
Математические модели и алгоритмы сегодня отвечают за принятие важных решений, влияющих на нашу повседневную жизнь, более того — они сами управляют нашим миром.
Без высшей математики мы бы лишились алгоритма Шора для факторизации целых чисел в квантовых компьютерах, калибровочной теории Янга-Миллса для построения Стандартной модели в физике элементарных частиц, интегрального преобразования Радона для медицинской и геофизической томографии, моделей эпидемиологии, анализов рисков в страховании, моделей стохастического ценообразования финансовых производных, шифрования RSA, дифференциальных уравнений Навье-Стокса для прогнозирования изменений движения жидкостей и всего климата, всех инженерных разработок от теории автоматического управления до методов нахождения оптимальных решений и еще миллиона других вещей, о которых даже не задумываемся.
Математика стоит в основе цивилизации. Тем интереснее узнать, что с самого зарождения этого краеугольного камня в нем содержатся ошибки. Иногда ошибки математики остаются незаметными тысячелетия; порой они возникают спонтанно и быстро распространяются, проникая в наш код. Опечатка в уравнении ведет к катастрофе, но и само уравнение может быть потенциально опасно.
Мы воспринимаем ошибки как нечто чуждое, но что если вокруг них и строится наша жизнь?
Как доказать доказательство

Алекс Беллос в книге «Красота в квадрате» рассуждает о том, можно ли вообще доверять компьютерам и математике на примере теоремы о четырех красках. Эта теорема утверждает, что всякую расположенную на сфере карту можно раскрасить не более чем четырьмя разными цветами (красками) так, чтобы любые две области с общим участком границы были раскрашены в разные цвета. При этом области могут быть как односвязными, так и многосвязными (в них могут присутствовать «дырки»), а под общим участком границы понимается часть линии, то есть стыки нескольких областей в одной точке не считаются общей границей для них. Теорема была сформулирована Фрэнсисом Гутри в 1852 году и долгое время не имела доказательства.
В 1976 году Кеннет Аппел и Вольфганг Хакен из Иллинойского университета использовали суперкомпьютер для проверки перебором всех вероятных конфигураций карт. Первым шагом доказательства была демонстрация того, что существует определенный набор из 1936 карт, ни одна из которых не может содержать карту меньшего размера, которая опровергала бы теорему. Авторы доказали это свойство для каждой из 1936 карт. После этого был сделан вывод, что не существует наименьшего контрпримера к теореме, потому что иначе он должен был содержать какую-нибудь из этих 1936 карт, чего нет.
Долгое время никто не мог доказать доказательство компьютера — был проведен слишком большой объем вычислений, для того чтобы можно было их все проверить. С точки зрения «чистой» математики принять такое решение проблемы было сложно — оно противоречило эталону доказательства теорем, использовавшемуся со времен Евклида. Кроме того, математики предположили, что в программе могли быть ошибки. И ошибки в коде действительно были.
В 2004 году Джордж Гонтье из исследовательской лаборатории Microsoft перепроверил доказательство с помощью программы Coq v7.3.1, использующей собственный язык функционального программирования Gallina. Математики задали следующий вопрос: есть ли доказательство того, что программа-проверщик не содержит ошибок? Полной уверенности в этом нет, однако программа была многократно протестирована при выполнении многих других задач. В результате специализированный софт, помогающий математикам, содержит десятки тысяч формальных доказательств.
Несмотря на все обнаруженные ошибки, доказательство теоремы о четырех красках — одно из наиболее тщательно проверенных в математике.
Случайные числа и криптография

Компьютеры дали возможность значительно продвинуть математику, но самое главное, они позволили сделать из внешне красивых, но «бесполезных» теорем коммерчески успешные продукты. Одно из главных достижений компьютерной математики — работа с генераторами случайных чисел.
Проблема поиска случайных чисел интересно затронута в книге Беллоса «Алекс в стране чисел. Необычайное путешествие в волшебный мир математики». Число ? долгое время считалось хорошим примером случайности. Конечно, какие-то последовательности в бесконечном числе есть. Так на 17 387 594 880-м месте после запятой можно найти подряд цифры 0123456789. Однако эта последовательность лишь случайность — как показывает эксперимент с подбрасыванием монеты, противоречащие интуиции длинные последовательности являются скорее нормой.
Цифры Пи могут вести себя, как будто они случайны, но на самом деле они предопределены. Например, если бы цифры в числе ? были случайны, то шанс, что первая цифра после десятичной запятой будет равна 1, был бы равен всего 10%. Однако же мы с абсолютной определенностью знаем, что там стоит 1; ? проявляет случайность не случайно.
На самом деле найти случайность в окружающих явлениях сложно. Подбрасывание монеты случайно только потому, что мы не задумываемся о том, как именно она приземлится, но считая точную скорость, угол подбрасывания, плотность воздуха и все остальные существенные физические параметры процесса, можно точно вычислить, какой стороной она упадет.
