
Расскажу Вам свой опыт по созданию приложения, который собирает статистику о печати устройств по SNMP протоколу. Всего более 1000 устройств и опрос выполняется в режиме реального времени, пока печатает принтер. Как это все реализовано вы узнаете из статьи.
Введение
SNMP это стандартный интернет-протокол для управления устройствами в IP-сетях на основе архитектур TCP/UDP.
С помощью SNMP не собрать информацию о пользователе, который отправил на печать файл. Кроме этого, SNMP нельзя использовать для локальных принтеров подключенных по USB.
Чтобы решить эти задачи необходимо создать клиента, который должен собирать информацию и отправлять всю статистику на сервер. В организации было так заведено, что на все клиентские машины устанавливали одинаковые ОС Linux. Соответственно клиент по сбору статистики печати написан в Linux системе, как демон (аналог службы в Windows).
Клиент сбора информации о печати
Клиент сбора печати (написан на Python) выполняет следующие задачи:
- перехватывает сообщения из сервиса печати CUPS
- сохраняет информацию о печати в CSV-файл
- отправляет CSV файлы в папку на сервер по FTP
CSV файл содержит следующие поля:
- Дата и время задания печати
- IP-адрес или доменное имя компьютера, с которого отправлен документ на печать
- IP-адрес или хост устройства печати
- Идентификатор работы (Cups Job ID) — ID задания из сервиса печати CUPS
- Наименование работы — чаще всего это имя файла
- Имя пользователя, отправившего на печать
- Количество страниц
- Размер задания печати (Размер задания в КБ)
- Статус печати (Статус задания)
- Количество копий (Кол-во копий)
- Кол-во копий по файлу задания — служит для более точного определения количества копий;
- Количество страниц по SNMP-протоколу — служит для более точного определения количества страниц
- SNMP доступно — это признак, что устройство должно непрерывно опрашиваться по SNMP-протоколу, пока документ распечатывается
- Счетчик устройства печати на время начала печати (Значение переменной SNMP) — это проверочный счетчик, по которому определяется начало SNMP-опроса сервером
Клиент не имеет GUI-интерфейса, все настройки прописаны в конфигурационном файле
Пример конфигурационного файла:
[main]
# Основной каталог с приложением
app_directory = /opt/printwatcher
# Директория данных. Здесь располагаются данные приложения
# подготовленные к отправке файлы отчётов и служебные файлы)
stat_file_directory = /opt/printwatcher/data
# Файл, в котором хранится внутреннее состояние системы
state_file = /opt/printwatcher/data/state.pickle
# Файл, в котором хранится номер последней выполненной команды
command_state_file = /opt/printwatcher/data/command.state
# Шаблон имени файла отчёта
# Возможные именованные аргументы:
# datetime - дата создания в формате ISO 8601
# random - случайный идентификатор из 8 символов
stat_filename_template = {random}_print_jobs.csv
# Максимальный размер файла отчёта в МБ
# (при превышении начальные строки удаляются)
max_stat_file_size_mb = 10
# Разделитель CSV. Возможные значения: TAB, SPACE, SEMICOLON, COMMA
csv_delimiter = SEMICOLON
# Запускать ли поток наблюдения за очередью
start_service = start
[logging]
# Уровень логирования (DEBUG, INFO, TRACE)
level = DEBUG
# Расположение лога
log_file = /var/log/printwatcher.log
# Временный лог для загрузки после рестарта
restart_log_file = /var/log/printwatcher-restart.log
# Максимальный размер лога
# (при превышении архивируется/удаляется системной утилитой logrotate)
max_log_file_size_mb = 10
[cups]
# Директория, в которой хранятся временные файлы CUPS
spool_directory = /var/spool/cups/
# Удалять временные файлы CUPS по прошествии этого времени
# (в часах)
job_file_lifetime_hours = 48
# Не обновлять в отчёте информацию по задаче по прошествии этого времени
# (в часах)
job_info_lifetime_hours = 48
# Настройки FTP
[ftp]
host = 192.168.1.39
user = ftpuser
password = P@ssw0rd
port = 21
# Задержка перед следующей попыткой при неудачном соединении по FTP
# (в секундах)
connection_retry_seconds = 10
# Максимальная задержка, после которой прекращаются попытки соединения по FTP
# (в секундах)
connection_timeout_seconds = 3600
# Задержка между проверками файла с командами на FTP сервере
# (в секундах)
polling_interval = 30
# Каталог управления агентом на ftp-серевер
management_directory = /management
# Каталог для записи ответов агентом на ftp-серевер
response_directory = /management
# Каталог обновления агента
update_directory = /update
# Каталог в котором ищется конфигурационный файл
data_directory = /data
# Настройки SNMP
[snmp]
# следует ли опрашивать устройство по SNMP
retrieve_snmp_info = false
community = public
oid = 1.3.6.1.2.1.43.10.2.1.4.1.1
port = 161
Итак, клиент написан, теперь нужен сервер, который будет не только собирать информацию со всех клиентов, а также сервер должен отслеживать нештатные ситуации — приостановку печати, отсутствие или замятие бумаги и т.д.
