
В статье рассказывается как при внедрении WMS-системы мы столкнулись с необходимостью решения нестандартной задачи кластеризации и какими алгоритмами мы ее решали. Расскажем, как мы применяли системный, научный подход к решению проблемы, с какими сложностями столкнулись и какие уроки вынесли.
Эта публикация начинает цикл статей, в которых мы делимся своим успешным опытом внедрения алгоритмов оптимизации в складские процессы. Целью цикла статей ставится познакомить аудиторию с видами задач оптимизации складских операций, которые возникают практически на любом среднем и крупном складе, а также рассказать про наш опыт решения таких задач и встречающиеся на этом пути подводные камни. Статьи будут полезны тем, кто работает в отрасли складской логистики, внедряет WMS-системы, а также программистам, которые интересуются приложениями математики в бизнесе и оптимизацией процессов на предприятии.
Узкое место в процессах
В 2018 году мы сделали проект по внедрению WMS-системы на складе компании «Торговый дом «ЛД» в г. Челябинске. Внедрили продукт «1С-Логистика: Управление складом 3» на 20 рабочих мест: операторы WMS, кладовщики, водители погрузчиков. Склад средний около 4 тыс. м2, количество ячеек 5000 и количество SKU 4500. На складе хранятся шаровые краны собственного производства разных размеров от 1 кг до 400 кг. Запасы на складе хранятся в разрезе партий, так как есть необходимость отбора товара по FIFO.
При проектировании схем автоматизации складских процессов мы столкнулись с существующей проблемой неоптимального хранения запасов. Специфика хранения и укладки кранов такая, что в одной ячейке штучного хранения может находиться только номенклатура одной партии. Продукция приходит на склад ежедневно и каждый приход – это отдельная партия. Итого, в результате 1 месяца работы склада создаются 30 отдельных партий, притом, что каждая должна хранится в отдельной ячейке. Товар зачастую отбирается не целыми палетами, а штуками, и в результате в зоне штучного отбора во многих ячейках наблюдается такая картина: в ячейке объемом более 1м3 лежит несколько штук кранов, которые занимают менее 5-10% от объема ячейки.

На лицо неоптимальное использование складских мощностей. Чтобы представить масштаб бедствия могу привести цифры: в среднем таких ячеек объемом более 1м3 с «мизерными» остатками в разные периоды работы склада насчитывается от 100 до 300 ячеек. Так как склад относительно небольшой, то в сезоны загрузки склада этот фактор становится «узким горлышком» с сильно тормозит складские процессы.
Идея решения проблемы
Возникла идея: партии остатков с наиболее близкими датами приводить к одной единой партии и такие остатки с унифицированной партией размещать компактно вместе в одной ячейке, или в нескольких, если места в одной не будет хватать на размещение всего количества остатков.
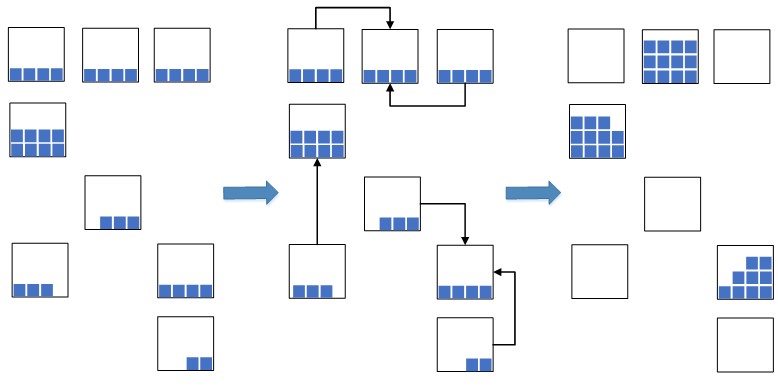
Рис.2. Схема сжатия остатков в ячейках
Это позволяет значительно сократить занимаемые складские площади, которые будут использоваться под новый размещаемый товар. В ситуации с перегрузкой складских мощностей такая мера является крайне необходимой, в противном случае свободного места под размещение нового товара может попросту не хватить, что приведет к стопору складских процессов размещения и подпитки. Раньше до внедрения WMS-системы такую операцию выполняли вручную, что было не эффективно, так как процесс поиска подходящих остатков в ячейках был достаточно долгим. Сейчас с внедрением WMS-системы решили процесс автоматизировать, ускорить и сделать его интеллектуальным.