Переводя вопросы математики в плоскость физики можно достигнуть удивительных результатов. В 1969 году математик Эдвард Торп выяснил (на самом деле этим вопросом он занимался более 10 лет), что стремление казино снизить систематическое отклонение от идеальной случайной статистически приводит к тому, что предсказать движения шарика оказывается проще. Дело в том, что при настройке ось колеса иногда наклоняют — наклона в 0,2 градуса достаточно для того, чтобы на воронкообразной поверхности появился достаточно большой участок, с которого шарик никогда не соскакивает на колесо. Используя эти сведения, можно довести матожидание выигрыша до 0,44 от ставки.
Случайность числа означает, что, помимо прочего, невозможно угадать следующее значение или предыдущее значение этого числа, основанное даже на знании всех устаревших предыдущих значений. Это может быть достигнуто генератором псевдослучайных чисел (PRNG) только в том случае, если он основан на принципах стойкой криптографии, смешанной с достаточным количеством энтропии, или по-настоящему случайной информацией.
На основе чистой математики можно сделать генератор PRNG с очень высокой стойкостью. Например, алгоритм Блюма-Блюма-Шуба (авторы алгоритма чета Блюмов и Майкл Шуб) имеет высокую криптостойкость, основанную на предполагаемой сложности факторизации целых чисел. Алгоритм математически красив:
где M = pq является произведением двух больших простых чисел p и q. На каждом шаге алгоритма выходные данные получаются из Xn путем взятия либо контрольного бита чётности, либо одного или больше наименее значимых бит Xn.
Некоторые математики считают алгоритм ББШ и им подобные потенциально опасными, поскольку задача факторизации целых чисел может оказаться не такой трудной, как предполагается, и на выходе алгоритма будут числа, которые могут быть выявлены при достаточном объеме вычислений. При использовании быстрого квантового алгоритма для факторизации будет достигнуто огромное пространство возможностей поиска уязвимостей криптостойкого шифрования. За примерами далеко ходить не надо. Когда-то сильный алгоритм DES теперь считается недостаточным для многих приложений. Некоторые старые алгоритмы, которые, как все думали, требуют миллиарда лет вычислительного времени, теперь могут быть взломаны через несколько часов (MD4, MD5, SHA1, DES и другие алгоритмы).
В семействе криптостойких генераторов Fortuna (используется в FreeBSD, OpenBSD, Mac OS X и др.) генератор получает псевдослучайные данные через шифрование последовательных натуральных чисел. Исходным ключом становится начальное число, а после каждого запроса происходит обновление ключа: алгоритм генерирует 256 бит псевдослучайных данных с помощью старого ключа и использует полученное значение в качестве нового ключа. Кроме того, блочный шифр в режиме счетчика производит неповторяющиеся 16-байтовые блоки с периодом 2128 в то время, как в истинных случайных данных при таких длинах последовательности с большой вероятностью должны встречаться одинаковые значения блоков — как мы видели выше на примере числа Пи. Поэтому для улучшения статистических свойств максимальный размер данных, которые могут быть выданы в ответ на один запрос, ограничивается 220 байт (при такой длине последовательности вероятность найти одинаковые блоки в истинно случайном потоке составляет порядка 2?97). Ко всему прочему подмешиваются истинно (возможно) случайные данные — перемещения мыши, время нажатия на клавиши, отклики жестких дисков, шумы звуковой карты и так далее.
Впрочем, математики даже в таких наборах случайных чисел подозревают наличие шаблонизированных последовательностей и предлагают использовать непредсказуемые физические явления, такие как радиоактивный распад и космическое излучение.
Возникновение ошибок
Иногда всех степеней защиты не хватает, если программист допускает досадный баг. Ошибка на любом шаге создания программы может подорвать безопасность всей системы.
if ((err = SSLHashSHA1.update(...)) != 0)
goto fail;
goto fail; /* BUG */
if ((err = SSLHashSHA1.final(...)) != 0)
goto fail;
err = sslRawVerif(...);
…
fail:
…
return err;Классическая ошибка SSL/TLS из 2014 года. Дополнительный оператор goto приводит к тому, что устройства iOS и Mac принимают недействительные сертификаты, что делает их восприимчивыми к MITM-атакам. Разработчик случайно добавил одну избыточную инструкцию goto, возможно, через ctrl+c/ctrl+v, дав возможность обходить все проверки сертификатов для соединений SSL/TLS. Эта ошибка существовала более года, в течение которой миллионы устройств были подвержены MITM-атакам. По иронии судьбы, в том же году более серьезная ошибка «goto» была обнаружена в коде проверки сертификата GnuTLS. Причем ошибка существовала более десяти лет.
Простые опечатки иногда бывает неожиданно трудно увидеть. К счастью, это именно та ошибка, которая сейчас может быть устранена ранними тестами. Однако для поиска более сложных ошибок всегда будет требоваться больше времени, чем есть. В конечном счете, программа, возможно, будет в большей степени адаптирована для прохождения тестов, а не для выполнения остальной части ее спецификации.