Архитектура сервера сбора информации о печати
Сервер написан на языке C#, СУБД — MSSQL.
- Конфигуратор БД — GUI приложение, позволяющее создать и удалить БД.
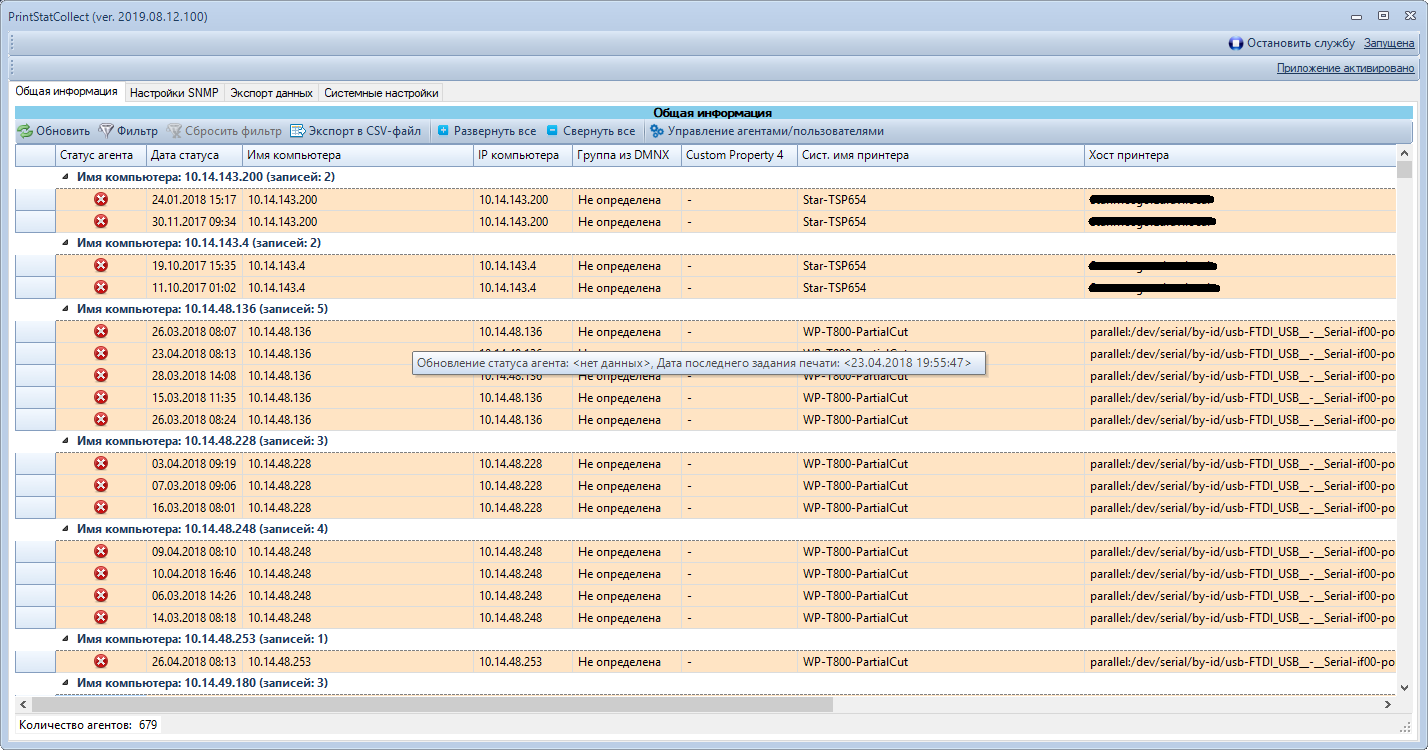
БД максимально нормализована таким образом, чтобы в основной таблице статистики не было текстовых полей для экономии места на диске. - Приложение настройки сбора статистики, это GUI приложение позволяющее внести изменения в БД по SNMP-опросу, настроить OIDы, а также запускать и останавливать службу сбора статистики печати.

