
На фото я за рабочим столом у себя дома, где я работаю 90% времени.
У нас небольшая команда, мы разрабатываем web-приложения для автоматизации бизнеса. Помимо выполнения проектов на заказ мы создали и развиваем два онлайн-сервиса:
Над AB-DOC трудится не вся наша команда, а всего два человека: я и IgorBB.

Итак, что же из себя представляет AB-DOC.
Бессерверная архитектура
Бессерверные приложения — сейчас мощный тренд в мире веб-разработки. Простыми словами это такие приложения, которые работают полностью на базе сервисов облачных провайдеров. Их преимущества вытекают из характеристик облачных сервисов, благодаря которым они работают, — это отказоустойчивость и масштабируемость. Кроме того, как и с облачными сервисами, расходы на них напрямую зависят от нагрузки. Если нагрузки нет, то и стоимость равна нулю. Это очень удобно и здорово.
Но есть и обратная сторона медали. Первый недостаток бессерверных приложений — это сложный процесс разработки. То есть на этапе первоначальной настройки инфраструктуры, и выстраивания процесса разработки они требуют больше усилий, чем обычные веб-приложения, у которых есть сервер. Второй недостаток — такие приложения обычно зависимы от вендора и перенос их к другому облачному провайдеру может быть непростой задачей.
Мы создаем приложения в Amazon Web Services, поэтому далее в статье все будет относится к этому облачному провайдеру.
Обычно бессерверные приложения имеют бэкенд. В качестве бэкенда выступает база данных в виде сервиса DynamoDB (NOSQL СУБД) или RDS (реляционные СУБД). Код для бекэнд реализуется в виде Lambda-функций, доступ к которым осуществляется через API Gateway.
У AB-DOC ничего этого нет. У него вообще нет бекэнда и серверного кода (по крайней мере, пока).
Архитектура AB-DOC выглядит примерно так
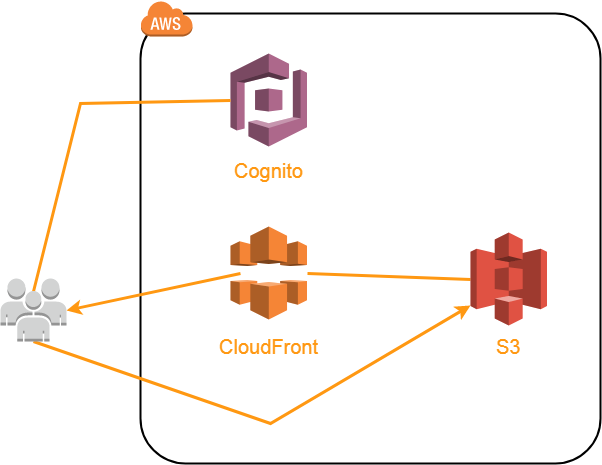
Код приложения (HTML, CSS, JavaScript и т.д.) размещен в отдельном бакете S3 и отдается через CDN CloudFront. В принципе можно было бы отдавать и напрямую из S3, ведь для бакетов можно включать функцию хостинга статического контента.
Причина, по которой нам понадобился CloudFront, не только в том, чтобы ускорить загрузку контента, но и в том, что нам нужен был способ перенаправления всех ссылок на index.html. AB-DOC является single-page-application (SPA), поэтому при запросе любого URL нам нужно, чтобы пользователю загружался index.html. Дальше исходя из запрошенного URL JavaScript загружает нужный для пользователя контент при помощи ajax. Мы не используем фронтэнд-фреймворки, поэтому написали свой маленький роутер.
Так вот для перенаправления всех URL на index.html мы настроили в CloudFront свое правило обработки ошибок 404 (страница не найдена).

Благодаря этому правилу CloudFront при запросе любого несуществующего на нашем ресурсе URL отдает index.html с кодом ответа 200. Вот и вся магия для реализации SPA с хостингом кода в S3.
Пользовательский контент также размещается в S3, в отдельном бакете, и отдается тоже через CloudFront. Пользовательский контент включает структуру дерева (Json), содержимое документов (HTML), встроенные в документы изображения и приложенные файлы (различные форматы).
Дальше речь пойдет об отдельных, интересных на мой взгляд, нюансах реализации нашего приложения.
Аутентификация и авторизация
После загрузки кода в браузер пользователя AB-DOC первым делом производит аутентификацию и авторизацию пользователя. Для этого мы используем Cognito.
Напомню, что аутентификация — это процесс проверки подлинности пользователя, а авторизация — процесс наделения этого пользователя определенными правами для работы в программе.
Cognito состоит из 3 сервисов:
- User Pools
- Federated Identities
- Sync
Если у вас не было опыта работы с сервисами Cognito, то будет непросто понять для чего нужен каждый их них. Пишу, как я это понимаю.
User Pools
Это управляемый сервис, обеспечивающий регистрацию, аутентификацию (подтверждение подлинности) пользователей и хранение их учетных записей. Он позволяет настроить поля данных по каждому пользователю (что храним), политику сложности паролей, будете ли вы использовать MFA, различные триггеры, которые могут срабатывать при регистрации, входе и так далее. Тут же можно настроить сообщения, которые сервис будет отсылать для верификации email при регистрации пользователей.
