Введение
Внимание, это не очередная «Hello world»статья о том как помигать светодиодом или попасть в свое первое прерывание на STM32. Однако, я постарался дать исчерпывающие объяснения по всем затрагиваемым вопросам, поэтому статья будет полезна не только многим профессиональным и мечтающим стать таковыми разработчикам (как я надеюсь), но и начинающим программистам микроконтроллеров, так как тема эта почему-то обходится стороной на бесчисленных сайтах/блогах «учителей программирования МК».
Почему я решил это написать?
Хоть я и преувеличил, сказав ранее, что аппаратный bit banding семейства Cortex-M не описывается на специализированных ресурсах, все же есть места, где это возможность освещается (и даже тут встречал одну статью), но эта тема явно нуждается в дополнении и осовременивании. Отмечу, что это касается и англоязычных ресурсов. В следующем разделе я объясню, почему эта возможность ядра может быть чрезвычайно важной.
Теория
(а те кто с ней знаком, могут прыгать сразу в практику)
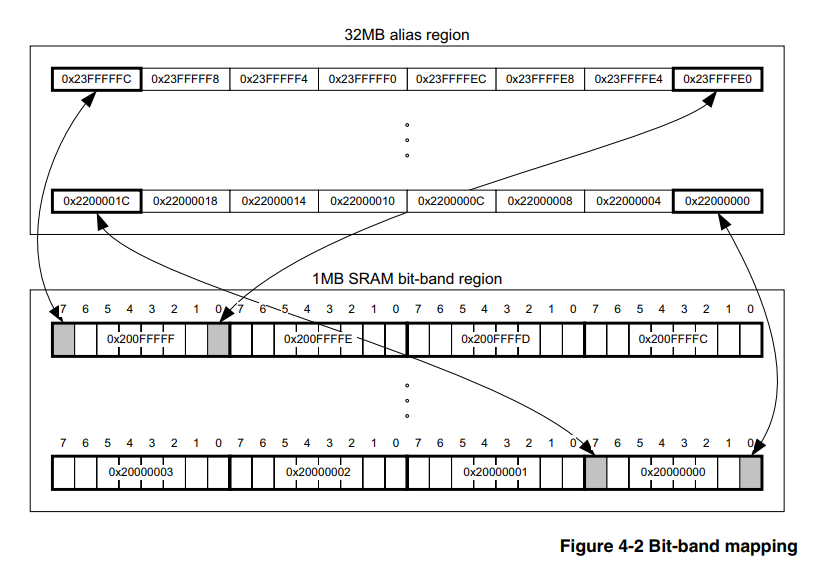
Аппаратный bit banding — это особенность самого ядра, поэтому и не зависит от семейства и фирмы производителя микроконтроллеров, главное чтобы ядро было подходящее. В нашем случае пусть это будет Cortex-M3. Следовательно, и информацию по этому вопросу следует искать в официальном документе на само ядро, и такой документ есть, вот он, раздел 4.2 подробно описывает как пользоваться этим инструментом.
Тут я хотел бы сделать небольшое техническое отступление для программистов, не знакомых с ассемблером, коих сейчас большинство, ввиду пропагандируемой сложности и бесполезности ассемблера для таких «серьёзных» 32битных микроконтроллеров, как STM32, LPC и т. д. Более того, нередко можно встретить попытки порицания за использования ассемблера в этой области даже на хабре. В этом разделе я хочу кратко описать механизм записи в память МК, которой и должен прояснить преимущества bit banding.
Поясню на конкретном простом примере для большинства STM32. Допустим, мне нужно превратить PB0 в выход общего назначения. Обычное решение будет выглядеть так:
GPIOB->MODER |= GPIO_MODER_MODER0_0;Очевидно, мы используем побитовое «ИЛИ», чтобы не затереть остальные биты регистра.
Для компилятора это транслируется в следующий набор из 4х инструкций:
- Загрузить в регистр общего назначения(РОН) адрес GPIOB->MODER
- Загрузить в другой РОН значения по адресу, указанному в РОН из п1.
