Существует множество как платных, так и бесплатных решений для этого. Например, есть готовое решение, основанное на адаптивном методе оптимизации индексов.
Далее рассмотрим бесплатную утилиту SQLIndexManager, автором которой является AlanDenton.
Основное техническое различие между SQLIndexManager и ряда других аналогов приводит сам автор здесь и здесь.
В этой же статье со стороны взглянем на проект и на возможности эксплуатации данного программного решения.
Обсуждают данную утилиту здесь.
Со временем большая часть замечаний и багов были исправлены.
Итак, перейдем теперь к самой утилите SQLIndexManager.
Приложение написано на языке C# .NET Framework 4.5 в Visual Studio 2017 и использует DevExpress для форм:
и выглядит следующим образом:
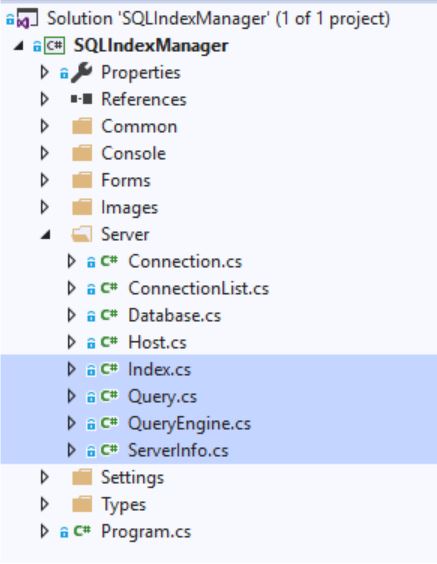
Все запросы формируются в следующих файлах:
- Index
- Query
- QueryEngine
- ServerInfo
При подключении к базе данных и отправке запросов к СУБД, приложение подписывается следующим образом:
ApplicationName=”SQLIndexManager”При запуске приложения откроется модальное окно на добавление подключения:
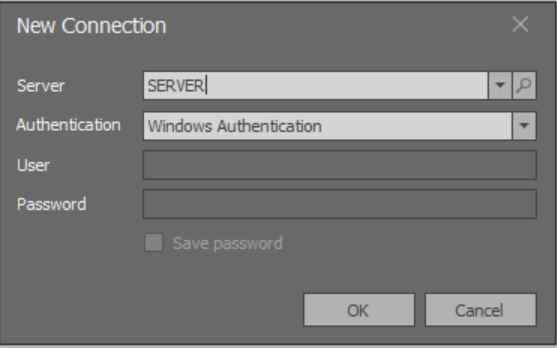
Здесь пока не работает подгрузка полного списка всех экземпляров MS SQL Server, доступных по локальным сетям.
Также добавить подключение можно с помощью крайней левой кнопки на главном меню:
Далее запустятся следующие запросы к СУБД:
- Получение информации о СУБД
SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
- Получение списка доступных баз данных с их краткими свойствами
SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
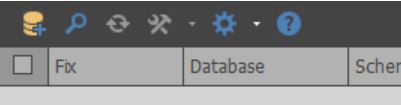
После выполнения вышеуказанных скриптов появится окно, содержащее краткую информацию о базах данных выбранного экземпляра MS SQL Server:
Стоит отметить, что расширенная информация показывается, исходя из прав. Если есть sysadmin, то можно выбирать данные из представления sys.master_files. Если таких прав нет, то просто возвращается меньше данных, чтобы не замедлять запрос.
Здесь необходимо выбрать интересующие базы данных и нажать на кнопку “ОК”.
