Продолжение серии статей, написанных по мотивам выступлений на нашем внутреннем мероприятии DevForum:
1. Кот Шрёдингера без коробки: проблема консенсуса в распределённых системах.
2. Infrastructure as code. (You are here)
3. Генерация Typescript контрактов по c# моделям. (In progress...)
4. Введение в алгоритм консенсуса Raft. (In progress...)
...
Мы решили сделать команду SRE, воплотив идеи google sre. Набрали программистов из своих же разработчиков и отправили их обучаться на несколько месяцев.
Перед командой стояли следующие учебные задачи:
- Описать нашу инфраструктуру, которая по большей части в Microsoft Azure в виде кода (Terraform и все, что около).
- Научить разработчиков работе с инфраструктурой.
- Подготовить разработчиков к дежурствам.
Вводим понятие Infrastructure as code
В обычной модели мира (классическом администрировании) знания об инфраструктуре находятся в двух местах:
- Либо в виде знаний в головах экспертов.

- Либо эти сведения находятся на каких-то машинках, часть из которых знают эксперты. Но не факт, что человек со стороны (в случае, если вся наша команда внезапно умрёт) сможет разобраться, что и как работает. На машине может быть много сведений: аксессы, кронджобы, подмаученный (см. disk mounting) диск и просто бесконечный список того, что может происходить. По ней сложно понять, что в реальности происходит.

В обоих случаях мы оказываемся в ловушке, становясь зависимыми:
- либо от человека, который смертный, подверженный болезням, влюблённостям, перепадам настроения и просто банальным увольнениям;
- либо от физически работающей машины, которая тоже падает, воруется, преподносит неожиданности и неудобства.
Само собой напрашивается решение, что в идеале всё надо перевести в человекочитаемый, поддерживаемый, качественно написанный код.
Таким образом инфраструктура как код (Incfastructure as Code – IaC) – это описание всей имеющейся инфраструктуры в виде кода, а также сопутствующие средства по работе с ним и воплощению из него же реальной инфраструктуры.
Мы много и долго искали их на кадровом рынке за пределами нашей компании. Но вынуждены признать, что не нашли ни одного под наши запросы. Пришлось пошерстить среди своих.
Проблемы Infrastructure as code
Теперь давайте посмотрим примеры того, как инфраструктура может быть зашита в код. Код хорошо написан, качественно, с комментами и отступами.
Пример кода из Terraforma.
Пример кода из Ansible.

Господа, но если бы всё было так просто! Мы же с вами в реальном мире, а он всегда готов удивить вас, преподнести сюрпризы, проблемы. Не обходится без них и здесь.
1. Первая проблема состоит в том, что в большинстве случаев IaC – это какой-то dsl.
А DSL, в свою очередь, – это описание структуры. Точнее того, что у тебя должно быть: Json, Yaml, модификации от каких-то крупных компаний, которые придумали свой dsl (в терраформе используется HCL).
Беда в том, что в нём может легко не быть таких привычных нам вещей как:
- переменные;
- условия;
- где-то нет комментариев, например, в Json, по дефолту их не предусмотрено;
- функции;
- и это я еще не говорю о таких высокоуровневых вещах, как классы, наследование и всё такое.
2. Вторая проблема такого кода – чаще всего это гетерогенная среда. Обычно вы сидите и работаете с C#, т.е. с одним языком, одним стеком, одной экосистемой. А тут у вас огромное разнообразие технологий.
Вполне реальная ситуация, когда баш с питоном запускает какой-то процесс, в который подсовывается Json. Вы его анализируете, потом еще какой-то генератор выдает ещё 30 файлов. Для всего этого поступают входные переменные из Azure Key Vault, которые стянуты плагином к drone.io, написанным на Go, и переменные эти проходят через yaml, который получился в результате генерации из шаблонизатора jsonnet. Довольно сложно иметь строго хорошо описанный код, когда у вас настолько разнообразная среда.