С точки зрения математики даже верное уравнение, дающее правильный результат, может содержать ошибку, имеющую далеко идущие последствия. Эту мысль хорошо иллюстрирует уравнение Блэка-Шоулза, ставшее математической основой торговли и приведшее банки к нескольким мировым кризисам. Красивое, правильное уравнение не учитывало лишь один параметр — случайность.
Формула модели оценки опционов впервые была выведена Фишером Блэком и Майроном Шоулзом в 1973 году. Опцион — это договор, по которому покупатель товара или ценной бумаги (так называемый базовый актив) получает право (но не обязательство), совершить покупку или продажу данного актива по заранее оговоренной цене в определенный договором момент.
Модель, определяющая теоретическую цену на европейские опционы, подразумевала, что если базовый актив торгуется на рынке, то цена опциона на него неявным образом уже устанавливается самим рынком. Согласно модели Блэка-Шоулза, ключевым элементом определения стоимости опциона является ожидаемая волатильность (изменчивость цены) базового актива. В зависимости от колебания актива, цена на него возрастает или понижается, что прямо пропорционально влияет на стоимость опциона. Таким образом, если известна стоимость опциона, то можно определить уровень волатильности, ожидаемой рынком.
Уравнение выглядит так:
C(S,t) — текущая стоимость опциона в момент t до истечения срока опциона;
S — текущая цена базисной акции;
N(x) — вероятность того, что отклонение будет меньше в условиях стандартного нормального распределения (таким образом и ограничивают область значений для функции стандартного нормального распределения);
K — цена исполнения опциона;
r — безрисковая процентная ставка;
T-t — время до истечения срока опциона (период опциона);
? — волатильность (квадратный корень из дисперсии) базисной акции.
Уравнение связывает рекомендуемую цену с четырьмя другими величинами. Три могут быть измерены напрямую: время, цена актива, по которому обеспечен опцион, и безрисковая процентная ставка. Четвертая величина — волатильность актива. Это показатель того, насколько изменчива его рыночная стоимость. Уравнение предполагает, что волатильность актива остается неизменной для срока действия опциона, однако это предположение оказывается ошибочным. Волатильность может быть оценена статистическим анализом движения цен, но она не может быть измерена точным, надежным способом, и оценки могут не соответствовать действительности.
Эта модель восходит к 1900 году, когда в докторской диссертации французский математик Луи Башелье предположил, что колебания фондового рынка могут быть моделированы случайным процессом, известным как броуновское движение. В каждый момент времени цена акции увеличивается или уменьшается, и модель предполагает фиксированные вероятности для этих событий. Они могут быть одинаково вероятными или быть более вероятными, чем другие. Их положение соответствует цене акции, двигаясь вверх или вниз наугад. Важнейшими статистическими особенностями броуновского движения являются его среднее и стандартное отклонение. Среднее значение — это краткосрочная средняя цена, которая обычно дрейфует в определенном направлении вверх или вниз. Стандартное отклонение можно рассматривать как среднюю величину, по которой цена отличается от средней, рассчитанной с использованием стандартной статистической формулы. Для цен на акции это называется волатильностью, и она измеряет, насколько неустойчива цена.
Уравнение Блэка-Шоулза давало возможность рационально оценить финансовый контракт еще до его начала через дифференциальные уравнения в частных производных, выражающих скорость изменения цены с точки зрения темпов изменения различных других величин. Проблема формулы оказалась в возможности ее модификации под различные случаи. На практике банки используют еще более сложные формулы, оценка риска в которых становится все более непрозрачной. Компании нанимают математически талантливых аналитиков для разработки аналогичных формул и получают решения, которые не имеют никакого значения в случае изменения рыночных условий.
Модель была основана на теории арбитражного ценообразования, в которой и дрейф, и волатильность являются постоянными. Это предположение распространено в финансовой теории, но оно часто неверно для реальных рынков — да, речь идет о набившем оскомину «черном лебеде». Непредвиденное изменение волатильности рынков привело к последствиям, которые невозможно было предугадать с помощью формул. Кризис 1998 года показал, что сильное изменение волатильности случается чаще, чем предполагалось. Кризис 2008 года продемонстрировал, как множество банков рухнули из-за нехватки ликвидных активов, вызванных неверной оценкой рисков с помощью не учитывающих случайности формул.
Уравнение Блэка-Шоулза имеет свои корни в математической физике, где величины бесконечно делимы, время течет непрерывно, а переменные плавно меняются. Такие модели могут быть несовместимы с реальной жизнью.
Первородные проблемы вычислений
Адекватная оценка риска имеет решающее значение в прогнозировании ошибок. Если мы рассчитываем риск воздействия гигантского астероида, который убьет все человечество, ошибка, означающая, что астероид фактически убивает человечество дважды, не имеет значения. Однако зеркальная ошибка — астероид, фактически убивающий половину человечества — имеет большое значение!
Где проходит разница между двумя событиями с невероятным расчетом полета астероида, показывают ошибки первого рода (false positives) и ошибки второго рода (false negatives) — ключевые понятия задач проверки статистических гипотез.
Ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Величину ошибок первого рода можно рассчитать по формуле:
где
F(x) — функция распределения значений измеряемой величины;
a, d — границы интервала, в котором существует вероятность наступления ошибок первого рода;
F(?) — функция распределения действительных значений погрешности средств измерений;
-?, p — границы интервала, в котором погрешность средств измерений не препятствует наступлению ошибки первого рода.
Ошибку второго рода называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал.
Величина ошибки второго рода рассчитывается по формуле:
где
с, a — границы интервала, в котором существует вероятность наступления ошибок второго рода;
p, +? — границы интервала, в котором погрешность средств измерений не препятствует наступлению ошибки второго рода.
В математике понятия формируются следующим образом:
- ошибки, где теорема все еще верна, но доказательство было неверным, относятся к первому роду;
- ошибки, когда теорема была ложной, и доказательство также было неверным, относятся ко второму роду.
Иногда возникновение ошибки связано с изменением стандартов доказывания. Например, когда Давидом Гильбертом были обнаружены ошибки в доказательствах Евклида, которые никто раньше не замечал, теоремы евклидовой геометрии все еще оставались правильными, а ошибки возникли из-за того, что Гильберт был современным математиком, думающим в терминах формальных систем (о чем Евклид и не мыслил). В свою очередь сам Гильберт допустил несколько других досадных ошибок: его знаменитый список из 23 кардинальных проблем математики содержит 2, которые не являются корректными математическими проблемами (одна сформулирована слишком расплывчато, чтобы понять, решена она или нет, другая, далекая от решения, — физическая, а не математическая).
Ни одна другая наука не может сравниться с математикой по количеству ошибок, шлейфом тянущихся на протяжении человеческой истории (возможно, слишком громкое высказывание и физики приведут немало аргументов в пользу своей победы в этом споре). Один из самых досадных промахов был связан с отсутствием в уравнениях бесконечно малых чисел, которые иногда рассматривались как 0, а иногда — как бесконечно малое ненулевое число. На основе неправильных вычислений в Средние века строились теории, которые ошибочно развивались столетиями.
Маловероятно, что в 21 веке начали рождаться люди, которые кардинально не похожи на своих предков и все поголовно гении. Однако нам кажется, что именно мы — самые умные и то, что придумано нами и есть подлинная картина мира. Но Евклид, например, на основе логики создал научную структуру, в которой его современники не могли найти недостатка. Точно так же мы можем не видеть недостатков в наших математических инструментах.
Неопровержимые данные свидетельствуют о том, что треть всех статей, опубликованных в математических журналах, содержат ошибки — не только незначительные ошибки, но и неправильные теоремы и доказательства. А вслед за математикой следует признать наличие проблем и в программировании. Есть такая шутка (с долей правды), что при переходе от 4000 строк кода Microsoft DOS к десяткам миллионам строк в последующих версиях Windows, количество активных ошибок выросло пропорционально.
Не просто программы содержат ошибки, а математические программы, которые должны проверять математиков на ошибки. Эта общая проблема приводит к созданию систем автоматической проверки других систем проверки. Для примера можно посмотреть, как нашли ошибку в популярной системе Mathematica при вычислении определителя матриц с целым числом записи. Mathematica не только неправильно вычисляет определитель матрицы, но также выдает разные результаты, если вы дважды оцениваете один и тот же определитель.
Не так давно математики вообще не одобряли использование компьютеров — необходимость избегать сложных вычислений всегда двигала прогресс в этой области и приводила к созданию элегантных, красивых решений. А теперь математики привыкли использовать специализированный софт, имеющий в своих самых популярных вариантах (Mathematica, Maple и Magma) закрытый исходный код.
Математики постоянно ошибаются — это нормально
Математические ошибки гораздо чаще встречаются в компьютерной индустрии, чем большинство людей думают. Также существует много ошибок, которые остаются незамеченными.
Числа Мерсенна, названные в честь математика Марена Мерсенна, исследовавшего их свойства в 17 веке, имеют вид Mn = 2n -1, где n — натуральное число. Числа такого вида интересны тем, что некоторые из них являются простыми числами. Мерсенн предполагал, что числа 2n-1 являются простыми для n = 2, 3, 5, 7, 13, 17, 19, 31, 67, 127, 257 и составными для всех остальных положительных числе n < 257. Позже выяснилось, что Мерсенн допустил пять ошибок: n = 67 и 257 дают составные числа, а n = 61, 89, 107 — простые.
Между теорией Мерсенна и опровержением прошло почти 200 лет.
То, что число 267-1 является произведением двух чисел 193 707 721 и 761 838 257 287 доказал в 1903 году профессор Коул. На вопрос, сколько он потратил времени, чтобы разложить число на множители, Коул ответил: «Все воскресенья в течение трех лет».
