Мы продолжаем рассказывать о проектах весеннего хакатона DevDays, в котором участвовали студенты магистерской программы «Разработка программного обеспечения / Software Engineering».

Кстати, хотим пригласить читателей присоединиться к VK-группе магистратуры. В ней мы будем публиковать самые свежие новости о наборе и учебе. Видеозапись со дня открытых дверей также можно будет найти в группе. Напоминаем: мероприятие пройдет 29 апреля, подробности на сайте.
Автор идеи
Хорошев Артём
Состав команды
Хорошев Артем – менеджер проекта/разработчик/QA
Елисеев Антон – бизнес-аналитик/специалист по маркетингу
Куклина Мария – UI дизайнер/разработчик
Бахвалов Павел – UI дизайнер/разработчик/QA
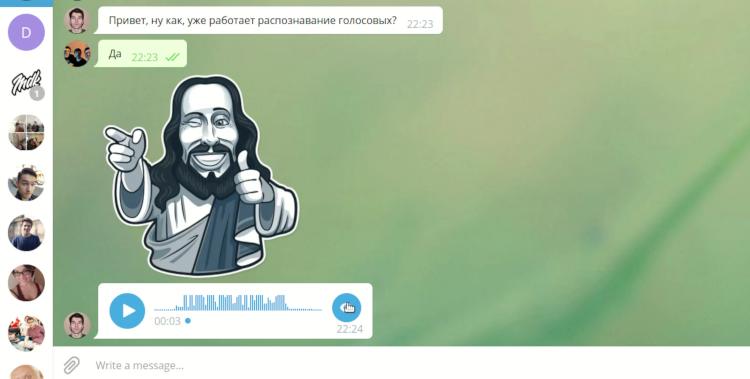
С нашей точки зрения, Telegram является современным и удобным мессенджером, а его версия для ПК отличается популярностью и открытым исходным кодом, вследствие чего имеется возможность его модифицировать. Клиент предлагает достаточно богатую функциональность. Помимо стандартных текстовых сообщений, в нем присутствуют голосовые звонки, видеосообщения, голосовые сообщения. И именно последние порой приносят неудобство своему получателю. Зачастую нет возможности прослушать голосовое сообщение, находясь за компьютером или ноутбуком. Может мешать окружающий шум, отсутствие наушников, или вы не хотите, чтобы содержимое сообщения кто-либо услышал. Таких проблем почти не возникает, если вы используете телеграм на смартфоне, ведь его можно просто поднести к уху, в отличие от ноутбука или ПК. Мы попробовали решить данную проблему.
Задачей нашего проекта на DevDays было добавить в настольный клиент Telegram (далее Telegram Desktop) возможность транслировать полученные голосовые сообщения в текст.
Все аналоги на данный момент — это боты, которым можно переслать звуковое сообщение, а в ответ получить текст. Нас это не очень устраивает: пересылать сообщение боту не очень удобно, хотелось бы иметь нативную функциональность. К тому же любой бот — это третья сторона, которая выступает посредником между API по распознаванию речи и пользователем, а это, как минимум, небезопасно.
Как было отмечено ранее, telegram-desktop обладает двумя весовыми преимуществами: легкостью и скоростью работы. И это не случайно, ведь он полностью написан на C++. А так как мы решили добавлять новую функциональность прямо в клиент, то и разрабатывать пришлось на C++.
 В нашей команде было 4 человека. Изначально, двое занимались поиском подходящей библиотеки для распознавания речи, один человек изучал исходный код Telegram-desktop, еще один разворачивал build проекта Telegram Desktop. Позднее все занимались фиксами UI и отладкой.
В нашей команде было 4 человека. Изначально, двое занимались поиском подходящей библиотеки для распознавания речи, один человек изучал исходный код Telegram-desktop, еще один разворачивал build проекта Telegram Desktop. Позднее все занимались фиксами UI и отладкой.
Казалось, что реализация задуманной функциональности не составит труда, но, как всегда и бывает, возникли трудности.
