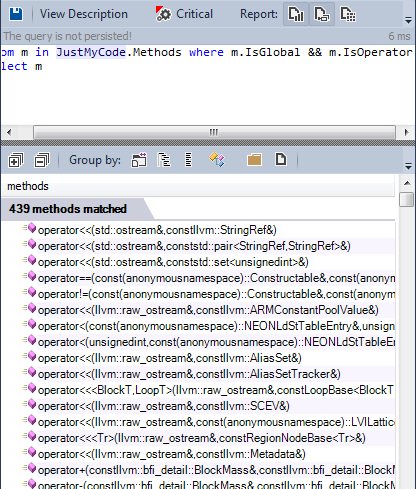
В исходном коде llvm/clang встречаются почти все переопределённые операторы.
3 – Функции, относящиеся к логике компилятора: Множество глобальных функций, реализующих различные функции компилятора.
Возможно, такой тип функций следовало бы сгруппировать по категориям, как статические методы классов, или сгруппировать их по пространствам имён.
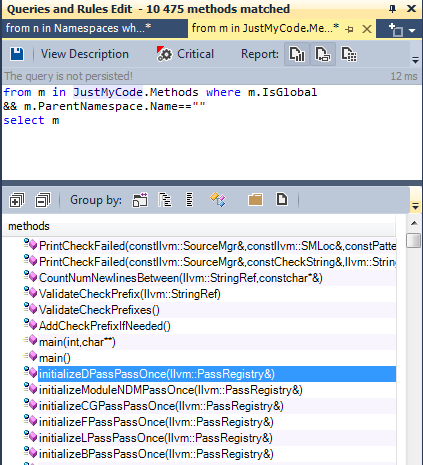
2.1.2. Статические глобальные функции
Наилучшей практикой является объявлять глобальные функции как статические, кроме тех специфических случаев, когда вам нужно вызывать их из другого файла исходного текста.
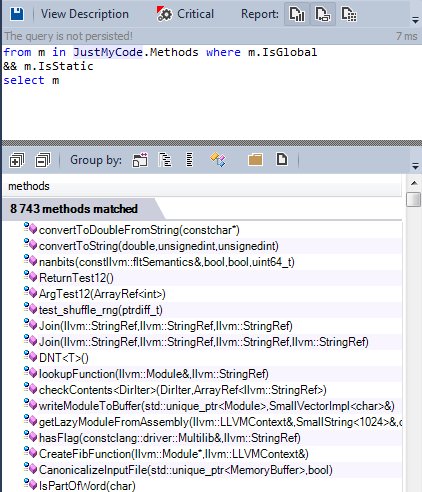
Почти все глобальные функции объявлены как статические.
2.1.3. Глобальные функции — кандидаты в статические
Глобальные, не экспортируемые функции, не объявленные в анонимном пространстве имён, не использованные никаким методом вне файла, где они были объявлены — это хорошие кандидаты на рефакторинг в статические.
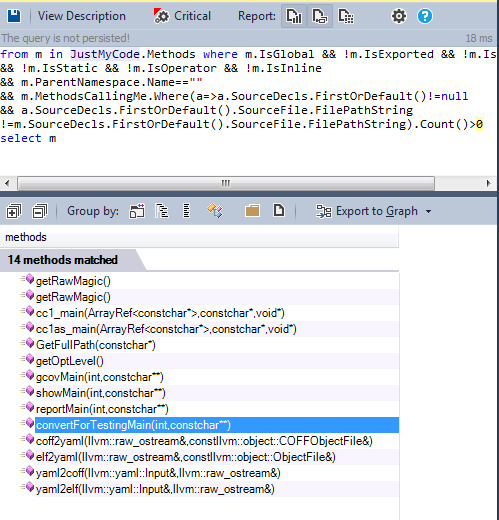
Как мы можем наблюдать, только несколько функций могут быть отрефакторены в статические.
2.2.1. Наследование
В объектно-ориентированном программировании (OOP), наследование — это способ установить отношение «является» между объектами. Его часто путают со способом повторного использования существующего кода, что не является хорошей практикой, потому что наследование для повторного использования реализации приводит к сильной взаимосвязи. Способность кода к повторному использованию достигается через композицию (композиция предпочтительнее наследования). Давайте поищем все классы, имеющие как минимум один базовый класс:
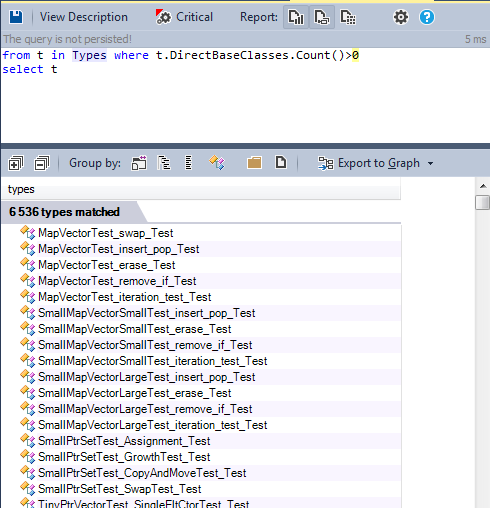
Лучше всего в этом запросе использовать Metric View.
В Metric View, кодовая база представлена как Treemap. Это метод отображения древовидной структуры данных, используя вложенные прямоугольники. Древовидная структура, использованная в CppDepend, это обычная иерархия кода:
Проекты содержат пространства имён.
Пространства имён содержат типы.
Типы содержат методы и поля.
Treemap — это полезный способ представления результатов запросов CQLinq, синие прямоугольники представляют результат, мы можем видеть типы, связанные с запросом.
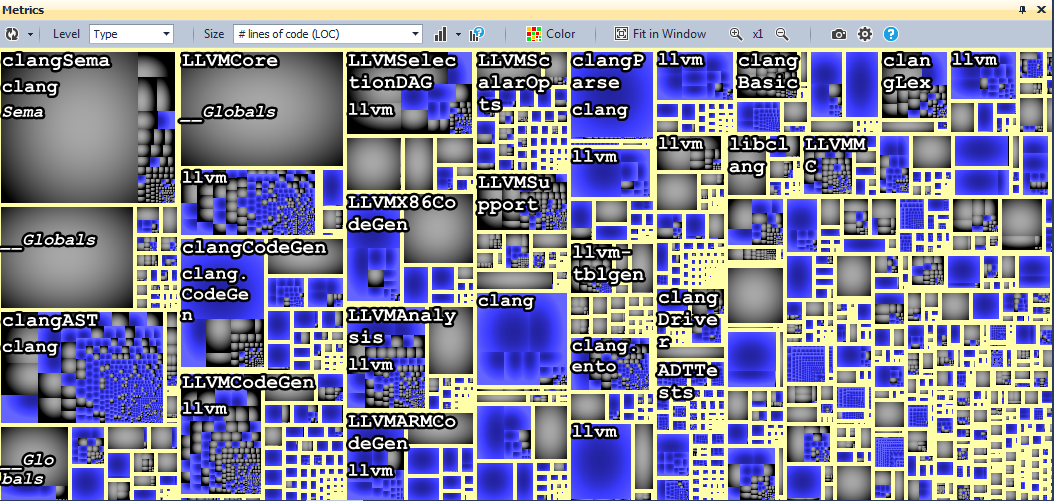
Как мы можем наблюдать, наследование широко используется в исходном коде llvm/clang.
Множественное наследование: давайте найдём классы, унаследованные более, чем от одного класса.
