
Примерно 1-1,5 года назад Spring Webflux был на хайпе. Практически на любой Java-конференции можно было встретить доклады по Webflux, реактивному программированию, где-то даже проскакивали доклады про RSocket. Выступлений было много, сообщество маленькое, работающих проектов еще меньше. Возможно, тому виной была достаточно сырая технология в мире Spring и отсутствие поддержки со стороны многих модулей экосистемы, но мы рискнули.
Меня зовут Александр, я техлид в команде кабинета участника сделки в ДомКлике. В этой статье я не буду пересказывать документацию по Spring Webflux, она есть и очень подробная. А расскажу о том, как мы полностью перешли на реактивное программирование в нашем проекте, что нас сподвигло на это, и что в итоге получилось.
Вступление
Шёл 2018 год…
У нас примерно 700 (микро)сервисов, применяющих различные технологии и написанных на разных языках программирования. Часть сервисов скрыта от внешнего взора, тогда как другая часть является фронт-офисом для наших клиентов. Одним из таких (микро)сервисов мы и являемся.
Технологический стек не представляет чего-то необычного для 2018 года: это контейнер сервлетов (Tomcat), Spring Framework (webmvc, data, hibernate, resttemplate и дальше по списку), PostgreSQL в качестве хранилища и RabbitMQ для асинхронного взаимодействия (+ кластер ELK для журналирования). В качестве CI/CD у нас Jenkins, где это всё собирается, пакуется в Docker и доставляется в кластер Kubernetes.
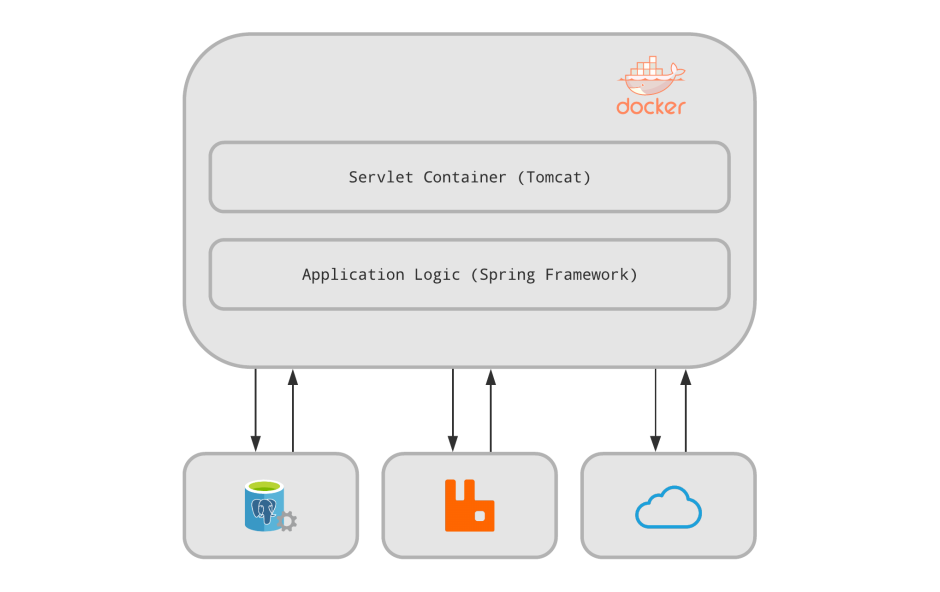
Мы не являемся высоконагруженным сервисом и обслуживаем в довольно спокойном темпе около 30-40 запросов в секунду на трёх активных подах (по 1 процессору и 2 Гб ОЗУ). Так мы беспроблемно существовали, развивали продукт и добавляли новую функциональность, пока не столкнулись с проблемами, о которых никто и не задумывался…
Первые звоночки
В один прекрасный день мы начали ловить в K8s перезагрузки по liveness probe.
Liveness probe сервиса был настроен таким образом, что учитывал доступность базы данных (SELECT 1) и использовал общий с приложением datasource и пулл коннектов. Расследование инцидента показало, что при очередной проверке K8s мы не могли получить подключение из пулла и возвращали ошибки, что приводило к перезагрузке поды.
Сначала мы вынесли liveness probe на выделенный datasource, и перезагрузки прекратились. Новый удар прилетел с другой стороны: теперь нам не хватало свободных подключений в пулле для обработки рядовых запросов. Мы начали анализировать код приложения, чтобы понять первоисточник проблемы.
