Теперь Даша Криворучко (так зовут десятиклассницу) переехала жить в московский интернат и спрашивает у меня, чего бы ей еще спроектировать. Я думаю, что на этом этапе карьеры ей стоит спроектировать аппаратный ускоритель нейросетей на основе систолического массива для умножения матриц. Использовать язык описания аппаратуры Verilog и ПЛИС Intel FPGA, но не дешевенький MAX10, а что-нибудь подороже, чтобы вместить большой систолический массив.
После этого сравнить производительность аппаратного решения с программой, работающей на процессоре schoolMIPS, а также с программой на Питоне, работающей на десктопном компьютере. В качестве тестового примера использовать распознавание цифр с небольшой матрицы.

Собственно все части этого упражнения уже разработаны разными людьми, но вся фишка в том, чтобы скомпоновать это в единое задокументированное упражнение, которое можно потом использовать как основу для онлайн курса и для практических олимпиад:
1) В онлайн-курсе такого рода (проектирование хардвера на уровне регистровых передач + нейросети) заинтересовано eNano, образовательное отделение РОСНАНО, которое в прошлом организовало семинары Чарльза Данчека по проектированию современной электроники (маршрут RTL-to-GDSII) для студентов и сейчас работает над облегченным курсом для продвинутых школьников. Вот мы с Чарльзом у их офиса:

2) В базе для олимпиад может быть заинтересованы Олимпиады НТИ, с которыми я затронул этот вопрос пару недель назад в Москве. К такому примеру участники олимпиад могли бы добавлять хардвер для разных функций активации. Вот коллеги из Олимпиад НТИ:

Так что если Даша это разработает, она теоретически может внедрить свой хорошо описанный акселератор и в РОСНАНО, и в Олимпиады НТИ. Я думаю, для администрации ее школы это было бы выгодно — можно было бы по телевизору показать или вообще на конкурс Intel FPGA отправить. Вот пара россиян из Санкт-Петербурга на финале конкурса Intel FPGA в Санта-Клара, Калифорния:

Теперь поговорим про техническую сторону проекта. Идея акселератора систолического массива описана в статье, которую перевел редактор Хабра Вячеслав Голованов SLY_G Почему TPU так хорошо подходят для глубинного обучения?
Так выглядит dataflow граф нейросети для простого распознавания:

Примитивный вычислительный элемент, который выполняет умножения и сложения:

Сильно конвейеризованная структура из таких элементов, это систолический массив для умножения матриц и есть:

В интернете есть куча кода на Verilog и VHDL с реализацией систолического массива, например код вот под этим блог-постом:

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9);
parameter data_size=8;
input wire clk,reset;
input wire [data_size-1:0] a1,a2,a3,b1,b2,b3;
output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9;
wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69;
pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1));
pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2));
pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3));
pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4));
pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5));
pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6));
pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7));
pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8));
pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9));
endmodule
module pe(clk,reset,in_a,in_b,out_a,out_b,out_c);
parameter data_size=8;
input wire reset,clk;
input wire [data_size-1:0] in_a,in_b;
output reg [2*data_size:0] out_c;
output reg [data_size-1:0] out_a,out_b;
always @(posedge clk)begin
if(reset) begin
out_a<=0;
out_b<=0;
out_c<=0;
end
else begin
out_c<=out_c+in_a*in_b;
out_a<=in_a;
out_b<=in_b;
end
end
endmodule
Замечу, что этот код не оптимизирован и вообще корявый (и даже непрофессионально написан — исходник в посте использует блокирующие присваивания в @ (posedge clk) — я это поправил). Даша могла бы например использовать конструкции Verilog generate для более элегантного кода.
Кроме двух экстремальных реализаций нейросети (на процессоре и на систолическом массиве) Даша могла бы рассмотреть и другие варианты, которые быстрее чем процессор, но не такие прожорливые на операции умножение как систолический массив. Правда это уже скорее не для школьников, а для студентов.
Один вариант — это выполняющее устройство с большим количеством параллельно работающих функциональных блоков, как в Out-of-Order процессоре:

Другой вариант — это так называемый Coarse Grained Reconfigurable Array — матрица из квази-процессорных элементов, у каждого из которых есть небольшая программа. Эти процессорные элементы идейно похожи на ячейки ПЛИС/FPGA, но оперируют не с отдельными сигналами, а с группами бит / числами на шинах и в регистрах — см. Прямой репортаж с рождения крупного игрока в аппаратном AI, который ускоряет TensorFlow и конкурирует с NVidia".
Теперь собственно исходное письмо от Даши:
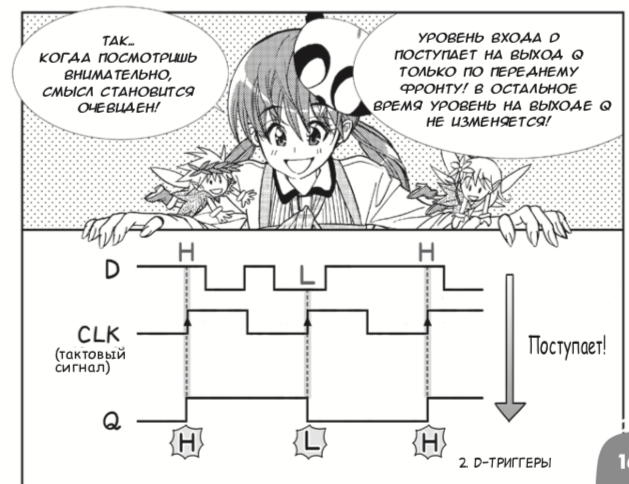
Доброго времени суток, Юрий.Даша учила Verilog и проектирование на уровне регистровых передач с помощью меня и книжки Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера». Однако если вы школьник/школьница и хотите понять основные концепции ну на совсем простом уровне, то для вас издательство ДМК-Пресс выпустило русский перевод японской манги 2013 года про цифровые схемы, созданной Амано Хидэхару и Мэгуро Кодзи. Несмотря на несерьезную форму изложения, книжка корректно вводит логические элементы и D-триггеры, после чего привязывает это к ПЛИС-ам:
Я в 2017 году в ЛШЮПе училась в у вас в мастерской и в октябре 2017 года участвовала в конференции в Томске в октябре того же года с работой посвящённой встраиванию блока умножения в процессор SchooolMIPS.
Я бы сейчас хотела продолжить эту работу. В данный момент мне удалось получить разрешение в школе взять эту тему в качестве небольшой курсовой. У вас есть возможность помочь мне с продолжением данной работы?
P.S. Поскольку работа делается в определенном формате, требуется написание введения и литературного обзора темы. Посоветуйте, пожалуйста, источники, из которых можно взять информацию по истории развития данной темы, по философиям архитектур и прочее, если у вас есть такие ресурсы на примете.
Плюсом, в данный момент я проживаю в Москве в школе-интернате, возможно, будет проще осуществлять взаимодействие.
С уважением,
Дарья Криворучко.
Вот как выглядела Летняя Школа Юных Программистов в Новосибирской области, где Даша выучила Verilog, ПЛИС, методологию разработки на уровне регистровых передач (Register Transfer Level — RTL):


А вот выступление Даши на конференции в Томске вместе с другим десятиклассником, Арсением Чегодаевым:
После выступления Даша со мной и с Станиславом Жельнио sparf, главным создателем учебного процессорного ядра schoolMIPS для реализации на ПЛИС:

Проект schoolMIPS находится с документацией на https://github.com/MIPSfpga/schoolMIPS. В простейшей конфигурации этого учебного процессорного ядра всего 300 строк на Verilog, в то время как в промышленном встроенном ядре среднего класса примерно 300 тысяч строк. Тем не менее, Даша смогла почувствовать, как выглядит работа проектировшиков в индустрии, которые точно так же меняют декодер и выполняющее устройство, когда добавляют в процессор новую инструкцию:
В заключение приведем фотографии декана Самарского Университета Ильи Кудрявцева, который заинтересован в создании летней школы и олимпиад с процессорами на ПЛИС для будущих абитуриетов:

И фотографию сотрудников зеленоградского МИЭТ, которые уже планируют такую летнюю школу в следуюшем году:

И в одном, и в другом месте должны хорошо пойти как материалы от РОСНАНО, так и возможные материалы Олимпиады НТИ, а также наработки, которые сделаны в последние пару лет во внедрении ПЛИС и микроархитектуры в программу университетов ВШЭ МИЭМ, МГУ и казанского Иннополиса.
Комментарии (65)

berezuev
07.12.2018 12:38+1Прочитал статью и с тоской вспомнил свои школьные годы, где учитель на серьезных щах объясняла, что BSOD появляется, когда компьютер заражен вирусами…
YuriPanchul Автор
07.12.2018 12:43Ну вы ему объяснили про виртуальную память, user/kernel mode итд?
berezuev
07.12.2018 12:54Ей. Но, к сожалению, это была крайне твердолобая особа… Из тех, кто считает, что «яйцо курицу не учит». Один раз даже до завуча дошло дело, но та развела руками, ибо ругать меня было не за что :)
Jump
07.12.2018 16:52+2А что еще ему было объяснять? Человек первый раз в жизни увидел компьютер, прочитал кривую инструкцию и ему приходилось учить.
Ну не было тогда учителей по этому предмету, и вели его по совместительству учителя физики, или математики.tormozedison
08.12.2018 09:09Так было, когда предмет «основы информатики и вычислительной техники» только начинался. Уже к 1992-му (где как) для этого начали появляться отдельные учителя. А сначала да, математики и физики к преподаванию привлекались.
IvanTamerlan
09.12.2018 00:492 десятилетия спустя все точно также в какой-нибудь глубинке. Учил самостоятельно TurboPascal в школе (ничего другого подоступнее не было), чтобы в универе учить TASM. Хотел как-то научиться управляться с компьютером, но воз и нынче там. Причем под управлением подразумеваю не тыкать мышкой/клавиатурой в соцсети (тогда их не было), а контроль на уровне — какой код можно выполнять, а какой нет. Смотреть в любой момент память или состояние регистров процессора, выполняемые задачи и т.д. И при этом понимать что вообще происходит! До такого состояния как до Луны. Хотя нет, до Луны ближе.
Mike_soft
10.12.2018 08:30литературы по этой теме сейчас (точнее, не только сейчас, а уже лет 30 как) — более чем достаточно. как бумажной, так и электронной. Как для «соответсвующих специальностей ВУЗов», так и для школьников. начиная от «энциклопедии профессора фортрана», и заканчивая упомянутой Харрис&Харрис.
Для практики начиная от поиска где-нибудь на авито какого-нибудь УМПК-80/УМПК-51 (или эмулятора процессора), и заканчивая пинбордой с изиэлектроникс (или платой FPGA с алиэкспресса)…
AntonSazonov
07.12.2018 13:04-1Не по теме, не в обиду, а вы спите тоже с "натянутой" улыбкой?
YuriPanchul Автор
07.12.2018 20:45Это такой местный американский социальный протокол. Входит в привычку. С волками жить — по волчьи выть.
matabili1973
07.12.2018 13:43Пожелаем Даше, чтобы ее фамилия никак не повлияла на ее умения и результаты ее труда. А у меня дилетантский вопрос:
Чему надо научиться, чтобы я смогу сделать что-то похожее? Насколько высок порог вхождения в эту область?qw1
07.12.2018 13:50Звучит как «как мне захотеть». Тут уж или интересно, и тогда хватаешь любую информацию и сразу бросаешься проверять на практите, или не интересно, и тогда «ну нафиг, почитаю лучше Хабр или посмотрю сериал».
matabili1973
07.12.2018 15:08Проблема в том, что я не знаю, чего конкретно захотеть: гуманитарий, у которого точные науки кончились после 8 класса школы, вряд ли в состоянии оценить, какой общеобразовательный багаж нужен, чтобы разобраться в строении компьютерного железа. А Хабр читать, по-моему, очень полезно, если с разбором.
YuriPanchul Автор
07.12.2018 20:49+1Если вы скачаете книжку «Цифровая схемотехника и архитектура компьютера» Дэвида и Сары Харрис, и начнете ее читать, вы очень быстро сориентируетесь что вам нужно. Книжка написана с нуля, с уровня 8 класса, и идет вплоть до обзора продвинутых микроархитектур, по пути обучая двум языкам описания аппаратуры, синтезируемому подмножеству, основам архитектуры, цифровой схемотехнике итд.
matabili1973
07.12.2018 22:16Спасибо за подсказку.
tchspprt
08.12.2018 14:04На самом деле таки вредный совет.
Харрис&Харрис, как бы её не позиционировали авторы, имеет не нулевой порог вхождения. Совсем. А для гуманитария это окажется полным адом из-за количества информации, которую придётся переваривать (пусть и язык не самый сложный).
Вам нужен «Код. Тайный язык информатики» Петцольда. По-моему, для полных нулей соотношение осиляемости Петцольда к осиляемости Харрис&Харрис примерно равно соотношению осиляемости Х&Х к «Архитектуре» Танненбаума.
wormball
07.12.2018 14:01+1> Пожелаем Даше, чтобы ее фамилия никак не повлияла
Имя тоже хорошее. Так и просится заголовок «Помоги Даше сделать нейроускоритель на ПЛИС».
И сама Даша подозрительно похожа на автора.REPISOT
07.12.2018 14:50Статья вроде про «Десятиклассницу из Сибири», а на фото какие-то левые мужики…
8street
07.12.2018 18:35+1По-моему производительность с питоном сравнивать не нужно. И так ясно будет. Если только он не использует open cl с какой-нибудь среднестатистический видеокартой.

