В последнее время интервалы (ranges), которые должны войти в стандарт C++20, довольно много обсуждают, в том числе и на Хабре (пример, где много примеров). Критики интервалов хватает, поговаривают, что
- они слишком абстрактны и нужны только для очень абстрактного кода
- читаемость кода с ними только ухудшается
- интервалы замедляют код
Давайте посмотрим совершенно рабоче-крестьянскую практическую задачку, для того, чтобы понять, справедлива ли эта критика и правда ли, что Эрик Ниблер был укушен Бартошем Милевски и пишет range-v3 только при полной луне.
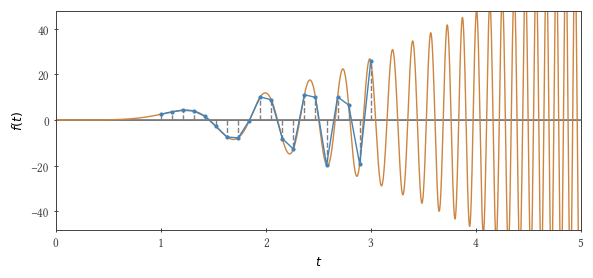
Будем интегрировать методом трапеций вот такую функцию: , в пределах от нуля до . Если равняется нечётному числу, то интеграл равен 2.
Итак, задачка: напишем прототип функции, которая вычисляет интеграл методом трапеций. Кажется, на первый взгляд, что здесь не нужны абстракции, а вот скорость важна. На самом деле, это не совсем так. По работе мне часто приходится писать "числодробилки", основной пользователь которых — я сам. Так что поддерживать и разбираться с их багами приходится тоже мне (к сожалению моих коллег — не всегда только мне). А еще бывает, что какой-то код не используется, скажем, год, а потом… В общем, документацию и тесты тоже нужно писать.
Какие аргументы должны быть у функции-интегратора? Интегрируемая функция и сетка (набор точек , используемых для вычисления интеграла). И если с интегрируемой функцией всё понятно (std::function здесь будет в самый раз), то в каком виде передавать сетку? Давайте посмотрим.
Варианты
Для начала — чтобы было, с чем сравнивать производительность — напишем простой цикл for с постоянным шагом по времени:
// trapezoidal rule of integration with fixed time step;
// dt_fixed is the timestep; n_fixed is the number of steps
double integrate() {
double acc = 0;
for(long long i = 1; i < n_fixed - 1; ++i) {
double t = dt_fixed * static_cast<double>(i);
acc += dt_fixed * f(t);
}
acc += 0.5 * dt_fixed * f(0);
acc += 0.5 * dt_fixed * f(tau);
return acc;
}При использовании такого цикла можно передавать в качестве аргументов функции начало и конец интервала интегрирования, а еще число точек для этого самого интегрирования. Стоп — метод трапеций бывает и с переменным шагом, и наша интегрируемая функция просто просит использовать переменный шаг! Так и быть, пусть у нас будет ещё один параметр () для управления "нелинейностью" и пусть наши шаги будут, например, такими: . Такой подход (ввести один дополнительный числовой параметр) используется, наверное, в миллионе мест, хотя, казалось бы, ущербность его должна быть всем очевидна. А если у нас другая функция? А если нам нужен мелкий шаг где-то посередине нашего числового интервала? А если у интегрируемой функции вообще пара особенностей есть? В общем, мы должны уметь передать любую сетку. (Тем не менее в примерах мы почти до самого конца "забудем" про настоящий метод трапеций и для простоты будем рассматривать его версию с постоянным шагом, держа при этом в голове то, что сетка может быть произвольной).
Раз сетка может быть любой — передадим её значения завёрнутыми в std::vector.
// trapezoidal rule of integration with fixed time step
double integrate(vector<double> t_nodes) {
double acc = 0;
for(auto t: t_nodes) {
acc += dt_fixed * f(t);
}
acc -= 0.5 * dt_fixed * f(0);
acc -= 0.5 * dt_fixed * f(tau);
return acc;
}Общности в таком подходе — хоть отбавляй, а что с производительностью? С потреблением памяти? Если раньше у нас всё суммировалось на процессоре, то теперь приходится сначала заполнить участок памяти, а потом читать из него. А общение с памятью — довольно медленная вещь. Да и память всё таки не резиновая (а силиконовая).
Посмотрим в корень проблемы. Что человеку нужно для счастья? Точнее, что нужно нашему циклу (range-based for loop)? Любой контейнер с итераторами begin() и end(), и операторами ++, * и != для итераторов. Так и напишем.