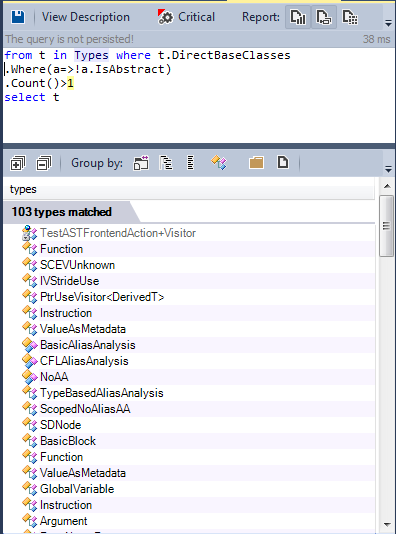
Множественное наследование используется нечасто, менее 1% классов унаследованы более, чем от одного класса.
2.2.2. Виртуальные методы
Давайте найдём все виртуальные методы, определённые в исходном коде:
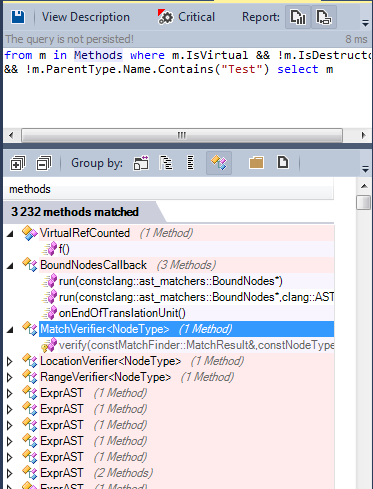
Многие методы виртуальные, некоторые из них являются чистыми виртуальными (pure virtual):
Парадигма OOP широко используется в исходном коде llvm/clang. Что насчёт обобщённого программирования?
С++ предоставляет уникальные возможности выражать идеи обобщённого программирования через шаблоны. Шаблоны являются формой параметрического полиморфизма, который позволяет выражать обобщённые алгоритмы и структуры данных. Механизм инстанцирования шаблонов С++ гарантирует, что, когда используются обобщённые алгоритмы и структуры данных, будет создана полностью оптимизированная и специализированная версия именно под конкретные параметры, позволяя обобщённым алгоритмам быть такими же эффективными, как их необобщённым версиям.
2.3.1. Обобщённые типы
Давайте найдём все обобщенные типы, определённые в исходном коде:
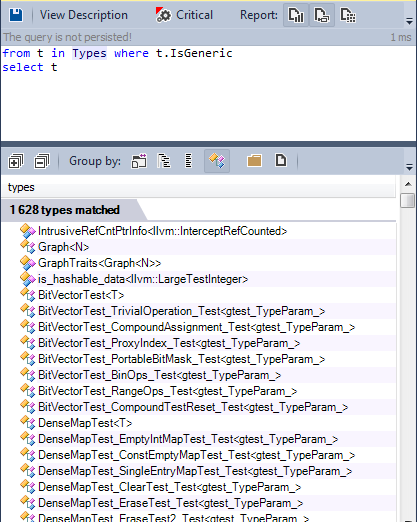
Многие типы определены как обобщённые. Давайте найдём обобщённые методы:
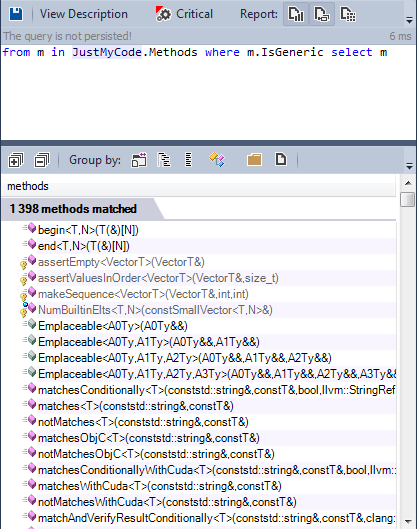
Менее 1% методов обобщённые
Итак, исходный код llvm/clang использует три парадигмы.
В объектно-ориентированном программировании, plain old data (POD) — это структура данных, которая представляет только пассивную коллекцию значений, без использования объектно-ориентированных функций. В computer science они также известны как пассивные структуры данных.
Давайте поищем типы POD в исходном коде.
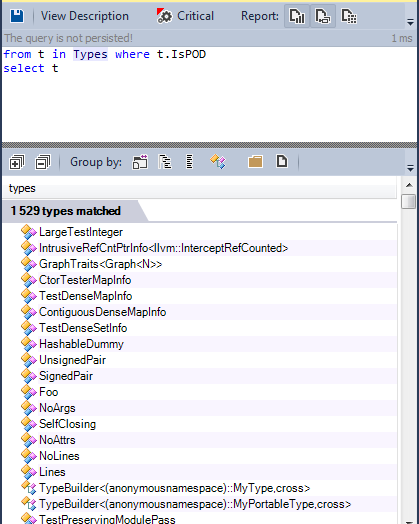
Более 1500 типов определены как типы POD, многие из них используются для определения модели данных компилятора.
Паттерны проектирования — это концепция программной инженерии, описывающая решения часто встречающихся проблем в проектировании ПО. Паттерны «Банда четырёх» являются самыми популярными. Давайте найдём их использование в исходном коде llvm/clang.
Список фабричных методов, определённых в исходном коде:
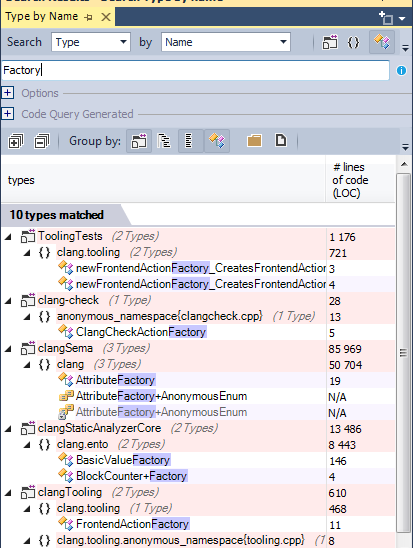
Список абстрактных фабричных методов:
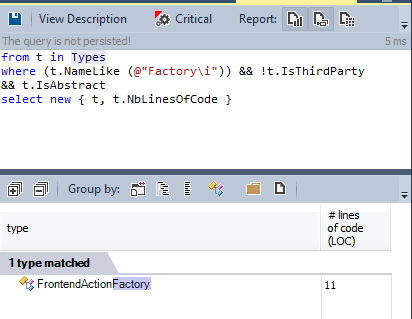
Паттерн наблюдателя — это паттерн проектирования, в котором объект содержит список объектов-наблюдателей, и уведомляет их автоматически о любых изменениях состояния, обычно вызывая один из их методов.
В исходном тексте есть только один наблюдатель:

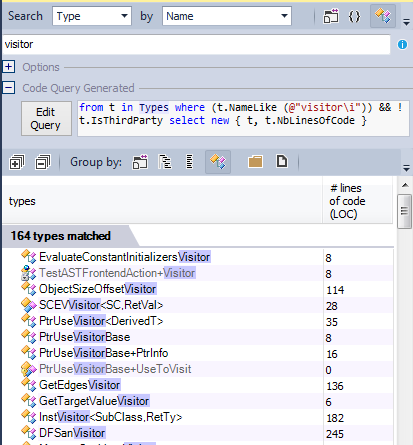
Паттерн посетителя рекомендуется когда нужно совершить обход структуры и совершить специфические действия в каждом узле структуры.
