Добрый день. Меня зовут Роман Ларчиков, я инженер по технической поддержке Docsvision. Данная статья подготовлена для тех, кого интересуют технические детали реализации масштабирования поиска и знакомство с работой Elasticsearch. В статье пойдёт рассказ о причинах использования ES, требованиях к системе, а также о преимуществах над поиском от MS SQL Server.
Если вам интересно в более общих чертах узнать о том, как мы масштабировали поиск в последней версии нашей платформы – об этом рассказывали мои коллеги на вебинаре «Docsvision ECM. Масштабирование поиска ElasticSearch».

Для начала, стоит отметить, что версия платформы Docsvision 5.5 принципиально отличается от предыдущих своей модульной архитектурой. В связи с этим нам необходимо было обеспечить возможность практически неограниченного масштабирования системы с сохранением скорости работы. В частности, требовалось получить возможность масштабирования сервиса индексации и при высокой скорости его работы.
В этой связи в версии Docsvision 5.5 появилась возможность использования внешних (сателлитных) баз данных. Теперь нет необходимости все данные хранить в рамках одной БД, которая при интенсивной работе ежедневно разрастается в объемах, что затрудняет процесс обслуживания БД, оперативность ее восстановления при падениях и замедляет в целом работу самой БД.
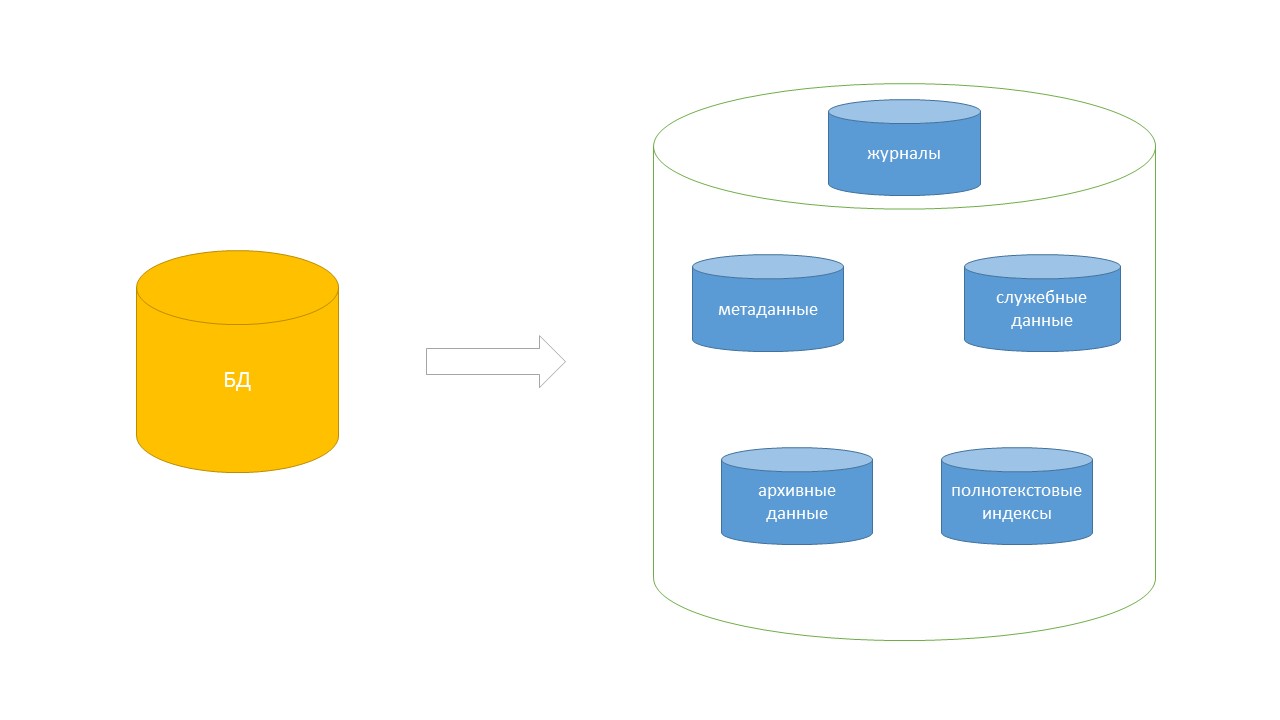
Использование одной БД для всего – плохо. Реализованная в Docsvision 5.5 возможность выноса данных в отдельные внешние БД позволяет правильно реструктурировать базу данных. Таким образом, если говорить о поиске, то данные индексации можно будет хранить уже за пределами основной БД, исключив влияние на её размер.