// функция стала шаблоном, чтобы справиться со всем, что в неё задумают передать
template <typename T>
double integrate(T t_nodes) {
double acc = 0;
for(auto t: t_nodes) {
acc += dt_fixed * f(t);
}
acc -= 0.5 * dt_fixed * f(0);
acc -= 0.5 * dt_fixed * f(tau);
return acc;
}
// ...
// Вот здесь всё самое интересное
class lazy_container {
public:
long long int n_nodes;
lazy_container() {
n_nodes = n_fixed;
}
~lazy_container() {}
class iterator {
public:
long long int i; // index of the current node
iterator() {
i = 0;
}
~iterator() {}
iterator& operator++() { i+= 1; return *this; } // вот!
bool operator!=(const iterator& rhs) const { return i != rhs.i; }
double operator* () const
{ return dt_fixed * static_cast<double>(i); }
};
iterator begin() {
return iterator();
}
iterator end() {
iterator it;
it.i = n_nodes;
return it;
}
};
// ...
// а так это можно использовать
lazy_container t_nodes;
double res = integrate(t_nodes);Мы вычисляем здесь новое значение по требованию, так же, как мы делали это в простом цикле for. Обращений к памяти при этом нет, и можно надеяться, что современные компиляторы упростят код очень эффективно. При этом код интегрирующей функции почти не поменялся, и она по-прежнему может переварить и std::vector.
А где гибкость? На самом деле мы теперь можем написать любую функцию в операторе ++. То есть такой подход позволяет, по сути, вместо одного числового параметра передать функцию. Генерируемая "на лету" сетка может быть любой, и мы к тому же (наверное) не теряем в производительности. Однако писать каждый раз новый lazy_container только ради того, чтобы как-то по-новому исказить сетку совсем не хочется (это же целых 27 строк!). Конечно, можно функцию, отвечающую за генерацию сетки, сделать параметром нашей интегрирующей функции, и lazy_container тоже куда-нибудь засунуть, то есть, простите, инкапсулировать.
Вы спросите — тогда что-то опять будет не так? Да! Во-первых, нужно будет отдельно передавать число точек для интегрирования, что может спровоцировать ошибку. Во-вторых, созданный неstанdартный велосипед придётся кому-то поддерживать и, возможно, развивать. Например, сможете сходу представить, как при таком подходе сочинить комбинатор для функций, стоящих в операторе ++?
C++ более 30 лет. Многие в таком возрасте уже заводят детей, а у C++ нет даже стандартных ленивых контейнеров/итераторов. Кошмар! Но всё (в смысле итераторов, а не детей) изменится уже в следующем году — в стандарт (возможно, частично) войдёт библиотека range-v3, которую уже несколько лет разрабатывает Эрик Ниблер. Воспользуемся трудами его плодов. Код скажет всё сам за себя:
#include <range/v3/view/iota.hpp>
#include <range/v3/view/transform.hpp>
//...
auto t_nodes = ranges::v3::iota_view(0, n_fixed)
| ranges::v3::views::transform(
[](long long i){ return dt_fixed * static_cast<double>(i); }
);
double res = integrate(t_nodes);Интегрирующая функция осталась прежней. То есть всего 3 строчки на решение нашей проблемы! Здесь iota_view(0, n) генерирует ленивый интервал (range, объект, который инкапсулирует обобщённые begin и end; ленивый range — это view), который при итерировании на каждом шаге вычисляет следующее число в диапазоне [0, n). Забавно, что название ? (греческая буква йота) отсылает на целых 50 лет назад, к языку APL. Палка | позволяет писать цепочки (pipelines) модификаторов интервала, а transform, собственно, и является таким модификатором, который с помощью простой лямбда-функции превращает последовательность целых чисел в ряд . Всё просто, как в сказке Haskell.
А как всё-таки сделать переменный шаг? Всё так же просто:
В качестве фиксированного шага мы брали десятую часть периода нашей функции вблизи верхнего предела интегрирования . Теперь шаг будет переменный: можно заметить, что если взять , (где — общее число точек), то шаг будет , что составляет десятую часть периода интегрируемой функции при данном , если . Остаётся "подшить" это к какому-нибудь разумному разбиению при малых значениях .
#include <range/v3/view/drop.hpp>
#include <range/v3/view/iota.hpp>
#include <range/v3/view/transform.hpp>
//...
