Привет всем!
Сегодня я хотел бы рассказать о языке программирования Red. Язык Red является непосредственным преемником более раннего языка REBOL. Оба они малоизвестны в русскоязычном сообществе, что само по себе странно, т.к. указанные языки представляют интерес как с точки зрения оригинального взгляда на то, каким должно быть программирование, так и тем, что отличаются потрясающей выразительностью, позволяя решать сложные задачи простыми способами.
Данная статья призвана исправить сложившуюся ситуацию, являясь первым пособием по основам языка Red на русском языке.

О языке Red
В 1997 году Карлом Сассенратом, бывшим основным разработчиком AmigaOS, был предложен язык REBOL (http://www.rebol.com/). Однако разработка REBOL прекратилась к 2010 году, и в качестве его преемника в 2011 году Ненадом Ракоцевичем был анонсирован язык Red (http://www.red-lang.org/), наследуя синтаксис родоначальника и призванный его превзойти.
Одним из главных преимуществ Red/REBOL является его исключительная выразительность, позволяющая реализовать заданную функциональность минимальным количеством кода. Следующий график иллюстрирует результат исследования данного показателя для разных языков программирования:
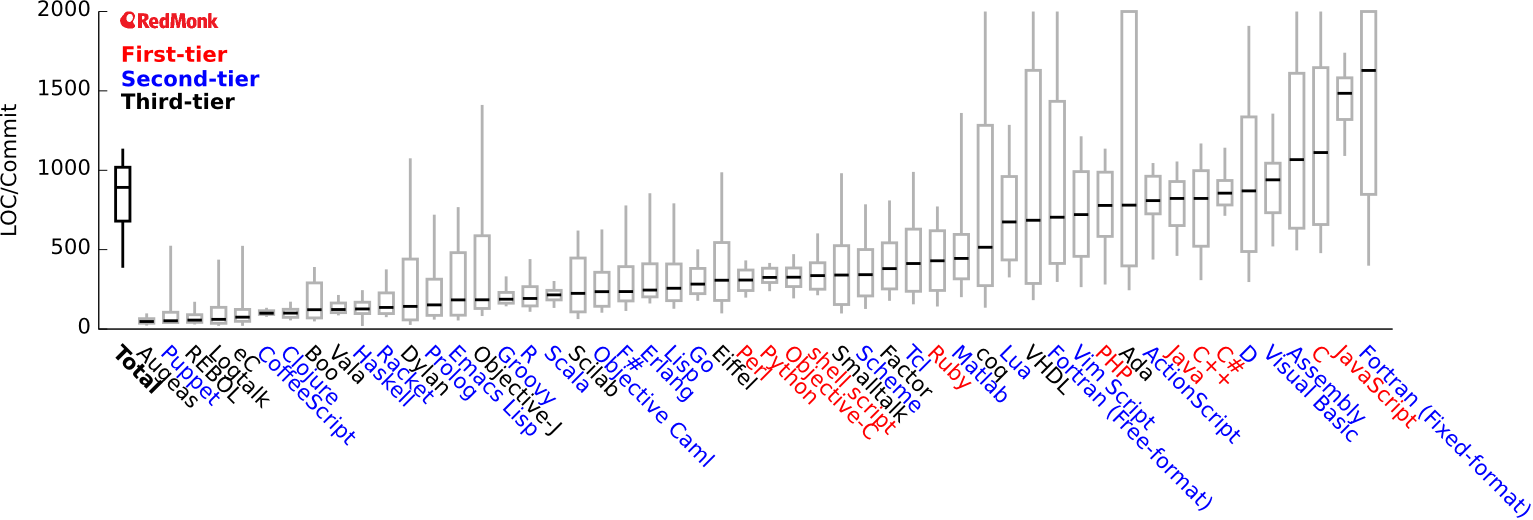
Сравнение выразительности языков программирования (источник)
Из графика видно, что согласно примененной методике сравнения REBOL является самым выразительным языком общего назначения (лидирующие Augeas и Puppet – языки узких предметных областей). Red в ряде случаев является даже более выразительным, чем REBOL.
Другие ключевые отличия и достоинства языка Red:
- Язык полного стека – от низкоуровневого программирования до написания скриптов.
- Создание мультиплатформенных приложений.
- Поддержка кросс-платформенного нативного GUI.
- Легкое создание DSL.
- Функциональное, императивное, реактивное программирование.
- Гомоиконность (способность программы обрабатывать свой код в качестве данных).
- Развитая поддержка макросов.
- Большое число встроенных типов.
- Исключительная простота установки, не требующая инсталляции и настройки.
На текущий момент Red активно развивается, поэтому часть возможностей еще только готовится к реализации. Среди таких возможностей, не реализованных на момент написания данной статьи: поддержка Android и iOS GUI, поддержка в полном объеме операций ввода/вывода, поддержка модульной компиляции, поддержка параллелизма.
Начало работы
Установка программы
Установка Red под платформу Windows:
- Скачайте исполняемый файл, расположенный по адресу (файл весит всего лишь около 1МВ).
- Разместите скачанный файл в выбранную папку.
- Запустите скачанный файл. Выполнится сборка GUI-консоли, которая займет некоторое время (сборка осуществляется лишь при первом запуске).
После того, как сборка выполнится, откроется консоль – Red готов к работе.
Hello World!
Консоль вызывается всякий раз, когда исполняемый файл Red запускается без аргументов. Консоль дает возможность работать с кодом Red в режиме интерпретации.
Для создания первой программы, выводящей текст «Hello world!», введите и выполните в консоли следующий код:
print "Hello World!"Для создания программы с нативным GUI:
view [text "Hello World!"]Или немного более сложный вариант:
view [name: field button "Hello world!" [name/text: "Hello world!"]]Создание исполнимого файла
Для компиляции кода Red в исполнимый файл выполните следующие шаги:
- Введите в текстовом редакторе следующий код (для компиляции, в отличие от интерпретации, код должен обязательно содержать заголовок):
Red [] print "Hello World!" - Сохраните код в файл
hello.redв папке, где расположен Red. - В терминале выполните команду (если имя вашего файла компилятора отличается от red, поменяйте его на корректное):
red -c hello.red
В результате выполнения перечисленных шагов программа будет скомпилирована.
Компиляция программы с нативным GUI осуществляется аналогично, однако в заголовок программы для этого требуется внести небольшое изменение:
Red [Needs: 'View]
view [text "Hello World!"]Общие сведения о программах Red
Диалекты
Red включает в себя ряд диалектов, используемых в зависимости от предметной области:
- Red/Core – основа языка Red.
- Red/System – диалект для программирования на системном уровне.
- Red/View – набор диалектов для визуализации (VID и Draw).
- Red/Parse – диалект, используемый для парсинга.
Далее в статье пойдет речь об основе языка – Red/Core.
Файлы
Файл, содержащий код Red, должен иметь расширение
.red и кодировку UTF-8.Заголовки
Программа Red обязательно должна иметь заголовок. Заголовок указывает, что содержащийся в файле код – код Red, а также позволяет задать ряд дополнительных атрибутов.
Для программ Red заголовок в общем случае имеет вид:
Red [block]Важно! Несмотря на то, что Red нечувствителен к регистру, слово “Red” в заголовке обязательно должно писаться в точности, как показано в примере – с заглавной буквы.
Перечень атрибутов заголовка опционален и определяется самим пользователем.
Минимальный заголовок:
Red []Стандартный заголовок:
Red [
Title: "Hello World!" ;-- название программы
Version: 1.1.1 ;-- версия программы
Date: 7-Nov-2017 ;-- дата последней модификации
File: %Hello.red ;-- название файла
Author: "John Smith" ;-- имя автора
Needs: 'View ;-- зависимости
]Комментарии
Программы Red могут содержать комментарии.
Для комментария, состоящего из одной строки, используется точка с запятой:
max: 10 ;-- максимальное значение параметраДля комментария, состоящего из нескольких строк используются фигурные скобки
{}. Для того, чтобы быть точно уверенным, что такие комментарии будут восприняты Red как комментарии, а не как код, перед ними следует указать ключевое слово comment:{
Это многострочный
комментарий
}
comment {
Это многострочный
комментарий
}Основы синтаксиса
Блоки
Программа, написанная на Red, состоит из блоков, комбинирующих значения (values) и слова (words). Блоки заключаются в квадратные скобки
[]. Значения и слова в составе блоков всегда разделяются одним или несколькими пробелами – это важно для правильной интерпретации кода.Блоки используются для кода, списков, массивов и других последовательностей, представляя собой разновидность серий (series).
Примеры блоков:
[white yellow orange red green blue black]
["Spielberg" "Back to the Future" 1:56:20 MCA]
[
"Elton John" 6894 0:55:68
"Celine Dion" 68861 0:61:35
"Pink Floyd" 46001 0:50:12
]
loop 12 [print "Hello world!"]Значения
Каждое значение в Red имеет свой тип. По умолчанию, наименования типов оканчиваются восклицательным знаком
!.Наиболее часто используемые типы:
| Тип | Описание | Примеры |
|---|---|---|
word! |
Слово программы, рассматриваемое в качестве значения и не требующее выполнения (литерал). | 'print |
block! |
Блок слов программы. | [red green blue] |
integer! |
Целое число. | 1234 |
float! |
Дробное число. | 1.234 |
binary! |
Байтовая строка произвольной длины. | #{ab12345c} |
string! |
Строка. Если строка содержит переносы, кавычки, табуляцию, то она заключается в фигурные скобки {}. |
"Hello world!" |
char! |
Символ. | #"C" |
logic! |
Булевское значение. | true |
time! |
Время. | 12:05:34 |
date! |
Дата. | 07-November-2017 |
tuple! |
Номер версии, значение цвета RGB, сетевой адрес. Должен содержать как минимум три значения, разделенных точками. |
255.255.0.0 |
pair! |
Пара значений для координат, размеров. | 100x200 |
file! |
Название файла, включая путь. | %red.exe |
Слова
Слова в Red должны удовлетворять следующим требованиям:
- Могут включать в себя буквы, цифры и следующие символы:
? ! . ' + - * & | = _ ~ - Не могут содержать символы:
@ # $ % ^ , - Не могут начинаться с цифры или быть составлены таким образом, что могут быть интерпретированы как числа.
Слова не чувствительны к регистру и не имеют ограничений по длине.
