В начале января Электромузей Москвы объявил открытый отбор экспонатов для участия в выставке Open Museum 2020. В этой заметке я расскажу, как превратил идею когнитивного портрета, о которой я уже писал, в интерактивный экспонат, и как после закрытия музея на карантин этот экспонат стал виртуальным. Под катом — экскурс в Azure Functions, Bot Framework, когнитивные сервисы и обнаружение лиц в UWP-приложениях.

Этот пост является частью инициативы AI April. В течение всего апреля, мои коллеги из Microsoft каждый день пишут интересные статьи на тему AI и машинного обучения. Посмотрите на календарь — вдруг вы найдёте там другие интересующие вас темы. Статьи преимущественно на английском.
Ранее я писал про технику когнитивного портрета, которая позволяет создавать смешанные портреты людей из серии фотографий:
 |
 |
|---|---|
| Ольга, 2019, People Blending | Круговорот людей, 2020, Cognitive Portrait |
Когда был объявлен открытый конкурс работ для предстоящей выставки OpenMuseum, и я сразу же подумал о том, чтобы воплотить идею когнитивного портрета в виде какого-нибудь интерактивного экспоната. Мне пришла в голову идея интерактивного стенда, который захватывал бы фотографии посетителей выставки и превращал их в "усреднённый" когнитивный портрет посетителей.
Поскольку техника когнитивного портрета использует когнитивные сервисы для извлечения ключевых точек лица, экспонату потребуется подключение к интернет. Вообще говоря, "подключенный" к сети экспонат, в котором логика оформлена в виде облачного сервиса, позволит делать намного больше интересного:
- Он сможет записывать в облако фотографии, чтобы затем использовать их для последующей экспозиции.
- Можно получить демографический портрет посетителей выставки, включая распределение по полу, возрасту и эмоциям.
- Отслеживание посетителей позволит нам понимать, сколько времени они проводят перед экспонатом, а также какой эмоциональный эффект имеют те или иные фотографии на посетителей.
- Впоследствии, чтобы задействовать новые техники когнитивного портрета, достаточно будет всего лишь изменить программный код в облаке, при этом экспонат "поменяется" без всякой необходимости личного посещения музея.
Архитектура
С точки зрения архитектуры, экспонат будет состоять из двух частей:
- Клиентское UWP-приложение, работающее на компьютере в музее, с веб-камерой и дисплеем. UWP-приложение может также работать на Raspberry Pi на Windows IoT Core. Клиентское приложение делает следующее:
- Обнаруживает, есть ли перед камерой человек (face detection).
- Если человек стоит относительно неподвижно около секунды — оно делает фотографию и посылает её в облако.
