Эта статья — попытка систематизации того как в Qt «под капотом» реализована работа с потоками и о некотором количестве неочевидных подводных камней связанных с ограничениями этой модели.
Основы
Thread affinity, инициализация и их ограничения
Главный поток, QCoreApplication и GUI
Rendering thread
Заключение
Основы
Давайте начнем с основ. В Qt любые объекты способные работать с сигналами и слотами является наследниками класса QObject. Эти объекты by design являются некопируемыми и логически представляют из себя некоторые индивидуальные сущности которые «разговаривают» друг с другом — реагируют на те или иные события и могут сами генерировать события. Если говорить другими словами, то QObject в Qt реализует паттерн Actors. При правильной реализации любая программа на Qt по сути представляет из себя не более чем сеть взаимодействующих между собой QObject в которых «живет» вся программная логика.
Помимо набора QObject-ов, программа на Qt может включать в себя объекты с данными. Эти объекты не могут генерировать и принимать сигналы, но могут копироваться. К примеру можно сравнить между собой QStringList и QStringListModel. Один из них является QObject и не копируем, но может напрямую взаимодействовать с UI-объектами, другой — это обычный копируемый контейнер для данных. В свою очередь объекты с данными делятся на «Qt Meta-types» и все остальные. К примеру QStringList — это Qt Meta-type, а std::list<std::string> (без дополнительных телодвижений) — нет. Первые могут использоваться в любом Qt-шном контексте (передаваться через сигналы, лежать в QVariant и т.д.), но требуют специальной процедуры регистрации и наличия у класса публичных деструктора, конструктора копирования и конструктора по умолчанию. Вторые — это произвольные С++-типы.
Плавно переходим к собственно потокам
Итак, у нас есть условные «данные» и есть условый «код» который с ними работает. Но кто на самом деле будет выполнять этот код? В модели Qt ответ на этот вопрос задается явным образом: каждый QObject строго привязан к какому-то потоку QThread который, собственно, и занимается обслуживанием слотов и прочих событий данного объекта. Один поток может обслуживать сразу множество QObject или вообще ни одного, а вот QObject всегда имеет родительский поток и он всегда ровно один. По сути можно считать что каждый QThread «владеет» каким-то набором QObject. В терминологии Qt это называется Thread Affinity. Попробуем для наглядности визуализировать:
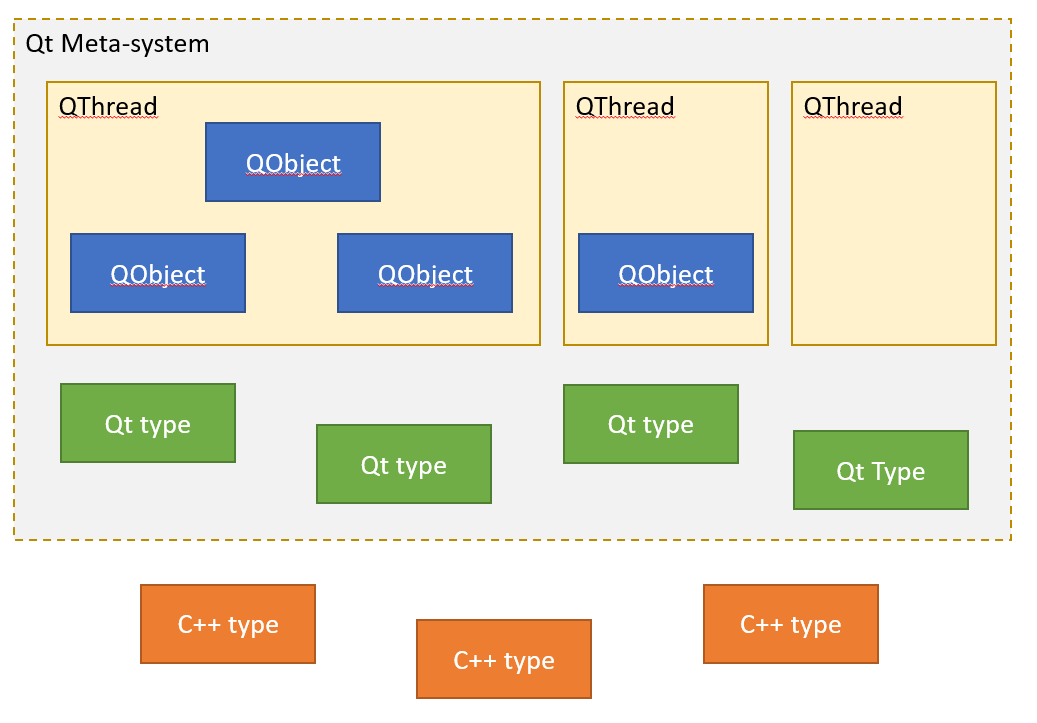
Внутри каждого QThread спрятана очередь сообщений адресованных к объектам которыми данный QThread «владеет». В модели Qt предполагается что если мы хотим чтобы QObject сделал какое-либо действие, то мы «посылаем» данному QObject сообщение QEvent:
QCoreApplication::postEvent(QObject *receiver, QEvent *event, int priority);В этом потоково-безопасном вызове Qt находит QThread которому принадлежит объект receiver, записывает QEvent в очередь сообщений этого потока и при необходимости «будит» этот поток. При этом ожидается что код работающий в данном QThread в какой-то момент после этого прочитает сообщение из очереди и выполнит соответствующее действие. Чтобы это действительно произошло, код в QThread должен войти в цикл обработки событий QEventLoop, создав соответствующий объект и позвав у него либо метод exec(), либо метод processEvents(). Первый вариант входит в бесконечный цикл обработки сообщений (до получения QEventLoop события quit() ), второй ограничивается тем что обрабатывает сообщения ранее накопившиеся в очереди.

