Рано или поздно любому растущему сервису приходится оценивать свои технические возможности. Сколько посетителей мы в силах обслужить? Какова ёмкость (она же capacity) системы? Не добрались ли мы до предела и не упадём ли, если привлечём ещё несколько тысяч пользователей? Сколько дополнительных вычислительных ресурсов заложить в бюджет на следующий год, чтобы соответствовать планам роста?
Ответы можно получить аналитическим путём, адресовав вопросы опытному разработчику/DevOps/SRE/админу. Достоверность оценки зависит от огромного числа факторов: начиная с темпов наполнения системы функциональностью и графа взаимосвязей между компонентами и заканчивая временем, которое эксперт с утра провёл в пробке. Чем сложнее система — тем больше сомнений в адекватности аналитической оценки.
Меня зовут Максим Куприянов, вот уже пять лет я работаю в Яндекс.Маркете. Сегодня я расскажу читателям Хабра, как мы учились оценивать ёмкость наших сервисов и что из этого вышло.
Выходим на позицию
Структура компонентов Маркета довольно сложна, так что мы решили оценить ёмкость только самых крупных и дорогих в масштабировании сервисов. При этом ежедневное количество запросов на них должно явно зависеть от размера дневной аудитории Маркета (daily active users, DAU). Почему именно от DAU? Да потому что аналитики, строя прогнозы на месяцы и годы вперёд, всегда подсчитывают будущий размер аудитории, а мы этим приятным обстоятельством как раз и воспользуемся.
Теперь поговорим о том, без чего точно не построить объективные оценки: о метриках работы сервиса. Если число запросов на сервис зависит от DAU — значит, нам точно понадобится метрика «число запросов в секунду» (requests per second, RPS). Кроме того, чтобы оценить качество работы сервиса, нужно знать процент ошибок и времён ответа (таймингов запросов). Ошибкой будем считать ответ с HTTP-кодом от 500 и выше. Ошибки из диапазона 4xx клиентские и в нормально работающей системе обычно ничего не говорят о проблемах сервиса. Что касается таймингов, то тут у нас принято рассчитывать и хранить 80-й, 95-й, 99-й и 99,9-й перцентили времён ответа, но конкретный набор может немного отличаться от сервиса к сервису.
Итак, у нас есть метрики частоты запросов, процента ошибок и набор перцентилей времени ответа. А ещё мы знаем DAU сервиса на каждый день и на будущие периоды (в виде прогноза). Учитывая, что усреднённые паттерны поведения пользователей не слишком меняются день от дня, допустим следующее: зная RPS в наиболее активный период рабочего дня (пиковое RPS), мы можем спрогнозировать пиковое RPS на будущие периоды, при условии, что у нас есть прогноз DAU. И наоборот: если мы знаем, сколько запросов в секунду выдерживает система, не нарушая договорённости по времени ответа и проценту ошибок, то можем оценить, какой объём аудитории сможем обслужить, т. е. знаем ёмкость системы.
Отлично, мы определились с задачей: зафиксировать в виде договорённостей тайминги ответа и процент ошибок и найти максимальное RPS, которое система выдержит при этих условиях. Как будем решать?
Стреляем по мишени
Вот классический подход к решению задачи: собираем тестовый полигон, берём access-логи системы из production-окружения, делаем из них патроны и обстреливаем систему, повышая частоту запросов, пока полигон не покажет значимую деградацию по таймингам ответа и/или ошибкам. В этот момент останавливаемся и фиксируем частоту запросов (то самое RPS). Победа? Как бы не так. И вот почему:
- тестовый полигон, как правило, не идентичен платформе под сервисом в production-окружении;
- код сервиса меняется каждый день, а то и чаще;
- на нагрузку могут влиять эксперименты;
- запросы пользователей по тяжести зависят от времени суток и прочих условий;
- современные сервисы редко работают изолированно, чаще они делают подзапросы в другие сервисы, и это придётся как-то учитывать.
Улучшение: будем обстреливать сервис автоматически каждый день, собирая патроны из журналов в пиковые часы. А чтобы зря не расходовать ресурсы на тестовый полигон, станем обстреливать интересующие нас компоненты на одном и том же стенде по очереди. Звучит сложно и не решает всех проблем. Но какие ещё есть варианты?
