В этой заметке я расскажу о паре простых приемов, полезных при работе с данными, не помещающимися в память локальной машины, но все еще слишком мелкими чтобы называться Большими. Следуя англоязычной аналогии (large but not big), будем называть эти данные толстыми. Речь идет о размерах в единицы и десятки гигабайт.
[Дисклеймеръ]Если вы любите SQL все написанное ниже может вызвать в вас яркие, скорее всего, негативные эмоции, в Голландии 49262 Теслы, из них 427 такси, дальше лучше не читайте [/Дисклеймеръ].

Отправной точкой стала статья на хабре с описанием интересного набора данных — полного списка транспортных средств зарегистрированных в Голландии, 14 миллионов строк, всё от седельных тягачей до электровелосипедов со скоростью выше 25 км/ч.
Набор интересный, занимает 7 Гигабайт, скачать можно на сайте ответственной организации.
Попытка загнать данные как есть в пандас чтобы их пофильтровать и почистить окончилась фиаско (господа SQL-гусары, я предупреждал!). Пандас упал от нехватки памяти на десктопе с 8 Гб. Малой кровью вопрос можно решить если вспомнить, что пандас умеет читать csv файлы кусочками умеренного размера. Размер фрагмента в строках определяется параметром chunksize.
Для иллюстрации работы напишем простую функцию делающую запрос и определяющую, сколько всего есть машин Тесла и какая их доля работает в такси. Без фокусов с пофрагментным чтением такой запрос сперва отъедает всю память, потом долго мучается, а под конец обваливает пандас.
C пофрагментным чтением наша функция будет выглядеть примерно так:
Указав вполне разумный миллион строк можно выполнить запрос за 1:46 и использовав 1965 M, памяти на пике. Все цифры для стремного десктопа с чем-то древним, восьмиядерным о 8 Гб памяти и под седьмой виндой.


Если менять chunksize то пиковый расход памяти следует за ним достаточно буквально, время выполнения меняется мало. Для 0.5 М строк запрос занимает 1:44 и 1063 Мб, для 2М 1:53 и 3762 Мб.
Скорость не особо радует, еще меньше радует то, что считывание файла фрагментами заставляет писать адаптированные под это функции, работающие со списками фрагментов, которые надо потом собирать в датафрейм. Также не особо радует сам формат csv, который занимает много места и медленно читается.
Раз уж мы можем загнать данные в пандас можно использовать для хранения гораздо более компактный апачевский формат parquet где и сжатие есть, и, благодаря схеме данных, парсистся при считывании он намного быстрее. И пандас вполне умеет с ним работать. Только вот не умеет читать их фрагментами. Что же делать?
— Давай приколемся, возьмембаян Даск и ускоримся!
Dask ! Заменитель пандаса из коробки умеющий считывать большие файлы, умеющий работать параллельно на нескольких ядрах и использующий ленивые вычисления. К моему удивления про Даск на Хабре находится всего 4 публикации.
Итак, берем даск, загоняем в него исходный csv и с минимальными преобразованиеми перегоняем в паркет. При чтении даск ругается на неоднозначность типов данных в некоторых колонках, поэтому задаем их явно (для чистоты сравнения то же самое сделано для пандаса, время работы выше уже с учетом этого фактора, словарь с dtypes вырезан для наглядности из всех запросов), остальное он сам. Далее для проверки делаем небольшие улучшения в паркете, а именно стараемся привести типы даннных к наиболее компактным, заменяет пару колонок с текстовыми да/нет на булевые, и приводим другие данные к наиболее экономным типам (для числа цилиндров двигателя точно хватит uint8). Сохраняем оптимизированный паркет отдельно и смотрим что же у нас получилось.
Первое что радует при работе с Даском — нам не нужно писать ничего лишнего просто из-за того что у нас толстые данные. Если не обращать внимание на то, что импортируется даск, а не пандас все выглядит также как обработка в пандасе файла на сто строчек (плюс пара декоративных свистелок для профилирования).