- В ответ на фотографию приложение получает из облака ссылку на изображение, которое оно отображает на экране.
- Облачный сервис, который собственно и определяет логику экспоната и отвечает за рисование когнитивного портрета:
- Получает изображение от клиентского приложения.
- Вызывает когнитивные сервисы для извлечения ключевых точек лица, применяет аффинное преобразование и выравнивает изображение таким образом, чтобы глаза и середина рта были расположены в точках с фиксированными координатами.
- Сохраняет выровненное изображение в Azure Storage.
- Получает несколько последних выровненных изображений, усредняет их для получения портрета, сохраняет его в Azure Storage и возвращает полученную ссылку.
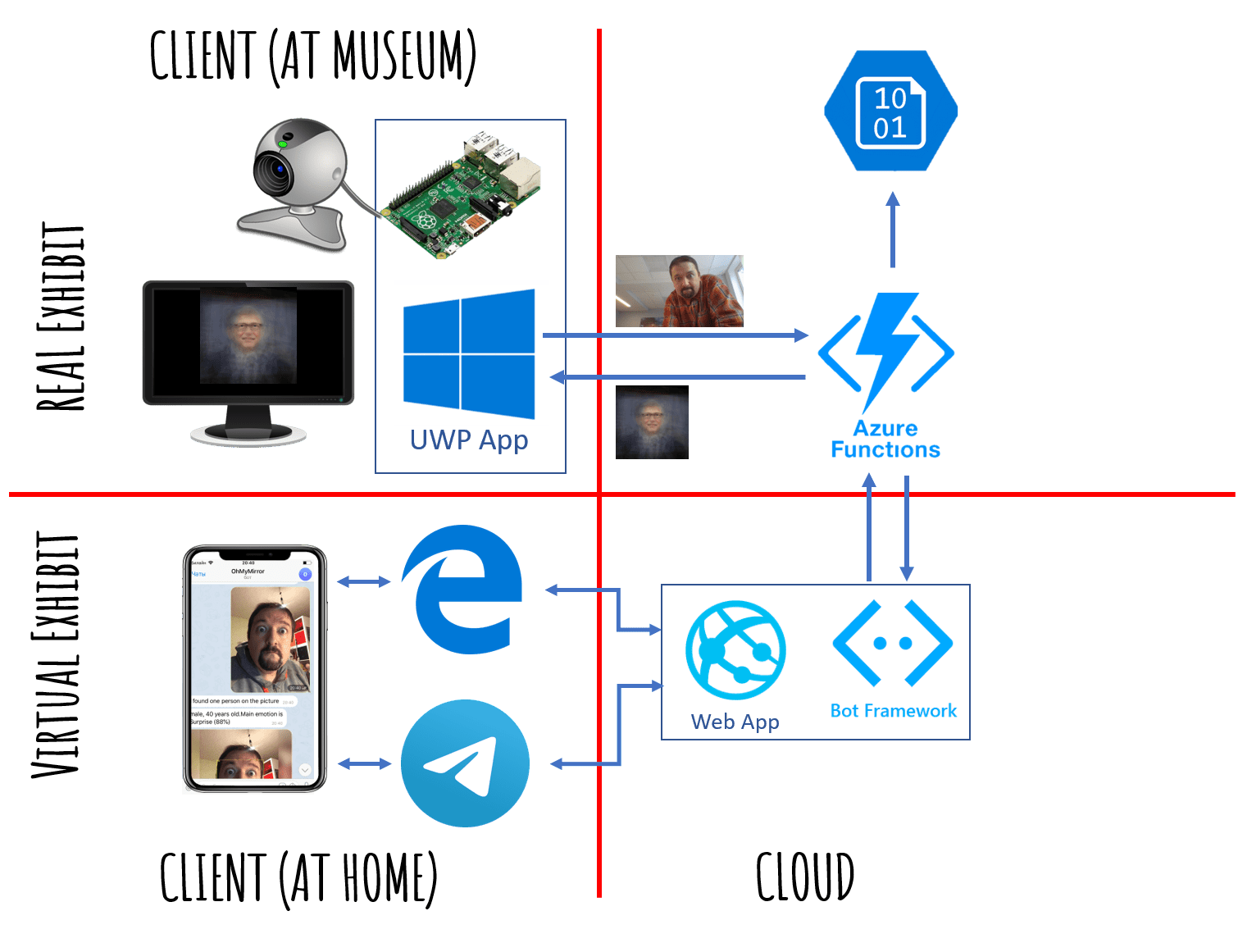
Виртуальный экспонат в условиях самоизоляции
Через несколько недель после открытия выставки, на которой был представлен экспонат, работа музея была временно приостановлена из-за карантина. Однако, учитывая клиент-серверную архитектуру решения, оказалось возможным заменить клиентскую часть приложения, и создать интерактивный музейный бот-экспонат.
Бот доступен а телеграм как @PeopleBlenderBot. Он вызывает тот же самый облачный сервис через REST API, и показывает пользователю полученное изображение. Пользователь посылает боту свою фотографию, и получает в ответ когнитивный портрет со своим участием, и с участием нескольких других "посетителей виртуальной выставки", которые посылали свои фотографии до этого. При этом, если в это время работала бы реальная выставка, то изображения бы смешивались ещё и с теми посетителями, которые пришли посмотреть на экспонат "в реальном мире".
Интерактивный бот @PeopleBlenderBot стирает границы между реальным и виртуальным миром, смешивая фотографии посетителей реальной выставки (или нескольких выставок) и людей, посещающих её из дома с помощью бота, в единый когнитивный портрет. Он являет собой искусство без границ, в прямом смысле объединяя людей из разных городов и стран. Вы можете протестировать бота в телеграм, или в моём виртуальном музее.
Далее поговорим подробнее про техническое устройство экспоната.
Клиентское приложение UWP
Одна из основных причин, по которой я выбрал технологию универсальных приложений Windows в качестве клиента — это наличие функции распознавания лиц прямо "из коробки". Универсальное приложение может быть запущено как на персональном компьютере, так и на микроконтроллере Raspberry Pi с операционной системой Windows 10 IoT Core. Конечно, Raspberry на Windows не слишком шустр, поэтому я использовал компактный компьютер Intel NUC.
