

Откройте для себя современные возможности ядра GNU/Linux, которые пригодятся вам для обеспечения мониторинга, наблюдаемости, безопасности, инжиниринга производительности и профилирования – всё это достижимо при помощи eBPF. Ниже будет разобрано несколько практических случаев и дана информация, касающаяся внутреннего устройства BPF.
❯ 1. Контекст и обоснование
IT-технологии развиваются изо дня в день, при этом постоянно усложняясь. Те вызовы, с которыми довелось столкнуться ещё десятилетие назад, сохраняются и сегодня, но теперь обременены новыми уровнями абстрагирования. То, что вчера было вполне осуществимо, сегодня осложнено новыми деталями реализации. Всё это требует кратко описать eBPF, внутреннее устройство ядра Linux, а также рассказать о других сопутствующих НИОКР-задачах.
Поскольку GNU/Linux широко применяется, можно предположить, что описанные здесь вещи можно воспроизвести, и они универсально применимы в энтерпрайзе и в сегменте SOHO.
1.1 Что такое eBPF
Аббревиатура eBPF означает ‘enhanced Berkeley Packet Filter’ («берклийский улучшенный фильтр пакетов») и, в принципе, является расширенной версией BPF. Что же тогда такое BPF? Инструмент BPF был написан ещё в 1992 году для анализа сетевого трафика. Он по-прежнему активно используется и предоставляет грубый интерфейс для обработки сетевых пакетов между всеми сетевыми устройствами и ядрами. BPF – это виртуальная машина внутри ядра Linux, и она выполняет код BPF в рамках режима ядра. Если вам когда-либо ранее доводилось работать с tcpdump, это значит, что и BPF вы уже пользовались.
1.2 С чего всё началось
Давным-давно была такая компания Sun Microsystems, располагавшая крайне продвинутой для своего времени операционной системой – называлась она Solaris (SunOS). Именно с этой операционной системы начинается история многих технологий, в частности, зон, файловой системы ZFS, пофайлового аудита, безопасных песочниц и DTrace.
Технология DTrace была многофункциональной и гибкой, она обеспечивала наблюдаемость системы, профилирование производительности, мониторинг безопасности. К сожалению, после того, как Sun Microsystems была приобретена Oracle, лицензия на исходный код изменилась, и больше никто не мог пользоваться технологиями Sun, не получив на это согласия от Oracle Corp.
Потеряв Solaris, неравнодушное сообщество постаралось придумать, как заново выстроить имевшийся инструментарий, который уже был очень популярен в среде больших предприятий и высоконагруженных систем. Предпринималось несколько попыток такого рода, которые, честно говоря, успехом не увенчались.
Только в версии Linux 3.18 eBPF была исходно включён в основную линию разработки, и это событие можно считать рождением eBPF.
❯ 2. eBPF и его возможности
eBPF – это ультрасовременная технология, встроенная в ядро Linux и позволяющая гонять в пространстве ядра программы, заключённые в песочницу (напр. в нулевом кольце защиты). Фильтр eBPF используется для совершенствования и расширения возможностей ядра без необходимости загружать в него какие-либо дополнительные модули и без какой-либо перекомпиляции ядра. Этот фильтр работает безопасно и надёжно.
Самое подходящее место, где в компьютере стоит реализовать безопасность, работу с сетью, мониторинг и профилировочный функционал — это ядро ОС. С другой стороны, ядра поддерживаются консервативно, так как ядро – это жизненно важная часть любой ОС. Поэтому разработка новых возможностей в любом ядре идёт сравнительно медленно, не говоря уже о той подоплёке для безопасности и о тех рисках, которые потенциально могут быть привнесены в ядро вместе с новыми возможностями.
eBPF меняет правила игры, так как предусматривает возможность выполнять программы ядра в режиме песочницы. С его помощью разработчики могут без труда расширять возможности ядра, и для этого не требуется писать драйверы и модули. Подсистема eBPF гарантирует безопасность и стабильность, так как использует динамический (JIT) компилятор и движок для проверки байт-кода.