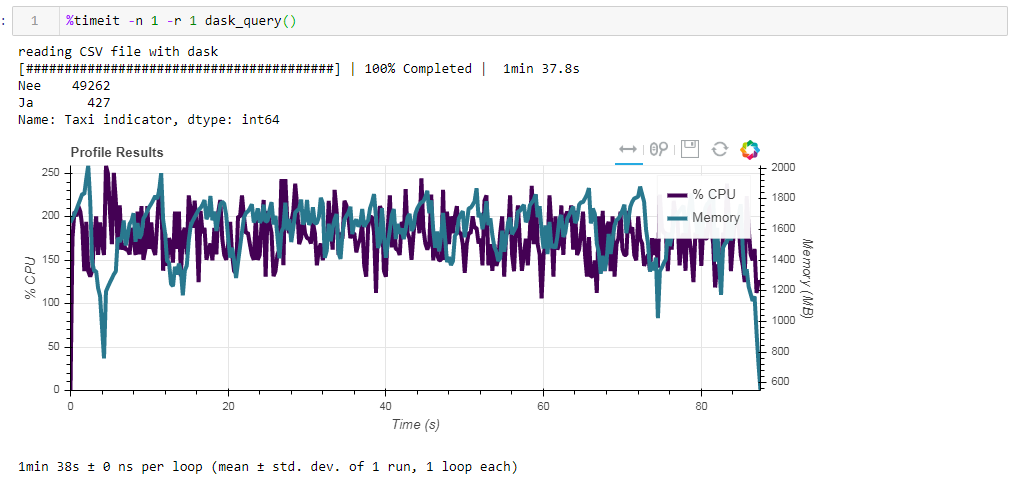
Теперь сравним влияние исходного файла на быстродействие при работе с даском. Первым читаем тот же самый csv файл что и при работе с пандасом. Те же примерно две минуты и два гига памяти (1:38 2096 Мб). Казалось бы, стоило ли в кустах целоваться?
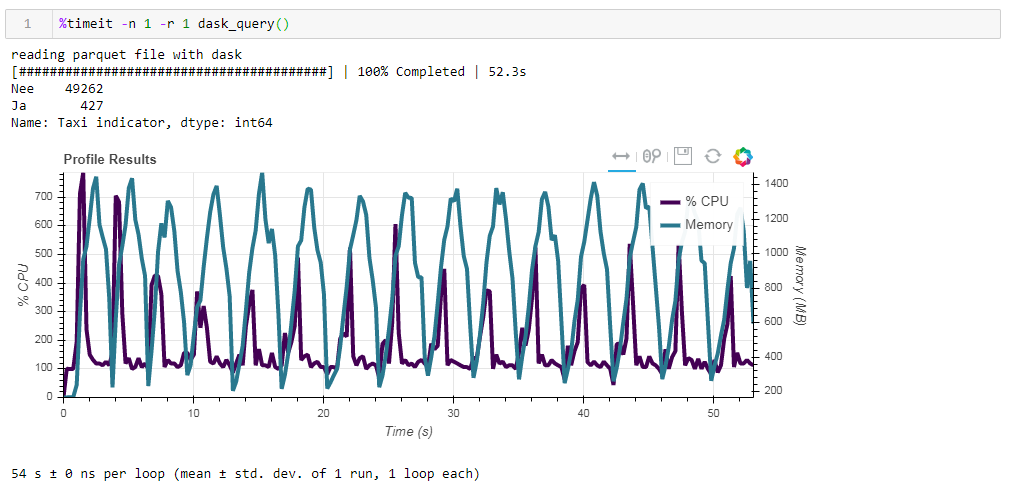
Теперь скармливаем даску неоптимизированный parquet файл. Запрос обработался за примерно 54 секунды потребляя 1388 Мб памяти, а сам файл для запроса теперь в 10 раз меньше (около 700 Мб). Тут уже бонусы видны выпукло. Загрузка CPU в сотни процентов — это распараллеливание на несколько ядер.
Ранее оптимизированный паркет с чуть измененными типами данных в сжатом виде всего на 1 Мб меньше, что говорит о том, что и без подсказок все ужимается достаточно эффективно. Прирост в производительности также не особо существенен. Запрос занимает те же 53 секунды и ест чуть меньше памяти — 1332 Мб.
