Имена сотрудников может и изменены, а вот задачи вполне себе реальны!
На часах 12:45, вся команда собирается в переговорке. Первым слово берет Иван, стажёр-разработчик.
Иван:
Я работал над задачей отображения всех возможных вариантов сумм, которые пассажир мог дать водителю при известной стоимости поездки. Задача достаточно известная — называется «Размен монет». С учётом специфики добавил в алгоритм несколько оптимизаций. Отдал пул-реквест на ревью еще позавчера, но с тех пор я исправляю замечания.
По довольной улыбке Анны стало понятно, чьи замечания исправляет Иван.
В первую очередь произвёл минимальную декомпозицию алгоритма, раcхардкодил получение банкнот. В первой реализации возможные банкноты были прописаны в коде, поэтому вынес их в конфиг по странам.
Добавил комментариев на будущее, чтобы любой читающий мог быстро разобраться в алгоритме:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value) # основные разветвления алгоритма дают некратные купюры for exception in self.exceptions[banknote]: # для таких исключений можно посчитать результат по остатку от # деления таких купюр exc_value = value + exception.delta # но при этом результат не может получиться больше самой банкноты # (corner case) if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Ну и, естественно, остаток времени потратил на покрытие всего кода тестами.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [ # no banknotes ( 321, [], [], ), # zero cost ( 0, RUB, [], ), # negative cost ( -13, RUB, [], ), # simple testcase ( 264, RUB, [265, 270, 300, 400, 500, 1000, 2000, 5000], ), # cost bigger than max banknote ( 6120, RUB, [6121, 6150, 6200, 6300, 6500, 7000, 8000, 10000], ), # min cost ( 1, RUB, [2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000], ), ... ], )
Помимо обычных тестов, которые запускаются при каждом билде проекта, написал тест, использующий алгоритм без оптимизаций (считай — полный перебор). Результат работы этого алгоритма для каждой купюры из первых 10 тысяч случаев положил в файл и прогнал отдельно на алгоритме с оптимизациями, чтобы быть уверенным, что он действительно работает верно.
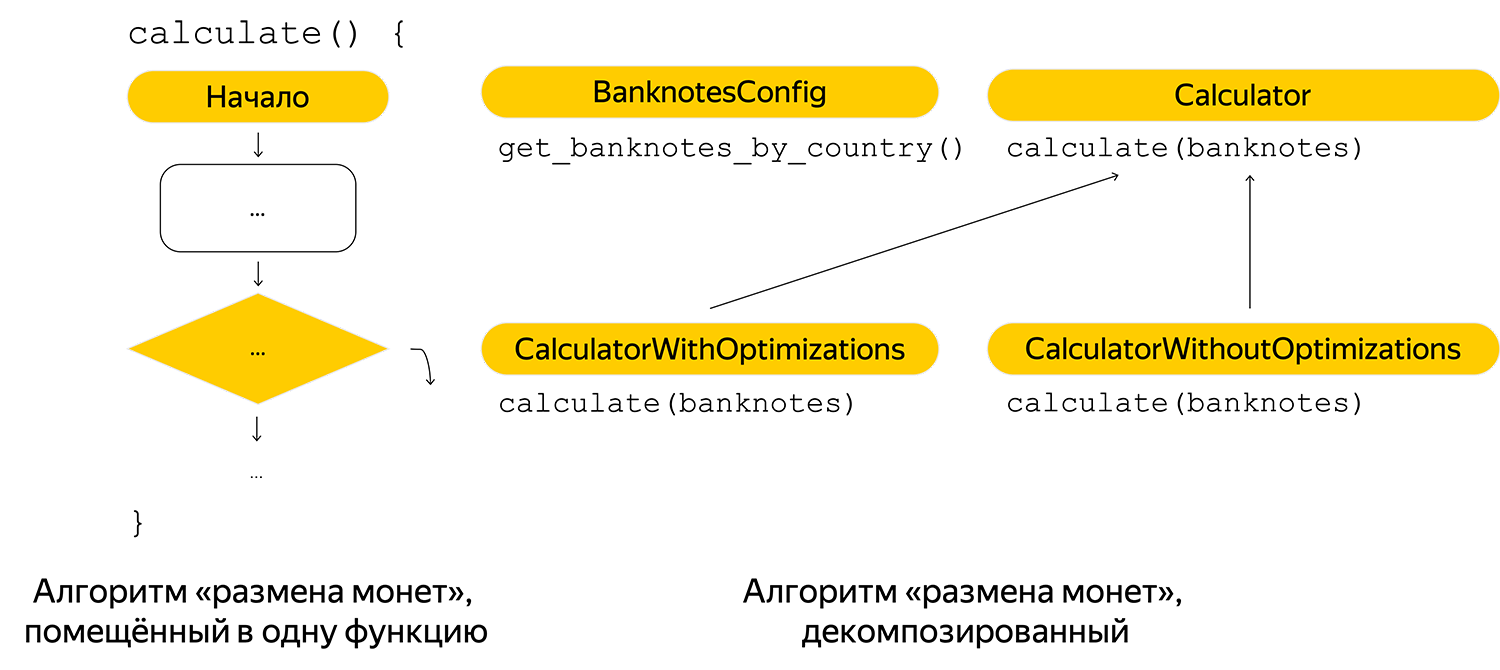
Давайте на минуту отвлечёмся от стендапа и подведем локальные итоги всего того, о чём говорит Иван. При написании кода основная цель — обеспечить его работоспособность. Чтобы эта цель была достигнута, необходимо выполнить следующие задачи:
- Декомпозировать бизнес-логику на атомарные фрагменты. Читаемость усложняется при просмотре полотна кода, написанного в одной функции.