Процесс решения такой задачи разбивается на 2 этапа:
- на первом этапе мы находим близкие по дате группы партий для сжатия;
- на втором этапе мы для каждой группы партий вычисляем максимально компактное размещение остатков товара в ячейках.
В текущей статье мы остановимся на первом этапе алгоритма, а освещение второго этапа оставим для следующей статьи.
Поиск математической модели задачи
Перед тем как садиться писать код и изобретать свой велосипед, мы решили подойти к такой задаче научно, а именно: сформулировать ее математически, свести к известной задаче дискретной оптимизации и использовать эффективные существующие алгоритмы для ее решения или взять эти существующие алгоритмы за основу и модифицировать их под специфику решаемой практической задачи.
Так как из бизнес-постановки задачи явно следует, что мы имеем дело с множествами, то сформулируем такую задачу в терминах теории множеств.
Пусть – множество всех партий остатков некоторого товара на складе. Пусть – заданная константа дней. Пусть – подмножество партий, где разница дат для всех пар партий подмножества не превосходит константы . Требуется найти минимальное количество непересекающихся подмножеств , такое что все подмножества в совокупности давали бы множество .
Иными словами, нам нужно найти группы или кластеры схожих партий, где критерий схожести определяется константой . Такая задача напоминает нам хорошо известную всем задачу кластеризации. Важно сказать, что рассматриваемая задача отличается от задачи кластеризации, тем что в нашей задаче есть жестко заданное условие по критерию схожести элементов кластера, определяемое константой , а в задаче кластеризации такое условие отсутствует. Постановку задачи кластеризации и информацию по этой задаче можно найти здесь.
Итак, нам удалось сформулировать задачу и найти классическую задачу с похожей постановкой. Теперь необходимо рассмотреть общеизвестные алгоритмы для ее решения, чтобы не изобретать велосипед заново, а взять лучшие практики и применить их. Для решения задачи кластеризации мы рассматривали самые популярные алгоритмы, а именно: -means, -means, алгоритм выделения связных компонент, алгоритм минимального остовного дерева. Описание и разбор таких алгоритмов можно найти здесь.
Для решения нашей задачи алгоритмы кластеризации -means и -means не применимы вовсе, так как заранее никогда не известно количество кластеров и такие алгоритмы не учитывают ограничение константы дней. Такие алгоритмы были изначально отброшены из рассмотрения.
Для решения нашей задачи алгоритм выделения связных компонент и алгоритм минимального остовного дерева подходят больше, но, как оказалось, их нельзя применить «в лоб» к решаемой задаче и получить хорошее решение. Чтобы пояснить это, рассмотрим логику работы таких алгоритмов применительно к нашей задаче.
Рассмотрим граф , в котором вершины – это множество партий , а ребро между вершинами и имеет вес равный разнице дней между партиями и . В алгоритме выделения связных компонент задается входной параметр , где , и в графе удаляются все ребра, для которых вес больше . Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение , при котором граф «развалится» на несколько связных компонент, где партии, принадлежащие этим компонентам, будут удовлетворять нашему критерию схожести, определяемому константой . Полученные компоненты и есть кластеры.
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом до тех пор, пока граф не «развалится» на несколько связных компонент, где партии, принадлежащие этим компонентам, будут также удовлетворять нашему критерию схожести. Полученные компоненты и будут кластерами.
При использовании таких алгоритмов для решения рассматриваемой задачи может возникнуть ситуация как на рисунке 3.
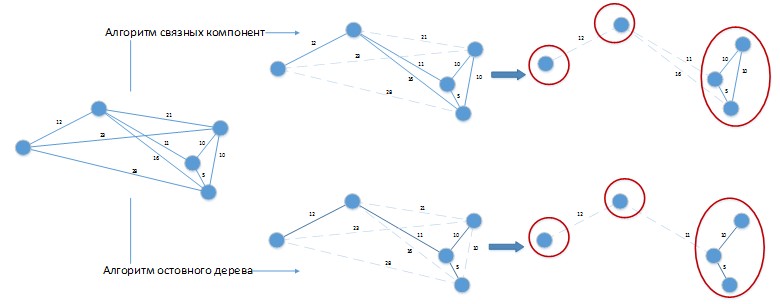
Рис 3. Применение алгоритмов кластеризации к решаемой задаче
Допустим у нас константа разницы дней партий равна 20 дней. Граф был изображен в пространственном виде для удобства визуального восприятия. Оба алгоритма дали решение с 3-мя кластерами, которое можно легко улучшить, объединив партии, помещенные в отдельные кластеры, между собой! Очевидно, что такие алгоритмы необходимо дорабатывать под специфику решаемой задачи и их применение в чистом виде к решению нашей задачи будет давать плохие результаты.