// trapezoidal rule of integration; step size is not fixed
template <typename T>
double integrate(T t_nodes) {
double acc = 0;
double t_prev = *(t_nodes.begin());
double f_prev = f(t_prev);
for (auto t: t_nodes | ranges::v3::views::drop(1)) {
double f_curr = f(t);
acc += 0.5 * (t - t_prev) * (f_curr + f_prev);
t_prev = t;
f_prev = f_curr;
}
return acc;
}
//...
auto step_f = [](long long i) {
if (static_cast<double>(i) <= 1 / a) {
return pow(2 * M_PI, 1/3.0) * a * static_cast<double>(i);
} else {
return tau * pow(static_cast<double>(i) / static_cast<double>(n), 1/3.0);
}
};
auto t_nodes = ranges::v3::iota_view(0, n)
| ranges::v3::views::transform(step_f);
double res = integrate(t_nodes);Внимательный читатель заметил, что в нашем примере переменный шаг позволил уменьшить число точек сетки в три раза, при этом дополнительно возникают заметные расходы на вычисление . Но если мы возьмём другую , число точек может измениться гораздо сильнее… (но здесь автору уже становится лень).
Итак, тайминги
У нас есть такие варианты:
- v1 — простой цикл
- v2 — лежат в
std::vector - v3 — самодельный
lazy_containerс самодельным итератором - v4 — интервалы из C++20 (ranges)
- v5 — снова ranges, но только здесь метод трапеций написан с использованием переменного шага
Вот что получается (в секундах) для , для g++ 8.3.0 и clang++ 8.0.0 на Intel® Xeon® CPU® X5550 (число шагов около , кроме v5, где шагов в три раза меньше (результат вычислений всеми методами отличается от двойки не более, чем на 0.07):
| v1 | v2 | v3 | v4 | v5 | |
| g++ | 4.7 | 6.7 | 4.6 | 3.7 | 4.3 |
| clang++ | 5.0 | 7.2 | 4.6 | 4.8 | 4.1 |
g++ -O3 -ffast-math -std=c++2a -Wall -Wpedantic -I range-v3/include
clang++ -Ofast -std=c++2a -Wall -Wpedantic -I range-v3/include
В общем, муха по полю пошла, муха денежку нашла!
Кому-то это может быть важно
| v1 | v2 | v3 | v4 | v5 | |
| g++ | 5.9 | 17.8 | 7.2 | 33.6 | 14.3 |
Итог
Даже в очень простой задаче интервалы (ranges) оказались очень полезными: вместо кода с самодельными итераторами на 20+ строк мы написали 3 строки, при этом не имея проблем ни с читаемостью кода, ни с его производительностью.
Конечно, если бы нам была нужна (за)предельная производительность в этих тестах, мы должны были бы выжать максимум из процессора и из памяти, написав параллельный код (или написать версию под OpenCL)… Также я понятия не имею, что будет, если писать очень длинные цепочки модификаторов. Легко ли отлаживать и читать сообщения компилятора при использовании ranges в сложных проектах. Увеличится ли время компиляции. Надеюсь, кто-нибудь когда-нибудь напишет и про это статью.
Когда я писал эти тесты, я сам не знал, что получится. Теперь знаю — ranges однозначно заслужили того, чтобы их протестировать в реальном проекте, в тех условиях, в которых вы предполагаете их использовать.
Ушёл на базар покупать самовар.
Полезные ссылки
Документация и примеры использования v3
списки в haskell, для сравнения
Благодарности
Спасибо fadey, что помог с написанием этого всего!
P.S.
Надеюсь, кто-нибудь прокомментирует вот такие странности: i) Если взять в 10 раз меньший интервал интегрирования, то на моём Xeon пример v2 оказывается на 10% быстрее, чем v1, а v4 в три раза быстрее, чем v1. ii) Интеловский компилятор (icc 2019) иногда в этих примерах делает код, который оказывается в два раза быстрее, чем скомпилированный g++. Векторизация виновата? Можно g++ заставить делать так же?
Комментарии (74)

picul
30.10.2019 18:07Ну или можно сравнить с весьма компактным вариантом, который не пытается эмулировать контейнеры там, где они не нужны:
Кодtemplate <typename T> double integrate(T generator) { double acc = 0; double t; while(generator(t)) { acc += dt_fixed * f(t); } acc -= 0.5 * dt_fixed * f(0); acc -= 0.5 * dt_fixed * f(tau); return acc; } long long int i = 0; double res = integrate( [&i, n_nodes](double& t) { t = static_cast<double>(i); ++i; return i < n_nodes; } );
271828 Автор
31.10.2019 10:11Тоже хороший вариант, добавил его в репозиторий в виде v6.cpp. Выполняется около 4.5 с при компиляции и g++, и clang++.
Меня в нём смущает висячаяlong long i, чтоб её убрать, надо делать генератор объектом класса (который хранит i), писать конструкторы и в итоге получится не сильно короче, чем с итераторами. Хотя этот вариант в целом попроще.picul
31.10.2019 13:37Чтоб убрать висячий каунтер, надо всего то обернуть код в {}, в крайнем случае можно вынести в отдельную функцию. Без обид, но опять создаете проблемы на пустом месте.