В исходном коде llvm/clang паттерн посетителя широко используется:
Низкая степень сцепления является желательной, так как изменения в одной части приложения потребуют меньше изменений в остальном приложении. В долгосрочной перспективе, это может сэкономить много времени, усилий и денег, связанных с модификацией и добавлением новых возможностей в приложение.
Низкая степень сцепления может быть достигнута использованием абстрактных классов или использованием обобщённых типов и методов.
Давайте найдём все абстрактные классы, определённые в исходном коде:
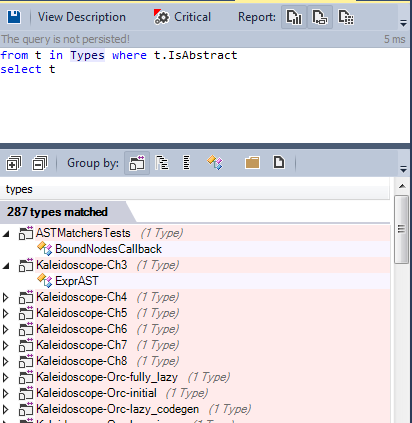
Более 280 типов задекларировано как абстрактные. Однако низкая степень сцепления также достигнута за счёт использования обобщённых типов и обобщённых методов.
Связность
Принцип единичной ответственности утверждает, что у класса не может быть более одной причины для изменений. Такие классы называются связными. Высокое значение LCOM чаще всего соответствует плохо связанным классам. Есть несколько метрик LCOM. LCOM принимает значение в диапазоне [0-1]. LCOM HS (HS означает Хендерсон-Селлерс) принимает значение в диапазоне [0-2]. Значение LCOM HS больше 1 должно настораживать. Метрики LCOM считаются как:
LCOM = 1 – (sum(MF)/M*F)
LCOM HS = (M – sum(MF)/F)(M-1)
где:
M — число методов класса (считая статические методы, конструкторы, геттеры/сеттеры, методы добавления и удаления событий).
F — количество нестатических полей класса.
MF — количество методов класса, имеющих доступ к конкретному нестатическому полю.
Sum(MF) — сумма MF по всем нестатическим полям класса.
Идея, выраженная этой формулой, может быть сформулирована следующим образом: класс связный, если все методы используют все нестатические поля, то есть sum(MF)=M*F, и, следовательно, LCOM = 0 и LCOMHS = 0.
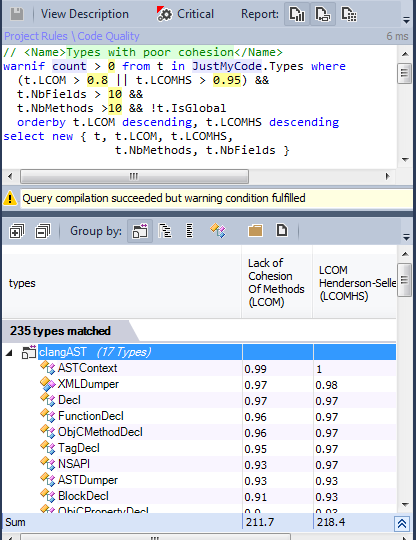
235 классов рассмотрено, возможно, некоторые из них могут быть отрефакторены для улучшения связности.
Объект называется иммутабельным, если его состояние не изменяется с момента, когда он был создан. Следовательно, класс называется иммутабельным, если его экземпляры иммутабельны.
Есть один аргумент в пользу использования иммутабельных объектов: он сильно упрощает конкурентное программирование. Подумайте, почему операция записи в многопоточном программировании настолько сложна? Потому что сложно синхронизировать доступ потоков к ресурсу (объектам или другим ресурсам ОС). Почему сложно синхронизировать доступ? Потому что трудно гарантировать, что не возникнет гонок между множеством потоков. Что, если не будет доступа на запись? Другими словами, что, если состояние объектов, к которым имеют доступ потоки, неизменно? Тогда нет необходимости в синхронизации.
Другое преимущество иммутабельных классов в том, что они никогда не нарушают принцип подстановки Лисков, вот определение принципа Лисков из википедии:
"подкласс не должен создавать новых мутаторов свойств базового класса. Если базовый класс не предусматривал методов для изменения определенных в нем свойств, подтип этого класса так же не должен создавать таких методов. Иными словами, неизменяемые данные базового класса не должны быть изменяемыми в подклассе."
Вот список иммутабельных типов в исходном коде:
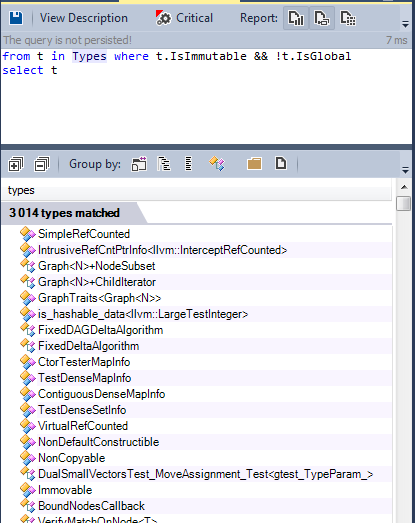
Главное преимущество иммутабельных типов происходит из факта, что они устраняют побочные эффекты. Я не смогу сказать об этом лучше, чем Уэс Дайер (Wes Dyer), и я процитирую его:
«Мы все знаем, что использование глобальных переменных не является хорошей идеей. Это происходит из-за опасности побочных эффектов (глобальной области видимости). Многие программисты, которые не используют глобальные переменные, не понимают, что тот же принцип применим к полям, свойствам, параметрам, и переменным в более ограниченном масштабе: не изменяйте их без веских причин (...)»
Одним из способов увеличить надёжность модуля, это избавиться от побочных эффектов. Это делает составление и интеграцию модулей более простым и надёжным делом. Если они не имеют побочных эффектов, они всегда работают одинаковым образом, вне зависимости от окружения. Это называется чистотой программирования (referential transparency).
Пишите функции и методы без побочных эффектов — это будут чистые функции, не изменяющие объект — так будет лучше в смысле корректности вашей программы.
Вот список всех методов без побочных эффектов:
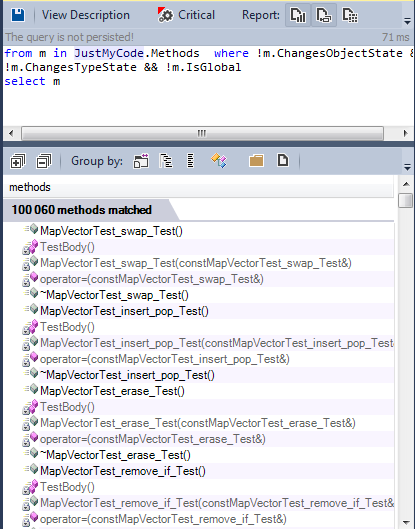
Более 100000 методов являются чистыми.
Методы с большим количеством строк кода трудно поддерживать и понимать. Давайте найдём методы, больше 60 строк.
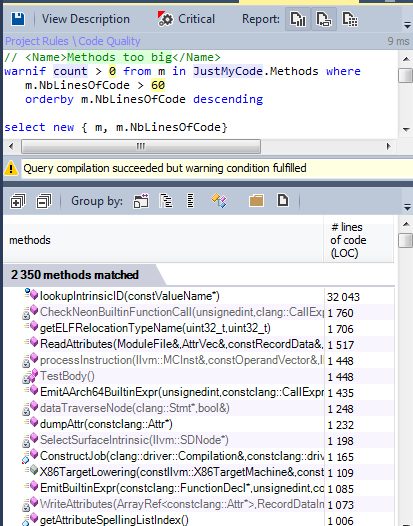
Исходный текст llvm/clang содержит более 100 000 методов, и менее 2% из них можно считать слишком большими.