По итогам наших упражнений можно сказать следующее:
Напоследок о ленивых вычислениях. Одна из особенностей даска в том, что он использует ленивые вычисления, то есть вычисления проводятся не сразу как только они встречаются в коде, а когда они действительно необходимы или когда вы это явно затребовали использовав метод compute. Например, в нашей функции даск не считывает все данные в память, когда мы указываем считать файл. Считывает он их позже, и только те колонки, которые относятся к запросу.
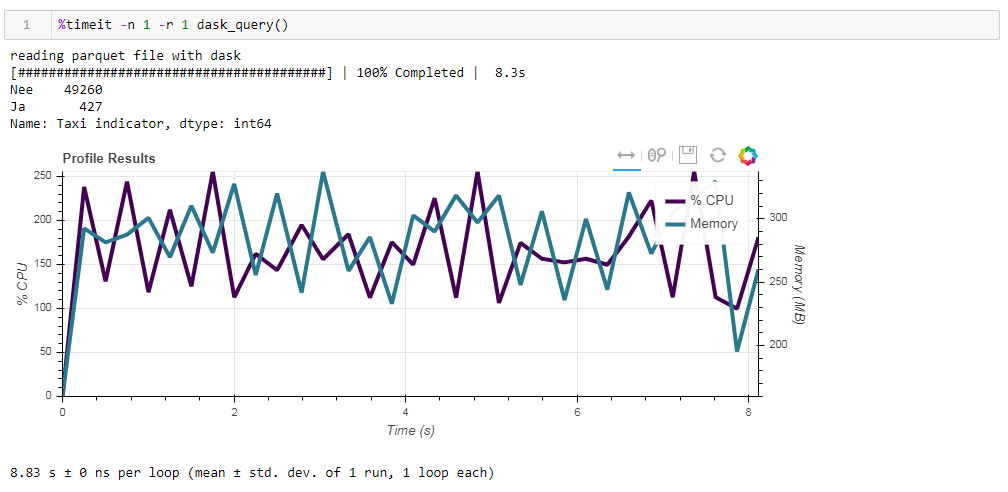
В этом легко убедиться на следующем примере. Берем предварительно отфильтрованный файл, в котором мы оставили только 12 колонок из начальных 64, сжатый паркет занимает 203 Мб. Если запустить на нем наш обычный запрос, то он выполнится за 8.8 секунды, а пиковое использование памяти составит около 300 Мб что соответсвует десятой части от разжатого файла если перегнать его в простой csv.
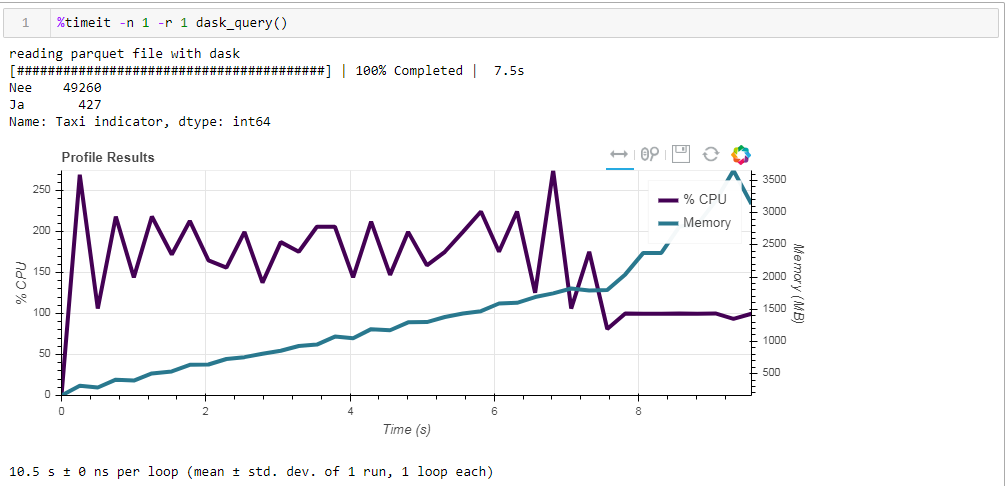
Если же мы в явном виде потребуем считать файл, а потом выполнить запрос, то расход памяти составит почти в 10 раз больше. Изменим незначительно нашу функцию явным требованием чтения файла:
И вот что мы получаем, 10.5 секунд и 3568 Мб памяти (!)
