
Привет, читатели Хабра. Этой статьей мы открываем цикл, который будет рассказывать о разработанной нами гиперконвергентной системе AERODISK vAIR. Изначально мы хотели первой же статьей рассказать всё обо всём, но система довольно сложная, поэтому будем есть слона по частям.
Начнем рассказ с истории создания системы, углубимся в файловую систему ARDFS, которая является основой vAIR, а также немного порассуждаем о позиционировании этого решения на российском рынке.
В дальнейших статьях мы будем подробнее рассказывать о разных архитектурных компонентах (кластер, гипервизор, балансировщик нагрузки, система мониторинга и т.п.), процессе настройки, поднимем вопросы лицензирования, отдельно покажем краш-тесты и, конечно же, напишем о нагрузочном тестировании и сайзинге. Также отдельную статью мы посвятим community-версии vAIR.
Аэродиск — это вроде история про СХД? Или зачем мы вообще начали заниматься гиперконвергентом?
Изначально идея создать свой гиперконвергент пришла нам где-то в районе 2010-ого года. Тогда ещё не было ни Аэродиска, ни подобных решений (коммерческих коробочных гиперконвергентных систем) на рынке. Задача у нас была следующая: из набора серверов с локальными дисками, объединённых интерконнектом по протоколу Ethernet, надо было сделать растянутое хранилище и там же запускать виртуальные машины и программную сеть. Всё это требовалось реализовать без СХД (ибо на СХД и её обвязку просто не было денег, а своей СХД мы тогда ещё не изобрели).
Мы перепробовали много open source-решений и все-таки задачу эту решили, но решение было очень сложным, и его трудно было повторить. Кроме того, это решение было из разряда «Работает? Не трожь!». Поэтому, решив ту задачу, мы не стали дальше развивать идею превращения результата нашей работы в полноценный продукт.
После того случая мы отошли от этой идеи, но нас все равно не покидало ощущение того, что задача эта вполне решаема, а польза от такого решения более чем очевидна. В дальнейшем вышедшие HCI-продукты зарубежных компаний это ощущение только подтвердили.
Поэтому в середине 2016-ого года мы вернулись к этой задаче уже в рамках создания полноценного продукта. Тогда у нас ещё не было никаких взаимоотношений с инвесторами, потому стенд разработки пришлось покупать за свои не очень большие деньги. Набрав на Авито БУ-шых серверов и коммутаторов, мы принялись за дело.

Основной начальной задачей было создание своей, пусть простой, но своей файловой системы, которая смогла бы автоматически и равномерно распределять данные в виде виртуальных блоков на n-ном количестве нод кластера, которые объединены интерконнектом по Ethernet-у. При этом ФС должна хорошо и легко масштабироваться и быть независимой от смежных систем, т.е. быть отчуждаемой от vAIR в виде «просто хранилки».

Первая концепция vAIR

Мы намеренно отказались от использования готовых open source-решений для организации растянутого хранилища (ceph, gluster, lustre и им подобные) в пользу своей разработки, поскольку уже имели с ними много проектного опыта. Безусловно, сами по себе эти решения прекрасны, и мы до работы над Аэродиском реализовали с ними не один интеграционный проект. Но одно дело – реализовать конкретную задачу одного заказчика, обучить персонал и, возможно, купить поддержу большого вендора, и совсем другое дело – создать легко тиражируемый продукт, который будет использоваться под разные задачи, о которых мы, как вендор, возможно, даже сами знать не будем. Для второй цели существующие open source-продукты нам не подходили, поэтому решили распределенную файловую систему пилить сами.
Через два года силами нескольких разработчиков (которые совмещали работы над vAIR с работой над классической СХД Engine) добились определенного результата.
К 2018-ому году мы написали простейшую файловую систему и дополнили её необходимой обвязкой. Система объединяла по внутреннему интерконнекту физические (локальные) диски с разных серверов в один плоский пул и «резала» их на виртуальные блоки, далее из виртуальных блоков создавались блочные устройства с той или иной степенью отказоустойчивости, на которых с помощью гипервизора KVM создавались и выполнялись виртуальные машины.
С названием файловой системы мы особо заморачиваться не стали и лаконично назвали её ARDFS (догадайтесь, как это расшифровывается))
Этот прототип выглядел хорошо (не визуально, конечно, визуального оформления тогда ещё не было) и показывал хорошие результаты по производительности и масштабированию. После первого реального результата мы дали ход этому проекту, организовав уже полноценную среду разработки и отдельную команду, которая занималась только vAIR-ом.
Как раз к тому времени созрела общая архитектура решения, которая до сих пор не претерпела серьезных изменений.
Погружаемся в файловую систему ARDFS
ARDFS является основой vAIR, которая обеспечивает распределенное отказоустойчивое хранение данных всего кластера. Одна из (но не единственная) отличительных особенностей ARDFS состоит в том, что она не использует никаких дополнительных выделенных серверов под мету и управление. Так было задумано изначально для упрощения конфигурации решения и для его надежности.