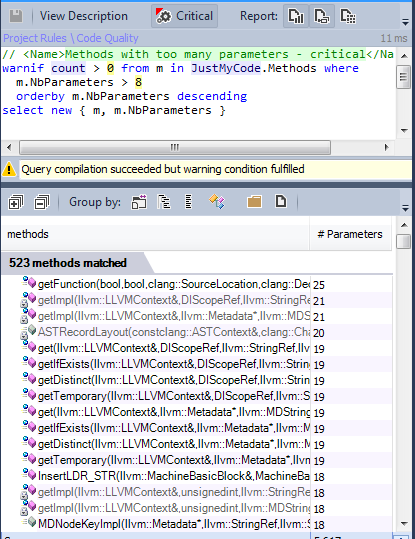
Несколько методов имеют больше 8 параметров.
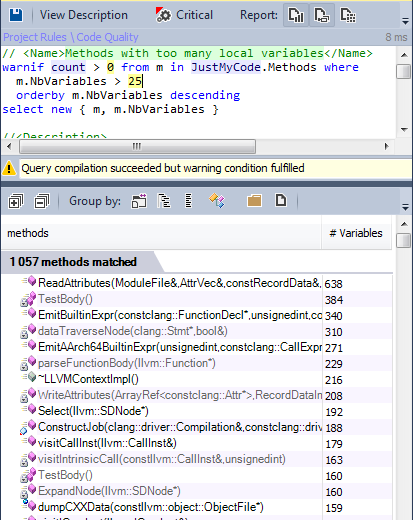
Менее 1% методов имеют много локальных переменных.
Многие метрики существуют для обнаружения сложных функций, вычисления количества строк кода, количества параметров, количества локальных переменных.
Существуют также интересные метрики для обнаружения сложных функций:
Цикломатическая сложность — популярная метрика процедурного программирования, равная количеству решений, которое принимается в процедуре.
Вложенная глубина — метрика, определённая для метода, определяющая максимальную глубину вложения областей видимости в теле метода.
Максимальная вложенность циклов.
Максимальные значения, допустимые для этих метрик, зависят больше от выбора команды разработки, здесь нет общепринятых стандартов.
Давайте найдём методы, которые могут рассматриваться как сложные.
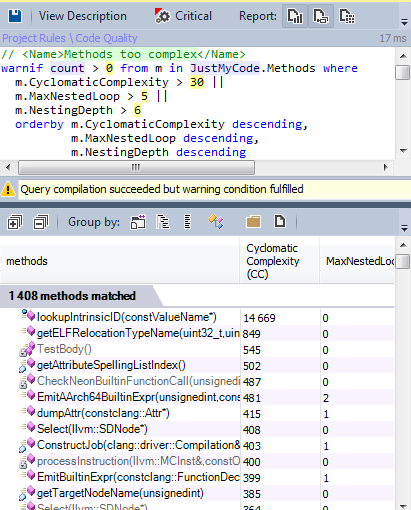
Только 1,5% методов являются кандидатами для минимизации сложности.
Сложность по Холстеду — это метрика программного обеспечения, введённая Морисом Говардом Холстедом в 1977 году. Холстед сделал наблюдение, что метрика программы должна отражать реализацию алгоритма на различных языках, но независимо от платформы. Эти метрики вычисляются статически по коду.
Холстед ввёл множество различных метрик, рассмотрим для примера одну из них — TimeToImplement, которая обозначает время, требуемое на то, чтобы запрограммировать метод, в секундах.
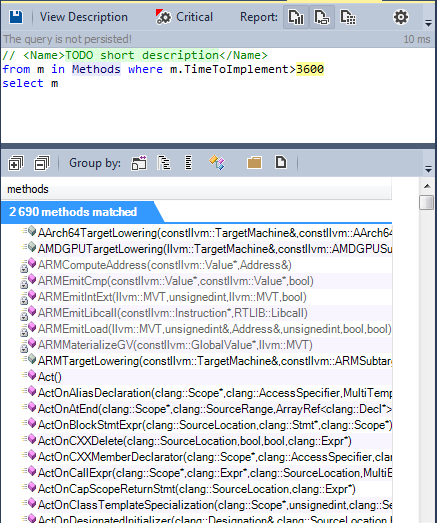
2690 методов требуют для своей реализации больше часа.
RTTI — способность системы сообщать о динамическом типе объекта и предоставлять информацию о типе во время исполнения (а не во время компиляции). Однако, использование RTTI считается спорным в сообществе С++. Многие разработчик С++ не используют этот механизм.
А как к этому относится команда разработчиков llvm/clang?
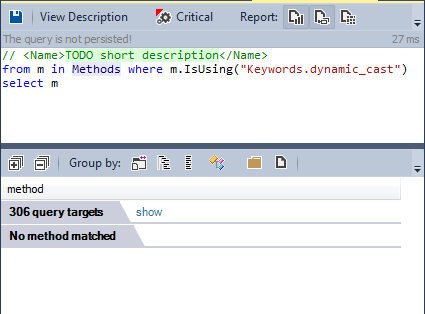
Ни один метод не использует ключевое слово dynamic_cast. Команда разработчиков llvm/clang выбрала не использовать механизм RTTI.
Поддержка исключений — другая спорная черта С++. Много известных опенсорсных проектов С++ не используют её.
Давайте посмотрим, не выбрасываются ли исключения где-либо в коде.
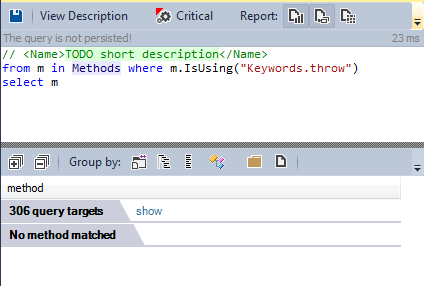
Как и RTTI, механизм исключений не используется.
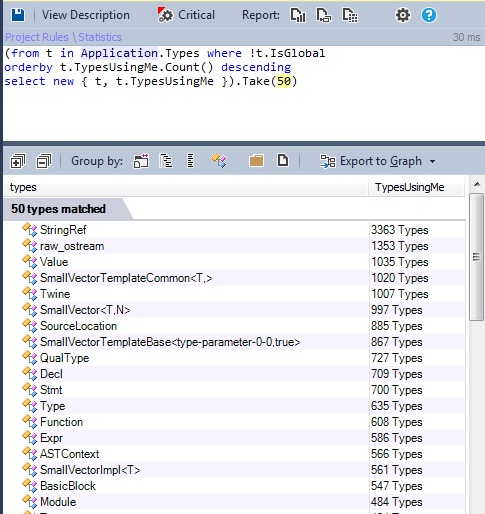
Интересно узнать, какой самые используемые типы в проекте, так как такие типы должны быть наилучшим образом спроектированы, реализованы и протестированы. Любые изменения в них повлияют на проект в целом.