- Добавить комментарии в «особо сложные» части кода. У нас в команде следующий подход: если на код-ревью задают вопрос по поводу реализации (просят объяснить алгоритм), то необходимо добавить комментарий. А ещё лучше подумать об этом заранее и добавить его самому.
- Написать тесты, покрывающие основные ветви выполнения алгоритмов. Тесты — не только метод проверки работоспособности кода. Они ещё выполняют роль примера использования вашего модуля.
Увы, но даже специалисты с многолетним опытом не всегда используют эти подходы в своей работе. В Школе бэкенд-разработки, которую мы сейчас делаем, студенты получат практические навыки написания архитектурно качественного кода. Ещё одна наша цель — распространение практик покрытия проекта тестами.
Но вернёмся на стендап. После Ивана выступает Анна.
Анна:
Я разрабатываю микросервис отдачи промотирующих изображений. Как вы помните, сервис изначально отдавал статичные данные-стабы. Затем тестировщики попросили кастомизировать их, и я вынесла их в конфиг, а сейчас делаю «честную» реализацию с отдачей данных из базы (PostgreSQL 10.9). Мне очень помогла заложенная изначально декомпозиция, в рамках которой интерфейс получения данных в бизнес-логике не меняется, а каждый новый источник (будь то конфиг, база данных или внешний микросервис) лишь реализует свою логику.Вадим:
Я проверила написанную систему под нагрузкой, тестирование показало, что ручка начинает резко тормозить, когда мы ходим в БД. По explain увидела, что индекс не используется. Пока не придумала, как пофиксить.

А что за запрос?Аня:
Два условия под OR:Вадим:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Explain запроса показал, что в нём не используется один из индексов по атрибутам attr1 таблицы table_2 и attr2 таблицы table_1.
Сталкивался с аналогичным поведением в MySQL, проблема как раз в условии по OR, из-за которого используется лишь один индекс, скажем, attr2. А второе условие использует seq scan — полный проход по таблице. Запрос можно разбить на два независимых запроса. Как вариант — разделить и замержить результат запросов на стороне бэкенда. Но тогда нужно подумать над тем, чтобы обернуть эти два запроса в транзакцию, либо объединить их с помощью UNION — по сути, на стороне базы:Аня:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Спасибо, попробую ^_^
Снова подведём итоги:
- Почти все задачи продуктовой разработки связаны с получением записей из внешних источников (сервисов или баз данных). Нужно тщательно подойти к вопросу декомпозиции классов, выгружающих данные. Правильно спроектированные классы позволят вам без проблем писать тесты и модифицировать источники данных.
- Чтобы эффективно работать с БД, нужно знать особенности выполнения запросов, например разбираться в explain.
Работа с информацией и организация потоков данных — неотъемлемая часть задач любого бэкенд-разработчика. Школа познакомит с архитектурой взаимодействия сервисов (и источников данных). Студенты научатся работать с базами архитектурно и с точки зрения эксплуатации — миграции данных и тестирования.
Последним на встрече выступает Вадим.
Вадим:
Я на неделе дежурил, разбирал очередь инцидентов. Одна нелепая ошибка в коде заняла ну очень много времени: в проде не было логов по запросу, хотя их создание было прописано в коде.
По скорбному молчанию всех присутствующих понятно — все уже так или иначе сталкивались с проблемой.