Итак, прежде чем начинать писать код модифицированных под нашу задачу графовых алгоритмов и изобретать свой велосипед (в силуэтах которого уже угадывались очертания квадратных колес), мы, опять же, решили подойти к такой задаче научно, а именно: попробовать свести ее к другой задаче дискретной оптимизации, в надежде на то, что существующие алгоритмы для ее решения можно будет применить без модификаций.
Очередной поиск похожей классической задачи увенчался успехом! Удалось найти задачу дискретной оптимизации, постановка которой 1 в 1 совпадает с постановкой нашей задачи. Этой задачей оказалась задача о покрытии множества. Приведем постановку задачи применительно к нашей специфике.
Имеется конечное множество и семейство всех его непересекающихся подмножеств партий, таких что разница дат для всех пар партий каждого подмножества из семейства не превосходит константы . Покрытием называют семейство наименьшей мощности, элементы которого принадлежат , такое что объединение множеств из семейства должно давать множество всех партий .
Подробный разбор этой задачи можно найти здесь и здесь. Другие варианты практического применения задачи о покрытии и её модификаций можно найти здесь.
Алгоритм решения задачи
С математической моделью решаемой задачи определились. Теперь приступим к рассмотрению алгоритма для ее решения. Подмножества из семейства можно легко найти следующей процедурой.
- Упорядочить партии из множества в порядке убывания их дат.
- Найти минимальную и максимальную даты партий.
- Для каждого дня от минимальной даты до максимальной найти все партии, даты которых отличаются от не более чем на (поэтому значение лучше брать четное).
Логика работы процедуры формирования семейства множеств при дней представлена на рисунке 4.

Рис.4. Формирование подмножеств партий
В такой процедуре необязательно для каждого перебирать все другие партии и проверять разность их дат, а можно от текущего значения двигаться влево или право до тех пор, пока не нашли партию, дата которой отличается от более чем на половинное значение константы. Все последующие элементы при движении как вправо, так и влево будут нам не интересны, так как для них различие в днях будет только увеличиваться, поскольку элементы в массиве были изначально упорядочены. Такой подход будет существенно экономить время, когда число партий и разброс их дат значительно большие.
Задача о покрытии множества является -трудной, а значит для её решения не существует быстрого (с временем работы равному полиному от входных данных) и точного алгоритма. Поэтому для решения задачи о покрытии множества был выбран быстрый жадный алгоритм, который конечно не является точным, но обладает следующими достоинствами:
- Для задач небольшой размерности (а это как раз наш случай) вычисляет решения достаточно близкие к оптимуму. С ростом размера задачи качество решения ухудшается, но всё же довольно медленно;
- Очень прост в реализации;
- Быстр, так как оценка его времени работы равна .
Жадный алгоритм выбирает множества руководствуясь следующим правилом: на каждом этапе выбирается множество, покрывающее максимальное число ещё не покрытых элементов. Подробное описание алгоритма и его псевдокод можно найти здесь.
Сравнение точности такого жадного алгоритма на тестовых данных решаемой задачи с другими известными алгоритмами, такими как вероятностный жадный алгоритм, алгоритм муравьиной колонии и т.д., не производилось. Результаты сравнения таких алгоритмов на сгенерированных случайных данных можно найти в работе.
Реализация и внедрение алгоритма
Такой алгоритм был реализован на языке 1С и был включен во внешнюю обработку под названием «Сжатие остатков», которая была подключена к WMS-системе. Мы не стали реализовывать алгоритм на языке С++ и использовать его из внешней Native компоненты, что было бы правильней, так как скорость работы кода на C++ в разы и на некоторых примерах даже в десятки раз превосходит скорость работы аналогичного кода на 1С. На языке 1С алгоритм был реализован для экономии времени на разработку и простоты отладки на рабочей базе заказчика. Результат работы алгоритма представлен на рисунке 5.