Найдём их, используя метрику TypesUsingMe:
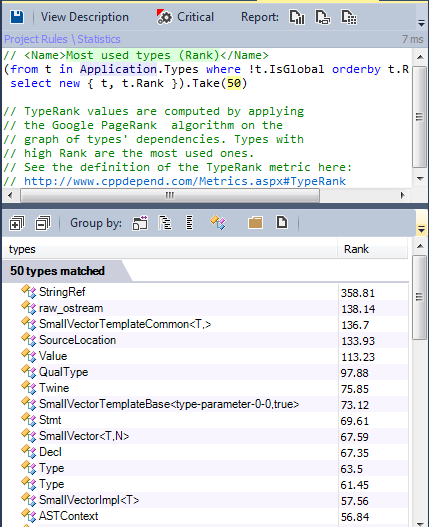
Есть ещё одна интересная метрика для поиска популярных типов: TypeRank.
Значение TypeRank вычисляется путём применения алгоритма Google PageRank на графе зависимости типов. Применена гомотетия центра 0.15 для того, чтобы средний TypeRank был равен единицы.
Типы с высоким TypeRank должны тестироваться более тщательно, потому что баги в них могут быть более катастрофическими.
Ниже приведены результаты всех популярных типов в соответствии с метрикой TypeRank:
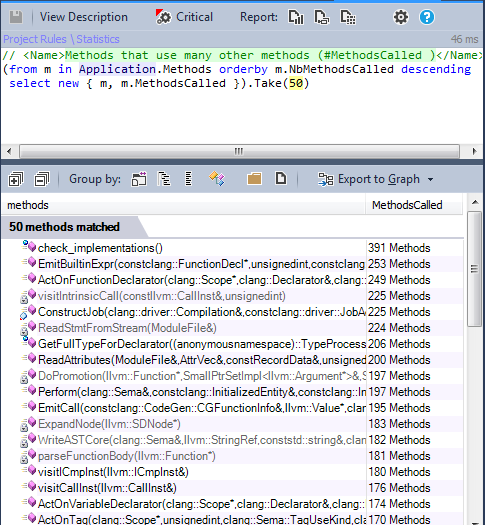
Интересно узнать, какие методы вызывают много других методов, это может выявить проблемы дизайна. В некоторых случаях требуется рефакторинг, чтобы сделать их более читаемыми и простыми в поддержке.
LLVM/Clang очень хорошо спроектирован и реализован, и, как для любой другой проект, его можно улучшить путём некоторого рефакторинга. В этом посте мы раскрыли некоторые минимальные возможные изменения, которые можно сделать в исходном коде. Не бойтесь исследовать исходный код и улучшать ваши знания С++.
Время доказало, что Clang является таким же зрелым компилятором C и C++, как GCC и компилятор от Microsoft, но то, что делает его особенным, это то, что это не просто компилятор. Это инфраструктура для создания инструментов. Благодаря тому, что его архитектура основана на использовании библиотек, повторное использование и интеграция функциональности в ваш проект делается более просто и гибко.
Структура Clang
Как и многие другие компиляторы, Clang состоит из трёх фаз:
Фронтенд, который делает парсинг исходного кода, проверяет ошибки, и строит зависящее от языка абстрактное синтаксическое дерево (AST), представляющее входной код.
Оптимизатор: его целью является оптимизация AST, сгенерированного фронтендом.
Бэкенд: генерирует финальный код, исполняемый машиной, зависит от целевой машины.
В чём разница между Clang и другими компиляторами?
Самое большое отличие состоит в том, что Clang основан на LLVM, а основной идеей LLVM является использование промежуточного представления (IR), которое является чем-то вроде байткода для Java.
LLVM IR разработан для поддержки промежуточных стадий анализа и преобразования, которые находятся в оптимизирующей стадии компилятора. Он разработан с учётом множества специфических требований, включая поддержку «лёгких» рантаймовых оптимизаций, межпроцедурных/межфункциональных оптимизаций, анализа программы в целом, агрессивных структурных преобразований, и т.п. Самым важным аспектом, однако, является то, что промежуточное представление само по себе является первоклассным языком с хорошо определённой семантикой.
С такой структурой мы можем повторно использовать большую часть компилятора для создания других компиляторов, например, вы можете заменить фронтенд для поддержки других языков.
Очень интересно залезть внутрь этой мощной игрушки и посмотреть, как она спроектирована и реализована. Разработчики на C++ могут изучить много хороших практик из этой кодовой базы.
Давайте «просветим рентгеном» исходный код, использовав CppDepend и CQLinq, чтобы понять некоторые решения разработчиков.
1. Модульность
1.1. Модульность и использование библиотек
Главной концепцией при разработке clang-а стало использование библиотек. Различные части фронтенда могут быть явно разделены на различные библиотеки, которые могут быть совместно использованы для различных целей. Такой подход поощряет использование хороших интерфейсов и облегчает задачу новым разработчикам (поскольку им нужно будет понять только маленькую часть общей картины).
DSM (Dependency Structure Matrix), матрица структуры зависимостей — это компактный способ представления зависимостей между компонентами. Непустая ячейка матрицы содержит число. Это число выражает силу связи, представленную ячейкой. Сила связи может быть выражена как число членов/методов/полей/типов и пространств имён, вовлечённых в связь.
Этот граф зависимостей показывает нам библиотеки, которые clang использует напрямую.
Как мы можем видеть, здесь существует три циклических зависимости между библиотеками clangBasic/clangFrontEnd, clangBasic/clangDriver и clangBasic/clangLex. Рекомендуется удалять любые циклические зависимости между библиотеками, чтобы код был более читаемым и простым в поддержке.
Почему clangFrontend использует библиотеку clangBasic?
Только одно поле enum является причиной циклической зависимости, код может быть отрефакторен, и зависимость может быть легко устранена.
1-2 Модульность с использованием пространств имён
В С++ пространства имён используются для придания модульности коду, и в LLVM/clang они используются по трём главным причинам:
Многие пространства имён содержат только перечисления, как показано в следующем CQLinq запросе.
В большом проекте нельзя гарантировать, что два различных перечисления не будут называться одинаково. Проблема была разрешена в С++11, с использованием классов перечислений, которые подразумевают использование значений перечисления вместе с именем перечисления. Код может быть отрефакторен в ближайшем будущем с использованием классов перечислений С++11.
Анонимные пространства имён: Пространства имён без имени, позволяющие избегать создания глобальных статических переменных. Анонимное пространство имён, которое вы создали, будет доступно только в том файле, в котором оно создано. Вот список всех использованных анонимных пространств имён.
Все неанонимные пространства имён:
Пространства имён — это хорошее решение для того, чтобы сделать приложение модульным, LLVM/clang определяет более чем 500 пространств имён для обеспечения модульности, чтобы сделать код читаемым и поддерживаемым.
2. Использование парадигм
С++ — не просто объектно-ориентированный язык. Бьярн Страуструп указал, что С++ — мультипарадигменный язык. Он поддерживает множество стилей программирования, или парадигм, и объектная ориентация — лишь одна из них. Другие — процедурное программирование и обобщённое программирование.
2.1. Процедурное программирование
2.1.1. Глобальные функции
Найдём все глобальные функции, определённые в исходнике LLVM/Clang:
Мы можем разделить эти функции на три категории:
1 – Утилиты: Например, функции преобразования из одного типа в другой.
2 – Операторы: определено много операторов, как показывает результат CQLinq:
В исходном коде llvm/clang встречаются почти все переопределённые операторы.
3 – Функции, относящиеся к логике компилятора: Множество глобальных функций, реализующих различные функции компилятора.
Возможно, такой тип функций следовало бы сгруппировать по категориям, как статические методы классов, или сгруппировать их по пространствам имён.