К User pool можно привязывать внешних провайдеров идентификации (Facebook, Google, Amazon или SAML). При входе через внешнего провайдера создается учетная запись в вашем User pool. В основном это работает, если использовать страницы входа, размещаемые в самом сервисе Cognito. То есть надо перенаправлять пользователей для входа на специальный URL вида your-app.auth.[region].amazoncognito.com. Вид этой страницы можно настроить, чтобы он был похож на вид вашего приложения. После авторизации пользователь будет возвращен в ваше приложение. Мне такой вариант реализации не понравился.
Я довольно долго пытался реализовать интеграцию User pool с внешними провайдерами с помощью Amazon Cognito Identity SDK for JavaScript. Теоретически это тоже возможно, но никакой документации на эту тему мне не удалось найти и я сдался. Это было 2-3 месяца назад.
Federated Identities
В отличие от User Pools данный сервис отвечает за авторизацию пользователей, то есть наделение их определенными полномочиями для доступа к сервисам AWS (S3, например).
Для работы этого сервиса нужно создать Identity pool и настроить провайдеров аутентификации, с которыми он будет работать. В качестве провайдеров аутентификации может выступать ваш User pool, а также ряд внешних провайдеров, таких как Amazon, Facebook, Google, Twitter, OpenID, SAML или даже провайдер аутентификации, который вы создадите сами.
В AB-DOC в качестве провайдеров аутентификации мы используем наш User pool и один внешний провайдер — Google. Поэтому у пользователей есть 2 варианта:
- Создать новую учетную запись (придумать логин-пароль, подтвердить email). В этом случае для него создается учетная запись в User pool и дальше создается запись в Identity pool, благодаря которой он получается нужные разрешения.
- Войти с помощью учетной записи Google. Тогда учетная запись в User pool не создается, пользователю просто создается запись в Identity pool, и он наделяется нужными полномочиями для работы с приложением.
Сам процесс наделения полномочиями в Identity pool довольно простой. Для Identity pool выбираются в 2 роли из AWS Identity and Access Management (IAM): для аутентифицированных и для неаутентифицированных пользователей.
К каждой роли в IAM можно привязать любые политики, которые будут сколь угодно гибко наделять пользователей нужными правами. Индивидуализация возможна за счет использования в политиках переменных. Например, для того, чтобы дать доступ на запись пользователям только в рамках их папки в бакете S3, мы используем такую переменную в описании ресурса
...
"Resource": [
"arn:aws:s3:::ab-doc-storage/${cognito-identity.amazonaws.com:sub}",
"arn:aws:s3:::ab-doc-storage/${cognito-identity.amazonaws.com:sub}/*",
]
...Таким образом, вместо ${cognito-identity.amazonaws.com:sub} для каждого пользователя в политику подставляется его идентификатор в Identity pool. Каждый пользователь работает внутри своей папки в бакете, имя которой соответствует его id в Identity pool.
Слово папка тут можно было бы поставить в кавычки, потому что на самом деле в S3 нет папок. Это плоская файловая система. Каждый файл просто имеет ключ (Key), и разделение на «папки» условно.
Sync
Этот сервис обеспечивает хранение данных пользователей приложения. Данные, размещаемые в Sync, хранятся в виде наборов ключ-значения (Datasets), которые привязаны к id пользователя в Identity pool. Таким образом, Sync позволяет сохранять произвольную информацию по всем пользователям, через что бы они не аутентифицировались: будь то User pool или внешний провайдер. Кроме того, Sync обеспечивает синхронизацию наборов данных между всеми устройствами, на которых пользователь работает в приложении.
В целом авторизация построена на токенах. Код JavaScript, отвечающий за нее, составляет на текущий момент более 1/3 всего кода приложения. То есть это довольно объемная тема, и может быть я напишу об этом отдельную статью в будущем.
Отслеживание изменений и очереди событий
AB-DOC сам отслеживает и сохраняет изменения, которые делает пользователь, когда редактирует узлы дерева или содержимое документа.
Работа этого механизма построена на таймерах JavaScript: setInterval(). Для дерева и для документа создаются отдельные таймеры, которые раз в 3 секунды проверяют, появились ли изменения, и если да, сохраняют их в S3. Таймеры в приложении централизованно создаются через объект TIMERS.
Для централизованного отслеживания изменений мы написали объект ACTIVITY, который отвечает за ведение очередей событий. Очереди формируется в соответствии с вариантами контента, который может создавать пользователь. У дерева — своя очередь, у документа — своя, для каждого загружаемого файла создается своя очередь и так далее.
События, записываемые в очереди, могут быть двух типов: ожидание (pending) или сохранение (saving). Логика работы очередей следующая.
Когда пользователь вносит какую-то правку, в нужную очередь добавляется событие ожидания. В дереве события добавляются прямо из кода, который обрабатывает изменения, а изменения в документах отслеживаются благодаря Mutation Observer.