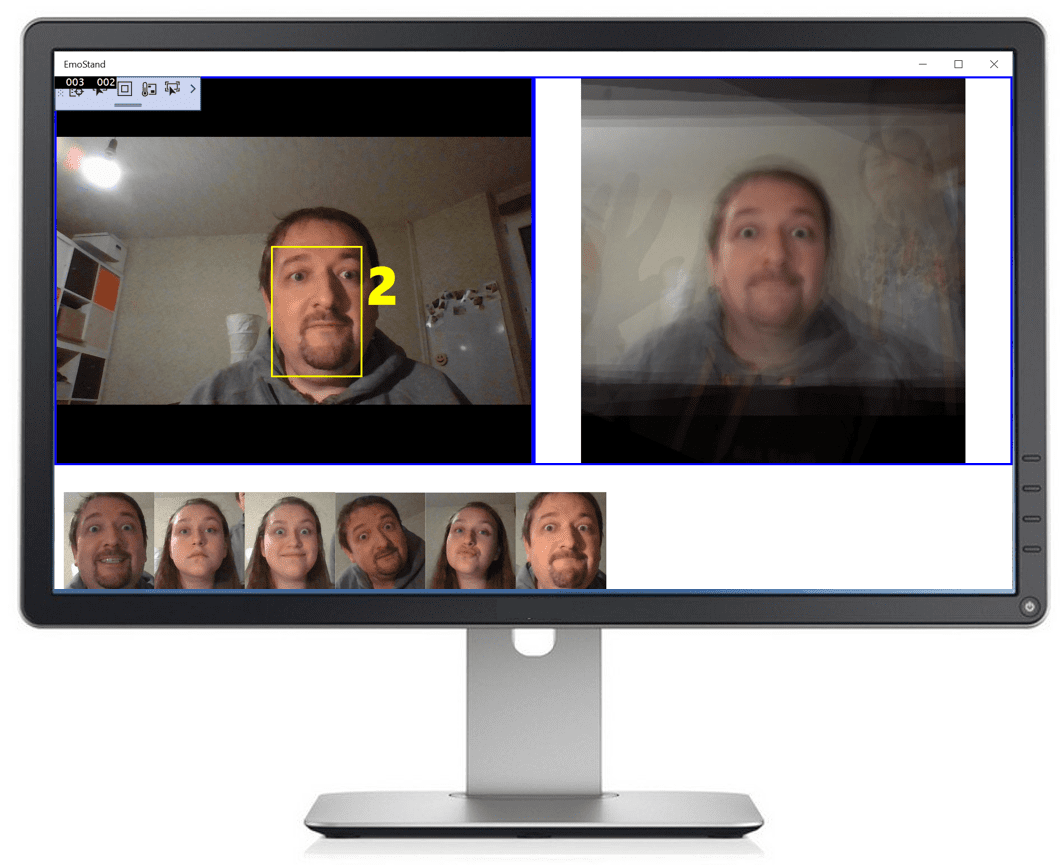
Примерно так выглядит пользовательский интерфейс приложения:
Такой интерфейс описывается на XAML следующим образом (с незначительными упрощениями):
<Grid Background="{ThemeResource ApplicationPageBackgroundThemeBrush}">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="*"/>
<ColumnDefinition Width="*"/>
</Grid.ColumnDefinitions>
<Grid.RowDefinitions>
<RowDefinition Height="*"/>
<RowDefinition Height="170"/>
</Grid.RowDefinitions>
<Grid x:Name="FacesCanvas" Grid.Row="0" Grid.Column="0">
<CaptureElement x:Name="ViewFinder" />
<Rectangle x:Name="FaceRect"/>
<TextBlock x:Name="Counter" FontSize="60"/>
</Grid>
<Grid x:Name="ResultCanvas" Grid.Row="0" Grid.Column="1">
<Image x:Name="ResultImage" Source="Assets/bgates.jpg"/>
</Grid>
<ItemsControl x:Name="FacesLine" Grid.Row="1" Grid.ColumnSpan="2"
ItemsSource="{x:Bind Faces,Mode=OneWay}"/>
</Grid>Наиболее интересны для нас следующие элементы управления:
ViewFinderпоказывает живое потоковое видео с камеры.FaceRectиCounterнаходятся поверхViewFinder, чтобы показывать прямоугольник поверх обнаруженного лица и счетчик обратного отсчета 3-2-1, после чего производится фотографирование.ResultImage— это основная область экрана, показывающая полученный из облака смешанный когнитивный портрет.FacesLineпоказывает несколько последних фотографий посетителей, сделанных экспонатом. Этот элемент управления декларативно привязан к коллекцииFaces, которая являетсяObservable. Таким образом, чтобы добавить в интерфейс новое лицо, достаточно просто добавить изображение в коллекциюFaces.- Остальной код XAML используется для правильного позиционирования элементов на экране.
Пример реализации обнаружения лиц в UWP можно найти в этом примере, или в документации. Он слегка сложноват, я позволил себе его немного упростить (и в статье для простоты также его немного сокращу).
Для начала, запустим камеру, и добьемся того, что изображение в реальном времени отображается в окне ViewFinder:
MC = new MediaCapture();
var cameras = await DeviceInformation.FindAllAsync(
DeviceClass.VideoCapture);
var camera = cameras.First();
var settings = new MediaCaptureInitializationSettings()
{ VideoDeviceId = camera.Id };
await MC.InitializeAsync(settings);
ViewFinder.Source = MC;Теперь займёмся трекингом лиц. Для этого создадим объект FaceDetectionEffect, который будет вызывать метод FaceDetectedEvent при обнаружении лица:
var def = new FaceDetectionEffectDefinition();
def.SynchronousDetectionEnabled = false;
def.DetectionMode = FaceDetectionMode.HighPerformance;
FaceDetector = (FaceDetectionEffect)
(await MC.AddVideoEffectAsync(def, MediaStreamType.VideoPreview));
FaceDetector.FaceDetected += FaceDetectedEvent;
FaceDetector.DesiredDetectionInterval = TimeSpan.FromMilliseconds(100);
FaceDetector.Enabled = true;
await MC.StartPreviewAsync();Когда в кадре обнаруживается лицо, вызывается FaceDetectedEvent, которая запускает таймер обратного отсчета, срабатывающий раз в секунду. По таймеру обновляется содержимое текстового поля Counter, показывающее обратный отсчет 3, 2 и 1. Когда счетчик достигает 0, изображение с камеры сохраняется в MemoryStream, и затем вызывается функция CallCognitiveFunction, которую мы реализуем позже:
var ms = new MemoryStream();
await MC.CapturePhotoToStreamAsync(
ImageEncodingProperties.CreateJpeg(), ms.AsRandomAccessStream());
var cb = await GetCroppedBitmapAsync(ms,DFace.FaceBox);
Faces.Add(cb);
var url = await CallCognitiveFunction(ms);
ResultImage.Source = new BitmapImage(new Uri(url));Мы ожидаем, что веб-сервис REST получит на вход изображение в виде потока методом POST, сделает всю основную магию по созданию портрета, сохранит его где-нибудь в облаке в открытом хранилище, и вернёт общедоступный URL изображения. Чтобы отобразить изображение в нашем интерфейсе, мы просто присваиваем этот URL свойству Source элемента управления ResultImage, что приводит к отображению результата на экране (при этом фреймворк UWP сам скачивает изображение по сети).