vectorplus
07.12.2018 20:49У Гугла же вроде есть свои TPU для тензорфло. Когда можно будет попробовать нейросетки запустить на ускорителях от Wave?
Шлю лучи поддержки за работу с российской молодёжью, спасибо! :)
eyellow
07.12.2018 20:49Оффтоп, но… Почему-то сейчас мне надо сделать усилие, чтобы прочитать РОСНАНО именно как роснано, а не ПОЧАХО.
ineganov
07.12.2018 20:50+5Ну правильно, комменты о фамилии, внешнем виде и БолгенОС.
Меж тем, предложенный проект весьма непрост, хотя, казалось бы, циферки — это даже не котят распознавать.
Если брать, например, Ленет, то несжатые коеффициенты не влезут в набортную память недорогих ПЛИС. О более крупных сетях я даже не говорю.
А значит, нужно как-то планировать вычисления: загрузить часть коэффициентов, применить, загрузить следующую.
Вот какую именно и в каком именно порядке — нетривиальное решение для сверточных сетей, особенно когда надо целиком уместиться в 128 кбайт и при этом не быть безнадежно тормознутым. Ну, вот, в частности, если хочется выгружать хотя бы по 16 коэффициентов из однопортовой памяти за раз, нужно чтобы они были расположены рядом. Если брать стандартный row-major alignment из всяких кафе и тензорфлоу, то хорошо будут работать первые слои, а если col-major из Julia с матлабом, то последние. И видимо, нужно или городить многопортовую память, или хитро готовить данные в зависимости от слоя. Кажется, именно последнее делает nvidiа и movidius, но как именно, они, конечно, не спешат рассказывать. Еще туда же: некоторые университетские реализации эту проблему вообще не решают и говорят, что у нас будут только сверточные слои.
Другая проблема — переполнение/нормализация. В выгодном на ПЛИС целочисленном режиме за этим нужно внимательно следить. Настолько внимательно, что, кажется, проще использовать аппаратное FP. В принципе, если выкинуть denormals, то оно не такое страшное и вполне компактное для фп16. Другой (куда более модный) подход — угореть по одно- двух- или четырехбитным коеффициентам. Это реально работает (тм), куча статей с историями успеха, но этот путь явно сложнее.
Так что да, проект крутой, несмотря на весь хайп и определенно менее затасканный, чем свой процессор.
В качестве идеи, можно использовать сенсор от оптической мышки и радостно демонстрировать realtime распознавание. Даром, что для этого не нужна такая уж прямо скорость :)YuriPanchul Автор
07.12.2018 20:54Да ладно, Илья, пусть распознает цифирьки с минимальной матрицы 3x5 (15 пикселей), а константы хардкодит. Использовать для inference fixed point, а floating point оставить для трейнинга, который делать на десктопе на питоне. И 15 пикселей вводить кнопочками. Что, так не будет работать?
ineganov
08.12.2018 01:09+1Ну, так конечно будет работать, но тогда теряется интерес. Рукописного ввода прямо карандашом на листочке не будет, да и сама сеть не нужна: 15 бит можно полностью покрыть table lookup-ом :)
А в LeNet'е ценность в том, что он хоть и маленький, но полностью настоящий. Учебно-боевой. Но там, если мне память не изменяет, 400k коэффициентов.YuriPanchul Автор
08.12.2018 02:22Нужно иметь весь спектр, от тривиального до интересного. Так чтобы можно было еще строить графики размера, частоты, accuracy — чтобы был просто для олимпиадства и чтобы шло на всех платах — от плат за $20 до плат за $20,000. Сейчас благо этим интересуется МИЭТ, МИЭМ, Самара, РОСНАНО итд — так что разные варианты работ и проектов упражнений можно раскидать на кучу людей с разным уровнем skills.