В очередной раз убеждаемся что даск — компетентно справляется со своими задачами сам, и лишний раз лезть к нему с микроменджментом нет особого смысла.
[Дисклеймеръ]Если вы любите SQL все написанное ниже может вызвать в вас яркие, скорее всего, негативные эмоции, в Голландии 49262 Теслы, из них 427 такси, дальше лучше не читайте [/Дисклеймеръ].
Отправной точкой стала статья на хабре с описанием интересного набора данных — полного списка транспортных средств зарегистрированных в Голландии, 14 миллионов строк, всё от седельных тягачей до электровелосипедов со скоростью выше 25 км/ч.
Набор интересный, занимает 7 Гигабайт, скачать можно на сайте ответственной организации.
Попытка загнать данные как есть в пандас чтобы их пофильтровать и почистить окончилась фиаско (господа SQL-гусары, я предупреждал!). Пандас упал от нехватки памяти на десктопе с 8 Гб. Малой кровью вопрос можно решить если вспомнить, что пандас умеет читать csv файлы кусочками умеренного размера. Размер фрагмента в строках определяется параметром chunksize.
Для иллюстрации работы напишем простую функцию делающую запрос и определяющую, сколько всего есть машин Тесла и какая их доля работает в такси. Без фокусов с пофрагментным чтением такой запрос сперва отъедает всю память, потом долго мучается, а под конец обваливает пандас.
C пофрагментным чтением наша функция будет выглядеть примерно так:
def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
Указав вполне разумный миллион строк можно выполнить запрос за 1:46 и использовав 1965 M, памяти на пике. Все цифры для стремного десктопа с чем-то древним, восьмиядерным о 8 Гб памяти и под седьмой виндой.
Если менять chunksize то пиковый расход памяти следует за ним достаточно буквально, время выполнения меняется мало. Для 0.5 М строк запрос занимает 1:44 и 1063 Мб, для 2М 1:53 и 3762 Мб.
Скорость не особо радует, еще меньше радует то, что считывание файла фрагментами заставляет писать адаптированные под это функции, работающие со списками фрагментов, которые надо потом собирать в датафрейм. Также не особо радует сам формат csv, который занимает много места и медленно читается.
Раз уж мы можем загнать данные в пандас можно использовать для хранения гораздо более компактный апачевский формат parquet где и сжатие есть, и, благодаря схеме данных, парсистся при считывании он намного быстрее. И пандас вполне умеет с ним работать. Только вот не умеет читать их фрагментами. Что же делать?
— Давай приколемся, возьмем
Dask ! Заменитель пандаса из коробки умеющий считывать большие файлы, умеющий работать параллельно на нескольких ядрах и использующий ленивые вычисления. К моему удивления про Даск на Хабре находится всего 4 публикации.
Итак, берем даск, загоняем в него исходный csv и с минимальными преобразованиеми перегоняем в паркет. При чтении даск ругается на неоднозначность типов данных в некоторых колонках, поэтому задаем их явно (для чистоты сравнения то же самое сделано для пандаса, время работы выше уже с учетом этого фактора, словарь с dtypes вырезан для наглядности из всех запросов), остальное он сам. Далее для проверки делаем небольшие улучшения в паркете, а именно стараемся привести типы даннных к наиболее компактным, заменяет пару колонок с текстовыми да/нет на булевые, и приводим другие данные к наиболее экономным типам (для числа цилиндров двигателя точно хватит uint8). Сохраняем оптимизированный паркет отдельно и смотрим что же у нас получилось.