Традиционная разработка в рамках одной задачи идет с одним языком. Здесь же мы работаем с большим количеством языков.
3. Третья проблема – это тулинг. Мы привыкли к крутым редакторам (Ms Visual Studio, Jetbrains Rider), которые все делают за нас. И даже, если мы затупили, они скажут, что мы не правы. Кажется, что это нормально и естественно.
Но где-то рядышком есть VSCode, в котором есть какие-то плагины, которые как-то ставятся, поддерживаются или не поддерживаются. Вышли новые версии, и их не поддержали. Банальный переход к имплементации функции (даже если она есть) становится сложной и нетривиальной проблемой. Простой ренейм переменной – это реплейс в проекте из десятка файлов. Повезёт, если он то, что надо зареплейсит. Есть, конечно, кое-где подсветка, есть автокомплишн, где-то есть форматинг (правда у меня в терраформе на винде не завелся).
На момент написания статьи vscode-terraform plugin еще не выпустили для поддержки версии 0.12, хотя она зарелижена уже как 3 месяца.
Пришло время забыть о...
- Debugging.
- Refactoring tool.
- Auto completion.
- Обнаружении ошибок при компиляции.
Смешно, но это же увеличивает время на разработку и увеличивает количество ошибок, которые неизбежно происходят.
Самое страшное, что мы вынуждены думать не о том как спроектировать, разложить файлики по папочкам, декомпозировать, сделать поддерживаемым, читаемым и так далее код, а о том, как бы мне корректно написать эту команду, потому что я её как-то неправильно написал.
Как новичок вы пытаетесь познать терраформ, а IDE вам в этом нисколько не помогает. Когда есть документация – зашли, посмотрели. Но если бы вы въезжали в новый язык программирования, то IDE подсказала бы, что есть такой тип, а такого нет. По крайней мере, на уровне int или string. Это часто бывает полезным.
А как же тесты?
Вы спросите: «Как же тесты, господа программисты?» Серьёзные ребята тестируют всё на проде, и это жестко. Вот пример юнитеста для терраформ-модуля с сайта Microsoft.
У них хорошая документация. Microsoft мне всегда нравились своим подходом к документации и обучению. Но не нужно быть дядюшкой Бобом, чтобы понять, что здесь не идеальный код. Обратите внимание на валидацию, вынесенную вправо.
Проблема unit-теста в том, что мы с вами можем проверить корректность Jsonа на выходе. Я кинул 5 параметров, мне выдалась портянка Json на 2000 строк. Я могу проанализировать, что здесь происходит, validate test result…
Сложно анализировать Json в Go. А надо писать в Go, потому что терраформ на Go – это хорошая практика того, что тестируешь в том языке, в котором ты пишешь. Сама организация кода очень слабая. При этом – это лучшая библиотека для тестирования.
Сам Microsoft пишет свои модули, тестируя их таким способом. Конечно, это Open Source. Всё, о чем я говорю вы можете прийти и починить. Я могу сесть и за недельку всё починить, заопенсорсить плагины VS-кода, терраформ, сделать плагин для райдера. Может быть, написать парочку анализаторов, прикрутить линтеры, законтрибьютить библиотеку для тестирования. Всё могу сделать. Но я не этим должен заниматься.
Лучшие практики Infrastructure as code
Едем дальше. Если в IaC нет тестов, плохо с IDE и тулингом, то должны быть хотя бы лучшие практики. Я просто пошёл в гугл-аналитику и провёл сравнение двух поисковых запросов: Terraform best practices и c# best practices.