271828 Автор
31.10.2019 14:23Мне кажется, не на пустом. Представьте, вам справку писать придётся по этому коду. И вы напишете "Вот так это нужно использовать… И не забываем оборачивать в {}!"? Не самый это изящный вариант. И функции нечистые я не люблю. А с итератором сразу понятно, что внутри грязная функция спряталась.
picul
31.10.2019 14:59Это можно использовать как угодно, главное знать что должен из себя представлять генератор (именно об этом в справке и напишут). Если так изящнее — ОК, пусть будет изящнее. Просто нужно учитывать, что часто впоследствии код читают другие люди, и для них важнее быстро разобраться, чем всячески избегать нечистых функций.

mobi
30.10.2019 20:07А ключик -march=native в g++ влияет на производительность?
khim
31.10.2019 00:17-2Скорее на воспроизводимость. Он означает «включи те фичи, которые вот тут, на этом конкретном процессоре, имеют смысл».
Отличная штука для того, чтобы собрать что-nj для себя и использовать, категорически недопустима для замеров скорости.
Потому что фиг его знает что именно у вас там в CPU есть — это ж не только от модели CPU может зависеть, некоторые фичи могут и от версии операционки или BIOS зависеть!
271828 Автор
31.10.2019 09:10Как ни странно, но для моего Xeon-а — нет, не влияет. Только для clang++ v1 стал на 0.5 с быстрее с ним, для остальных всё осталось в пределах +- 0.1-0.2 с.

Refridgerator
31.10.2019 05:52Будем интегрировать методом трапеций вот такую функцию:
А какой в этом смысл, если эта функция прекрасно интегрируется аналитически? На что у меня потребовалось меньше времени, чем на прочтение следующего абзаца.271828 Автор
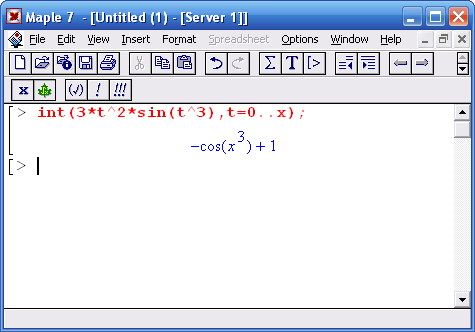
31.10.2019 08:51Конечно, тестировать производительность лучше всего на примере, для которого заранее известен ответ, иначе можно написать очень быстрый, но неправильный код. Аналитический ответ, кстати, есть в тексте статьи.
Refridgerator
31.10.2019 09:11Для заранее известного ответа можно использовать системы компьютерной алгебры, которые с произвольной точностью считать умеют. И метод трапеций очевидно не так быстро сходится, по сравнению с другими — тоже не самый лучший выбор. Закономерно возникает сомнение, что и дальше по тексту у вас будет оптимальное решение.

devpony
31.10.2019 11:27Статья не про численное интегрирование. И не про интегрирование вообще. Она даже не в хабе «Математика». Статья про новую фишку C++20.
Автор подобрал максимально простой пример, в котором эту фишку можно использовать, понятный большинству читателей. Вместо интегрирования методом трапеций тут могло быть вообще всё что угодно, использующее цикл с переменным шагом.
Refridgerator
31.10.2019 17:01-4Я понимаю, что математика нужна не каждому программисту, но автор всё-таки позиционирует себя как «физик-теоретик», а от физика-теоретика ожидаешь содержания чуть более интересного, чем школьные примеры. Статья бы только выиграла, будь в качестве примера хотя бы эллиптический интеграл. И ещё больше бы выиграла, если бы код из неё можно было бы взять и использовать «как есть» в реальных задачах.
khim
31.10.2019 17:25Статья бы только выиграла, будь в качестве примера хотя бы эллиптический интеграл.
Статья бы, конечно, проиграла, если бы в качестве примера был взят эллиптический интеграл.
Потому что важно не то, что умеет автор стартьи (он же не для себя статью пишет!), важно что знают и умеют читатели.
Так вот про интегралы и как их считать — рассказывается даже в школьной программе, а вот эллиптических — там уже нет.
Если ваша задача рассказать про фишки C++, а не про математику кривых — то лучше, чтобы эллиптических интегралов в статье бы не было.
И ещё больше бы выиграла, если бы код из неё можно было бы взять и использовать «как есть» в реальных задачах.
Возможно, но тут проблема курицы и яйца: пока ranges не в релизе — их мало кто использует, а когда будет набрана статистика использования — писать «вводную» статью типа обсуждаемой… уже поздновато.Refridgerator
31.10.2019 18:36-1Статья бы, конечно, проиграла, если бы в качестве примера был взят эллиптический интеграл.