Также для красоты мы хотим показывать внизу экрана несколько предыдущих фотографий. Для этого вызывается функция GetCroppedBitmapAsync, вырезающая фрагмент изображения, и он добавляется в коллекцию Faces, в результате чего лицо отображается на экране (здесь нам помогает магия DataBinding).
Функция CallCognitiveFunction вызывает наш облачный сервис, который нам ещё предстоит реализовать, по протоколу REST с использованием объекта HttpClient:
private async Task<string> CallCognitiveFunction(MemoryStream ms)
{
ms.Position = 0;
var resp = await http.PostAsync(function_url,new StreamContent(ms));
return await resp.Content.ReadAsStringAsync();
}Azure Function для создания когнитивного портрета
Для выполнения основной работы мы используем технологию Azure Functions и реализуем код на Python. Использование Azure Functions имеет несколько преимуществ:
- Нет необходимости думать о том, где и как ваш код будет выполняться. Поэтому Azure Functions называют бессерверными вычислениями (serverless).
- Если мы используем план functions consumption plan, то мы платим только за количество вызовов функции, а не за время работы сервера. Единственным существенным минусом является ограничение на время работы функции (15 секунд), при превышении которого функция принудительно завершается. В нашем случае это не проблема, алгоритм должен уложиться в это время.
- Функция автоматически масштабируется в зависимости от нагрузки, не нужно думать про автомасштабирование.
- Azure Function может запускаться в ответ на различные события в облаке. В нашем примере мы будем явно запускать функцию по REST-запросу, но возможно также привязать запуск функции к появлению нового объекта в хранилище, нового сообщения в очереди, или сделать автозапуск по таймеру.
- Azure Function может быть легко интегрирована с хранилищем декларативным способом, при этом объект будет автоматически извлечен из хранилища и передан в функцию в качестве параметра. Мы можем концентрироваться на логике, а не на том, как работать с облачным хранилищем.
В качестве примера рассмотрим задачу, когда нам нужно наносить текущую дату поверх фотографий, присылаемых пользователем. Мы можем создать Azure Function, которая будет срабатывать автоматически при помещении фотографии в блоб-хранилище, и которая будет размещать результат в другом хранилище. Нам останется лишь написать код для импринтинга даты, входное изображение мы получим автоматически в качестве параметра, а выходное — вернем как результат функции. Минимум boilerplate code!
Azure Functions настолько полезны, что я рассматриваю их как основной выбор во всех случаях, когда мне нужно запускать какой-то код для обработки данных в облаке, включая чат-ботов, обработку IoT-сообщений и т.д.
В нашем случае алгоритм рисования портрета реализован на Python с использованием OpenCV — я описывал реализации в своей более ранней заметке. Раньше считалось, что Azure Functions очень неэффективны при работе с Python, но эта информация устарела — вторая версия (V2) работает как часы.
Проще всего начать разрабатывать функцию локально. Этот процесс хорошо описан в документации, но я тоже коротко на нём остановлюсь. Если вы хотите сделать больше операций из VS Code, а не из командной строки — смотрите это пошаговое руководство.
Для начала создадим новую функцию с помощью CLI:
func init coportrait –python
cd coportrait
func new --name pdraw --template "HTTP trigger"Конечно, предварительно нам потребуется установить Azure Functions Core Tools.
Функция описывается двумя основными файлами:
- Основной код функции на Python (в нашем случае, он будет в файле
__init__.py). - Файл описания
function.json, который описывает все интеграции, т.е. связь функции с хранилищами, её входные и выходные параметры и критерии срабатывания.
В нашем случае функция срабатывает по HTTP-запросу, и function.json выглядит так:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [ "post" ]},
{
"type": "http",
"direction": "out",
"name": "$return"
}]}Здесь указывается имя скрипта, имя входного параметра req связывается с входящим HTTP-триггером, а выход функции — это HTTP response, возвращаемый из функции как результат ($return). Мы также указываем, что функция поддерживает лишь POST-запросы. Изначально в шаблоне был также указан метод "get", который я удалил.