YuriPanchul Автор
08.12.2018 02:35+1Кстати, сразу исследовательский вопрос для школьно-десятиклассного проекта: при каком N размер и эффективность систолического массива становится выгоднее, чем lookup table? Может реализовать так и так и померять.
Xalium
07.12.2018 22:56+2особо не программист, но к примеру не понимаю, зачем вообще нейросейти и им подобное экспериментировать на слабых ПЛИС? Только для опыта оптимизации?
Ведь в реальности все равно нейросети не стоят и в ближайшее время не будут стоят в каждом доме. Это удел корпораций, которые предоставляют (захотят/могут предоставить) к себе доступ.YuriPanchul Автор
07.12.2018 23:44*** зачем вообще нейросейти и им подобное экспериментировать на слабых ПЛИС? Только для опыта оптимизации? ***
Потому что принципы RTL (Register Transfer Level) одинаковы и для слабых ПЛИС и для 7-нм чипа с миллиардами транзисторов, над которым я сейчас работаю. Это опыт разработки.
*** Ведь в реальности все равно нейросети не стоят и в ближайшее время не будут стоят в каждом доме ***
Именно сейчас я работаю над конфигурируемым IP блоком ускорителя нейросетей, который будет использоваться как в тяжелых устройствах типа ящиков для data-центров, так (в небольшой конфигурации) и в мобильных устойствах и других применениях on edge (например распознавании вашего лица телефоном или датчиком итд).Xalium
08.12.2018 01:03Потому что принципы RTL (Register Transfer Level) одинаковы и для слабых ПЛИС и для 7-нм чипа с миллиардами транзисторов, над которым я сейчас работаю. Это опыт разработки.
Здесь больше вопрос не в скорости обработки, а в кол-ве памяти. Загрузка кучи маленьких пакетов данных намного медленнее, чем одного большого пакета.
Именно сейчас я работаю над конфигурируемым IP блоком ускорителя нейросетей, который будет использоваться как в тяжелых устройствах типа ящиков для data-центров, так (в небольшой конфигурации) и в мобильных устройствах и других применениях on edge (например распознавании вашего лица телефоном или датчиком и т.д.).
ну заточка на один/группу объектов — это не совсем одно и то же, что выделить/определить кучу однотипных объектов, т.к. однотипность понятие растяжимое.
Т.е. в 1-ом случае ищем сами объекты (т.е. определение конкретики), во 2-м – ищет объекты, имеющие какую-то общность (т.е. определение типа), а это как раз проблема. И во 2-м случае проблема не только в самом «процессоре», но и в объеме инфы, за счет которой он улучшается. Эту инфу надо где-то хранить.
Jef239
08.12.2018 00:24В реальности во многих карманах есть смартфон со специальным чипом для нейросети. Той самой, что из шума выделяет«ОК, Google» или «слушай, Алиса».
Так что в каждой многоэтажке уже есть такой чип.Xalium
08.12.2018 01:11Той самой, что из шума выделяет«ОК, Google» или «слушай, Алиса».
Именно эти слова можно и без всяких чипов хранить. Я на определенные фразы старую русскую прогу «Дракон» (типа того, не помню как точно наз-ся) натаскивал. Нормально определяла. И эти «гугл ок/алисы» один фиг дальнейшую фразу без инета не поймут, т.к. обработка твой фразы идет на их серверах.Jef239
08.12.2018 01:17+1Хранить — можно. Выделять из фонового шума, не посадив при этом батарейку за сутки — вряд ли. Сопроцессор нужен ровно потому, что его энергопотребление на порядок меньше, а работать он должен постоянно.
Xalium
08.12.2018 08:35Хранить — можно.