Структура хранения
В рамках всех нод кластера ARDFS организовывает логический пул из всего доступного дискового пространства. Важно понимать, что пул — это ещё не данные и не форматированное пространство, а просто разметка, т.е. любые ноды с установленным vAIR-ом при добавлении к кластеру автоматически добавляются в общий пул ARDFS и дисковые ресурсы автоматически становятся общими на весь кластер (и доступными для будущего хранения данных). Такой подход позволяет на лету добавлять и удалять ноды без какого-либо серьезного влияния на уже работающую систему. Т.е. систему очень легко масштабировать «кирпичами», добавляя или убирая ноды в кластере при необходимости.
Поверх пула ARDFS добавляются виртуальные диски (объекты хранения для виртуалок), которые строятся из виртуальных блоков размером 4 мегабайта. На виртуальных дисках непосредственно хранятся данные. На уровне виртуальных дисков также задается схема отказоустойчивости.
Как можно было уже догадаться, для отказоустойчивости дисковой подсистемы мы не используем концепцию RAID (Redundant array of independent Disks), а используем RAIN (Redundant array of independent Nodes). Т.е. отказоустойчивость измеряется, автоматизируется и управляется, исходя из нод, а не дисков. Диски, безусловно, тоже объект хранилища, они, как и всё остальное, мониторятся, с ними можно выполнять все стандартные операции, в том числе и собирать локальный аппаратный RAID, но кластер оперирует именно нодами.
В ситуации, когда очень хочется RAID (например, сценарий, поддерживающий множественные отказы на маленьких кластерах), ничто не мешает использовать локальные RAID-контроллеры, а поверх делать растянутое хранилище и RAIN-архитектуру. Такой сценарий вполне себе живой и поддерживается нами, поэтому мы расскажем о нем в статье про типовые сценарии применения vAIR.
Схемы отказоустойчивости хранилища
Схем отказоустойчиовсти виртуальных дисков в vAIR может быть две:
1) Replication factor или просто репликация – этот метод отказоустойчивости прост «как палка и веревка». Выполняется синхронная репликация между нодами с фактором 2 (2 копии на кластер) или 3 (3 копии, соответственно). RF-2 позволяет виртуальному диску выдержать отказ одной ноды в кластере, но «съедает» половину полезного объема, а RF-3 выдержит отказ 2-х нод в кластере, но зарезервирует уже 2/3 полезного объема под свои нужды. Эта схема очень напоминает RAID-1, то есть виртуальный диск, сконфигурированный в RF-2, устойчив к отказу любой одной ноды кластера. В этом случае с данными будет все в порядке и даже ввод-вывод не остановится. Когда упавшая нода вернется в строй, начнется автоматическое восстановление/синхронизация данных.
Ниже приведены примеры распределения данных RF-2 и RF-3 в штатном режиме и в ситуации отказов.
Имеем виртуальную машину объемом 8МБ уникальных (полезных) данных, которая работает на 4-х нодах vAIR. Понятно, что в реальности вряд ли будет такой малый объем, но для схемы, отражающей логику работы ARDFS, этот пример наиболее понятен. AB – это виртуальные блоки по 4МБ, содержащие уникальные данные виртуальной машины. При RF-2 создаются две копии этих блоков A1+A2 и B1+B2, соответственно. Эти блоки «раскладываются» по нодам, избегая пересечения одних и тех же данных на одной ноде, то есть копия А1 не будет находится на одной ноде с копией A2. С B1 и B2 аналогично.
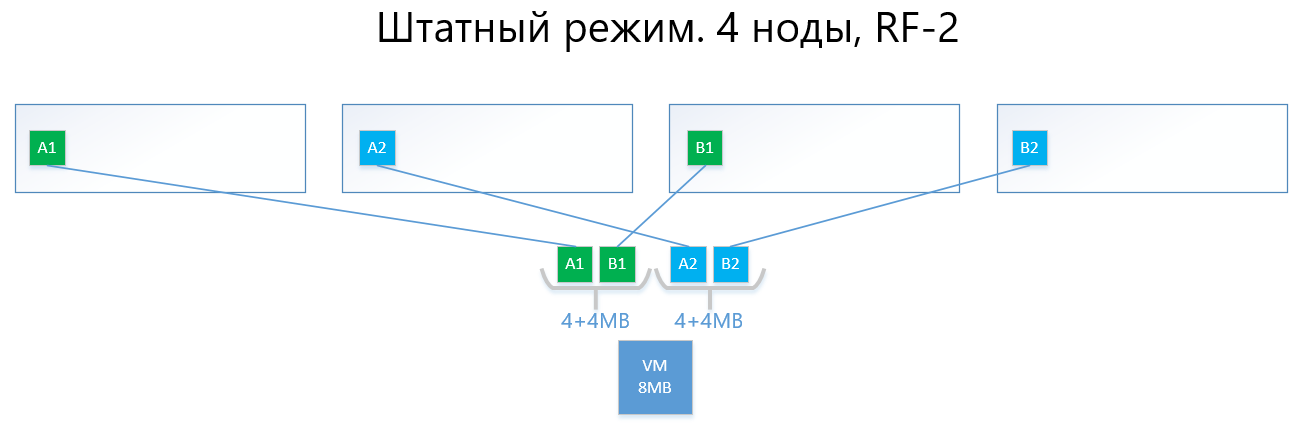
В случае отказа одной из нод (например, ноды №3, где содержится копия B1), данная копия автоматически активируется на ноде, где нет копии её копии (то есть копии B2).
