
(изображение взято отсюда)
Сегодня мы бы хотели вам рассказать о задаче пост-обработки результатов распознавания текстовых полей исходя из априорных знаний о поле. Ранее мы уже писали про метод коррекции полей на основе триграмм, который позволяет исправлять некоторые ошибки распознавания слов, написанных на естественных языках. Однако значительную часть важных документов, в том числе документов, удостоверяющих личность, составляют поля другого характера – даты, номера, VIN-коды автомобилей, номера ИНН и СНИЛС, машинно-читаемые зоны с их контрольными суммами и многое другое. Хотя их нельзя отнести к полям естественного языка, тем не менее у таких полей зачастую существует некоторая, иногда неявная, языковая модель, а значит, для них тоже можно применить некоторые алгоритмы коррекции. В этом посте речь пойдет об двух механизмах пост-обработки результатов распознавания, которые можно применять для большого количества документов и типов полей.
Языковую модель поля можно условно подразделить на три составляющие:
- Синтаксис: правила, регулирующие структуру текстового представления поля. Пример: поле “дата окончания срока действия документа” в машинно-читаемой зоне представлятся в виде семи цифр “DDDDDDD”.
- Семантика поля: правила, основывающиеся на смысловой интерпретации поля или его составных частей. Пример: в поле “дата окончания срока действия документа” машинно-читаемой зоны первые две цифры – это последние две цифры года, 3-я и 4-я цифры – это месяц, 5-я и 6-я – это день, и 7-я цифра – контрольная сумма.
- Семантика связей: правила, основывающиеся на структурной и смысловой связи поля с другими полями документа. Пример: поле “дата окончания срока действия документа” не может кодировать дату, соответствующую более раннему моменту времени, чем поле “дата рождения”.
Располагая информацией о семантической и синтаксической структуре документа и распознаваемого поля, можно построить специализированный алгоритм пост-обработки результата распознавания. Однако, принимая во внимание необходимость поддержки и развития систем распознавания и сложность их разработки, интересно рассмотреть “универсальные” методы и инструменты, которые позволили бы с минимальными усилиями (со стороны разработчиков) построить достаточно хороший алгоритм пост-обработки, который бы работал с обширным классом документов и полей. Методика настройки и поддержки такого алгоритма была бы унифицирована, а изменяемым компонентом структуры алгоритма была бы только языковая модель.
Стоит отметить, что пост-процессинг результатов распознавания текстовых полей не всегда полезен, а иногда даже вреден: в случае, если у вас достаточно хороший модуль распознавания строки и вы работаете в критических системах с документами, удостоверяющими личность, то какой-либо пост-процессинг лучше минимизировать и выдавать результаты “так как есть”, либо четко контролировать любые изменения и сообщать о них клиенту. Однако во многих случаях, когда заведомо известно, что документ действительный, и что языковая модель поля надежна – использование алгоритмов пост-обработки позволяет значительно повысить итоговое качество распознавания.
Итак, в статье пойдет речь о двух методах пост-обработки, претендующих на универсальность. Первый основан на взвешенных конечных преобразователях, требует описания языковой модели в виде конечного автомата, не очень прост в использовании, но более универсален. Второй – более простой в использовании, более эффективен, требует всего лишь написания функции проверки валидности значения поля, но также обладает рядом недостатков.
Метод на основе взвешенных конечных преобразователей
Красивая и достаточно общая модель, позволяющая построить универсальный алгоритм пост-обработки результатов распознавания, описана в этой работе. Модель опирается на структуру данных взвешенных конечных преобразователей (Weighted Finite-State Transducers, WFST).