- Сделать побитовое «ИЛИ» этого значения с GPIO_MODER_MODER0_0.
- Загрузить результат обратно в GPIOB->MODER.
Также нельзя забывать, что данное ядро использует набор инструкция thumb2, а значит они могут быть разными по объёму. Отмечу также, что везде речь идёт об уровне оптимизации O3.
На языке ассемблера это выглядит вот так:

Видно, что самая первая инструкция есть ни что иное, как псевдо-инструкция со смещением, находим по адресу PC(учитывая конвеерность) + 0x58 значение адреса регистра.
Получается у нас 4 шага (а тактов еще больше) и 14 байт занимаемой памяти на одну операцию.
Если вы хотите больше знать об этом, то рекомендую книгу [2], кстати, есть и на русском.
Переходим к методу bit_banding.
Суть, по крестьянски, в том, что в процессоре есть специально выделенная область памяти, записывая значения в которую, мы не меняем другие биты регистра периферии или RAM. То есть нам не нужно выполнять пункты 2) и 3), описанные выше, и для этого достаточно лишь пересчитать адрес по формулам из [1].

Пробуем проделать аналогичную операцию, ее ассемблер:

Пересчитанный адрес:

Тут у нас добавилась инструкция записи #1 в РОН, но все равно, в итоге получается 10 байт, вместо 14, и на пару тактов меньше.
А что и с того, раз разница то смешная?
С одной стороны, экономия не существенна, особенно в тактах, когда уже заведено за привычку разгонять контроллер до 168МГц. В среднем проекте, моментов, где можно применить этот метод будет 40 — 80, соответственно в байтах экономия может достигать 250 байт, если адреса будут различаться. А если учесть, что «зашкваром» сейчас считается программирование МК напрямую на регистрах, а «круто» использовать всякие кубики
Также, цифра 250 байт искажена тем, что в сообществе активно используются высоко-уровневые библиотеки, прошивки раздуваются до неприличных размеров. Программируя же на низком уровне, это как минимум 2 — 5% объема ПО для среднестатистического проекта, с грамотной архитектурой и O3 оптимизацией.
Опять же, я не хочу сказать, что это какой-то супер-пупер-мега крутой инструмент, которым должен пользоваться каждый уважающий себя программист МК. Но если я могу сократить расходы даже на столь малую часть, то почему бы этого не сделать?
Реализация
Все варианты будут даны только для настройки периферии, так как мне не попадалась ситуация, когда это было бы нужно для RAM. Строго говоря, для RAM формула похожа, достаточно лишь поменять базовые адреса для расчёта. Так как же это реализовать?
Ассемблер
Пойдём с самых низов, с моего любимого Ассемблера.
На ассемблерных проектах, я обычно выделяю пару 2байтных(по работающих с ними инструкциями) РОН под #0 и #1 на весь проект, и использую их также в макросах, что сокращает мне еще 2 байта на постоянной основе. Ремарка, на Ассемблер для STM я CMSIS не нашёл, потому в макрос кладу сразу номер бита, а не его значение по регистру.
@Захардкориваю два РОНа.
MOVW R0, 0x0000
MOVW R1, 0x0001
@Макрос установки бита
.macro PeriphBitSet PerReg, BitNum
LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4))
STR R1, [R3]
.endm
@Макрос сброса бита
.macro PeriphBitReset PerReg, BitNum
LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4))
STR R0, [R3]
.endmПримеры:
PeriphSet TIM2_CCR2, 0
PeriphBitReset USART1_SR, 5
Безусловный плюс этого варианта в том, что мы имеем полный контроль, чего нельзя сказать о дальнейших вариантах. И как покажет последний раздел статьи, плюс этот очень весомый.
Однако, никому не нужны проекты для МК на Ассемблере, примерно с конца нулевых, а значит нужно переходить на СИ.