Удобство настройки, гибкость, надежность, масштабируемость, скорость индексирования и поиска в режиме онлайн – это всё про Elasticsearch.
Elasticsearch прекрасно ориентирован на работу с документами. После индексации мы можем выполнять поиск, сортировать, фильтровать данные, а не строки данных в столбцах. Что, в свою очередь, демонстрирует иной подход к поиску данных, и указывает на то, что Elasticsearch может выполнять сложный полнотекстовый поиск.
Документы представлены в виде объектов JSON. При этом сериализация (процесс перевода какой-либо структуры данных в последовательность бит) JSON поддерживается большинством языков программирования и является уже стандартным форматом для NoSQL.
Elasticsearch — это масштабируемый полнотекстовый поисковый движок с открытым исходным кодом, использующий библиотеку Lucene и написанный на Java. Описание всех преимуществ этого движка доступно на официальном сайте.
Он предназначен для сложных поисков по базе документов/файлов. В базе данных Elasticsearch таблицы называются индексами, а процесс загрузки документов — индексированием.
Можно его считать и не реляционным хранилищем документов в формате JSON, и поисковой системой на базе полнотекстового поиска Lucene. Официальные клиенты доступны на Java, NET (C#), Python, Groovy, JavaScript, PHP, Perl, Ruby.
ES разрабатывается компанией Elastic вместе со связанными проектами, называемыми Elastic Stack — Elasticsearch, Logstash, Beats и Kibana.
За хранение и поиск данных отвечает Elasticsearch (далее для краткости в статье будем называть его ES).
В Docsvision 5.5 есть возможность выбора, с каким поисковым движком работать. В этой статье сделаю акцент на использовании поискового движка Elasticsearch и расскажу о его преимуществах над поиском от MS SQL Server.
Основные преимущества:
ES можно развернуть не только на высокопроизводительных серверах, но и на ноутбуке. Но если речь идет о продуктивной среде, то стоит использовать отдельный сервер и придерживаться некоторых рекомендаций, которые стоит учесть.
Наиболее критичным ресурсом для ES является оперативная память. Это первостепенный ресурс, который вероятнее всего закончится первым. Минимальный допустимый размер — 8Gb, рекомендуемый — от 16 до 64 Gb. Допускается больше, если в этом действительно есть необходимость.
Сортировка и агрегация могут потреблять большое количество памяти, поэтому важно иметь достаточный её запас. Машина с 64 ГБ оперативной памяти — идеальное решение, но машины с 32 ГБ и 16 ГБ также распространены. Если на машине установлено 8 Гб и менее, это может привести к обратным результатам (в конечном итоге вам может потребоваться несколько таких «маленьких» машин). Использование более 64 Гб тоже имеет свои особенности.
ES, как правило, не имеет больших требований к процессору, поэтому его выбор имеет меньшее значение, чем другие ресурсы.
Но стоит придерживаться правила. Выбирать стоит современный процессор с несколькими ядрами. Как правило, сервера в кластере используют двух-восьмиядерные машины.
Если стоит выбор между более быстрыми процессорами или процессорами с несколькими ядрами, стоит выбирать последние. Дополнительный параллелизм, предлагаемый несколькими ядрами, даст больший результат, нежели чуть более высокая тактовая частота.
Диск – также важный ресурс для быстрой работы ES. Он важен при использовании кластера и вдвойне важен для кластеров с большими объёмами индексируемых данных.
Диски являются самой медленной подсистемой на сервере, а это означает, что кластеры с интенсивной записью могут оказывать высокую нагрузку на диски, что, в свою очередь, становится узким местом сервера. Если имеется возможность использовать твердотельные накопители, то необходимо использовать именно их, т.к. они намного превосходят любые вращающиеся носители. Узлы с SSD-поддержкой имеют заметное повышение производительности как запросов, так и индексации.

Если предполагается использование жестких дисков (HDD), то желательно использовать высокопроизводительные серверные диски (диски со скоростью вращения шпинделя 15000 об/мин).
Использование RAID 0 — эффективный способ увеличения скорости диска как для вращающихся дисков, так и для SSD. Нет необходимости использовать варианты RAID с зеркальным отображением или контролем четности, поскольку высокая доступность встроена в ES через реплики.