WFST представляют собой обобщение взвешенных конечных автоматов – если взвешенный конечный автомат кодирует некоторый взвешенный язык
 (т.е. взвешенное множество строк над некоторым алфавитом
(т.е. взвешенное множество строк над некоторым алфавитом  ), то WFST кодирует взвешенное отображение языка
), то WFST кодирует взвешенное отображение языка  над алфавитом
над алфавитом  в язык
в язык  над алфавитом
над алфавитом  . Взвешенный конечный автомат, принимая строку
. Взвешенный конечный автомат, принимая строку  над алфавитом , ставит ей в соответствие некоторый вес
над алфавитом , ставит ей в соответствие некоторый вес  , тогда как WFST, принимая строку
, тогда как WFST, принимая строку  над алфавитом , ставит ей в соответствие множество (возможно, бесконечное) пар
над алфавитом , ставит ей в соответствие множество (возможно, бесконечное) пар  , где
, где  – строка над алфавитом , в которую преобразуется строка , а
– строка над алфавитом , в которую преобразуется строка , а  – вес такого преобразования. Каждый переход преобразователя характеризуется двумя состояниями (между которыми осуществляется переход), входным символов (из алфавита ), выходным символов (из алфавита ) и весом перехода. Считается, что пустой символ (пустая строка) является элементом обоих алфавитов. Весом преобразования строки
– вес такого преобразования. Каждый переход преобразователя характеризуется двумя состояниями (между которыми осуществляется переход), входным символов (из алфавита ), выходным символов (из алфавита ) и весом перехода. Считается, что пустой символ (пустая строка) является элементом обоих алфавитов. Весом преобразования строки  в строку
в строку  является сумма произведений весов переходов по всем путям, на которых конкатенация входных символов образует строку , а конкатенация выходных символов образует строку , и которые переводят преобразователь из начального состояния в одно из терминальных.
является сумма произведений весов переходов по всем путям, на которых конкатенация входных символов образует строку , а конкатенация выходных символов образует строку , и которые переводят преобразователь из начального состояния в одно из терминальных.Над WFST определяется операция композиции, на которую и опирается метод пост-обработки. Пусть заданы два преобразователя
 и
и  , причем преобразует строку над
, причем преобразует строку над  в строку над
в строку над  с весом
с весом  , а преобразует над в строку
, а преобразует над в строку  над
над  с весом
с весом  . Тогда преобразователь
. Тогда преобразователь  , называемый композицией преобразователей, преобразует строку в строку с весом
, называемый композицией преобразователей, преобразует строку в строку с весом  . Композиция преобразователей является вычислительно затратной операцией, но может вычисляться лениво – состояния и переходы результирующего преобразователя могут быть построены в момент, когда к ним необходимо совершать доступ.
. Композиция преобразователей является вычислительно затратной операцией, но может вычисляться лениво – состояния и переходы результирующего преобразователя могут быть построены в момент, когда к ним необходимо совершать доступ.Алгоритм пост-обработки результата распознавания на основе WFST опирается на три основных источника информации – модель гипотез
 , модель ошибок
, модель ошибок  и языковую модель
и языковую модель  . Все три модели представляются в виде взвешенных конечных преобразователей:
. Все три модели представляются в виде взвешенных конечных преобразователей:- Модель гипотез представляет из себя взвешенный конечный автомат (частный случай WFST – каждая строка преобразуется сама в себя, вес преобразования совпадает с весом самой строки), принимающий гипотезы, видвинутые системой распознавания поля. К примеру, пусть результатом распознавания текстового поля является последовательность ячеек
 , а каждая ячейка соответствует результату распознавания некоторого символа и представляет собой множество альтернатив и их оценок (весов):
, а каждая ячейка соответствует результату распознавания некоторого символа и представляет собой множество альтернатив и их оценок (весов):  , где
, где  –
–  -й символ алфавита,
-й символ алфавита,  – оценка (вес) этого символа. Тогда модель гипотез можно представить в виде конечного преобразователя с
– оценка (вес) этого символа. Тогда модель гипотез можно представить в виде конечного преобразователя с  -м состоянием, уложенным в цепочку:
-м состоянием, уложенным в цепочку:  -е состояние является начальным,
-е состояние является начальным,  -е – терминальным, переходы осуществляются между
-е – терминальным, переходы осуществляются между  -м и
-м и  -м состояниями и соответствуют ячейке
-м состояниями и соответствуют ячейке  . На -м переходе входным и выходным символом является символ , а вес перехода соответствует оценке данной альтернативы. Ниже на рисунке представлен пример модели гипотез, сооветствующей результату распознавания строки из трех символов.
. На -м переходе входным и выходным символом является символ , а вес перехода соответствует оценке данной альтернативы. Ниже на рисунке представлен пример модели гипотез, сооветствующей результату распознавания строки из трех символов.
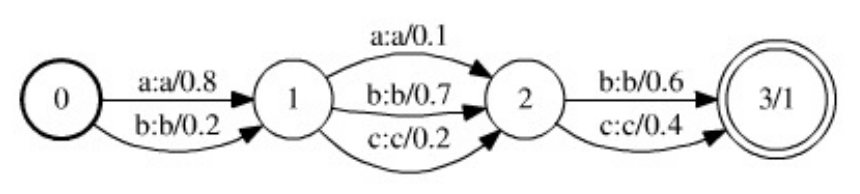
Рис. 1. Пример модели гипотез, представленной в виде WFST (рисунок из этой статьи). Переходы с нулевым весом опущены.