Дальше когда срабатывает соответствующий таймер, в очередь добавляется событие сохранения, и начинается процесс загрузки изменений в S3. После успешного завершения загрузки данная очередь очищается вплоть до последнего события сохранения. На момент очищения в очереди могут быть уже новые события ожидания, которые будут дожидаться следующего 3-х секундного цикла.
Вот так это выглядит на примере очереди doc modify, которая отвечает за изменения документа.
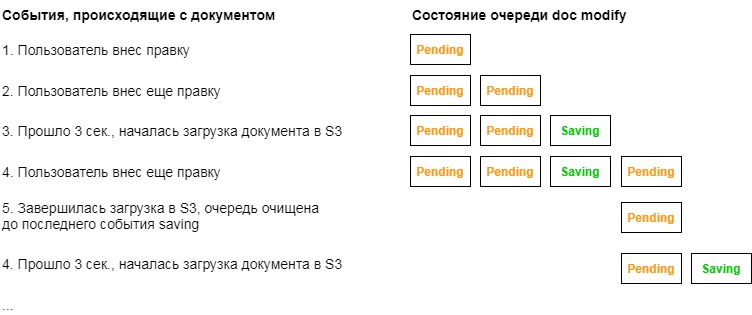
Индикатор изменений в шапке отражает состояние очередей событий.
Когда ничего не происходит, и все очереди пустые, то индикатор не отображается.

При наличии в очередях событий ожидания, он представлен оранжевым карандашом.

Если есть очереди, в которых идет процесс сохранения, то индикатор становится белым.

Если очереди не пустые, а пользователь попытается закрыть браузер или просто уйти со страницы, то сработает функция window.onbeforeunload(). Она предупредит пользователя, что его правки еще не успели сохраниться. Он может или подождать завершения сохранения или покинуть страницу, потеряв последние изменения.
Индикатор записан в переменную $update:
$update = $('#update');//TIMERS object
//tracks all timers and prevents memory leaks
//call TIMERS.set('name') to create new timer
//call TIMERS.<timer_name>.destroy() to destroy timer
//call TIMERS.<timer_name>.execute() to execute timer
TIMERS = {
on: true, //timers are ON when true
set: function(callback, interval, name){
if(['on', 'set', 'execute', 'destroy', 'Timer'].indexOf(name) !== -1){
throw new Error('Invalid timer name: ' + name);
}
if(this.hasOwnProperty(name) && this[name].id !== 0){ //automatically clears previous timer
this[name].destroy();
}
if(this.on || PRODUCTION){
this[name] = new this.Timer(callback, interval);
} else {
this[name] = {
id: 0,
execute: callback,
destroy: function(){ void(0); }
}
}
},
Timer: function(callback, interval){ //timer constructor
this.id = setInterval(callback, interval);
this.execute = callback;
this.destroy = function(){ clearInterval(this.id); };
}
};//ACTIVITY object
//stores activities states and updates indicator in navbar.
//Activities: doc edit, file [guid] upload, file [guid] delete or whatever.
//Two possible states: pending or saving.
//Each activity on each specific object must be reported independently!
//"saving" class is "!important", so it dominates if both classes are active
ACTIVITY = {
lines: {}, //each activity has own line of pending and saving events
push: function (activity, state){
var self = this;
if(this.lines.hasOwnProperty(activity)){
this.lines[activity].push(state);
} else {
this.lines[activity] = [state];
}
this.refresh();
return self;
},
get: function(activity){
var self = this;
if(this.lines.hasOwnProperty(activity)){
var length = this.lines[activity].length;
return this.lines[activity][length-1];
} else {
return undefined;
}
},
flush: function(activity){
var self = this;
if(this.lines.hasOwnProperty(activity)){
var index = this.lines[activity].indexOf('saving');
if(index !== -1){
this.lines[activity] = this.lines[activity].slice(index+1);
}
}
this.refresh();
return self;
},
drop: function(activity){
var self = this;
if (this.lines.hasOwnProperty(activity)){
delete this.lines[activity];
this.refresh();
}
return self;
},
refresh: function(){
var keys = Object.keys(this.lines),
pending = false,
saving = false;
for (var i = 0; i < keys.length; i++) {
pending = pending || this.lines[ keys[i] ].indexOf('pending') !== -1;
saving = saving || this.lines[ keys[i] ].indexOf('saving') !== -1;
}
pending ? $update.addClass('pending') : $update.removeClass('pending');
saving ? $update.addClass('saving') : $update.removeClass('saving');
}
}Опять же на примере документа процесс выглядит так. При открытии документа навешивается обработчик событий изменения содержимого документа (внутри это Mutation Observer). Обработчик просто добавляет событие ожидание в очередь doc modify:
editor.on('text-change', function () {
ACTIVITY.push('doc modify', 'pending');
});Таймер документа раз в 3 секунды проверяет очередь doc modify на наличие событий ожидания и при необходимости загружает содержимое документа в S3, после чего очищает очередь:
TIMERS.set(function () {
if(ACTIVITY.get('doc modify') === 'pending'){
ACTIVITY.push('doc modify', 'saving');
var params = {
Bucket: STORAGE_BUCKET,
Key: self.ownerid + '/' + self.docGUID + '/index.html',
Body: self.editor.root.innerHTML,
ContentType: 'text/html',
ContentDisposition: abUtils.GetContentDisposition('index.html'),
ACL: 'public-read'
};
Promise.all([
s3.upload(params).promise(),
new Promise(function(res, rej) { setTimeout(res, 800); })
]).then(function(){
ACTIVITY.flush('doc modify');
}).catch(function(){
g.abUtils.onWarning(g.abUtils.translatorData['couldNotSave'][g.LANG]);
});
}
}, 3000, 'doc');
Здесь есть забавный момент, связанный с тем, что загрузка в S3 происходит обычно очень быстро. Поэтому, чтобы индикатор сохранения не мерцал, мы используем Promise.all(), который срабатывает, когда завершается выполнения двух Promise: собственно s3.upload() и маленького setTimeout() длительностью 0.8 сек. Это нужно, чтобы индикатор показывал сохранение не менее 0.8 секунд, даже если по факту изменения загрузились быстрее.