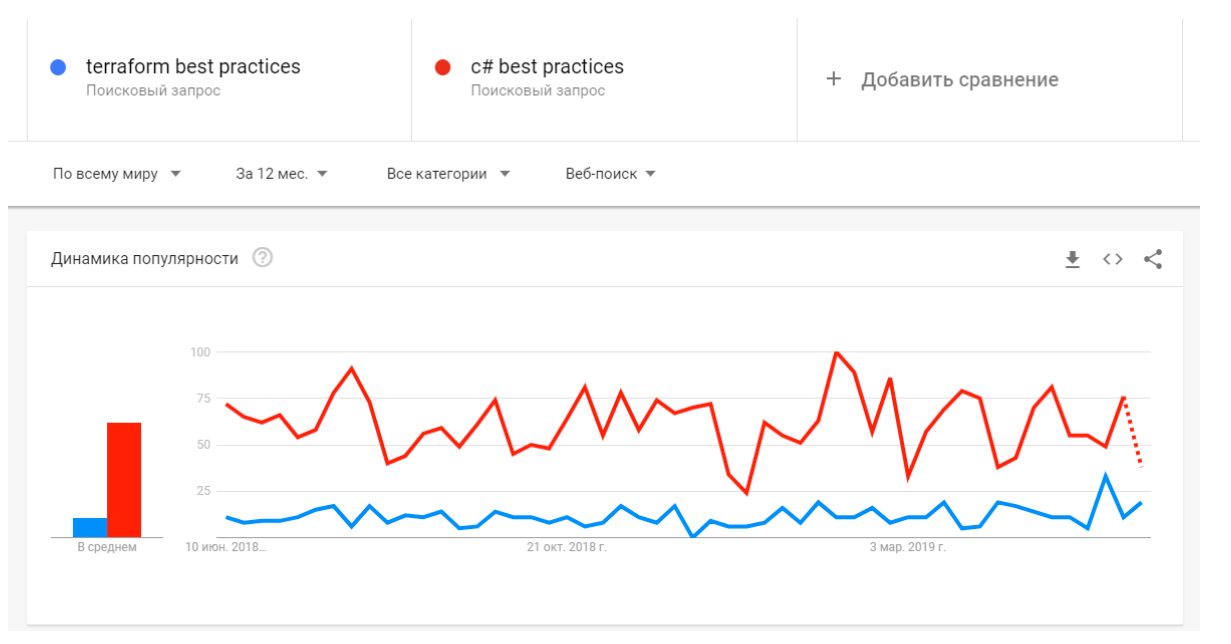
Что мы видим? Беспощадную статистику не в нашу пользу. По количеству материала – то же самое. В C# разработке мы просто купаемся в материалах, у нас есть сверхлучшие практики, есть книги написанные экспертами, и также книжки, написанные на книжки другими экспертами, которые критикуют те книжки. Море официальной документации, статей, обучающих курсов, сейчас еще и open source разработка.
Что касается запроса по IaC: здесь вы по крупицам пытаетесь собрать инфу с докладов хайлоада или HashiConf, с официальной документации и многочисленных issue на гитхабе. Как вообще эти модули раскидывать, что с ними делать? Кажется, что это реальная проблема… Есть же комьюнити, господа, где на любой вопрос тебе дадут 10 комментов на гитхабе. Но это не точно.
К сожалению, в данный момент времени эксперты только начинают появляться. Пока их слишком мало. А само комьюнити болтается на уровне зачатков.
Куда всё это движется и что делать
Можно всё бросить и пойти обратно на C#, в мир райдера. Но нет. Зачем вы вообще стали бы этим заниматься, если не найти решение. Далее я привожу свои субъективные выводы. Можете поспорить со мной в комментариях, будет интересно.
Лично я ставлю на несколько вещей:
- Развитие в данной сфере происходит очень быстро. Привожу график запросов по DevOps.