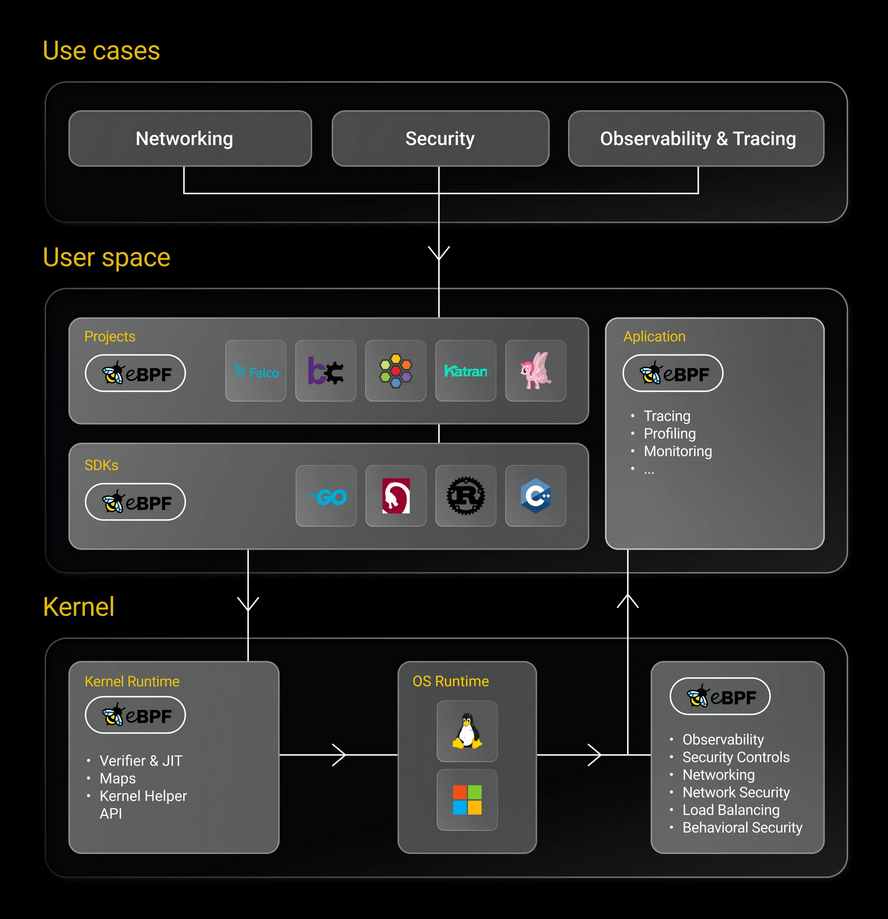
Рис. 1: типичная архитектура eBPF. (eBPF.io, 2022)
Вместе с eBPF появился целый флот нового софта, в том числе, программно-конфигурируемые сети (SDN), проекты по наблюдаемости, а также софт для обеспечения безопасности. Также эта технология покрывало множество предметных областей и практических случаев: обеспечение высокопроизводительной обработки пакетов, балансировки нагрузки, перехвата критически важных системных вызовов, отладки действующего софта и пр. В принципе, eBPF можно охарактеризовать как суперсилу Linux, высвобождающую безграничную креативность при решении задач любой сложности.
2.1 Обзор вариантов использования
Варианты использования eBPF можно сгруппировать на несколько категорий:
- Безопасность
- Профилирование и трассировка софта
- Работа с сетями (XDP)
- Мониторинг
Давайте подробнее рассмотрим некоторые из них.
2.2 Безопасность
eBPF позволяет пользователю перехватывать любые системные вызовы, а также даёт возможность обработать любой сетевой пакет и собирать на уровне сокетов информацию обо всех сетевых операциях. Так обеспечивается очень высокая производительность и открывается революционный способ конструирования систем для обеспечения безопасности и мониторинга. Ещё одно яркое достоинство – данная технология предоставляет пользователю (и собирает в одном месте) любую информацию о системных вызовах, сетевых событиях, аппаратных запросах на прерывания и т.д. Поэтому нет острой необходимости собирать целый паноптикум совершенно разных технологий, чтобы закрыть ту или иную зону из области безопасности.
2.3 Профилирование и трассировка софта
eBPF в полной мере позволяет прикрепляться к любому процессу, действующему в системе, получать доступ к стеку, куче и даже переменным из функций внутри действующей ОС. Также здесь предусмотрены пробы ядра, пользовательские пробы и точки трассировки. Система позволяет пользователю их перехватывать и предоставляет незамутнённый обзор всего того, что происходит во время выполнения. Также в eBPF есть встроенные статистические структуры данных, при помощи которых можно извлекать отладочную и трассировочную информацию без необходимости экспортировать конкретные данные куда-либо ещё.
2.4 Работа с сетью
Естественно, BPF был спроектирован для обработки сетевых пакетов в потоковом режиме. У eBPF возможности ещё шире, и он отлично подходит для обработки пакетов в рамках любого сетевого решения. При помощи eBPF пользователь может в два счёта соорудить конвейер для обработки, к которому потом можно надстроить синтаксические анализаторы пакетов и сетевую логику. Вишенка на торте здесь такова: обработка происходит ещё до того, как сам пакет добирается до сетевой подсистемы Linux. Например, именно так в Cloudflare снижается риск DDoS-атак, а в Meta организуется маршрутизация трафика.
2.5 Мониторинг
Дедовские мониторинговые решения в значительной степени опирались на статические точки трассировки и ряд точек перехвата в ОС — все они были публично доступны. eBPF, напротив, предоставляет возможность агрегировать в ядре и собирать пользовательские метрики, основываясь на различных источниках событий. Таким образом, конечному пользователю становится проще понять, какие действия системы проходят незамеченными для человека и ускользают от типичного системного мониторинга. Например, стандартный способ отслеживать ввод/вывод в системе – собирать метрики IOPS и, основываясь на выводе, заключать, деградируют ли массивы у вас на диске. Чтобы ещё лучше понять происходящее, желательно отслеживать множество уровней абстрагирования от уровня приложения до аппаратных прерываний на физическом диске. Именно для этого и нужен eBPF.