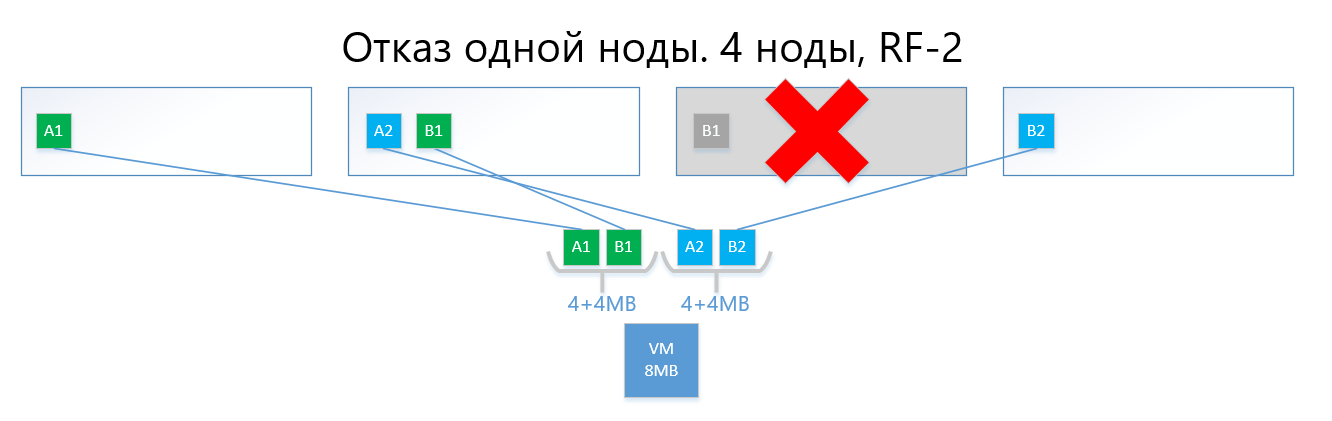
Таким образом, виртуальный диск (и ВМ, соответственно) легко переживут отказ одной ноды в схеме RF-2.
Схема с репликацией при своей простоте и надежности болеет той же болячкой, что и RAID1 – мало полезного пространства.
2) Erasure coding или удаляющее кодирование (также известно под именами «избыточное кодирование», «стирающее кодирование» или «код избыточности») как раз существует для решения проблемы выше. EC – схема избыточности, которая обеспечивает высокую доступность данных при меньших накладных расходах на дисковое пространство по сравнению с репликацией. Принцип работы этого механизма похож на RAID 5, 6, 6P.
При кодировании процесс EC делит виртуальный блок (по умолчанию 4МБ) на несколько меньших «кусков данных» в зависимости от схемы EC (например, схема 2+1 делит каждый блок 4 МБ на 2 куска по 2МБ). Далее это процесс генерирует для «кусков данных» «куски четности» размером не более одной из ранее разделенных частей. При декодировании EC генерирует недостающие куски, считывая «выжившие» данные по всему кластеру.
Например, виртуальный диск с EC-схемой 2 + 1, реализованный на 4-х нодах кластера, спокойно выдержит отказ одной ноды в кластере так же, как и RF-2. При этом накладные расходы будут ниже, в частности коэффициент полезной емкости при RF-2 равен 2, а при EC 2+1 он будет 1,5.
Если описать проще, то суть заключается в том, что виртуальный блок разделяется на 2-8 (почему от 2-х д 8-ми см. ниже) «кусков», а для этих кусков вычисляются «куски» чётности аналогичного объема.
В итоге данные и чётность равномерно распределяются по всем нодам кластера. При этом, как и при репликации, ARDFS в автоматическом режиме распределяет данные по нодам таким образом, чтобы не допустить хранения одинаковых данных (копий данных и их четности) на одной ноде, чтобы исключить шанс потерять данные из-за того, что данные и их четность внезапно окажутся на одной ноде хранения, которая выйдет из строя.
Ниже пример, с той же виртуалкой в 8 МБ и 4-мя нодами, но уже при схеме EC 2+1.
Блоки A и B делятся на два куска каждый по 2 МБ (на два потому что 2+1), то есть на A1+A2 и B1+B2. В отличие от реплики, A1 не является копией A2, это виртуальный блок A, разделенный на две части, так же и с блоком B. Итого получаем два набора по 4МБ, в каждом из которых лежит по два двухмегабайтных куска. Далее, для каждого из этих наборов вычисляется чётность объемом не более одного куска (т.е. 2-х МБ), получаем дополнительно + 2 куска чётности (A-P и B-P). Итого имеем 4x2 данных + 2x2 четность.
Далее куски «раскладываются» по нодам так, чтобы данные не пересекались с их четностью. Т.е. A1 и A2 не будут лежать на одной ноде с A-P.

В случае отказа одной ноды (допустим, тоже третьей) упавший блок B1 будет автоматически восстановлен из чётности B-P, которая хранится на ноде №2, и будет активирован на ноде, где нет B-четности, т.е. куска B-P. В данном примере – это нода №1

Уверен, у читателя возникает вопрос:
«Все что вы описали, давно реализовано и конкурентами, и в open source-решениях, в чем отличие вашей реализации EC в ARDFS?»