То есть, если бы автор начал статью не с «найти интеграл функции ...» а с «посчитать длину кривой» было бы хуже?
Потому что важно не то, что умеет автор статьи (он же не для себя статью пишет!), важно что знают и умеют читатели.
Если статья о том, что все и так знают, то какой вообще смысл её читать?khim
31.10.2019 19:13-1Если статья о том, что все и так знают, то какой вообще смысл её читать?
Естественно статья должна включать что-то, чего люди не знают. Но все «посторонние» вещи — желательно свести к минимуму.
То есть, если бы автор начал статью не с «найти интеграл функции ...» а с «посчитать длину кривой» было бы хуже?
Да, потому что понять — откуда там вообще берутся проблемы гораздо сложнее.
devpony
01.11.2019 14:12Если статья о том, что все и так знают, то какой вообще смысл её читать?
Статья не об интегралах, а о ranges в C++20. Интегралы тут вообще сбоку, как пример.

playermet
31.10.2019 19:55-1Нет уж, спасибо, как-то не хочется видеть обозрение трехстрочных фич языка на примерах с постшкольным матаном (я в курсе про термин, если что, поправлять не надо).
Refridgerator
01.11.2019 05:35-2Извлечение корня изучают ещё в школе и даже раньше, чем тригонометрию. Это операция, обратная возведению в квадрат. Что страшного в корне, я упорно не понимаю.
Математику за то и не любят, что её дают на примерах, отдалённых от реальности; и многие вещи, звучащие страшно и непонятно, на деле оказываются простыми и очевидными — если их излагать не как «вешь в себе», а применительно к реальным задачам.playermet
01.11.2019 11:06+2Математику за то и не любят, что её дают на примерах, отдалённых от реальности
Это можно ставить в упрек статьям по математике, но никак не статьям в которых сама математика — пример использования чего-то.
З.Ы. Мое сообщение выше действительно стоило плевка в карму? Серьезно?Refridgerator
01.11.2019 15:55-2Я не знаю, моя карма пострадала сильно больше, если вам станет от этого легче.
Refridgerator
03.11.2019 04:51Я вам поставил (а не «плюнул») минус не столько за содержание, сколько за мотивацию. Вы шли мимо, увидели, что кого-то сильно минусуют, и решили попинать его за компанию, ничем при этом не рискуя. Это низко и недостойно. Самоутверждаются за чужой счёт только те, кому утвердиться больше нечем — у вас нет ни статей, ни сколько-нибудь значимых комментариев в обозримый промежуток времени.
По содержанию. Изображая из себя знающего человека вы прокололись, назвав эллиптический интеграл «термином» — в то время как это никакой не термин, а функция. По основной теме статьи — ranges — вы также ничего сказать не смогли.
Вы никак не подтвердили свою квалификацию, чтобы позволить себе подобного рода высказывания. Я считаю, что вам и подобным вам нет места на Хабре. Ваше последующее прилюдное нытьё по поводу потери единицы кармы лишь подтвердило это.
Ну а если другим членам сообщества, минусующим мои комментарии, ваши более интересны — имеют на то полное право.
P.S. Чтобы читать о фичах языка без матана и прочей шелухи, нужно читать просто документацию.
nckma
31.10.2019 09:17for(long long i = 1; i < n_fixed - 1; ++i) {
double t = dt_fixed * static_cast(i);
acc += dt_fixed * f(t);
}
Чего-то я туплю, но почему у вас этот подсчет называется методом трапеции?
271828 Автор
31.10.2019 09:29Тем не менее в примерах мы почти до самого конца "забудем" про настоящий метод трапеций и для простоты будем рассматривать его версию с постоянным шагом, держа при этом в голове то, что сетка может быть произвольной.
Меня интересовал вопрос — как сетку в интегрирующую функцию передать, а не как именно написать метод трапеций для этой функции. По сути здесь речь об удобстве написания/поддержки без потери производительности. Честный метод трапеций, с переменным шагом там есть в конце (в репозитории — файл v5.cpp).
nckma
31.10.2019 09:51Честно говоря я не про шаг спрашивал…
Мне всегда казалось что площать трапеции вычисляется как-то так:
s=(f(t0)+f(t1))*h/2
где t1=t0+delta_t271828 Автор
31.10.2019 09:57Это и написано в v5.cpp. Если же t_{i+1} — t_i = const (то есть не зависит от i), то из метода трапеций получается то, что написано в v1-v4. Просто формулу трапеций так можно преобразовать в случае постоянного шага. Вычислений при этом меньше, скорость — выше.
khim
31.10.2019 14:25Я думаю претензия была просто в том, что не стоит метод правых прямоугольников назвывать методом трапеции.