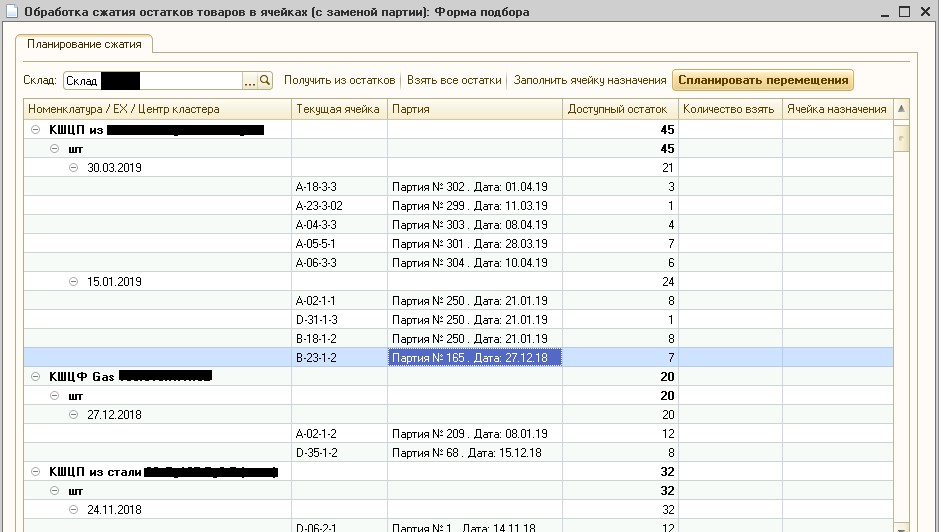
Рис.5. Обработка по «сжатию» остатков
На рисунке 5 видно, что на указанном складе текущие остатки товаров в ячейках хранения разбились на кластеры, внутри которых даты партий товаров отличаются между собой не более чем на 30 дней. Так как заказчик производит и хранит на складе металлические шаровые краны, у которых срок годности исчисляется годами, то такой разницей дат можно пренебречь. Отметим, что в настоящее время такая обработка используется в продакшене систематически, и операторы WMS подтверждают хорошее качество кластеризации партий.
Выводы и продолжение
Главный опыт, который мы получили от решения такой практической задачи – это подтверждение эффективности использования парадигмы: мат. формулировка задачи известная мат. модель известный алгоритм алгоритм с учетом специфики задачи. Дискретной оптимизации уже насчитывается более 300 лет и за это время люди успели рассмотреть очень много задач и накопить большой опыт по их решению. В первую очередь целесообразнее обратиться к этому опыту, а уж потом начинать изобретать свой велосипед.
В следующей статье мы продолжим рассказ о алгоритмах оптимизации и рассмотрим самое интересное и гораздо более сложное: алгоритм оптимального «сжатия» остатков в ячейках, который использует на входе данные, полученные от алгоритма кластеризации партий.
Статью подготовил
Роман Шангин, программист департамента проектов,
компания Первый БИТ, г. Челябинск
Комментарии (38)

caballero
13.08.2019 10:15Намного проще если партией считать товар по одинаковой входной цене независимо от поступления. Это ж не лекарства что по сроку годности надо учитывать.

1c1bit Автор
13.08.2019 10:20под партией вообще много что можно понимать. В данном случае цена ни при чем, эта продукция на склад приходит прямо с цеха производства. Одна из характеристик партии, это дата, в данном случае дата производства, по этому параметру и была классификация.
Учет по датам производства был требованием заказчика, так как до внедрения WMS системы у них была проблема с устареванием товара на складе.
TiesP
13.08.2019 10:36По идее, если использовать постоянную «разницу дат», то всё равно ячейки будут заполняться неравномерно — где больше, где меньше. Может задачу немного переформулировать?
1c1bit Автор
13.08.2019 10:56к этому термину «постоянная разница дат» мы с заказчиком приходили уже как-то :) Вы, наверное, имеете ввиду учет постоянной разницы дат при самОм помещении товаров в ячейки? То есть перед помещением товара в ячейку учитываем даты имеющиеся в ячейках, и кладем товар в ту ячейку, где партия отличается не более чем на заданную постоянную разницу дат. Верно я понял Вас?