А далее пойдут интересные особенности работы ARDFS.
Erasure coding с упором на гибкость
Изначально мы предусмотрели довольно гибкую схему EC X+Y, где X равен числу от 2-х до 8-ми, а Y равен числу от 1-ого до 8-ми, но всегда меньше или равному X. Такая схема предусмотрена для гибкости. Увеличение числа кусков данных (X), на которые делится виртуальный блок, позволяет снижать накладные расходы, то есть увеличивать полезное пространство.
Увеличение же числа кусков четности (Y) увеличивает надежность виртуального диска. Чем больше значение Y, тем больше нод в кластере может выйти из строя. Само собой, увеличение объема четности снижает объем полезной емкости, но это плата за надежность.
Зависимость производительности от схем EC почти прямая: чем больше «кусков», тем ниже производительность, тут, понятное дело, нужен сбалансированный взгляд.
Такой подход позволяет администраторам максимально гибко конфигурировать растянутое хранилище. В рамках пула ARDFS можно использовать любые схемы отказоустойчивости и их комбинации, что тоже, на наш взгляд, очень полезно.
Ниже приведена таблица сравнения нескольких (не всех возможных) схем RF и EC.

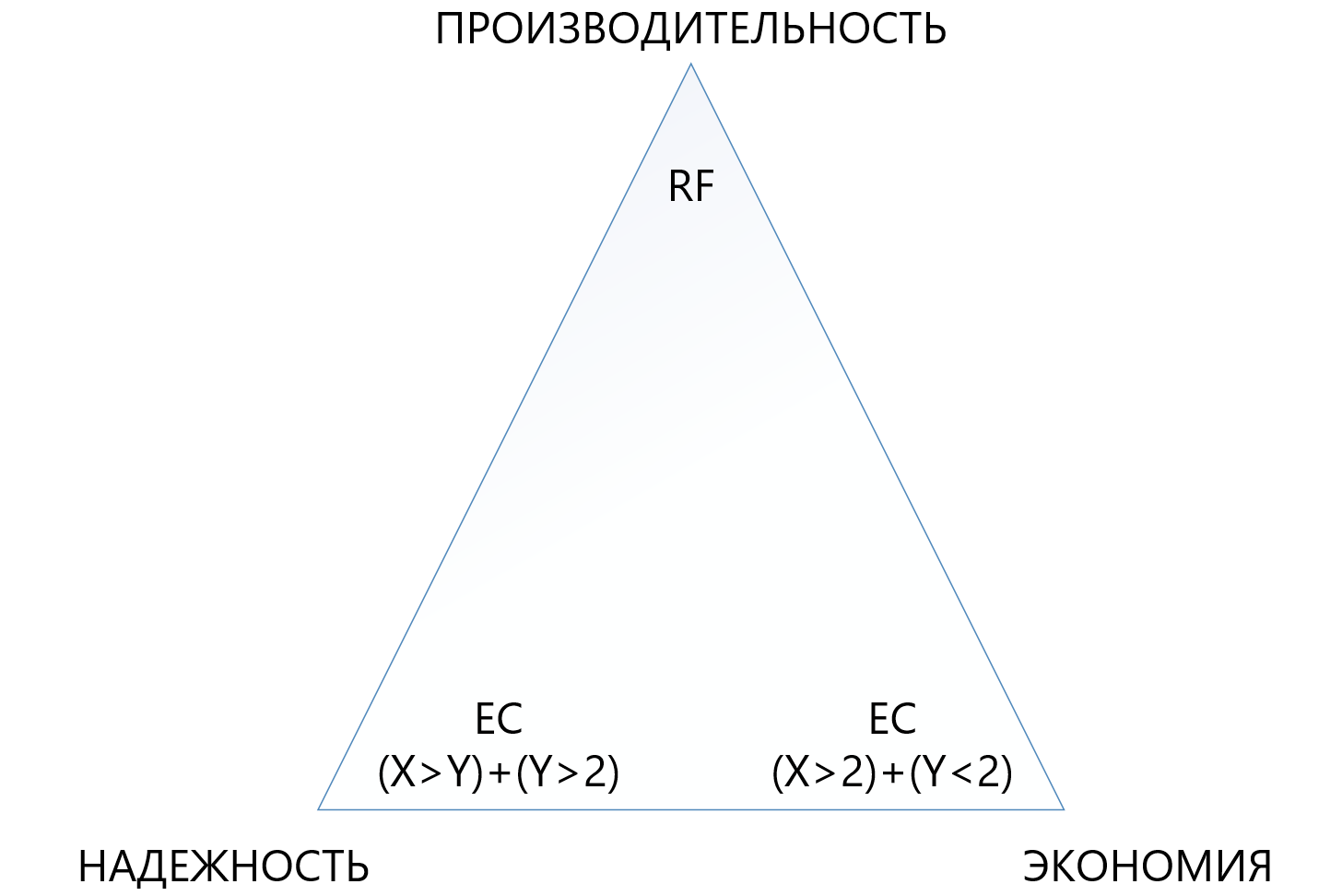
Из таблицы видно, что даже самая «махровая» комбинация EC 8+7, допускающая потерю одновременно до 7-ми нод в кластере, «съедает» меньше полезного пространства (1,875 против 2), чем стандартная репликация, а защищает в 7 раз лучше, что делает этот механизм защиты хоть и более сложным, но значительно более привлекательным в ситуациях, когда нужно обеспечить максимальную надёжность в условиях нехватки дискового пространства. При этом нужно понимать, что каждый «плюс» к X или Y будет дополнительным накладным расходом на производительность, поэтому в треугольнике между надежностью, экономией и производительностью нужно выбирать очень внимательно. По этой причине отдельную статью мы посветим сайзингу удаляющего кодирования.