Далее будет выполнен следующий скрипт для каждой выбранной базы данных для анализа состояния индексов:
declare @Fragmentation float=15;
declare @MinIndexSize bigint=768;
declare @MaxIndexSize bigint=1048576;
declare @PreDescribeSize bigint=32768;
SET NOCOUNT ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL
DROP TABLE #AllocationUnits
CREATE TABLE #AllocationUnits (
ContainerID BIGINT PRIMARY KEY
, ReservedPages BIGINT NOT NULL
, UsedPages BIGINT NOT NULL
)
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages)
SELECT [container_id]
, SUM([total_pages])
, SUM([used_pages])
FROM sys.allocation_units WITH(NOLOCK)
GROUP BY [container_id]
HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
IF OBJECT_ID('tempdb.dbo.#ExcludeList') IS NOT NULL
DROP TABLE #ExcludeList
CREATE TABLE #ExcludeList (ID INT PRIMARY KEY)
INSERT INTO #ExcludeList
SELECT [object_id]
FROM sys.objects WITH(NOLOCK)
WHERE [type] IN ('V', 'U')
AND ( [is_ms_shipped] = 1 )
IF OBJECT_ID('tempdb.dbo.#Partitions') IS NOT NULL
DROP TABLE #Partitions
SELECT [object_id]
, [index_id]
, [partition_id]
, [partition_number]
, [rows]
, [data_compression]
INTO #Partitions
FROM sys.partitions WITH(NOLOCK)
WHERE [object_id] > 255
AND [rows] > 0
AND [object_id] NOT IN (SELECT * FROM #ExcludeList)
IF OBJECT_ID('tempdb.dbo.#Indexes') IS NOT NULL
DROP TABLE #Indexes
CREATE TABLE #Indexes (
ObjectID INT NOT NULL
, IndexID INT NOT NULL
, IndexName SYSNAME NULL
, PagesCount BIGINT NOT NULL
, UnusedPagesCount BIGINT NOT NULL
, PartitionNumber INT NOT NULL
, RowsCount BIGINT NOT NULL
, IndexType TINYINT NOT NULL
, IsAllowPageLocks BIT NOT NULL
, DataSpaceID INT NOT NULL
, DataCompression TINYINT NOT NULL
, IsUnique BIT NOT NULL
, IsPK BIT NOT NULL
, FillFactorValue INT NOT NULL
, IsFiltered BIT NOT NULL
, PRIMARY KEY (ObjectID, IndexID, PartitionNumber)
)
INSERT INTO #Indexes
SELECT ObjectID = i.[object_id]
, IndexID = i.index_id
, IndexName = i.[name]
, PagesCount = a.ReservedPages
, UnusedPagesCount = CASE WHEN ABS(a.ReservedPages - a.UsedPages) > 32 THEN a.ReservedPages - a.UsedPages ELSE 0 END
, PartitionNumber = p.[partition_number]
, RowsCount = ISNULL(p.[rows], 0)
, IndexType = i.[type]
, IsAllowPageLocks = i.[allow_page_locks]
, DataSpaceID = i.[data_space_id]
, DataCompression = p.[data_compression]
, IsUnique = i.[is_unique]
, IsPK = i.[is_primary_key]
, FillFactorValue = i.[fill_factor]
, IsFiltered = i.[has_filter]
FROM #AllocationUnits a
JOIN #Partitions p ON a.ContainerID = p.[partition_id]
JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id] AND p.[index_id] = i.[index_id]
WHERE i.[type] IN (0, 1, 2, 5, 6)
AND i.[object_id] > 255
DECLARE @files TABLE (ID INT PRIMARY KEY)
INSERT INTO @files