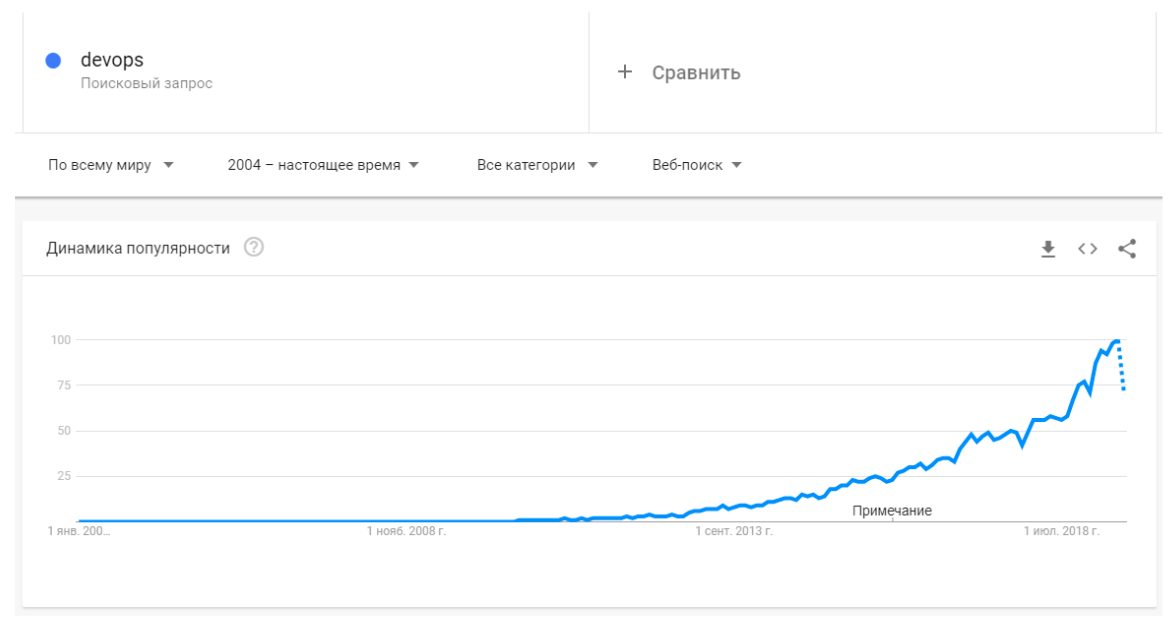
Может быть тема хайповая, но сам факт того, что сфера растёт, вселяет некоторую надежду.
Если что-то растет настолько быстро, то обязательно появятся умные люди, которые скажут как надо делать, а как не надо. Увеличение популярности ведет к тому, что может у кого-то будет время дописать наконец плагин к jsonnet для vscode, который позволит переходить к имплементации функции, а не искать ее через ctrl+shift+f. Когда всё развивается, появляется больше материалов. Тот же выход книги от гугла про SRE отличный тому пример. - Есть разработанные методики и практики в обычной разработке, которые мы можем успешно применять здесь. Да, есть нюансы с тестированием и гетерогенной средой, недостаточный тулинг, но накоплено громадное число практик, которые могут пригодиться и помочь.
Банальный пример: совместная работа через pair programming. Он сильно помогает разобраться. Когда у тебя есть рядом сосед, который тоже что-то пытается понять, вместе вы поймёте лучше.
Понимание о том, как делается рефакторинг помогает даже в такой ситуации производить его. То есть, ты можешь поменять не всё сразу, а поменять нейминг, потом поменять расположение, потом может выделить какую-то часть, ой, а здесь не хватает комментариев.
Заключение
Несмотря на то, что мои рассуждения могут показаться пессимистичными, я с надеждой смотрю в будущее и искренне надеюсь, что у нас (и у вас) всё получится.
Следом готовится вторая часть статьи. В ней я расскажу о том, как мы попробовали применять практики гибкой разработки, чтобы улучшить наш процесс обучения и работу с инфраструктурой.
Комментарии (29)

SemenPV
29.08.2019 19:14Подготовить разработчиков к дежурствам.
Одно из основных преимуществ разработчика над админами и т.п. то что ты это level 4 support. Хотя конечно если предыдущие три уровня туповаты, то всё равно идёт к тебе.