Первое что радует при работе с Даском — нам не нужно писать ничего лишнего просто из-за того что у нас толстые данные. Если не обращать внимание на то, что импортируется даск, а не пандас все выглядит также как обработка в пандасе файла на сто строчек (плюс пара декоративных свистелок для профилирования).
def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
Теперь сравним влияние исходного файла на быстродействие при работе с даском. Первым читаем тот же самый csv файл что и при работе с пандасом. Те же примерно две минуты и два гига памяти (1:38 2096 Мб). Казалось бы, стоило ли в кустах целоваться?
Теперь скармливаем даску неоптимизированный parquet файл. Запрос обработался за примерно 54 секунды потребляя 1388 Мб памяти, а сам файл для запроса теперь в 10 раз меньше (около 700 Мб). Тут уже бонусы видны выпукло. Загрузка CPU в сотни процентов — это распараллеливание на несколько ядер.
Ранее оптимизированный паркет с чуть измененными типами данных в сжатом виде всего на 1 Мб меньше, что говорит о том, что и без подсказок все ужимается достаточно эффективно. Прирост в производительности также не особо существенен. Запрос занимает те же 53 секунды и ест чуть меньше памяти — 1332 Мб.
По итогам наших упражнений можно сказать следующее:
- Если ваши данные относятся к «толстым» и вы привычны к пандасу — chunksize поможет пандасу переварить этот объем, скорость будет терпимой.
- Если вам хочется выжать побольше скорости, съэкономить место при хранении и вас не держит использование именно пандаса, то даск с паркетом это неплохая связка.
Напоследок о ленивых вычислениях. Одна из особенностей даска в том, что он использует ленивые вычисления, то есть вычисления проводятся не сразу как только они встречаются в коде, а когда они действительно необходимы или когда вы это явно затребовали использовав метод compute. Например, в нашей функции даск не считывает все данные в память, когда мы указываем считать файл. Считывает он их позже, и только те колонки, которые относятся к запросу.
В этом легко убедиться на следующем примере. Берем предварительно отфильтрованный файл, в котором мы оставили только 12 колонок из начальных 64, сжатый паркет занимает 203 Мб. Если запустить на нем наш обычный запрос, то он выполнится за 8.8 секунды, а пиковое использование памяти составит около 300 Мб что соответсвует десятой части от разжатого файла если перегнать его в простой csv.
Если же мы в явном виде потребуем считать файл, а потом выполнить запрос, то расход памяти составит почти в 10 раз больше. Изменим незначительно нашу функцию явным требованием чтения файла:
def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
#print(model_df.head())
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
И вот что мы получаем, 10.5 секунд и 3568 Мб памяти (!)
В очередной раз убеждаемся что даск — компетентно справляется со своими задачами сам, и лишний раз лезть к нему с микроменджментом нет особого смысла.
StasTukalo
А зачем тогда паркет, если даск умеет большие сам? Для чистоты эксперимента паркет лишний) Ну и как-то не очень понятна страсть к героическому решению всех этих проблем чтения csv-файлов — ну загрузи ты все это хозяйство в бд и тащи оттуда хоть все сразу, хоть по одному. Кому-нибудь в продакшене хоть раз встречался csv? Практически всегда же источником служит бд. Даже в данном примере- этот голландский файл- это выгрузка из базки… хотя… а что если они там в экселе все хранят?! ))
По существу- спасибо, не знал что даск умеет многоядерно.
Matshishkapeu Автор
Паркет скорее для компактного хранения, на 7 Гб немного жаба душит. Некоторые вещи типа машинных логов с редко меняющимися состояниями он ужимает совсем люто.
Про продакшн, и бд. Дисклеймкр про SQL в начале собственно о том и говорит. Если задача делать серьезно, то пандас на костылях тут совсем не к месту. Если надо быстро разворошить палочкой, окинуть взором и бежать к следующей не аналогичной задаче — то вполне сгодится.
v_m_smith
Куда более примечательно, что даск парой строк можно превратить в распределенный кластер с клевым админским дашбордом. Это уже куда веселее
StasTukalo
А можете в меня ссылкой пульнуть на эту тему? Если не сложно…
v_m_smith
Вот небольшое демо от автора dask.distributed https://www.youtube.com/watch?v=N_GqzcuGLCY