Вот уже 12 лет я занимаюсь обслуживанием ИТ-систем на промышленных предприятиях. Очень часто работодатели ставят передо мной весьма интересную задачу: сделать так, чтобы ИТ-системы работали без сбоев и с минимально возможным операционным бюджетом.
Для реализации этой цели я использую «деформированную» ITIL. Началось все со смены терминологии. Дело в том, что заводами руководят люди старой закалки. Они плохо понимают значение «Problem Management». Но очень хорошо знают, что такое «устранение аварий». Поэтому рассказывать о «проактивном управлении проблемами» все равно, что о стенку головой биться. Оплачивать эту заморскую диковинку они не хотят.
А вот когда говоришь о «безаварийной эксплуатации оборудования» начинают слушать очень внимательно. Ведь аварии — это простои оборудования, сорванные сроки поставок. Это нервы, это деньги. Руководство заводов не хочет аварий. Поэтому готово вкладывать ресурсы в эксплуатацию без аварий.
Но изменением терминологии ITIL дело не ограничивалось, изменения затрагивают и процессную модель. Плохо это или хорошо – прочитайте статью до конца и решите сами.
В упрощенном виде безаварийную модель эксплуатации ИТ-оборудования можно разделить на два процесса.
Зеленая ветка – усеченная версия процесса «Управление инциндентами». Его цель – обеспечить ежедневное функционирование ИТ-систем. Это «обслуживание по факту», т.к. мы приступаем к работе только после получения информации о произошедшем инциденте.
Красная ветка — плановое техническое обслуживание (ТО). Задача этого блока мероприятий – поддерживать исправное состояние оборудования и коммуникаций в течение всего срока службы. Чтобы не допустить возникновения инцидентов мы по заранее составленному плану ликвидируем причины их появления.
По моим оценкам, грамотно спланированное и правильно реализованное ТО позволяет на 50-70% снизить количество обращений пользователей за поддержкой. И поскольку планирование технического обслуживания сделано совсем не по ITIL, стоит рассмотреть эту процедуру более подробно.
Во-первых, хочу отметить, что ТО в моем понимании складывается из нескольких видов работ:
Небольшое отступление. Помните, с описания какой цели я начал эту статью? Cделать так, чтобы ИТ-оборудование работало без сбоев и с минимальным операционным бюджетом.
Скорее всего, что системы и оборудование, задействованные в основных бизнес-процессах, будут наиболее важны для работодателя. И при обслуживании таких систем он сделает акцент на «работа без сбоев». В этом случае нужно большее внимание уделить предупредительным работам. Для вспомогательных систем во главу угла, скорее всего, встанет «с минимальным бюджетом». В этом случае нужно внедрять профилактические работы и текущие ремонты. У нас эти моменты решаются через SLA, но это тема другой статьи.
Во-вторых, хочу отметить, чтобы персонал ИТ-службы смог качественно провести техническое обслуживание, он должен быть обеспечен документацией на проведение ТО.
Фундаментом для организации ТО является перечень работ по каждой группе оборудования. В качестве примера привожу фрагмент нашего перечня работ по обслуживанию ПК.
Т.е. это простой «чеклист» для обслуживающего персонала. Составив такой перечень можно переходить к формированию графика ТО оборудования. Но что бы проводимые работы были обоснованными и максимально эффективными, стоит подготовить еще несколько документов:
Руководства по эксплуатации основных ИТ-систем (ЛВС, учетная система и т.д.). В таких документах должно содержаться общее описание ИТ-систем, описание действий персонала в штатном режиме работы, определение зон ответственности и обязанностей команд эксплуатации.
Планы послеаварийного восстановления (DRP). В этих документах должны быть описаны наиболее вероятные отказы в работе ИТ-систем и пошаговые процедуры восстановления работоспособности. Кроме этого должны быть описаны программы тестирования планов.
Из этих документов в график работ «перекочуют» действия обслуживающего персонала в штатном режиме (в основном это проверка log-файлов) и процедуры по тестированию DRP (замена жесткого диска в сервере с целью проверки работы RAID и т.д.).
Третий момент, на котором хочу заострить ваше внимание. Чтобы графики ТО наиболее точно соответствовали потребностям бизнеса в отказоустойчивости оборудования, нужно учитывать несколько факторов: плановый срок службы комплектующих, рекомендации производителя оборудования по проведению ТО, фактические условия эксплуатации. Что это значит на практике? В частности то, что для групп оборудования, находящегося в разных условиях эксплуатации, стоит сделать разные графики обслуживания.
