
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
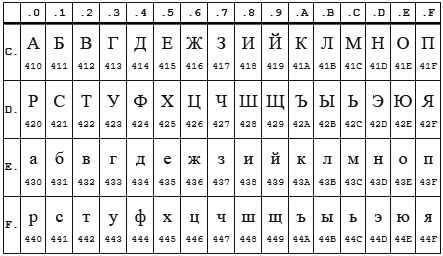
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожёгах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader®.Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
Комментарии (28)

MedicusAmicus
08.01.2020 19:20"Штирлиц"
Пользовался им в студенчестве довольно активно.
До 2001г. версия 4.01
После 2014 — плагин к Notepad++
Переваривал практически все
sotland Автор
08.01.2020 23:49Всё верно, есть ещё Akelpad. Тоже хорошо определяет кодировки. Даже FAR manager вполне неплохо определяет. Это сейчас вообще не проблема.
Только это всё не помогает при опознавании кодировки в программе. И вот тут, оказалось, что для golang готового решения нет. Решения работающего по трём самым популярным кодировкам: 1251, 866 и KOI8-r точно нет.
Grey83
09.01.2020 21:21Жаль только не всегда правильно определяет UTF-8 без BOM (думает, что видит Win1251).
Есть у меня несколько таких файлов, например вот этот (по ссылке исходник плагина в текстовом формате, в строках 11, 345 и 373 вместо 1 символа в кодироке UTF-8 получается 2-3 символа в Win1251).
Интересно, можно это как-то вылечить?

falconandy
08.01.2020 23:52Взглянул на исходники — навскидку несколько замечаний:
В тестах windows-пути прошиты с обратным слэшем и регистронезависимые — на Linux тесты падают. Например, «test_files\\utf8-wbom.txt»
C этой библиотечкой тесты будут выглядеть попроще.
Линтеры выдают несколько предупреждений — орфография, неиспользуемый код, необработанные ошибки.
Проверять на nil конкретно в том месте наверно вообще не стоит — в вашем случае nil можно рассматривать как нарушение контракта, пусть паникует, а проверка на nil возлагается на клиентов метода. Например, после проверки вы используете библиотечный метод bufio.NewReader( r ).Peek(ReadBufSize), который тоже не проверяет на nil и паникует.sotland Автор
09.01.2020 00:11Вот, вот этого я ждал.
1. С тестами. Пожалуй я заставлю себя переделать тесты с файлов на вшитые строки.
Если не сложно, а какие пути должны быть в Linux?
2. Линтеры. Я так понимаю вы прогнали статический анализатор кода? По ссылке нет версии под Windows, а делать через go get они не рекомендуют. Я конечно попробую.
3. Проверка на nil. Конечно я посмотрел исходники стандартной библиотеки, проверки входного параметра там я не нашёл, удивился. Вообще я расчитывал именно из std lib взять методику проверки. Подумал, покурил и решил, нет, то есть да, короче, пусть проверка будет. У меня нет опыта глубокого проектирования, мне сложно определиться на каком уровне чья ответственность будет лежать. Если это нормально (а судя по std lib это действительно нормально), пожалуй уберу.
Только вопрос, а чем плохо оставлять reflect в одном месте для конкретной цели?
ProfBiss
09.01.2020 03:38А чем не устроила проверка на nil? Зачем тащить reflect? Достаточно же if r == nil…
sotland Автор
09.01.2020 20:55Вроде именно по этому play.golang.org/p/NoNN4SvIFkz
Если передаём явный nil, то проверка работает, а вот если раскоментировать строки 23 и 25, то получим ошибку выполнения.
И даже явно присвоив nil (раскоментировать ещё и строку 24) всё равно получим ошибку.
Кажется так.
sotland Автор
09.01.2020 21:42Вроде я разобрался с nil, io.Reader и bufio.NewReader…
Вы правы в главном, проверка на nil ВООБЩЕ не требуется поскольку это делает bufio.NewReader()
falconandy
09.01.2020 09:091. Вместо обратного слэша должен быть прямой и имя файла в коде теста должно полностью совпадать с именем в файловой системе, т.е. например путь
test_files\utf8-wbom.txtдолжен бытьtest_files/utf8-wBOM.txt.
Надо использовать функцию filepath.Join() — это решит проблему со слэшами.
Небольшие файлы для тестов можно затащить в исходники — большие (или например картинки) я бы не стал.
2. Наверно вы невнимательно посмотрели — golangci-lint-1.22.2-windows-amd64.zip
3. Я вообще не припомню, чтобы видел в чьем-то коде такую проверку на nil с помощью reflect — такая проверка меня бы как минимум насторожила, почему сделано так заморочено. Обычной проверки на nil было бы достаточно, тем более что на практике лично я вообще ни разу не сталкивался с этим «оттенком» Go. В Go принято по-возможности обрабатывать nil случаи без возврата ошибки — например, в вашем коде можно было бы вернуть кодировку ASCII без ошибки «input reader is nil», т.е трактовать nil ридер и ридер без данных одинаково. Проверку на EOF лучше писать какerr != io.EOF