Оказалось, у нас много мест в коде, где мы в рамках транзакционных методов вызывали блокирующие операции, поэтому подключения к базе удерживались дольше. Там, где это было возможно, мы вынесли внешние обращения за пределы транзакции, но кардинально ситуация не улучшилась. Любое отклонение длительности ответа внешнего ресурса от «нормы» вело к тому, что для новых запросов просто не хватало свободных подключений к базе. Начинали копиться запросы на уровне Tomcat, довольно быстро мы пересекали верхнюю границу в 200 запросов и вставали в очередь, начинались отказы в обслуживании (таймауты).
Другие (микро)сервисы тоже не стояли на месте — росли, развивались, менялись профили их нагрузки, поэтому длительность ответов начала расти. Постоянно масштабировать размер пулла подключений к базе тоже не вариант: открывать и держать подключение к PostgreSQL довольно дорого, к тому же начинаются проблемы с синхронизацией локальных копий данных с реальными. И мы решили выбросить всё в мусор и начать с чистого листа.
Время рефакторинга
Первая проблема в списке — отказ от локальных копий данных, которые постоянно расходятся с реальными (необходимость в собственном хранилище вообще была под сомнением). Компания активно переходит на микросервисную архитектуру, а мы до сих пор храним у себя локально данные, которые переехали в целевые сервисы. Начались проблемы с синхронизацией этих данных и поддержкой в актуальном состоянии.
Нам необходимо было увеличить количество внешних взаимодействий, что могло вызвать ряд проблем, которые нужно учитывать на раннем этапе.
Как всем известно, при использовании servlet мы получаем многопоточную, блокирующуюся систему, которая обрабатывает запросы с помощью отдельного потока для каждого подключения.

Количество потоков в приложении напрямую зависит от количества запросов к системе, но не только. Так как I/O-операции блокируют текущий поток, то любой затык внешнего ресурса экспоненциально увеличивает количество потоков в приложении (так как внешние вызовы продолжают поступать), что рано или поздно приведет к откидыванию запросов по таймауту и снижению доступности системы (Servlet < 3.1 — рано или поздно кончатся потоки у контейнера приложений; Servlet 3.1 поддерживает nio, но приложение начнёт пухнуть по памяти и процессору, и погрязнет в переключениях контекста). Ситуация стала критической когда rediness/liveness probe уже не мог пробиться через очередь подключений.
Мы начали смотреть в сторону альтернативных подходов.
Полной противоположностью императивному программированию на servlet является реактивное программирование — это парадигма асинхронного программирования, связанная с потоками данных и распространением изменений. Одной из её реализаций на JVM является Project Reactor, на основе которого построен Spring Webflux.

При таком подходе не было необходимости плодить потоки в приложении, мы работали с фиксированным количество потоков (Event Loop), обрабатывающих события в порядке очереди. В качестве аналога можно привести классическое асинхронное программирование, но лишенное callback hell. Мы перестали блокироваться, вся система перестала зависеть от скорости внешних ресурсов и стала отзывчивей.
Вторая проблема — слишком объемные ответы. При использовании servlet'ов мы старались снизить количество обращений к бэкенду за данными, по максимуму насыщая ответы информацией (это не было проблемой, потому что у нас были копии в базе). Переходя на сбор данных по внешним сервисам нам необходимо было на один запрос клиента обратиться к 5-6 внешним системам. Причем большинство запросов были последовательными, что ожидаемо начало драматически сказываться на скорости ответа клиенту. Выход из ситуации — раздробить один большой запрос на кучку мелких, перекладывая ответственность за сбор данных на потребителя. Мы «искусственно» увеличили частоту запросов к бэкенду, но это уже не было проблемой, потому что мы перестали блокироваться и плодить потоки, а фронтенд мог эффективно распараллеливать запросы и запрашивать только ту информацию, которая его интересует в данный момент.
Третья проблема, как следствие предыдущей — сложность логики формирования ответа. И нам, и потребителям необходимо было учитывать, что часть ответа может быть пустой из-за недоступности источника. Это усложняло логику бэкенда и фронтенда, а порой делало сервис полностью недоступным для клиента.
Жизнь после рефакторинга
К лету 2019 года все запросы с фронтенда нашего кабинета уже шли к новому бэкенду, нагрузка выросла примерно в 2-3 раза по сравнению со старой версией (мы увеличили количество запросов). На текущий момент мы в production уже практически год, и вот некоторые результаты:
- У нас не было ни одного отказа из-за приложения (были инфраструктурные проблемы, не более).
- Из всех сервисов ДомКлик наш кабинет сейчас показывает самое низкое время до отображения (конечно, не без помощи коллег из фронтенда).
- Практически отсутствуют отказы в обслуживании запросов.
- Мы стали меньше зависеть от внешних сервисов. Даже если какой-то из них отказывает, мы продолжаем показывать работоспособную часть кабинета.