- Собственно приложение сбора и обработки статистики (служба Windows)
Сервер сбора информации о печати
Задачи сервера
- следить за очередью печати при обработке большого количества CSV-файлов
- постоянно сканировать папку на наличие CSV файлов
- парсить CSV-файлы и записывать информацию о печати в БД
- сохранение копии CSV-файлов в архив (параметр настраивается) [помогает для отладки]
- удаление CSV-файла после обработки
- ожидать разрешения конфликта
- вычислять выражения над значениями OID'ов
- раз в месяц информация выгружается в архив, а старая информация удаляется
Подробное описание алгоритмов работы внутри сервера
Прежде чем служба будет отслеживать печать в режиме реального времени, необходимо выполнить парсинг старых CSV-файлов (которые накопились, пока не работал сервер) и сохранить информацию в БД. Будем называть этот пункт «первым чтением каталога CSV-файлов», который может помочь быстро собрать статистику старой печати и сохранить в БД.
Затем служба переходит в постоянное отслеживание появления CSV-файлов в папке в отдельном потоке с интервалом 1 сек. Каждый CSV-файл обрабатывается в отдельном потоке.
Если CSV файлов в папке очень много, то на этот случай предусмотрено ограничение количества одновременных потоков чтения файлов, чтобы приложение стабильно работало. При запуске службы в папке может быть очень много CSV-файлов и эти файлы обрабатываются без SNMP-опроса, соответственно на первое чтение каталога установлено отдельное ограничение на количество потоков обработки CSV-файлов (опытным путем было установлено, что количество потоков при первом чтении CSV-файлов должно быть значительно меньше, чем количество потоков после обработки большого количества файлов).
В алгоритме предусмотрено определение IP-адреса по имени устройства и наоборот (определение имени устройства по IP-адресу) с помощью метода System.Net.Dns.GetHostEntry(). В случае отсутствия наличия связи с устройством, метод System.Net.Dns.GetHostEntry() выполняется очень долго, в связи с этим был доработан клиент, который предоставляет эту информацию в CSV. Но на сервере эта проверка осталась и метод System.Net.Dns.GetHostEntry() до сих пор является узким местом.
Сохранение информации в БД
Кроме информации о печати, в БД хранится информация для статистики:
- время начала и окончания SNMP-опроса
- общее количество строк в CSV-файле
- количество строк с включенным SNMP-опросом.
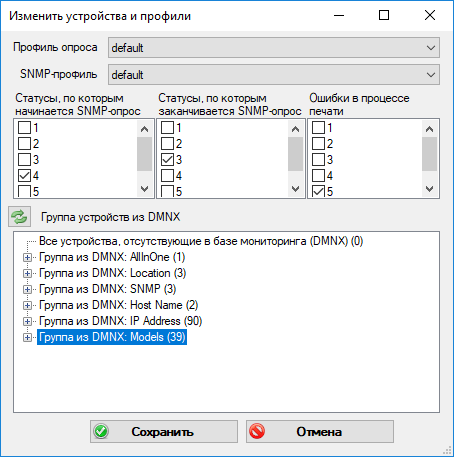
Предусмотрено хранение списка устройств, которые не должны опрашиваться, так называемые исключения, по которым в БД ничего не сохраняется.
После прочтения всего CSV-файла собирается информация о всех заданиях печати в объект List, которые должны быть проконтролированы SNMP-опросом. После чтения CSV-файла, он переносится в архив, если это задано настройками, и затем CSV-файл удаляется.
После того, как CSV-файл полностью прочитан проверяется, что заданы настройки опроса по SNMP-протоколу, затем устройства сортируются по приоритетам:
- Группа по-умолчанию, в которой есть все устройства базы «ricoh_dmnx» — так называется БД системы мониторинга от производителя Ricoh, из которой мы берем список опрашиваемых устройств.