Решение задачи складывалось из двух независимых подзадач: выбора подходящего средства для распознавания речи и реализации UI для новой функциональности.
При выборе библиотеки для распознавания голоса нам сразу пришлось отказаться ото всех offline API, потому что языковые модели занимают много места. А ведь речь идет лишь об одном языке. Стало понятно, что придется использовать online API. Позже выяснилось, что сервисы по распознаванию речи таких гигантов как Google, Yandex и Microsoft совсем не бесплатные, и нам придется довольствоваться пробным периодом. В итоге был выбран Google Speech-To-Text, так как он позволяет получить токен для пользования сервисом, которого хватит на целый год.
Вторая проблема, с которой мы столкнулись, связана с некоторыми недостатками C++ — зоопарком различных библиотек при отсутствии централизованного репозитория. Так получилось, что Telegram Desktop зависит от множества других библиотек конкретных версий. В официальном репозитории есть инструкция по сборке проекта. А также большое количество открытых issues о проблемах сборки, например раз и два. Все проблемы оказались связаны с тем, что build script написан для Ubuntu 14.04, и для того чтобы успешно собрать telegram под Ubuntu 18.04, пришлось вносить изменения.
Сам по себе Telegram Desktop собирается достаточно долго: на ноутбуке с Intel Core i5-7200U полная сборка (флаг -j 4) со всеми зависимостями занимает порядка трех часов. Из них порядка 30 минут занимает линковка самого клиента (позже выяснилось, что в Debug-конфигурации линковка занимает около 10 минут), а ведь этап линковки приходится повторять каждый раз после внесения изменений.
Несмотря на проблемы, нам удалось реализовать задуманную идею, а также обновить build script для Ubuntu 18.04. Демонстрацию работы можно увидеть по ссылке. Также прикладываем несколько анимаций. Около всех голосовых сообщений появилась кнопка, позволяющая транслировать сообщение в текст. При нажатии правой кнопкой мыши можно дополнительно указать язык, который будет использован для трансляции. По ссылке доступен клиент для загрузки.
Репозиторий.
По нашему мнению, получился хороший Proof of Concept функциональности, которая была бы удобна многим пользователям. Надеемся увидеть ее в будущих релизах Telegram Desktop.
Автор идеи
Танков Владислав
Состав команды
Танков Владислав (тимлид, работа с LanguageTool и IntelliJ IDEA)
Соколов Никита (работа с LanguageTool и создание UI)
Хворов Александр (работа с LanguageTool и оптимизация производительности)
Садовников Александр (поддержка парсинга языков разметки и кода)
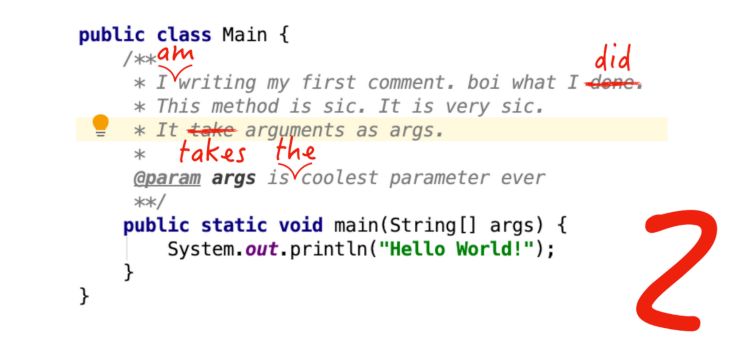
Мы разработали плагин для IntelliJ IDEA, проверяющий различные тексты (комментарии и документацию, литеральные строки в коде, текст оформленный в Markdown или XML-разметке) на грамматическую, орфографическую и стилистическую верность (в английском это называется proofreading).
Идеей проекта было расширить стандартный spellcheck IntelliJ IDEA до масштабов Grammarly, сделать своего рода Grammarly inside IDE.
Посмотреть на то, что получилось, можно по ссылке.