Plain C
Честно говоря, простой Сишный вариант был найден мной в начале пути, где-то на просторах сети. На тот момент я уже реализовал bit banding на Ассемблере, и случайно наткнулся на C файл, он сразу заработал и я решил ничего не изобретать.
/*!<=================PLAIN C SECTION========================>!*/
#define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0
#define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A)
#define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A)
#define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A)
#define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A)
#define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A)
#define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A)
#define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A)
#define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A)
#define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A)
#define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A)
#define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A)
#define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A)
#define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A)
#define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A)
#define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A)
#define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A)
#define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A)
#define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A)
#define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A)
#define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A)
#define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A)
#define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A)
#define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A)
#define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A)
#define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A)
#define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A)
#define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A)
#define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A)
#define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A)
#define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A)
#define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A)
#define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
Как видно, очень простой и прямолинейный кусок кода, написанный на языке пре процессора. Основная работа здесь — это перевод CMSIS значений в номер бита, которая отсутствовала как необходимость в ассемблерном варианте.
Ах да, пользоваться этим вариантом так:
BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0; //Сброс
BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 1; //Установка (!0)
Однако современные (массово, по моим наблюдениям, примерно с 2015г) тенденции идут в пользу замены С на С++ даже для МК. Да и макросы не самый надёжный инструмент, поэтому предначертано было родиться следующей версии.
Cpp03
Тут всплывает очень интересный и обсуждаемый, но мало используемый в виду своей сложности, с одним заезженным примером факториала, инструмент — метапрограммирование.
Ведь задача перевода значения переменной в номер бита идеальна(значения то в CMSIS уже есть), и в данном случае практична, для compile time.
Я реализовал это следующим образом, при помощи шаблонов:
template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value
{
enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num };
};
template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)>
{
enum { bit_num = 31 };
};
#define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
Пользоваться можно аналогично:
BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false; //Сброс
BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = true; //Установка
А почему же остался макрос? Дело в том, что я не знаю другого способа гарантированно вставить данную операцию без перехода в другую область кода программы. Буду очень рад, если в комментариях подскажут. Ни шаблоны, ни inline функции такой гарантии не дают. Да и макрос тут справляется со своей задачей на отлично, нет смысла его менять только потому, что
Удивительно, но время все еще не стояло на месте, компиляторы все активнее поддерживали C++14/C++17, почему бы не воспользоваться новшествами, сделав код более понятным.
Cpp14/Cpp17
constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num)
{
return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1);
}
#define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
Как видно, я просто заменил шаблоны на рекурсивную constexpr функцию, что на мой взгляд, человеческому глазу это более понятно.
Пользоваться аналогично. Кстати, в С++17 по идее можно использовать рекурсивную лямбда constexpr функцию, но не уверен, что это приведет хоть к каким-то упрощениям, а также не усложнит ассемблерный порядок.
Резюмируя, все три С/Cpp реализации дают одинаково корректный набор инструкций, согласно разделу «Теория». Работаю давно со всеми реализациями на IAR ARM 8.30 и gcc 7.2.0.
Практика is a bitch
Вот все, кажется, и сложилось. Экономию памяти подсчитали, реализацию выбрали, готовы улучшать производительность. Не тут то было, тут как раз случай расхождения теории и практики. А когда было по-другому?
Я бы никогда не опубликовал это, если бы не протестировал, а насколько реально на проектах уменьшается занимаемый объем. Я специально на паре старых проектов заменил этот макрос на обычную реализацию без маски, и посмотрел разницу. Результат удивил неприятно.
Как оказалось, объём практически не меняется. Я специально выбрал проекты, где как раз и использовалось по 40-50 подобных инструкций. Согласно теории, я должен был сэкономить ну как минимум 100 байт, а как максимум 200. На практике же, разница получилось 24 — 32 байта. Но почему?
Обычно, когда настраиваешь периферию, настраиваешь 5-10 регистров практически подряд. И на высоком уровне оптимизации, компилятор не располагает инструкции точно в порядке следования регистров, а располагает инструкции так, как ему кажется правильным, порой мешая их, в казалось бы, неразрывных местах.