Но тогда даже возникает потребность в сжатии, хотя конечно ситуацию улучшает (они так и делают сейчас). Могу в принципе показать на примере, но, думаю, вы его сами можете смоделировать :)TiesP
13.08.2019 11:07Нет, я имел в виду решать немного другую задачу: вместо «найти партии в фиксированном промежутке дат» >>> «заполнить ячейки как можно плотнее». Т.е. разница дат может быть не постоянной в 30 дней, но товары всё равно будут из ближайших партий.
Вообще интересно, как это происходит на практике у заказчика. Например, алгоритм нашел новое распределение. Надо переложить товары — но это же огромный объем работы для большого склада. Или эта процедура происходит не часто?1c1bit Автор
13.08.2019 11:1630 дней это максимальная разница дат между каждой парой партий в кластере. По факту разница может быть и 5 и 1 и даже 0 дней. А большей этой даты в 30 дней клиент не хочет товар объединять, так как краны это не пирожки конечно же, но тоже свой срок годности на складе имеют (может ржавчина появиться без спец покрытия и т.д.). Или вы другое имели ввиду?
процедура делается регламентно раз в неделю или по требованию, когда места критически мало становится.TiesP
13.08.2019 11:32Ясно, я думал можно объединять с бОльшим разбросом дат.
Интересно, как ваш алгоритм объединит их и разложит по двум ячейкам в такой ситуации?
Например, есть три Партии в трёх разных Ячейках — День 1 = 50; День 29=50; День 30=50. Ячейка вмещает 100. Все даты в одном промежутке 30 дней.1c1bit Автор
13.08.2019 12:46это хороший вопрос. Как раз здесь выходят на сцену алгоритмы комбинаторной оптимизации (скоро опубликуем в следующих статьях). Будет учитываться расстояние между ячейками. Оно в данном случае будет играть ключевую роль. Будем рады дельным комментам в следующих публикациях :)
gennayo
13.08.2019 11:14Учёт шаровых кранов в разрезе дат изготовления — это похоже на создание себе трудностей с их последующим героическим преодолением. Более логичен учёт по сериям, например, с возрастанием номера серии раз в месяц.
1c1bit Автор
13.08.2019 11:28партия нужна не только для FIFO. Она нужна например и для простоты отслеживания истории складских операций, когда приходит претензия на битые товары. Чем мельче аналитика проще можно просмотреть историю операций, чем крупнее, тем сложнее. Но это только часть.
Даже в том решение, которое вы предлагаете, возникнет потребность с сжатии (думаю, вы сами сможете это смоделировать).
на похожий вопрос ответил в комментарииMinimaJack
13.08.2019 12:09Компрессия склада нужна при любом алгоритме.
Пришла претензия на битые товары? И что? Это может быть как заводской брак, так и удар на складе, так и в машине перевозчика…
Ни разу на моей памяти ударенный(отгруженный товар) не компенсировали за счет склада; уверен что в 99.99% случаев битый товар просто списывается(разбирается по возможности).
Вот если «жахнули» на складе — тогда и вопросов нет, но там и историю отслеживать не нужно — все и так видно кто-где накосячил… камеры то стоят =)1c1bit Автор
13.08.2019 12:49отслеживание нужно по большей части для санкций к конкретным сотрудникам, чтобы впредь этого не делали и репутацию компании не портили. А кто именно, определяется по операциям. Получается набор моментов времени, а там уже смотрят камеры если нужно :)
gennayo
13.08.2019 12:34Решений как обеспечить прослеживаемость может быть много. И далеко не факт, что для этого нужен раздел аналитики в ВМС. С другой стороны, не зная оборачиваемость и количество заказов и позиций в них правильных вариантов не предложить.
1c1bit Автор
13.08.2019 12:53да, решений по прослеживаемости действительно много. Для тотальной прослежки можно ввести уникальные идентификаторы на каждую единицу упаковки товара, но это влечет трудности с выполнением складских операций (за прозрачность нужно платить). Если без партий вообще (все в общий котел), то там очень долго и трудно концы искать потом.