Хотя было бы, наверное, проще так и написать, чем пытаться «эзоповым языком» на этот вариант вывести.271828 Автор
31.10.2019 15:08Метод правых/левых прямоугольников менее точен, чем метод трапеций. Я же говорил про то, что википедия зовёт формулой Котеса.
khim
31.10.2019 15:39Вот только формула Котеса опирается на тот факт, что у нас трапеции имеют одинаковую ширину.
А вы проде как шаг менять собрались…
hhba
31.10.2019 15:06Общности в таком подходе — хоть отбавляй, а что с производительностью? С потреблением памяти? Если раньше у нас всё суммировалось на процессоре, то теперь приходится сначала заполнить участок памяти, а потом читать из него. А общение с памятью — довольно медленная вещь.
Хм, ну подождите, если ставится задача «делаем универсальную функцию интегрирования трапециями, в которую снаружи передается набор узлов», то без трат памяти не обойтись. Кто-то где-то в другом месте этот набор генерирует и так или иначе записывает его в память, чтобы нам передать. Этот генератор может быть разным по устройству, не обязательно компилируемым вместе с функцией интегрирования, возможно набор узлов вообще по почте приходит.
К слову, если ваш второй пример запустить, то (количество узлов я взял поменьше, а то у меня чего-то bad alloc вылезал) результат таков: 1.3 секунды занимает заполнение вектора и 3.8 секунды собственно вычисление интеграла, отсюда и берется «худший результат из сравниваемых». Да и вообще сравнение получается немного странным:
1) Постоянный шаг, вычисление аргумента «по месту».
2) Постоянный шаг, вычисление аргумента где-то снаружи, но с учетом времени этого вычисления (!?).
3) 4) Постоянный шаг, вычисление аргумента «по месту» (если я правильно понимаю этот код, простите мое плохое знание С++ и ленивых вычислений).
5) Переменный шаг, вычисление аргумента «по месту».
То есть везде какие-то отличия по сути, что же мы сравниваем?
Но вообще спасибо за статью, узнал новое для себя!
P.S.: Я же верно понимаю, что для варианта 5 теряется совместимость с вектором?271828 Автор
31.10.2019 15:24А почему во всех вариантах вычисление сетки должно учитываться (по времени), а во втором — нет? Так нечестно.
std::vectorплох не только скоростью. Если интегрируемая функция достаточно тяжело вычисляется на каждом шаге, то общение с памятью не будет "бутылочным горлышком, конечно. Но может банально памяти не хватить под этот вектор, например.
5 вариант не потерял совместимость с вектором, просто t_i в вектор нужно положить другие (в смысле другие числа, а тип тот же;vector<double>). Но работает это не быстро (14 секунд в моих условиях, из них 9 на заполнение вектора, из которых можно 1.5 секунды сэкономить, если сделать заранее reserve).
А сравниваем мы и скорость, и удобство, ну и потребление памяти, если хотите.hhba
31.10.2019 16:01А почему во всех вариантах вычисление сетки должно учитываться (по времени), а во втором — нет? Так нечестно
Потому что во всех вариантах это именно вычисление, а во втором — работа с памятью. И в зависимости от свойств системы результат получается разным. Я бы сказал так, что либо второй вариант в вашей статье лишний, либо наоборот — все остальные лишние. И, разумеется, самой идеи рассказать таким образом о ranges это никак не умаляет.
std::vector плох не только скоростью
Конкретно вектор ничем вообще не плох. Плох (или «плох») любой способ формирования набора узлов, который требует промежуточной памяти. А тут уже нет никакого выбора — либо вам без памяти не обойтись (набор получен по сети), либо нет никакого смысла хранить его в памяти (и вычисляем на каждом шаге, любым из предложенных вами способов).
5 вариант не потерял совместимость с вектором
Пардон, но если посмотреть на код в for()?271828 Автор
31.10.2019 23:02Пардон, но если посмотреть на код в for()?
for (auto t: t_nodes | ranges::v3::views::drop(1))работает и в том случае, еслиt_nodesестьvector<double>. О времени для такого варианта я выше и говорил.hhba
01.11.2019 09:27А можете тогда пояснить, что делает ranges::v3::views::drop(1)? А то в документации на сайте Ниблера написано что-то невнятное.
271828 Автор
01.11.2019 12:20Отбрасывает первый элемент и оставляет всё остальное.