Ну а ниже мы подробнее расскажем о возможностях плагина, а также о трудностях, возникших при его создании.
Мотивация
Существует множество продуктов, созданных для написания текстов на естественных языках, но документация и комментарии к коду пишутся чаще всего в средах разработки. В тоже время IDE прекрасно справляются с поиском ошибок в написании кода, но плохо приспособлены для текстов на естественных языках. Из-за этого очень легко допустить ошибки в грамматике, пунктуации или стиле, а среда разработки не укажет на них. Наиболее критично допустить ошибку в написании пользовательского интерфейса, так как от этого пострадает не только понятность кода, но и сами пользователи разработанного приложения.
Одной из самых популярных и развитых сред разработки является IntelliJ IDEA, а также IDE, основанные на IntelliJ Platform. В IntelliJ Platform уже есть встроенный spellchecker, однако он не избавляет даже от простейших грамматических ошибок. Мы решили интегрировать одну из популярных систем анализа естественного языка в IntelliJ IDEA.
Реализация
 Мы не ставили перед собой задачи создать свою систему верификации текстов, поэтому воспользовались существующим решением. Наиболее подходящим вариантом оказался LanguageTool. Лицензия позволяла беспрепятственно использовать его для наших целей: он бесплатен, написан на Java и выложен в open-source. Кроме того, он поддерживает 25 языков и развивается уже больше пятнадцати лет. Несмотря на открытость, LanguageTool является серьезным конкурентом платных решений верификации текстов, а то, что он способен работать локально, буквально является его killer feature.
Мы не ставили перед собой задачи создать свою систему верификации текстов, поэтому воспользовались существующим решением. Наиболее подходящим вариантом оказался LanguageTool. Лицензия позволяла беспрепятственно использовать его для наших целей: он бесплатен, написан на Java и выложен в open-source. Кроме того, он поддерживает 25 языков и развивается уже больше пятнадцати лет. Несмотря на открытость, LanguageTool является серьезным конкурентом платных решений верификации текстов, а то, что он способен работать локально, буквально является его killer feature.
Код плагина лежит в репозитории на GitHub. Весь проект писался на Kotlin с небольшим добавлением Java для UI. За время хакатона удалось реализовать поддержку Markdown, JavaDoc, HTML и Plain Text. После хакатона в большом обновлении были добавлены поддержка XML, строковых литералов в Java, Kotlin и Python, а также проверка орфографии.
Трудности
Довольно быстро мы поняли, что если каждый раз будем скармливать весь текст на проверку LanguageTool, то интерфейс IDEA будет подвисать на любых мало-мальски серьезных текстах, так как инспекция сама по себе блокирует поток UI. Проблема решалась через проверку `ProgressManager.checkCancelled` — эта функция выбрасывает исключение если IDEA считает, что инспекции пора бы прерваться.
Это полностью избавило от зависаний, но пользоваться этим невозможно: очень уж долго обрабатывается текст. При этом в нашем случае чаще всего меняется очень небольшая часть текста и хочется как-то закешировать результаты. Именно это мы и сделали. Чтобы не проверять каждый раз все, мы детерминированно разбивали текст на куски и проверяли только те, которые изменились. Так как тексты могут быть большими и нагружать кеш не хотелось, мы хранили не сами тексты, а их хеши. Это позволило добиться плавной работы плагина даже на больших файлах.
LanguageTool поддерживает более 25 языков, но вряд ли одному пользователю нужны они все. Хотелось дать возможность скачивать библиотеки для конкретного языка по запросу (если отметили его галочкой в UI). Мы даже реализовали это, но получилось слишком сложно и ненадежно. В частности, нам приходилось отдельным classloader-ом подгружать LanguageTool с новым набором языков, после чего аккуратно его инициализировать. При этом все библиотеки лежали в пользовательском .m2-репозитории, и при каждом старте нам приходилось проверять их целостность. В итоге мы решили, что если у пользователей будут проблемы с размером плагина, то мы будем поставлять отдельный плагин для нескольких наиболее популярных языков.