2.1.2. Статические глобальные функции
Наилучшей практикой является объявлять глобальные функции как статические, кроме тех специфических случаев, когда вам нужно вызывать их из другого файла исходного текста.
Почти все глобальные функции объявлены как статические.
2.1.3. Глобальные функции — кандидаты в статические
Глобальные, не экспортируемые функции, не объявленные в анонимном пространстве имён, не использованные никаким методом вне файла, где они были объявлены — это хорошие кандидаты на рефакторинг в статические.
Как мы можем наблюдать, только несколько функций могут быть отрефакторены в статические.
2.2. Объектно-ориентированная парадигма
2.2.1. Наследование
В объектно-ориентированном программировании (OOP), наследование — это способ установить отношение «является» между объектами. Его часто путают со способом повторного использования существующего кода, что не является хорошей практикой, потому что наследование для повторного использования реализации приводит к сильной взаимосвязи. Способность кода к повторному использованию достигается через композицию (композиция предпочтительнее наследования). Давайте поищем все классы, имеющие как минимум один базовый класс:
Лучше всего в этом запросе использовать Metric View.
В Metric View, кодовая база представлена как Treemap. Это метод отображения древовидной структуры данных, используя вложенные прямоугольники. Древовидная структура, использованная в CppDepend, это обычная иерархия кода:
Проекты содержат пространства имён.
Пространства имён содержат типы.
Типы содержат методы и поля.
Treemap — это полезный способ представления результатов запросов CQLinq, синие прямоугольники представляют результат, мы можем видеть типы, связанные с запросом.
Как мы можем наблюдать, наследование широко используется в исходном коде llvm/clang.
Множественное наследование: давайте найдём классы, унаследованные более, чем от одного класса.
Множественное наследование используется нечасто, менее 1% классов унаследованы более, чем от одного класса.
2.2.2. Виртуальные методы
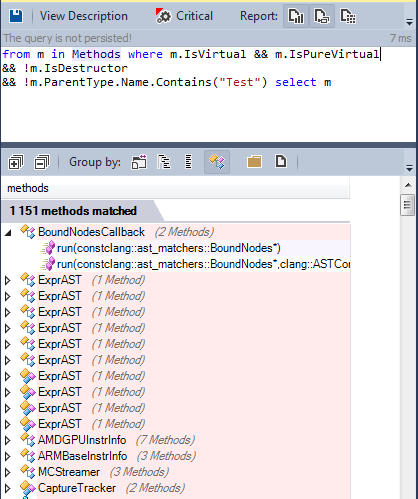
Давайте найдём все виртуальные методы, определённые в исходном коде:
Многие методы виртуальные, некоторые из них являются чистыми виртуальными (pure virtual):
Парадигма OOP широко используется в исходном коде llvm/clang. Что насчёт обобщённого программирования?
2.3. Обобщённое программирование
С++ предоставляет уникальные возможности выражать идеи обобщённого программирования через шаблоны. Шаблоны являются формой параметрического полиморфизма, который позволяет выражать обобщённые алгоритмы и структуры данных. Механизм инстанцирования шаблонов С++ гарантирует, что, когда используются обобщённые алгоритмы и структуры данных, будет создана полностью оптимизированная и специализированная версия именно под конкретные параметры, позволяя обобщённым алгоритмам быть такими же эффективными, как их необобщённым версиям.
2.3.1. Обобщённые типы
Давайте найдём все обобщенные типы, определённые в исходном коде:
Многие типы определены как обобщённые. Давайте найдём обобщённые методы:
Менее 1% методов обобщённые
Итак, исходный код llvm/clang использует три парадигмы.
3. PODы определяют модель данных
В объектно-ориентированном программировании, plain old data (POD) — это структура данных, которая представляет только пассивную коллекцию значений, без использования объектно-ориентированных функций. В computer science они также известны как пассивные структуры данных.
Давайте поищем типы POD в исходном коде.
Более 1500 типов определены как типы POD, многие из них используются для определения модели данных компилятора.
4. Паттерны проектирования банды четырёх
Паттерны проектирования — это концепция программной инженерии, описывающая решения часто встречающихся проблем в проектировании ПО. Паттерны «Банда четырёх» являются самыми популярными. Давайте найдём их использование в исходном коде llvm/clang.
4.1. Фабрика
Список фабричных методов, определённых в исходном коде:
Список абстрактных фабричных методов:
4.2. Наблюдатель
Паттерн наблюдателя — это паттерн проектирования, в котором объект содержит список объектов-наблюдателей, и уведомляет их автоматически о любых изменениях состояния, обычно вызывая один из их методов.
В исходном тексте есть только один наблюдатель:
4.3. Посетитель
Паттерн посетителя рекомендуется когда нужно совершить обход структуры и совершить специфические действия в каждом узле структуры.
В исходном коде llvm/clang паттерн посетителя широко используется:
5. Сцепление и связность (Coupling and Cohesion)
5.1. Сцепление
Низкая степень сцепления является желательной, так как изменения в одной части приложения потребуют меньше изменений в остальном приложении. В долгосрочной перспективе, это может сэкономить много времени, усилий и денег, связанных с модификацией и добавлением новых возможностей в приложение.
Низкая степень сцепления может быть достигнута использованием абстрактных классов или использованием обобщённых типов и методов.
Давайте найдём все абстрактные классы, определённые в исходном коде:
Более 280 типов задекларировано как абстрактные. Однако низкая степень сцепления также достигнута за счёт использования обобщённых типов и обобщённых методов.
Связность
Принцип единичной ответственности утверждает, что у класса не может быть более одной причины для изменений. Такие классы называются связными. Высокое значение LCOM чаще всего соответствует плохо связанным классам. Есть несколько метрик LCOM. LCOM принимает значение в диапазоне [0-1]. LCOM HS (HS означает Хендерсон-Селлерс) принимает значение в диапазоне [0-2]. Значение LCOM HS больше 1 должно настораживать. Метрики LCOM считаются как:
LCOM = 1 – (sum(MF)/M*F)
LCOM HS = (M – sum(MF)/F)(M-1)
где:
M — число методов класса (считая статические методы, конструкторы, геттеры/сеттеры, методы добавления и удаления событий).
F — количество нестатических полей класса.
MF — количество методов класса, имеющих доступ к конкретному нестатическому полю.
Sum(MF) — сумма MF по всем нестатическим полям класса.
Идея, выраженная этой формулой, может быть сформулирована следующим образом: класс связный, если все методы используют все нестатические поля, то есть sum(MF)=M*F, и, следовательно, LCOM = 0 и LCOMHS = 0.
235 классов рассмотрено, возможно, некоторые из них могут быть отрефакторены для улучшения связности.
6. Иммутабельность, чистота и побочные эффекты
6.1. Иммутабельные типы
Объект называется иммутабельным, если его состояние не изменяется с момента, когда он был создан. Следовательно, класс называется иммутабельным, если его экземпляры иммутабельны.
Есть один аргумент в пользу использования иммутабельных объектов: он сильно упрощает конкурентное программирование. Подумайте, почему операция записи в многопоточном программировании настолько сложна? Потому что сложно синхронизировать доступ потоков к ресурсу (объектам или другим ресурсам ОС). Почему сложно синхронизировать доступ? Потому что трудно гарантировать, что не возникнет гонок между множеством потоков. Что, если не будет доступа на запись? Другими словами, что, если состояние объектов, к которым имеют доступ потоки, неизменно? Тогда нет необходимости в синхронизации.