Загрузка и хранение данных в S3
Каждому пользователю в S3 выделяется отдельная папка, имя которой совпадает с его id в Identity pool. В корне этой папки AB-DOC сохраняет файл tree.json, в котором хранится структура дерева пользователя.
Формат файла tree.json вот такой:
[
{
"id": "GUID узла (документа)",
"name": "Имя узла (документа)",
"children":
[
{ "id": "...", "name": "...", "children": [...] },
{ "id": "...", "name": "...", "children": [...] },
...
]
},
{
"id": "GUID узла (документа)",
"name": "Имя узла (документа)",
"children":
[
{ "id": "...", "name": "...", "children": [...] },
{ "id": "...", "name": "...", "children": [...] },
...
]
},
...
]Данная структура используется без изменений в качестве источника данных для zTree при рендеринге дерева.
Каждый документ сохраняется в отдельной подпапке, имя которой совпадает с guid документа. Внутри этой папки сохраняется файл index.html, который собственно и является документом. Помимо этого файла, в папке документа сохраняются в виде отдельных объектов вставленные в документ изображения, а в подпапке attachments — все приложенные к документу файлы.
Загрузка всех данных происходит напрямую из браузера пользователя в S3 с помощью функции AWS JavaScript SDK upload(). Она умеет загружать файлы в S3, разбивая их на части (multipart upload) и делать это в несколько потоков.
Например, вот так загружаются приложенные к документу файлы в 4 потока, с разбиением на части по 6 Мб. Этот код работает внутри объекта abDoc (документ), self в данном случае = this этого объекта.
ACTIVITY.push('doc file upload', 'saving');
var fileGUID = abUtils.GetGUID(),
key = self.ownerid + '/' + self.docGUID + '/attachments/' + fileGUID,
partSize = 6 * 1024 * 1024;
var file_obj = {
guid: fileGUID,
name: file.name,
iconURL: abUtils.mimeTypeToIconURL(file.type),
key: key,
size: file.size,
percent: '0%',
abortable: file.size > partSize //only multipart upload can be aborted
};
var params = {
Bucket: STORAGE_BUCKET,
Key: key,
Body: file,
ContentType: file.type,
ContentDisposition: abUtils.GetContentDisposition(file.name),
ACL: 'public-read'
};
var upload = s3.upload(params, {partSize: partSize, queueSize: 4});
upload.on('httpUploadProgress', function(e) {
var $file = $('.file-container[data-guid='+fileGUID+']');
if(!$file.hasClass('freeze')){
file_obj.percent = Math.ceil(e.loaded * 100.0 / e.total) + '%';
var $file_size = $file.find('.file-size');
$file_size.css('width', file_obj.percent);
if($file_size.attr('data-text')){
$file_size.text( file_obj.percent );
}
}
});
upload.send(function(err, data) {
if(err) {
if (err.name !== 'RequestAbortedError') {
abUtils.onError(err);
}
}
else {
var params = {
Bucket: data.Bucket,
Prefix: data.Key
};
s3.listObjectsV2(params, function(err, data) {
if (err) { abUtils.onError(err); }
else {
file_obj.modified = data.Contents[0].LastModified;
self.updateFilesList();
ACTIVITY.flush('doc file upload');
}
});
}
});
Событие httpUploadProgress позволяет отслеживать прогресс загрузки и обновлять прогресс-бар файла.
Объект s3 (AWS JavaScript SDK) использует credentials, которые включают id Identity pool-а, id token пользователя и имя провайдера аутентификации. Все обращения к сервису S3 производятся с передачей id token пользователя. Пользователь наделяется теми правами, которые прописываются в политике, привязанной к роли, которая в свою очередь задана в Identity pool. Тот же принцип работает и при работе с другими сервисами AWS через JavaScript SDK. Id token имеет короткий срок жизни (1 час), по истечение которого нужно получить новый id token при помощи refresh token. Refresh token имеет срок жизни 365 дней.