Если мы посмотрим в __init__.py, то там будет изначально содержаться примерно такой шаблон кода (который я для наглядности ещё немного упростил):
def main(req:func.HttpRequest) -> func.HttpResponse:
logging.info('Execution begins…')
return func.HttpResponse(f"Hello {name}!")Здесь, req — это наш запрос. Чтобы получить изображение, закодированное как двоичный поток в формате JPEG, мы сначала получаем данные через get_body, а затем преобразуем их в numpy-массив с помощью OpenCV:
body = req.get_body()
nparr = np.fromstring(body, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)Для работы с хранилищем мы будем использовать объект azure.storage.blob.BlockBlobService. Альтернативой было бы использовать интеграции, но в моём примере мне показалось, что проще включить код для работы с хранилищем внутрь функции, поскольку нам нужно работать сразу с несколькими контейнерами в рамках одного хранилища, и прописывать доступ ко всем этим контейнерам с помощью интеграции было бы дольше. Про работу с хранилищами в Azure из Python можно подробнее прочитать в документации.
Для начала сохраним входное изображение в контейнер cin:
blob = BlockBlobService(account_name=..., account_key=...)
sec_p = int((end_date-datetime.datetime.now()).total_seconds())
name = f"{sec_p:09d}-{time.strftime('%Y%m%d-%H%M%S')}"
blob.create_blob_from_bytes("cin",name,body)Здесь мы делаем один очень важный трюк с именованием файла. Поскольку далее нам потребуется обращаться к 10 последним фотографиям, нам хотелось бы иметь возможность это делать, не считывая все файлы в хранилище. Поскольку имена объектов в хранилище возвращаются в алфавитном порядке, нам необходимо придумать такое именование файлов, чтобы они были отсортированы в порядке убывания дат. В этом примере я просто вычисляю количество секунд от текущего момента времени до 1 января 2021 года, и добавляю соответствующее число (с лидирующими нулями) в начало имени файла, которое формируется стандартным образом из текущей даты и времени в формате YYYYMMDD-HHMMSS. При этом наш код будет страдать от проблемы 2021 года...
Далее будем вызывать Face API для извлечения опорных точек лица, и применять к изображению аффинное преобразование для совмещения глаз с предопределёнными позициями:
cogface = cf.FaceClient(cognitive_endpoint,
CognitiveServicesCredentials(cognitive_key))
res = cogface.face.detect_with_stream(io.BytesIO(body),
return_face_landmarks=True)
if res is not None and len(res)>0:
tr = affine_transform(img,res[0].face_landmarks.as_dict())
body = cv2.imencode('.jpg',tr)[1]
blob.create_blob_from_bytes("cmapped",name,body.tobytes())Код функции affine_transform можно взять из моего предыдущего поста. После того, как изображение повёрнуто, оно сохраняется как JPEG-картинка в контейнер cmapped.
Наконец, нам надо подготовить очередной когнитивный портрет, а для этого взять 10 последних выровненных изображений из cmapped и наложить их друг на друга. Для этого мы используем функцию list_blobs для получения генератора всех имен файлов в блобе, берем из него 10 первых элементов с помощью islice, и затем применяем к ним imdecode для получения numpy-массивов изображений:
imgs = [ imdecode(blob.get_blob_to_bytes("cmapped",x.name).content)
for x in itertools.islice(blob.list_blobs("cmapped"),10) ]
imgs = np.array(imgs).astype(np.float)Для наложения всех фотографий, нам необходимо провести усреднение массива по первой оси. Единственная важная тонкость здесь состоит в том, что нам надо привести изображения к float, а затем — обратно к np.uint8:
res = (np.average(imgs,axis=0)).astype(np.uint8)В завершение, мы сохраняем результат в контейнере out, сначала превращая изображение в байтовый поток с помощью cv2.imencode, а затем вызывая create_blob_from_bytes:
b = cv2.imencode('.jpg',res)[1]
r = blob.create_blob_from_bytes("out",f"{name}.jpg",b.tobytes())
result_url = f"https://{act}.blob.core.windows.net/out/{name}.jpg"
return func.HttpResponse(result_url)Важный момент — мы должны заранее создать контейнер out, и пометить его как открытый блоб, чтобы доступ к нему был возможен снаружи из интернет, без указания дополнительных параметров.
После написания кода функции в __init__.py, нам также важно правильно указать все зависимости в requirements.txt:
azure-functions
opencv-python
azure-cognitiveservices-vision-face
azure-storage-blob==1.5.0Сделав это, мы можем запустить функцию локально:
func startПри этом запустится локальный веб-сервер, и на экране будет напечатана локальная URL функции, которую мы можем для проверки попробовать вызвать с помощью Postman. Мы должны использовать метод POST, и передать какое-нибудь изображение в теле запроса.
Мы также можем указать эту же URL в переменной function_url в нашем UWP-приложении, после чего весь экспонат должен успешно запуститься и заработать на локальном компьютере.