- Синтетические тесты показали, что мы можем держать до 1000 запросов в секунду без драматического увеличения времени ответа при текущей конфигурации (3 поды по 1 процессору и 1,5 Гб ОЗУ). Но в реальности мы, к сожалению, упираемся в быстродействие смежных систем.

В каждой бочке есть...
В завершение я бы хотел немного рассказать о проблемах и сложностях, с которым мы столкнулись.
Блокирующие вызовы
Если у тебя фиксированный event loop, который отвечает за обработку всего и вся, то любая случайная блокировка этого потока моментально приводит к фатальным последствиям. Необходимо убедиться, что используемая функциональность не блокирующая. А если всё-таки блокирующая, то не забывать уводить выполнение в соответствующий scheduler (обычно Elastic). Для поиска блокирующих вызовов есть полезный инструмент Blockhound.
Отсутствие поддержки реляционных баз
К моменту написания этой статьи проблема уже неактуальна, потому что вышла стабильная версия драйвера R2DBC. Но когда его не было, проект пришлось перевести на MongoDB, либо мучиться с отдельным пуллом потоков для взаимодействия с БД.
Отладка
Логи важны, особенно когда произошло что-то неожиданное. Это необходимое средство отладки. Если вы начинаете писать проект на Spring Webflux, то будьте готовы к тому, что придется подключать к приложению дополнительный агент — Reactor Debug Agent (и в проде тоже), иначе логи будут выглядеть так:
Запрещено для детей, беременных женщин, пожилых и людей с заболеваниями сердца
java.lang.IndexOutOfBoundsException: Source emitted more than one item
at reactor.core.publisher.MonoSingle$SingleSubscriber.onNext(MonoSingle.java:129)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.tryEmitScalar(FluxFlatMap.java:445)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onNext(FluxFlatMap.java:379)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onNext(FluxMapFuseable.java:121)
at reactor.core.publisher.FluxRange$RangeSubscription.slowPath(FluxRange.java:154)
at reactor.core.publisher.FluxRange$RangeSubscription.request(FluxRange.java:109)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.request(FluxMapFuseable.java:162)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onSubscribe(FluxFlatMap.java:332)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onSubscribe(FluxMapFuseable.java:90)
at reactor.core.publisher.FluxRange.subscribe(FluxRange.java:68)
at reactor.core.publisher.FluxMapFuseable.subscribe(FluxMapFuseable.java:63)
at reactor.core.publisher.FluxFlatMap.subscribe(FluxFlatMap.java:97)
at reactor.core.publisher.MonoSingle.subscribe(MonoSingle.java:58)
at reactor.core.publisher.Mono.subscribe(Mono.java:3096)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:3204)
at reactor.core.publisher.Mono.subscribe(Mono.java:3090)
at reactor.core.publisher.Mono.subscribe(Mono.java:3057)
at reactor.core.publisher.Mono.subscribe(Mono.java:3029)
...
Польза от такого лога сомнительна, своего кода в трассировке стека вы не увидите.
Если вы привыкли использовать АРМ и это не New Relic/Dynatrace или другие коммерческие мастодонты, то можете выкинуть его сразу — адекватной инструментации Netty и Spring Webflux практически нигде нету.
Качество кода
Реактивный подход заставляет писать код по-другому. Если вы привыкли писать в императивном стиле и, не дай бог, в enterprise-стиле, то перестроится довольно сложно. При оформлении кода в виде стримов неудобно реализовывать сложную логику, логику с ветвлением или пробрасывать какое-либо значение из начала в конец стрима. Приходится пристальнее следить за качеством кода, а программистам — перестраиваться. У нас поначалу выходило так себе…
Еще не самый худший пример
Flux.fromIterable(participants)
.flatMap { participant -> getPerson(participant).map { PersonInfo(participant, it) } }
.collectList()
.flatMapMany { recipients ->
val borrower = recipients
.filter { it.participant.role == ParticipantRole.BORROWER }
.map { it.person }
.firstOrNull() ?: throw BusinessException(SystemError.BORROWER_NOT_FOUND)
recipients
.filter { if (currentParticipant == null) true else currentParticipant.casId == it.participant.casId }
.distinctBy { it.person.confirmedPhone }
.toFlux()
.flatMap { recipient ->
val template = templateMapping.getValue(recipient.participant.role)
createNotification(dealId, message, borrower, template, recipient.person)
}
}
.flatMap { notification ->
logger.info { "Sending sms $notification to ${notification.recipient.casId}" }
notificationClient.send(notification).map {
notification
}
}
.onErrorContinue { exception, obj ->
handleException(obj, message, exception)
}
.onErrorResume {
handleException(null, message, it)
Flux.empty()
}
С выходом Spring Boot 2.2.0 разработчики добавили поддержку Kotlin Coroutines взамен Flux/Mono, и стало намного удобнее писать, читать и поддерживать код. Сейчас мы активно переходим на корутины и, вполне вероятно, опишем свой опыт в следующей статье.