SELECT DISTINCT [data_space_id]
FROM sys.database_files WITH(NOLOCK)
WHERE [state] != 0
AND [type] = 0
IF @@ROWCOUNT > 0 BEGIN
DELETE FROM i
FROM #Indexes i
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id]
WHERE ISNULL(dds.[data_space_id], i.DataSpaceID) IN (SELECT * FROM @files)
END
DECLARE @DBID INT
, @DBNAME SYSNAME
SET @DBNAME = DB_NAME()
SELECT @DBID = [database_id]
FROM sys.databases WITH(NOLOCK)
WHERE [name] = @DBNAME
IF OBJECT_ID('tempdb.dbo.#Fragmentation') IS NOT NULL
DROP TABLE #Fragmentation
CREATE TABLE #Fragmentation (
ObjectID INT NOT NULL
, IndexID INT NOT NULL
, PartitionNumber INT NOT NULL
, Fragmentation FLOAT NOT NULL
, PRIMARY KEY (ObjectID, IndexID, PartitionNumber)
)
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation)
SELECT i.ObjectID
, i.IndexID
, i.PartitionNumber
, r.[avg_fragmentation_in_percent]
FROM #Indexes i
CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r
WHERE i.PagesCount <= @PreDescribeSize
AND r.[index_level] = 0
AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA'
AND i.IndexType IN (0, 1, 2)
IF OBJECT_ID('tempdb.dbo.#Columns') IS NOT NULL
DROP TABLE #Columns
CREATE TABLE #Columns (
ObjectID INT NOT NULL
, ColumnID INT NOT NULL
, ColumnName SYSNAME NULL
, SystemTypeID TINYINT NULL
, IsSparse BIT
, IsColumnSet BIT
, MaxLen INT
, PRIMARY KEY (ObjectID, ColumnID)
)
INSERT INTO #Columns
SELECT ObjectID = [object_id]
, ColumnID = [column_id]
, ColumnName = [name]
, SystemTypeID = [system_type_id]
, IsSparse = [is_sparse]
, IsColumnSet = [is_column_set]
, MaxLen = [max_length]
FROM sys.columns WITH(NOLOCK)
WHERE [object_id] IN (SELECT DISTINCT i.ObjectID FROM #Indexes i)
IF OBJECT_ID('tempdb.dbo.#IndexColumns') IS NOT NULL
DROP TABLE #IndexColumns
CREATE TABLE #IndexColumns (
ObjectID INT NOT NULL
, IndexID INT NOT NULL
, OrderID INT NOT NULL
, ColumnID INT NOT NULL
, IsIncluded BIT NOT NULL
, PRIMARY KEY (ObjectID, IndexID, ColumnID)
)
INSERT INTO #IndexColumns
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, OrderID = CASE WHEN [is_included_column] = 0 THEN [key_ordinal] ELSE [index_column_id] END
, ColumnID = [column_id]
, IsIncluded = ISNULL([is_included_column], 0)
FROM sys.index_columns ic WITH(NOLOCK)
WHERE EXISTS(
SELECT *
FROM #Indexes i
WHERE i.ObjectID = ic.[object_id]
AND i.IndexID = ic.[index_id]
AND i.IndexType IN (1, 2)
)
IF OBJECT_ID('tempdb.dbo.#Lob') IS NOT NULL
DROP TABLE #Lob
CREATE TABLE #Lob (
ObjectID INT NOT NULL
, IndexID INT NOT NULL
, IsLobLegacy BIT
, IsLob BIT
, PRIMARY KEY (ObjectID, IndexID)
)
INSERT INTO #Lob (ObjectID, IndexID, IsLobLegacy, IsLob)
SELECT c.ObjectID
, IndexID = ISNULL(i.IndexID, 1)
, IsLobLegacy = MAX(CASE WHEN c.SystemTypeID IN (34, 35, 99) THEN 1 END)