Ildarovich
15.08.2019 00:27Могу ошибаться, но предположу, что задача классифицирована неправильно.
По-моему, это занимательная «математическая» задача, но не более того.
Ведь если изобразить партии на временной оси (0, T), то, если там нет пропусков длиной более C, тогда минимальное число партий ВСЕГДА будет ] T / С [, то есть ближайшее сверху целое от деления размера интервала между первой и последней партией на «масштабный коэффициент» С.
Если промежутки есть, то к каждому разделенному промежутками «островку» применяется та же формула, определяющая число партий.
То есть минимальное число партий однозначно определяется простой формулой. Из нее же следует очевидный алгоритм разбиения на партии. Для реализации которого и 1С будет достаточно (даже запросом можно обойтись).
Некоторая вариативность просматривается в мелком движении границ партий, если до ближайшего сверху есть зазор ] T / С [ — T / С. Но на число партий это не повлияет.
А еще легче было бы вообще помечать партии не днем, а месяцем выпуска. В итоге бизнес-результат, думаю, был бы тем же.
А вот если бы декомпозиции на две задачи: «укрупнение партий» и «компрессия ячеек» не было, то задача в целом была бы поинтереснее.MinimaJack
15.08.2019 10:19то, если там нет пропусков длиной более C, тогда минимальное число партий ВСЕГДА будет ] T / С [
Наверное имелось ввиду: если разбить интервал от Тmin до Тmax, с длиной пропуска С — всегда получится точное количество новых партий (при округлении вверх). Разница формирования будет зависеть лишь от направлении сворачивания партий слева-справа.
Аналогично считаю что отметка партии месяцем — дала бы точно такой же бизнес-результат.
1c1bit Автор
15.08.2019 11:05коммент интересный, спасибо, но вы немного не правы :) Поясню.
1. Если взять такую ситуацию, что промежутков больше C нет, то как вы выражаетесь "]T/С[" является верхней оценкой величины минимального числа партий. То есть больше быть не может, а вот меньше да ]T/С[ — 1. Например, вот рисунок. Здесь Т делится нацело на С.

то есть экономим 1 «кластер», ну и чем больше таких островков будет, тем больше Ваш алгоритм будет ошибаться. Кстати, такую идею мы самую первую и рассмотрели, но отказались :)
2. По месяцу я писал уже в других комментариях, да сейчас они так и делают (если есть существующая партия и разница дней приемлемая, то присваивают не новую, а существующую). Да, это снижает бедствие, но кладовщики не всегда это делают и присваивают новую партию. Иногда случается, что выпускается отдельная партия для клиента, но он не забирает ее всю. Вот и остатки образуются.
3. Да, решение таких задач вместе было бы более интересным и эффективным. Но, увы, там алгоритмы были бы сложнее, а бюджет был ограничен. Решили сделать все проще и прозрачнее.MinimaJack
15.08.2019 11:16В вашем 2-м решении в одном кластере оказались партии с датами более С
1c1bit Автор
15.08.2019 11:21здесь 4 отрезка с длиной С (прошу прощения, обозначить забыл). Ну а разница дат партий в этих группах менее С, даже визуально. Или Вы другое имели ввиду?
MinimaJack
15.08.2019 11:27
Как у вас 1,2 и 3 партии слились, если разница между 1 и 3 превышает С?
Аналогично 6,7,8....1c1bit Автор
15.08.2019 11:36так это 2 разные ситуации. Они никак не связаны. В первой ситуации, только на 4 группы можно, а во воторой на 3. Или я Вас не так понял?
MinimaJack
15.08.2019 11:49- Алгоритм не от 0 до Tmax — а от Tmin до Tmax, результат тот же был...
- Почему то для центра кластера выбирается "взвешенная" дата партии — при таком раскладе ай ай ай…
1 мелкая партия
2 и 3 партии большие
На первом этапе: 1 и 2 партии сливаются — центр смещается ко второй
На втором этапе уже 4( 1 + 2) и 3 партия сливаются и тут ай ай ай ой ой ой. По факту 1 и 3 партия слились, что не допустимо по условиям задачи =)

p.s. да в общем то неважно какой центр выбирать… что так, то эдак. Пока не будет информации о минимальной и максимальной даты в партии — будут некорректные слияния
1c1bit Автор
15.08.2019 12:011. разницы для 0 до Tmax и для от Tmin до Tmax не вижу. От Tmin можно прийти в 0, если от всех дат вычесть Tmin, как бы нормировать.