Хранить что? На изначальную фразу прога уже заточена. А на распознавание остального уже нужно намного большая нейросеть.Jef239
08.12.2018 10:09Именно эти слова можно и без всяких чипов хранить.
Xalium
08.12.2018 10:56+1понял.
P.S. Но все равно для части из этого какой особый сопроцессор не нужен. Снимать уровень звука ? ниже какого-то уровня ? дальше не реагировать. Подавление шума уже тоже есть. И т.п.
P.S.
Что вообще делает этот нейроспроцессор? Т.е. что вообще в него вводится и что выводится?qw1
08.12.2018 11:50+1Снимать уровень звука ? ниже какого-то уровня ? дальше не реагировать
То есть, если человек работает в шумном месте, у него батарейка постоянно будет высаживаться за 6 часов?Xalium
08.12.2018 13:45Вообще то дальше было написано
Подавление шума уже тоже есть. И т.п.
qw1
08.12.2018 19:00+1Тут скорее не про шум, а про галдёж вокруг. Например, человек работает на вокзале или на рынке, где вокруг постоянные разговоры. Какой должен быть подавитель шума, чтобы отсечь галдёж, но не отсечь кодовую фразу.
Jef239
08.12.2018 22:51Можно и без шумного места — просто включенное радио или телик. Там не шум — там разговоры.
Jef239
08.12.2018 23:35А какая разница? В тихом месте тоже надо будет запитывать АЦП, и CPU c FPU для шумодавителя и анализатор громкости. Разница с полным анализом на основном проце — будет процентов 20 энергопотребления. Все равно одно ядро будет постоянно активно, а это уже немало.
Jef239
08.12.2018 22:50Основное — это голосовая активация с потреблением 650мкА. Да, можно и на процессоре, вот потребление будет в 100 раз больше, то есть в районе 65 мА. Все-таки нужно включить таймеры, CPU, FPU, АЦП… а с учетом, что там linux — так и вообще почти весь процессор.
P.S.
Снимать уровень звука ? ниже какого-то уровня ? дальше не реагировать.
Без процессора??? Как? АЦП у вас в процессоре, чтобы определить уровень громкости — нужен CPU и FPU. С учетом, что там linux, а не RTOS, фактически для этого должен быть включен (запитан) весь процессор. А запитанные части процессора потребляют энергию, независимого от того, используются они или нет. Просто если используются — потребляют совсем много.
Я вам по одному из своих GPS-ных чипов скажу
«РЕЗЕРВ» — 8мкА
«ВЫКЛЮЧЕН» — 150 мкА
СОН — 5 мА
ЭНЕРГОСБЕРЕЖЕНИЕ — 10 мА
«ОБНУЛЕН» — 20 мА
РАБОТА — 50 мА
ЗАПУСК — 110 мА
CrashLogger
08.12.2018 09:10+1За сутки? У меня без всяких нейросетей ни один смартфон до вечера не доживал.
ianzag
07.12.2018 21:36+3После девочка пойдет в Интел. Который в один прекрасный момент закроет свое очередное (к тому моменту уже последнее) представительство в РФ. Предложив офер с релокейшеном для тех немногих, кого считает интересными. Потом скорее всего Калифорния (хотя именно Интел живет вроде севернее?). Потом… ну там как сложится сложно загадывать.
YuriPanchul Автор
07.12.2018 21:42+1Штаб-квартира Интела в Санта-Клара, Калифорния, самом центре Silicon Valley. Отделение Интела в Портланд, Орегон значительное, но возникло позже.
Кто-то из России уедет, кто-то не уедет. В Silicon Valley гораздо менее живая социальная жизнь, чем в Москве.ianzag
07.12.2018 22:20+1> Кто-то из России уедет, кто-то не уедет. В Silicon Valley гораздо менее живая социальная жизнь, чем в Москве.
По мне так это лишь в плюс Долине :)YuriPanchul Автор