Ошибаются математики даже в понимании значимости своей работы. Кембриджский профессор Г. X. Харди, занимавшейся теорией чисел, утверждал, что если полезные знания определяются как знания, которые могут влиять на материальное благополучие человечества, так, что чисто интеллектуальное удовлетворение несущественно, то большая часть высшей математики бесполезна. Он оправдывает стремление к чистой математике аргументом, что ее совершенная «ненужность» в целом лишь означает, что она не может быть использована для причинения вреда. Харди заявлял, что теория чисел лишена каких бы то ни было практических применений; на самом же деле в наше время эта теория лежит в основе множества программ, обеспечивающих безопасность.
Проблема Цербера

Сетевой протокол Kerberos, основанный на протоколе Нидхема-Шрёдера с некоторыми изменениями, предлагает механизм взаимной аутентификации клиента и сервера перед установлением связи между ними. Протокол включает несколько степеней защиты, причем в Kerberos учтен тот факт, что начальный обмен информацией между клиентом и сервером происходит в незащищенной среде, а передаваемые пакеты могут быть перехвачены и модифицированы.
Первая версия протокола была создана в 1983 году в Массачусетском технологическом институте (MIT) в рамках проекта «Афина», основной целью которого была разработка плана по внедрению компьютеров в учебный процесс MIT. Проект был образовательным, но в конечном итоге дал миру несколько программных продуктов, которые используются и сегодня (например, X Window System).
В 1989 году появилась 4-я версия протокола, которая стала общедоступной. Другие крупные проекты по распределенным системам (например, AFS) использовали идеи Kerberos 4 для своих систем аутентификации. Генератор случайных чисел Kerberos в течение нескольких лет широко использовался в различных системах шифрования. И в течение десяти лет никто не обращал внимания на гигантскую дыру, позволявшую попасть в любую систему, использовавшую модуль Kerberos.
Предполагалось, что программа должна выбирать ключ случайным образом из огромного массива чисел, но оказалось, генератор случайных чисел выбирал из небольшого набора. 10 лет исследователи не знали, что в Kerberos 4 рандомные числа вовсе не рандомные, а секретные ключи можно получить в течение нескольких секунд.
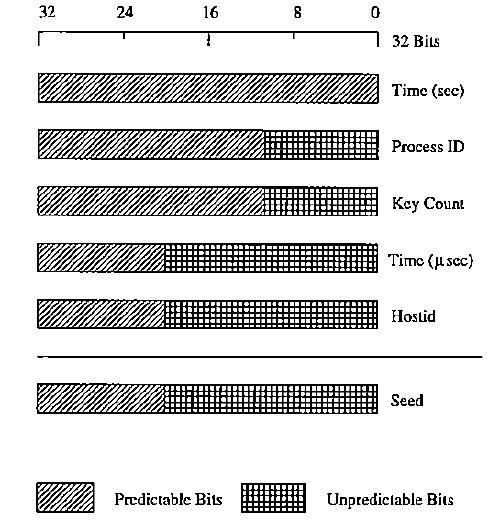
Kerberos 4 использовал функцию UNIX для создания случайных 56-разрядных DES-ключей. Неверная реализация алгоритма, используемого для генерации псевдослучайных чисел, привела к тому, что любая последовательность чисел ключа имела энтропию всего 32 бита, из которых первые 12 бит редко менялись и были предсказуемы. В результате у Kerberos 4 было только около 220 (или примерно один миллион) возможных ключей.
Самое забавное в этой истории то, что у Kerberos 4 открыты исходники. Простое использование открытого исходного кода само по себе не должно вызывать уверенности в его правильности. К сожалению, наличие кода, доступного для публичного контроля, привело к ложному пониманию безопасности. Более того, с течением времени росла уверенность в его безопасности — она подкреплялась верой в то, что если проблемы еще не были обнаружены, то и вероятность возможных ошибок снижается. Тенденции в разработке, где ошибки часто обнаруживаются в софте через несколько дней после релиза, как правило, только усугубляют эту общую проблему.
Ошибка, которая ничего не значит

Иногда ошибка вовсе не означает, что от уравнения или доказательства нужно отказаться.
Принцип Дирихле — знаменитое утверждение, сформулированное немецким математиком Дирихле в 1834 году, устанавливающее связь между объектами («голубями») и контейнерами («клетками») при выполнении определенных условий, звучит примерно так:
Если голуби рассажены в клетки, причем число голубей больше числа клеток, то хотя бы в одной из клеток находится более одного голубя.
Переведем на язык математики:
Пусть в n клетках сидит не менее kn + 1 голубей, тогда в какой-то из клеток сидит, по крайней мере, k + 1 голубь.
Звучит интересно, но самое интересное происходит в другой области. В математической физике принцип Дирихле относится к теории потенциала и формулируется следующим образом: если функция u(x) есть решение уравнения Пуассона
? u+f=0
в области ??Rn с граничным условием: u = g на границе ?, то u может быть найдена как решение вариационной задачи: найти минимум
среди всех дважды дифференцируемых функций v таких, что v=g на границе ?.