Другое преимущество иммутабельных классов в том, что они никогда не нарушают принцип подстановки Лисков, вот определение принципа Лисков из википедии:
"подкласс не должен создавать новых мутаторов свойств базового класса. Если базовый класс не предусматривал методов для изменения определенных в нем свойств, подтип этого класса так же не должен создавать таких методов. Иными словами, неизменяемые данные базового класса не должны быть изменяемыми в подклассе."
Вот список иммутабельных типов в исходном коде:
6.2. Чистота и побочные эффекты
Главное преимущество иммутабельных типов происходит из факта, что они устраняют побочные эффекты. Я не смогу сказать об этом лучше, чем Уэс Дайер (Wes Dyer), и я процитирую его:
«Мы все знаем, что использование глобальных переменных не является хорошей идеей. Это происходит из-за опасности побочных эффектов (глобальной области видимости). Многие программисты, которые не используют глобальные переменные, не понимают, что тот же принцип применим к полям, свойствам, параметрам, и переменным в более ограниченном масштабе: не изменяйте их без веских причин (...)»
Одним из способов увеличить надёжность модуля, это избавиться от побочных эффектов. Это делает составление и интеграцию модулей более простым и надёжным делом. Если они не имеют побочных эффектов, они всегда работают одинаковым образом, вне зависимости от окружения. Это называется чистотой программирования (referential transparency).
Пишите функции и методы без побочных эффектов — это будут чистые функции, не изменяющие объект — так будет лучше в смысле корректности вашей программы.
Вот список всех методов без побочных эффектов:
Более 100000 методов являются чистыми.
7. Качество реализации
7.1. Слишком большие методы
Методы с большим количеством строк кода трудно поддерживать и понимать. Давайте найдём методы, больше 60 строк.
Исходный текст llvm/clang содержит более 100 000 методов, и менее 2% из них можно считать слишком большими.
7.2. Методы с большим количеством параметров
Несколько методов имеют больше 8 параметров.
7.3. Методы с множеством локальных переменных
Менее 1% методов имеют много локальных переменных.
7.4. Слишком сложные методы
Многие метрики существуют для обнаружения сложных функций, вычисления количества строк кода, количества параметров, количества локальных переменных.
Существуют также интересные метрики для обнаружения сложных функций:
Цикломатическая сложность — популярная метрика процедурного программирования, равная количеству решений, которое принимается в процедуре.
Вложенная глубина — метрика, определённая для метода, определяющая максимальную глубину вложения областей видимости в теле метода.
Максимальная вложенность циклов.
Максимальные значения, допустимые для этих метрик, зависят больше от выбора команды разработки, здесь нет общепринятых стандартов.
Давайте найдём методы, которые могут рассматриваться как сложные.
Только 1,5% методов являются кандидатами для минимизации сложности.
7.5. Сложность по Холстеду
Сложность по Холстеду — это метрика программного обеспечения, введённая Морисом Говардом Холстедом в 1977 году. Холстед сделал наблюдение, что метрика программы должна отражать реализацию алгоритма на различных языках, но независимо от платформы. Эти метрики вычисляются статически по коду.
Холстед ввёл множество различных метрик, рассмотрим для примера одну из них — TimeToImplement, которая обозначает время, требуемое на то, чтобы запрограммировать метод, в секундах.
2690 методов требуют для своей реализации больше часа.
8. RTTI
RTTI — способность системы сообщать о динамическом типе объекта и предоставлять информацию о типе во время исполнения (а не во время компиляции). Однако, использование RTTI считается спорным в сообществе С++. Многие разработчик С++ не используют этот механизм.
А как к этому относится команда разработчиков llvm/clang?
Ни один метод не использует ключевое слово dynamic_cast. Команда разработчиков llvm/clang выбрала не использовать механизм RTTI.
9. Исключения
Поддержка исключений — другая спорная черта С++. Много известных опенсорсных проектов С++ не используют её.
Давайте посмотрим, не выбрасываются ли исключения где-либо в коде.
Как и RTTI, механизм исключений не используется.
10. Некоторая статистика
10.1. Самые популярные типы
Интересно узнать, какой самые используемые типы в проекте, так как такие типы должны быть наилучшим образом спроектированы, реализованы и протестированы. Любые изменения в них повлияют на проект в целом.
Найдём их, используя метрику TypesUsingMe:
Есть ещё одна интересная метрика для поиска популярных типов: TypeRank.
Значение TypeRank вычисляется путём применения алгоритма Google PageRank на графе зависимости типов. Применена гомотетия центра 0.15 для того, чтобы средний TypeRank был равен единицы.
Типы с высоким TypeRank должны тестироваться более тщательно, потому что баги в них могут быть более катастрофическими.
Ниже приведены результаты всех популярных типов в соответствии с метрикой TypeRank:
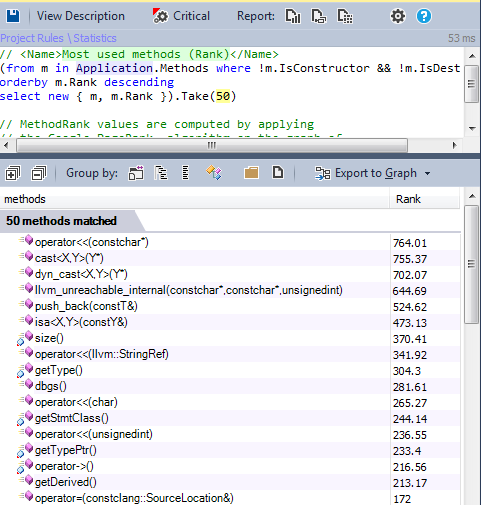
10.2. Самые популярные методы
10.3. Методы, вызывающие много других методов
Интересно узнать, какие методы вызывают много других методов, это может выявить проблемы дизайна. В некоторых случаях требуется рефакторинг, чтобы сделать их более читаемыми и простыми в поддержке.
Итоги
LLVM/Clang очень хорошо спроектирован и реализован, и, как для любой другой проект, его можно улучшить путём некоторого рефакторинга. В этом посте мы раскрыли некоторые минимальные возможные изменения, которые можно сделать в исходном коде. Не бойтесь исследовать исходный код и улучшать ваши знания С++.
Комментарии (24)

Einherjar
12.03.2018 15:54очень хорошо спроектирован
Быдлокодеров туда тоже иногда пускают. Два года назад где то в libclang добавились функции для вычисления выражений (clang_Cursor_Evaluate и.т.п.). Но функция выдающая целочисленный результат возвращала только 32 битное число, при том что весь внутренний код изначально вполне вменяемо вычислял 64-битные значения — оно просто потом тупо обрезалось. Как же бесило то что кто то в 201х годах еще не знает о том что бывают 64 битные вычисления. Правил в своем локальном форке пока в новой версии они не добавили таки потом костыль clang_EvalResult_getAsLongLong, но почему сразу было не сделать нормально большой вопрос.
32bit_me Автор
12.03.2018 18:15Интересно. Я туда не заглядывал.
Имхо, здесь имеется в виду вот что. LLVM основан на мощной концепции: языке LLVM IR, и системе классов, представляющих основные структуры компилятора. Именно эти базовые вещи спроектированы очень хорошо. А 100500 проходов оптимизации и трансформации кода могут быть написаны самыми разными людьми, и не все из них гении, увы. Но хорошая базовая структура позволяет развивать и поддерживать такой большой проект.
knstqq
Даааа, в Runtime совсем не используется никакой информации о типах
32bit_me Автор
LLVM не использует RTTI. Вместо него используется оригинальный механизм, и собственные шаблоны dyn_cast<> и isa<>.