Легко видеть что события для всех объектов принадлежащих одному потоку обрабатываются последовательно. Если обработка какого-то события потоком займет много времени, то все остальные объекты окажутся «заморожены» — их события будут накапливаться в очереди потока, но не будут обрабатываться. Чтобы этого не происходило в Qt предусмотрена возможность cooperative multitasking — обработчики событий в любом месте могут «временно прерваться», создав новый QEventLoop и передав в него управление. Поскольку обработчик события до этого тоже был вызван из QEventLoop в потоке при подобном подходе формируется цепочка «вложенных» друг в друга event loop-ов.
Что входит в понятие «события» обрабатываемого в подобном цикле? Хорошо знакомые всем Qt-шникам «сигналы» — это лишь один из частных примеров, QEvent::MetaCall. Подобный QEvent хранит в себе указатель на информацию необходимую для идентификации функции (слота) которую нужно позвать и ее аргументов. Однако помимо сигналов в Qt существует еще порядка сотни (!) других событий, из которых десяток зарезервирован за специальными Qt-шными событиями (ChildAdded, DeferredDelete, ParentChange) а остальные соответствуют различным сообщениям от операционной системы.
Одним из неочевидных подводных камней здесь является то что в Qt у потока, вообще говоря, может вообще не быть Dispatcher-а и соответственно ни одного EventLoop-а. Объекты принадлежащие этому потоку не будут реагировать на посылаемые им события. Поскольку QThread::run() по умолчанию вызывает QThread::exec() внутри которого как раз реализован стандартный EventLoop, то с этой проблемой часто сталкиваются те кто пытается определить свою собственную версию run() отнаследовавшись от QThread-а. Подобный вариант использования QThread в принципе вполне валиден и даже рекомендуется в документации, но идет вразрез с общей идеей организации кода в Qt описанной выше и частенько работает не так как ожидают того пользователи. Характерной ошибкой при этом является попытка останавливать подобный кастомный QThread путем вызова QThread::exit() или quit(). Обе эти функции направляют сообщение в QEventLoop, но если в потоке этого QEventLoop просто нет, то и обрабатывать их, естественно, некому. В результате неопытные пользователи пытаясь «починить неработающий класс» начинают пытаться использовать «работающий» QThread::terminate, чего делать категорически нельзя. Имейте в виду — в случае если Вы переопределяете run() и не используете стандартный event loop, то механизм выхода из потока придется предусмотреть самостоятельно — к примеру воспользовавшись специально добавленной для этого функцией QThread::requestInterruption(). Правильнее, впрочем, просто не наследоваться от QThread если Вы не собираетесь действительно реализовывать какую-то специальную новую разновидность потоков и либо использовать специально созданный для подобных сценариев QtConcurrent, либо поместить логику в специальный Worker Object отнаследованный от QObject, поместить последний в стандартный QThread и управлять Worker-ом с помощью сигналов.