Индикатор свободного места
На первый взгляд может показаться, что это очень простая штука, но это не совсем так.

Мы сделали индикатор свободного места в виде корзины: узкой внизу и расходящейся кверху. Нам хотелось сделать, чтобы визуально заполняемость корзины соответствовала тому, как подобная корзина будет заполняться в физическом мире. То есть вначале она заполняется быстро, так как снизу она более узкая. А по мере заполнения, уровень повышается все медленнее из-за ее расширения кверху.
Чтобы это реализовать, мы воспользовались формулой площади Гаусса для четырехугольников.
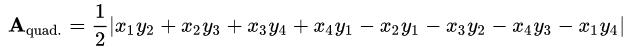
С помощью этой формулы по координатам точек корзины мы можем вычислить площадь всей корзины — этому у нас соответствует максимальный лимит свободного пространства в 1 Гб. Дальше, исходя из значения заполненного пользователем объема, мы вычисляем с помощью простой пропорции площадь части корзины, которая будет занята пользователем.
Имея занимаемую пользователем площадь, остается вычислить Y-координату верхней границы заполненного пространства исходя из вышеупомянутой формулы. Х-координаты верхних точек занимаемого пространства выводятся через тангенс угла корзины. В общем в результате вывода Y у меня получилось хоть и страшное по виду, но обычное квадратное уравнение. На доске оно в правом нижнем углу.

На доске size обозначает длину стороны квадрата, в который вписывается корзина. Для примера на доске size = 30. Нужно было вывести общую формулу, поэтому использовал обозначение size.
Сейчас, когда пишу эти строки, закрались смутные сомнения. Наверное, я сильно перемудрил и можно было бы вывести гораздо проще, учитывая то, что фигуры представляют собой равнобокие трапеции…
Для прорисовки индикатора мы использовали потрясающую библиотеку SVG.js, которая позволяет рисовать в JavaScript SVG-графику. Причем можно не просто рисовать, но и манипулировать графическими примитивами, делать анимацию и даже навешивать обработчики событий на элементы графики. Последней возможностью, правда, мы не пользовались.
function() {
var size = 32,
bucket_capacity = this.maxUsedSpace,
space_occupied = this.userUsedSpace + this.userUsedSpaceDelta + this.userUsedSpacePending;
//bucket coords
var bx1 = 2, bx2 = 5, bx3 = size - bx2, bx4 = size - bx1,
by1 = 2, by2 = size - by1, by3 = by2, by4 = by1,
tg_alpha = (bx2 - bx1) / (by2 - by1);
//calculate areas
var barea = Math.abs(bx1*by2 + bx2*by3 + bx3*by4 + bx4*by1 - bx2*by1 - bx3*by2 - bx4*by3 - bx1*by4) / 2,
sarea = Math.min(1.0, space_occupied / bucket_capacity) * barea;
//calculate y of the occupied space (see sizeIndicator.jpg for details)
var a = -2*tg_alpha,
b = 3*tg_alpha*by2 + bx3 + size - 3*bx2 + tg_alpha*by3,
c = bx2*by2 - tg_alpha*Math.pow(by2, 2) + 2*bx2*by3 - bx3*by2 - size*by3 - tg_alpha*by2*by3 + 2*sarea,
D = Math.pow(b, 2) - 4*a*c,
y = (-b + Math.sqrt(D)) / (2*a);
//occupied space coords
var sx1 = Math.ceil(bx2 - by2*tg_alpha + y*tg_alpha), sx2 = bx2, sx3 = bx3, sx4 = size - sx1,
sy1 = Math.ceil(y)-2, sy2 = by2, sy3 = by3, sy4 = sy1;
//draw
if(!this.sizeIndicator){
this.sizeIndicator = SVG('sizeIndicator');
this.sizeIndicator.space = this.sizeIndicator
.polygon([sx1,sy1, sx2,sy2, sx3,sy3, sx4,sy4]) //occupied space
.fill('#DD6600');
this.sizeIndicator.bucket = this.sizeIndicator
.polyline([bx1,by1, bx2,by2, bx3,by3, bx4,by4]).fill('none') //bucket shape
.stroke({ color: '#fff', width: 3, linecap: 'round', linejoin: 'round' });
} else {
this.sizeIndicator.space
.animate(2000)
.plot([sx1,sy1, sx2,sy2, sx3,sy3, sx4,sy4]);
}
//update tooltip
$('#sizeIndicator').attr('title', g.abUtils.GetSize(space_occupied) + ' / ' + g.abUtils.GetSize(bucket_capacity));
}Про мобильную версию
Мы не планируем создавать отдельное мобильное приложение. Потому что мобильное приложение нужно дополнительно устанавливать, чего пользователи не очень любят делать. И потому что для этого собственно нужно будет делать отдельное приложение, что затруднит поддержку и развитие проекта. Вместо этого мы собираемся идти по пути прогрессивного веб-приложения (Progressive Web App или PWA). Но на текущий момент AB-DOC не является таковым. Мы пока просто постарались сделать работу в приложении из мобильных браузеров максимально полноценной и удобной.