Если используются твердотельные накопители, то стоит убедиться, что планировщик ввода-вывода операционной системы настроен правильно. Когда происходит запись данных на диск, планировщик ввода/вывода решает, когда эти данные действительно отправляются на диск. В большинстве случаев по умолчанию используется планировщик cfq (полностью честная очередь).
Этот планировщик распределяет временные интервалы для каждого процесса, а затем оптимизирует доставку этих различных очередей на диск. Он оптимизирован для работы с HDD: характер вращающихся пластин означает, что более эффективно записывать данные на диск в зависимости от физического расположения.
Однако это неэффективно для твердотельных накопителей, поскольку в них не используются вращающиеся пластины. Вместо этого следует использовать крайний срок или noop. Планировщик крайнего срока оптимизирует в зависимости от того, как долго ожидали записи, тогда как noop — это просто простая очередь FIFO.
Эти простые изменения могут существенно улучшить пропускную способность при записи с помощью правильного планировщика.
Быстрая и надежная сеть важна для производительности в распределенной системе. Низкая задержка гарантирует, что узлы могут легко обмениваться данными, а высокая пропускная способность помогает перемещать и восстанавливать данные.
Современные сети центров обработки данных (1 GbE, 10 GbE) достаточны для подавляющего большинства кластеров.
Стоит избегать кластеров, которые охватывают несколько центров обработки данных, даже если центры обработки данных расположены в непосредственной близости. Определенно избегайте кластеров, которые охватывают большие географические расстояния.
Кластеры ES предполагают, что все узлы равны. Большие задержки, как правило, усугубляют проблемы в распределенных системах и затрудняют отладку и разрешение.
Стоит отдавать предпочтение «средним» и «большим» машинам, избегая низкопроизводительных машин, чтобы исключить издержки простого запуска ES. В то же время стоит избегать по-настоящему огромных машин: они часто приводят к несбалансированному использованию ресурсов (например, используется вся память, но не центральный процессор) и могут добавить логистическую сложность, если необходимо запустить несколько узлов на машину.
После того как мы выяснили, что такое Elasticsearch, его ключевые преимущества и требования для установки, можно приступать к самой установке ES для последующего конфигурирования в Docsvision.
О том как его установить и выполнить конфигурацию, а также проверить индексацию, т.е. работоспособность в Docsvision, читайте публикацию моего коллеги здесь.
Интересна тема? Тогда можно воспользоваться этой ссылкой и узнать ещё больше! А здесь можно зарегистрироваться на курсы.
Если вам интересно в более общих чертах узнать о том, как мы масштабировали поиск в последней версии нашей платформы – об этом рассказывали мои коллеги на вебинаре «Docsvision ECM. Масштабирование поиска ElasticSearch».
Почему Elasticsearch?
Для начала, стоит отметить, что версия платформы Docsvision 5.5 принципиально отличается от предыдущих своей модульной архитектурой. В связи с этим нам необходимо было обеспечить возможность практически неограниченного масштабирования системы с сохранением скорости работы. В частности, требовалось получить возможность масштабирования сервиса индексации и при высокой скорости его работы.
В этой связи в версии Docsvision 5.5 появилась возможность использования внешних (сателлитных) баз данных. Теперь нет необходимости все данные хранить в рамках одной БД, которая при интенсивной работе ежедневно разрастается в объемах, что затрудняет процесс обслуживания БД, оперативность ее восстановления при падениях и замедляет в целом работу самой БД.
Использование одной БД для всего – плохо. Реализованная в Docsvision 5.5 возможность выноса данных в отдельные внешние БД позволяет правильно реструктурировать базу данных. Таким образом, если говорить о поиске, то данные индексации можно будет хранить уже за пределами основной БД, исключив влияние на её размер.
Удобство настройки, гибкость, надежность, масштабируемость, скорость индексирования и поиска в режиме онлайн – это всё про Elasticsearch.
Elasticsearch прекрасно ориентирован на работу с документами. После индексации мы можем выполнять поиск, сортировать, фильтровать данные, а не строки данных в столбцах. Что, в свою очередь, демонстрирует иной подход к поиску данных, и указывает на то, что Elasticsearch может выполнять сложный полнотекстовый поиск.
Документы представлены в виде объектов JSON. При этом сериализация (процесс перевода какой-либо структуры данных в последовательность бит) JSON поддерживается большинством языков программирования и является уже стандартным форматом для NoSQL.
1. Знакомство с Elasticsearch
1.1. Что это такое?