Такое красивое и имеющее важное значение доказательство Лежёна Дирихле с точки зрения строгой математики оказалось ошибочным. Через несколько лет после его смерти математик Карл Вейерштрасс показал, что принцип не выполняется. Для этого он построил пример, в котором нельзя было найти функцию, минимизирующую интеграл при заданных граничных условиях.
Так как сам принцип оказался неверным, но красивым и нужным, математикам пришлось придумывать различные ограничения на кривые и граничные условия, устраняя возражение Вейерштрасса.
Та самая точка/запятая
О проблеме с плавающей точкой известно много и, на данный момент, это не такая уж проблема. Но коротко напомним: бинарная математика с трудом точно отражает определенные числа. Например, бесконечные числа невозможно точно выразить в двоичном формате. При делении 2/3 на компьютере вы получите ряд цифр: 0,6666666666666667.
Обратите внимание на последнюю цифру 7. Во время войны в Персидском заливе компьютер противоракетной системы Patriot из-за схожей арифметики пропустил удар, в результате которого погибли 28 человек и были ранены еще 100. Причиной сбоя было неточное вычисление времени. Системное время компьютера хранилось в 24-битном регистре с фиксированной точкой с точностью до одной десятой секунды. Таким образом, значение 1/10, которое имеет не заканчивающееся двоичное разложение, было прервано на 24 бите после точки счисления.
Система Patriot проработала около 100 часов. За это время ошибка составила примерно 0,34 секунды. Двоичное представление 1/10 = 0,0001100110011001100110011001100… В 24 битном регистре это выглядело как 0,00011001100110011001100, внося ошибку, равную 0,0000000000000000000000011001100… в двоичном исчислении или примерно 0,000000095 в десятичном. За сто часов работы получилось 0,000000095 ? 100 ? 60 ? 60 ? 10 = 0,34 секунды.
Ракета летела со скоростью 1676 метров в секунду, и прошла за 0,34 секунды больше полукилометра, опередив радиус поражения противоракетного комплекса.
Число с плавающей точкой математически записывается так:
(-1)s ? M ? BE, где s — знак, B — основание, E — порядок, а M — мантисса.
Бесконечность при делении разработчики определили исходя из существования пределов, когда делимое и делитель стремится к какому-то числу: c/0 = ±? (3/0 = +?, а -3/0 = -?, к тому же 1/? = 0), так как если делимое стремится к константе, а делитель к нулю, предел равен бесконечности. При 0/0 предел не существует, поэтому результатом будет неопределенность NaN.
Расчеты с плавающей точкой могут отражаться по-разному в зависимости от того, где они хранятся. Внутренние регистры FPU некоторых процессоров имеют другую длину, чем оперативная память, что может привести к разным результатам одной и той же арифметической операции на GPU и CPU.
Выработаны методы, позволяющие устранять эти известные неточности, однако то, что работает на домашнем компьютере, не обязательно будет эффективно использоваться на суперкомпьютере. Решения проблемы с плавающей точкой для высоконагруженных систем также известны. Исследователи Sun предлагают интервальную арифметику, которая ловит математически неправильное число между двумя другими правильными числами. В 1990 году появился метод пары Wilf-Zeilberger, позволяющий выдавать точные результаты без ошибок округления, даже оперируя десятками тысяч знаков после запятой.
Есть еще одна история, связанная с использованием точки/запятой, но уже не плавающей. Про крушение первого космического аппарата в программе «Маринер» слышали многие из-за анекдотичного описания причины аварии. В отчете о полете Маринера-1 была указана потеря дефиса «в коде компьютерной инструкции в программе обработке данных», что сделало возможным передачу неверных рулевых сигналов на корабль. Пропуск дефиса позволил компьютеру принять сигнал от наземного передатчика таким, каким его приняла антенна, и совместить эти данные с данными слежения, отправленными для вычисления траектории. Это вызвало серию бессмысленных попыток коррекции курса одновременно с ложными рулевыми командами, что привело в итоге к полной потере курса кораблем.
Однако существует мнение, что пробел не виноват, а ошибка заключалась в использовании точки вместо запятой. Программа работала на фортране, в котором выражение
DO 17 I = 1, 10было интерпретировано как
DO17I = 1.10то есть как присвоение переменной DO17I — так как пробельные символы не учитываются языком.
Идеальный код
В Sun тестировали метод создания программ, позволяющий доказывать безошибочность софта с той же уверенностью, с которой математики доказывают теоремы. Правда, возможно, разработчики Sun не учитывают, что во многих случаях математики полагаются больше на веру, чем на какие-то абсолютные истины.
В подходе «давайте сделаем программу по тем же принципам, на которых математики создают уравнение» нет ничего нового. Еще в 1973 году нидерландский ученый Эдсгер Дейкстра предложил идею безошибочного кода, оформленную в виде книги 1976 года «Дисциплина программирования». Идея Дейкстры проста: программа имеет дело с математическими объектами с рядом заданных характеристик. Фактически код описывает математическую модель, оперирующую параметрами в заданных диапазонах. Выход за пределы параметра означает отмену операции. Программа также должна обладать всей полнотой данных.