Слова могут быть записаны четырьмя способами, от чего зависит их интерпретация:
| Формат | Комментарий |
|---|---|
word |
Возврат значения, которое содержит слово. Если слово содержит функцию, то функция выполняется. |
word: |
Присвоение слову нового значения. |
:word |
Получение значения слова без его выполнения. |
'word |
Рассмотрение слова как символа, без его выполнения. Слово само рассматривается в качестве значения. |
Присвоение значений (создание переменных)
Двоеточие после слова (
:) используется для присвоения слову значения или ссылки на значение.Слову можно присвоить не только значения простых типов, но и более сложных – функций, блоков или блоков данных:
age: 33
birthday: 11-June-1984
town: "Moscow"
cars: ["Renault" "Peugeot" "Skoda"]
code: [if age > 32 [print town]]
output: function [item] [print item]Присвоить значение слову/словам можно также с помощью функции
set:set 'test 123
print test
; --> 123
set [a b] 123
print [a b]
; --> 123 123
Стоит обратить внимание, что при присваивании значения слову перед этим словом стоит одиночная кавычка, указывающая, что это слово – литерал, и оно не должно выполняться (имеет тип
word!). Но слова внутри блока не требуют кавычек, т.к. содержимое блока не выполняется без явного указания.Получение значений
Двоеточие перед словом (
:) используется для получения значения слова без его выполнения.Сказанное можно проиллюстрировать следующим примером:
печать: :print
печать "test"
; --> test
В примере содержимое переменной
print – функции печати – присваивается переменной печать без выполнения данной функции. Таким образом обе переменные print и печать содержат одинаковое значение и это значение – функция печати.Получить значение слова можно также с помощью функции
get:печать: get 'print
печать "test"
; --> test
Литералы
Литералы представляют собой слова Red, рассматриваемые в качестве значений, и имеют тип
word!Литералы можно задать двумя способами: указанием одиночной кавычки перед словом (
') или размещением слова внутри блока.word: 'this
print word
; --> this
word: first [this and that]
print word
; --> this
Рассмотренные выше функции
set и get требуют литералы в качестве своих аргументов.Пути
Пути представляют собой набор значений, разделяемых прямым слешем (
/). Значения в составе пути называются уточнениями (refinements). Пути используются для навигации и поиска.В зависимости от контекста, пути могут быть использованы для разнообразных целей:
| Russia/MO/Podolsk/size | Выбор значения из блока. |
| names/12 | Выбор значения из строки по заданной позиции. |
| account/balance | Доступ к функции в составе объекта. |
| sort/skip | Уточнение действия функции. |
Выполнение выражений
Приоритетность выполнения операций в Red отсутствует, и они по умолчанию выполняются слева направо. Если в выражении операторы смешаны с функциями, то сначала выполняются операторы, а затем функции. Для определения иного порядка выполнения операций используются круглые скобки.
print 5 + 4 * 3
; --> 27
print absolute -3 + 5
; --> 2
print 5 + (4 * 3)
; --> 17
print (absolute -3) + 5
; --> 8
Для выполнения блока используется функция
do. Особенность функции do состоит в том, что она возвращает только последнее вычисленное значение:do [1 + 2]
; --> 3
do [
1 + 2
3 + 4
]
; --> 7
Для того, чтобы вернуть результаты всех выражений, входящих в блок, используется функция
reduce. Эта функция вычисляет каждое выражение, входящее в блок, и помещает результат вычисления в новый блок:reduce [
1 + 2
3 + 4
]
; --> [3 7]
Функции управления выполнением
Условные операторы
Функция
if имеет два аргумента – логическое выражение и блок кода. Если логическое выражение имеет значение true, то блок кода выполняется. Если логическое выражение имеет значения false или none, то блок не выполняется, и функция возвращает none.a: -2
if a < 0 [print "a - отрицательное число"]
; --> a - отрицательное число
print if a < 0 ["a - отрицательное число"]
; --> a - отрицательное число
Функция
either похожа на функцию if с тем отличием, что имеет дополнительный третий аргумент – блок кода, который выполняется в случае, если логическое выражение не соблюдается (т.е. имеет значение false или none).b: 3
either b < 0 [
print "b - отрицательное число"
][
print "b – не отрицательное число"
]
; --> b – не отрицательное число
Функция
any принимает на вход блок кода и последовательно выполняет входящие в его состав выражения до тех пор, пока не встретит выражение со значением, отличным от false или none. В этом случае работа функции any завершается, и она возвращает найденное значение. В противном случае функция возвращает значение none.size: 40
if any [size < 20 size > 80] [
print "Значение вне рамок диапазона"
]
; --> Значение вне рамок диапазона
Функция
all принимает на вход блок кода и последовательно выполняет входящие в его состав выражения до тех пор, пока не встретит выражение со значениями false или none. В этом случае работа функции all завершается, и она возвращает значение none. В противном случае функция возвращает значение последнего выражения.size: 40
if all [size > 20 size < 80] [print "Значение в рамках диапазона"]
; --> Значение в рамках диапазонаУсловные циклы
Функция
while имеет два аргумента в виде блоков кода, циклически выполняя их до тех пор, пока первый блок возвращает значение true. Если первый блок возвращает значение false или none, второй блок не выполняется и осуществляется выход из цикла.a: 1
while [a < 3][
print a
a: a + 1
]
; --> 1
; --> 2
Функция
until имеет один аргумент в виде блока кода, циклически выполняя его до тех пор, пока блок не вернет значение true. Блок кода выполняется, как минимум один раз.a: 1
until [
print a
a: a + 1
a = 3
]
; --> 1
; --> 2
Циклы
Функция
loop циклически выполняет блок кода заданное число раз, возвращая последнее вычисленное значение.i: 0
print loop 20 [i: i + 20]
; --> 400
Функция
repeat циклически выполняет блок кода заданное число раз, возвращая последнее вычисленное значение. В отличии от функции loop ее первый аргумент служит для контроля за ходом выполнения цикла.i: 0
print repeat k 10 [i: i + k]
; --> 55
Функция
foreach позволяет выполнить блок выражений для каждого из элементов заданной серии, предоставляя доступ к каждому из этих элементов.colors: [red green blue]
foreach color colors [print color]
; --> red
; --> green
; --> blue
Функция
forall позволяет выполнить блок выражений для каждого из элементов заданной серии, изменяя значение позиции в пределах этой серии.colors: [red green blue]
forall colors [print first colors]
; --> red
; --> green
; --> blue
Функция
forever позволяет организовать бесконечный цикл. Выход из такого цикла может быть осуществлен при помощи функции break.a: 1
forever [
a: a * a + 1
if a > 10 [print a break]
]
; --> 26
Прерывание цикла
Функция
continue позволяет прервать выполнение текущей итерации цикла и перейти к следующей итерации.repeat count 5 [
if count = 3 [continue]
print ["Итерация" count]
]
; --> Итерация 1
; --> Итерация 2
; --> Итерация 4
; --> Итерация 5
Функция
break позволяет выйти из цикла.repeat count 5 [
if count = 3 [break]
print ["Итерация" count]
]
; --> Итерация 1
; --> Итерация 2
Выборочное выполнение
Функция
switch выполняет первый из блоков, соотнесенный с заданным значением. Функция возвращает значение блока, который был выполнен, или none в обратном случае. Функция также позволяет использовать множество значений для сопоставления.switch 1 [
0 [print "Ноль"]
1 [print "Единица"]
]
; --> Единица
num: 7
switch num [
0 2 4 6 8 [print "Четное число"]
1 3 5 7 9 [print "Нечетное число"]
]
; --> Нечетное число
Функция
case выполняет первый из блоков, для которого выполняется соотнесенное с ним условие. Функция возвращает значение блока, который был выполнен, или none в обратном случае.a: 2
case [
a = 0 [print "Ноль"]
a < 0 [print "Отрицательное число"]
a > 0 [print "Положительное число"]
]
; --> Положительное число
Команды ввода/вывода
Функция
print позволяет вывести на экран заданное значение. Если значение является блоком, то перед выводом к нему негласно применяется функция reduce.print 1234
; --> 1234
print [2 + 3 6 / 2]
; --> 5 3
Функция
prin практически идентична print за тем исключением, что после вывода значения не выполняется перенос на новую строку. Увидеть различие в работе можно при выводе в терминал, но не в консоль.prin "Александр "
prin "Невский"
; --> Александр Невский
Функция
probe позволяет вывести на экран заданное значение, которое перед выводом преобразуется в строку кода Red.colors: [red green blue]
probe colors
; --> [red green blue]
Функция
input позволяет осуществить ввод значения.prin "Введите ваше имя: "
name: input
print ["Здравствуйте," name]
; --> Здравствуйте, Антон
Работа с сериями
Серии представляют собой набор значений, упорядоченных в определенном порядке. Большое число типов Red, таких как блоки, строки, пути и т.д., представляют собой серии.
В общем виде серия выглядит следующим образом:

- голова (head) – первая позиция в серии.
- хвост (tail) – позиция, идущая вслед за последним элементом серии.
- позиция – текущая позиция.
По умолчанию, текущая позиция устанавливается на первый элемент в серии.
colors: [red green blue]
print first colors
; --> red
Извлечение значений
Для извлечения значений из серии относительно текущей позиции служат следующие порядковые функции:
first– значение текущей позиции.second– значение второй позиции относительно текущей.third– значение третьей позиции относительно текущей.fourth– значение четвертой позиции относительно текущей.fifth– значение пятой позиции относительно текущей.last– значение последней позиции в серии.