07.12.2018 23:39+2Я живу в Долине более 25 лет и могу сказать на основе опыта, что первые несколько лет вы будете заняты изучением нового окружения, но лет через 15-20 вы почувствуете ценность российского культурного окружения. Мне хоть моя жизнь в Калифорнии нравится (продвинутые коллеги на переднем краю), походы по холмам с ихучением местной флоры, но я с большим удовольствием езжу регулярно в Москву и вообще хотел бы проводить там несколько месяцев в году.
ianzag
08.12.2018 00:23> но я с большим удовольствием езжу регулярно в Москву и вообще хотел бы проводить там несколько месяцев в году.
И это тоже вариант. Почему нет? Если позволяет время (главное) и финансы (иначе смысл в Долине?) то вполне себе.
ankh1989
08.12.2018 07:23Очень круто выглядит. Не удивлюсь если лет через 20 аппаратные ускорители нейросетей будут бизнесом с оборотом в сотни миллиардов долларов. На её месте, я бы действовал так:
— Серьёзно заняться этим проектом с прицелом на то как это можно будет встроить в телефоны. Какие нейросети самые популярные? Распознавание картинок? Что там ещё? Вот для них и сделать интересную демку. Идеальная демка выглядит примерно так: мы взяли нейросеть ResNet50, сделали её в софте и на нашем железе и получили разницу в скорости и энергопотреблении в 1000 раз и при этом мы даже не начали ещё ничего оптимизировать. Сделали акцент на то, что если такая фигня будет в телефонах, они смогут распознавать картинки гораздо лучше (одна из киллер фич нового Пикселя это именно распознавание текста камерой).
— Учить английский. Доходы и профессиональные возможности прежде всего зависят от того где вы работаете. Больших высот в Роснано не достичь.
— Подавать на internship в Гугл, Интел, NVidia и т.д. Судя по статье, она могла бы уже сейчас там работать. Представьте, что будет через 10 лет. За один internship летом вам дадут ну… тыщ 25 долларов.
— Получать диплом бакалавра или магистра и валить на следующий день. Диплом это пустая формальность, но он должен быть и на нём должны быть написаны правильные слова про математику и компьютерные науки. Все эти компании сейчас усиленно напирают на diversity & inclusion, поэтому оффер она получит в приоритетном порядке.
— Найти знакомых которые работают в этих компаниях и через них отправить резюме эйчарам. Можно конечно и напрямую послать, но у них там беклог из миллионов резюме и все посмотреть просто не получится. Идеальное место работы, как мне кажется, это подразделение Гугла которое занимается TPU. Там будут почти бесконечные ресурсы для всех этих ПЛИС.
По такому направлению годам к 25 можно грести в гугле пол миллиона долларов в год. Годам к 35 можно иметь некислый счёт в банке и возможность заиметь свою компанию.
tnsaturday
09.12.2018 05:04Прекрасно, в дальнейшем, надеюсь, нас ждет перенос процессора в память и изобретение новых оптических носителей информации. Смотрю и радуюсь, вот-вот 3-4 года, и пойдет ведь в продакшн!
Wilderwein
09.12.2018 05:04Во первых удачи Даше. Во вторых у меня богатый опыт в вопросах ускорения вычислений нейросети в FPGA и я бы хотел поделится опытом. Ускорение вычислений прошло несколько этапов (и я тоже :) ) попробую описать:
1) Имплементация всех слоёв сети внурти ПЛИС на VHLD/Verilog.