Для публикации кода Azure Function в облако, нам сначала необходимо создать Python Azure Function через Azure Portal, или из командной строки Azure CLI:
az functionapp create --resource-group PeopleBlenderBot
--os-type Linux --consumption-plan-location westeurope
--runtime python --runtime-version 3.7
--functions-version 2
--name coportrait --storage-account coportraitstoreДелать это через Azure Portal поначалу безусловно проще, поскольку ряд вещей (вроде создания хранилища данных) будет сделан автоматически. Azure CLI полезен в том случае, если вы хотите автоматизировать процесс.
После того, как функция создана, её развёртывание делается совсем просто:
func azure functionapp publish coportraitПосле публикации нам нужно пойти на Azure Portal, и посмотреть там соответствующий функции URL:
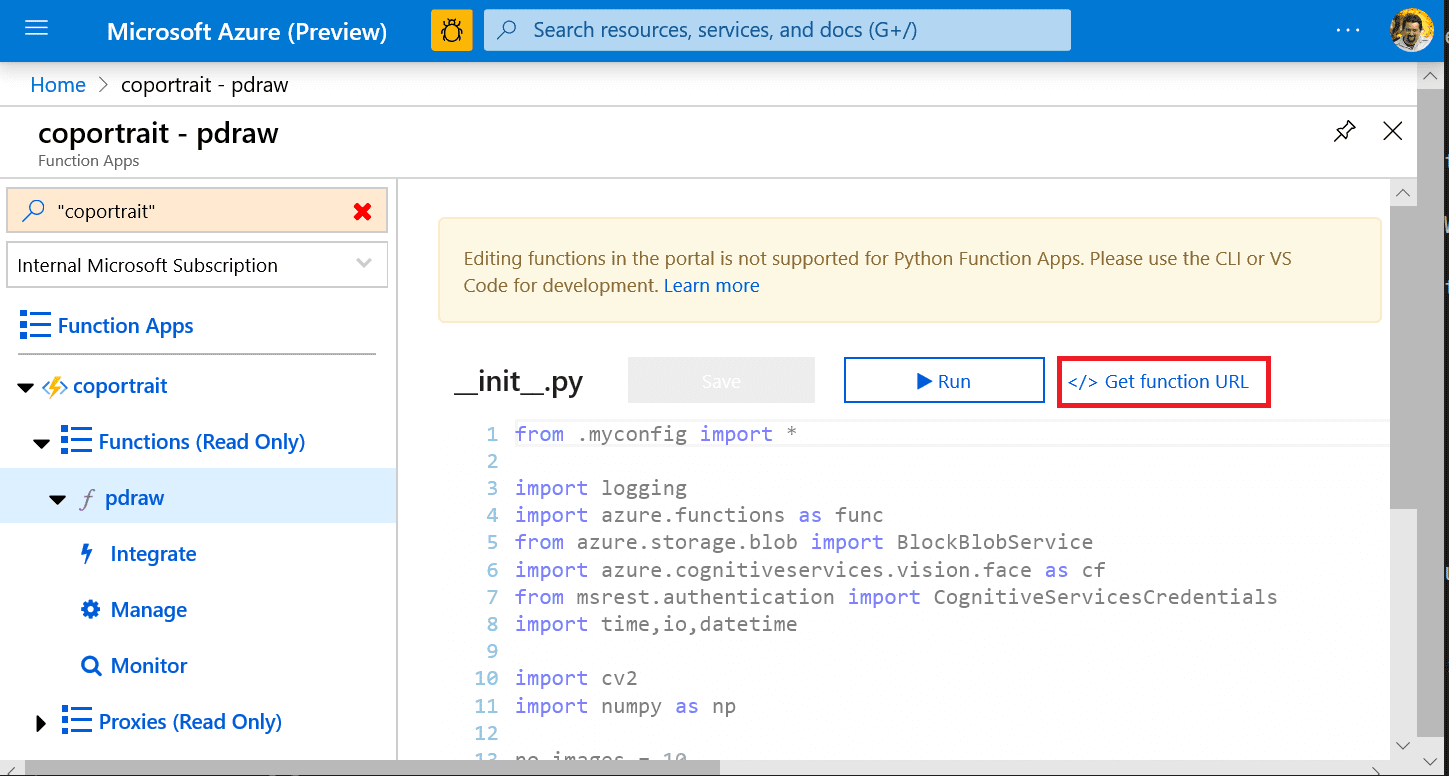
Этот URL будет выглядеть примерно так: https://coportrait.azurewebsites.net/api/pdraw?code=geE..e3P==, т.е. он будет содержать в себе код для вызова функции. Присвойте этот адрес (вместе с ключом) переменной function_url в нашем UWP-приложении, запустите его, и наслаждайтесь!
Создаём чат-ботный экспонат
Во время социальной изоляции, очень важно дать людям возможность наслаждаться искусством из дома. Лучший способ сделать экспонат доступным отовсюду — использовать Microsoft Bot Framework для создания чат-бота.