Thread affinity, инициализация и их ограничения
Итак, как мы уже разобрались, каждый объект в Qt «принадлежит» какому-то потоку. При этом встает закономерный вопрос: а какому, собственно говоря, именно? В Qt приняты следующие соглашения:
1. Все «дети» любого «родителя» всегда живут в том же потоке что и родительский объект
Это пожалуй самое сильное ограничение потоковой модели Qt и попытки его нарушить нередко дают весьма странные для пользователя результаты. К примеру попытка сделать setParent к объекту живущему в другом потоке в Qt просто молча фейлится (в консоль пишется предупреждение). На этот компромисс по всей видимости пошли из-за того что потоковобезопасное удаление «детей» при гибели живущего в другом потоке родителя является очень нетривиальной и склонной к трудно отлавливаемым багам проблемой. Хотите реализовывать иерархию взаимодействующих объектов живущих в разных потоках — придется организовывать удаление самостоятельно.
2. Объект у которого при создании не указан родитель живет в потоке который его создал
Тут все одновременно и просто и в то же время не всегда очевидно. К примеру в силу этого правила QThread (как объект) живет в другом потоке чем собственно тот поток который он контролирует (и в силу правила 1 не может владеть ни одним из объектов созданных в этом потоке). Или, скажем, если Вы переопределите QThread::run и будете внутри создавать какие-либо наследники QObject, то без принятия специальных мер (как разбиралось в предыдущей главе) созданные объекты не будут реагировать на сигналы.
Thread affinity при необходимости можно менять вызовом QObject::moveToThread. В силу правила 1, перемещать можно только верхнеуровневых «родителей» (у которых parent==null), попытка переместить любого «ребенка» будет молча проигнорирована. При перемещении верхнеуровневого «родителя» все его «дети» тоже переедут в новый поток. Любопытно что вызов moveToThread(nullptr) тоже легален и является способом создать объект с «null»-овой thread affinity; подобные объекты не могут получать никаких сообщений.
Получить «текущий» поток исполнения можно через вызов функции QThread::currentThread(), поток с которым ассоциирован объект — через вызов QObject::thread()
Главный поток, QCoreApplication и GUI
Среди всех потоков Qt обязательно выделяет один «главный» (main thread), который в случае с UI-приложениями так же становится GUI thread. В этом потоке живет объект QApplication (QCoreApplication / QGuiApplication) который обслуживает основной event loop ориентированный на работу с сообщениями от операционной системы. В силу правила №2 из предыдущего раздела на практике «главным» станет тот поток, который собственно создал объект QApplication, а поскольку во многих операционных системах «главный поток» имеет специальное значение, то документация настоятельно рекомендует создавать QApplication самым-самый первым объектом во всей Qt программе и делать это сразу же после старта приложения (== внутри первого потока в процессе). Для получения указателя на главный поток приложения соответственно можно воспользоваться конструкцией вида QCoreApplication::instance()->thread(). Впрочем чисто технически QApplication можно повесить и на не-main()-поток, к примеру если Qt интерфейс создается внутри какого-нибудь плагина и во многих случаях это будет нормально работать.