Для получения всех логов в рамках запроса используется request_id, который прокидывается во все записи в следующем виде:
# запись без request_id logger.info( 'my log msg', ) # запись с request_id logger.info( 'my log msg', extra=log_extra, # здесь передается request_id — связующая информация о запросе )
log_extra — это словарь с метаинформацией запроса, ключи и значения которого будут записаны в лог. Без передачи log_extra в функцию логирования запись не будет связана со всеми другими логами, потому что в ней не будет request_id.
Пришлось исправлять ошибку в сервисе, перевыкатывать его и лишь потом разбираться с инцидентом. Такое случается уже не первый раз. Чтобы больше это не повторялось, я постарался исправить проблему глобально и избавиться от log_extra.
Сначала я написал враппер над стандартным исполнением запроса:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
Нужно было решить, каким образом хранить log_extra в рамках одного запроса. Здесь было два варианта. Первый — изменить task_factory для eventloop из asyncio:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task # updating loop, so any created task will # get the log_extra of its parent loop.set_task_factory(log_extrad_factory) def set_log_extra(log_extra: dict): loop = asyncio.get_event_loop() task = asyncio.Task.current_task(loop=loop) setattr(task, LOG_EXTRA_CONTEXT_KEY, log_extra)
Второй вариант — «протолкнуть» через команду инфраструктуры переход на Python 3.7 для использования contextvars:
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Ну и дальше нужно было пробросить сохраненную в контексте log_extra в logger.
class LogExtraFactory(logging.LogRecord): # this class allows to create log rows with log_extra in the record def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) task = asyncio.Task.current_task() log_extra = getattr(task, LOG_EXTRA_CONTEXT_KEY, None) if not log_extra: return for key in log_extra: self.__dict__[key] = log_extra[key] logging.setLogRecordFactory(LogExtraFactory)
Итоги:
- В Яндекс.Такси (да и повсеместно в Яндексе) активно используется asyncio. Важно не только уметь его использовать, но и понимать его внутреннее устройство.
- Выработайте в себе привычку читать чейнджлоги всех новых версий языка, думайте, как вы можете облегчить жизнь себе и коллегам с помощью нововведений.
- При работе со стандартными библиотеками не бойтесь залезать в их исходный код и разбираться в их устройстве. Это очень полезный навык, который позволит вам глубже понять работу модуля и откроет новые возможности в реализации фич.
Преподаватели Школы бэкенда съели не один пуд соли и набили уйму шишек в асинхронной работе сервисов. Они расскажут студентам об особенностях асинхронной работы Python — и на уровне применения на практике, и в части разбора внутренностей пакетов.
Книги и ссылки
В изучении Python вам могут помочь:
- Три книги: Python Cookbook, Diving Into Python 3 и Python Tricks.
- Видеолекции таких столпов IT-индустрии, как Реймонд Хеттингер и Дэвид Бизли. Из видеолекций первого можно выделить доклад «Beyond PEP 8 — Best practices for beautiful intelligible code». У Бизли советую посмотреть выступление про asyncio.
Чтобы обрести более высокоуровневое понимание архитектуры, прочтите книги:
- «Высоконагруженные приложения». Здесь подробно расписаны вопросы взаимодействия с данными (кодирование данных, работа с распределёнными данными, репликация, секционирование, транзакции и т. д.).
- «Микросервисы. Паттерны разработки и рефакторинга». В книге показаны основные подходы к микросервисной архитектуре, описаны недостатки и проблемы, с которыми приходится сталкиваться при переходе с монолита на микросервисы. В посте про них почти ничего нет, но всё равно советую прочитать эту книгу. Вы начнёте понимать тенденции в построении архитектур и изучите основные практики декомпозиции кода.
Ещё один из самых важных навыков, который можно до бесконечности развивать в себе, — это чтение чужого кода. Если вдруг вы понимаете, что редко читаете чужой код — советую выработать в себе привычку регулярно смотреть новые популярные репозитории.
Стендап закончился, все разошлись по рабочим местам.
Комментарии (27)

delimer
19.08.2019 15:08Кстати, уже не раз терял деньги и время из-за непродуманности приложения.