На мобильных устройствах с шириной экрана менее 600px приложение начинает вести себя несколько иначе. На таких устройствах оно работает только в одном из двух режимов: дерево или документ. В целом нам удалось в полной мере сохранить функционал на тач-устройствах, включая drag'n drop узлов дерева и приложение файлов к документам.
Однако пока приложение не позволяет работать с документами без соединения с Интернетом. Это ключевая функция, которая будет реализована при создании PWA.
Одна из сложностей, с которой мы столкнулись при работе по адаптации приложения на мобильных устройствах, — отсутствие удобных средств для тестирования.
Открывать приложение, запущенное на локальной машине разработчика, с мобильного устройства не сложно. Можно заходить по локальному адресу через Wi-Fi. Можно для этого создать какой-нибудь домен и направить его на свой внешний IP, а на роутере пробросить порт к локальной машине. И тогда этот домен станет адресом приложения на локальной машине.
Еще есть вариант с использованием Wi-Fi через usb-адаптер, если нет возможности влезать в настройки роутера. Его придумал IgorBB. Про этот вариант подробнее можно почитать в моем дереве AB-DOC: https://ab-doc.com/eu-west-1_a01c087d-a71d-401c-a599-0b8bbacd99e5/d4b68bc3-2f32-4a3a-a57c-15cb697e8ef3.
Основная проблем в тестировании состоит в том, что в мобильных браузерах нет консоли разработчика. Пока мы выводим отладочную информацию через alert(), что конечно, не является хорошим вариантом. Но мы еще не внедрили более адекватный метод.
Разработка и развертывание
Процесс разработки у нас достаточно простой ввиду того, что над проектом работает всего два человека. Мы используем git и частный репозиторий на BitBucket. Ветка master у нас является production кодом. Только из нее мы делаем деплой. Над всеми функциями/ошибками мы работаем в отдельных ветках. Каждой ветке у нас соответствует отдельная задача в нашем собственном таск-трекере AB-TASKS. Ветки, стараемся как можно чаще сливать с мастером и деплоить.
Процесс деплоя заключается в том, что нам нужно загрузить код приложения в бакет S3. Тут есть свои нюансы.
Как я писал выше, мы используем CloudFront для отдачи контента. Нам нужно обеспечить механизм при котором, контент будет отдаваться почти всегда из кэша CloudFront, но когда мы загружаем обновленную версию файла (картинку, css, js, html или любой другой файл), CloudFront должен обновлять файл в своем кэше. Иначе могут возникать неприятные ситуации, при которых пользователь получит, например, часть файлов из кэша, а часть обновленных из источника (S3). Это может привести к непредсказуемым последствиям.
Для отдачи кода приложения у нас используется отдельный CloudFront Distribution с одним источником в виде бакета S3, содержащего исходный код AB-DOC, и с двумя правилами кэширования (Cache Behaviors).
Правило кэширования определяет, как CloudFront будет кэшировать те или иные файлы. Для настройки правила задается паттерн запросов (*.html или images/*.jpg и тому подобный) и настройки, которые будут применены при совпадении запроса с заданным паттерном. Настройки включают HTTP методы, для которых активно кэширование, параметры TTL или время жизни объектов в кэше (min, max, default), сжатие, а также на основе чего собственно производится кэширование (учитываются ли параметры, куки...), плюс ряд других параметров.
Мы настроили 2 правила кэширования:
- Первое правило для HTML-файлов. В настройках их кэширования заданы небольшие TTL (Minimum TTL = 100 секунд). При условии, что мы задаем для этих файлов cache-control max-age=0, применяется minimum TTL, то есть файлы HTML спустя 100 секунд считаются просроченным, и CloudFront обращается к источнику, чтобы проверить, не появилась ли там более свежая версия файла.
- Второе правило для всех остальных файлов. Для этих файлов мы не задаем заголовки файлов cache-control max-age, поэтому для них применяется максимальное значение из двух: minimum TTL и default TTL. В нашем случае это 86400 секунд или 24 часа, то есть они кэшируются надолго. Но помимо этого в настройках правила мы указываем, что CloudFront должен «смотреть» на параметры запроса при кэшировании объектов.
Вот тут в документации AWS описано, как сочетаются различные настройки TTL и cache-control.
Параметры запроса позволяют легко управлять кэшированием. Для всех файлов мы добавляем условную версию файла в виде параметра: filename.extension?v=123. Если файл менялся, нужно лишь изменить значение параметра, и это заставит CloudFront отдать файл не из кэша, а обратившись к источнику.
Однако отслеживать изменения файлов и вручную обновлять ссылки на них было бы очень утомительно, да и по большому счету невозможно. Мы бы постоянно забывали это делать. Поэтому мы написали bash-скрипт, который делает это в автоматическом режиме. Заодно он выполняет ряд функций для полноценного деплоя кода приложения в S3.