❯ 3. Как это работает?
В этой главе мы кратко рассмотрим основы eBPF. Если вы хотите подробнее познакомиться с eBPF, посмотрите следующее справочное руководство по BPF & XDP.
3.1 Что такое перехват?
eBPF работает на основе событий, и программа eBPF завладевает потоком управления, как только произойдёт определённое событие (происходит перехват) – например, поступит системный вызов, вызов функции, будет достигнута точка трассировки в ядре, произойдёт сетевое событие, т. д.
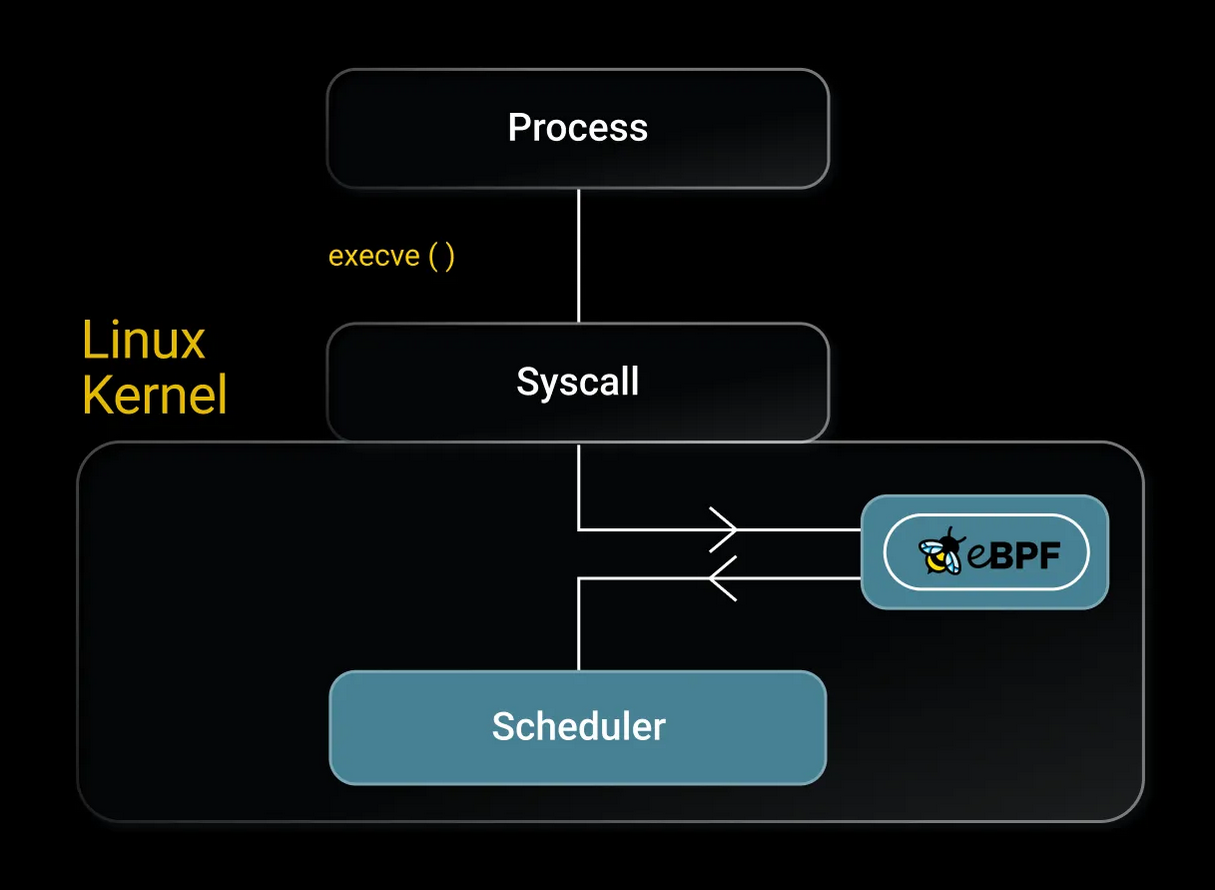

Рис. 2: Подрубаемся к системному вызову execve()
Перехваты обладают расширенной структурой, так что конечный пользователь может расширять список перехватов, создавая собственные пробы ядра (kprobe), пользовательские пробы (uprobe), чтобы прикрепляться к процессу выполнения где угодно в ядре или приложении из пользовательского пространства.
3.2 Архитектура eBPF
Существует множество способов вызывать и выполнять eBPF. Как правило, eBPF используется косвенно – то есть, выполняется программа, задействующая eBPF, например, Teleport, bcc или bpftrace, tcpdump, т.д. Тем не менее, конечный пользователь может писать на ассемблере для BPF, использовать псевдо-C или писать программы для eBPF на высокоуровневых языках, предварительно делая привязки к ним. Также существует целевая платформа для LLVM, позволяющая создавать байт-код BPF из C-подобного исходного кода.