Если интересно, могу кинуть ссылку на описание этого механизма.
knstqq
Да, интересно почитать про отличия, дайте ссылку пожалуйста.
В официальной документации говорится о том, что эти типы работают не только для классов с vtable.
32bit_me Автор
Хорошо, вечером найду.
32bit_me Автор
Вот здесь написано:
https://llvm.org/docs/HowToSetUpLLVMStyleRTTI.html
mayorovp
LLVM не использует стандартный RTTI. Но это не означает что они не используют никакого RTTI! Они даже в своих доках так напрямую и пишут:
32bit_me Автор
Это просто игра словами. Не используется стандартный механизм RTTI языка C++.
mayorovp
Игра словами — это то что у вас получилось.
Самая распространенная претензия к dynamic_cast, та самая "спорность" — "в хорошей архитектуре его просто не должно быть", обычно без обоснования. И про dyn_cast можно сказать то же самое независимо от того считать его RTTI ли нет.
32bit_me Автор
dyn_cast — очень лёгкий и быстрый механизм, с минимальными накладными расходами, в отличие от.
Рассуждения о «хорошей архитектуре» давайте оставим диванным теоретикам.
mayorovp
И что же мешает разработчикам компилятора сделать dynamic_cast таким же хорошим?
32bit_me Автор
То, что реализация dyn_cast требует от программиста дополнительных усилий. Этот механизм не работает автоматически. Вечером выложу сюда ссылку на документ с описанием.
32bit_me Автор
Выше привёл ссылку, там общий принцип механизма изложен.
Могу написать отдельный пост на эту тему.
Mingun
По той ссылке описана реализация, но совершенно не объяснено, зачем же она нужна. По мне, так описанное там с является самым наивным подходом, легко приводящим к багам. Даже как-то неловко, что выше тут ее называли "оригинальной реализацией".
Неясность нужности — необходимость
dynamic_cast-а вообще нужно только в случае виртуальных классов, я просто не могу придумать пример, когда его нужно применять для классов без виртуальных функций. Так что непонятно, нафига собственная реализация, если для класса с виртуальными функциями компилятор гарантированно может реализовать все оптимальным образом?32bit_me Автор
Тем, не менее, этот подход успешно работает.
Знаете, я прямо сейчас не готов всё сформулировать, зачем это и для чего. Предлагаю вам посмотреть исходники LLVM, там dyn_cast<> и isa<> встречаются повсеместно.
Или я могу написать отдельный пост на эту тему, но это займёт некоторое время.
Mingun
Копи-паст тоже успешно работает, но каждая статья о PVS-Studio показывает пачку багов, с ним связанных. Просто удивительно, почему в таком крупном и явно хорошо продуманном проекте используется такое хрупкое решение? Почему нельзя было хотя бы какую-то шаблонную магию применить для генерации уникальных чиселок вместо ручного прописывания enum-ов?
Вообщем, в статье хотелось бы увидеть, аргументированные минусы стандартного
dynamic_cast-а и случаи, когда их можно не опасаться, если они есть. По моему наивному предположению для реализации у класса с виртуальными функциями достаточно несколько сравнений указателя на vtable из экземпляра класса со всеми возможными для этого указателя vtable-ами всех классов из иерархии. У компилятора есть вся эта информация, говорить о бинарной совместимости в данном контексте глупо (когда часть классов в другой DLL), с кастомнымdynamic_cast-ом ABI тоже не будет. Компилятор для себя всегда может генерировать специальные функции, которыми будет связываться RTTI информация из разных модулей.Также еще хочется обратить внимание на такой момент: приведенная статья в документации LLVM рекомендует сделать
enumсо всеми возможными типами классов и сохранить его в поле класса. Если не указывать специально, то размерenum-а должен быть равен размеруint-а, а он, в свою очередь — размеру указателя. Т.е. при использовании встроенных возможностей черезdynamic_castможно сделать виртуальными даже те классы, которым виртуальность не нужна, если вдруг по каким-то причинам их должныdynamic_cast-ить. Накладных расходов по памяти на это не будет, и так и так в класс добавляется дополнительное поле размером с указатель, зато компилятор делает за нас всю работу. А в случае использования с классами, уже имеющими виртуальные функции даже оказываемся в выигрыше.Единственная проблема с
dynamic_cast-ом видится в том, что если он вдруг будет применен к классам без виртуальных функций, то его реализация может быть тяжелой. Если такое применение было сделано непреднамеренно, то можно незаметно получить просадку в производительности. Но ведь на такую ситуацию наверняка компилятор может выдать предупреждение, которое всегда можно повысить до ошибки и если сейчас такого предупреждения нет, то вопрос — почему?32bit_me Автор
Интересные идеи, над этим стоит поразмышлять. Я не готов сейчас ответить по существу.
Videoman
Класс «С» без проблем кастируется к классу «D» которого нет в иерархии vtable-ов С. Фактически, для реализации полноценного dynamic_cast, вам придется сравнивать с vtable-ами всех классов известных данному модулю.
Mingun
Тут как раз не класс «C», а класс «G» кастуется к классу «D», иерархия vtable-ов статического типа кастуемого указателя тут совсем не при чем. И сравнений тут будет не намного больше, чем при ручной реализации инструментарием LLVM (в LLVM может быть сделана оптимизация, заключающаяся в проверке диапазонов, экономящая сравнения. Но мне кажется, это экономия на спичках).
Здесь при касте затребован тип «D», значит компилятор должен сделать проверки только с vtable-ами всех типов, которые наследуются от него и с ним самим. В частности, здесь будет максимум всего 3 сравнения:
ptrC->vtblс таблицами классов «D», «F» и «G». Пожалуй, компилятор даже оптимизация с диапазонами может сделать, если будет располагать vtable классов в порядке обхода root-childs их дерева наследования, как предлагают делать в той статье в документации LLVM со значениями перечислений. Впрочем, в данном случае это сэкономит лишь одно сравнение, так что овчинка не стоит выделки.Videoman
Ну все верно. Только представьте, что в общем виде, может быть какой-нибудь класс который наследует все остальные — допустим «Z», и в данном дереве vtable-ов любой класс может быть скастирован к любому другому. Если сюда еще добавить возможность виртуального наследования (это ересь, на мой взгляд, но все же), то механизм становиться не таким уж тривиальным. Если данный механизм используется очень активно, то это может сильно сказаться на скорости.
В моей практике был случай, когда классы на стеке создавались так часто, что переопределив конструктор по-умолчанию (который зануляет поля класса) мы ускорили код в 10 раз, а что говорить про dynamic_cast.
Mingun
Ну согласитесь, это редкие случаи, а для частных случаев почему-бы компилятору не делать более быстрый код? Ведь если вручную писать все это, мы столкнемся с теми же самыми проблемами. И если они решаются вручную, пусть для каких-то частных случаев, что мешает компилятору распознать эти частные случаи и сделать все оптимально?
Вот я и кастую статью, где бы все это было объяснено. Тем более сейчас с новым стандартом, где есть
finalклассы, дерево классов можно ограничить.Videoman
Я думаю что если такие оптимизации возможны, они бы были, либо в новых стандартах нужно будет вводить дополнительные ограничения (типа ABI и т.п.).
Mingun
Я бы еще перефразировал фразу
"Около половины" не совсем то же самое, что и "почти все".