Но как быть, если код, написанный тобой в прошлом, ужасен и не дает тебе возможности развивать проект? Отставить в сторонку старые наработки, дать дорогу новому, вечному и светлому (да-да, и тут тоже без вариантов).

Цитата из кф Матрица: “Достаточно одной таблетки, Нео”. Режиссер: братья и сестры Вачовски. 1999. США
Уже больше 10 лет назад я написал код для ASH Viewer (более подробно о моем пути здесь ), выложил сначала на sourceforge.net, а потом и на github чтобы люди подключались и могли добавлять функционал, править ошибки. Была сделана сборка проекта с помощью Gradle, решили вопросы с отображением графиков: практически полный список улучшений по ссылке.
Однако я понимал, что написанный десять лет назад код, мягко говоря, неидеален. Внешне все выглядело неплохо, функциональность была развита, люди активно пользовались и благодарили. Но внутри программа содержал все ошибки первого опыта кодирования и, конечно, это очень сильно тормозило развитие проекта.
Каждому, кто был готов серьезно начать работу над приложением (например, dcvetkov), я говорил, что код требует полной переделки. И с каждой попыткой внедрить какую-либо функциональность или заняться исправлением ошибок я убеждался в этом. Доложу вам, править legacy-код — страшная пытка, особенно свой :). Надеюсь, в будущем роботы научатся переписывать все сами, ну а пока было принято волевое решение начать с чистого листа, с учетом уже наработанного опыта в создании программ и написании кода.
С момента первого релиза ASH Viewer активно работал в этом направлении. Было сделано 3 достаточно крупных проекта на базе JfreeChart для анализа данных. Кроме этих проектов, пробовал разные подходы, парадигмы и библиотеки. В итоге остановился на том, что писать надо все на чистой Java, без использования библиотек специально предназначенных для создания графического интерфейса с нуля. Но все же применять сторонние библиотеки для решения каких-то узкоспециализированных задач вполне допустимо — это позволит сохранить необходимый уровень гибкости и не потребует значительных затрат времени на исправление багов и разработку требуемой функциональности своими руками.
Как все начиналось
Меня всегда волновало, а есть ли в свободном доступе пример, который бы давал основы правильного написания приложений средней сложности на Java Swing? Конечно, меня отсылали к самой библиотеке или к каким-то простым примерам из учебников. И в чем-то они были правы.
Но я упорно искал код приложения, который можно было бы использовать в качестве примера «как надо делать правильно» на Java Swing. Причем хотелось иметь перед глазами рабочую систему, чтобы ее можно было «пощупать».
Начал изучать исходные коды приложений на Java Swing (всех их не перечесть). Где-то это были простые ToDo, где-то слишком сложные (для меня на тот момент), в каких-то подводило качество, а иногда было и то, и другое. Читал статьи на Хабре, писал код. Но все же чего-то не хватало. Возможно, я как раз тогда набирал критический для решения этой задачи объем знаний.
В один из дней обнаружил Angry IP Scanner уважаемого Антона Кекса antonkeks, посмотрел ее и сразу понял — вот оно! Java Swing, простой функционал, чистый код, модульность – приятно читать! В общем, используемые в ней подходы я взял за основу при написании одного из своих предыдущих проектов, а затем и при переписывании ASH Viewer.
ПО и библиотеки, которые помогли улучшить качество кода и упростили работу
IDEA: уже лет пять использую эту IDE для программирования в Java. Подтверждаю мнение большинства — это действительно полезная программа и очень удобный инструмент для написания кода. Когда я пересел на нее с Эклипса www.eclipse.org/ide (а первая версия была написана на этой IDE), то после непродолжительного обучения понял, IDEA ведет тебя и сообщает, когда ты пытаешься перейти на темную сторону :). Подсветка повторов в коде держит тебя в тонусе и не дает заниматься тупой копипастой. Аве JetBrains!