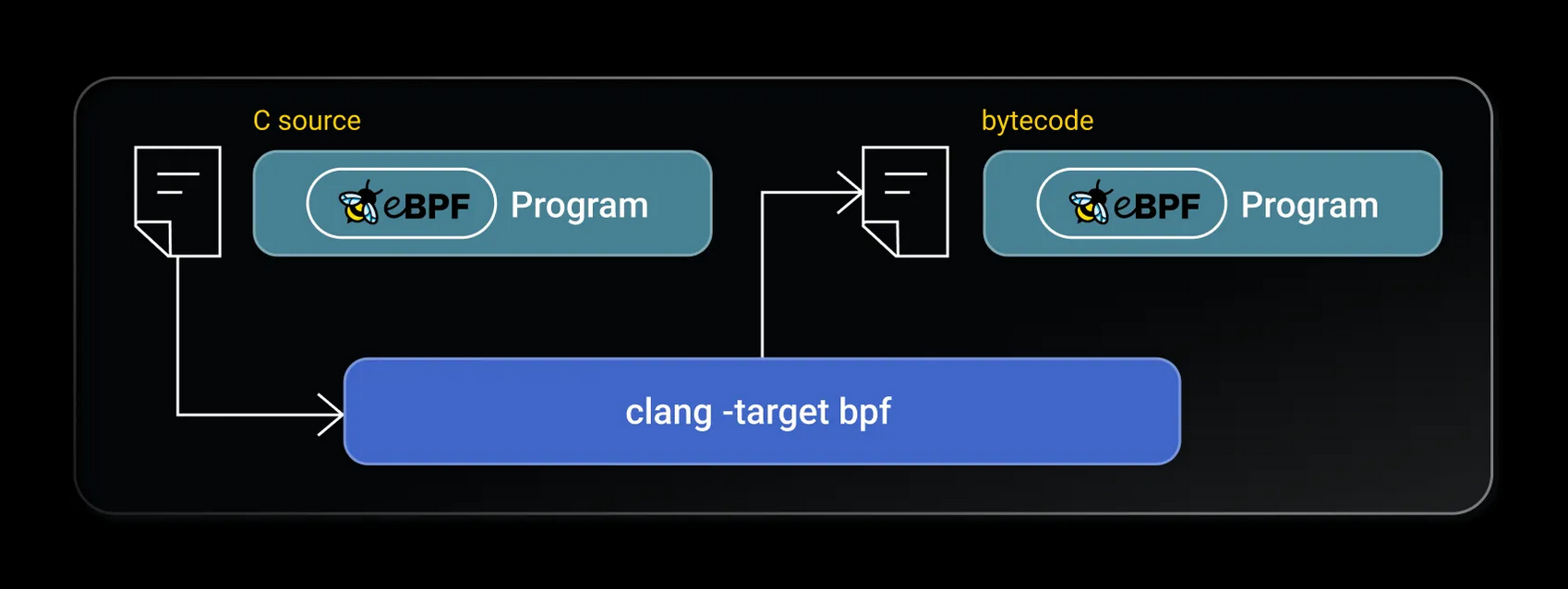
Рис. 3: Clang может компилировать байт-код eBPF
К моменту, когда целевой перехват уже определён, приложение eBPF загрузится в ядро – для этого используется специальный системный вызов BPF. Обычно это делается при помощи одной из доступных библиотек eBPF.