, IsLob = 0
FROM #Columns c
LEFT JOIN #IndexColumns i ON c.ObjectID = i.ObjectID AND c.ColumnID = i.ColumnID
WHERE c.SystemTypeID IN (34, 35, 99)
GROUP BY c.ObjectID
, i.IndexID
IF OBJECT_ID('tempdb.dbo.#Sparse') IS NOT NULL
DROP TABLE #Sparse
CREATE TABLE #Sparse (ObjectID INT PRIMARY KEY)
INSERT INTO #Sparse
SELECT DISTINCT ObjectID
FROM #Columns
WHERE IsSparse = 1
OR IsColumnSet = 1
IF OBJECT_ID('tempdb.dbo.#AggColumns') IS NOT NULL
DROP TABLE #AggColumns
CREATE TABLE #AggColumns (
ObjectID INT NOT NULL
, IndexID INT NOT NULL
, IndexColumns NVARCHAR(MAX)
, IncludedColumns NVARCHAR(MAX)
, PRIMARY KEY (ObjectID, IndexID)
)
INSERT INTO #AggColumns
SELECT t.ObjectID
, t.IndexID
, IndexColumns = STUFF((
SELECT ', [' + c.ColumnName + ']'
FROM #IndexColumns i
JOIN #Columns c ON i.ObjectID = c.ObjectID AND i.ColumnID = c.ColumnID
WHERE i.ObjectID = t.ObjectID
AND i.IndexID = t.IndexID
AND i.IsIncluded = 0
ORDER BY i.OrderID
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
, IncludedColumns = STUFF((
SELECT ', [' + c.ColumnName + ']'
FROM #IndexColumns i
JOIN #Columns c ON i.ObjectID = c.ObjectID AND i.ColumnID = c.ColumnID
WHERE i.ObjectID = t.ObjectID
AND i.IndexID = t.IndexID
AND i.IsIncluded = 1
ORDER BY i.OrderID
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
FROM (
SELECT DISTINCT ObjectID, IndexID
FROM #Indexes
WHERE IndexType IN (1, 2)
) t
SELECT i.ObjectID
, i.IndexID
, i.IndexName
, ObjectName = o.[name]
, SchemaName = s.[name]
, i.PagesCount
, i.UnusedPagesCount
, i.PartitionNumber
, i.RowsCount
, i.IndexType
, i.IsAllowPageLocks
, u.TotalWrites
, u.TotalReads
, u.TotalSeeks
, u.TotalScans
, u.TotalLookups
, u.LastUsage
, i.DataCompression
, f.Fragmentation
, IndexStats = STATS_DATE(i.ObjectID, i.IndexID)
, IsLobLegacy = ISNULL(lob.IsLobLegacy, 0)
, IsLob = ISNULL(lob.IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID AND f.IndexID = i.IndexID AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys.dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id] AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
)
Как видно из самих запросов, достаточно часто используются временные таблицы. Это сделано для того, чтобы не было рекомпиляций, и в случае большой схемы, план мог генерироваться параллельный при вставке данных, т к вставка с табличными переменными возможна только в один поток.
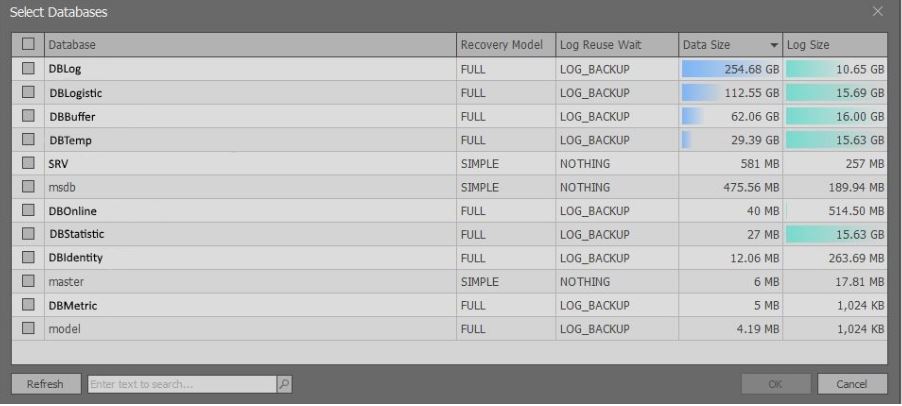
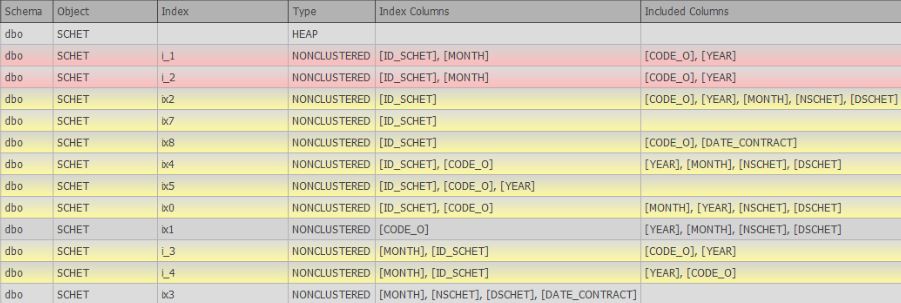
После выполнения вышеуказанного скрипта появится окно с таблицей индексов:

Также здесь можно вывести и другую детальную информацию, такую как:
- база данных
- количество секций
- дата и время последнего обращения
- сжатие
- файловая группа
и т. д.