nzeemin
09.01.2020 00:32Можно было пойти в исходники Far Manager и взять метод определения кодировки оттуда. Насколько я помню, там используется таблица частоты использования букв кириллицы.
sotland Автор
09.01.2020 22:24Моя версия Far'a (version 3.0 build 5300) автоматически не угадывает текст набранный полность большими буквами в кодировке KOI-8r, и не определяет случай больших букв в кодировке CP1251

gshep
09.01.2020 12:40попробуйте https://github.com/google/compact_enc_det, у нас неплохо для ласов работает =).
А вообще эта задачка идеальна для нейросетей.
Elemir
09.01.2020 22:12Во-первых nil это валидное значение для любого интерфейса, поэтому if r != nil правильная проверка перед вызовом метода Read
sotland Автор
09.01.2020 22:34В моём случае проверка входного интерфеса на nil вообще не требуется, как оказалось это делает сама bufio.NewReader().
Что важно совсем не через reflection, но и не через if r != nil
Если действительно нужно проверить на существование пришедший интерфейс, то проверки на nil мало play.golang.org/p/NoNN4SvIFkzProfBiss
10.01.2020 15:10Похоже на то, что пример высосан из пальца. Строчка 24 это же выстрел в ногу, после этого просто не стоит вызывать функцию. А во всех остальных случаях достаточно проверять на nil внутри.
sotland Автор
10.01.2020 22:44Все примеры высосаны из пальца.
Только вот без строчки b=nil проверка на nil не работает.
Мне кажется или объявить переменную, забыть инициировать, а потом передать в функцию это вполне нормальная ситуация? Это тоже высосано из пальца?ProfBiss
11.01.2020 12:42Строка 24 это дичь, https://play.golang.org/p/kyGC0mVdkbI. Всё работает и так, не нужно просто путать область ответственности.
sotland Автор
11.01.2020 17:20Хорошо, вы правы, вы добавили проверку в метод Get() и предотвратили ошибку. Признаю наверно можно обойтись только проверкой на nil. По совету falconandy уже переделал.
Только я не стану делать так:
func (r *reader) Get() string { if r == nil { return "" } return r.data }
проверять в каждом методе доступность владельца, это перебор.

berez
Ну так это любая библиотека с эвристикой так сделает. Потому что СТП — это непойми что, а «яро» таки похоже на слово.
EndUser
Это и есть слово. Наречие от слова «ярый».
Я бы посоветовал взять идеи punto/kbninja — автор идеи объяснил двум программистам принцип: при встрече нереального буквосочетания считать, что клавиатура неверная. Конечно, после пришлось поставить кучу костылей для аббревиатур и целых IDE… Но таки.
sotland Автор
Да, punto работает, прямо скажем, очень прилично. Мне придётся сильно подумать, что такое реальное, а что нереальное буквосочетание. Сходу идеи не появляются.
Кроме того, задача у punto существенно сложнее. Ему надо на ходу определять кодировку. В моей задаче можно позволить себе проанализировать весь объём данных. Это существенно меняет дело.
Я подумаю над нереальными буквосочетаниями.
berez
Цепи Маркова же.
Берем массив текстов (в известной кодировке, иссессна). Читаем тексты побуквенно и считаем все буквосочетания, скажем, длиной 2-3 буквы. На выходе имеем «профиль» самых частых буквосочетаний. Все, что не входит в сей профиль — нереальные буквосочетания.