К примеру мы разрабатываем отдельные графики обслуживания ПК в офисных и в производственных помещениях. Компьютеры в офисе размещены на столах или напольных подставках, влажная уборка помещений осуществляется ежедневно. В производственных помещениях хоть и делают влажную уборку каждый день, все равно очень пыльно. Поэтому ТО в офисе проводим 2 раза в год. Первый раз в мае, второй раз в ноябре. А вот в производственных помещениях ТО проводится ежемесячно. Перечень работ я указывал выше.
На этом я бы хотел пока остановиться и узнать мнение уважаемого сообщества.
Для реализации этой цели я использую «деформированную» ITIL. Началось все со смены терминологии. Дело в том, что заводами руководят люди старой закалки. Они плохо понимают значение «Problem Management». Но очень хорошо знают, что такое «устранение аварий». Поэтому рассказывать о «проактивном управлении проблемами» все равно, что о стенку головой биться. Оплачивать эту заморскую диковинку они не хотят.
А вот когда говоришь о «безаварийной эксплуатации оборудования» начинают слушать очень внимательно. Ведь аварии — это простои оборудования, сорванные сроки поставок. Это нервы, это деньги. Руководство заводов не хочет аварий. Поэтому готово вкладывать ресурсы в эксплуатацию без аварий.
Но изменением терминологии ITIL дело не ограничивалось, изменения затрагивают и процессную модель. Плохо это или хорошо – прочитайте статью до конца и решите сами.
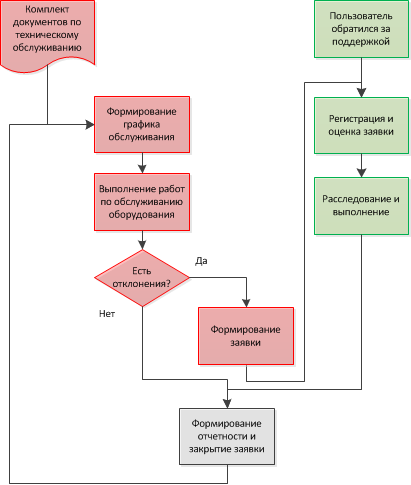
В упрощенном виде безаварийную модель эксплуатации ИТ-оборудования можно разделить на два процесса.
Зеленая ветка – усеченная версия процесса «Управление инциндентами». Его цель – обеспечить ежедневное функционирование ИТ-систем. Это «обслуживание по факту», т.к. мы приступаем к работе только после получения информации о произошедшем инциденте.
- Если у пользователя возникает потребность в помощи ИТ-специалистов, он отправляет заявку на обслуживание в ServiceDesk.
- ИТ-специалисты принимают обращение в работу, классифицируют, анализируют его и приступают к решению.
- После выполнения заявки вносят в ServiceDesk информацию о проделанной работе и использованных ТМЦ (необходимо для планирования закупок на следующий период).
Красная ветка — плановое техническое обслуживание (ТО). Задача этого блока мероприятий – поддерживать исправное состояние оборудования и коммуникаций в течение всего срока службы. Чтобы не допустить возникновения инцидентов мы по заранее составленному плану ликвидируем причины их появления.
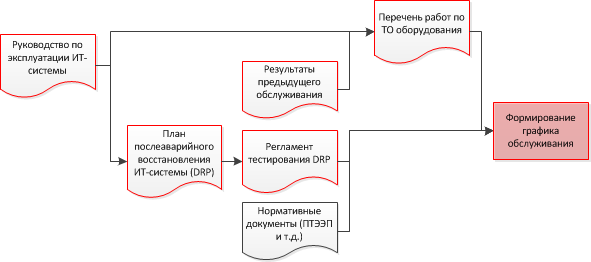
- В конце года руководитель ИТ-службы составляют графики ТО на следующий год. При этом используются документы: перечень работ технического обслуживания, руководство по эксплуатации, планы послеаварийного восстановления.
- В течение года (в соответствии с составленным расписанием) через ServiceDesk выдаются задания на конкретную работу по обслуживанию оборудования.
- Сотрудник ИТ-службы выполняет предписанный регламентом перечень работ. Если обнаруживает отклонение от нормального функционирования системы – создает заявку в ServiceDesk.
- После завершения работ заносит информацию в ServiceDesk информацию о проделанной работе и использованных ТМЦ.
По моим оценкам, грамотно спланированное и правильно реализованное ТО позволяет на 50-70% снизить количество обращений пользователей за поддержкой. И поскольку планирование технического обслуживания сделано совсем не по ITIL, стоит рассмотреть эту процедуру более подробно.