В описанной архитектуре, вся основная работа делается в облаке, поэтому очень легко создавать дополнительные интерфейсы к тому же экспонату. Например, интерфейс в виде чат-бота.
Процесс создания чат-бота на C# хорошо описан в документации, или вот в этом пошаговом руководстве. Вы также можете создать чат-бота на Python, но использование .NET сильно лучше документировано, поэтому мы пойдём именно таким путём.
Для начала, нам надо установить VS Bot Template для Visual Studio, и затем создать новый проект из шаблона Echo:
Я назову этого бота PeopleBlenderBot.
Основная логика бота содержится в файле Bots\EchoBot.cs, внутри функции OnMessageActivityAsync. Эта функция получает на вход т.н. turnContext. Главная составляющая этого контекста — поле Activity, которое в свою очередь содержит текст сообщения в поле Text, а также присоединенные файлы в объекте Attachments. Для начала нам надо проверить, содержится ли в сообщении пользователя картинка:
if (turnContext.Activity.Attachments?.Count>0)
{
// do the magic
}
else
{
await turnContext.SendActivityAsync("Please send picture");
}Если пользователь добавил картинку, то ссылка на неё будет доступна в поле ContentUrl объекта Attachment. Внутри if-блока, поместим код для считывания входного изображения в http-поток:
var http = new HttpClient();
var resp = await http.GetAsync(Attachments[0].ContentUrl);
var str = await resp.Content.ReadAsStreamAsync();Далее нам нужно передать этот поток на вход нашей Azure Function, в теле POST-запроса. Этот код выглядит очень похожим образом на код из нашего UWP-приложения:
resp = await http.PostAsync(function_url, new StreamContent(str));
var url = await resp.Content.ReadAsStringAsync();В результате вызова функции мы получаем URL результирующего изображения, которое необходимо вернуть пользователю. Для этого мы используем карточки, а именно Hero-card, которая передаётся назад в виде attachment-а:
var msg = MessageFactory.Attachment(
(new HeroCard()
{ Images = new CardImage[] { new CardImage(url) } }
).ToAttachment());
await turnContext.SendActivityAsync(msg);Написав код бота, мы можем запустить и отладить его локально с помощью Bot Framework Emulator:
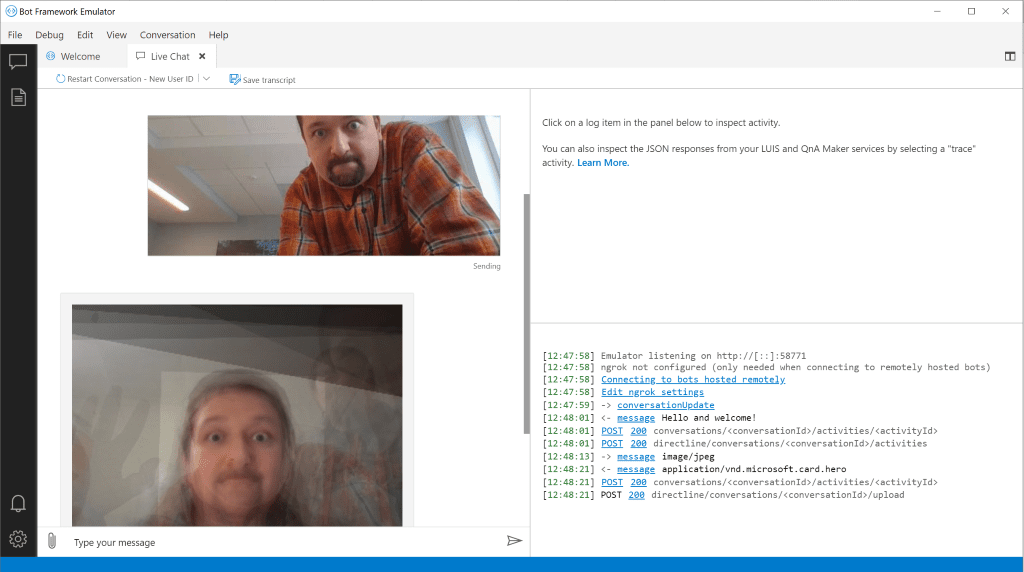
Убедившись, что бот работает, мы можем опубликовать код в облако, как это описано в документации через Azure CLI и ARM-шаблон. Однако, тоже самое можно сделать через Azure Portal:
- Создайте новый объект Web App Bot на портале, выбрав Echo Bot в качестве начального шаблона. Это приведёт к созданию двух объектов в вашей подписке:
- Bot Connector App, который описывает взаимодействие вашего бота в различными каналами связи, такими, как Telegram
- Bot Web App, веб-приложение, в рамках которого работает написанный вами код бота
- Скачайте код вашего бота из облака и скопируйте файл
appsettings.jsonиз него в наш проектPeopleBlenderBot. Этот файл содержит App Id и App Password, которые необходимы для безопасного подключения к bot connector. - Из Visual Studio нажмите правой кнопкой на проект
PeopleBlenderBotи выберите Publish. Выберите пункт Existing Web App, и приложение, созданное на шаге 1. Это позволит вам развернуть код вашего бота в облако.