Суть, выбираю такси и в пожеланиях указываю детское кресло. Идет поиск машины и свободных машин нет, с предложением попробовать поискать еще раз. Соглашаюсь и машина находится, вот только повторный поиск идет с пустыми пожеланиями. В итоге приезжает машина без детского кресла и приходится отменять заказ и вызывать заново.
dmitryvolkovtaxi
19.08.2019 15:43+1Приветствую! А давайте на примере посмотрим, что пошло не так. Напишите на почту blogs@taxi.yandex.ru с заказом, о котором идёт речь, пожалуйста.
vlad2135
19.08.2019 15:34+1Вы серьезно на таком низком уровне обсуждаете свою работу? Это же противоречит всем бест практикам стендапов. Такие обсуждения обычно очень быстро превращаются в бурные и длительные дискуссии и стендап очень сильно затягивается.
yataxi-dev Автор
19.08.2019 15:44спасибо за вопрос, верно подмечено, у нас в команде есть ограничение в 15 минут на скрам-митинг, в рамках встречи обязательно регулируется время, затраченное на поднятый вопрос и часто его обсуждение откладывается на время после скрама (особенно если это какой-то технически сложный вопрос, например требующий погружения в архитектуру сервиса)
но также скрам-встреча позволяет акцентировать внимание на отдельных моментах проделанной работы (как например вопрос связанный с sql скриптом), если бы вопрос не был поднят — Анна бы и не узнала, что у Вадима есть экспертиза в данном вопросе и скорее всего потратила намного больше времени на раскопкиos9
19.08.2019 15:56Немного странно, что Анна случайно это узнала, и что у Вадима случайно оказалась эта экпертиза.
yataxi-dev Автор
19.08.2019 16:01это достаточно частое явление, ведь у всех разработчиков разный опыт и разный путь в IT-индустрии — кто-то мог на предыдущем месте работы столкнуться с точно такой же проблемой, кто-то мог работать с той же СУБД но не касаться описанного случая, а кто-то мог работать с абсолютно другим стеком технологий, поэтому обсуждение (или хотя бы упоминание проблемы) только приветствуется на скрамах
SemenPV
19.08.2019 16:37+1А сколько человек на 15 минут? И есть ли модератор?
По моему опыту, чем лучше человек поёт на стендапе, тем хуже он как работник. (Ещё раз — мой личный опыт).
Если все сидят рядом в опенофисе, то хочешь не хочешь, знаешь и видишь что происходит вокруг. И Вадим бы давно был в курсе Анечкиных проблем, конечно если Анечка не ассоциальный элемент или Вадим аудиофил.yataxi-dev Автор
19.08.2019 18:41А сколько человек на 15 минут? И есть ли модератор?
как правило в таких митингах участвует ~5 человек, один из которых следит за проведением самого митинга
Если все сидят рядом в опенофисе, то хочешь не хочешь, знаешь и видишь что происходит вокруг.
Вы абсолютно правы, но при этом объявление какого-то значимого рефакторинга или тормозящей проблемы на стендапе 'гарантирует' что эта информация дойдет до каждого члена команды

Kanut
19.08.2019 18:18+1Всё равно на мой взгляд уровень «детализации» для стэндапа слишком высок. Если в команде 3-5 разрабов и 2-3 тестера, то в 15 минут они никак не уложатся.
И зачем вообще на стэндапе рассказывать каким образом кто-то уже решил какую-то проблему? Если есть проблема и сам не можешь её решить, то это одно. Но если уже сам нашёл решение, то это в лучшем случае информация на какой нибудь DevCop.yataxi-dev Автор
19.08.2019 18:49я согласен с Вами,
в большинстве случаев задачи обсуждаются на митингах в общих чертах, и лишь в редких случаях задачи разбираются подробно
в примере статьи есть подробные описания задач, их решения, а также итоги по задачам лишь по той простой причине, что читатели находятся вне контекста

dakuan
19.08.2019 18:27А какую задачу решают эти стендапы? Не подумайте, что пытаюсь троллить, действительно интересно. Работал пару лет в компании, где практиковались ежедневные собрания на 15-20 минут, каждый рассказывал, что делал вчера и что собирается делать сегодня. Но вот какой-то реальной пользы от этого так и не заметил — за отведенные 1-3 минуты просто невозможно нормально вникнуть в задачу, а информацию о том, что сотрудник Вася вчера работал над тикетом N и планирует продолжать над ним работать сегодня, обычно все мимо ушей пропускали. И я, каюсь, тоже. Возможно, конечно, что мы что-то делали неправильно… В своей команде я подобную практику отменил — считаю, что 1 собрания раз в неделю вполне достаточно.
Kanut
19.08.2019 19:00Ну у нас основная цель это мониторить укладываемся ли мы более-менее в сроки. И определять наличие проблем из-за которых мы можем в эти самые сроки не уложится и пытаться оперативно найти решение этих проблем.