2. Что Вы понимаете под весом, и почему решили, что он взялся? Количество штук в партии при кластеризации не учитывается.MinimaJack
15.08.2019 12:10- тогда Tmax — уже будет не тот
- Дата результирующей партии зависит от количества изделий.
Давайте проще поступим — вы приведете исходные данные на которых ваш алгоритм сформирует меньше кластеров, чем предложенный выше.
Ildarovich
15.08.2019 11:59Не согласен.
На вашем рисунке в случае 2 делимый интервал должен начинаться не в 0, а в Тmin. И тогда также получится три кластера.
Под 0 подразумевалось начало «островка».
Не думал, что это вызовет спор.
Нужно было написать еще Т = Тmах — Tmin для полной определенности.
А как вы меня поняли, то вообще имеете ввиду не алгоритм, а простейшую формулу
ДатаПартииНовая = Цел (ДатаПартии / С) * С,
в которой будут случаи, где из-за регулярной сетки партий слева от островка и справа от него иногда будет пустое место, которое вместе составит целый кластер. И, сместив, начало первого кластера, можно будет один сэкономить. Вероятность этого можно посчитать, она небольшая, но есть. Поэтому алгоритм немного лучше, чем формула, но я ее и не предлагал.
В целом я просто хотел сказать, что никакой сложной математики в этой части задачи нет. Математика элементарная. И упоминать кластеризацию, теорию графов, задачу о минимальных покрытиях было, по моему мнению, не нужно.
А вообще выход видится в уникальных штрих-кодах на каждую единицу продукции. Такая этикетка и даст нужную прослеживаемость. А эмуляция маленькой бумажной этикетки партии целой складской ячейкой и приводит к затратам на компрессию, в ходе которой прослеживаемость исчезает чуть ли не полностью. Жалко, когда математика служит неправильно поставленным целям «разработать алгоритм, который будет методично все сваливать в кучи».MinimaJack
15.08.2019 12:05
Так в том и прикол, что у них есть этикетки с датами выпуска… по крайней мере все что в каталоге — с ними.
1c1bit Автор
15.08.2019 12:26хорошо, тогда простой алгоритм какое число групп даст по этому рисунку:

4? Т поставил далеко в право, но смысл вроде не меняет.MinimaJack
15.08.2019 12:393! Да верхней оценкой
Да простят меня пользователи Хабра за код. Можете тестировать до дыр =)
Код 1СФункция Лог( Массив) Если Массив.Количество()>0 Тогда Сообщить("Объединение партий"); Для каждого флп_объеденить Из Массив Цикл Сообщить(Символы.Таб + флп_объеденить); КонецЦикла; Сообщить("Конец объединение"); КонецЕсли; КонецФункции Данные = Новый ТаблицаЗначений; Данные.Колонки.Добавить("Дата"); Данные.Колонки.Добавить("Партия"); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190101'), "1 партия")); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190130'), "2 партия")); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190201'), "3 партия")); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190228'), "4 партия")); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190301'), "5 партия")); ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура("Дата, Партия", Дата('20190330'), "6 партия")); Данные.Сортировать("Дата Возр"); флп_Объединяемые = Новый массив; С = 30; //дней макисмум МаксимальнаяДата = Дата('00010101'); Для каждого флп_строка Из Данные Цикл Если МаксимальнаяДата > флп_строка.Дата Тогда флп_Объединяемые.Добавить(флп_строка.Партия); Иначе Лог(флп_Объединяемые); флп_Объединяемые = Новый массив; МаксимальнаяДата = флп_строка.Дата + С*60*60*24; флп_Объединяемые.Добавить(флп_строка.Партия); КонецЕсли; КонецЦикла; Лог(флп_Объединяемые); //остаток1c1bit Автор
15.08.2019 14:05MinimaJack, спасибо за код. Да, я думал вы предлагаете просто разбивать на отрезки, так как предлагали брать целое при делении. Просто в каких-то примерах количество групп может быть целое при делении, а где-то целое +1. Не вник до конца в Ваше предложение.