Что вот мне совсем не нравится в ranges — очень скудная документация. В примерах у Ниблера drop даже не встречается. Но есть take — это, наоборот, взять n первых элементов, отбросив всё остальное. И оба они ленивые, то есть можно работать с бесконечной последовательностью, а уж потом сделать take, например.hhba
01.11.2019 12:57Вот, значит я правильно понял описание. И тогда единственный смысл этой операции — отбросить первый узел (который до цикла был взять через begin). При этом весь код до вызова integrate() может быть удален, насколько я понимаю (само собой потребуется альтернативный код для заполнения вектора). Но тогда непонятно, почему вдруг время так выросло по сравнению с вариантом 2.
271828 Автор
01.11.2019 13:45Там основное время — заполнение вектора, а поскольку шаг в этом примере переменный, то функция step_f, вычисляющая t_i, уже не такая простая. Я подозреваю, что всё дело в ней. Сами же integrate в v2 и v5 тоже разные, честная версия из v5 заметно медленнее версии из v2, в которой используется тот факт, что шаги одинаковые. Но шагов в v5 меньше, чем в v2. В общем, довольно проблематично их сравнивать.
hhba
01.11.2019 14:32Да, наверное дело в этом.
Ну и в очередной раз мы говорим о проводимых сравнениях. :)
Насчет модификаторов интервала, я не совсем понял (и сходу не нагуглил, точнее нагуглил нечто обратно противоположное) — это что-то общее для всех контейнеров С++, или только для интервалов?hhba
02.11.2019 14:22Прочитал наконец статью по ссылке — элементы подпространства ::view и есть по сути модификаторы для любых контейнеров.
khim
31.10.2019 15:40Хм, ну подождите, если ставится задача «делаем универсальную функцию интегрирования трапециями, в которую снаружи передается набор узлов», то без трат памяти не обойтись.
Не обязательно. Если снаружи передаётся короутина, то она может порождать набор «лениво».hhba
31.10.2019 15:53Если корутина — то да, а если именно массив значений, полученный по сети?
khim
31.10.2019 17:16Если это массив значений, то никакие ranges не нужны.
hhba
31.10.2019 17:21+1… и это та мысль, которую я хотел высказать, но боялся )))
А если стоит задача генерировать узлы «на месте», то можно генерировать их прямо в теле функции, а можно передать указатель на функцию-генератор (привет Си), а можно корутину, или вот ranges, или вообще что угодно еще, с примерно одинаковым результатом.khim
31.10.2019 17:28вообще что угодно еще, с примерно одинаковым результатом.
Не совсем. Ranges — это некоторая абстракция, которая легко получается из корутин или генераторов.
Вообще мне кажется на практике ragnges, реализованные через корутины могут оказаться самым распространённым вариантом…

0xd34df00d
31.10.2019 21:31а можно передать указатель на функцию-генератор (привет Си)
И ещё там войд-звёздочка где-нибудь, чтобы функция-генератор могла быть с состоянием, и ещё пару функций для создания и освобождения этого стейта...
Зато без темплейтов, ага.
hhba
01.11.2019 09:59-1Вообще я не призывал обойтись без темплейтов, просто приводил альтернативные примеры получения (не хранения) набора узлов «на месте».
Зачем войд-звездочка и пара функций? Вот вам без звездочек и пары функций (сказал он с хитрой улыбкой):
#include <iostream> double integrate(int generator()) { for(int i {}; i < 42; i++) { std::cout << 1.1 * static_cast<double>(generator()) << std::endl; } return 0.0; } int Generator() { static int count {}; return count++; } int main() { integrate(Generator); return 0; }0xd34df00d
01.11.2019 15:54+1А вы на каждый набор параметров генератора будете писать свою функцию? А запускать вычисления в том же потоке ещё раз с нуля как будете?
hhba
01.11.2019 16:07-1А вы на каждый набор параметров генератора будете писать свою функцию?
Все зависит от обстоятельств. Если генератор в принципе должен быть параметризован (что не факт, и, кстати, выше это требование не предъявлялось), то это можно сделать разными способами, а можно не суметь сделать вообще.
А запускать вычисления в том же потоке ещё раз с нуля как будете?
Тут конечно не поспоришь, в приведенном выше примере придется мутить несколько более сложный генератор (и конечно в стиле "о Боже, что это").0xd34df00d
01.11.2019 16:22+1И это я ещё не спрашивал про многопоточность с пулом обработчиков, где
thread_localне прокатит.hhba
01.11.2019 16:47Эм, не совсем понял, что вы имеете в виду в привязке к конкретному примеру — интегрировать в несколько потоков? Или в каждом из потоков считать свой интеграл, но по одному и тому же генерируемому функцией-генератором набору? Если второе, то thread_local с тем же самым вышеприведенным кодом вполне будет работать, почему нет?