В силу правила «созданные объекты наследуют текущий поток», Вы всегда можете спокойно работать не выходя за пределы одного потока. Все созданные объекты автоматически попадут на обслуживание в «главный» поток, где всегда будет event loop и (по причине отсутствия других потоков) никогда не будет проблем с синхронизацией. Даже если Вы работаете с более сложной системой, требующей многопоточности, то в основной поток скорее всего попадет большинство объектов, за исключением тех немногих которые явным образом будут размещены где-то еще. Возможно именно это обстоятельство и порождает кажущуюся «магию» в которой объекты кажутся безо всяких усилий работающими независимо друг от друга (ибо в пределах потока реализуется cooperative multitasking) и при этом не требующими синхронизации, блокировок и тому подобных вещей (ибо все происходит в одном потоке).
Помимо того что «главный» поток является «первым» и содержит в себе основной цикл обработки событий QCoreApplication, еще одним характерным для Qt ограничением является то что в этом потоке должны «жить» все объекты связанные с GUI. Отчасти это является следствием легаси: в силу того что в ряде операционных систем любые операции с GUI могут происходить только в главном потоке, Qt подразделяет все объекты на «виджеты» и «не-виджеты». Widget-type object может жить только в главном потоке, попытка «перевесить» такой объект в любой другой автоматически зафейлится. В силу этого даже существует специальный метод QObject::isWidgetType(), отражающий довольно глубокие внутренние различия в механике работы потоков с такими объектами. Но интересно что и в намного более новом QtQuick, где от костыля с isWidgetType попытались уйти осталась та же самая проблема
В чем же дело? В Qt5 QML-объекты больше не являются виджетами а их рендеринг может происходить в отдельном потоке. Но это привело к другой проблеме — сложностям синхронизации. Отрисовка объектов UI является «чтением» их состояния и должна происходить консистентно: если мы попытаемся изменить состояние объекта одновременно с его отрисовкой, то результат полученной «гонки» может нас не обрадовать. Кроме того OpenGL вокруг которого построена «новая» графика Qt крайне сильно «заточен» на то что формирование команд на отрисовку проводит один поток, работающий с некоторым глобальным состоянием -«графическим контекстом» который может меняться только в виде серии последовательных операций. Мы просто не можем одновременно отрисовывать на экране два разных графических объекта — они всегда будут рисоваться последовательно один за другим. В результате мы возвращаемся обратно к тому же самому решению — отрисовка UI оказывается возложена на один поток. Внимательный читатель, впрочем, заметит что этот поток не обязательно должен быть main thread — и в Qt5 фрейморк действительно попытается задействовать для этого отдельный Rendering thread
Rendering thread
В рамках новой модели Qt5 вся отрисовка объектов происходит в специально выделенном для этого потоке, rendering thread. При этом чтобы это имело смысл и не ограничивалось простым переходом от одного «главного» потока к другому, объекты неявно делятся на «фронт-енд» который видит программист и обычно скрытый от него «бэк-энд» который собственно осуществляет реальную отрисовку. Бэк-энд живет в rendering thread, тогда как фронт-энд, чисто теоретически, может жить в любом другом потоке. Предполагается что полезную работу (если таковая есть) в виде обработки событий выполняет именно фронт-енд тогда как функция бэка ограничена только рендерингом. В теории таким образом получается win-win: бэк периодически «опрашивает» текущее состояние объектов и отрисовывает их на экране, при этом его не может «остановить» то что какой-то из объектов слишком сильно «задумался» обрабатывая событие в силу того что эта медленная обработка происходит в другом потоке. В свою очередь потоку объекта нет нужды дожидаться «ответов» от графического драйвера подтвеждающих завершение отрисовки и разные объекты могут работать в разных потоках.
Но как я уже упомянул в предыдущей главе, раз у нас есть поток «создающий» данные («фронт») и поток который их читает («бэк»), то нам необходимо как-то обеспечивать их синхронизацию. Эта синхронизация в Qt делается блокировками. Поток где живет «фронт» временно приостанавливается, после чего следует специальный вызов функции (QQuickItem::updatePaintNode(), QQuickFramebufferObject::Renderer::synchronize() ) единственной задачей которого является копирование релевантного для визуализации состояния объекта из «фронта» в «бэк». При этом вызов такой функции происходит внутри rendering thread, но благодаря тому что поток где живет объект в этот момент остановлен, пользователь может свободно работать с данными объекта так, как если бы это происходило «как обычно», внутри потока которому принадлежит объект.