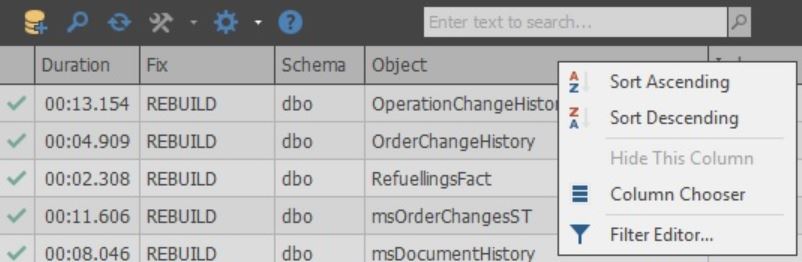
Сами колонки можно настраивать:
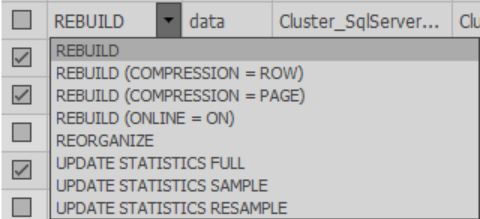
В ячейках колонки Fix можно выбрать какое действие будет выполнено при оптимизации. Также при завершении сканирования действие по умолчанию выбирается на основании выбранных настроек:
Необходимо выбрать нужные индексы для обработки.
С помощью главного меню можно как сохранить скрипт (эта же кнопка запускает сам процесс оптимизации индексов):
так и сохранить таблицу в разные форматы (эта же кнопка позволяет открыть детальные настройки для анализа и оптимизации индексов):

Также информацию можно обновить, нажав на третью кнопку слева в главном меню рядом с лупой.
Кнопка с лупой позволяет выбрать нужные базы данных для рассмотрения.
Полноценной справочной системы на текущий момент нет. Поэтому нажатие на кнопку “?” вызовет просто появление модального окна, содержащего основную информацию о программном продукте:
Помимо всего вышеописанного в главном меню есть строка поиска:

При запуске процесса оптимизации индексов:

Также внизу окна можно просмотреть лог выполняемых действий:
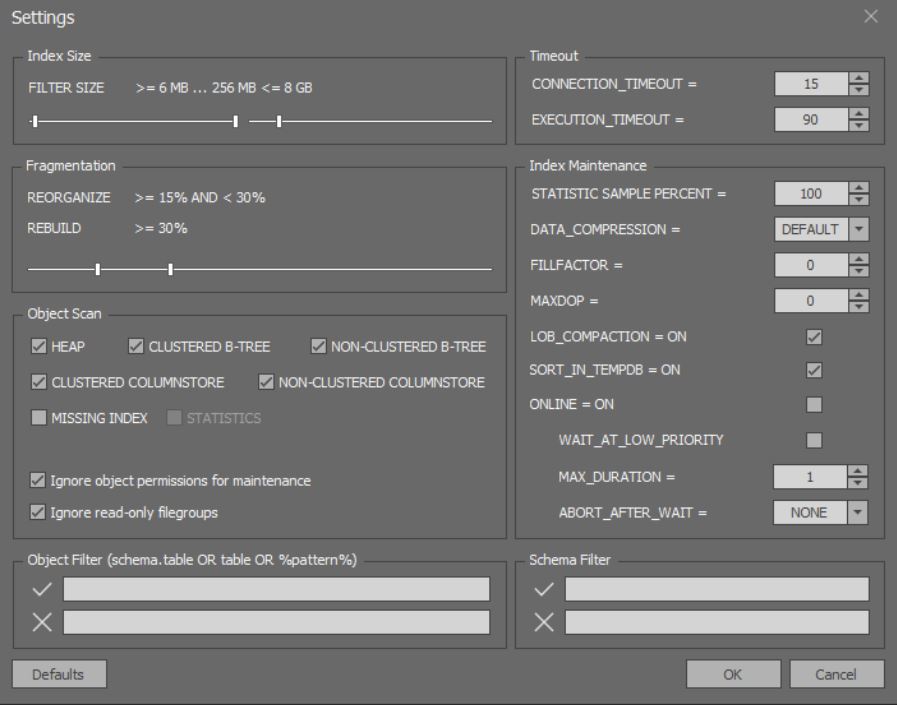
В окне детальных настроек анализа и оптимизации индексов можно настроить более тонкие опции:
Пожелания к приложению:
- сделать возможным выборочно обновлять статистики не только для индексов и также разными способами (полностью обновлять или частично)
- сделать возможным не только выбирать БД, но и разные сервера (это очень удобно, когда много экземпляров MS SQL Server)
- для большей гибкости в использовании предлагается обернуть команды в библиотеки, и вывести в команды PowerShell, как это сделано, например, здесь:
- dbatools.io/commands
- сделать возможным сохранять и изменять персональные настройки как для всего приложения, так и в случае необходимости для каждого экземпляра MS SQL Server и каждой базы данных
- из п.2 и 4 вытекает пожелание сделать группы по базам данных и группы по экземплярам MS SQL Server, для которых настройки одинаковые
- сделать поиск дубликатов индексов (полных и неполных, которые либо несильно отличаются, либо отличаются только по включенным колонкам)
- т к SQLIndexManager используется только для СУБД MS SQL Server, то необходимо отразить это в названии, например, следующим образом: SQLIndexManager for MS SQL Server
- все части приложения не GUI вынести в отдельные модули и переписать на .NET Core 2.1
На момент написания статьи п.6 из пожеланий активно разрабатывается и уже есть поддержка в виде поиска полных и подобных дубликатов:
Источники
Комментарии (25)

Karl_Marx
31.07.2019 21:40Эмм… Я не DBA, объясните, пожалуйста, а чем он отличается от стандартного Tuning Advisor'а?

AlanDenton
31.07.2019 23:16+1Формально это два разных продукта. Tuning Advisor с помощью гипотетических индексов создает недостающие индексы. Второй эти индексы обслуживает.
DenisTrunin
01.08.2019 05:37+1Есть вполне авторитетное мнение что фрагментация индексов не нужна и как правило приносит больше проблем чем пользы(что я лично наблюдал на нескольких проектах), так что цель данной программы не очень понятна
youtu.be/iEa6_QnCFMU?t=700 (Why Defragmenting Your Indexes Isn’t Helping with Brent Ozar) и www.brentozar.com/archive/2017/12/index-maintenance-madness
jobgemws Автор
01.08.2019 08:30Нужно две вещи определять:
1) использование индексов
2) какие индексы будут использоваться
Чем больше фрагментация, тем больше операций чтения.
А авторитетные мнения могут говорить что угодно-важно не отключать свое критическое мышление и все перепроверять, ставя под сомнение любое мнение даже авторитетное (даже от самого Microsoft)DenisTrunin
01.08.2019 09:02Посмотрите видео — там как раз объясняется популярное заблуждение — «Чем больше фрагментация, тем больше операций чтения.». Если у вас данные в памяти, то какая там фрагментация к примеру — это все равно и т.д.
jobgemws Автор
01.08.2019 09:06+1А всегда данные в памяти будут?
Автор не учитывает российских реалий, что в большинстве будет стоять не Enterprise редакция, да и обьемы ОЗУ не так велики
AlanDenton
01.08.2019 08:56+1так что цель данной программы не очень понятна
Цель предоставить функционал, а то как ним пользоваться уже дело пользователя. Зачастую ребилд индексов и вправду смысла не имеет. А вот обновление статистики, сжатие индексов и прочии перки — это да.
moresnow
01.08.2019 08:25Попробовал как раз пару недель тому назад. Тулза практически не работает. Из базы с более 1500 индексов с трудом притаскивает около сотни, из базы с 600+ индексами притаскивает те же… около 100. И базы в принципе не большие, по сегодняшним меркам, ~1.5ТБ и вторая ок. 500ГБ, Причём как-то странно более половины индексов на таблице не видит т.е. из 12 тянет 3-5 и всё. Не говоря уже о том что считать эти индексы уходит аж несколько (5-7) минут. В общем покрутил минут 20 и снёс. В принципе тулза интересная, но подождём пока допилят до приемлимого функционала, ибо на сейчас оно для моих баз никакое.
jobgemws Автор
01.08.2019 08:26+1Странно, но на БД от 100 до 1200 ГБ на 10-ки БД на сервере норм работает.