Сейчас понимаю, что я упустил сказать об одном условии в тексте статьи, что требовалось не просто разбить на минимальное количество групп, а еще при этом попытаться максимизировать количество элементов в группе. В таком случае последующее сжатие остатков с большим количеством ячеек предполагается (здесь конечно не более чем умственное рассуждение) более качественным.
Поясню на примере. Если в исходный пример добавить такие данные:
данные в коде 1СЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190101'), «1 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190130'), «2 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190130'), «3 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190201'), «4 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190301'), «5 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190301'), «6 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190301'), «7 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190304'), «8 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190304'), «9 партия»));
ЗаполнитьЗначенияСвойств(Данные.Добавить(), Новый Структура(«Дата, Партия», Дата('20190304'), «10 партия»));MinimaJack
16.08.2019 11:58Вы точно предоставили вывод своего алгоритма?
Почему не {5,6,7,8,9,10},{4,3,2},{1} — так ведь более оптимально...1c1bit Автор
16.08.2019 12:09да, прошу прощения. Такое разбиение как у Вас получится, опечатался. Алгоритм то жадный. Сам алгоритм не запускал на этих, так как немного другая структура данных на входе. Хотел показать, что наибольшее множество будет другим.
Iskender
15.08.2019 11:07Наверное я что-то не так понял, но кажется что перемудрили. Извините и поправьте пожалуйста, если не разобрался в вашей проблеме )
Есть числа x1 < x2 <… < xn (даты) и надо найти покрытие минимальным числом отрезков длины не более c.
Мы знаем что x1 должен принадлежать какому-то элементу покрытия. Не умаляя общности можем считать что это левый край интервала длины c (всегда можем расширить интервал и сдвинуть его вправо не ухудшив ситуацию). После этого выкидываем точки которые попали в этот интервал, берём следующий минимум, это край следующего интервала. Повторяем, так находим искомое покрытие.
Почему так просто. Ваша модель покрывает больше чем надо, у вас просто подмножества с расстоянием. Не учитывается что даты это просто точки на отрезке (вместо рассмотрения абстрактного метрического пространства).1c1bit Автор
15.08.2019 11:11да, Ваш алгоритм очень похож на алгоритм в комментарии. По поводу его я ответил. Да, конечно, этот алгоритм более общий чем решаемая задача.
MinimaJack
Как соотносится
с тем что остаются штучные остатки партий?1c1bit Автор
Если честно, не совсем понял вопроса, но постараюсь ответить. Штучные остатки во многих ячейках остаются потому что в 1 ячейке должна храниться только 1 партия (это требование из-за специфики продукции), а партий много, они каждый день приходят.
А по FIFO отбираем чтобы не оставалось старого залежавшегося товара на складе.
Если не ответил на вопрос, то поясните, что имели ввиду
MinimaJack
Приходят то понятно что каждый день, но почему они не уходят по ФИФО?
Начало:1 партия - 50 шт
2 партия - 50 шт
Забрали - 49 шт
Остаток:
1 партия - 1 шт
2 партия - 50 шт
Забрали - 50 шт
Остаток:
1 партия - 0 шт
2 партия - 1 шт
При списании по ФИФО, никаких штучных остатков не должно оставаться… А если у вас остаются, значит у вас нет ФИФО.
1c1bit Автор
да, вы все верно написали, но это если не учитывать специфику складских операций. По факту ячейки с мелкими остатками товаров получаются из-за таких основных причин:
1. Каждый день: новая партия производства, так как новая дата. В результате получаем что небольшое количество штучных остатков помещаются в разные ячейки, хотя можно было поместить, например, в одну (сжать).
2. здесь посложнее.
а) Допустим, у нас палет товара с датой 1.01 размещается на верхние этажи и ждет своей очереди, когда его спустят в зону отбора штучного товара, когда там остатки снизятся до минимального уровня.
б) Потом штучный товар с датой 10.01 при приемке размещается сразу в зону отбора штук (так настроены правила размещения и это логично).
в) потом остаток штучного товара опускается до установленного минимума и спускается наш старый палет с датой 1.01. И его начинают отбирать по FIFO (он же самый старый).
г) и наступает ситуация, когда в ячейках с датами 1.01 и датой 10.01 остается мизерные остатки. Вот здесь и нужно сжатие, чтобы экономить драгоценное место в зоне отбора штучного товара :)