Все хорошо, все отлично? К сожалению нет, и здесь начинаются достаточно неочевидные моменты. Если мы будем брать для каждого объекта блокировку по отдельности, то это будет довольно медленно поскольку rendering thread будет вынужден ждать пока эти объекты завершат обработку своих событий. «Повиснет» поток где живет объект — «повиснет» и рендеринг. Вдобавок станет возможен «рассинхрон» когда при одновременном изменении двух объектов один успеет отрисоваться еще в кадре N а другой будет отрисован только в кадре N+1. Предпочтительнее было бы брать блокировку лишь один раз и на все объекты сразу и лишь тогда когда мы уверены что эта блокировка будет успешной.
Что было реализовано для решения этой проблемы в Qt? Во-первых было принято решение что все «графические» объекты одного окна будут жить в одном потоке. Таким образом для отрисовки окна и взятия блокировки на все содержащиеся в нем объекты становится достаточно остановить один этот поток. Во-вторых блокировку для обновления бэк-энда инициирует сам же поток с UI-объектами, посылая сообщение rendering thread о необходимости провести синхронизацию и останавливая сам себя (QSGThreadedRenderLoop::polishAndSync если кому интересно). Это гарантирует что rendering thread никогда не будет «ждать» поток с «фронт-ендом». Если тот вдруг «зависнет» — rendering thread просто продолжит отрисовывать «старое» состояние объектов, не получая сообщений о необходимости обновиться. Это правда порождает довольно забавные баги вида «если рендеринг по какой-то причине не может отрисовать окно сразу, то главный поток зависает», но в целом является разумным компромиссом. Начиная c QtQuick 2.0 ряд «анимационных» объектов можно даже «поселить» имено в render thread чтобы анимация могла тоже продолжать работать если основной поток «задумался».

Однако практическим следствием этого решения является то что все UI-объекты в любом случае должны жить в одном и том же потоке. В случае со старыми виджетами — в «главном» потоке, в случае с новыми Qt Quick-объектами — в потоке объекта QQuickWindow который ими «владеет». Последнее правило довольно изящно обыграно — для того чтобы нарисовать QQuickItem ему нужно сделать setParent к соответствующему QQuickWindow что как уже обсуждалось гарантирует что объект или переедет в соответствующий поток или вызов setParent провалится.
А теперь, увы, ложка дегтя: хотя разные QQuickWindow чисто теоретически могли бы жить в разных потоках, на практике это требует аккуратной пересылки им сообщений от операционной системы и в Qt сегодня таковая не реализована. В Qt 5.13 к примеру QCoreApplication пытается общаться с QQuickWindow через sendEvent требующий чтобы получатель и посылатель были в одном потоке (вместо postEvent который допускает чтобы потоки были разными). Поэтому на практике QQuickWindow правильно работают только в GUI-потоке и как следствие все QtQuick-объекты живут там же. В результате несмотря на наличие rendering thread практически все доступные пользователю объекты связанные с GUI по-прежнему обитают в одном и том же GUI thread. Возможно это изменится в Qt 6.
Помимо вышесказанного стоит так же помнить что поскольку Qt работает на множестве разных платформ (включая те в которых не поддерживается многопоточность), то в фреймворке предусмотрено приличное количество fallback-ов и в некоторых случаях функциональность rendering thread в реальности выполняется тем же самым gui thread-ом. В этом случае весь UI включая рендеринг живет в одном потоке и проблема синхронизации автоматически отпадает. Аналогично обстоят дела и с более старым, Qt4-style UI на основе виджетов. При большом желании можно заставить Qt работать в таком «однопоточном» режиме с помощью установки переменной окружения QSG_RENDER_LOOP в соответвующий вариант.