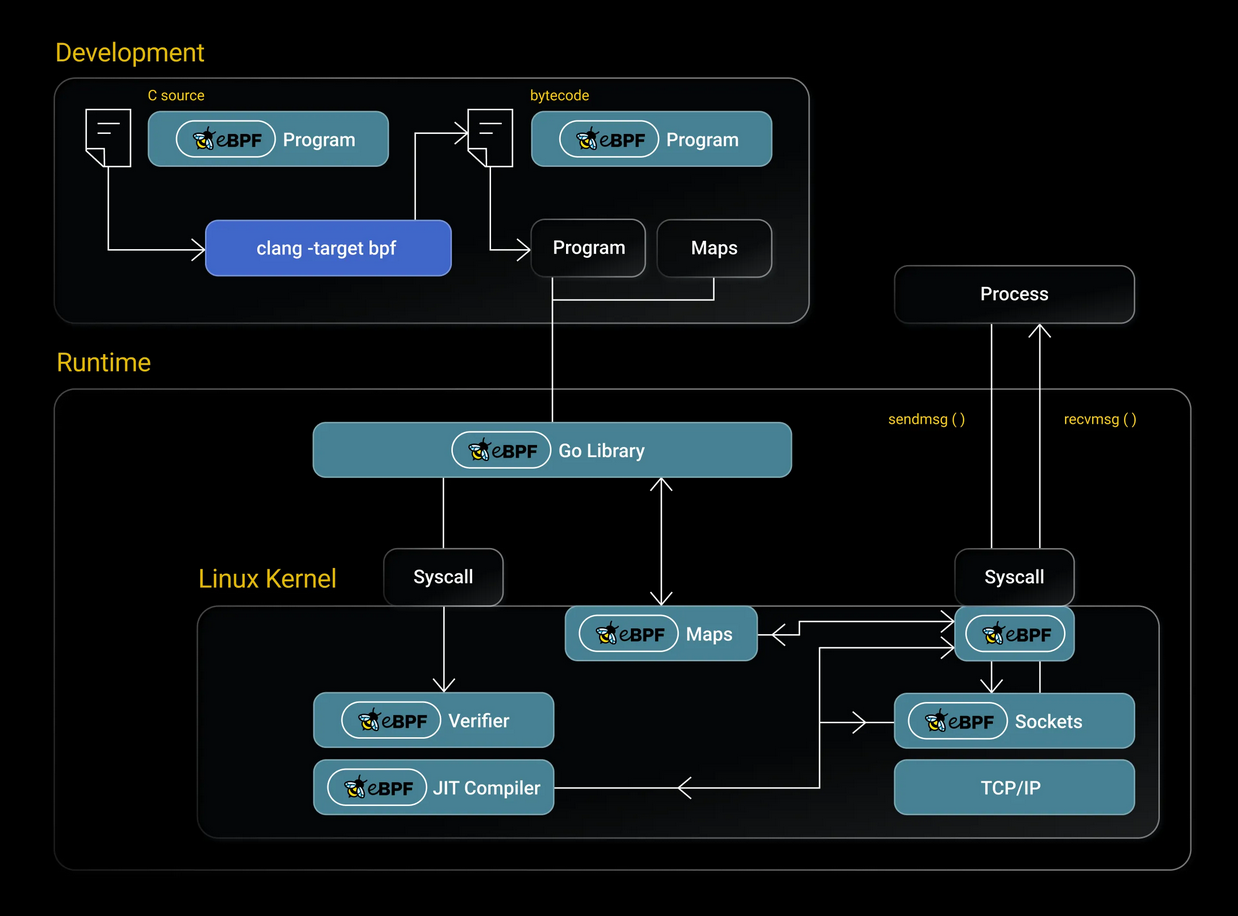
Рис. 4: Обзор, демонстрирующий, как программа eBPF переходит от исходного кода к байт-коду
Как показано на рис. 4, перед загрузкой байт-кода BPF в виртуальную машину ядра нужно преодолеть следующие шаги:
- Проверка
- Динамическая компиляция
Проверка
Универсальная встроенная в ядро виртуальная машина BPF гарантирует безопасность памяти и стабильность системы. Чтобы это обеспечить, любой скомпилированный байт-код должен гарантировать, что запуск программы eBPF безопасен. Для это нужно проверить, в самом ли деле приложение:
- Не стопорит или не обрушивает ядро;
- Предусматривает условие выхода (напр., в нём не содержится операторов while true);
- Обладает правильными CAP и достаточными привилегиями.
Динамическая компиляция
На данном этапе обычный байт-код BPF компилируется в машинно-специфичный ассемблерный код, чтобы ускорить выполнение программы. Динамическая компиляция позволяет выполнять приложения eBPF настолько же быстро, насколько и нативно скомпилированный код ядра, либо как код, скомпилированный в виде модуля ядра.
❯ 4. Опыт использования
Допустим, у вас в компании обширная инфраструктура. Вам нужно обеспечить, что она будет в безопасности и при этом будет как следует мониториться. Вам известно о многочисленных успешных проектах с использованием eBPF в различных компаниях от Cloudflare до Meta. Итак, давайте выясним, чего можно добиться при помощи eBPF в продакшене. На рис. 5 подчёркнуто, что в принципе достижимо при помощи eBPF от аппаратного уровня вплоть до уровня приложений.

Рис. 5. Обзор инструментария eBPF (Gregg, 2019)
Показанные здесь списки, указывающие на каждый блок – это, как правило, программы bpftrace(3) или bcc(4), готовые к использованию. Они послужат хорошей отправной точкой, если вы хотите попробовать eBPF на вашем практическом примере. Просто установите bpftrace и bcc в вашем дистрибутиве Linux – и можете сразу переходить к /usr/share/{bcc, bpftrace}/.
Допустим, нам нужно пронаблюдать исходящие TCP-соединения. Для этого можно подрубиться к пробе ядра — tcp_connect. Выполните либо tcpconnect.bt из bpftrace, либо tcpconnect из bcc.

Рис. 6: tcpconnect отслеживает исходящие TCP-соединения
Рассмотрим другой пример: давайте проанализируем трафик, защищённый SSL-шифрованием, не изменяя при этом сертификатов. Чтобы этого добиться, можно подключаться к функциям шифрования/дешифрования functions.