Java 8: лямбда-выражения, которые дают возможность писать более короткий код, новое Time API, позволившее отменить использование сторонней библиотеки Joda Time.
Dagger 2: Dependency injection framework я раньше вообще не применял. Но как-то подсмотрел, как используется эта библиотека у Антона antonkeks, и стал делать по шаблону. Делить программу на модули, где это возможно, использовать внедрение зависимостей. Где это было невозможно, использовал создание объектов оболочек заранее, а потом проводил установку необходимых атрибутов или просто не использовал DI.
Система сборки Maven. Именно это система сборки является стандартом де-факто, поэтому решил сделать добавление библиотек чисто, через pom.xml и использовать систему модулей от Maven для работы с кодом JFreeChart и Gantt в одном проекте.
Lombok: тоже невероятно удобная библиотека, чтобы не писать и не поддерживать «портянки» однообразного кода (getter-ы, setter-ы и проч.). Правда, в некоторых случаях отказывался от ее использования, так как надо было переопределить equals и compareTo, но как быстро это сделать в Lombok не нашел.
Журналирование: делаем идеальную Java программу? Значит, без современных средств журналирования никуда. Поэтому берем за основу Simple Logging Facade for Java SLF4J и Logback.
Layout менеджер: в основном использую Miglayout. Достаточно сложный в освоении (в некоторых местах по старинке использую Swing layout manager-ы), но зато краткий. Позволяет делать вот такие интересные эффекты, как на вкладке Detail.
Swingx от Swinglabs: давно заброшенный Java Swing UI tooklit. Активно использую JXTable. Произвольный выбор столбцов таблицы и встроенный поиск по содержимому ячеек облегчают детальный анализ данных истории активных сессий.
Сommons-dbcp2: полезен для создания connection pool подключений к БД. В старой версии использовал доработанную реализацию, которую нашел в Интернет.
Библиотеки, которые переехали из старой версии
Oracle Berkeley DB Java Edition v. 5.0.73: встраиваемая key-value storage. Для хранения агрегированных данных истории активных сессий.
JFreeChart: тысячи проектов для анализа данных написаны с использованием этой библиотеки. Взял за основу экспериментальную версию, которая выложена на github и добавил ее как модуль. Это было сделано для удобства работы с кодом, так как требовались изменения, чтобы Stacked Chart отображал график как нужно.
E-Gantt: библиотека для создания Gantt-графиков в Java Swing. Следов ее сейчас не найти даже в интернетах, увы. Тоже разместил отдельным модулем Maven в проекте.
Из интересного в коде, на что можно обратить внимание
Архитектурные изменения:
- Теперь настройки хранятся в отдельной встроенной БД, не в plain text файлах. Так как данных немного, используется расширенный паттерн EAV для хранения настроек подключения;
- Для хранения данных мониторинга решил сделать подобие OLAP-engine. Во-первых, для ускорения отображения детализации Gantt по SQL_ID/SESSION_ID по выбранному диапазону. Во-вторых, для возможности получения быстрой детализации по SQL_ID/SESSION_ID по stacked и Gantt графикам. В-третьих, формирования в будущем просмотра истории активных сессий (Top по ожиданиям, детализация по ожиданиям, детализация по SQL_ID/SESSION_ID). Все хранится в одной сущности (данные по секундному, 15-секундному и, в перспективе, по другим расширенным интервалам физически разделены);
- Побочным эффектом clean architecture имеем возможность поддержки мониторинга истории активных сессий других БД. На данный момент реализована поддержка Postgres. Чтобы подключить другие БД, нужен или готовый интерфейс к данными истории активных сессий (который добавили в Postgres или вот такая реализация) или самостоятельно настроенный сбор истории активных сессий в отдельную таблицу, к которому можно будет в последствии обращаться.
Как включить поддержку другой БД- Создать новый класс и реализовать интерфейс IProfile. Сделать аналогично, как и в случае Postgres;
- Добавить в процедуру loadProfile класса ConnectToDbArea и enum Function класса ConstantManager реализацию для новой версии БД;
- Подключиться и проверить работу приложения.