ivanovdev
Спасибо за статью! Разве у томката нельзя настроить размер тред пула и если он весь исчерпан складывать сообщения в очередь на обработку?
1nDivid Автор
Конечно можно, но если внешние ресурсы деградируют, то это как снежный ком (старые запросы в ожидании, новые порождают еще большую нагрузку на внешние системы). Очередь будет разрастаться и коннекты начнут отпадать по таймауту на уровне клиента/nginx так и не попав в обработку.
Проблема еще кроется в том, что очередь общая и есть запросы, которые не требуют обращения к внешним ресурсам и быстро обрабатываются. Они также начнут падать. Особенно остро это касается health-чеков k8s, которые отваливались находясь в очереди и прибивали поду.
sved
Так это у вас с перфомансом проблемы были, а не с потоками.
Почитайте что-нибудь по теории массового обслуживания.
Очередь может увеличиваться, только если ресурсов меньше, чем требуется.
Надо было открыть профайлер и разобраться почему 40 запросов в секунду, которые не считают параметры чёрных дыр, так нагружают сервера
И правильно, что health-check прибивается — какой же это health, хотя «быстрые» запросы можно на уровне прокси пропускать.
Я уверен, что пока вы свою архитектуру переделывали, кто-то в вашей команде тупо пофиксил перформанс. А вы этого даже и не заметили.
Параллельные запросы просто убили. Это же настоящий антипаттерн — противоположность паттерну DTO
dvmaslov
При нормальных условия все работает хорошо, но, к сожалению, мир не идеален и в любой момент что-то может пойти не так, например деградация одного или нескольких сервисов, к которым мы делаем запросы.
Конечно же можно залить это ресурсами, если таковых хватит, но эффективность использования ресурсов при этом упадет ниже плинтуса.
Если последовать вашему же совету и посмотреть информацию о потоках в момент проблемы, то можно увидеть кучу тредов которые просто ждут ответа от проблемного апстрима и, кроме этого, ничего полезного не делают.
Кстати, подобную, пусть и не такую драматическую картину с потоками можно увидеть и в нормальной ситуации, если у вас много внешних вызовов.
При использовании webflux и неблокирующих операций мы эффективнее используем потоки, они не висят в ожидании ответа от сервиса, но начинают обслуживать другие запросы и затуп одного апстрима не повлияет на скорость работы той части системы, которая с ним не связана.
Не понял, что же правильно в том, что рабочее приложение ложится по health check? Мы же тем самым только усугубляем ситуацию.
Что касается множества запросов, то этим мы:
sved
Ну вы точно также могли бы и на бэкенде подождать ответа и, если ответ не пришёл, то записать null в соответствующее поле DTO. Ваше решение выглядит как перекладывание проблем с бакэнда на UI.
У UI разработчиков и так (как правило) самая сложная работа, так теперь им ещё
надо ломать голову о том, как правильно ошибки обрабатывать от ваших 700 микросервисов.
dvmaslov
В общем случае null <> ошибка. Конечно, можно это обойти, но выглядеть это в модели данных будет не очень.
Основной набор данные фронт получает от одного бека, который в свою очередь при необходимости ходит к другим сервисам, поэтому с форматами ошибок проблем нет.
Подождать ответа на беке можно, но вы как-то забыли о клиенте в этой истории, а он будет все это время ждать отрисовки страницы, хотя ему возможно и не нужна та информация, которая предоставляется затупившим сервисом.
Вообще это конечно две крайности (1 эндпоит который тащит все vs 100500 эндпоинтов на каждый чих), а правда я считаю находится где-то посередине и это разумное разделение, при котором фронт может запросить ровно те данные, которые ему нужны в данный момент.
sved
Если сервис затупил, то ничего ждать не надо. Ваш сервис фасад просто пометит его как недоступный и не будет обращаться некоторое время.
Будет вместо актуальных данных какой-нибудь null вставлять, либо старые данные
1nDivid Автор
Отдача кэшированных данных для нас огромная проблема ибо каналов информирования клиента об изменении ключевых данных очень много и клиент, что логично, пытается зайти и увидеть эти данные. Если мы начнем после уведомления показывать старые данные — это проблема.
По circuit breaker.
Это все отлично работает при параллельных запросах, а не последовательных, логика формирования ответа, который зависит от нескольких источников очень сильно усложняется в ситуациях, когда вам нужно поддерживать более 1 версии API с разной логикой и форматом.