colors: [red green blue yellow cyan black]
print first colors
; --> red
print third colors
; --> blue
print fifth colors
; --> cyan
print last colors
; --> black
Для извлечения значения по номеру позиции можно использовать пути или функцию
pick.print colors/3
; --> blue
print pick colors 3
; --> blue
Изменение позиции
Для смещения текущей позиции на одну позицию вперед служит функция
next. Для изменения текущей позиции требуется изменить значение переменной, ссылающейся на серию.values: [1 2 3]
print next values
; --> 2 3
print first values
; --> 1
values: next values
print first values
; --> 2
Для смещение текущей позиции на одну позицию назад служит функция
back.values: back values
; --> [1 2 3]
print first values
; --> 1
Для смещения сразу на несколько позиций служит функция
skip. В случае, если смещение имеет положительное значение, то осуществляется смещение вперед, а если отрицательное – назад.values: [1 2 3]
probe values: skip values 2
; --> [3]
probe values: skip values -2
; --> [1 2 3]
Для смещения непосредственно в голову или на хвост серии служат функции
head и tail соответственно (стоит напомнить, что хвостом серии служит позиция, идущая вслед за последним элементом серии).values: [1 2 3]
probe values: tail values
; --> []
probe values: head values
; --> [1 2 3]
Вставка и добавление значений в серии
Для вставки одного или нескольких значений в серию используется функция
insert. Значение вставляется на место текущей позиции, при этом текущая позиция не изменяется.colors: [green blue]
insert colors 'red
probe colors
; --> [red green blue]
С помощью функции
insert можно осуществлять вставку в произвольное место серии и вставку нескольких значений.colors: [green blue]
insert next colors 'red
probe colors
; --> [green red blue]
insert colors [silver black]
probe colors
; --> [silver black green red blue]
Работа функции
append схожа с работой функции insert с тем отличием, что новое значение или значения всегда добавляются в конец серии.colors: [green blue]
append colors 'red
probe colors
; --> [green blue red]
Удаление значений из серий
Для удаления одного или нескольких значений серии используется функция
remove. Удаляется значение, на которое указывает текущая позиция.colors: [red green blue yellow cyan black]
remove colors
probe colors
; --> [green blue yellow cyan black]
Функция
clear позволяет удалить все значения серии, начиная с текущей позиции и до ее хвоста. При помощи функции clear также можно легко очистить всю серию.colors: [red green blue yellow cyan black]
clear skip colors 3
probe colors
; --> [red green blue]
clear colors
probe colors
; --> []
Изменение значений серий
Для изменения одного или нескольких значений серии используется функция
change:colors: [red green blue]
change next colors 'yellow
probe colors
; --> [red yellow blue]
Работа функции
poke схожа с работой функции change с тем отличием, что она позволяет явно указать номер позиции относительно текущей, значение которой будет изменено.colors: [red green blue]
poke colors 2 'yellow
probe colors
; --> [red yellow blue]
Функция
replace позволяет изменить первое значение в серии, совпадающее с заданным.colors: [red green blue green]
replace colors 'green 2
; --> [red 2 blue green]
Создание и копирование серий
Функция
copy позволяет создать новую серию путем копирования существующей. Копирование также важно в случае использования функций, модифицирующих исходную серию, и при желании сохранить исходную серию неизменной.str: copy "Копируемая строка"
new-str: copy str
blk: copy [1 2 3 4]
str2: uppercase copy "Копируемая строка"
Используя уточнение
/part, с помощью функции copy можно скопировать часть серии. В этом случае в качестве аргумента указывается либо число копируемых значений, либо конечная позиция, до которой осуществляется копирование.colors: [red green blue yellow]
sub-colors: copy/part next colors 2
probe sub-colors
; --> [green blue]
probe copy/part colors next colors
; --> [red]
probe copy/part colors back tail colors
; --> [red green blue]
Поиск в сериях
Функция
find используется для поиска в серии заданного значения. В случае удачного поиска, функция возвращает позицию, на которой расположено найденное значение. В случае, если заданное значение в серии найдено не было, функция возвращает none.a: [1 2 3 4 5]
probe find a 2
; --> [2 3 4 5]
probe find a 7
; --> none
Функция
find имеет ряд уточнений, позволяющих осуществить более сложный поиск.Также для поиска может быть полезна функция
select. Ее работа похожа на работу функции find с тем отличием, что она возвращает не подсерию, а единственное значение серии, следующий за найденным. Это позволяет организовать поиск элементов по сопоставленным с ними значениями.colors: [red green blue yellow]
print select colors 'green
; --> blue
colors: [
1 red
2 green
3 blue
4 yellow
]
print select colors 2
; --> green
Сортировка серий
Функция
sort позволяет быстро и легко сортировать серии. Она особенно полезна при сортировке блоков данных, но может также использоваться и для сортировки символов в строке.names: [Иван Андрей Максим Юрий Вячеслав Дмитрий]
probe sort names
; --> [Андрей Вячеслав Дмитрий Иван Максим Юрий]
print sort [22.8 18 132 57 12 64.9 85]
; --> 12 18 22.8 57 64.9 85 132
print sort "валидация"
; --> аавдиилця
Функция
sort непосредственно изменяет значение серии, к которой она применяется. Для того, чтобы сохранить исходную серию неизменной, функцию sort стоит использовать совместно с функцией copy:probe sort copy names
По умолчанию сортировка осуществляется по возрастанию. Для изменения направления сортировки используется уточнение
/reverse:print sort/reverse [22.8 18 132 57 12 64.9 85]
; --> 132 85 64.9 57 22.8 18 12
В случае, если требуется отсортировать серию, каждая запись которой состоит из нескольких полей, то следует использовать уточнение
/skip совместно с аргументом, задающим длину каждой записи. По умолчанию сортировка осуществляется по первому значению записи.colors: [
3 red
4 green
2 blue
1 yellow
]
probe sort/skip colors 2
; --> [
; --> 1 yellow
; --> 2 blue
; --> 3 red
; --> 4 green
; --> ]
Функция
sort также имеет ряд уточнений, позволяющих организовать более сложную сортировку.Работа с блоками
Блоки могут содержать в своем составе другие блоки. Вне зависимости от того, сколько значений содержит вложенный блок, он рассматривается как одно значение для внешнего блока. Это определяет правила обращения к значениям блоков для их извлечения.
values: [
123 ["one" "two"]
%file1.red ["test1" ["test2" %file2.txt]]
]
print length? values
4
Массивы
Для реализации массивов используются блоки.
arr: [
[1 2 3 ]
[10 20 30 ]
[a b c ]
]
probe arr/1
; --> [1 2 3]
probe arr/2/2
; --> 20
arr/1/2: 5
probe arr/1
; --> [1 5 3]
arr/2/3: arr/2/2 + arr/2/3
probe arr/2/3
; --> 50
Специальных функций для работы с массивами в Red (пока) нет, однако возможности Red позволяют воспроизвести такую функциональность. В частности, для создания и инициализации массива можно использовать следующий код:
block: copy []
repeat n 5 [append block n]
probe block
; --> [1 2 3 4 5]
Такой подход не требует накладывать ограничения на размер массивов, делая их динамическими.
Создание блоков
Для создания блоков на основе динамических значений используется функция
compose. В качестве аргумента функции выступает блок, содержащий данные, на основании которых создается новый блок. Выражения в круглых скобках выполняются до того, как новый блок будет создан.probe compose [(1 + 2) 3 4]
; --> [3 3 4]
probe compose ["Текущее время" (now/time)]
; --> ["Текущее время" 13:28:10]
Функции
В Red существует несколько видов функций:
- Нативные (Native) – функции, вычисляемые непосредственно процессором.
- Пользовательские – функции, определяемые пользователем.
- Мезанин-функции (Mezzanine) – функции, являющиеся частью языка, однако не относящиеся к числу нативных.
- Операторы – функции, используемые как инфиксные операторы (например, +, –, * и /)
- Рутины (Routine) – функции, используемые для вызова функций внешних библиотек.
Выполнение функций
Исходя из особенностей синтаксиса Red, важно учитывать порядок выполнения функций и ее аргументов, который является следующим: сначала рассчитываются значения аргументов функции, которые затем подставляются в функцию, после чего осуществляется выполнение функции. При этом расчет аргументов функции выполняется слева направо, т.е. сначала рассчитывается первый аргумент функции, затем второй и т.д. В то же время аргумент функции сам может являться функцией, поэтому допустимы и широко используются выражения следующего вида:
colors: [red green blue]
insert tail insert colors 'yellow 'black
probe colors
; --> [yellow red green blue black]
Уточнения
Уточнения позволяют внести коррективы в стандартное выполнение функции, к которой они применяются. Уточнения также позволяют задать дополнительные аргументы.
Возможно одновременное использование нескольких уточнений для одной функции. Если они требуют дополнительных аргументов, то порядок аргументов определяется порядком записи уточнений, к которым они относятся.
blk: [1 2 3 4 5]
insert/part/dup blk [6 7 8 9] 2 3
probe blk
; --> [6 7 6 7 6 7 1 2 3 4 5]
blk: [1 2 3 4 5]
insert/dup/part blk [6 7 8 9] 2 3
probe blk
; --> [6 7 8 6 7 8 1 2 3 4 5]
Определение функций
Простую пользовательскую функцию, не требующую аргументов, можно создать с помощью функции
does. Вызов функции по заданному имени вызывает ее выполнение.print-time: does [print now/time]
print-time
; --> 13:18:13
Если пользовательская функция требует аргументы, то ее можно определить с помощью функции
func, которая в свою очередь имеет два аргумента:func spec body
Первый аргумент представляет собой блок, который определяет интерфейс к функции и содержит описание функции, ее аргументы, типы аргументов, описание аргументов. Второй блок представляет собой непосредственно блок, который выполняется при вызове функции.
Использование функций можно показать на примере расчета среднего значения:
average: func [
arg1 arg2
][
sum: arg1 + arg2
sum / 2
]
В приведенном примере сначала определяется пользовательская функция
average, имеющая два аргумента, задаваемых в первом блоке. Во втором блоке задается тело функции. По умолчанию функция возвращает последнее вычисленное в ее теле значение.В дальнейшем функция может быть вызвана по имени с указанием ее аргументов.
print average 8 14
; --> 11
Стоит обратить внимание, что в приведенном примере переменная
sum, определенная в теле функции, по умолчанию становится глобальной и ее значение доступно за пределами функции. Для того, чтобы переменная оставалась локальной, она должна быть описана в блоке, определяющем аргументы функции, с уточнением /local. После уточнения /local можно указать целый список переменных, объявляемых локальными:evaluation: func [
arg1 arg2
/local sum length depth
][
; ... тело функции
]
Пользовательская функция также может быть определена с помощью функции
function, которая идентична функции func с тем отличием, что все переменные, определенные в ее теле, по умолчанию являются локальными. Таким образом, при работе с функцией function не требуется предварительно объявлять локальные переменные с уточнением /local.Выход из функций и возврат значений
По умолчанию пользовательская функция возвращает последнее вычисленное в ее теле значение. С помощью функции
return можно прервать выполнение пользовательской функции в заданной точке и вернуть значение.iteration: func [i][
repeat count i [if count = 5 [return count]]
none
]
print iteration 3
; --> none
print iteration 7
; --> 5
Для прерывания выполнения пользовательской функции в заданной точке без возврата значения используется функция
exit.iteration: func [i][
repeat count i [if count > 5 [print "Stop!" exit]]
none
]
print iteration 7
; --> Stop!
Объекты
Объекты объединяют значения в едином контексте. Объекты могут включать простые значения, серии, функции и другие объекты.