После хакатона
Хакатон закончился, но работа над плагином продолжилась уже более узким составом. Хотелось поддержать строки, комментарии и даже конструкции языка, такие как названия переменных и классов. Сейчас это поддерживается только для Java, Kotlin и Python, но мы надеемся, что этот список будет расти. Мы исправили множество небольших ошибок и стали более совместимыми с встроенным спеллчекером Idea. Кроме этого появилась поддержка XML и проверка орфографии. Все это можно найти во второй версии, которую мы опубликовали недавно.
Что дальше?
Такой плагин может быть полезен не только разработчикам, но и техническим писателям (часто работающим, к примеру, с XML в IDE). Им каждый день приходится работать именно с естественным языком, при этом не имея помощника в виде подсказок редактора о возможных ошибках. Наш плагин предоставляет такие подсказки и делает это с высокой степенью точности.
Мы планируем развивать плагин, как добавляя новые языки, так и исследуя общий подход к организации проверки текста. В ближайших планах реализация профилей стилистики (наборов правил определяющих стайлгайд для текста, к примеру «не писать e.g., а писать полную форму»), расширения словаря и улучшение пользовательского интерфейса (в частности, мы хотим дать пользователю возможность не просто игнорировать слово, а добавлять его в словарь, указывая часть речи).
Кстати, хотим пригласить читателей присоединиться к VK-группе магистратуры. В ней мы будем публиковать самые свежие новости о наборе и учебе. Видеозапись со дня открытых дверей также можно будет найти в группе. Напоминаем: мероприятие пройдет 29 апреля, подробности на сайте.
Telegram Desktop Voice Message Parser
Автор идеи
Хорошев Артём
Состав команды
Хорошев Артем – менеджер проекта/разработчик/QA
Елисеев Антон – бизнес-аналитик/специалист по маркетингу
Куклина Мария – UI дизайнер/разработчик
Бахвалов Павел – UI дизайнер/разработчик/QA
С нашей точки зрения, Telegram является современным и удобным мессенджером, а его версия для ПК отличается популярностью и открытым исходным кодом, вследствие чего имеется возможность его модифицировать. Клиент предлагает достаточно богатую функциональность. Помимо стандартных текстовых сообщений, в нем присутствуют голосовые звонки, видеосообщения, голосовые сообщения. И именно последние порой приносят неудобство своему получателю. Зачастую нет возможности прослушать голосовое сообщение, находясь за компьютером или ноутбуком. Может мешать окружающий шум, отсутствие наушников, или вы не хотите, чтобы содержимое сообщения кто-либо услышал. Таких проблем почти не возникает, если вы используете телеграм на смартфоне, ведь его можно просто поднести к уху, в отличие от ноутбука или ПК. Мы попробовали решить данную проблему.
Задачей нашего проекта на DevDays было добавить в настольный клиент Telegram (далее Telegram Desktop) возможность транслировать полученные голосовые сообщения в текст.
Все аналоги на данный момент — это боты, которым можно переслать звуковое сообщение, а в ответ получить текст. Нас это не очень устраивает: пересылать сообщение боту не очень удобно, хотелось бы иметь нативную функциональность. К тому же любой бот — это третья сторона, которая выступает посредником между API по распознаванию речи и пользователем, а это, как минимум, небезопасно.
Как было отмечено ранее, telegram-desktop обладает двумя весовыми преимуществами: легкостью и скоростью работы. И это не случайно, ведь он полностью написан на C++. А так как мы решили добавлять новую функциональность прямо в клиент, то и разрабатывать пришлось на C++.
В нашей команде было 4 человека. Изначально, двое занимались поиском подходящей библиотеки для распознавания речи, один человек изучал исходный код Telegram-desktop, еще один разворачивал build проекта Telegram Desktop. Позднее все занимались фиксами UI и отладкой.Казалось, что реализация задуманной функциональности не составит труда, но, как всегда и бывает, возникли трудности.