Надежность и автономность файловой системы
ARDFS локально запускается на всех нодах кластера и синхронизирует их собственными средствами через выделенные Ethernet-интерфейсы. Важным моментом является то, что ARDFS самостоятельно синхронизирует не только данные, но и метаданные, относящиеся к хранению. В ходе работы над ARDFS мы параллельно изучали ряд существующих решений и мы обнаружили, что многие делают синхронизацию меты файловой системы с помощью внешней распределенной СУБД, которую мы тоже используем для синхронизации, но только конфигураций, а не метаданных ФС (об этом и других смежных подсистемах в следующей статье).
Синхронизация метаданных ФС с помощью внешней СУБД решение, конечно, рабочее, но тогда бы консистентность данных, хранимых на ARDFS, зависела бы от внешней СУБД и её поведения (а она, прямо скажем — дама капризная), что на наш взгляд плохо. Почему? Если метаданные ФС повредятся, самим данным ФС тоже можно будет сказать «до свидания», поэтому мы решили пойти по более сложному, но надежному пути.
Подсистему синхронизации метаданных для ARDFS мы сделали самостоятельно, и живет она абсолютно независимо от смежных подсистем. Т.е. ни одна другая подсистема не может повредить данные ARDFS. На наш взгляд — это наиболее надежный и правильный путь, а так ли это на самом деле – покажет время. Кроме того, с таким подходом появляется дополнительное преимущество. ARDFS можно использовать независимо от vAIR, просто как растянутую хранилку, чем мы непременно будем пользоваться в будущих продуктах.
В итоге, разработав ARDFS, мы получили гибкую и надежную файловую систему, дающую выбор, где можно сэкономить на емкости или отдать все на производительности, или же сделать хранилище сверхнадежным за умеренную плату, но снизив требования к производительности.
Вместе с простой политикой лицензирования и гибкой моделью поставки (забегая вперед, лицензируется vAIR по нодам, а поставляется либо софтом, либо как ПАК) это позволяет очень точно заточить решение под самые разные требования заказчиков и в дальнейшем легко поддерживать этот баланс.
Кому это чудо нужно?
С одной стороны, можно сказать, что на рынке уже есть игроки, у которых серьезные решения в области гиперконвергента, и куда мы, собственно, лезем. Кажется, что это утверждение верно, НО…
С другой стороны, выходя «в поля» и общаясь с заказчиками, мы и наши партнеры видим, что это совсем не так. Задач для гиперконвергента много, где-то люди просто не знали, что такие решения есть, где-то это казалось дорого, где-то были неудачные тесты альтернативных решений, а где-то вообще покупать запрещают, ибо санкции. В общем поле оказалось непаханым, поэтому мы пошли поднимать целину))).
Когда СХД лучше чем ГКС?
По ходу работы с рынком нас часто спрашивают, когда лучше применять классическую схему с СХД, а когда – гиперконвергент? Многие компании — производители ГКС (особенно те, у которых в портфеле нет СХД) говорят: «СХД отживает своё, гиперконвергент only!». Это смелое заявление, но оно не совсем отражает действительность.
По правде говоря, рынок СХД, действительно, переплывает в сторону гиперконвергента и подобных решений, но всегда есть «но».
Во-первых, построенные ЦОД-ы и ИТ-инфраструктуры по классической схеме с СХД вот так просто не перестроишь, поэтому модернизация и достройка таких инфраструктур — это ещё наследие лет на 5-7.
Во-вторых, те инфраструктуры, которые строятся сейчас в массе своей (имеется ввиду РФ) строят по классической схеме с применением СХД и не потому, что не знают люди о гиперконвергенте, а потому, что рынок гиперконвергента новый, решения и стандарты ещё не устоялись, ИТ-шники еще не обучены, опыта мало, а строить ЦОД-ы надо здесь и сейчас. И эта тенденция ещё на 3-5 лет (а потом ещё наследие, см. пункт 1).
В-третьих, чисто техническое ограничение в дополнительных небольших задержках в 2 миллисекунды на запись (без учета локального кэша, конечно), которые являются платой за распределенное хранение.
Ну и не будем забывать об использовании больших физических серверов, которые любят вертикальное масштабирование дисковой подсистемы.