На практике оказалось, что за пределами алгоритмических задач крайне сложно предусмотреть все случайности. Более того, программа не существует в вакууме, а крутится на железе, подверженном воздействию внешней среды.
Дейкстра много раз говорил о доказуемости компьютерных программ как абстрактных сущностей. В качестве следствия он отмечал, что обычного тестирования для программ недостаточно. Например, он указывал на невозможность проверить функцию умножения f (x, y) = x * y для любых больших значений x и y во всех диапазонах x и y. Правда, это утверждение относилось к 70-м годам прошлого века, но в одном с ученым можно согласиться и сейчас: программы содержат неустранимые ошибки.
Причем эти ошибки возникают даже не по вине разработчика или математика. Они просто есть. Знаете ли вы, что космические лучи обладают достаточной энергией для изменения состояний компонентов в электронных интегральных схемах, приводя к возникновению кратковременных ошибок, таких как повреждение данных в запоминающих устройствах или неправильная производительность процессоров?
Проблема не только для спутников, но и для наземной электроники (с учетом уменьшения размеров транзисторов). В 1990-х годах IBM исследовала воздействие космических лучей на электронику. Оказалось, что из-за излучения компьютеры получают около одной ошибки на 256 мегабайт оперативной памяти в месяц. Это означает, что есть вероятность 3,7 ? 10-9 байт в месяц или 1,4 ? 10-15 за байт в секунду. Если ваша программа работает в течение 1 минуты и занимает 20 МБ ОЗУ, то вероятность сбоя будет:
1 – (1 – 1,4,e-15)60 ? 20 ? 1024? = 1,8e-6
В общем, весьма мало, но как мы увидим дальше, даже такое воздействие может происходить в реальной жизни. Кроме того, не только космические лучи, но и радиоактивные изотопы в материалах чипа могут оказывать воздействие. Из-за помех в системе всегда есть вероятность, что будет считываться неправильный бит.
Точность вычислений
В 1990-х специалисты по теоретической физике предсказали наличие «красивого ответа» на вопрос о пространствах высшей размерности и феномене «зеркальной симметрии», относящихся к теории струн. Когда математики написали компьютерную программу для проверки гипотезы, они обнаружили, что она неверна. Физики представили убедительное исследование, доказывающее, что математики ошиблись.
(Замечание. Есть маргинальное мнение, поддерживаемое рядом ученых, что вся теория струн — это одна большая ошибка, на которой непонятно зачем строится современная теоретическая физика. Это мнение активно продвигает физик Ли Смолин, занимающий 21-е место в списке 100 самых выдающихся мыслителей мира по версии журнала Foreign Policy. Смолин сам известен пионерскими работами по теории струн, однако позже кардинально изменил свое мнение и сейчас является сторонником «альтернативы» — теории петлевой квантовой гравитации. Кроме того, ученый указывает на несправедливый перевес интереса академической науки в сторону струнного подхода в ущерб всем конкурентам, среди которых техниколор, преонные модели, суперсимметрия, теория твисторов, причинные ряды, супергравитация, динамические триангуляции и другие).
Откуда берутся ошибки? Они возникают всюду и по любому поводу.
Упрощение, округление и сокращение — злейшие враги. Во всех учебниках по математике и физике вы найдете задачу, начинающуюся со следующих слов: частица, падающая под действием силы тяжести, подвержена постоянному ускорению 9,8 м/с2…
С точки зрения ученого здесь написана полная чушь. Даже не будем касаться того факта, что ускорение свободного падения на поверхности Земли варьируется от 9,780 м/с? до 9,832 м/с?, а стандартное значение, принятое при построении систем единиц, 9,80665 м/с?. Посмотрим на саму цифру 9,8. Означает ли она, что ускорение ближе к 9,8, чем к 9,9 или 9,7? Означает ли это, что ускорение ближе к 9,80000, чем к 9,80001 или 9,79999?
Точность цифр, зависящая он контекста, может влиять не только на задачи в учебнике, но и на человеческую жизнь.
В 2008 году бортовой компьютер самолета А-330 авиакомпании Qantas через 3 часа после взлета неожиданно дал сбой, в результате чего самолет свалился в пике. Многих пассажиров швырнуло в потолок, но пилот смог взять управление на себя и благополучно посадить борт.
Что произошло? На самолете А-330, как и на многих других, установлено три компьютера (FCPC), которые получают данные от трех инерциально-навигационных систем (ADIRU). В ADIRU произошел аппаратный сбой в процессоре Intel, в результате которого вместо одних параметров полета стали выдаваться совершенно другие. Однако компьютер сходу ничего не заметил. (Кстати, есть мнение, что сбой в процессоре вызвали уже упоминавшиеся космические лучи. Круговорот ошибок).
Для вычисления угла атаки использовалось среднее значение с двух сенсоров: если значение сильно отличалось от среднего, алгоритм использовал крайнее допустимое значение на протяжении 1,2 секунды. Если на протяжении 1 секунды ситуация не менялась — этот вход отключался и больше не использовался. Через секунду после скачка значение было правильным, но через 1,2 секунды опять произошел скачок и это значение пометилось как допустимое. В результате ошибка образовалась из-за разницы всего в 0,2 секунды.