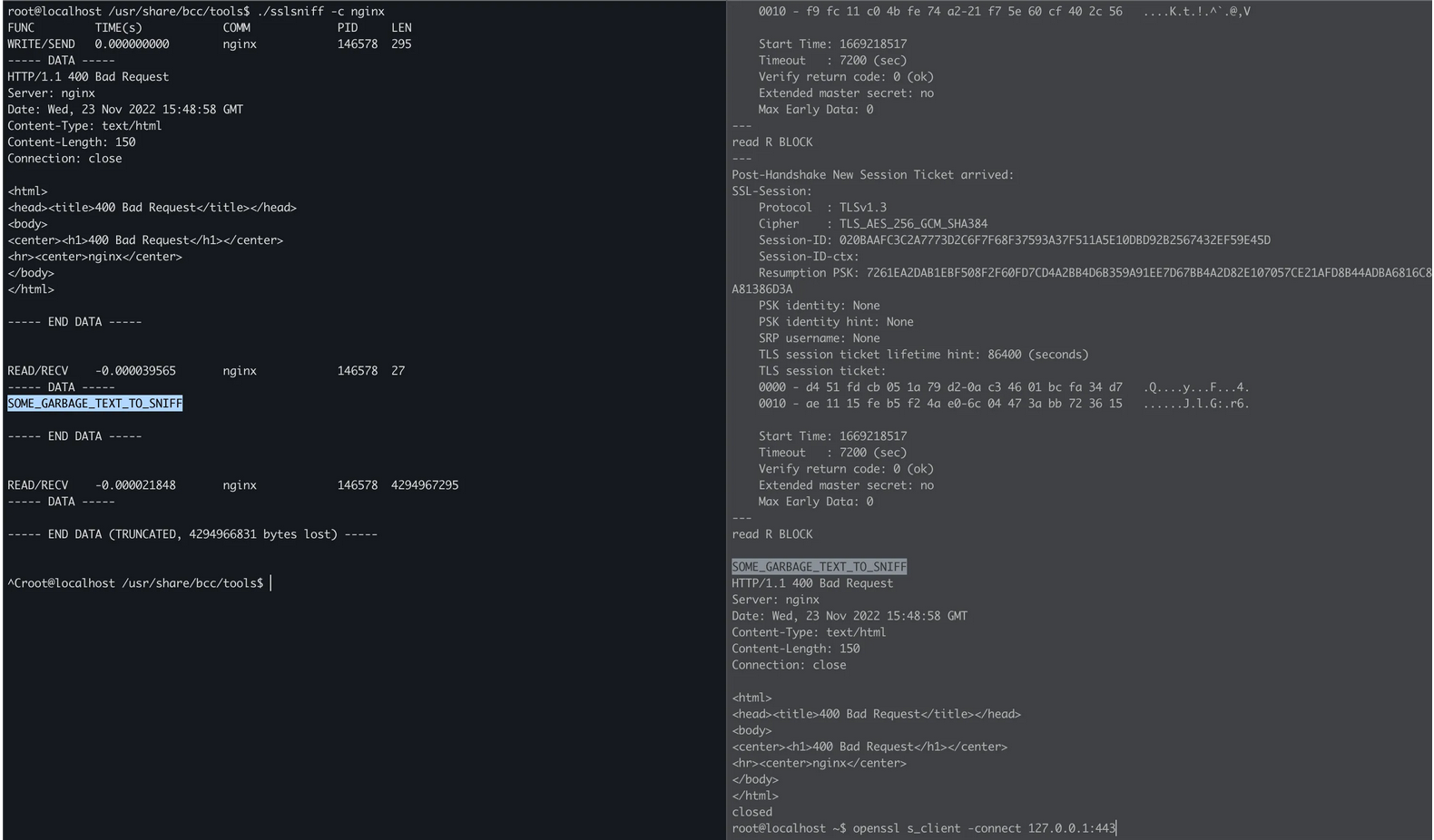
Рис. 7: Атакуем трафик методом «человек посередине», не компрометируя цепочку доверия (CA-chain)
Поскольку eBPF очень эффективен, он обставит любой инструмент обеспечения безопасности, использующий какой-либо иной механизм для входа в систему, перехвата и отслеживания активности системы.

Рис. 8: мониторинг выполнения файлов
Мы не ставим своей целью подчеркнуть все и каждую возможности, имеющиеся у eBPF, так что давайте перейдём к практике и обратим внимание на некоторые практически случаи.
5 eBPF в компании Exness
В компании Exness используется очень современный технологический стек, обеспечивающий многогранность и гибкость при эксплуатации. Здесь применяется Kubernetes, кластеры высокой доступности и распределённые базы данных. Все сливки IT-индустрии по состоянию на 2022 год. Но за всё приходится платить. Так, за приобретённые преимущества компания платит сложной инфраструктурой и множеством слоёв абстрагирования.