Заключение
Qt — огромный и сложный фреймворк и работа с потоками в нем отражает часть этой сложности. Но спроектирован он очень аккуратно, логично и грамотно, так что при понимании нескольких ключевых идей с потоками в Qt довольно просто работать не допуская ошибок.
Напомню еще раз основные моменты;
- Каждый объект имеет «владеющий» им поток выполняющий обработчики всех событий происходящих с объектом, включая обработку queued signals
- Если «владеющий» объектом поток не выполняет Qt Event Loop то принадлежащие ему объекты не получат никаких сообщений а сам поток не будет реагировать на попытки сказать ему exit()
- Родители и потомки всегда живут в одном и том же потоке. Переносить из потока в поток можно только top-level parent. Нарушение этого правила может приводить к тихому провалу операции setParent или moveToThread
- Объект у которого не указан родитель поступает во владение потока который этот объект создал
- Все GUI-объекты кроме rendering back-end должны жить в GUI-потоке
- GUI-потоком является тот в котором был создан объект QApplication
Надеюсь что это поможет Вам эффективнее использовать Qt и не совершать ошибок связанных с его многопоточной моделью
Комментарии (30)

Tantrido
30.10.2019 01:41+2Писал, писал чего-то — много воды, примеров — мало, без примеров не так понятно. И главное таки не написал, как правильно работать с потоками. А именно, код исполняемого объекта должен создаваться в функции
void QThread::run(). Если его создать в родительском потоке или даже в самомQThread, например:
class MyThread: public QThread { MyObjects obj; protected: void run() override { obj.execute(); } }
То данные и стек этого объекта будут всё равно находиться в родительском потоке, т.е. обращение всё равно будет к данным из другого потока, что чревато крэшами. Правильное объявление:
class MyThread: public QThread { protected: void run() override { MyObjects obj; obj.execute(); } }
Вот привёл бы парочку подобных примеров — уже было бы гораздо понятнее! ;)

darkxanter
30.10.2019 07:43Не обязательно создавать наследника QThread, чтобы поместить выполнение QObject в потоке, в большинстве случаев нужно использовать moveToThread. И в Qt есть более высокоуровневые классы для потоков чем QThread.
0serg Автор
30.10.2019 08:57То данные и стек этого объекта будут всё равно находиться в родительском потоке
У объекта нет стека (стек — часть потока) и в приведенном примере если .execute() вызвано в потоке MyThread, то и стек будет находиться так же. Данные объекта в свою очередь не привязаны ни к одному потоку ибо лежат в «куче» (heap, говорящее название, не правда ли?). per se, чисто из того что написано в обоих примерах проблем нет.
Приведенный пример может крэшиться по другой причине — если MyObjects обрабатывают какие-то сигналы с данными которые меняет запущенный в другом потоке .execute. Но в этом случае второй пример (как показано) работать не будет, т.к. MyObjects просто не будут обрабатывать сигналы.
Как правильно:
MyObjects obj; connect(this, startRunning, obj, execute) QThread thread; thread.run(); obj.moveToThread(&thread); emit startRunning();
Это в предположении что MyObjects занимаются обработкой сигналов. Если нет и речь идет просто о запуске функции execute, то правильно
MyObjects obj; QtConcurrent::run([&obj](){ obj.execute(); }); // assuming obj won't be destroyed soon
Вообще, как правило если Вы переопределяете QThread::run(), то Вы скорее всего делаете что-то неправильно.mayorovp
30.10.2019 10:04Что-то мне кажется, что ваш "правильный" код будет вести себя крайне странно если выполнить его хотя бы два раза. Почему бы не сделать
connect(thread, started, obj, execute)?0serg Автор
30.10.2019 11:22Код несколько упрощен, он показывает основную идею (в частности то что создание QThread не обязательно привязано к созданию MyObjects, этот поток мог быть создан и запущен давным-давно и совсем в другом месте). Работать должен без проблем, или я Вашу идею не вполне понял.