Я вижу два варианта(тут мои домыслы):
- Либо компилятор настолько умен, что за тебя знает как будет лучше оптимизировать сет инструкций
- Либо компилятор все же пока еще не умнее человека, и сам себя путает, встречая такие конструкции
То есть получается, этот метод на языках «высокого уровня» при высоком уровне оптимизации отрабатывает корректно только в том случае, если по-близости с одной такой операцией нету похожих операций.
Кстати говоря, на уровне O0 теория с практикой сходятся в любом случае, но мне этот уровень оптимизации не интересен.
Резюмирую
Отрицательный результат — тоже результат. Я думаю, каждый сделает выводы для себя сам. Лично я так и продолжу использовать данный прием, хуже от него точно не будет.
Надеюсь было интересно и хочу выразить огромнейший респект тем, кто дочитал до конца.
Перечень литературы
- «Cortex-M3 Technical Reference Manual», раздел 4.2, ARM 2005.
- The definitive guide to the ARM Cortex-M3, Joseph Yiu.
P.S У меня в запасе мешок мало освещенных тем, связанных с разработкой встраиваемой электроники. Дайте знать, если интересно, буду потихоньку доставать их.
P.P.S. Как-то секции кода кривовато получилось вставить, подскажите пожалуйста, как улучшить, если это возможно. В целом, можно скопировать интересующий кусок кода в notepad и избежать неприятных эмоций при анализе.
UPD:
По просьбам читателей указываю, что операция bit banding сама по себе атомарна, что дает нам определенную безопасность при работе с регистрами. Это одна из важнейших особенностей данного методаКомментарии (36)

lamerok
02.06.2019 18:02Отлично, кстати, IAR 8.40.1 вышел с С++17). Да еще к этому решению это не имеет отношения, но количество constexpr рекурсий в ИАР ограничено, я наткнулся на это, когда сделал tuple с количеством элементов больше 64. Мне выдалось, что превышен порог количества рекурсий. Это конечно можно в настройках поменять, но неприятно, когда думаешь, что все работает, а потом бах в один прекрасный момент и код не компилится.

big_dig_dev Автор
02.06.2019 20:36Спасибо, строго говоря, с рекурсиями шаблонов столкнулся c ограничением вложенности, именно поэтому в коде для 03 стандарта есть отдельный шаблон для 31ого бита, иначе рекурсия уходит в бесконечность(сталкивался для gcc).
А по теме в общем, я могу ошибаться, но вроде как стандарт языка позволяет компилятору конвертировать constexpr функцию в run time, если ему кажется это правильным. Поэтому я всегда очень осторожно к ним отношусь и проверяю каждый случай применения.
0xd34df00d
01.06.2019 22:48Не совсем так.
constexprскорее сообщает компилятору, что эту функцию вообще можно пытаться вычислить в контекстах, требующих вычисления времени компиляции (что, впрочем, как мы знаем, не мешает компиляторам вычислять во время компиляции и не аннотированные какconstexprфункции).
Если вы хотите быть уверенным, что
constexpr-функция вычисляется на этапе компиляции, то её результат нужно засунуть в соответствующий контекст, например, сделав его аргументом шаблона или сохранив вconstexpr-переменную.
А в C++20, впрочем, будет
consteval...lamerok
02.06.2019 04:10Можно еще static_assert вставить внутрь функции на проверку входных аргументов, если фукнция будет не constexpr, т. Е кто то попытается рантайм передать значения. Не посчитаннве на этапе компиляции, компилятор руганется.

khim
02.06.2019 11:30Вот только он точно также преотлично ругнётся и на значения, заданные в компайл-тайме.
static_assertвы можете сделать только «снаружи» — а там достаточно присвоить значениеconstexpr-переменной, чтобы гарантировать, что всё будет вычислено в компайл-тайме. Даже в -O0. Собственно вот. Сравните кодbarиbaz…
godbolt — ваш друг а таких вещах.
big_dig_dev Автор
02.06.2019 12:54Спасибо за пояснения! Я обычно и стараюсь такую функцию приравнять к constexpr переменной.