Работает на маленьких и очень маленьких сетях. Какого бы ни был размера ПЛИС в итоге приходим к тому что внутренних ресурсов памяти (для weights и промежуточных результатов) перестает хватать. В итоге приходится постоянно качать туда-обратно данные из веншней памяти. Сделать это с высоким КПД не тривиальная задача. Решения такие масштабируются плохо (хотим не 20 а 40 слоёв): либо Routing а то и просто кол-во свободных ресурсов подведёт. А написать всё это да так чтобы работало на 300 + MHz тоже не просто. Тут приходится выбирать между удобством соединения слоёв, модульностью и хорошо спроектированной pipeline. Из плюсов — при условии что все влезло в ПЛИС и Timing сошёлся получаем совершенно бешеный FPS (если работаем с изображениями) при низком энергопотреблении.
Итог: Лично я отказался от этого пути быстро. Ребята из Xilinx даже сделали готовый проект потратив год работы команды инжинеров, но потом у них попросили что то поменять и большая часть рабты была выброшена.
2) ПЛИС как co-processor для ARM(SoC решения) или x86.
На данный момент оба производителя ПЛИС (маленьких в расчет не беру) осознали что при постоянном росте глубины сетей ни о какой полной имплетентации в ПЛИС не может быть и речи. Размеры чипов так быстро расти не могут и всвязи с этим путь был выбран иной.
Intel PSG (Altera) выкатил свое решение для data centers (Xenon CPU + PAC) соединенные через PCIe. На плате PAC стоит ПЛИС который умеет быстро считать разные влои и функции сетей но в 1 экземпляре. Задача CPU «кормить» очень быстрые модули на ПЛИС и считать самому то что ПЛИС не поддерживается.
Xilinx сделал что то очень похожее совместно с Amazon. Плюс они так же поддерживают Embedded решения. Там работу x86 выполняет встроенный ARM. Работает но не так густро как с 86-ым. Сдругой стороны — не везде 86-ой можно впихнуть: прожорливы и громоздки.
Как мне кажется — именно этот путь имеет шанс на успех. Эти решения реально рабоатют, пусть они пока только «в пеленках». Тем более что производители увеличивают количество поддерживаемых ПЛИС функций а за счет этого растет и скорость вычислений.
Если Даша хочет серьёзно подойти в ускорению вычислений — стоит задуматься о написании своего co-processor. Это не всё конечно. Нужна оптимизация и квантазация сети. Но с co-processor можно начать.
kaleman
У меня школьники всегда вызывают подозрение в создании очередной Болген ос.
YuriPanchul Автор
В учебных процессорных ядрах и систолических массивах строк кода меньше, легче проверить на легитимность проекта
PKav
Вы считаете это опасным? Ведь они всё-равно не получат большого финансирования — общественный резонанс не позволит.
myxo
Не скажу, что подозрение совсем несправедливо, но это все-таки редкость. Я имею в виду такое несоответствие того что сделали с тем как представили.
ps. Мы в ЛШЮП такой фигни не делаем =)
tormozedison
Была и у меня такая привычка: всё созданное школьниками заранее подозревать в болгеносности. Но вот недавно выяснилось, что Павел Суходольский выпустил первые версии прошивки для АОНов "Русь" будучи школьником. Для меня это стало сюрпризом, я был уверен, что в девяностых ему было около пятидесяти. Призадумался. Школьник школьнику рознь.
Whuthering
Просто те школьники, кто реально в чем-то разбираются и делают что-то стоящее, страдают от синдрома самозванца, а разные болгеносники — наоборот от феномена Даннига-Крюгера :)
Jef239
У меня при слове школьники вспоминается 16-летний kitten, ныне больше всего известный как автор kPHP (ну и дважды призер международки по программированию) и 17летний yole, известный как создатель идеи языка kotlin и автор первой книжки по нему. Yole, правла, в свои 17 был уже на 3ем курсе.
Ну а я сам в 17 лет пытался писать компилятор. Правда написал только немного процедур нижнего слоя (разработка шла снизу вверх).