- Модель ошибок является взвешенным конечным преобразователем, кодирующим всевозможные преобразования гипотез, которые можно производить для их приведения в соответствие языковой модели. В самом простом случае она может быть представлена в виде WFST с единственным состоянием (которое является и начальным и терминальным). Каждый переход кодирует некоторое изменение символа с соответствующим весом. К примеру, весом замены символа может являться оценка вероятности соответствующей ошибки алгоритма распознавания символа.
- Языковой моделью является представление синтаксиса и семантики распознаваемого поля в виде взвешенного конечного автомата. Т.е. языковой моделью яляется автомат, принимающий все допустимые значения рассматриваемого поля (и выставляющий каждому допустимому значению некоторый вес).
После определения модели гипотез, ошибок и языковой модели задача пост-обработки результатов распознавания теперь может быть поставлена следующим образом: рассмотрим композицию всех трех моделей
 (в терминах композиции WFST). Преобразователь
(в терминах композиции WFST). Преобразователь  кодирует всевозможные преобразования строк из модели гипотез в строки из языковой модели , применяя к строкам преобразования, закодированные в модели ошибок . Причем вес такого преобразования включает вес исходной гипотезы, вес преобразования и вес результирующей строки (в случае взвешенной языковой модели). Соответственно в такой модели оптимальной пост-обработке результата распознавания будет соответствовать оптимальный (с точки зрения веса) путь в преобразователе , переводящий его из начального в одно из терминальных состояний. Входная строка на этом пути будет соответствовать выбранной исходной гипотезе, а выходная строка – исправленному результату распознавания. Оптимальный путь можно искать с помощью алгоритмов поиска кратчайших путей в ориентированных графах.
кодирует всевозможные преобразования строк из модели гипотез в строки из языковой модели , применяя к строкам преобразования, закодированные в модели ошибок . Причем вес такого преобразования включает вес исходной гипотезы, вес преобразования и вес результирующей строки (в случае взвешенной языковой модели). Соответственно в такой модели оптимальной пост-обработке результата распознавания будет соответствовать оптимальный (с точки зрения веса) путь в преобразователе , переводящий его из начального в одно из терминальных состояний. Входная строка на этом пути будет соответствовать выбранной исходной гипотезе, а выходная строка – исправленному результату распознавания. Оптимальный путь можно искать с помощью алгоритмов поиска кратчайших путей в ориентированных графах.Преимуществами данного подхода является его общность и гибкость. Модель ошибок, к примеру, может быть без труда расширена таким образом, чтобы учесть удаления и добавления символов (для этого всего лишь стоит добавить в модель ошибок переходы с пустым выходным или входным символом соответственно). Однако у такой модели есть и существенные недостатки. Во-первых, языковая модель здесь должна быть представлена в виде конечного взвешенного конечного преобразователя. Для сложных языков такой автомат может получиться довольно громоздким, и в случае изменения или уточнения языковой модели будет необходимо его перестроение. Также необходимо заметить, что композиция трех преобразователей в качестве результата имеет, как правило, еще более громоздкий преобразователь, а эта композиция вычисляется каждый раз при запуске пост-обработки одного результата распознавания. Ввиду громоздкости композиции, поиск оптимального пути на практике приходится выполнять эвристическими методами, такими как A*-search.
Метод на основе проверяющих грамматик
Используя модель проверяющих грамматики можно построить более простую модель задачи пост-обработки результатов распознавания, которая будет не насколько общей, как модель на основе WFST, однако легко расширяемой и простой в имплементации.
Проверяющей грамматикой будем называть пару
 , где – алфавит, а
, где – алфавит, а  – предикат допустимости строки над алфавитом , т.е.
– предикат допустимости строки над алфавитом , т.е.  . Проверяющая грамматика кодирует некоторый язык над алфавитом следующим образом: строка
. Проверяющая грамматика кодирует некоторый язык над алфавитом следующим образом: строка  принадлежит языку, если предикат принимает на этой строке истинное значение. Стоит заметить, что проверяющая грамматика является более общим способом представления языковой модели, чем конечный автомат. Действительно, любой язык, представимый в виде конечного автомата , может быть представлен в виде проверяющей грамматики (с предикатом
принадлежит языку, если предикат принимает на этой строке истинное значение. Стоит заметить, что проверяющая грамматика является более общим способом представления языковой модели, чем конечный автомат. Действительно, любой язык, представимый в виде конечного автомата , может быть представлен в виде проверяющей грамматики (с предикатом  , где
, где  – множество строк, принимаемых автоматом . Однако не все языки, которые можно представить в виде проверяющей грамматики, представимы в виде конечного автомата в общем случае (к примеру, язык слов неограниченной длины над алфавитом
– множество строк, принимаемых автоматом . Однако не все языки, которые можно представить в виде проверяющей грамматики, представимы в виде конечного автомата в общем случае (к примеру, язык слов неограниченной длины над алфавитом  , в которых количество символов
, в которых количество символов  больше, чем количество символов
больше, чем количество символов  ).