SergeyMax
02.06.2019 21:02Автор забыл упомянуть про ключевую особенность этого bit banding, для которой он собственно и был реализован в железе (да, а совсем не для экономии памяти). Bit banding — атомарный. Между вычиткой ячейки памяти и последующей записью поксоренного содержимого исходное значение может измениться. В результате запись модифицированного содержимого затрёт произошедшие изменения. Для того, чтобы такого не происходило, и используется описываемая технология манипуляции отдельными битами.
big_dig_dev Автор
02.06.2019 21:45Ну не то чтобы забыл, статья и должна была осветить только аспект затрачиваемой памяти и тактов.
Однако я не считаю верным утверждение, что основная особенность — атомарность операции. Я думаю экономия памяти по значимости не уступает ей.
yleo
02.06.2019 13:17На запрещение/разрешение прерываний уходит более чем достаточно как байтов кода, так и таков.
Думаю вам стоит поправить/доработать статью.big_dig_dev Автор
02.06.2019 14:55Что конкретно по-вашему мнению мне следует поправить? Это не наезд, как можно подумать, я правда не понял из вашего комментария.
По теме байтов, вы приводите ссылку на другую версию ядра. В cortex-m3 это всего-лишь одна инструкция CPSIE/ CPSID.
Но дело то даже и не в этом. На счёт той же атомарности, в STM32, к примеру, почти все биты, что могут поменяться из вне, вынесены в отдельный Read-Only регистр (ANY_PERIPH)->SR. Если подобные биты есть в других регистрах, то обычно сбросить подобные флаги можно только записью единицы, что не нарушит логику программы даже при неатомарной операции.yleo
02.06.2019 16:02+1Видимо есть недопонимание "атомарности".
В случае управления "выходами" GPIO речь не о memory barries и/или memory ordering, а о потенциальном переключении процессора на другую задачу и/или обработчик прерываний, которые могут обращаться к тому-же GPIO. Соответственно будет прелестный heisenbug, если переключение произойдет между
LDRиSTR.
Кроме этого,
CPSIEне всегда подходит, например если прерывания были запрещены выше по стеку вызовов для более широкого контекста. Соответственно, нередко перед CPSID приходится сохранять маску, а вместо CPSIE ёё восстанавливать.big_dig_dev Автор
02.06.2019 19:52Вы ошибаетесь или выдаете свое желаемое за действительное. Я, очевидно, знаю далеко не все, но вот это
В случае управления «выходами» GPIO речь не о memory barries и/или memory ordering, а о потенциальном переключении процессора на другую задачу и/или обработчик прерываний, которые могут обращаться к тому-же GPIO. Соответственно будет прелестный heisenbug, если переключение произойдет между LDR и STR.
мне известно. И я хотел бы знать, почему вы посчитали, что этого понимания у меня нет?
Я же описал особенности организации периферийных модулей, которые помогают избегать проблем изменения битов в памяти во время модификации исходного значения, когда значения уже реально поменялось, а записано будет модифицированное старое.
А вот вас я действительно не очень понял. CPSIE глобальная команда, не зависит от места в стеке вызовов и разрешает прерывания для проца в целом.
Вы также сказали, что статью следует поправить или дополнить, и я по прежнему хочу знать, как именно, по вашему мнению, это нужно сделать, поскольку вы опять не сказали, что именно вас не устраивает.
Такое обычно называют не здоровой критикой.khim
02.06.2019 20:32И я хотел бы знать, почему вы посчитали, что этого понимания у меня нет?
У вас возможно, такое понимание есть. А вот у читателя — далеко не факт. Вы же сами пишите о том, что статей про это дело мало.
И с учётом этого делать акцент в статье на «побочную», в общем-то, фичу — экономию нескольких байт — не упомянув основную… ну как-то странно.