Создание объектов
Новые объекты создаются с помощью функции
make, имеющей следующий формат:new-object: make parent-object new-values
Здесь
new-object – имя создаваемого нового объекта.Первый аргумент функции,
parent-object, является родительским объектом, на основании которого создается новый объект. Когда родительского объекта нет, как в случае создания первого объекта заданного типа, то тогда в его качестве указывается тип данных object!new-object: make object! new-values
Второй аргумент функции,
new-values, представляет собой блок, который определяет дополнительные переменные и их инициализирующие значения. При создании объекта данный блок выполняется, поэтому может содержать любые выражения для вычисления значений переменных.Переменные в рамках объекта могут ссылаться в том числе и на функции, определяемые в контексте объекта. Такие функции могут обращаться к другим переменным объекта напрямую, без использования путей.
example: make object! [
var1: 10
var2: var1 + 10
F: func [val][
var1: val
var2: val + 20
]
]
После того, как объект будет создан, он может служить прототипом для создания новых объектов. При этом новые объекты будут являться клонами первого объекта, для переменных которых можно задать собственные значения:
example2: make example []
example3: make example [
var1: 30
var2: var1 + 15
]
Объект, создаваемый на основе другого объекта, можно расширить, добавив в него новые переменные:
example4: make example [
var3: now/date
var4: "Депозит"
]
Доступ к объектам
Доступ к переменным объекта осуществляется с помощью указания путей к ним. Используя пути, можно изменить переменные объекта или выполнить инкапсулированные в него функции:
example/var1: 37
print example/var1
; --> 37
example/F 100
print example/var2
; --> 120
Доступ к переменным объекта также можно получить с помощью функции
in, которая извлекает соответствующее слово из контекста объекта. Далее с помощью функции set можно задать значение выбранной переменной, а с помощью функции get – получить это значение:print in example 'var1
; --> var1
set in example 'var1 52
print get in example 'var1
; --> 52
Полезные ссылки:
Официальная страница
Полный список функций Red с примерами
Сообщество
Комментарии (158)

DoctorMoriarty
13.03.2018 17:11Эта выразительность подкрепляется результатами соответствующего исследования, которые я привел в самом начале статьи и даже график привел.
1) Зачем тогда эта статья, если наиболее значимая по смыслу её часть, эээ, располагается по ссылке в начале?
2) Красивый график совершенно не информативен.DVL333 Автор
13.03.2018 17:18Эта статья является пособием по языку Red! А не исследованием о выразительности…
Извините, не вижу смысла с вами далее дискутировать, если первый вопрос вы задали не прочитав далее первого абзаца, а второй — не прочитав дальше второго абзаца.
Shtucer
13.03.2018 17:51+4А я прочитал дальше второго абзаца, но так и не понял, в чём заключается "потрясающая выразительность, позволяя решать сложные задачи простыми способами".
DVL333 Автор
13.03.2018 17:56-1«Выразительность языка программирования» — это принятый термин. Т.е. чем меньше кода требуется для реализации вашей идеи, тем более выразителен язык. Соответственно, сложные вещи делаются более просто. :)
Shtucer
13.03.2018 18:05+1Типа так?
Картинка про Python
DVL333 Автор
13.03.2018 18:13-1Эта статья — пособие по языку Red. Если вам так интересна методология проведения исследования, на которое я сослался — прочитайте это исследование и как оно проводилось.
DoctorMoriarty
13.03.2018 18:40прочитайте это исследование и как оно проводилось
Исследование-то мы почитаем, а вот ваше «пособие» — что вы им сказать-то хотели?
Gentlee
13.03.2018 19:10То есть Objective-C более выразителен чем JS? :) Кода на JS требуется в 5 раз меньше для одних и тех же действий. Полный бред.

0xd34df00d
13.03.2018 20:18+1Зависимые типы есть?
9214
14.03.2018 14:23Встроенных нет, но их можно прикрутить за один вечер.
0xd34df00d
14.03.2018 17:35Вкрученные относительно гигиеническими макросами ассерты — это не зависимые типы.
9214
14.03.2018 17:54Где ты тут макросы увидел?
0xd34df00d
14.03.2018 18:08В районе определения
afunc, конкретнее в
insert body compose/deep [ assert [(word) (symbol) (val)] ]9214
14.03.2018 18:16Это не совсем макрос (по крайней мере в определении языка), а механизм подстановки значений (интерполяция?) — выражения в скобках вычисляются и заменяются на возвращаемый результат.
Но в целом, да, согласен что мой пример некорректный. Зависимых типов нету. Что-то конкретное о системе типов в Red сказать не могу, поскольку не силен в этом плане, но все значения в языке строго типизированы, однако на «переменные» это не распространяется. Если интересно, есть график с иерархией типов.0xd34df00d
14.03.2018 18:22Я скорее про макрос в смысле какого-нибудь лиспа, когда вы на уровне языка определяете изменения в теле порождаемой функции (вот это вот, как я понимаю,
insert body).9214
14.03.2018 19:40А, нет,
insertэто просто функция вставки элемента по текущему индексу серии (общее название для спископодобных типов данных, строки там, [блоки], (скобочки), #{бинарные данные} и т.д.
Фишка в том, что блок это просто кусок кода, поэтому подобные функции для работы с сериями можно применять для его (кода) генерации и модификации. К примеру:
>> block: []
== []
>> append block 6
== [6]
>> head insert block [7 *]
== [7 * 6]
>> do block
== 42
0xd34df00d
14.03.2018 21:40Фишка в том, что блок это просто кусок кода, поэтому подобные функции для работы с сериями можно применять для его (кода) генерации и модификации.
Ну точно ж лисп :)
ToshiruWang
15.03.2018 13:57Простой способ — разместить кнопку на view, сложная задача — понять где эта кнопка появится и что с ней можно сделать (кроме вывода простой фразы в непонятном месте). Хочется выразительно выражаться от таких примеров, 10 PRINT «HW!» столь же содержателен.
DVL333 Автор
15.03.2018 15:02Нет, не так.
Создавая кнопки при помощи View (графическая система Red), вы всегда руками прописываете их координаты и вручную определяете действия.
Но существует еще диалект VID, который вы видимо и имеете в виду, который является "надстройкой" над View, позволяющий облегчить конструирование интерфейса за счет некоторых правил, принятых по умолчанию. Так, добавляемые с помощью VID элементы интерфейса, если не задавать их координаты вручную, будут отображаться друг за другом в ряд. А при нажатии на кнопку по умолчанию будет обрабатываться событие on-click (можно обработать любое событие, но это надо будет указать отдельно).
Просто сейчас имеется проблема в недостатке документации, отчасти решить которую как раз и была нацелена эта статья. Причем специально не касался построения интерфейса — это отдельная и серьезная тема. После более глубокого ознакомления с VID, думаю, вы бы скорректировали свое мнение.
DoctorMoriarty
13.03.2018 18:37первый вопрос вы задали не прочитав далее первого абзаца, а второй — не прочитав дальше второго абзаца
Будьте уверены, я взял на себя труд осилить весь текст.
пособие по языку Red
Вы это серьезно? Пособие?! Вот K&R — это пособие. «Программирование. Принципы и практика с использованием С++» Страуструпа — пособие. «Java How To Program (Early Objects)» Дейтелов — пособие. А у вас — ни разу не пособие, у вас — обзорный справочник в духе заметки из энциклопедического словаря.
TargetSan
13.03.2018 17:39+2К сожалению, пока выглядит как помесь Bash и Forth.
Какие проблемы он решает? Почему стоит его изучать?DVL333 Автор
13.03.2018 17:52Навскидку:
1) Red — компилируемый (!) язык полного стека, позволяющий создавать нативные кроссплатформенные приложения, начиная с драйверов и заканчивая DSL.
2) «Человеческий» синтаксис.
3) Высокая выразительность.
4) Простота использования.TargetSan
13.03.2018 18:11+1Как вам сказать, вы назвали его свойства. Но не решаемые им проблемы.
Например, тот же пример "калькулятор" показывает степень развитости стандартной библиотеки. Круто. Но питон, к примеру, тоже в этом плане много чего умеет.
Не могли бы вы добавить ссылки на примеры с реализацией логики? Например, простейший word count, но без магических функций. Или минимальный эхо-сервер.DVL333 Автор
13.03.2018 18:21Согласно вашей логике, такой же вопрос можно задать абсолютно по каждому языку программирования, включая ассемблер. Потому что все-все-все можно написать в машинных кодах. :)
В качестве примера программ на Red, могу привести вот такую вот ссылку:
redlcv.blogspot.ru
Собственно, это библиотека машинного зрения, написанная на Red.TargetSan
13.03.2018 18:37Я не совсем понял, откуда вы взяли про ассемблер.
Повторюсь, можно ли где-то посмотреть более простые примеры?
Я уже увидел, что язык (а, точнее, его стандартные "батарейки") умеет "варить кофе". А хотелось бы увидеть, с каких элементарных блоков стоило бы начать, если мне нужно будет сделать что-то, чего в "батарейки" не положили.DVL333 Автор
13.03.2018 18:57Например, можно посмотреть примеры кода вот здесь:
github.com/red/community
9214
14.03.2018 19:50Я бы сказал что это гибрид Лиспа и Форта на спидах. Изучить стоит если вы интересуетесь языково-ориентированным / мета- / символьным программированием, созданием проблемно-ориентированных языков.
Есть зачатки реактивного программирования, так же присутствует куча встроенных DSL: Red/System для системного программирования, VID для создания GUI-ёв в декларативном стиле, Logo-подобный язык для рисования графических примитивов (Draw), встроенный TDPL парсер. Всё это и многое другое впихано в 1 мегабайт.
Для практических задач Red пока довольно сложно применять, поскольку язык находится в альфа версии, но клепать всякие демки и прототипы одно удовольствие.
Klenov_s
13.03.2018 17:58-1А в исследовании выразительности не учитывали, что один китайский иероглиф заменяет целое слово? Давайте тогда лучше придумывать еще более выразительный ЯП на китайском. Ведь про удобство использования речь не идет совсем…
DVL333 Автор
13.03.2018 18:08Вы не правы, т.к. в исследовании сравнивали не длину кода программы, а число операторов и функций.
TargetSan
13.03.2018 18:16Мне откровенно непонятна применённая в исследовании метрика. Для меня мерять выразительность по проценту изменённых каждым коммитом строк всё равно что мерять продуктивность кол-вом строк написанных.
Как учитывается разница в предметной области каждого проекта?
Как учитывается общий уровень программистов, участвующих в проекте?
Как учитывается степень сложности проекта?DVL333 Автор
13.03.2018 18:29Давайте тогда еще более наглядно.