Есть много нужных и популярных задач, где СХД ведет себя лучше, чем ГКС. Тут с нами конечно же не согласятся те производители, у которых в продуктовом портфеле нет СХД, но мы готовы аргументировано спорить. Само собой, мы, как разработчики обоих продуктов в одной из будущих публикаций обязательно проведем сравнение СХД и ГКС, где наглядно продемонстрируем, что в каких условиях лучше.
А где гиперконвергентные решения будут работать лучше СХД?
Исходя из тезисов выше, можно сделать три очевидных вывода:
- Там, где дополнительные 2 миллисекунды задержки на запись, которые устойчиво возникают в любом продуктиве (сейчас речь не идет о синтетике, на синтетике можно и наносекунды показать), являются некритичными, гиперконвергент подойдет.
- Там, где нагрузку из больших физических серверов можно превратить в много маленьких виртуальных и распределить по нодам, там тоже гиперконвергент зайдёт хорошо.
- Там, где горизонтальное масштабирование более приоритетно, чем вертикальное, там тоже ГКС зайдут прекрасно.
Какие это решения?
- Все стандартные инфраструктурные сервисы (служба каталогов, почта, СЭД, файловые серверы, небольшие или средние ERP и BI системы и пр.). Мы это называем «общие вычисления».
- Инфраструктура облачных провайдеров, где необходимо быстро и стандартизованно горизонтально расширяться и легко «нарезать» большое количество виртуальных машин для клиентов.
- Инфраструктура виртуальных рабочих столов (VDI), где много маленьких пользовательских виртуалок запускаются и спокойно «плавают» внутри единообразного кластера.
- Филиальные сети, где в каждом филиале нужно получить стандартную, отказоустойчивую, но при этом недорогую инфраструктуру из 15-20 виртуальных машин.
- Любые распределенные вычисления (big data-сервисы, например). Там, где нагрузка идет не «вглубь», а «вширь».
- Тестовые среды, где допустимы дополнительные небольшие задержки, но есть бюджетные ограничения, ибо это тесты.
На текущий момент именно для этих задач мы сделали AERODISK vAIR и именно на них делаем упор (пока успешно). Возможно, скоро это изменится, т.к. мир не стоит на месте.
Итак…
На этом первая часть большого цикла статей завершена, в следующей статьей мы расскажем об архитектуре решения и используемых компонентах.
Будем рады вопросам, предложениям и конструктивным спорам.
Комментарии (25)

vtolstov
30.09.2019 11:36По описанию очень похоже на Sheepdog. Помню даже комитил в него несколько лет назад, пока верил что с ним можно сварить что-то годное в больших масштабах. НО…
NTT его забросила, плюс междоусобица между корными разработчиками из ntt и china mobile.
Проблема в таком простом варианте состоит в том, что нет возможности гибко влиять на отказоустойчивость в рамках стойки или даже дц. Все же crushmap Ceph это крутая штука, которая позволяет гибко для пула указывать какая степень надежности нужна.
Если все это расползается между 3 дц и дальше то вот с такой простой схемой как у вас аля «sheepdog» не очень представляю как это будет дружить.
П.С. Erasure Code клево, но только для объектного хранилища. Для фс накладно слишком. Может у вас есть какое-то ноу хау, но перезапись куска данных в 4Mb блоке заставить прочесть весь блок. обновить кусок и пересчитать четность и все это записать. Не помню как сделали в Ceph.
Viacheslav_V Автор
30.09.2019 15:38Различные сценарии масштабирования в т.ч. между ЦОД-ами, покажем тут, опишем плюсы, минусы и подводные камни их само собой достаточно.
По производительности EC для блочного доступа работает он хорошо (файловый примерно тоже самое, т.к. подложка используется та же), понятное дело медленнее чем RF, но терпимо. К примеру EC 2+1 примерно на 5-10% медленнее, чем RF-2, но по объему EC значительно выгоднее.
vtolstov
30.09.2019 18:58Просто гиперконвергентный + EC мне кажется плохим сочетанием. Сделаешь больше кусков — меньше оверхед при перезаписи, но больше операций по сети, чтобы это распихать на соседей, плюс затраты на цпу для обсчета четности все равно остаются. В общем у меня, конечно, данные уже не очень актуальны, но обычно там где работают виртуалки не запускают EC, ну только для совсем бедного по железу варианта.

oller
02.10.2019 08:22Между цодами не очень интересно, там решений полно, а вот в рамках одной стойки и как передивает отключение питания стойки...
Viacheslav_V Автор
02.10.2019 19:33Для деления между стойками предусмотрены т.н. зоны данных, задача зон — распределить фрагменты данных таким образом, чтобы копии данных не оказались в той же стойке, где оригиналы, на случай если целая стойка выйдет из строя.
oller
02.10.2019 19:49я писал, про одну стойку, а вы про разные пишите
Как переживает одну стойку?Viacheslav_V Автор
02.10.2019 20:37Не очень понял вопрос. Вы имеете ввиду аппаратную защиту от потери питания в целой стойке? Поясните?
oller
02.10.2019 20:47Я имею ввиду поведение решения при пропадании питания во всей единственной стойке, или отказе большинства нод.
Viacheslav_V Автор
02.10.2019 21:04Ясно, спасибо.
Программно мы от этого защищаемся следующим образом.