После этого, переходите на страничку объекта Bot Connector App на портале Azure Portal, и убедитесь, что бот работает в режиме Web Chat:
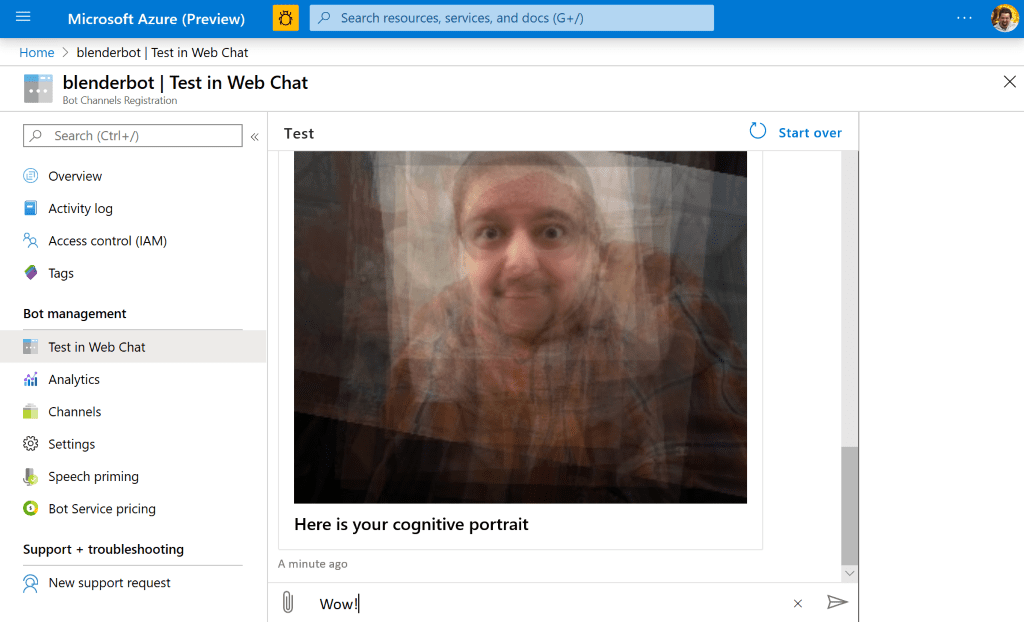
Теперь развернуть бота в телеграмм — это пара кликов! Этот процесс детально описан в документации, да и на самом портале при добавлении канала Telegram в разделе Channels предложат пошаговую инструкцию:
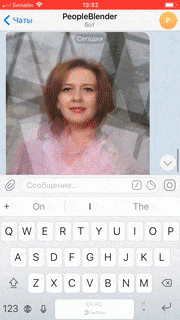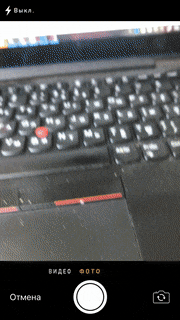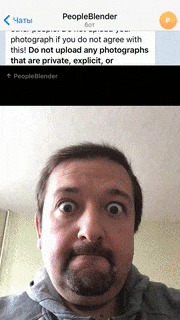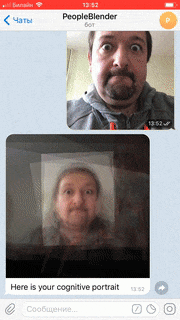
Заключение
Я поделился своим опытом создания интерактивного экспоната, основная логика которого реализована в виде облачного сервиса. Такой подход оказывается очень плодотворным, мы ранее уже успешно использовали его для создания экспонатов в компании Mechanium, и на Moscow Maker Faire 2019. Я призываю вас использовать такой подход, если вы делаете какие-то музейные экспонаты или выставки. Ну а если нет — призываю вас присмотреться к направлению Science Art, поскольку это прекрасная возможность для нас — технарей — приобщиться к художественному творчеству. В качестве отправной точки приглашаю вас в репозиторий техник когнитивного портрета, в котором собраны разные техники, основанные на извлечении опорных точек лица! Попробуйте сделать что-то своё — я буду очень рад получить pull request от вас! В моей другой заметке я обсуждаю искусственный интеллект и искусство, и показываю примеры того, как ИИ может быть ещё более креативным. Если вас интересует эта тема — давайте поговорим, и возможно сделаем что-нибудь совместно!
Чат-бот, описанный в этой статье, доступен в Telegram как @peopleblenderbot, а также в моём виртуальном музее. Попробуйте его сами! Помните, что вы не просто переписываетесь в ботом, а получаете опыт созерцания удалённого виртуального экспоната, который делает людей ближе, несмотря на расстояния и на период самоизоляции. Посылая фотографии, имейте в виду, что ваши фотографии будут сохраняться в облаке и отправляться другим людям в усреднённом виде.
Следите за новостями! Очень надеюсь, что в скором времени мы сможем насладиться этим экспонатом не только виртуально, но и на реальной выставке!