Графический интерфейс
Форма подключения к БД
Полностью переписана с нуля, раньше использовал наработки c открытого проекта Squirrel-sql. Сейчас все в одном файле. Красота!
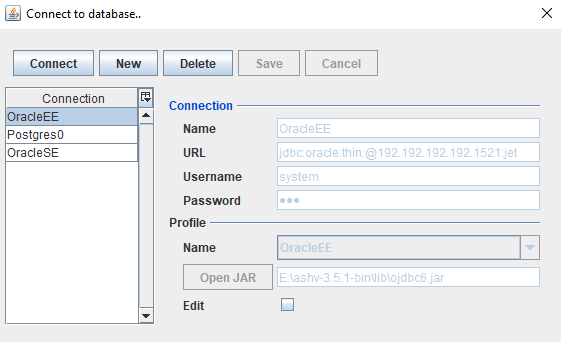
- Создать новое подключение;
- Указать имя, URL (JDBC стандартно для Oracle: jdbc:oracle:thin:@host:port:SID, для Postgres: jdbc:postgresql://host:port:database), username/password, профиль и выбрать jdbc библиотеку;
- Для Oracle все работает с ojdbc6.jar, для PostgresDB проверена работа с postgresql-42.2.5
Интерфейс Top activity/Detail
Здесь без существенных изменений, аналогично как в старой версии, только без просмотра истории.
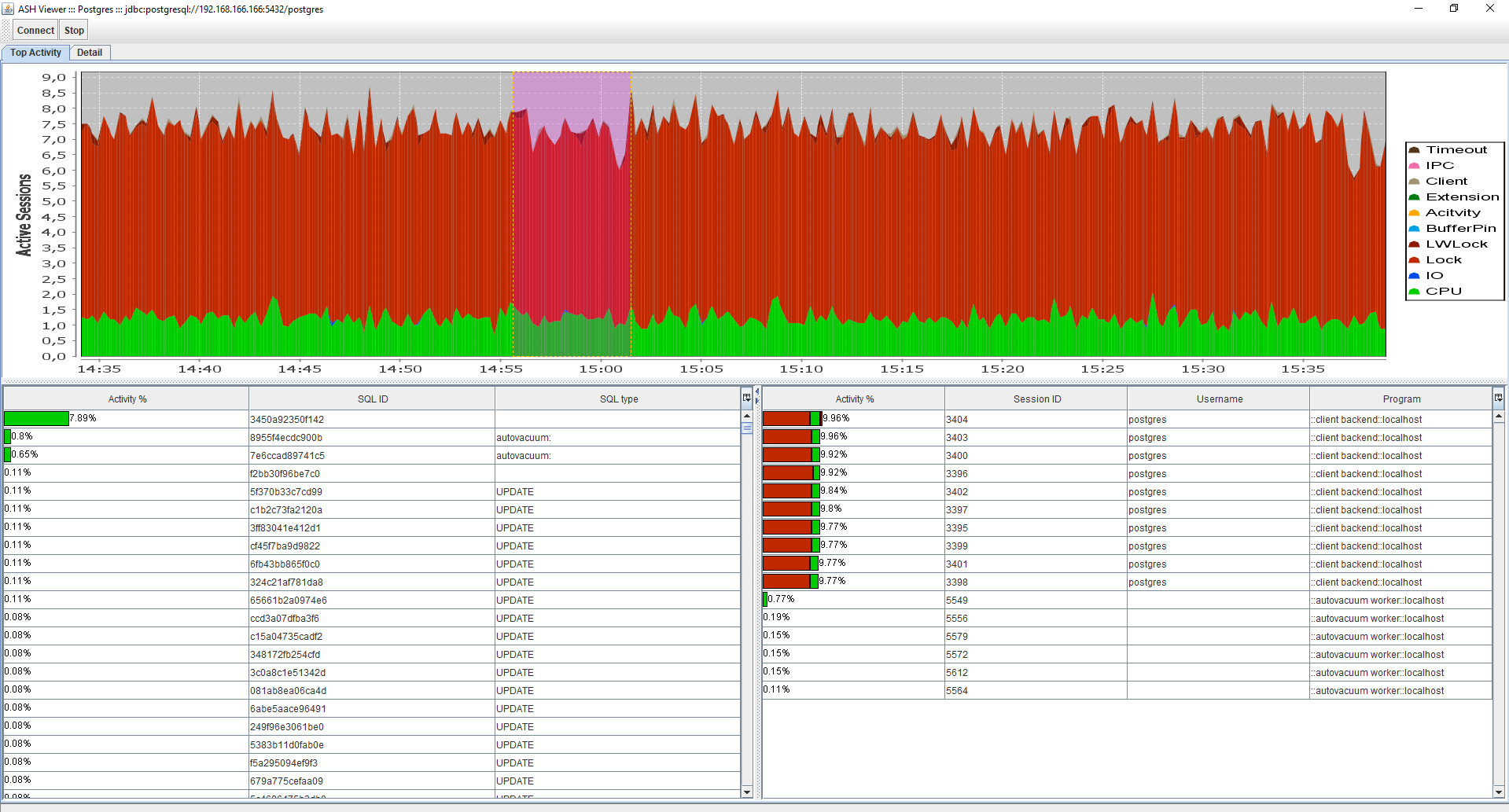