CPSIE глобальная команда, не зависит от места в стеке вызовов и разрешает прерывания для проца в целом.
Что не очень-то хорошо, если вызывающая вас процедура этого не ожидает. Представьте себе, что вам нужна процедура, которая должна «атомарно» флипнуть бит, но может быть вызвана как из обработчика прерываний (где разрешать прерывания, до того, как вы к этому готовы не слишком-то хорошо), так и из обычного кода. «Бездумно» включать прерывания в таком случае не получится, а разводить две копиии… ну можно, наверное, на шаблонах — но тут вы можете много-таки кода в итоге надублировать…big_dig_dev Автор
02.06.2019 21:33И с учётом этого делать акцент в статье на «побочную», в общем-то, фичу — экономию нескольких байт — не упомянув основную… ну как-то странно.
С этой точки зрения вы правы конечно, тут мне и возразить то нечего, а в статью я этот момент добавил уже ранее. Для себя учел на будущее, если взялся тему раскрывать, то описать следует все важные особенности.
yleo
02.06.2019 20:47- Использование bit banding для GPIO даёт чуть больше удобства/выгоды, чем подсчитано в статье.
- Потому-что операции bit banding атомарны, что избавляет от необходимости запрещать/разрешать прерывания для изменения отдельных бит.
- При этом затраты на запрещение/разрешения прерываний, как правило, больше чем просто пара инструкций CPSID/CPSIE.
- Потому-что непосредственно использование CPSIE в большом/сложном проекте (и/или в повторное используемом коде), как правило, недопустимо.
- Потому-что прерывания могут быть уже запрещены ранее по стеку вызова или потоку выполнения кода и будут разрешены позже, т.е. прерывания могут быть запрещены для более широкого контекста, внутри которого может быть вызван ваш GPIO-код.
Соответственно, вместо__disable_irq()/__enable_irq() требуется сохранять и восстанавливать маску прерываний или флаги CPU. Например, см local_irq_save() / local_irq_restore(). Но при использовании bin banding всего этого можно избежать, как минимум использовать реже (при операциях над несколькими регистрами и т.п.).
evgeniy1294
03.06.2019 16:18-2Использование Bit banding для GPIO в частности и для периферии в целом, как правило, не дает ничего. Все давным давно решено на уровне организации периферии. Например, проблемы с GPIO решаются через SET/RST регистры (BSRR в случае stm32).
hhba
02.06.2019 23:03Ну, для исключения таких ситуаций есть эксклюзивные чтение и запись. Так что вряд ли bit banding только ради этого придуман.
khim
03.06.2019 00:52Ещё раз: ARM — это RISC. Там нет атомарных инструкций. За исключением SWP (что, всё-таки, немного не то).
Bit banding как раз и позволяет реализовать захват шины и атомарную модификацию данных — никакого другого способа на RISC процессорах нету (придумать-то можно, но практически — нету).hhba
03.06.2019 09:21Не, стоп. Я комментировал конкретное сообщение, в котором было следующее:
Между вычиткой ячейки памяти и последующей записью поксоренного содержимого исходное значение может измениться. В результате запись модифицированного содержимого затрёт произошедшие изменения. Для того, чтобы такого не происходило
Так вот, чтобы «такого не происходило» — есть LDREX/STREX. Вот собсна и все, атомарные инструкции тут приплетать незачем, тем более что bit banding выглядит менее универсальным средством, чем LL/SC.
И, к слову, чем вам не понравилась SWP, если уж мы тут все равно извращаемся? Ну, кроме того, что она deprecated. Формально отлично подходит для записи значения.khim
03.06.2019 18:35Так вот, чтобы «такого не происходило» — есть LDREX/STREX.
Про которые мануал говорит следующее: Load-Exclusive and Store-Exclusive must only access memory regions marked as Normal — то есть для GPIO они неприменимы.