А так-то да, started вполне можно использовать в качестве startRunning. Если совсем канонически то остановка потоков и уничтожение объектов (оставленные в моем примере полностью за скобками) тоже вешается аналогичным образом на сигнал finished
QThread* thread = new QThread; MyObjects * worker = new MyObjects (); worker->moveToThread(thread); connect(thread, started, worker, execute); connect(worker, finished, thread, quit); connect(worker, finished, worker, deleteLater); connect(thread, finished, thread, deleteLater); thread->start();
Здесь предполагается что execute() должен обязательно сделать emit finished().mayorovp
30.10.2019 11:38Работать должен без проблем, или я Вашу идею не вполне понял.
У вас в процессе работы накапливаются соединения с событием startRunning. Второе выполнение кода приведёт к вызову execute у двух объектов сразу, третье вызовет вызов execute у трёх объектов.
Или я что-то путаю, и connect срабатывает только 1 раз? В таком случае я не вполне понимаю как им пользоваться в GUI.
0serg Автор
30.10.2019 13:03Да, это верное замечание. Это не очень критично для реального кода — там обычно для старта используется некоторое существующее событие, а не создается специально свое новое и если объект создается и остается, то предполагается что он собственно и должен отрабатывать на каждое такое событие. Но в приведенном модельном примере да, надо либо гарантировать что MyObject будут существовать не более чем в одном экземпляре на создавший его инстанс, либо вручную делать disconnect у запустившегося потока, либо создавать по отдельному QThread на каждый объект и стартовать через сигнал started.
mayorovp
30.10.2019 13:41Ну, поскольку вы приводили свой пример как альтернативу наследованию от QThread — то очевидно, что правильным будет только последний вариант. Остальные варианты попросту решают другую задачу.

lexa
30.10.2019 10:27Насколько я понимаю (и насколько написано в вашем тексте же) QThread::run переопределить в случае, когда
— мы не пользуемся в данном thread signal/slot
— мы сделали какой-то свой механизм остановки
— мы сделали какой-то (свой) механизм синхронизации, чтобы этот run() не молотил бы непрерывно
Вроде бы — в таком случае все ок?0serg Автор
30.10.2019 11:27Вроде бы — в таком случае все ок?
В таком случае — да. Можно даже поддержку signal/slot реализовать сравнительно простыми усилиями. Но это определенное велосипедостроительство, «канонически» в Qt предполагается паттерн Actors в котором работу делают QObject-ы в ответ на сигналы.
Goron_Dekar
30.10.2019 10:34В таком случае есть другая проблема: obj не может сам усыплять свой поток. А если логике не надо управлять потоком, то надо использовать greenthread и прочие очереди выполнения.
nckma
30.10.2019 10:40Такой странный вопрос: вы же все равно компилируете C++ современным компилятором? Есть ли какая нибудь особая причина использовать в Qt приложении именно QThread, а не std::thread?
Я почему-то последнее время все больше склоняюсь к тому, чтобы писать как можно больше std:: и как можно меньше Qt кода (только то, что иначе нельзя), даже в Qt приложении.mayorovp
30.10.2019 10:49Есть ли какая нибудь особая причина использовать в Qt приложении именно QThread, а не std::thread?
Обработка очереди сообщений же.
serjeant
30.10.2019 11:28На работе вечный спор между stdшниками и qtшниками. Первые с пеной у рта доказывают, что надо всё на std писать, а от qt использовать только gui. Но при это истинно удивляются, когда у них не работают нормально сигналы-слоты, или же приходится городить костыли, потому-что нет возможности использовать meta систему qt. Вторые доказывают, что раз пишешь на qt, то нужно использовать только qt. Чтобы по максимуму использовать всю мощь фреймворка, пусть даже в угоду переносимости (в случаях, когда хочется использовать код в другом проекте, без qt).
nckma
30.10.2019 11:31Как по мне, так метасистема Qt — зло. Я видимо к первым отношусь.