Elasticsearch — это масштабируемый полнотекстовый поисковый движок с открытым исходным кодом, использующий библиотеку Lucene и написанный на Java. Описание всех преимуществ этого движка доступно на официальном сайте.
Он предназначен для сложных поисков по базе документов/файлов. В базе данных Elasticsearch таблицы называются индексами, а процесс загрузки документов — индексированием.
Можно его считать и не реляционным хранилищем документов в формате JSON, и поисковой системой на базе полнотекстового поиска Lucene. Официальные клиенты доступны на Java, NET (C#), Python, Groovy, JavaScript, PHP, Perl, Ruby.
ES разрабатывается компанией Elastic вместе со связанными проектами, называемыми Elastic Stack — Elasticsearch, Logstash, Beats и Kibana.
За хранение и поиск данных отвечает Elasticsearch (далее для краткости в статье будем называть его ES).
1.2. Преимущества поискового движка Elasticsearch в сравнении с поисковым движком MS SQL
В Docsvision 5.5 есть возможность выбора, с каким поисковым движком работать. В этой статье сделаю акцент на использовании поискового движка Elasticsearch и расскажу о его преимуществах над поиском от MS SQL Server.
Основные преимущества:
- Возможность сервиса индексации получать доступ к внешним хранилищам данным. При этом данные корректно индексируются и корректно выводятся при поиске. При использовании поискового движка SQL Server была возможность искать только по тем данным, которые хранятся в основной БД.
- ES — это opensource проект, и многие мировые компании его используют для поиска по огромным массивам данных.
- ES позволяет оперировать петабайтами данных, обрабатывая десятки миллиардов документов в индексах, при этом показывая высокую скорость.
- При росте объема данных можно провести масштабирование (кластеризацию). В отличие от ES, полнотекстовый движок SQL Server не имеет возможности масштабирования.
- ES по сути — это большая БД, где с помощью запросов мы получаем данные.
- ES умеет работать с разными запросами (простые, сложные, структурированные), с различными типами данных.
- Умеет делать агрегацию, проводить анализ, собрать сущности, закономерности и упростить поиск.
- Также к преимуществам ES можно отнести скорость поиска и быструю выдачу результатов. По индексам происходит быстрая выборка данных из базы и показ результата поиска.
- Высокая отказоустойчивость. Имеется механизм обнаружения проблем, позволяет найти проблемы в кластере, локализовать их, что, в свою очередь, обеспечивает высокую отказоустойчивость.
- Умеет работать с различными данными, будь то числа, текст, геоданные, структурированные и неструктурированные данные.
- ES легко разворачивается (более подробно ниже). С точки зрения Docsvision, поиск ES настраивается быстрее, чем поиск от SQL сервера.
- Скорость индексирования данных — большое преимущество над поиском SQL. Как только мы добавляем новую карточку, она сразу попадает в очередь на индексирование, и сервис работает в режиме онлайн, с небольшим периодом индексации. При использовании полнотекстового поиска мы могли задать периодичность индексирования или выполнять индексацию вручную, т.е. приходилось добавлять карточку, затем ждать момент индексации. Как правило, в крупных компаниях индексация настроена ежедневно на нерабочее время, т.е. информация в индексах появлялась только на следующий день. При использовании ES результат получаем практически сразу.
- БД не увеличивается в размерах при добавлении языков. В отличие от ES, при использовании полнотекстового поиска в MS SQL проиндексированные данные увеличивают размер основной базы данных, особенно если индексирование настроено на разные языки, к примеру, на русский/нейтральный/английский. В таком случае, рост таблиц индексирования увеличивается уже в несколько раз, нежели был бы выбран только один язык для индексирования, к примеру, нейтральный.
2. Требуемое ПО и системные требования для установки Elasticsearch
ES можно развернуть не только на высокопроизводительных серверах, но и на ноутбуке. Но если речь идет о продуктивной среде, то стоит использовать отдельный сервер и придерживаться некоторых рекомендаций, которые стоит учесть.
2.1. Оперативная память
Наиболее критичным ресурсом для ES является оперативная память. Это первостепенный ресурс, который вероятнее всего закончится первым. Минимальный допустимый размер — 8Gb, рекомендуемый — от 16 до 64 Gb. Допускается больше, если в этом действительно есть необходимость.
Сортировка и агрегация могут потреблять большое количество памяти, поэтому важно иметь достаточный её запас. Машина с 64 ГБ оперативной памяти — идеальное решение, но машины с 32 ГБ и 16 ГБ также распространены. Если на машине установлено 8 Гб и менее, это может привести к обратным результатам (в конечном итоге вам может потребоваться несколько таких «маленьких» машин). Использование более 64 Гб тоже имеет свои особенности.