Вот собсна и все, атомарные инструкции тут приплетать незачем, тем более что bit banding выглядит менее универсальным средством, чем LL/SC.
Зато он работает — в отличие от LL/SC. Которые, как бы, для совсем-совсем другого.
И, к слову, чем вам не понравилась SWP, если уж мы тут все равно извращаемся?
Тем, что она не работает?Формально отлично подходит для записи значения.
«Записать не глядя» — да. Но вот беда: единственный способ её использования — это изменить значение, понять, что мы «натворили делов» и быстро-быстро всё исправить. Если вы реализуете какую-нибудь многопоточность — этого, в общем и целом, достаточно. Если вы «дёргаете» оборудование, то случайные скачки туда-сюда на линиях могут к разным очень странным эффектам на подключённом оборудовании производить…hhba
03.06.2019 18:43то есть для GPIO они неприменимы
Весомо, упустил.
Зато он работает — в отличие от LL/SC. Которые, как бы, для совсем-совсем другого.
Буквально для того же, но, как стало известно, не подходят для портов ввода-вывода.
«Записать не глядя» — да
Запись в порт обычно именно так и происходит. Заметьте, что я только про запись и говорил.khim
03.06.2019 19:39Запись в порт обычно именно так и происходит.
Нет. Если вы используете bit banding — то вы читаете/пишите (поднимаете бит), читаете/пишите (поднимаете второй).
А с SWP вы вначане читаете, потом прерывание, внова прочитали и подняли бит, потом опустили первый, подняли второй, потом поняли, что натворили — и подняли оба. Вот этого «дёрг-дёрг» хотелось бы избежать — и именно это является преимуществом bit banding'а.hhba
03.06.2019 23:24+1Если нужно устанавливать/сбрасывать отдельные биты — то bit banding является лучшим выбором и по сути для этого сделан. Если же говорить о «записи вообще», без привязки именно к дерганию битов, о чем собственно я и писал постом выше, то и SWP достаточно.
Предлагаю дискуссию завершить, а то по третьему кругу пошли. Думаю все всё уже поняли.
AVI-crak
02.06.2019 21:11+1Следует отметить что bit banding уже отсутствует в М7, мне пришлось переписывать часть кода по этой бяке. После чего я выяснил что структуры, перечисления и прочие гадости — дают намного больший эффект, чем дёрганье отдельных битов.
Небольшой примерчик для глобальных флагов — forum.easyelectronics.ru/viewtopic.php?f=35&t=22572big_dig_dev Автор
02.06.2019 21:39Слышал об этом, но как-то не довелось с семёрками поработать. Спасибо за ссылку, оставлю себе на заметку для подходящего случая.
ncr
02.06.2019 21:32в С++17 по идее можно использовать рекурсивную лямбда constexpr функцию, но не уверен, что это приведет хоть к каким-то упрощениям, а также не усложнит ассемблерный порядок.
Зачем лямбды, у вас и так уже как-то всё очень сложно — рекурсия, дополнительные аргументы…
Даже на C++14 уже вполне можно так:
constexpr uint32_t bit_num_from_value_cpp14_v2(uint32_t val) { uint32_t i = 0; while (1 << i != val) ++i; return i; }big_dig_dev Автор
02.06.2019 21:39Можно и так конечно, может это влияние шаблона, но мне почему-то эти способы равнозначны по восприятию.
so1ov
03.06.2019 21:55bit_num_from_value_cpp14_v2(3) выглядит как феерический
compile-timeсуицид.ncr
04.06.2019 22:48О, всегда приятно встретить эксперта.
Вы хотите сказать, что для комплятора в compile-time цикл феерически сложнее, чем рекурсия, поэтому время компиляции будет в разы больше, я правильно понимаю?
evgeniy1294
02.06.2019 21:32Несколько лет узнал об этой, казалось бы, классной фиче из книги «The Designer’s Guide to the
Cortex-M Processor Family». Думая о том, какие возможности это дает, добавил макросы, похожие на представленные в статье, в свои библиотеки. В результате, за два года ими никто не пользовался, включая меня(((
У этого конечно есть применение по мимо настройки периферии, например можно дать какому-то классу «указатель на бит», управляющий уровнем GPIO. Но как оказалось, в работе этого не достаточно.