KanuTaH
30.10.2019 11:37У вас это чисто идеологическая неприязнь или все-таки имеет под собой какую-то практическую основу? Например в случае тех же потоков метасистема Qt хороша уже хотя бы тем, что при правильном использовании практически полностью снимает вопрос безопасного взаимодействия между потоками, ибо сигналы/слоты — потокобезопасный инструмент by design.
hhba
30.10.2019 21:54Ну, возможно у них там специфическая ситуация, когда проблемы взаимодействия между потоками нет (но потоки нужны), либо хочется делать это все руками (и это не обязательно плохо).
0serg Автор
30.10.2019 11:35+1Я не вижу прямо такого вот страшного конфликта между stl и qt. Серьезно пересекаются разве что только в контейнерах, но нет ни малейших проблем сделать QObject который будет хранить внутри себя stl-контейнер и предоставлять к нему наружу Qt-совместимый интерфейс.

svr_91
30.10.2019 12:49И постоянно конвертировать QString в std::string и обратно…
У меня тоже проблема с использованием stl и qt типов. Все никак не могу провести границу между тем, где использовать qt, а где stl. Точнее, границу то провожу, но на этой границе получаются постоянные конвертирования туда-сюда. И что с этим делать, не понятно
0serg Автор
30.10.2019 11:30QThread нужен только для QObject-ов и корректной работы у них сигналов и слотов «из коробки». Ну и появился он на 10 лет раньше и доступен на большем спектре платформ. Других причин предпочесть его std::thread нет, более того — Qt в принципе совместим и с std::thread.
hhba
30.10.2019 21:50Если вам не нужна обработка сообщений из коробки (а то может быть и вообще не нужна, и таких ситуаций миллион), то конечно причин нет.
Paulus
31.10.2019 01:24Так назовите хоть одну реальную многопоточную альтернативу Qt signal-slot connection в std. И чтоб один и тот же код работал хотя бы в Linux и Windows, MacOS тоже приветствуется.
Уже даже и не спрашиваю про std::gui или std::sql.
Да, знаю, и в Qt шаг влево, шаг вправо, и прыжок на месте часто караются assertion или вообще acceess violation, а куда уйти то???nckma
31.10.2019 09:24Вы просто привыкли к парадигме signal-slot и думаете без них обойтись нельзя.
Но по поводу кроссплатформного GUI тут соглашусь, особо выбора нет.BeardedBeaver
31.10.2019 09:36Справедливости ради, парадигма весьма удобна и изящна. К тому же в Qt5 она сводится только к «сигнал», сигналы подключаются к любым методам, не только к слотам.
Paulus
01.11.2019 04:23> Вы просто привыкли к парадигме signal-slot и думаете без них обойтись нельзя.
юноша, я отлично программировал на Окнах. когда еще даже Borland не было
> Но по поводу кроссплатформного GUI тут соглашусь, особо выбора нет.
А что по поводу QtSql?
Ryppka
01.11.2019 09:58юноша, я отлично программировал на Окнах. когда еще даже Borland не было
Преклоняюсь: Windows 3.0 вышла в 1990, Borland C++ — в 1991. Правда, сама фирма Borland основана в 1981.., но это так…
Целый год отлично программировать на Win16 — это супер!Paulus
02.11.2019 02:34+1Преклоняюсь перед Вашим умением цитировать Вики и полном непонимании того, что был тогда Turbo Pascal и Turbo Vision, и почему Borland до Delphi не имел никакого отношения к созданию приложений под Windows
aol-nnov
Спасибо за популяризацию данной темы и детальное описание "кишков"! А то, увы, на поверку оказывается, что большинство "разработчиков на куте" совершенно не умеют в потоки и высшим пилотажем оказывается наследование от QThread с переопределением run, а то, так и более убойные перлы типа obj->moveToThread(obj) и вариации этого...
QtRoS
Мне понравилось одно высказывание про `this->moveToThread(this)` — это как сначала закинуть удочку, а потом следом кинуть саму удочку (С)
Вообще, понимание данного механизма в настоящее время может пригодиться и вне Qt, например, при изучении Node.JS — там тоже есть свой цикл событий.