Детализация по SQL_ID/SESSION_ID
SQL
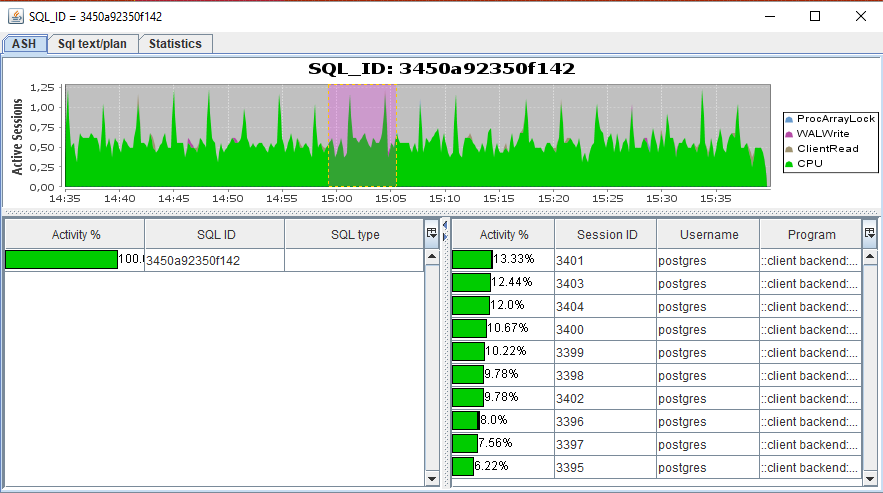
ASH: график активности по определенному SQL_ID, вызывается двойным кликом по строке с SQL_ID из Gantt-графика.
Sql text/plan: для Oracle/Postgres есть возможность получить полный текст запроса. Только для Oracle предоставляются планы выполнения запроса по всем plan_hash_value.
Statistics: данные в табличном виде по SQL_ID: выборка из V$SQL. В коде есть возможность добавлять еще сущности, по которым можно делать выборку (см. реализацию). но нужно быть очень аккуратным, так как могут быть проблемы с производительностью: например, выборка из V$SQLAREA на нагруженных системах работает очень медленно).