Имитируем реальность
Общая идея такова: скопируем часть трафика с балансеров на площадку, где соберём полный аналог production-окружения в миниатюре и, регулируя объём копируемого трафика, станем искать точку деградации. Идея красивая, и мы в Маркете так делаем, чтобы протестировать новую функциональность и сравнить поведение новых версий со старыми. Мой коллега Евгений в подробностях рассказывал об этом — см. раздел о теневом кластере. Но тут тоже есть очевидные сложности:
- не решается проблема со взаимодействием с внешними компонентами, так как копию всего production-окружения делать очень дорого;
- журналы запросов из системы-зеркала могут случайно смешаться с журналами из production-окружения, а значит, необходимо строить систему с маркировкой зеркального трафика, чтобы потом его можно было найти и почистить;
- запросы обычно зеркалируются либо в полном объёме, либо в процентном отношении от общего числа, а такая точность нас не устраивает (но это можно решить, мы в эту сторону работаем).
В целом имитация production — подход очень хороший и перспективный, но весьма дорогой и с существенными ограничениями.
Тестируем прямо в production
И вот мы наконец добрались до вкусного. Для каждого тестируемого компонента мы поднимаем в production отдельный экземпляр, частоту запросов на который регулируем с балансировщика с высокой точностью. В прошлый раз читатели нас спрашивали: «Хватает ли возможностей HAProxy? Не возникала ли необходимость писать что-то своё?». Так вот, это тот самый редкий случай, когда не хватило и пришлось писать.
При этом есть отдельный сервис, который пристально наблюдает за метриками нагружаемого экземпляра и, когда показатели приближаются к критическим величинам, прикрывает вентиль на балансировщике, уменьшая частоту запросов. Если же сервис работает в допустимых границах — вентиль, наоборот, открывается. Конечно, пороги таймингов и ошибок при нагрузке живого сервиса заметно более консервативны (обычно на 5–10%), чем на полигоне, ведь мы не хотим ухудшать взаимодействие с пользователями. Таким образом, нагружаемый экземпляр всегда работает на пределе возможностей. Эти показатели мы фиксируем. А дальше уже арифметика: мы знаем количество ядер сервиса под нагрузкой на каждый момент, знаем DAU за вчерашний день. Из этого считаем утилизацию, резервы по ёмкости и варианты поведения системы при отключении той или другой локации. Всё это ложится в базу, откуда строятся красивые графики. На основании этих данных при снижении ёмкости ниже заложенного порога срабатывают алерты.
Давайте посмотрим на графики
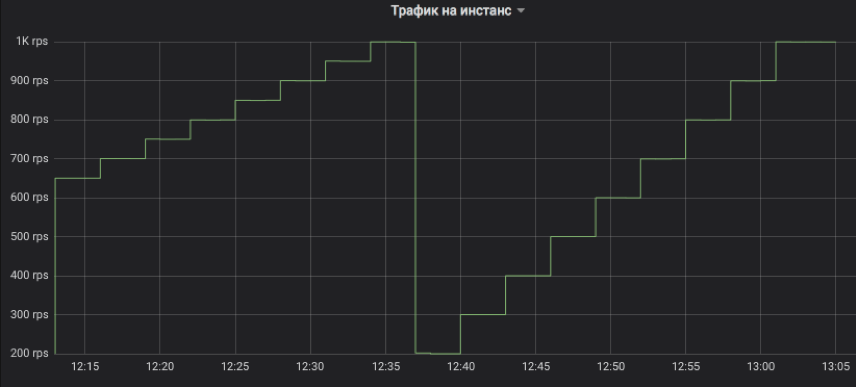
Вот так мы регулируем подачу трафика на тестируемый инстанс. Шаг может быть любым кратным 1 RPS. На графике для иллюстрации смоделирован подъём с трёхминутным интервалом: сначала от 650 до 1K RPS с шагом 50, а потом от 200 до 1K с шагом 100. Напомню, это настоящий пользовательский трафик, на который клиенты получали ответы.