Есть такой язык Nim — тоже очень интересный, тоже вполне себе выразительный, и тоже активно развивается. Заходим в репозитории Red и Nim и смотрим число коммитов и количество изменений. Вычисляем средний размер коммита (а это как правило исправление какого-то бага) и сравниваем значения. Я в свое время сравнил — у Red получилось раз в 8 меньше. Думаю, вполне наглядно.TargetSan
13.03.2018 18:39И? Есть APL, K в которых этот показатель ещё ниже. Поймите, выразительность не есть абсолют. Выразительность хороша, когда её результат понятен людям и выражен знакомыми им идиомами.
DVL333 Автор
13.03.2018 18:48Ну вот смотрите:
1) Nim и Red — одна предметная область: активное создание языка программирования и одна и та же проблема — наличие бага.
2) В одном случае это чинится с помощью 40 строк. В другом — с помощью 300.
И что вам тут не понятно? Куда уж нагляднее.Desprit
13.03.2018 19:00+1Странное сравнение.
Мой коллега разбивает задачу на десяток подзадач и делает коммиты после исправление каждой из них. Я же имею привычку делать один коммит когда сделана вся задача. Коллега пишет на php, а я на python. Значит ли это, что php более выразителен, чем python?DVL333 Автор
13.03.2018 19:18Во-первых, над каждым языком «колдует» несколько человек. Поэтому речь идет не об отклонении поведения отдельного программиста, а о среднем значении. И, как ни странно, это согласуется с результатом исследования. «Случайность? Не думаю». :)
Ну и во-вторых, фиксить баги частями, в рамках нескольких коммитов, как-то странно. Думаю, здесь нельзя проводить параллели.

YemSalat
14.03.2018 20:49С другими языками сравнивали? Или делаете свои заключения исключительно из выборки в количестве двух экземпляров?
Klenov_s
13.03.2018 20:17Вам явно плохо знакомо слово сарказм. В моем комментарии речь о том, что малое количество операторов и функций в данном случае превращается не в выразительность, а скорее в косноязычность. Читать такой «выразительный» код ужасно. Немного иносказательно, но именно об этом ))
DVL333 Автор
13.03.2018 22:33Мне прекрасно известно понятие слова сарказм. Зато вы провели откровенно плохую параллель с китайским языком, потому что его «краткость» обусловлена не емкостью его лексем, а краткостью записи иероглифов. На что я вам и указал.
Я не уверен, что у вас есть достаточно знания и опыта работы с Red, чтобы утверждать, что он косноязычный и нечитаемый. Получается из серии «Не читал, но осуждаю». :)

SADKO
13.03.2018 18:12+1Не народ, язык прикольный в смысле компактности по крайней мере…
… вот для примера игра пятнашки
view/tight [
title "Tile game"
style piece: button 60x60 font-size 12 bold [
delta: absolute face/offset - empty/offset
if delta/x + delta/y > 90 [exit]
pos: face/offset face/offset: empty/offset empty/offset: pos
]
piece "1" piece "2" piece "3" piece "4" return
piece "5" piece "6" piece "7" piece "8" return
piece "9" piece "10" piece "11" piece "12" return
piece "13" piece "14" piece "15" empty: piece ""
]

DsideSPb
13.03.2018 18:25+2Автор исследования о выразительности сам указывает на важную деталь:
It won’t tell you how readable the resulting code is (Hello, lambda functions) or how long it takes to write it (APL anyone?), so it’s not a measure of maintainability or productivity.
Т. е. рассматривается выразительность не для людей, а для машин.
И это наверняка расходится с пониманием слова "выразительность" (без дополнительных пояснений) у многих читателей. Тут напрашивается цитата мсье Фаулера о том, что "хорошие программисты пишут программы, понятные людям".
DVL333 Автор
13.03.2018 18:39Все верно. Но здесь указано, что в исследовании учитывалось одно качество, но не принимались в расчет другие, а вовсе не то, что эти другие качества попросту отсутствуют.
Для меня показателем является хотя бы то, что сам Red пишется на REBOL. И делают это всего 2-3 человека. Сравнить хотя бы с тем же Nim, который я упомянул выше, который пишут в несколько раз большее число людей, а создается он раза в два дольше.
kez
13.03.2018 23:42Программистам в среднем не важно, насколько их код будет выразителен для машины, поэтому это исследование — немного странный аргумент в пользу языка.
DVL333 Автор
13.03.2018 23:48Выразительность касается как раз таки людей, количества кода, который они пишут, а не к машинам! Просто комментатор выше указал на то, что в исследовании не рассматривались такие критерии, как поддерживаемость и продуктивность программирования на языке, с чем я согласился и указал на то, что одно другому не противоречит.
Вы делаете какие-то странные выводы, непонятно откуда берущиеся.DsideSPb
14.03.2018 20:38Для этой метрики просто выбрано очень неподходящее название.
Что качественный перевод (ха-ха) успешно сохранил.
Технически эта «выразительность» определена, придраться не к чему, но как можете заметить из комментариев, это значение слабо стыкуется с интуитивным пониманием у большинства читателей.
Для меня, например, «выразительность языка программирования» в интуитивном представлении это насколько легко программный код выражает человеку, что он делает. И в этом значении она влияет на поддерживаемость кода напрямую: высокий показатель означает, что код легко читать (писать… уже не факт).
В комментариях к исследованию, например, один из читателей предложил вариант немножко получше: conciseness. Даже у него есть тот же оттенок «коротко и ясно», а «ясно» метрика вовсе не предполагает. Но оно, скажем так, «менее неподходящее».DVL333 Автор
14.03.2018 22:33Проблема в том, что понятие «выразительность» — это не недостаток отдельной статьи, а это общепринятый термин. И я был свято убежден, что на сайте подобной направленности посетители будут в курсе подобной терминологией. Вот, посмотрите в Вики:
Выразительность языков программирования
Но по факту вы конечно же правы — глядя на комментарии вижу, что надо было дать расшифровку.DsideSPb
15.03.2018 00:41В Вики нет определения, источник термина не указан, в аналогичной статье на английском этого термина нет вовсе. Самое близкое, что есть, это expressive power, но она с исследуемой метрикой не имеет ничего общего — она про представимость алгоритмов на языке, но не про длину представления (полагая конечные длины, разумеется). Это что касается формальных и общепринятых определений.
Так что не вижу оснований не думать, что источник определения этой «выразительности» — само исследование. И я не пытаюсь придираться, и буду рад, если мне укажут на мою неправоту и приведут источники. Век учись и всё такое.
(PS: *подобной терминологии; всё, я заткнулся)
(PPS: надеюсь, я не кажусь едким из-за ссылок на XKCD, это непреднамеренно)DVL333 Автор
15.03.2018 01:25Вот как раз речь идет о «expressive power»:
https://en.wikipedia.org/wiki/Expressive_power_(computer_science)
В указанном определении сказано, что под этим термином в программировании чаще всего подразумевают лаконичность и простоту изложения идеи — «concisely and readily». Которая, как нетрудно догадаться, имеет следствием краткость кода.
Кроме того от себя добавлю, что про метрику «выразительность» я знал задолго до чтения статьи, о которой идет речь — и без нее на эту тему материалов хватает.DsideSPb
15.03.2018 01:46Неформальные определения открыты для интерпретации, поэтому я и ограничился формальными. Но если погружаться и туда, то код в конечном счёте пишут программисты, а объём их работы, как уже заметили другие господа в комментариях к этой статье, измеряется вовсе не в строчках кода — объём умственных усилий этому соответствует гораздо ближе.
Потому эта метрика и не имеет ничего общего с expressive power.
Вот. В общем, меня вы не убедили.
Краткость — следствие. Как и ясность. Которую приведённое исследование игнорирует и прямо об этом говорит.DVL333 Автор
15.03.2018 09:04«The design of languages and formalisms involves a trade-off between expressive power and analyzability. The more a formalism can express, the harder it becomes to understand what instances of the formalism say.» — это из статьи из Вики. Сопоставьте с тем, что вы утверждаете. ;)
Причем никто не опроверг, что в каком-либо языке компромисс между выразительностью и понятностью мог быть достигнут.
И вовсе не собирался вас переубеждать — это изначально бесполезное занятие по отношению к человеку, который занял определенную позицию и собирается на ней стоять.DsideSPb
15.03.2018 11:56Ну вот опять, [citation needed], интерпретация неформального определения каким-то случайным неуказанным человеком.
DVL333 Автор
15.03.2018 12:34«неформального определения»
Почему вы все время употребляете данное словосочетание? Это вы так фразу «Information description» умудрились перевести? :)
information!=informalDsideSPb
15.03.2018 13:13Вот почему:
The first sense dominates in areas of mathematics and logic that deal with the formal description of languages and their meaning, such as formal language theory, mathematical logic and process algebra.
In informal discussions, the term often refers to the second sense, or to both. This is often the case when discussing programming languages. Efforts have been made to formalize these informal uses of the term.
Ну и из-за отсутствия формального определения, разумеется.DVL333 Автор
15.03.2018 14:40This is often the case when discussing programming languages.
Т.е. когда речь идет о языке программирования, то имеется в виду как раз лаконичность и только она. Что же до отсутствия формального определения, то у понятия "компьютерный вирус" тоже нет формального определения, что вовсе не подразумевает использование данного термина для ПО, работа которого вам лично не нравится.
Ладно, дальнейшую дискуссию вижу бессмысленной: свои обоснования я привел и подкрепил ссылками, вы же свою позицию — авторское толкование термина — не удосужились. На том и закончим.
rraderio
14.03.2018 18:17сам Red пишется на REBOL
Почему еще не на самом Red?9214
14.03.2018 18:22Потому что мы ещё на фазе раскрутки компилятора (bootstrapping). После релиза 1.0 всё перепишут на Red и Red/System (низкоуровневый C-подобный DSL). Технически, ничего не мешает сделать это уже сейчас, но тогда надо будет реализовать и поддержку 64-х разрядных процессоров (Rebol2 поддерживает только 32-х битные, насколько я помню, Red, пока что, так же имеет это ограничение, поскольку компилятор написан на Rebol2).
DVL333 Автор
14.03.2018 18:26Банально еще не успели. Но это стоит в планах.
khim
15.03.2018 02:56В планах на какое столетие, извините? Вроде речь идёт о языке, которому 7 лет…
DVL333 Автор
15.03.2018 10:45Rust 5 лет делали при поддержке Mozilla.
Nim 14 лет уже делают, причем компилятор там взят сторонний.