В системе должно работать 50% + 1 нода от всего количества задействованных в IO нод. Если это количество меньше, то система автоматически остановит ввод-вывод.
Например, если у вас 4 ноды и все хранят виртуальные диски. Упала 1 = ОК, упало 2 = автостоп IO.
Например №2, если у вас 100 нод и все хранят виртуальные диски. Упало 49 = ОК, упало 50 = автостоп IO.
Данные останутся живы (именно ради них все и автостопится), но будут недоступны, пока не включиться нода, которая +1 после 50%.
Если допускать работу меньшинства нод (менее 50%), это чревато ( т.е. резко возрастает риск) потерей данных при любых схемах RF и EC. Понятное дело, на это мы пойти не можем.
Если упадет вся стойка (все ноды), то всё выключится :-). Тут только аппаратная защита — резервный ввод, ИБП, дизель и т. п.
GeorgBud
30.09.2019 14:29Каким образом происходит регулировка оборотов куллеров?
Viacheslav_V Автор
02.10.2019 19:34С помощью сенсоров, как и в наших СХД. Про аппаратку и список совместимости обаятельно напишем отдельную статью
beremour
01.10.2019 01:34ScaleIO был прекрасен, пока его продавали.
vtolstov
01.10.2019 01:49Может перестали продавать не с проста?:)

ximik13
02.10.2019 10:23Таки все еще продают, только называется оно теперь VxFlex и доступно только с Ready нодами от Dell. Софтовый вариант официально не доступен без нод. Но неофициально это все тот же SDS, которому пофиг на каком железе и OS работать (поддерживаются почти все популярные коммерческие).
beremour
02.10.2019 12:13Не-не) Они его пилят вовсю, но хотят поставлять только в своих решениях к сожалению.
Berserkr
01.10.2019 02:50как на счет тестов производительности? откуда 2 мсек задержки?
Далее приведены факты, они могут быть проверены из открытых источников, можно заказать оборудование на тест у местных реселлеров и т.д.
Я не имею никакого отношения к компании Nutanix и это не реклама :)
Вот эта фраза сразу цепляет:
Многие компании — производители ГКС (особенно те, у которых в портфеле нет СХД) говорят: «СХД отживает своё, гиперконвергент only!». Это смелое заявление, но оно не совсем отражает действительность
Тут явно прослеживается отсылочка к конкретному вендору т.к. по фактам реальных конкурентов особо нет — для тех кто немного в теме HCI понятно что эта фраза точно не может относится к VMware vSAN или к HPE SimpliVity и уж подавно не может относится к Cisco HyperFlex, про Microsoft с Storage Spaces Direct я вообще промолчу как и про Red Hat Hyperconverged Infrastructure на базе gluster storage.
На рынке сейчас есть решение которое является эталонной HCI системой — это Nutanix — Erasure coding(лучший на рынке), Deduplication(inline для RAM и SSD уровней и post-process для SSD\HDD capacity уровня — фактически inline позволяет в принципе меньше записывать данных на диски в реальном времени, а post-process это capacity deduplication), Compression(inline — опять же на примере записи позволяет значительно ускорить операции за счет того что нужно меньше данных записать на диски, offline), Storage Tiering(лучший или один из лучших на рынке).
Так же есть Rack Fault Tolerance позволяющий управлять отказоустойчивостью нод, блоков и стоек с учетом механизма Erasure coding.
При это все эти технологии могут быть использованы в рамках одного кластера неограниченного(!) размера.
Производительность:
очень много различных тестов, например
longwhiteclouds.com/2017/11/14/1-million-iops-in-1-vm-world-first-for-hci-with-nutanix
As with any major achievement there is a big team involved. This time is no different. Felipe helped me get a single Ubuntu VM on Nutanix NX9030 cluster up to 1M IOPS at 4KB. 100% Random Read. I ran a series to tests to make sure it could be sustained and then thought why can’t we do 8KB instead of 4KB. After more work with Felipe and some last minute tuning by Malcolm Crossly (Staff Engineer on AHV Team), we got to 1M IOPS at 8KB 100% random read and could sustain it for 24 hours. What was also impressive was that the latency was just 110 microseconds, or 0.11ms.
1 миллион IOPS блоками по 8KB 100% random read непрерывно в течении 24 часов с latency 110 микросекунд.
Вопросы обычные к производителям HCI:
— почему вы против data locality раз уж у вас HCI и вы достоверно можете узнать на какой ноде работает виртуальный сервер, зачем лишний раз ходить куда-то по сети если этого можно не делать?;
— почему бы не сделать нормальный tiering — ram, optane, nvme — могут невероятно ускорить ввод-вывод и для этого не нужно делать весь кластер из них? ведь на самом деле эра AF схд настала из-за того что флеш начал быстро падать в цене и производители не могут или не хотят осилить нормальный tiering;
— почему вы вообще считаете нормальным вспоминать и даже предложить использовать аппаратные raid-контроллеры зная какое количество проблем они создают в реальной жизни и то что ваш софт в принципе не сможет понимать что происходит с дисковой подсистемой. Как не плохой пример можно вспомнить zfs которому практически 15 лет и уже тогда люди поняли что овчинка не стоит выделки и намного надежнее и проще работать с устройствами для хранения данных напрямую.