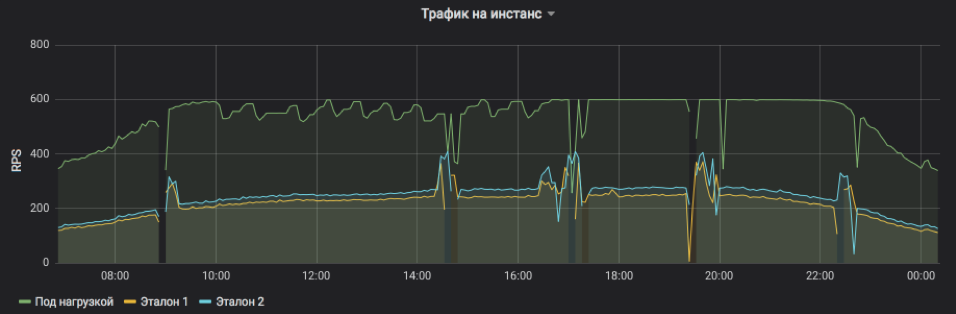
Здесь показано RPS на три инстанса: один под нагрузкой и два контрольных. Для испытуемого искусственно задали верхний предел — 600 RPS. Сервис может и больше, но становится слишком неустойчивым и зависимым от внешних воздействий. Хорошо видно, что в первой половине дня запросы на сервис в среднем более тяжёлые и инстанс не может на приемлемых условиях достичь пиковой ёмкости, но ближе к вечеру всё приходит в норму. Всплески и пропуски на графике — это рестарты инстансов для выкладки релизов и прочих обновлений (все они под балансировкой, никто не пострадал). А ступенчатые корректировки RPS на испытуемом — как раз работа алгоритма, который ищет предел возможностей.

Хорошо видна частота запросов на сервис и нагрузка, которую может выдержать один инстанс.
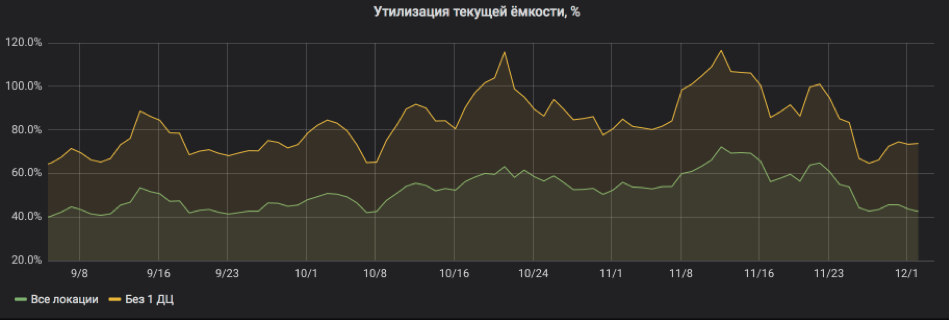
А тут мы пересчитываем всё в проценты утилизации. На графике видно, что сервис был довольно сильно нагружен и при отключении одной из локаций возникли риски уйти за SLA. Но сейчас уже всё в порядке: в сервис добавили ресурсы, утилизация вернулась в приемлемые границы.
Таким образом, нагрузочное тестирование в production позволяет быстро оценить ёмкость системы и спрогнозировать потребление ресурсов на будущие периоды. При этом система фактически не добавляет заметных расходов и можно спокойно работать со stateful-сервисами, так как мы не порождаем новый трафик, а лишь аккуратно перераспределяем тот, что есть. Ну и напоследок: для работы, как правило, не требуется изменять код само?й подопытной системы, что позволяет тестировать даже legacy-приложения.
Рефлексируем
В Маркете эта методика работает уже не первый год, и мы можем поделиться наблюдениями и рекомендациями:
- Рядом с нагружаемым экземпляром обязательно должен быть обычный — контрольный, а лучше пара, так как деградация часто наступает не из-за того, что инстанс перегружен, а из-за общих проблем с сервисом в целом.
- Методика хорошо работает только с теми компонентами, чья нагрузка выше сотни запросов в секунду на локацию. Причина довольно проста: нам нужно нагрузить и тестируемый экземпляр, и один-два контрольных. Если трафика не хватит — мы не достигнем насыщения или не сможем честно сравнивать. А если предельное RPS на инстанс очень мало, то минимальный шаг изменения частоты запросов в 1 RPS может оказаться слишком грубым.
- Фронты и бэкенды лучше тестировать на разных локациях, чтобы артефакты нагрузочного тестирования бэкендов не влияли на оценку ёмкости фронтов.
- Когда мы анализируем тайминги ответов и ищем признаки деградаций, мы обычно берём пять минутных агрегатов и считаем медиану, чтобы не реагировать на случайные всплески.
- Основная причина, по которой падает нагружаемый экземпляр сервиса, — место на диске для файлов-журналов (логов). О нём всегда забывают.
- Запись логов на нагруженный по вводу-выводу диск web-серверов – очень частая причина ухудшения таймингов, даже на SSD. Всегда включайте буферизацию, асинхронную запись, да всё что угодно, лишь бы не висеть в ожидании, пока запись кончится.