Мне представляется, у вас какое-то неверное представление о процессе создания ЯП.khim
15.03.2018 17:52-1А мне представляется, что у вас какое-то неверное представление о «запуске» ЯП.
Разрабатывать «в стол» у себя дома ЯП вы можете сколько угодно. А вот когда вы о нём где-то заявили — у вас не так много времени на то, чтобы людей привлечь.
Иначе получаются долгострои типа Perl6, о которых много говорят, но никто не пользуется.
DoctorMoriarty
13.03.2018 20:35+1Скорее всего это Кэп — но три года назад была хорошая обзорная статья на Хабре про Red: habrahabr.ru/post/265685
Shtucer
13.03.2018 21:18И за три года прогресс языка как-то не впечатляет. Релиз 1.0, напомню, был запланирован на 2016 год. Но что-то с потрясающей выразительностью, позволяющей сложные задачи решать простыми способами, пошло не так.
DVL333 Автор
13.03.2018 22:54Да нет, как раз таки впечатляет. :) Релиз 1.0 предполагал в первую очередь поддержку нативного интерфейса всего под Android. В итоге же дорожная карта была скорректирована и появился нативный интерфейс под Windows и MacOS. Кроме того появилось реактивное программирование. Т.е. задержка вызвана просто количеством добавляемых новых «фич».
Shtucer
13.03.2018 23:10Очень много уже реализовано, поэтому я лучше опишу чего пока не хватает. Прямо сейчас мы завершаем поддержку кросс-платформенного GUI с первым бекендом для Windows. Бекенды для Android, Linux и OS X будут следующими. Ввод/вывод пока ограничен простыми файловыми операциями и HTTP-клиентом. Модульная компиляция, полноценный сборщик мусора и поддержка конкурентности — главные цели до релиза 1.0. Мы планируем выпустить 1.0 в 2016 году.
Мммм… ладно. Я не силён в истории Red. Но, нет, не впечатляет.
DVL333 Автор
13.03.2018 23:59В том интервью Ненад несколько приукрасил. :) В последующих он говорил, что начали как раз с Android, но потом переключились на Windows, причем поддержка GUI планировалась минимальной. Сейчас же она гораздо больше, чем планировалась изначально:
www.red-lang.org/2018/01/overview-of-red-development-history.html
9214
14.03.2018 15:48«Релиз 1.0 в 2016» у меня самого вызывал много вопросов, поэтому я лично попросил Ненада (главный разработчик) более подробно осветить историю разработки, выше DVL333 ссылку на этот рассказ уже привел.
В кратце, планы проекта постоянно менялись и подстраивались под рынок, потому что всегда стояла острая необходимость в финансировании (напомню, что Red начинался как проект одного энтузиаста).
Например, изначально графический движок должен был поддерживать только Win платформу, но затем нашли инвесторов, заинтересованных в нативных (и кроссплатформенных) гуях, поэтому решили выкатить backend для макОСи. Потом решили что Android тоже можно взять как целевую платформу, из этого прямым образом возникла необходимость в поддержке компилятором ARMов. Не так давно начали активно участвовать в блокчейнах и успешно профинансировали создание DSL для смарт-контрактов.
Всё это, бесспорно, выглядит сумбурно, но таковы реалии маленьких компаний и амбициозных проектов — без гроша в кармане ничего сделать не получится, не говоря уже об удовлетворении требований со стороны сообщества.YemSalat
14.03.2018 20:54Не так давно начали активно участвовать в блокчейнах и успешно профинансировали создание DSL для смарт-контрактов.
Уууу… С этого надо было начинать.
У них тоже «блокчейн» в приоритетах. Расходимся короче…9214
14.03.2018 20:55Ну, так и думал что не стоит об этом упоминать и кормить троллей. Удачной дороги!
YemSalat
14.03.2018 21:17+2Можете считать меня троллем или кем угодно, но я уже достаточно варюсь в сфере разработки по, и факт того что у инвесторов в голове основной приоритет — «блокчейн» — лично мне о многом говорит.
«Удачной дороги» логичнее пожелать вам.DVL333 Автор
14.03.2018 22:44Вы делаете явно поспешные выводы. Действительно, в дорожной карте языка недавно появилась разработка дополнительного DSL, ориентированного на блокчейн, но она вовсе не в главных приоритетах, как вы посчитали. Мне понятен ваш скепсис, потому что сам так думал до последнего времени, но сейчас пришлось скорректировать свое мнение. Ну просто примите это как факт — сами увидите. :)
9214
14.03.2018 21:50-1Тем же у кого к теме криптовалют и блокчейнов отторжения нету, я советую прочитать whitepaper, в котором описывается зачем это нужно проекту.
YemSalat
14.03.2018 21:59+2Зачем это нужно и без вайтпэйпера понятно — денег заработать (ясно дело не напрямую, это же — платформа..)
Просто когда создатели руководствуются текущим рынком, а не текущими проблемами разработки, то в голове, уже испытанной плачевным опытом всей этой фигни, начинают раздаваться тревожные звоночки.
Может вы правда больше меня знаете, а может у вас нет такого опыта просто. Время рассудит.
ПС
У меня предрассудков к самому блокчейну нет, есть только предрассудки по отношению к бизнесу, который ни с того ни с сего «влезает в блокчейн»9214
14.03.2018 22:07-1Просто когда создатели руководствуются текущим рынком, а не текущими проблемами разработки
Я, видимо, не совсем уточнил этот момент, но DSL для смарт-контрактов они делают именно для того, чтобы адресовать текущие проблемы в их (контрактов) разработке, что с безопасностью что с кросплатформенностью. Последнии посты в блоге разработчиков слегка проясняют все эти моменты.
Я понимаю что всех уже тошнит от этой темы, но как-то так. Мне кажется, для немэйнстримного языка поймать хайп-волну и получить огромное финансирование это маркетинговый ход на 5+.
А как что из этого всего получится — поживем и увидим, верно?
P.S. извините за тон, с резкой ноты начали :)YemSalat
14.03.2018 22:42Мне кажется, для немэйнстримного языка поймать хайп-волну и получить огромное финансирование это маркетинговый ход на 5+.
Наверное согласен, но у меня на пути было много гораздо менее впечатляющих проектов, которые тоже «сорвали волну блокчейна», будте осторожны.
Тем более что самих потенциальных разработчиков, скорее всего, будет как вы написали «тошнить от этой темы» (кстати, большинство текущих блокчейн проектов разрабатывается на Python, JS и Go — все эти языки и так кроссплатформерные)
P.S. извините за тон, с резкой ноты начали :)
Все ОК ;) Но вообще мне кажется лучше представлять свой проект со стороны того чем он может решать текущие проблемы, а не с рекламы странных метрик вроде «выразительности» (даже если у проекта есть перспективное финансирование)9214
14.03.2018 22:48По поводу рекламы — это к автору статьи. Само исследование проводилось в чёрт-его-знает каком году, и относится только к Rebol'у. Тащемта, автор тоже оседлал
хайпкликбэйт волну и пробился в топ обсуждаемых статей ;)
А так, язык интересный и развивающийся. Будет желание — заглядывайте на огонёк.
DVL333 Автор
13.03.2018 22:48Данная статья называется «Краткое пособие по языку Red». Т.е. не планировалась бы обзорной, тем более, что таковая здесь уже была.
Мне кажется, что более ценным является материал о самом языке, о его синтаксисе, нежели очередной общий обзор. Тем более, что (повторюсь), материалов по нему пока нет не только на русском, но и на английском языке тоже.
Ладно, как говорится, «Jedem das Seine». :)Shtucer
13.03.2018 23:16Данная статья называется "Самый выразительный." Т.е., как я понимаю, планировалось вызвать определённую реакцию. Успешно.
YemSalat
14.03.2018 23:25Данная статья называется «Краткое пособие по языку Red». Т.е. не планировалась бы обзорной
Logic, level 80

kovserg
13.03.2018 22:01а как на этом выразительном языке сделать функцию y: diff x
x: [ 1 2 1 ]
; y[i] = x[i+1] — x[i]
y: [ 1 -1 ]DVL333 Автор
13.03.2018 23:38x: [1 2 1]
forall x [if not tail? next x [append y:[] (second x) — (first x)]]
print y
DVL333 Автор
14.03.2018 00:28Еще так можно:
x: [1 2 1]
forall x [if not none? x/2 [append y:[] x/2 — x/1]]
print y
DVL333 Автор
14.03.2018 04:34Еще более простой и понятный вариант:
x: [1 2 1]
x: next x
forall x [append y: [] x/1 — x/-1]
print y
Кстати, напрямую этот код, как и вышеприведенные, в консоль копировать нельзя — при публикации комментария символ "-" в коде заменяется на длинный пробел, что приводит к ошибке при попытке выполнения такого кода в консоли. Поэтому перед запуском требуется вручную поменять символ на исходный.
AotD
14.03.2018 07:23А ещё можно пользоваться блоком code:
x: [1 2 1]
x: next x
forall x [append y: [] x/1 - x/-1]
print y
И ничего не будет заменяться ;)
forcam
13.03.2018 22:05Язык может и прикольный, амбициозный, вкусный, но по видео его развития можно сразу понять, когда эта самая альфа выкатится в продакшн.
Развитие Red:
www.youtube.com/watch?v=OdEqMILgDKo
Для сравнения
Развитие Rust
www.youtube.com/watch?v=URAJsTlPnnc
Я к тому, что программировать на нем если и будут то только мои правнуки, хотя он и симпотичный, тут вопросов нет)DVL333 Автор
13.03.2018 23:03Не соглашусь сразу по двум причинам:
1) На текущий момент есть все основания полагать, что до версии 1.0 в Red потребуется еще добавить расширенную поддержку операций ввода/вывода и поддержку создания нативных приложений под Andriod (причем часть этого уже реализована). Как видите, список задач вполне компактный.
2) Совершенно недавно разработчики нашли источники финансирования и расширяют свою команду. Т.ч. в ближайшем будущем скорость работы существенно возрастет. Более того, к команде Red буквально на днях присоединился Карл Сассенат — создатель REBOL. Как раз этим событиям посвящены крайние записи на официальной странице проекта.
Т.ч. все очень даже обнадеживающе. :)
9214
14.03.2018 14:21Не, ты молодец конечно, сравнивать язык за которым стоит Mozilla и язык, который начался как проект одного энтузиаста (Nenad Rakocevic) и только сейчас стал прибавлять в массе.