Главное чтобы завернуть это так чтобы все level 4 запросы шли к твоему менеджеру и он их все разруливал и чувствовал боль.
По крайней мере он будет бодаться с нижними уровнями, а в противном случае у тебя нету реальной власти чтобы всех посылать, а им так легче и удобнее.
pritchin Автор
29.08.2019 19:29Тут скорее про то, что вот есть разработчики(мы) и нас надо подготовить к дежурствам в инфраструктуре, в которых мы не знаем как вести себя, не обладаем изначально нужными знаниями.
При дежурствах ты становишься уже первой линией, должен первым реагировать на инциденты и если необходимо, то уже подключать аналитиков или непосредственно разработчиков, которые и ответственны за сервис.SemenPV
29.08.2019 19:33При дежурствах ты становишься уже первой линией
т.е. непосредственно тебе идут оповещения от системы мониторинга? Нету специально обученных людей которые 24/7 сидят в OC и разруливают проблемы?
т.е. если я разработчик и у меня крепкий сон, так что я не услышу звонок, полстраны лишаться пиццы?pritchin Автор
29.08.2019 19:47т.е. непосредственно тебе идут оповещения от системы мониторинга?
Сейчас мы в процессе онбординга, но уже скоро пойдут. В этом одна из целей — чтобы увеличить пул дежурных.
т.е. если я разработчик и у меня крепкий сон, так что я не услышу звонок, полстраны лишаться пиццы?
Разработчик в команде инфраструктуры должен дежурить, быть на пейджере. Есть расписание, есть процесс дневных вечерних дежурств. Кстати, можно было бы и рассказать про то, как это подробно работает.
Обычные разработчики не дежурят(за исключением некоторых праздников).SemenPV
29.08.2019 19:54В этом одна из целей — чтобы увеличить пул дежурных.
Понятно, система OncallOps. Надеюсь хоть если ты на дежурстве, эти часы оплачиваются, или это общественная нагрузка со стороны ДоДо.Обычные разработчики не дежурят(за исключением некоторых праздников).
Интересно что ещё за исключением обычные разработчики не делают. И тот же вопрос про оплату исключений.
VolCh
29.08.2019 07:38А как мотивировали разработчиков во всё это вникать?
pritchin Автор
29.08.2019 09:01Изначально в группу обучения вступили все равно те разработчики, кто занимался близкой тематикой последнее время. К примеру я до этого 2 года занимался так или иначе техническими задачами, а они непременно связаны. Остальные примерно так же.
Еще участие добровольное и те, кто не захотят остаться в инфраструктуре могут выйти.
Плюс прорекламирую непосредственно доклад на эту тему еще от одного члена команды. devopsconf.io/moscow/2019/abstracts/5575

Symsym
29.08.2019 07:45+1Спасибо за актуальную статью! Тесты пишутся со временем, в том же ансибл, в dev контуре для инфраструктуры.
pritchin Автор
29.08.2019 08:56Спасибо! В итоге мы стали писать тесты, поднимающие отдельный терраформ модуль, проверяющие, что там все поднялось корректно и все данные на машине прошли. Мы стали использовать питон, т.к. на нем пишутся скрипты-склейки, так что он уже был в части инфраструктуры.
И пока полет нормальный. Вот что прям не вызывает проблем — так это тесты на питоне и сам питон

amarao
29.08.2019 10:59-1Я давно и кровавыми слезами плачу от всей существующей инфраструктуры для iaac. Сверхленивая типизация, UB как нормальное состояние (что именно делает UB проверяют тесты, и если поведение похоже на нужное, то это принимается), отсутствие нормальных интерфейсов...
Остро хочется системы управления конфигурациями, которая бы знала всё (т.е. не пришли и что-то там подфигачили, а runtime, который знает всё — от ip-адресов до номеров прерываний), и которая бы на уровне системы типов могла надавать по ушам до запуска чего-либо.