- Ночная нагрузка не показательна, так как запросы в среднем более тяжёлые из-за большей доли роботов. Поэтому для оценки ёмкости лучше фиксировать диапазон из условно светлого времени суток, а ночью лишь уменьшать поток запросов, если появились признаки деградации.
- 99,9-й перцентиль таймингов ответа бесполезен для оценки ёмкости, так как гарантии доступности сети редко превышают 99%.
- Заведите таймлайн и фиксируйте релизы сервисов и прочие значимые события. Очень помогает находить то, что привело к снижению ёмкости.
- При детальном разборе причин деградации также полезна трассировка: в каждый запрос на сервис добавляется заголовок-маркер, который проходит от фронта до последнего бэкенда и попадает во все журналы. Так можно проследить весь путь запроса и понять, что приводит к задержкам.
Комментарии (7)

Winnie13
25.12.2019 00:56Ну да, подход использовать продакшеновский трафик для нагрузочного теста компонентов — интересен.
А если на уровень ниже опуститься, базы данных и т.п. — что-нибудь такое же делаете, или
это уже только в тестовом окружении отдельно тестируется?
Если ничего не путаю, то слышал сколько-то лет назад, что dropbox так целиком окружение дублировал на основное и тестовое, и трафик на самом входе копировался туда и туда. Когда тестовое доказывало свою работоспособность, его ставили на место основного, а на основное ставили новую версию всего — и всё повторялось.
GreyTomcat Автор
25.12.2019 10:19А если на уровень ниже опуститься, базы данных и т.п. — что-нибудь такое же делаете, или это уже только в тестовом окружении отдельно тестируется?
Специально больших перекосов нагрузки на production-инстансы баз данных мы не создаем. Но в Яндексе существует практика регулярных учений по отключению локаций, в рамках которых нагрузка с одной локации снимается и автоматически перераспределяется на остальные. В эти моменты все компоненты сервисов и в т.ч. СУБД испытывают повышенную нагрузку и мы внимательно следим за метриками.
Если ничего не путаю, то слышал сколько-то лет назад, что dropbox так целиком окружение дублировал на основное и тестовое, и трафик на самом входе копировался туда и туда. Когда тестовое доказывало свою работоспособность, его ставили на место основного, а на основное ставили новую версию всего — и всё повторялось.
Тоже интересный подход, но полная копия всего окружения, если в нем живет большое количество сервисов – это, пожалуй, довольно дорого.
Еще, кстати говоря, Facebook пользуется для capacity-тестирования live-трафиком, они регулярно и автоматически повышают нагрузку той или иной локации, или кластера и снимают метрики.
otchgol
Как разработчику утилиты нагрузочного тестирования всегда было интересно услышать о реальных проектах!
Несколько странным для меня выглядит ориентация на количество запросов. Совершенно синтетическая характеристика. Понятно, что полностью пользователя симулировать сложно, но сделать примитивные действия по удержанию сессии и группировке нескольких запросов в рамках одной сессии мне кажется очевидным. Мне кажется очевидным, что загрузка первой страницы без авторизации и загрузка персонализированной страницы нагружает сервер по разному. Разные пользователи нарушают отработку кешированием и нагружают сервис иначе. Не это не являлось целью теста?
GreyTomcat Автор
Конечно, все запросы очень разные. Но в рамках данного проекта нам не нужна высокая точность и потому мы используем упрощенную модель, рассматривающую весь поток запросов как однородный, но качественно меняющийся во времени. И этого оказывается достаточно для оценки имеющихся ресурсов и планирования их потребления в будущем.
Отчасти именно из-за этого я отмечал тот факт, что методика подходит лишь для «высоконагруженных» сервисов, т.к. иначе результаты становятся слишком «шумными» на выходе.
otchgol
Вероятно есть ниши, где достаточно простого бомбардирования запросами. Мне не понять. Всегда считал нагрузочное тестирование продолжением функционального. Потому и не понимал почему кто-либо может рассматривать скрипт как средство тестирования. Теперь понятно. Каждый останется при своем мнении. Мне такой тест кажется неполноценным, но тут каждому свое. Маркет вроде выдерживает запросы :)
AKomarov
отнеситесь к этому тесту, как к оценке верхней границы сервиса, которая из-за большого кол-ва пользователей, в последствии домножается на поправочный коэффициент, устанавливаемый опытным путем.
otchgol
Это можно и по единичному запросу интерполировать. Я где-то, кстати, взаправду видел подобную теорию. Мой практический опыт говорит о неприемлимости таких интерполяций. Но каждому свое, очевидно.