Rust, насколько я знаю, использует LLVM, для Red же с нуля написан свой тулчейн. Rust компилируемый, Red компилируемый и интерпретируемый.
Не знаю про вес и батарейки у Rust, но в 1 мегабайт экзешника Red вмещается DSL для системного программирования (Red/System), DSL для создания гуей и кроссплатформенный графический движок (VID и View), TDPL парсер, использующийся как для метапрограммирования и создания eDSL, так и для парсинга как такового (Parse). Что ещё… макросы понятно дело, 50+ типов данных, REPL.
Не холивара ради, но подобное сравнение считаю некорректным.
evocatus
14.03.2018 00:35Кто-нибудь переходил по ссылке на исследование? Вот что там сказано:
What numbers are we showing? It’s a distribution of lines of code per commit every month for around 20 years, weighted by the number of commits in any given month.
Т.е. «Какие значения мы обозначаем? Это распределение количества строк кода на коммит каждый месяц в течение 20 лет, взвешенное по числу коммитов в соответствующий месяц.»
Т.е. это абсолютно не имеет никакого отношения к выразительности языка. По одной простой причине: на разных языках пишут разные программы (у ЯП свои ниши), они развиваются с разной скоростью и т.д.
Поэтому не удивительно, что Clojure здесь впереди планеты всей (это хороший язык, но не в N-цать же раз он выразительнее Python), а Go обогнал Python, Java, C++ и т.д.evocatus
14.03.2018 10:27Готов поспорить, что корреляция приведённого в статье графика с возрастом языка программирования будет существенная.
smer44
14.03.2018 06:50опять пермутация синтаксиса, не дающая ничего нового, при этом невысокого уровня, с непонятной (или не показаной тут) системой макросов, модулей, версий, паралелизации, питон круче.
фичу prin без t, символ!, second… fifth, присвоение через set считаю быдлосинтаксисом.
любое DSL естественным образом создаётся на питоне за одну-две страницы кода
sptorin
14.03.2018 09:18На самом деле язык интересный, единственный минус — альфа версия (в данный момент нет GC, нет полноценного ввода-вывода, нет 64 бит и т.д.). Но! Прошедшее недавно ICO вселяет некоторую надежду на более быстрое развитие языка.
В статье стоило бы указать примеры диалекта parse, вот например email адрес валидатор:
digit: charset "0123456789" letters: charset [#"a" - #"z" #"A" - #"Z"] special: charset "-" chars: union union letters special digit word: [some chars] host: [word] domain: [word some [dot word]] email: [host "@" domain]
Первые три строки — определения наборов символов, дальше идут определения слов, из слов составляются более сложные слова. Проверка адреса:
>> parse "john@doe.com" email == true
Проверка строки на сбалансированность скобок (каждой открывающей скобке "[" есть закрывающая пара и наборы не пересекаются):
balanced-brackets: [#"[" any balanced-brackets #"]"] rule: [any balanced-brackets end] balanced?: func [str][parse str rule]
В первой строке задаем формат нашей конструкции balanced-brackets. Начинается с символа #"[" (#«char» — определение чара в Red) потом идет любое количество повторений balanced-brackets (ссылаемся сами на себя) и в конце всегда закрывающий символ #"]".
Вторая строка — правило: [любое количество balanced-brackets конец]
Третья строка — делаем функцию проверки.
Проверяем:
>> balanced? "[[][]]" == true >> balanced? "][[][]]" == false
С использованием parse можно создавать различные DSL. В примерах есть интерпретатор брейнфака, 22 строки.evocatus
14.03.2018 10:32+1Вы серьёзно? Вот в моём адресе на gmail.com есть точка. Прямо в имени ящика. Что мне теперь делать с такими валидаторами, которые написали контрол-фрики, не читавшие стандарт RFC822? Хорошо, что точка в имени почтового ящика игнорируется, поэтому письмо по адресу без точки всё равно дойдёт, но лично мне не очень удобно помнить, что foursquare делали неграмотные люди и там у меня логин другой, чем на всех остальных сайтах.
В общем, учите матчастьsptorin
14.03.2018 11:52Это же пример работы parse. Взят с туториала: www.red-lang.org/2013/11/041-introducing-parse.html
Если необходимо расширить условия, то можно дописать необходимые проверки.
digit: charset "0123456789" letters: charset [#"a" - #"z" #"A" - #"Z"] special: charset "-" dot: charset "." chars: union union letters special digit chars-dot: union union union letters special digit dot word: [some chars] word-dot: [some chars-dot] host: [word-dot] domain: [word some [dot word]] email: [host "@" domain] >> parse "agro.evocactus@gmail.com" email == true
В том собственно и смысл, можно составлять паттерны как душе угодно.
Я не специалист в Red, думаю добавить обработку точки в имени ящика можно еще проще.evocatus
14.03.2018 11:58Вы вообще не в теме. Просто прочитайте статью по ссылке. ЕДИНСТВЕННАЯ проверка, которую вы имеете право делать — то, что в строке есть хотя бы один символ "@" — да, в корректном e-mail адресе их может быть несколько. ВСЁ.
9214
14.03.2018 20:18>> balanced?: func [x][to logic! attempt [load x]]
== func [x][to logic! attempt [load x]]
>> balanced? "[]"
== true
>> balanced? "[]]"
== false
>> balanced? "[[]]"
== true
>> balanced? "[[[]]"
== false
Упс, не в ту ветку.0xd34df00d
14.03.2018 21:43А теперь если открывающий элемент — z, а закрывающий — Z? Открывающий — $, а закрывающий #?
DVL333 Автор
14.03.2018 12:05Вам привели пример (!) простого (!) валидатора.
Я не разбирался в диалекте parse, но простейшая логика подсказывает мне, что элементарная замена правила для host на
host: [word some [dot word] | word]
полностью решает вашу проблему.
9214
14.03.2018 14:27В оригинале этот парсер назывался ничем иным как «A crude, but practical email address validator», и был приведен как небольшой пример реализации PEG грамматики в диалекте Parse.
evocatus
15.03.2018 21:38Нифига он не practical, потому что накладывает на имена e-mail требования, которых нет в стандарте, а значит это НЕПРАВИЛЬНЫЙ валидатор.
С таким же успехом синтаксис языка можно демонстрировать на функции, которая должна возвращать сумму чисел, а возвращает произведение. Формально правильно, а по сути издевательство.9214
15.03.2018 22:08Ок, тогда бы всё выглядело как:
[to "@" to end]
Практично? Да. Просто? Да. Показывает различные фичи, которые можно использовать при работе с парсером? Нет.
Целью статьи (откуда оригинальный пример был взят) было именно ознакомление читателей с основными фишками и конструктами, отсюда и надуманный пример. Почему вы к нему прицепились — мне не понятно.evocatus
16.03.2018 11:08Я понимаю. Можно было взять для примера номера телефонов. Или почтовые адреса.
0xd34df00d
14.03.2018 18:07Далеко не ново.
balancedBrackets = "[" *> many balancedBrackets *> "]" :: Parser ByteString rule = balancedBrackets <* endOfInput isBalanced = isRight . parseOnly rule > isBalanced "[[]]" True > isBalanced "[[][]]]" False > isBalanced "[[][[]]]" True
9214
14.03.2018 20:28Откровенно раздражает, когда новички лезут показывать что из себя представляет parse, и начинают с парсинга строк. Показали бы как разглаживать серии, к примеру, или как прикрутить UCS синтакис. Написали бы правило, находящее арность функции. Все примеры что вы показали можно реализовать на том же Пистоне.
Parse не ограничен одними лишь строками, его можно использовать как для метапрограммирования, так и для создания других DSL (+ макросы его тоже используют).
FillCT
14.03.2018 11:16Хотел набросать простой пример. Не компилируется при использовании input. Выдает «undefined word input»
Еще не хватает возможности отсчета с заданного числа в цикле repeat. В примерах разработчиков указан только такой вариант для отсчета с нуля:
repeat y 5 [y: y - 1 print ["y =" y]]DVL333 Автор
14.03.2018 11:39Да, пока еще есть такой момент с этой функцией.
Добавьте в код строчку:
#include %environment/console/input.red
и скомпилируйте в режиме релиза с ключом -r.
Насчет циклов, то за описанную вами функциональность должен отвечать другой оператор — for, но он еще не добавлен, поэтому пока приходится обходиться другими операторами.FillCT
14.03.2018 14:27Спасибо, работает. Есть также проблема компиляции с prin. Код компилируется, но строка не выводится через prin, хотя через print всё работает.
Не нашел преобразование строки в число, может плохо смотрел.
Почему-то довольно долго происходит компиляция в релизную версию (40 секунд обычный вывод Hello world на Intel Core 2 Q8400 2.66GHz).
Непонятно зачем было разделять if и either. Язык интересный, надеюсь будет дальше развиваться. Спасибо за статью.9214
14.03.2018 14:38Строка в число:
>> load "123"
== 123
>> to integer! "123"
== 123
Компилятор никак не оптимизирован и написан на Rebol, после релиза 1.0 его планируют переписать на самом Red. Насчёт вывода на консольку после компиляции — по-моему известная проблема, я постараюсь это разработчикам передать.
nybkox
14.03.2018 13:20Вроде прочитать интересно, но ездить на этом желания нет.
Можно ссылку на что-то серьезное написанное на Red.9214
14.03.2018 14:29Выше уже приводили ссылку на CV фреймворк, написанный на Red. Рантайм Red написан на нём же самом, к примеру. По большей части только демки (пусть даже впечатляющие), поскольку язык находится в альфа версии.
nybkox
14.03.2018 21:21Прошу прощения за свою невнимательность.
Подождать годик бы, посмотреть что с ним (Red -ом) станет. Может и вправду что-то интересное получится.
9214
14.03.2018 14:43+1Денис, молодец что рассказываешь о Red массам, но высокопарные утверждения вроде «самый выразительный» надо быть готовым подкреплять живыми и интересными примерами, а не копипастой из документации.
scalavod
14.03.2018 15:50Интересный язык. Из статьи не понял как указать аргументам типы, нашёл тут. Остался вопрос, как указать тип возвращаемого из функции значения. Подскажете?
Еще можете подсказать, что с обработкой ошибок, есть ли исключения или как в go?
Так же напряг этот момент:
«Стоит обратить внимание, что в приведенном примере переменная sum, определенная в теле функции, по умолчанию становится глобальной и ее значение доступно за пределами функции».