Ансибл, кстати, в этой области сделал просто преступление, переведя всё на массив глобальных переменных. Coupling на максимальном уровне, переиспользования кода нет, попытка написать чистую функцию оставляет после себя perl на jinja, плюс бесконечное нарушение абстракций.
de1m
29.08.2019 17:55Пока вы льёте слёзы в виллобаджо уже нафигачили в баше и пьют пиво.
Это я к тому, что жить как-то надо и приходится работать с тем, что есть.amarao
29.08.2019 17:58Работаем с чем есть, но для ansible и динамической типизации в iaac поставлено клеймо "плохо". Это означает, что есть большой стимул смотреть на следующую попытку сделать систему управления конфигурациями как только она появится.
Бывают инструменты для которых есть точное мнение "лучше не нужно". Пример — py.test, который лучшее, что
естья видел.

FakieStyle
29.08.2019 12:07Так есть же специально обученный человек — System Engineer. Он привыкший к таким вещам как отсутствие:
Debugging.
Refactoring tool.
Auto completion.
Обнаружении ошибок при компиляции.
Какие объекты? зачем они нам если мы пол жизни провели в баше?
Его полностью устраивает весь тулинг. Зачем делать из ваших девов систем инженеров и забирать у нас наш хлеб? Я к тому что каждый должен делать свою работу, а не быть Крузенштерном фуллстаком. И кстати про неудобства — через полгода все может очень сильно поменяться. Сами написали про скорость развития этого направления.


alex005
29.08.2019 15:04Возможно не понимаю сложностей пицерии и C#, но что в этом бизнесе такого, что отличает его от других? Почему-то не видно слез рыдания передовых технологических стартапов о том, что инфраструктуру нельзя протестировать и все делается на проде без тестов, автокомплита и работающих плагинов, как операция на живом сердце.
На самом деле инфраструктуру можно и нужно тестировать, но это делается не путем синтаксических проверок кода развертывания этой инфраструктуры, а совершенно другими методами и средствами.
ArSoron
Чисто из любопытства: учитывая, что инфраструктура в Azure, рассматривали вариант использования AzureRM Template'ов? У них есть существенные преимущества над TF, например, неразрушающие апгрейды, возможность экспорта ресурсов нативными средствами и, наконец, таки работающий плагин к VSCode с поддержкой Go to definition и всего такого.
pritchin Автор
Мы изначально выбирали именно решение с возможностью работы с несколькими cloud providers. Есть у нас сервисы не только в ажуре, причем в основном именно наши, инфраструктурные.
Про поддержку плагинов — мы частично используем плагин от Jetbrains и соответственно Rider.
sentyaev
Вот каждый раз читаю такое и удивляюсь, почему компании пытаются играть в независимость от поставщика услуг? Ведь риск того, что Azure/AWS/Google и другие исчезнут — на несколько порядков ниже, чем риски вашего бизнеса.
Я еще пойму, что риски работы в России накладывают определенные ограничения, тут уж ничего не поделать, но «возможность работы с несколькими cloud providers»… хоть убейте, не могу понять.
VolCh
Исчезнут — ладно, но могут резко изменить ценовую политику, или быстро не просто задепрекейтить что-то в текущей версии, но и перестать поддерживать в следующей. Отсутствие вендор-лока это ещё постоянная готовность к обновлению на новую версию текущего.
sentyaev
Ценовая политика может быть определенным аргументом в зависимости от типа компании, но что вы предлагаете, покупать свое железо и строить свои дата-центры?
Ведь цены на те же EC2 по вашей логике могут поменяться.
Вот есть несколько больших игроков на рынке такие как Google/Azure/AWS и ценовая политика зависит не от желания этих компаний, а от их конкуренции.
Вот это точно не аргумент, это просто работа. Нам постоянно приходится следить за обновлениями в ОС, языках программирования, библиотеках и фреймворках которые используем, различных 3rd party сервисах. Тут скорее наоборот, используя какой-либо сервис cloud provider'а количество подвижных частей уменьшается, т.к. он предоставляет некую абстракцию.
pritchin Автор
Такой риск существует и это одна из причин.