В данном случае команда безопасников должна отслеживать активность системы на множестве уровней – от ОС и вплоть до активности контейнеров. В каждом слое, накатываемом сверху, есть свои причуды и нюансы. С учётом всех ограничений и после обширного исследования рынка пришлось признать, что нет такого решения, которое идеально отвечало бы всем целям.
Поэтому было решено развивать наиболее доступное и удобное в поддержке решение — Tetragon. Согласно краткой характеристике:
Tetragon – это мощная платформа на основе eBPF, предназначенная для обеспечения наблюдаемости и регулирования среды выполнения …
Это так. Tetragon – это самодостаточный программный пакет, проросший в глубины проекта Cilium. Предпочтение было отдано Tetragon благодаря его расширяемости, мощности eBPF, тому, что инструмент написан на Go, а также прямо из коробки приспособлен к работе с контейнерами.
Команда сделала форк Tetragon, чтобы расширить его функционал с учётом внутрикорпоративных требований к безопасности.
Для каждого process_exec вычисляется двоичный хеш, после чего результат кэшируется (см. рисунок 9), чтобы не приходилось снова и снова вычислять хеш и не нагружать ЦП сверх меры.

Рис. 9: Событие при выполнении процесса. Показан двоичный хеш.
Итак, Tetragon «из коробки» умеет работать с контейнерами, но он не предназначается для извлечения контейнерных метаданных с хост-машины. В то же время, приходилось спланировать использование Tetragon как на хост-машинах, так и в качестве прицепа на развёрнутых инстансах Kubernetes. Поэтому команда реализовала сбор контейнерных данных, а также наладила обогащение событий из этих контейнеров.
При этом использовался клиент на Go для движка Docker. Есть метод ContainerInspect, возвращающий информацию о контейнере.
Получив контейнерные метаданные, можно пройти через файловую систему контейнера и собрать всю полезную информацию – например, uid, системные умолчания, софтверный список материалов и пр.
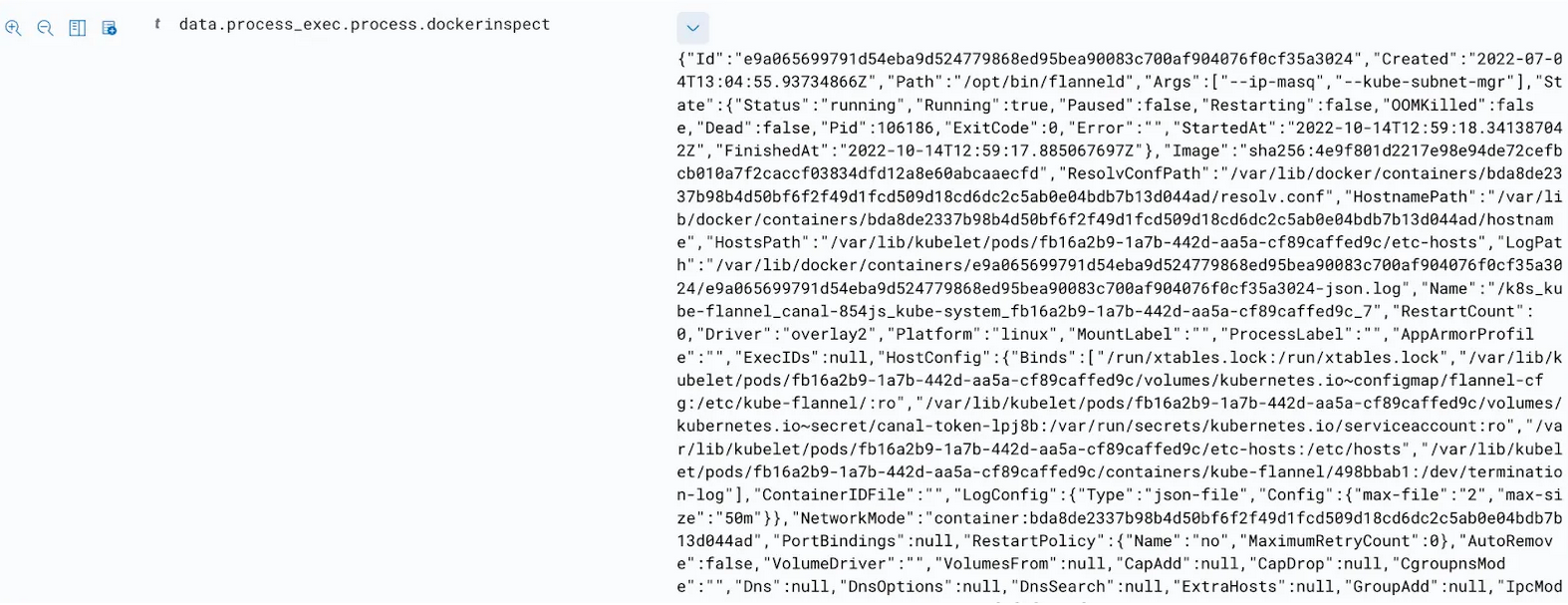
Рис. 10: Контейнерные метаданные, собираемые Tetragon на хост-машине с контейнером.