Session
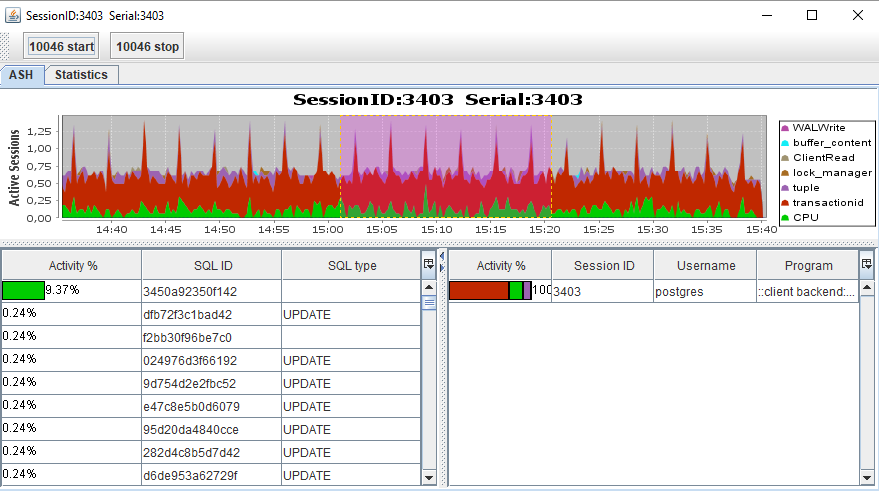
ASH: график активности по session_id, аналогично SQL вызывается двойным кликом по строке сессии из Gantt-графика.
Statistics: данные в табличном виде по SQL_ID: выборка из V$SESSION и V$PROCESS. В коде есть возможность добавлять еще сущности, по которым можно делать выборку (см. реализацию).
Дальнейшие планы
- Устаканить API. Провести финальный рефакторинг кода. Реализовать динамическое хранение исходных данных мониторинга, который бы не зависел от версий и типов БД;
- Очень не хватает тестов, которые бы проверяли ключевые модули системы, CI и других передовых практик.
Код проекта на github, файлы проекта;
Ссылка на группу в Телеграмм t.me/ashviewer для информирования о последних обновлениях;
P.S. Кто надумает подключиться к разработке — пишите в ЛС, без излишнего ажиотажа и не создавая давки, естественно :).
На этом все. Спасибо за внимание!
Комментарии (8)

viking_dooh
22.02.2019 14:41Вопрос…
1. Сейчас получается при автотипическом обновлении окна активных сессий, сами запросы не обновляются?
2. На графике активных сессий при нажатии левой кнопки есть свойство настройки, оно не отрывается?akardapolov Автор
22.02.2019 14:54Здравствуйте,
1. Если запрос уже есть в локальной базе — то текст его не обновляется, если есть — идет запись (для PostgresDB). Для Oracle данные (текст запроса, планы) запрашиваются при запуске детализации по SqlID. Или о чем речь?
2. Да, заблокировано.viking_dooh
22.02.2019 15:07Я про Oracle. Раньше сразу обновлялся график активных и сразу ниже топик запросов.
В текущей версии если обновился график сессий, но топик как стоял так и стоит, мне кажется это уже не удобно.akardapolov Автор
22.02.2019 15:12А, понял. Да, этой функциональности пока нет, в автоматическом режиме не делает выборку последние 1, 5 минут и далее как в ветке 3.5.
VadimGuslistov
23.02.2019 10:03А разве Bigdata это про объём данных, а не про то, что ты собираешь их все, даже те, из которых пока не знаешь какую информацию извлечь?
Valle
Swing интерфейс не меняет с момента создания, уже лет 15, да?
akardapolov Автор
Я привык к MetalLookAndFeel, если хотите — можете поставить классический Windows или Nimbus через строку запуска run.bat:
%JAVA_EXE% -Xmx512m -Dswing.defaultlaf=javax.swing.plaf.nimbus.NimbusLookAndFeel -jar ASH-Viewer.jar%JAVA_EXE% -Xmx512m -Dswing.defaultlaf=com.sun.java.swing.plaf.windows.WindowsLookAndFeel -jar ASH-Viewer.jar