Также, как я уже говорил, часть функций находится в других облаках. Например, на google functions у нас бот для ScaleFT или бот, создающий карточки при инциденте.
Еще один риск — это ценовая политика. Деньги в клауде могут улететь очень быстро, а цены могут отличаться в разы.
kemko
Кстати да. Еще забавно, когда облако не особо виновато, просто курс изменился раза в 2.
jmistx
А ещё у каждого клауд провайдера бывают глобальные аутеджи. У того же ажура была недавно история, когда DNS на managed базы лежал час. Или нетворк между датацентрами 6 часов лежал без предсказания, когда поднимется.
Это происходит очень редко, но в такие моменты или уже должна быть готова инфраструктура на другом облаке, либо должна быть возможность, инструкции и подготовленный плацдарм, чтобы быстро развернуться на другом облаке и переключить на него трафик.
sentyaev
Ну так историю этих аутеджей можно посмотреть и спланировать стратегию для своего сервиса.
Большой вопрос что для вашего сервиса это значит, если это критическая часть системы, то что поделать, возможно нельзя использовать managed db, возможно разделить read/write модели, возможно добавить кеширование. Но решение как поступить оно только ваше, т.к. никто кроме вас специфики не знает.
Тоже самое, возможно мой сервис в одном датацентре. А если в нескольких, то тут же очевидно, что хоть с клаудом, хоть без него должна быть стратегия как сервис будет работать и восстанавливаться при отключении одного из датацентров или потери связи между ними. Ничего нового клауд в этом смысле не привнес.
jmistx
> Ну так историю этих аутеджей можно посмотреть и спланировать стратегию для своего сервиса.
Смысл аутеджей, в том, что их сложно предсказывать. Мы же говорим не про плановую поддержку.
Ну и да, мы сделали как вы советуете: спланировали, что в перспективе должны иметь план в виде второго облака / независимого ДЦ. (Это не только из-за отказов облаков, но и из-за правовых причин)
> возможно нельзя использовать managed db
on-premise машины тоже будут падать, сеть до них тоже будет теряться. Естественно, если это критический путь в системе, он должен быть достаточно надёжен, чтобы самовосстановиться и продолжить работать. Мы так и делаем.
Второй ДЦ берётся не из воздуха, а из попытки достичь большего количества «девяток», чем может предложить одно облако. Объяснять бизнесу, что ажур (амазон, гугл) сломался во всём мире и мы ничего не можем с этим поделать – слабая позиция.
> Ничего нового клауд в этом смысле не привнес.
Согласен
kemko
В какой-то момент прошлого (прошлого же?) года из России исчезла заметная часть AWS, а часть Digital Ocean вовсе до сих пор не вернулась. Вот в ситуации, когда "А-ааа, РКН опять!" очень пригодятся затраты на то, чтобы не сильно зависеть от конкретного облачного провайдера.
sentyaev
Я бы не стал примешивать политику в обсуждение зависимости от поставщиков.
Мы же не все в России живем, да и я согласен, что законы принимаемые в России это весомый аргумент для бизнеса.
Мне интересно было бы обсудить реальные аргументы против зависимости от поставщиков, ведь по логике, вендор заинтересован предоставить лучший сервис т.к. он же не в вакууме живет, а также как и другие бизнесы находится в конкурентной среде, даже в высоко-конкурентной, другими словами он деньгами заинтересован бороться за минимальные цены, повышать SLA, делать обратно совместимые изменения.
VolCh
Если вендор уверен, что большинство его клиентов залочено на него, то он может себя вести в отношении них как будто конкурентов у него особо нет.
sentyaev
Зачем? Чтобы новые клиенты со 100%-ой вероятностью выбрали конкурента, а старые начали думать о миграции?