0xd34df00d
01.11.2019 16:55Потому что если у вас что-то сложнее запуска пачки
std::threadруками, то вы не всегда можете гарантировать, что один и тот же кусок вычислений всегда будет выполняться на одном и том же системном потоке.hhba
01.11.2019 17:10Здесь я должен честно признать, что в моих задачах всегда хватало «запуска пачки std::thread руками» (образно выражаясь). Я смутно себе представляю, зачем может потребоваться делать то, о чем вы говорите.
0xd34df00d
01.11.2019 19:05Ну, например, если в процессе работает не только ваш код по вычислению интегралов, и общий параллелизм охота ограничить каким-то фреймворком для управления параллелизмом.
Не, конечно, если нужно просто один раз посчитать интеграл, то это всё не нужно.
hhba
02.11.2019 10:44общий параллелизм охота ограничить каким-то фреймворком для управления параллелизмом
Ну, это тогда надо смотреть, что за фреймворк… Если он действительно ведет себя так, как описано выше, то возможно не только в вычислении интеграла возникнет фатальная проблема.
4e1
31.10.2019 15:21+1Про icc — надо дизасемблировать и тогда сравнивать. Например, он любит анролить и инлайнить поболее gcc/clang.
klirichek
31.10.2019 17:59range что с сеткой, что без неё всё равно остаётся последовательным.
А хотелось бы магии, чтобы для задач вроде подобной сгенерировался такой код, который разбил бы range на subranges, и запустил их в параллель на нескольких ядрах.
Но для этого сами исходники (итератор, который знает свои границы и умеет шагать вперёд) не очень хороши. Ну разве что сделать тестовый прогон без финальных вычислений, и там эти самые границы разметить (собрать таблицу значений итератора), а потом уже выдать каждому потоку/задаче по собственному диапазону/подтаблице. Но это уже не так прямолинейно.
MaxakCh
31.10.2019 23:32Интересно как изменится производительность в V2 вектор заменить на «голый» массив?
P.S.… а v4 в три раза быстрее, чем v1
а вот это совсем странно.
Antervis
скорее «они очень абстрактны потому, что нужны для любого не очень абстрактного кода».
Моя личная претензия к с++20 (даже не к ranges как таковым) — отсутствие генераторов, с помощью которых уже можно было бы выразить и ranges, и корутины.
khim
Чем генераторы от корутин отличаются???
Antervis
корутина — частный случай генератора. И даже если за счет плюсовой шаблонной магии любой генератор можно выразить корутиной, приделать к ним range-like интерфейс всё равно непросто.
khim
Вообще у нормальных людей короутина — это частный случай генератора.
Chaos_Optima
Вы наверно хотели сказать что генератор это частный случай корутин.
Antervis
Генераторы можно делать с помощью корутин, а можно делать и без корутин. А вот корутины с помощью генератора делать это я слабо себе представляю. И да в С++20 корутины же будут. В vs19 их можно включить кстати. Также корутины можно эмулировать по средством потоков или файберов.
Вот например
cpp.sh/8dy27
khim
Выразался очень смутно, но имел в виду то же, что и вы. Собственно как пишет Wikipedia: Generators, also known as semicoroutines, are a special case of (and weaker than) coroutines, in that they always yield control back to the caller (when passing a value back), rather than specifying a coroutine to jump to
Но это у нормальных людей так. У Antervis генераторы явно не такие, как у нормальных людей, раз через них и ranges и корутины выражаются… потому и возник вопрос: а что он, собственно, под словом «геренатор» подразумевает?
Конечно та же Wikipedia рассказывает как корутины эмулировать на генераторах… но тут надо понимать, что эмулировать можно вообще всё на почти всём (главное вначале машину Тьюринга построить, а дальше задача сводится к предыдущей), вопрос же не в этом.
Antervis
и в gcc есть ветка с корутинами.
khim
На самом деле с короутинами история STL повторяется. Если посмотреть на существующую реализацию, то память уже не выделяется, но какие-то «следы» в коде остаются… думаю со времением и их изведут.
Почему нет? В языке это ничто не запрещает, а компиляторы, я думаю, подтянутся…
Осталось понять чем это от существующего предложения отличается…
А в clang не нужна ветка — там это опция компилятора.
Antervis
строчка 5 асма — call operator new.
khim
Смтрю в книгу — вижу фигу. А ничего что эта строчка при работе программы (то есть функии
barв вашем случае) никогда не вызывается? От выделения памяти все компиляторы уже давно избавились, а вот оптимизации… да, «провисают» пока. Ну ничего — лет через 10 поправят.0xd34df00d
У нормальных людей это всё частный случай ленивых списков.
По крайней мере, в значительной части случаев это всё ведёт к более краткому, выразительному и понятному коду.
khim
Я тоже не понимаю почему — это просто такой факт, который я вижу на практике.