По 1С правда загибается (долго), но выводит в итоге, а там 10-ки тысяч индексов
edo1h
01.08.2019 08:32+2Она же не показывает индексы, у которых фрагментация ниже установленного в настройках порога (в настройках есть и другие фильтры)
AlanDenton
01.08.2019 08:54+1Из базы с более 1500 индексов с трудом притаскивает около сотни
Все настройками устанавливается. По дефолту не тянутся индексы тяжелее 8Гб.
Не говоря уже о том что считать эти индексы уходит аж несколько (5-7) минут
Скажем за это спасибо Microsoft. Данные о фрагментации индекса не кешируется на постоянной основе, потому происходит частичный скан индекса если его нет в буффер пуле (потому ограничение по размеру и делал).
moresnow
01.08.2019 23:05>>Все настройками устанавливается. По дефолту не тянутся индексы тяжелее 8Гб.
Я пробовал, у меня не заработало. И какая разница при первом то скане сколько там этот индекс весит. Наиболее интересны как раз большие индексы, мелкие гораздо менее интересны.
Скриптом я вытягиваю все индексы с их статистикой за пару минут и это с анализом на каждой таблице на дупы, миссинг и т.д, чуть менее 2 сек на таблицу на тестовом сервере (на продакшене, десятки-сотня мс). Ожидал чего то лучшего. Вытянуть всё тоже, но в более удобной форме на той же базе готов ждать 5-10 мин. Хочется иметь инструмент отдельный от SSMS.
В любом случае спасибо, тулза интересная будет инетерсно посмотреть опять через некоторое времяAlanDenton
01.08.2019 23:10Странно что прога работает медленнее чем ваши скрипты. Можете постучаться в личку? Скажем в телеграмм или по скайпу (в профиле линки есть). Хочется разобраться в ситуации и пофиксить если это реально косяк с моей стороны.
AlanDenton
02.08.2019 12:40Плюс можно будет попросить у вас скрипты которыми данные вытягиваете о которых в своем комментарии написали. Заранее спасибо.

AlanDenton
03.08.2019 10:22
uaggster
Вот тут вопрос созрел…
А оно будет работать поверх тонких и ненадежных каналов? Тонких — ладно, а вот ненадежных?
А то у меня сервера и, скажем так, на Чукотке и в Магадане есть.
Нет, конечно, с интернетом там всё сильно лучше стало.
Сильно, да.
AlanDenton
В коде предусмотрен функционал если разрывается соединение, то команду пробуем заново выполнять. Но это не для всех запросов предусмотрено.
jobgemws Автор
в коде есть просто обработка исключений, однако не предусмотрено кусками передавать инфу, что для нестабильных сетей кстати сказать существенно. Думаю стоит взять на заметку AlanDenton
AlanDenton
Ну не совсем так. Реализован механизм частичного дескрайба. То есть все тянется не одним большим запросом, а вначале получаются все мелкие индексы за раз, а потом в цикле добирается точечными запросами большие по размеру индексы (если что настраивается).
jobgemws Автор
И что будет если по середине произойдет обрыв сети? Если обрывы будут постоянными до 35 сек каждую минуту?
uaggster
Это я к тому, что всё обслуживание, всё, что длится дольше пары минут — приходится делать одноразовыми джобами на той стороне.
AlanDenton
Тут as design. Если обрывается соединение, то и запрос будет откатываться. Для таких целей есть функционал копирования сгенерированного скрипта и его запуск со стороны сервака.
jobgemws Автор
Да, это решает проблему. Спасибо