В инфраструктуре Exness ежедневно генерируется объём событий в сотни гигабайт. Можно было бы использовать фильтрационные механизмы либо на уровне программы BPF, либо на уровне выходного фильтра. Обоими этими вариантами было решено пренебречь, так как приходится иметь дело с гигабайтами в минуту и даже в секунду. Вот почему команда реализовала собственный фильтр на уровне ядра. Теперь команда фильтрует огромные объёмы событий через Tetragon непосредственно перед отправкой информации на сервер сбора событий.
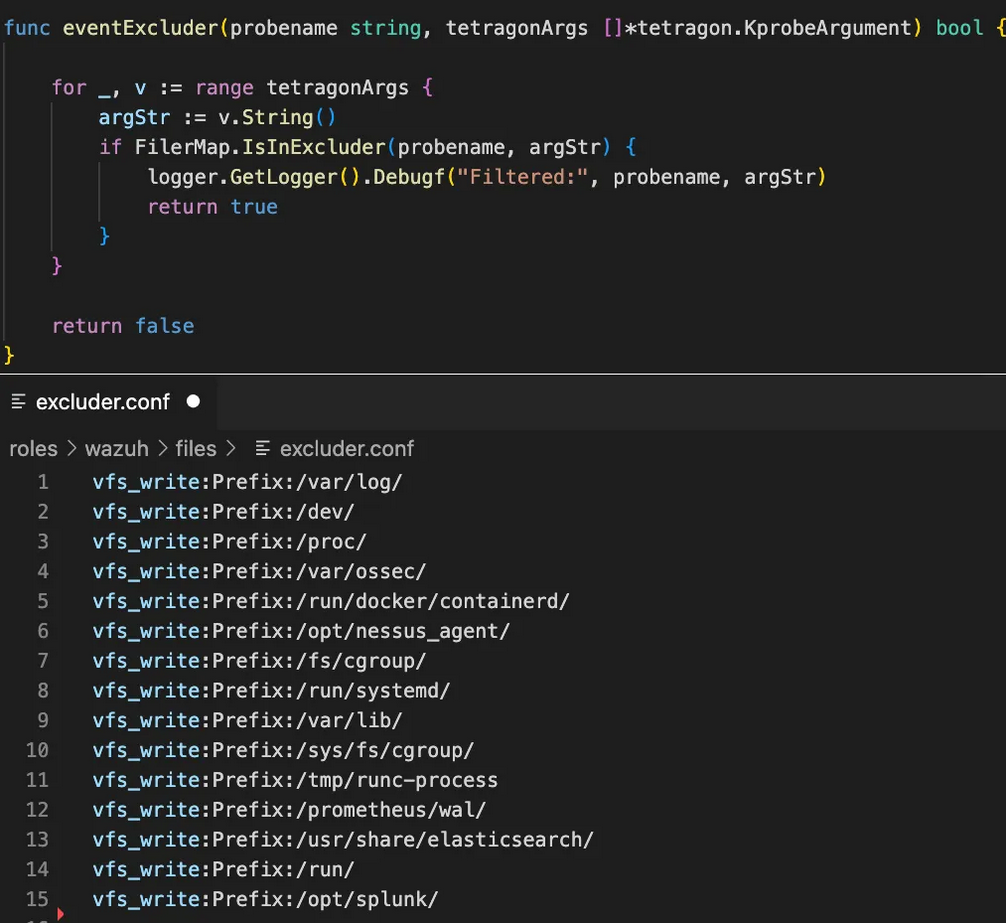
Рис. 11: Настраиваемый фильтр событий
Одна из проблем, с которыми пришлось столкнуться в ходе реализации, такова: некоторые данные, получаемые от eBPF, не являются человеко-читаемыми и взяты с нескольких проб. Например, вызов do_sys_open принимает в качестве третьего аргумента целое число (int), это аргумент вызова функции. Поэтому требовалось преобразовать флаги открытия файла из int в какие-то нормальные флаги, например, O_CREAT, O_APPEND, т.д.

Рис. 12: Исходный код вызова Linux do_sys_open
Для этой цели такие флаги в данной реализации преобразуются прямо на этапе обработки событий в Tetragon, как проиллюстрировано на рисунке 13.

Рис. 13: Преобразование флагов открытия в нормальное представление
В том же ключе была реализована обработка состояний TCP для пробы tcp_set_state и для сбора битов, регулирующих права доступа – это делается при помощи пробы sys_fchmodat.
NB: На порту назначения отсчёт байт ведётся от старшего к младшему, поэтому перед обработкой его необходимо обратить. Вот как это можно сделать:
dport = (dport >> 8) | ((dport << 8) & 0x00FF00)❯ Заключение
Едва ли возможно вместить в одну техническую статью все аспекты такой многогранной технологии как eBPF. Тем не менее, мы полагаем, что она послужит отличной отправной точкой для увлекательного путешествия в глубины ядра Linux и его внутренних компонентов.