Вот какие действия он выполняет:
- Он просматривает все HTML файлы. При помощи grep находит все ссылки на рисунки, стили, скрипты. Проверяет timestamp последнего изменения каждого файла при помощи команды stat. Если файл менялся с момента прошлого прохода скрипта, он при помощи sed обновляет timestamp в параметре v=[timestamp] в ссылке на файл.
- В конфиге скрипта можно указать ему, какие файлы JavaScript мы хотим собрать в единый бандл. Скрипт находит эти файлы, минимизирует их через babel и собирает в единый бандл. После этого заменяет все ссылки на отдельные файлы ссылкой на бандл.
- В конце скрипт загружает код приложения в S3 двумя отдельными командами для HTML файлов и всех остальных, устанавливая нужные заголовки:
aws s3 sync $PACKAGE s3://"$bucket"/ --delete --acl public-read --exclude "*.html" aws s3 sync $PACKAGE s3://"$bucket"/ --delete --acl public-read --cache-control max-age=0 --exclude "*" --include "*.html"
#! /bin/bash
# This script is used for deployment
# It uploads files to the bucket, corrects timestamps of files included in HTML, bundles js scripts.
# To use this script you need a config file:
# .service/deploy.config :
# bucket=mybucket
# exclude=.git/*,.service/*,secret_file # Files and directories to exclude from uploading
# bundle=script1.js,script2.js,script3.js # Scripts listed here would be removed from HTML files and bundeled into a single file, which will be minified. A separate bundle is created for every HTML file
# You also need to install babel-cli and babel-preset-minify from npm:
# npm install --save-dev babel-cli
# npm install --save-dev babel-preset-minify
# If you want this script to correct timestamps in HTML, you should include them with a ?v=<number> : <link rel="apple-touch-icon" sizes="180x180" href="/apple.png?ver=v123">
# You can use following options:
# -v,--verbose - for detailed output
# -n,--no-upload - do not upload result into bucket
VERBOSE=false
NO_UPLOAD=false
PACKAGE="package"
TMP="$PACKAGE/.temp"
CONFIG=".service/deploy.config"
PATH="$PATH:./node_modules/.bin"
function log() {
local message=$1
if [ "$VERBOSE" = true ] ; then
echo $message
fi
}
function error() {
echo "$1"
}
bundle_n=0
function create_bundle() {
local html_source_file=$1
echo "Creating bundle for \"$html_source_file\"..."
#this is a grep command
local grep0="$BUNDLE_GREP $html_source_file"
#name before babel
local bundle_before_babel="$TMP/ab.doc.bundle$bundle_n.js"
#name to be used in html
local bundle_after_babel_src="scripts/ab.doc.bundle$bundle_n.min.js"
#name after babel
local bundle_after_babel="$PACKAGE/$bundle_after_babel_src"
$grep0 | while read -r x; do
log "Adding \"$x\" to bundle"
echo -en "//$x\n" >> $bundle_before_babel
cat $x >> $bundle_before_babel
echo -en "\n" >> $bundle_before_babel
done
# if files for bundling were found in html
if [ -f $bundle_before_babel ]
then
#putting bundle through babel
log "\"$bundle_before_babel\" >===(babel)===> \"$bundle_after_babel\""
npx --no-install babel "$bundle_before_babel" --out-file "$bundle_after_babel" --presets=minify
#removing bundeled scripts from file
log "Removing old scripts from \"$html_source_file\"..."
sed="sed -i.bak -e \""
grep1="$BUNDLE_GREP -n $html_source_file"
lines=($($grep1 | cut -f1 -d:))
for ln in ${lines[*]}
do
sed="$sed$ln d;"
done
sed="$sed\" $html_source_file"
eval $sed
#adding bundle instead of old scripts
log "Adding bundle to \"$html_source_file\"..."
current_time=$(stat -c %Y .$filename)
sed -i.bak -e "${lines[0]}i<script src=\"/$bundle_after_babel_src?ver=v$current_time\"></script>" $html_source_file
rm $html_source_file.bak
bundle_n=$(expr $bundle_n + 1)
fi
}
function update_versions() {
local html_source_file=$1
local found=0
local modified=0
#set file versions according to modify timestamp
echo "Updating file versions in \"$html_source_file\"..."
grep -oE "\"[^\"]+\?ver=v[^\"]+\"" $html_source_file | while read -r href ; do
((found++))
local href="${href//\"/}"
local current_timestamp=$(echo $href | grep -oE "[0-9]+$")
local filename="${href/?ver=v[0-9]*/}"
local new_timestamp=$(stat -c %Y $PACKAGE$filename)
log $new_timestamp
if [ "$current_timestamp" != "$new_timestamp" ]
then
((modified++))
sed -i "s|$filename?ver=v[0-9]*|$filename?ver=v$new_timestamp|g" $html_source_file
fi
log "Found $found, modified $modified"
done
}
function init_directory() {
local path=$1
log "Creating empty directory \"$path\""
if [ -d "$path" ]; then
log "\"$path\" already exists. Removing \"$path\""
rm -rf "$path"
fi
mkdir "$path"
}
echo "==== Initialization ===="
# check flags
while [[ $# -gt 0 ]]
do
key="$1"
case $key in
-v|--verbose)
VERBOSE=true
shift
;;
-n|--no-upload)
NO_UPLOAD=true
shift
;;
*)
shift
;;
esac
done
if [ ! -f $CONFIG ]; then
error "Could not load config \"$CONFIG\"."