Решение задачи складывалось из двух независимых подзадач: выбора подходящего средства для распознавания речи и реализации UI для новой функциональности.
При выборе библиотеки для распознавания голоса нам сразу пришлось отказаться ото всех offline API, потому что языковые модели занимают много места. А ведь речь идет лишь об одном языке. Стало понятно, что придется использовать online API. Позже выяснилось, что сервисы по распознаванию речи таких гигантов как Google, Yandex и Microsoft совсем не бесплатные, и нам придется довольствоваться пробным периодом. В итоге был выбран Google Speech-To-Text, так как он позволяет получить токен для пользования сервисом, которого хватит на целый год.
Вторая проблема, с которой мы столкнулись, связана с некоторыми недостатками C++ — зоопарком различных библиотек при отсутствии централизованного репозитория. Так получилось, что Telegram Desktop зависит от множества других библиотек конкретных версий. В официальном репозитории есть инструкция по сборке проекта. А также большое количество открытых issues о проблемах сборки, например раз и два. Все проблемы оказались связаны с тем, что build script написан для Ubuntu 14.04, и для того чтобы успешно собрать telegram под Ubuntu 18.04, пришлось вносить изменения.
Сам по себе Telegram Desktop собирается достаточно долго: на ноутбуке с Intel Core i5-7200U полная сборка (флаг -j 4) со всеми зависимостями занимает порядка трех часов. Из них порядка 30 минут занимает линковка самого клиента (позже выяснилось, что в Debug-конфигурации линковка занимает около 10 минут), а ведь этап линковки приходится повторять каждый раз после внесения изменений.
Несмотря на проблемы, нам удалось реализовать задуманную идею, а также обновить build script для Ubuntu 18.04. Демонстрацию работы можно увидеть по ссылке. Также прикладываем несколько анимаций. Около всех голосовых сообщений появилась кнопка, позволяющая транслировать сообщение в текст. При нажатии правой кнопкой мыши можно дополнительно указать язык, который будет использован для трансляции. По ссылке доступен клиент для загрузки.
Репозиторий.
По нашему мнению, получился хороший Proof of Concept функциональности, которая была бы удобна многим пользователям. Надеемся увидеть ее в будущих релизах Telegram Desktop.
Расширенная поддержка естественного языка в IntelliJ IDEA
Автор идеи
Танков Владислав
Состав команды
Танков Владислав (тимлид, работа с LanguageTool и IntelliJ IDEA)
Соколов Никита (работа с LanguageTool и создание UI)
Хворов Александр (работа с LanguageTool и оптимизация производительности)
Садовников Александр (поддержка парсинга языков разметки и кода)
Мы разработали плагин для IntelliJ IDEA, проверяющий различные тексты (комментарии и документацию, литеральные строки в коде, текст оформленный в Markdown или XML-разметке) на грамматическую, орфографическую и стилистическую верность (в английском это называется proofreading).
Идеей проекта было расширить стандартный spellcheck IntelliJ IDEA до масштабов Grammarly, сделать своего рода Grammarly inside IDE.
Посмотреть на то, что получилось, можно по ссылке.
Ну а ниже мы подробнее расскажем о возможностях плагина, а также о трудностях, возникших при его создании.
Мотивация
Существует множество продуктов, созданных для написания текстов на естественных языках, но документация и комментарии к коду пишутся чаще всего в средах разработки. В тоже время IDE прекрасно справляются с поиском ошибок в написании кода, но плохо приспособлены для текстов на естественных языках. Из-за этого очень легко допустить ошибки в грамматике, пунктуации или стиле, а среда разработки не укажет на них. Наиболее критично допустить ошибку в написании пользовательского интерфейса, так как от этого пострадает не только понятность кода, но и сами пользователи разработанного приложения.
Одной из самых популярных и развитых сред разработки является IntelliJ IDEA, а также IDE, основанные на IntelliJ Platform. В IntelliJ Platform уже есть встроенный spellchecker, однако он не избавляет даже от простейших грамматических ошибок. Мы решили интегрировать одну из популярных систем анализа естественного языка в IntelliJ IDEA.