- Устройства, которые есть в базе ricoh_dmnx, но нет в группах
- Устройства, которые есть в базе ricoh_dmnx и есть в группах
- Устройства, которых нет в базе ricoh_dmnx, но есть в базе нашей службы
У каждого устройства создается очередь печати, чтобы в один момент времени SNMP-опрос работал только с одним заданием печати. Таким образом, пока устройство опрашивается по SNMP-протоколу, пользователь может отправить на печать еще какой-нибудь файл и на сервер может поступить новый CSV-файл, который сохраняется сразу в БД, но опрос по нему будет выполняться после того, как закончится печать текущего документа.
При SNMP-опросе отслеживается изменение счетчика печати, статус устройства и признак ошибки устройства во время печати. Время ожидания между SNMP-опросами — 300 мс.
Подводные камни
Алгоритм сервера постоянно совершенствовался, так как возникало много разных ситуаций, при которых неверно считался счетчик. Приведу несколько советов из личного опыта:
1) Не продолжать опрос, пока устройство находится в состоянии ошибки (например: замята бумага)
2) Ошибка принтера может меняться с течением времени, поэтому таймаут SNMP-опроса не должен срабатывать в случае изменения ошибки (например, в принтере закончилась бумага, но после добавления бумаги в лоток статус принтера сменился)
3) Если на устройство печати отправляется несколько заданий одновременно, то при этом счетчик после печати первого задания:
— не изменяет статус
— изменяет счетчик
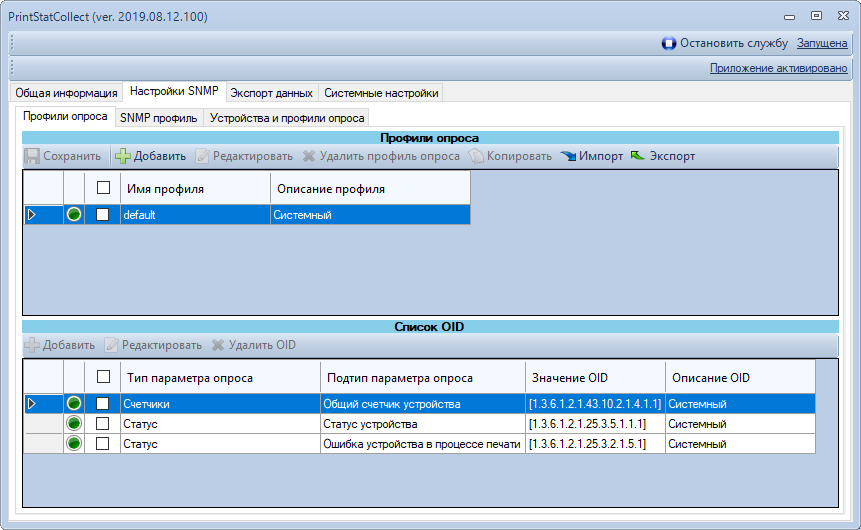
Системные OID-ы устройств печати
На основе анализа этих трех OID'ов было написано мое приложение опроса SNMP-устройств:
1) [1.3.6.1.2.1.43.10.2.1.4.1.1] — Общий счетчик устройства
2) [1.3.6.1.2.1.25.3.5.1.1.1] — Статус устройства
3) [1.3.6.1.2.1.25.3.2.1.5.1] — Ошибка устройства в процессе печати
Отчеты
Отчеты реализованы с помощью SQL Server Reporting Services.
Отчет по сравнению данных печати по месяцам

Печатные задания по пользователям

Сводный отчет по SNMP запросам

Статистика SNMP запросов

Вывод
Рад был поделиться своим опытом в реализации одного из самых сложных своих приложений, которое успешно работает начиная с 2018 года.
Особенностью в реализации проекта сбора печати была еще в том, что я не имел при себе ни одного принтера. Работал через эмулятор, который можно быстро установить и настроить (достаточно иметь MIB-файл настроек устройства печати).
В дальнейшем напишу о том, как было сделано управление агентами печати.
edo1h
сегодня это выглядит несколько странно (мягко говоря)
rrust
а как кошерно? посылать json post со всей таблицей с gzip компрессией?