Вообще у ядра есть более крутые возможности вроде:
- Перенос таблицы прерываний в ОЗУ (начиная с cortex-M0+). Очень удобно, когда куски кода сами назначают себе прерывание.
- Программные прерывания и вызов прерываний командой — это позволяет, например, писать тесты.
- Математика с насыщением(Saturated Maths Instructions), которая очень хороша при работе с ПИД-регуляторами или цифровыми фильтрами.
Разумеется есть куча тругих, не менее полезных возможностей, вроде проверки указателя на валидность.
shevmax
02.06.2019 07:41ни шаблоны, ни inline функции такой гарантии не дают.
ну так есть forceinline, у разных компиляторов он по разному описывается. К примеру GCC __attribute__((always_inline)), некоторые поддерживают вариант как в MSVC — __forceinline.
Единственные ограничения:
A recursive function is never inlined into itself.
Functions making use of alloca() are never inlined.
big_dig_dev Автор
02.06.2019 12:52Буду знать, спасибо!

Jef239
03.06.2019 23:49Эта фишка нужна для реализации классического ПЛК с языками IEC 61131-3, вроде Ladder. Там основная память — битовая и почти все операции — битовые. Так что такая модель памяти удешевляет трансляцию и прилично увеличивает быстродействие.
Видимо планировалось массовое производство ПЛК на основе Cortex-M.
mpa4b
02.06.2019 22:12+1В свежих инклудах для stm32 нынче есть номера всех битов. Потому достаточно вот такого:
__attribute__ ((always_inline)) static inline uint32_t BBIO_RD(volatile uint32_t * addr, uint8_t bitnum) { volatile uint32_t * bitptr; bitptr = ((uint32_t *)( (((uint32_t)addr)-(0x40000000UL))*32 + bitnum*4 + (0x42000000UL) )); return *bitptr; } __attribute__ ((always_inline)) static inline void BBIO_WR(volatile uint32_t * addr, uint8_t bitnum, uint32_t value) { volatile uint32_t * bitptr; bitptr = ((uint32_t *)( (((uint32_t)addr)-(0x40000000UL))*32 + bitnum*4 + (0x42000000UL) )); *bitptr = value; }
и использование типа такого:
BBIO_WR(&ADC1->CR2,ADC_CR2_ADON_Pos,1);
Благодаря __attribute__ ((always_inline)) функции всегда инлайнятся, а благодаря static — не генерятся отдельно.
Что касается того, почему не сильно сокращается размер, тут всё просто.
Обычно в один блок периферии делается много записей подряд, потому компилятор сначала одной командой грузит адрес начала ячеек блока в регистр, а потом использует его несколько раз в адресации со смещением, например:
// setup ADC ADC1->CR1 = ADC_CR1_SCAN | (0<<ADC_CR1_DUALMOD_Pos); 42: 4b13 ldr r3, [pc, #76] ; (90 <adc_init+0x90>) 44: f44f 7280 mov.w r2, #256 ; 0x100 48: 605a str r2, [r3, #4] ADC1->CR2 |= ADC_CR2_CONT | ADC_CR2_DMA | (0<<ADC_CR2_ALIGN_Pos); 4a: 689a ldr r2, [r3, #8] 4c: f442 7281 orr.w r2, r2, #258 ; 0x102 50: 609a str r2, [r3, #8]
AntonSor
Спасибо, очень интересно! То есть разработчики процессора заложили возможность управления отдельными битами, а разработчики версии языка сделали, как привыкли на больших машинах. В некоторых версиях С (например. от MikroE) есть управление отдельными битами по виду GPIOB_ODR.B13=1 (т.е. обращение к 13-му биту GPIOB_ODR), но все же это экзотика.