Я ничуть не умаляю ваших достижений — это на самом деле круто что вы делаете такие системы, тем более в рамках текущей политической ситуации такие решения могут быть хорошим выбором, но безапелляционность некоторых утверждений ставит прямо таки в тупик.
Можно взять лучшее что уже придумали сейчас другие, если появятся идеи как сделать лучше — доработать, но местами выглядит так что некоторые решения принципиально не хотят использовать только из-за того что их ранее придумал вендор X.
Ситуация прям напоминает то что происходит на рынке электрокаров — есть отличное решение, которое по совокупности всех факторов гениально, но при этом все вокруг упорно пытаются сделать так что только бы было так не у того кто делает качественное и успешное решение.
Viacheslav_V Автор
02.10.2019 19:54Больше спасибо за развернутый комментарий.
как на счет тестов производительности? откуда 2 мсек задержки?
Далее приведены факты, они могут быть проверены из открытых источников Производительность:
очень много различных тестов, например
longwhiteclouds.com/2017/11/14/1-million-iops-in-1-vm-world-first-for-hci-with-nutanixПо этой ссылке задержки ниже 2 миллисекунд указаны для операций чтения (возможно есть другие источники). Для операций записи они выше или примерно равны 2 миллисекундам.
Задержки в микросекунды на чтение само собой в ARDFS тоже реализуемы. К примеру с помощью локализации чтения данных, чтобы ВМ не ходила за чтением своих данных на другие ноды, а читала их именно с той ноды, где она выполняется. Похожий механизм, насколько нам известно, успешно используется у решений Нутаникс (про других не знаю)
С записью же дела обстоят сложнее, т.к. при записи системе следует дождаться подтверждения записи от всех нод, которые участвуют в хранении копий виртуального диска. Это подтверждение (обязательное) происходит по внутреннему интеконнекту и пока оно состоится, как раз и проходят те самые миллисекунды. Во всяком случае так сделано у нас.
Несомненно, существует еще много способов снижать количество операций записи (дедуп тот же), но есть задачи, в которых это не применимо (видеонаблюдение или биллинг с большим количество уникальных транзакций, как пример).
Возможно другие разработчики эту задачу ещё как-то решили, мы точно не знаем, но если есть методы, которые решают эту проблему (мы ещё в начале пути, все-таки), мы с радостью бы о них поговорили бы и не только))))
ximik13
02.10.2019 11:46Интересны подробности по внутреннему устройству ARDFS и как она работает с метаданными. Из этого будет понятнее про надежность/ненадежность.
Viacheslav_V Автор
02.10.2019 20:35Метаданные ARDFS условно делятся на два класса.
1)нотификации (инфа об операциях с объектами хранения, информация о самих объектах и т.п.)
2)служебная информация (блокировка, информация о конфигурации нод-хранилищ и т.п.)
Для распределения этих данных используется служба RCD (raft cluster driver) она автоматически назначает ноду с ролью лидера, задачей которого является получение и распространение информации по нодам. Лидер является единственно верным источником этой информации. Кроме того, лидер организовывает хартбит. Если по какой-либо причине для одной из рядовых нод лидер стал недоступен более одной секунды, эта рядовая нода организовывает перевыборы лидера, запрашивая доступность лидера с других рядовых нод. Если собирается кворум, лидер переизбирается. После того как бывший лидер "проснулся" он автоматически становится рядовой нодой, т.к. ему новый лидер отправляет соответствующую команду.
Может показаться, что лидер является "узким горлышком", которое будет тормозить в больших кластерах на сотни нод, но это не так. Описанный процесс происходит практически моментально и "весит" очень немного (т.к. писали его сами и включили только самые необходимые функции). Кроме того он происходит полностью автоматически, оставляя лишь сообщения в логах.
Тут мы не изобретали велосипед. Подобной логикой также руководствуются многие сторонние и коммерческие, и свободные решения (тот же зукипер), но эти решения достаточно тяжелые и оптимизировать их под наши простые задачи весьма сложно, поэтому мы просто написали свою службу RCD.
ximik13
03.10.2019 09:32Я правильно понимаю что служба RCD тоже распределенная?
Каким образом защищаются от потери сами метаданные? Тоже дублированием? С каким RF?
Предусмотрено ли кеширование метаданных на флеш при шпиндельных конфигурациях нод в кластере, что может быть критично при больших конфигурациях?

RStarun
02.10.2019 20:37А давайте в комплекте с СХД обычными прикладывать лицензии на VSAN?
Для вас технически не в убыток, а покупателям СХД приятно и есть возможность поиграть.
Из гипервизоров только KVM я так понял?Viacheslav_V Автор
02.10.2019 20:44Зачем нам vSAN? У нас есть vAIR))))
Из гипервизоров поддерживается наша улучшенная реализация KVM, которая управляется из той-же web-gui, что и хранилище ARDFS с программной сетью. Также поддерживается VMware. В будущем будет ещё HyperV.
past
Что на счет QOS?
Viacheslav_V Автор
Спасибо за комментарий.
QOS сейчас реализован на уровне ВМ, возможно задавать на каждую в отдельности.
Более подробно напишем в статье про функциональность.