Реализация
Мы не ставили перед собой задачи создать свою систему верификации текстов, поэтому воспользовались существующим решением. Наиболее подходящим вариантом оказался LanguageTool. Лицензия позволяла беспрепятственно использовать его для наших целей: он бесплатен, написан на Java и выложен в open-source. Кроме того, он поддерживает 25 языков и развивается уже больше пятнадцати лет. Несмотря на открытость, LanguageTool является серьезным конкурентом платных решений верификации текстов, а то, что он способен работать локально, буквально является его killer feature.Код плагина лежит в репозитории на GitHub. Весь проект писался на Kotlin с небольшим добавлением Java для UI. За время хакатона удалось реализовать поддержку Markdown, JavaDoc, HTML и Plain Text. После хакатона в большом обновлении были добавлены поддержка XML, строковых литералов в Java, Kotlin и Python, а также проверка орфографии.
Трудности
Довольно быстро мы поняли, что если каждый раз будем скармливать весь текст на проверку LanguageTool, то интерфейс IDEA будет подвисать на любых мало-мальски серьезных текстах, так как инспекция сама по себе блокирует поток UI. Проблема решалась через проверку `ProgressManager.checkCancelled` — эта функция выбрасывает исключение если IDEA считает, что инспекции пора бы прерваться.
Это полностью избавило от зависаний, но пользоваться этим невозможно: очень уж долго обрабатывается текст. При этом в нашем случае чаще всего меняется очень небольшая часть текста и хочется как-то закешировать результаты. Именно это мы и сделали. Чтобы не проверять каждый раз все, мы детерминированно разбивали текст на куски и проверяли только те, которые изменились. Так как тексты могут быть большими и нагружать кеш не хотелось, мы хранили не сами тексты, а их хеши. Это позволило добиться плавной работы плагина даже на больших файлах.
LanguageTool поддерживает более 25 языков, но вряд ли одному пользователю нужны они все. Хотелось дать возможность скачивать библиотеки для конкретного языка по запросу (если отметили его галочкой в UI). Мы даже реализовали это, но получилось слишком сложно и ненадежно. В частности, нам приходилось отдельным classloader-ом подгружать LanguageTool с новым набором языков, после чего аккуратно его инициализировать. При этом все библиотеки лежали в пользовательском .m2-репозитории, и при каждом старте нам приходилось проверять их целостность. В итоге мы решили, что если у пользователей будут проблемы с размером плагина, то мы будем поставлять отдельный плагин для нескольких наиболее популярных языков.
После хакатона
Хакатон закончился, но работа над плагином продолжилась уже более узким составом. Хотелось поддержать строки, комментарии и даже конструкции языка, такие как названия переменных и классов. Сейчас это поддерживается только для Java, Kotlin и Python, но мы надеемся, что этот список будет расти. Мы исправили множество небольших ошибок и стали более совместимыми с встроенным спеллчекером Idea. Кроме этого появилась поддержка XML и проверка орфографии. Все это можно найти во второй версии, которую мы опубликовали недавно.
Что дальше?
Такой плагин может быть полезен не только разработчикам, но и техническим писателям (часто работающим, к примеру, с XML в IDE). Им каждый день приходится работать именно с естественным языком, при этом не имея помощника в виде подсказок редактора о возможных ошибках. Наш плагин предоставляет такие подсказки и делает это с высокой степенью точности.
Мы планируем развивать плагин, как добавляя новые языки, так и исследуя общий подход к организации проверки текста. В ближайших планах реализация профилей стилистики (наборов правил определяющих стайлгайд для текста, к примеру «не писать e.g., а писать полную форму»), расширения словаря и улучшение пользовательского интерфейса (в частности, мы хотим дать пользователю возможность не просто игнорировать слово, а добавлять его в словарь, указывая часть речи).