Примерно половина «проблем» это когда кто-то «зависает» над какой-то задачей и не может сдвинуться с места. И тогда либо кто-то помогает, либо просто задачу передают кому-то другому.
Вторая половина это обычно проблемы «извне» команды, когда кто-то посторонний что-то не сделал вовремя или сделал неправильно. Тогда сениоры и/или ПО идут разруливать ситуацию в «большой мир».
П. С. Всё это в принципе можно и без стендапа, но мы всё равно идём утром всей тимой за «обязательным утренним кофе» и просто совмешаем приятное с полезным.

DarkWolf13
20.08.2019 16:12согласен, что одного собрания достаточно, остальные в рабочем порядке… а то эти ежедневные собрания напоминают поделись своим успехом у саентологов

QtRoS
19.08.2019 19:09- Сильно ли "Такси" полагается на Python? Или даже так — много ли удается писать на Python, а не на C++?
- Если не трудно, можете написать фидбек об использовании asyncio — что понравилось, а что нет и за какой по времени срок.

jirfag
19.08.2019 21:351. В продуктовой разработке Такси на Python можно писать практически все. Обычно мы даем разработчикам выбор: новые микросервисы можно писать либо на C++ либо на Python (Python3) — как захочет разработчик/команда. На практике примерно 50-70% новых микросервисов пишется на Python в продукте. В инфраструктурной разработке больше C++.
shark14
20.08.2019 09:17Недавно столкнулся с неприятным случаем — перед заказом iOS-приложение Такси показывало одну стоимость (с учётом скидки от плюса и даже при учете повышенного спроса), а после поездки внезапно обнаружил, что с карты списали более чем в 1.5 раза большую сумму.
Вероятно, это баг, но довольно серьёзный, и не хотелось бы, чтобы такие вещи далее появлялись на продакшне.

galvanom
20.08.2019 10:03У нас в команде следующий подход: если на код-ревью задают вопрос по поводу реализации (просят объяснить алгоритм), то необходимо добавить комментарий. А ещё лучше подумать об этом заранее и добавить его самому.
Есть вариант с тем чтобы переписать так, чтобы код был понятнее? Кажется это должен быть план А, а план Б уже написать комментарий.
mike1
20.08.2019 12:36Это точно статья про Яндекс? Там же 6-этапные многодневные изнурительные евроинтервью, они же отбирают сливки из лучших из лучших… не могу поверить, что тамошние программеры так могут косячить или не уметь оптимизировать SQL...
DarkWolf13
20.08.2019 16:08как и все хорошее, удобство яндекс такси закончилось и его поменяли на деньги.
1. Приезжаю в незнакомый город хочу узнать во сколько встанет поездка вокзал/аэропорт — гостинница/завод. НЕсколько похожих запросов из одной точки и вуаля: когда с выбором определился, цена выше- вы там как определяете повышенный спрос?
2. Приезжаю поездом выхожу, пытаюсь вызвать такси до дома/гостиницы, тариф показывается приемлемый, заказываю жду когда найдется машинка и приедет.Рядом стоят чуть ли не с десяток машин расклеенных Яндекс.Но машина не находится. Повторно тариф повышается. И так может раза три повысится. Если ожидается прибытие курортного поезда или из московского то тариф может меняться, машины брендированные чуть ли не рядом стоят ......(сами можете почитать боцманский словарь идиоматических выражений экспрессивной лексики по данному поводу). Как работает алгоритм если удобство уничтожено желанием таксистов за бешенную сумму везти с вокзала/аэропорта? Получается водители нашли лазейки самим определять цену которую желают?
3. КАк то заявлялось что в приложении водителя есть контроль за безопасностью движения, он есть или эта функция не прижилась?
BarakAdama
20.08.2019 16:15Я не из Такси, но проходил мимо. Есть хорошая статья про ценообразование habr.com/ru/company/yandex/blog/429226
DarkWolf13
20.08.2019 16:18вот в том и дело, что можно один раз посмотреть, закрыл. снова открыл — цена возросла. Хотя и народа, субъективно, никого нет вокруг. А статья спасибо, знакома.
nik_brons
Интересно, а у вас принято использовать во время стендапа маркерные доски, или другие инструменты для визуализации (как схемы приведенные статье) или понимания контекста внутри команды хватает?
yataxi-dev Автор
да, иногда используются маркерные доски (в офисе достаточно мест, где можно пописать маркером), но обычно какие-то визуальные или архитектурные вопросы откладываются на обсуждения после скрам-митинга