).Пусть задан результат распознавания (модель гипотез) в виде последовательности ячеек
(таких же, как и в предыдущем разделе). Для удобства будем считать, что каждая ячейка содержит K альтернатив и все оценки альтернатив принимают положительное значение. Оценкой (весом) строки будем считать произведение оценок каждого из символов этой строки. Если модель языка задана в виде проверяющей грамматики , то задача пост-обработки может быть сформулирована в виде задачи дискретной оптимизации (максимизации) на множестве управлений  (множестве всех строк длины над алфавитом ) с предикатом допустимости и функционалом
(множестве всех строк длины над алфавитом ) с предикатом допустимости и функционалом  , где
, где  – оценка символа
– оценка символа  в -й ячейке.
в -й ячейке.Любая задача дискретной оптимизации (т.е. с конечным множестве управлений) может быть решена при помощи полного перебора управлений. Описываемый алгоритм эффективно перебирает управления (строки) в порядке убывания значения функционала до того момента, пока предикат допустимости не примет истинного значения. Зададим как
 максимальное количество итераций алгоритма, т.е. максимальное количество строк с максимальной оценкой, на которой будет вычисляться предикат.
максимальное количество итераций алгоритма, т.е. максимальное количество строк с максимальной оценкой, на которой будет вычисляться предикат.Вначале проведем сортировку альтернатив по убыванию оценок, и будем далее считать что для любой ячейки
верно неравенство  при
при  . Позицией будем называть последовательность индексов
. Позицией будем называть последовательность индексов  , соответствующее строке
, соответствующее строке  . Оценкой позиции, т.е. значением функционала на этой позиции, считаем произведение оценок альтернатив, соответствующих индексам, входящих в позицию:
. Оценкой позиции, т.е. значением функционала на этой позиции, считаем произведение оценок альтернатив, соответствующих индексам, входящих в позицию:  . Для хранения позиций потребуется структура данных PositionBase, позволяющая добавлять новые позиции (с получением их адреса), получать позицию по адресу и проверять, добавлена ли заданная позиция в базу.
. Для хранения позиций потребуется структура данных PositionBase, позволяющая добавлять новые позиции (с получением их адреса), получать позицию по адресу и проверять, добавлена ли заданная позиция в базу.В процессе перечисления позиций мы будем выбирать непросмотренную позицию с максимальной оценкой, после чего добавлять в очередь на рассмотрение PositionQueue все позиции, которые можно получить из текущей добавлением единицы к одному из индексов, входящих в позицию. Очередь на рассмотрение PositionQueue будет содержать тройки
 , где
, где  – оценка непросмотренной позиции,
– оценка непросмотренной позиции,  – адрес просмотренной позиции в PositionBase, из которой была получена данная позиция,
– адрес просмотренной позиции в PositionBase, из которой была получена данная позиция,  – индекс элемента позиции с адресом , который был увеличен на единицу для получения данной позиции. Для организации очереди PositionQueue потребуется структура данных, позволяющая добавлять очередную тройку , а также извлекать тройку с максимальной оценкой .