Во-первых, хочу отметить, что ТО в моем понимании складывается из нескольких видов работ:
- Планово-предупредительные работы. Проводятся строго по графику, без привязки к фактическому состоянию оборудования. Позволяют точно планировать запасы комплектующих частей и свести к минимуму отказы оборудования. Могут осуществляться персоналом средней квалификации, но требуют значительных финансовых расходов (т.к. меняем еще рабочее детали, держим внушительный запас комплектухи на складе).
- Планово-профилактические работы. Инициируются с учетом текущего состояния оборудования, поэтому требуют высокой квалификации обслуживающего персонала и вложений в инструменты диагностики. Но позволяют минимизировать затраты на комплектующие материалы.
- Нормативное обслуживание. Выполняются в соответствии с требованием надзорных органов и нормативных документов (ПТЭЭП и т.д.). ИТ-служба редко сталкивается с такими работами, поэтому заострять внимание на них не будем.
- Текущий ремонт. Проводится раз в несколько лет с целью продлить нормативный срок службы оборудования и коммуникаций.
Небольшое отступление. Помните, с описания какой цели я начал эту статью? Cделать так, чтобы ИТ-оборудование работало без сбоев и с минимальным операционным бюджетом.
Скорее всего, что системы и оборудование, задействованные в основных бизнес-процессах, будут наиболее важны для работодателя. И при обслуживании таких систем он сделает акцент на «работа без сбоев». В этом случае нужно большее внимание уделить предупредительным работам. Для вспомогательных систем во главу угла, скорее всего, встанет «с минимальным бюджетом». В этом случае нужно внедрять профилактические работы и текущие ремонты. У нас эти моменты решаются через SLA, но это тема другой статьи.
Во-вторых, хочу отметить, чтобы персонал ИТ-службы смог качественно провести техническое обслуживание, он должен быть обеспечен документацией на проведение ТО.
Фундаментом для организации ТО является перечень работ по каждой группе оборудования. В качестве примера привожу фрагмент нашего перечня работ по обслуживанию ПК.
- Опрос пользователя о недостатках в работе оборудования.
- Проверка целостности наклеек с инвентарным номером и номером лицензии.
- Осмотр электрических кабелей подключенного оборудования.
- Проверка S.M.A.R.T. HDD, при необходимости тестирование HDD.
- Осмотр компонентов системного блока (материнская плата, блок питания, соединительные кабели и т.д.).
- Удаление пыли и грязи с поверхностей оборудования и внутри системного блока.
- Замена HDD, RAM, клавиатуры, мыши и других узлов (в случае выработки ресурса).
- Контроль температуры в помещении.
- Фиксация выполненных работ в ServiceDesk.
Т.е. это простой «чеклист» для обслуживающего персонала. Составив такой перечень можно переходить к формированию графика ТО оборудования. Но что бы проводимые работы были обоснованными и максимально эффективными, стоит подготовить еще несколько документов:
Руководства по эксплуатации основных ИТ-систем (ЛВС, учетная система и т.д.). В таких документах должно содержаться общее описание ИТ-систем, описание действий персонала в штатном режиме работы, определение зон ответственности и обязанностей команд эксплуатации.
Планы послеаварийного восстановления (DRP). В этих документах должны быть описаны наиболее вероятные отказы в работе ИТ-систем и пошаговые процедуры восстановления работоспособности. Кроме этого должны быть описаны программы тестирования планов.
Из этих документов в график работ «перекочуют» действия обслуживающего персонала в штатном режиме (в основном это проверка log-файлов) и процедуры по тестированию DRP (замена жесткого диска в сервере с целью проверки работы RAID и т.д.).
Третий момент, на котором хочу заострить ваше внимание. Чтобы графики ТО наиболее точно соответствовали потребностям бизнеса в отказоустойчивости оборудования, нужно учитывать несколько факторов: плановый срок службы комплектующих, рекомендации производителя оборудования по проведению ТО, фактические условия эксплуатации. Что это значит на практике? В частности то, что для групп оборудования, находящегося в разных условиях эксплуатации, стоит сделать разные графики обслуживания.
К примеру мы разрабатываем отдельные графики обслуживания ПК в офисных и в производственных помещениях. Компьютеры в офисе размещены на столах или напольных подставках, влажная уборка помещений осуществляется ежедневно. В производственных помещениях хоть и делают влажную уборку каждый день, все равно очень пыльно. Поэтому ТО в офисе проводим 2 раза в год. Первый раз в мае, второй раз в ноябре. А вот в производственных помещениях ТО проводится ежемесячно. Перечень работ я указывал выше.
На этом я бы хотел пока остановиться и узнать мнение уважаемого сообщества.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.