2.2. Процессор
ES, как правило, не имеет больших требований к процессору, поэтому его выбор имеет меньшее значение, чем другие ресурсы.
Но стоит придерживаться правила. Выбирать стоит современный процессор с несколькими ядрами. Как правило, сервера в кластере используют двух-восьмиядерные машины.
Если стоит выбор между более быстрыми процессорами или процессорами с несколькими ядрами, стоит выбирать последние. Дополнительный параллелизм, предлагаемый несколькими ядрами, даст больший результат, нежели чуть более высокая тактовая частота.
2.3. Диск
Диск – также важный ресурс для быстрой работы ES. Он важен при использовании кластера и вдвойне важен для кластеров с большими объёмами индексируемых данных.
Диски являются самой медленной подсистемой на сервере, а это означает, что кластеры с интенсивной записью могут оказывать высокую нагрузку на диски, что, в свою очередь, становится узким местом сервера. Если имеется возможность использовать твердотельные накопители, то необходимо использовать именно их, т.к. они намного превосходят любые вращающиеся носители. Узлы с SSD-поддержкой имеют заметное повышение производительности как запросов, так и индексации.
Если предполагается использование жестких дисков (HDD), то желательно использовать высокопроизводительные серверные диски (диски со скоростью вращения шпинделя 15000 об/мин).
Использование RAID 0 — эффективный способ увеличения скорости диска как для вращающихся дисков, так и для SSD. Нет необходимости использовать варианты RAID с зеркальным отображением или контролем четности, поскольку высокая доступность встроена в ES через реплики.
2.4. Планировщик ввода/вывода
Если используются твердотельные накопители, то стоит убедиться, что планировщик ввода-вывода операционной системы настроен правильно. Когда происходит запись данных на диск, планировщик ввода/вывода решает, когда эти данные действительно отправляются на диск. В большинстве случаев по умолчанию используется планировщик cfq (полностью честная очередь).
Этот планировщик распределяет временные интервалы для каждого процесса, а затем оптимизирует доставку этих различных очередей на диск. Он оптимизирован для работы с HDD: характер вращающихся пластин означает, что более эффективно записывать данные на диск в зависимости от физического расположения.
Однако это неэффективно для твердотельных накопителей, поскольку в них не используются вращающиеся пластины. Вместо этого следует использовать крайний срок или noop. Планировщик крайнего срока оптимизирует в зависимости от того, как долго ожидали записи, тогда как noop — это просто простая очередь FIFO.
Эти простые изменения могут существенно улучшить пропускную способность при записи с помощью правильного планировщика.
2.5. Сеть
Быстрая и надежная сеть важна для производительности в распределенной системе. Низкая задержка гарантирует, что узлы могут легко обмениваться данными, а высокая пропускная способность помогает перемещать и восстанавливать данные.
Современные сети центров обработки данных (1 GbE, 10 GbE) достаточны для подавляющего большинства кластеров.
Стоит избегать кластеров, которые охватывают несколько центров обработки данных, даже если центры обработки данных расположены в непосредственной близости. Определенно избегайте кластеров, которые охватывают большие географические расстояния.
Кластеры ES предполагают, что все узлы равны. Большие задержки, как правило, усугубляют проблемы в распределенных системах и затрудняют отладку и разрешение.
2.6. Общие рекомендации
Стоит отдавать предпочтение «средним» и «большим» машинам, избегая низкопроизводительных машин, чтобы исключить издержки простого запуска ES. В то же время стоит избегать по-настоящему огромных машин: они часто приводят к несбалансированному использованию ресурсов (например, используется вся память, но не центральный процессор) и могут добавить логистическую сложность, если необходимо запустить несколько узлов на машину.
3. Заключение
После того как мы выяснили, что такое Elasticsearch, его ключевые преимущества и требования для установки, можно приступать к самой установке ES для последующего конфигурирования в Docsvision.
О том как его установить и выполнить конфигурацию, а также проверить индексацию, т.е. работоспособность в Docsvision, читайте публикацию моего коллеги здесь.
Интересна тема? Тогда можно воспользоваться этой ссылкой и узнать ещё больше! А здесь можно зарегистрироваться на курсы.


evnuh
Наконец-то появился перевод главной страницы сайта ES на хабре, давно ждал!