exit -1
fi
. $CONFIG
exclude=${exclude//,/ }
if ! npm list babel-preset-minify > /dev/null ; then
error "babel-preset-minify is not installed"
exit -2
fi
if ! npm list babel-cli > /dev/null ; then
error "babel-cli is not installed"
exit -3
fi
if [ -v bundle ]; then
log "Using bundle"
bundle=${bundle//,/ }
BUNDLE_GREP="grep "
for b in $bundle
do
BUNDLE_GREP="$BUNDLE_GREP -o -e $b "
done
else
log "Not using bundle"
fi
# create package and tmp directories
echo "==== Creating temporary directories ===="
init_directory "$PACKAGE"
init_directory "$TMP"
# copying everything into package excluding files listed in $exclude
copy="tar -c --exclude \"$PACKAGE\" "
files_to_exclude="$exclude $bundle" #( "${exclude[@]}" "${bundle[@]}" )
for e in $files_to_exclude
do
log "Excluding $e"
copy="$copy --exclude \"$e\""
done
copy="$copy . | tar -x -C $PACKAGE"
eval $copy
echo "==== Working with HTML files ===="
for f in $(find $PACKAGE -name '*.html')
do
if [ -v bundle ]; then
create_bundle $f
fi
update_versions $f
done
rm -rf $TMP
if [ "$NO_UPLOAD" = false ] ; then
echo "==== S3 upload ====" #upload to S3
aws s3 sync $PACKAGE s3://"$bucket"/ --delete --acl public-read --exclude "*.html"
aws s3 sync $PACKAGE s3://"$bucket"/ --delete --acl public-read --cache-control max-age=0 --exclude "*" --include "*.html"
fi
echo "==== Cleaning up ===="
rm -rf $PACKAGE
exit 0
Комментарии (7)

visirok
16.03.2018 00:29Спасибо за интересную статью. Я от этой области далековат и для меня многие детали оказались очень интересными.

Stas911
16.03.2018 03:37Интересная статья, а из каких соображений выбрана такая архитектура, а не стандатные сервисы AWS и Лямбды?

gnemtsov Автор
16.03.2018 11:46Cognito, S3 и CloudFront — все это в общем-то стандартные сервисы AWS.
Что касается Лямбды. Мы пошли по пути приложения без бэкенда, потому это самый экономичный и самый эффективный вариант. Экономичный, потому что весь код работает только в браузере на компьютере пользователя, и мы за это ничего не платим. Эффективный, потому что взаимодействие с хранилищем происходит напрямую без «прослойки» в виде бэкенд-кода.
Правда, опять же есть и обратная сторона медали. Так как весь код приложения доступен пользователям, труднее предотвращать XSS, контролировать лимит на хранение данных и некоторые другие аспекты.

ckpunT
16.03.2018 13:26Наверное, я сильно перемудрил и можно было бы вывести гораздо проще, учитывая то, что фигуры представляют собой равнобокие трапеции…
С формулой объема усеченного конуса проще будет.ckpunT
16.03.2018 21:02Неверно я подсказал с конусом :(
Если разложить равнобокую трапецию (корзину) с основаниями A (нижнее), B (верхнее), высотой H и площадью S = (1 / 2) * (A + B) / H (1)
на простые фигуры, то получим прямоугольник, со сторонами A и H, и 2 прямоугольных треугольника с катетами C = (B — A) / 2 (2) и H.
Из формулы (2) выведем B = 2 * C + A и подставим в формулу (1) => S = (1 / 2) * (A + 2 * C + A) / H = (1 / 2) * (2 * A + 2 * C) / H = (A + C) / H => H = S / (A + C) (3)
A и S (100% заполнение корзины) константы. Если же нам надо заполнить корзину на определенный процент k (от 0 до 1) от S и взяв во внимание линейное изменение катета C' в зависимости от высоты H', то из формулы (3) следует H'(k) = (k * S) / (A + k * C').
Получается что координаты верхнего основания высчитываются:
y(B) = y(A) + H'
x(B)1 = x(A)1 — C'
x(B)2 = x(A)2 + C'
Нижние же координаты никуда не «едут».gnemtsov Автор
17.03.2018 19:09Площадь равнобедренной трапеции равняется произведению полусуммы оснований на высоту. А у вас в первой формуле идет деление на высоту, по-моему ошибка.
В целом, согласен, что можно вывести гораздо проще, чем у меня. Благодаря тому, что тут равнобедренные трапеции, — частный случай многоугольника. Зато мой вариант позволяет применять его к любым четырехугольникам.
jodaka
«в мобильных браузерах нет консоли разработчика».
Вообще-то есть, и довольно давно. Например, можно подключаться к мобильному хрому из dev консоли десктопного хрома.