А вообще, чувствую как мой мозг сопротивляется этому синтаксиcу, несмотря на то, что он «самый выразительный» и Human-friendly :)9214
14.03.2018 16:09Тип возвращаемого значения: по-моему в спецификации функции указать
return: your-typeset-goes-here, но интерпретатору на это будет по-барабану, т.е. это просто оптимизация для компилятора (в будущем должны будут прикрутить что-то более полноценное, надеюсь).
Обработка ошибок: есть примитивыattemptиtry, которыми можно отлавливать ошибки в виде объектов.
Момент, о которым ты говоришь, напряг тебя не спроста, поскольку в Red областей видимости переменных как таковых нет вообще (как и самих переменных), есть только символы (слова) и неймспейсы (контексты). Это вообще отдельная, слегка мозгодробительная тема :)
Главной фишкой, ИМХО, является не синтаксис, а семантика — в Red и Rebol разница между кодом и данными отсутствует, и блок[1 2 3]может быть как массивом из трех чисел, так и валидной программой для того же subleq интерпретатора. Можно писать самомодифицирующеся функции и некое подобие Лисповских макросов, перекидывать куски кода (блоки) туда-сюда и интерпретировать их как душе угодно.9214
14.03.2018 16:17Пардон,
tryдля отловли,attemptже возвращает результат вычисления илиnoneесли произошла ошибка.
scalavod
14.03.2018 23:11Тип возвращаемого значения: по-моему в спецификации функции указать return: your-typeset-goes-here, но интерпретатору на это будет по-барабану, т.е. это просто оптимизация для компилятора (в будущем должны будут прикрутить что-то более полноценное, надеюсь).
Похоже на то, вот пример.
Главной фишкой, ИМХО, является не синтаксис, а семантика — в Red и Rebol разница между кодом и данными отсутствует, и блок [1 2 3] может быть как массивом из трех чисел, так и валидной программой для того же subleq интерпретатора. Можно писать самомодифицирующеся функции и некое подобие Лисповских макросов, перекидывать куски кода (блоки) туда-сюда и интерпретировать их как душе угодно.
Конечно концепция code as data интересная и здорово, что появляются новые языки, в которых она получает своё развитие.
Я сейчас играюсь с pony и часто приходится обращаться к исходникам стандартной библиотеки. Заметил, что читать исходники даже проще, чем саму документацию (лучше понимаешь что происходит внутри), что для меня является хорошим показателем выразительности.
И вот, посидел вечерок, почитал библиотеку red. Нет, чисто интуитивно, по названию переменных, по опыту работы с похожими библиотеками на других языках, понятно что там происходит, но от ощущения невыразительности, избыточности и сложности конструкций избавиться не смог. В общем, на мой взгляд, далеко не Human-friendly.
Поэтому, буду поглядывать, что происходит с языком или, если на хабре будут появляться статьи по red, то с интересом почитаю, но как игрушку, пока буду использовать pony. Всё же, на мой вкус, он «самый выразительный» :)9214
15.03.2018 10:50Пример с
return:что ты привел относится к Red/System (низкоуровневый C-подобный DSL для системного программирования), а не к Red. То же самое с библиотекой, она чуть более чем полностью написана на R/S. И это не стандартная библиотека языка, а просто код, написанный членами сообщества.
Исходники языка можно почитать в его репозитории, годно написанные скрипты на Red (а не на R/S) есть здесь и здесь.

develop7
14.03.2018 20:25Выразительный, значит. А есть ли в языке из коробки частичное применение и сопоставление с образцом?
9214
14.03.2018 20:34Частичного применения нету, язык не чисто функциональный — реализовать можно будет, когда завезут тип данных
closure!(то бишь замыкания). Для сопоставления с образцом пока все обходятся встроенным парсером.
YemSalat
14.03.2018 21:28Спасибо за статью, но если хотите нормального обсуждения, а не флэйм нa 300+ комментов — нe надо пустых заявлений вроде «самый выразительный язык в мире»
Лучше на примерах покажите в чем он выразительней других языков.
Язык в целом вроде норм, но без определяющих фич — боюсь не взлетит.
oam2oam
14.03.2018 23:10Прошу прощения, может мой комментарий несколько не в тему, но мне кажется, что приведенный график отражает количество реально используемого на практике (ну то есть работающего где-то) кода написанного на данном языке — то есть наиболее важный fortran, а наименее — …
Такие вот мысли приходят при взгляде на график, а вовсе не выразительность. Может, это когнитивная ошибка составителя графика?DVL333 Автор
14.03.2018 23:37Если пройти по ссылке, которая есть под графиком, то там написано, что это все-таки диапазоны средних размеров одного коммита. Самое интересное, что в самой статье, откуда был взят график, Rebol практически не упоминается, и в качестве вывода рекомендуются к изучению другие «выразительные» языки, по причине большей распространенности.
Но еще раз подчеркну, что данная статья — это в первую очередь краткое пособие для желающих по быстрому разобраться в языке, а не доказательство его мегакрутости. :)

dimiork
15.03.2018 02:14Win10x64, установил консоль топика, а вдруг посреди ночи стандартный виндовый защитник выявил и сунул в карантин нечто, см. скрин: imgur.com/a/Z6ByE
Кто чего скажет? Гугл нем, увы.
Хм, отличная попытка господа майнеры?DVL333 Автор
15.03.2018 09:15У меня такая же версия Винды, все нормально.
Вы откуда дистрибутив брали? На скриншоте какое-то странное название у файла, отличное от того, что имеется на официальной странице.9214
15.03.2018 11:11Это GUI консоль, которая распаковывается ProgramData при первом запуске. В следующие разы скачанный бинарник просто проверяет наличие это файла, и, если он имеется, запускает его (консоль), иначе распаковывает всё заново.
DVL333 Автор
15.03.2018 11:57Да, нашел я этот файл, просто он у меня в папке «Пользователи» расположен, а на скриншоте почему-то в папке с дистрибутивом оказался, что сбило с толку. Судя по версии, использовалась стабильная сборка.
9214
15.03.2018 10:58Проблема с ложноположительными, увы, не нова. Тулчейн и линкер для Red написаны с нуля, и создаваемые ими файлы по структуре не совпадают со «стандартными» (GCC, VisualStudio). Плюс используется нестандартный алгоритм сжатия. Некоторые вендоры (в частности Avast, Avira, Norton, McAfee и WD) используют кривой эвристический анализ и сразу же пихают всё необычное в карантин.
Мы в сообществе работаем над этой проблемой, если у вас есть время, оставьте, пожалуйста, билет на трекере со названием ОС, антивируса, версией Red (stable / nightly), и собственно скриншотом что вы привели.

DoctorMoriarty
В чём она выражается? На примерах в духе «Hello World» эта заявленная выразительность не видна совершенно. Чем эта выразительность выразительнее той, которая присутствует в других распространенных языках? Поясните поподробнее, почему вы рекомендовали бы писать приложения (и какие именно приложения, в какой плоскости применения) именно на нём, а не на С, С++, C#, Java, Python,
прости ГосподиPascal etc, приведите сравнения. Без конкретики — это просто ещё один какой-то там ЯПмодный среди хипстеров.DVL333 Автор
Эта выразительность подкрепляется результатами соответствующего исследования, которые я привел в самом начале статьи и даже график привел. Там же и ссылка есть на источник.
worldmind
Вполне понятно что исследование можно по разному проводить и чтобы понять о чём говорит это исследование надо исследовать его методику, а читатели статьи вполне резонно ожидают увидеть примеры демонстрирующие выразительность, хоть примеры про гуй наверно могут быть такими
DVL333 Автор
Если бы я начал рассказывать про исследование, то статья бы стала про исследование, а не справочником по Red. Получается замкнутый круг: если написать только про то, какой он весь замечательный, то возникнет вопрос, а как им пользоваться? По нему материалов даже на английском практически нет, т.ч. получилось бы, что рассказ вообще ни о чем. А если написать про его синтаксис, то никто не поймет, что это за чудо-юдо и зачем всю эту простыню вообще читать.
Поэтому я просто привел результаты исследования и ссылку для тех, кому интересно. Вообще, мне кажется несколько странным ожидание выразительных примеров в материале, озаглавленном «Краткое пособие» и с меткой «Тутариал». Тем более, что их все равно бы никто не понял, не понимая синтаксиса языка — еще один замкнутый круг.
worldmind
Нет смысла рассказывать о синтаксисе не вызвав интереса к языку.
amarao
График показывает количество строк на коммит. Размер коммита зависит от сложности проекта. Если у меня весь проект — 300 строк (считает ерунду), то и коммиты в него — единицы строк.
А что на С++ в это время в браузере меняют в движок с однопоточного на моногопоточный — какая разница. Строк много? Много! Значит, не выразительный.
Более того, количество строк как метрика — это вообще ужас.
Потому что на питоне можно писать адские простыни из map/reduce/filter/lambda, которые даже создатель прочитать не может, а можно писать нормальный код с yield'ами. При этом по первый код (меньше строк) будет считаться более выразительным?
Спасибо, не надо.
YemSalat
В вашем графике Objective-C стоит на 7 позиций выше по «выразительности» чем Ruby…
Вы хоть раз пробовали писать на этих языках? Можете чисто субъективно сказать какой на ваш взгляд является более «выразительным»?
А если посмотреть на вертикальную ось — то можно заметить пометку «строк кода на коммит» — это по-вашему метрика выразительности, ни от чего болше не зависящая?
DVL333 Автор
На данном этапе я бы скорее рекомендовал Red к изучению и к использованию для создания небольших приложений, т.к. сейчас он пока еще на стадии альфы. О полном использовании можно будет говорить, когда он доберется до версии 1.0 (до которой еще, как минимум, должно быть два релиза). Из заявленных «фишек», к примеру, легкое создание кроссплатформенных нативных приложений, в том числе, под Android.
SADKO
А оно сейчас не работает?
И ещё интересно с какой скоростью это всё работает, я так вскользь просмотрел VID и он достаточно убог, но где наша не пропадала, можно вспомнить школьные годы и начать самостоятельно вырисовывать графики и гистограммы, но с какой скоростью это будет страдать на мобильных платформах?!
DVL333 Автор
Приложения под Android — нет, пока еще не поддерживаются. Это как раз планируется реализовать в рамках предстоящего релиза.
По поводу VID, то это всего лишь диалект, упрощающий создание интерфейса. Интерфейс можно создавать и другими способами. В принципе, VID достаточно удобен, но некоторые вещи не особенно понятны интуитивно, а документации по нему не хватает, что минус…
Честно говоря, я не замечал проблем в скорости работы интерфейса. Все вполне шустро.
9214
В чем, по твоему, эта убогость выражается?