– индекс элемента позиции с адресом , который был увеличен на единицу для получения данной позиции. Для организации очереди PositionQueue потребуется структура данных, позволяющая добавлять очередную тройку , а также извлекать тройку с максимальной оценкой .На первой итерации алгоритма необходимо рассмотреть позицию
 , обладающую максимальной оценкой. Если предикат принимает на строке, соответствующей этой позиции, истинное значение, то алгоритм завершается. В противном случае позиция добавляется в PositionBase, а в PositionQueue добавляются все тройки вида
, обладающую максимальной оценкой. Если предикат принимает на строке, соответствующей этой позиции, истинное значение, то алгоритм завершается. В противном случае позиция добавляется в PositionBase, а в PositionQueue добавляются все тройки вида  , для всех
, для всех  , где
, где  – адрес начальной позиции в PositionBase. На каждой последующей итерации алгоритма из PositionQueue извлекается тройка с максимальным значением оценки , по адресу исходной позиции и индексу восстанавливается рассматриваемая позиция . Если позиция уже добавлена в базу рассмотренных позиций PositionBase, то она пропускается и из PositionQueue извлекается очередная тройка с максимальным значением оценки . В противном случае на строке, соответствующей позиции проверяется значение предиката . Если предикат принимает на этой строке истинное значение, то алгоритм завершается. Если предикат не принимает истинное значение на этой строке, то строка добавляется в PositionBase (с присвоением адреса
– адрес начальной позиции в PositionBase. На каждой последующей итерации алгоритма из PositionQueue извлекается тройка с максимальным значением оценки , по адресу исходной позиции и индексу восстанавливается рассматриваемая позиция . Если позиция уже добавлена в базу рассмотренных позиций PositionBase, то она пропускается и из PositionQueue извлекается очередная тройка с максимальным значением оценки . В противном случае на строке, соответствующей позиции проверяется значение предиката . Если предикат принимает на этой строке истинное значение, то алгоритм завершается. Если предикат не принимает истинное значение на этой строке, то строка добавляется в PositionBase (с присвоением адреса  ), в очередь PositionQueue добавляются все производные позиции и происходит переход к следующей итерации.
), в очередь PositionQueue добавляются все производные позиции и происходит переход к следующей итерации.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
для каждого i : 1 ... N:
сортировка C[i] по убыванию оценок альтернатив
(конец цикла)
инициализация PositionBase и PositionQueue
S_1 = {1, 1, 1, ..., 1}
если P(S_1):
ответ: S_1, алгоритм завершается
(конец условия)
добавление S_1 в PositionBase с адресом R(S_1)
для каждого i : 1 ... N:
если K > 1, то:
добавить тройку <Q * q[i][2] / q[i][1], R(S_1), i> в PositionQueue
(конец условия)
(конец цикла)
пока количество позиций в PositionBase меньше M:
пока не пуста PositionQueue:
извлечь из PositionQueue тройку <Q, R, I> с максимальной Q
S_from = позиция в PositionBase по адресу R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
если S_curr содержится в PositionBase:
продолжаем цикл
иначе:
добавить S_curr в PositionBase с адресом R(S_curr)
(конец условия)
если P(S_curr):
ответ: S_curr, алгоритм завершается
(конец условия)
для каждого i : 1 ... N:
если K > S_curr[i]:
добавить тройку <Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> в PositionQueue
(конец условия)
(конец цикла)
выход из внутреннего цикла
(конец цикла)
(конец цикла)
ответ не найден за M итераций
Заметим, что за
итераций будет осуществлена проверка предиката не более чем раз, произойдет не более добавлений в PositionBase, а добавление в PositionQueue, извлечение из PositionQueue, а также поиск в PositionBase произойдет не более  раз. Если для реализации PositionQueue используется структура данных “куча”, а для организации PositionBase используеся структура данных “бор”, то трудоемкость алгоритма составляет
раз. Если для реализации PositionQueue используется структура данных “куча”, а для организации PositionBase используеся структура данных “бор”, то трудоемкость алгоритма составляет  , где
, где  – трудоемость проверки предиката на строке длины .
– трудоемость проверки предиката на строке длины .Пожалуй, самым важным недостатком алгоритма на основе проверяющих грамматик является то, что он не может обрабатывать гипотезы разной длины (которые могут возникнуть из-за ошибок сегментации: потеря или возникновение лишних символов, склейки и разрезания символов и т.п.), тогда как изменения гипотез вида “удаление символа”, “добавление символа”, или даже “замена символа парой” могут быть закодированы в модели ошибок алгоритма на основе WFST.
Однако быстродействие и простота использования (при работе с новым типом поля нужно просто дать алгоритму доступ к функции валидации значения) делают метод на основе проверяющих грамматик очень мощным инструментом в арсенале разработчика систем распознавания документов. Мы используем данный подход для большого количества разнообразных полей, таких как всевозможные даты, номер банковской карты (предикат – проверка Лун-кода), поля машинно-читаемых зон документов с контрольными суммами, и многих других.
Публикация подготовлена на основе статьи: Универсальный алгоритм пост-обработки результатов распознавания на основе проверяющих грамматик. K.Б. Булатов, Д.П. Николаев, В.В. Постников. Труды ИСА РАН, Т. 65, № 4, 2015, стр. 68-73.