Среди математиков ходит байка, что когда помощники Гаусса не смогли повторить результаты своих астрономических измерений, знаменитый математик разозлился и пообещал лично показать неумехам, как нужно делать измерения. Но у него ничего не вышло — Гаусс не смог повторить собственные результаты. Гаусс сделал гистограмму результатов конкретного измерения и обнаружил знаменитый график распределения вероятностей, в наши дни называемый гауссианой.
Некоторые ученые считают, что чем меньше данных получат при исследовании, тем меньше вероятность ошибки — они просто выкидывают любые данные, которые кажутся неправильными. Другие ученые пытаются справиться с этой проблемой, используя квази-объективные правила, такие как Критерий Шовене (используется для оценки на грубую погрешность одного сомнительного значения выборки из нормально распределенной случайной величины).
Есть ли вообще с точки зрения математики ограничения на количество необходимой выборки для устранения ошибок? Есть — это здравый смысл.
Предотвращение последствий
Впрочем, не все так страшно, как может показаться. Двадцать лет назад прогнозировалось, что размер программных продуктов будет сильно ограничен ненадежностью их компонентов. Софт мог содержать от одной до десяти ошибок на тысячу строк кода. Однако мы не захлебнулись в потоке ошибок. Строгое управление процедурами широкого спектра тестов, непрерывная эволюция путем удаления ошибок из продуктов, уже находящихся в широком использовании, формальные методы проектирования ПО значительно улучшили надежность и производительность.
Компьютеры, управляющие АЭС и самолетами, работают с миллионами строк кода и даже если код содержит ошибки, они не могут оказать воздействия на систему в целом. Ответ на вопрос «как это все работает и не разваливается» на самом деле комплексный: кажется, что это комбинация выросших вычислительных ресурсов, снижения количества излишних оптимизаций, более широкого использования тестирования, вызывающего состязательное отношение к своему коду, и применения формальных методов и статических проверок.
Используются языки, библиотеки или фреймворки, которые упрощают обработку чисел без неожиданных последствий. В тех языках, где возможно допустить ошибку в обработке уравнений, используются библиотеки безопасности (такие как SafeInt (C ++) или IntegerLib (C или C ++)), помогающие предотвращать переполнение емкости целочисленных переменных и исключить другие ошибки, возникающие в ходе выполнения математических операций.
Есть ли у нас основания предполагать, что математика внутри себя содержит более впечатляющие проблемы? Да, более того, математика содержит внутри не что-то «потенциально опасное», а настоящие бомбы замедленного действия, о некоторых из которых мы еще не знаем.
Прямо сейчас можно сказать, что математический фундамент цивилизации содержит несколько потенциальных ошибок, которые могут ощутимо сказаться на IT области. Если такие широко распространенные гипотезы, как P ? NP или гипотеза Римана, окажутся ложными, то, поскольку они находятся в основе многих современных правдоподобных предположений и доказательств, может произойти математический Холокост. Если P не равно NP, значит, все в порядке. Если P = NP, появятся способы относительно быстро решать NP-полные проблемы: криптография, основанная на RSA или DES/AES, окажется бесполезной.
Чистую математику можно сравнить с обычным программированием. Программист напишет короткую программу — 100 строк кода — за небольшой промежуток времени без особых проблем. Отладка займет больше времени, чем непосредственно создание кода, но она не повлечет за собой суицидальные мысли. Однако если неопытный программист обязуется написать немного более длинную программу, скажем, 1000 строк, последуют неутешительные результаты. Процесс отладки становится эмоциональным кошмаром, и можно засомневаться в собственном здравомыслии.
Крайне небольшой процент математиков подвергают доказательства любых своих теорем столь пристальному вниманию. И хотя можно быть уверенным абсолютно, что доказательства верны (по крайней мере, значимые), вера нуждается в обосновании. Сравните это с процессом отладки. В конце отладки мы довольны нашей программой из-за согласованности результатов, которую она дает, а не потому, что мы считаем, что мы доказали ее правильность — ведь мы делали это по крайней мере двадцать раз при отладке, и каждый раз мы ошибались. Почему не двадцать первый? На самом деле мы остро осознаем, что наша бедная программа была протестирована только с ограниченным набором ресурсов. Если программа достаточно важна, она будет отлаживаться до тех пор, пока не будет полностью защищенной.
Результат уравнения
Ошибки никуда не денутся, но никакой роли в получении верного результата они играть не будут.
Скорее всего.
Математика (и таящиеся в ней ошибки) и алгоритмы достигли такого уровня, что если человек понимает стоящую перед ним математическую задачу, то ее можно считать тривиальной. Очень долгое время казалось, что математическое доказательство — это всего лишь инструмент, используемый одним человеком для того, чтобы убедить другого человека в истинности математического утверждения (Steven G. Krantz, «The Proof is in the Pudding»), сейчас же мы вступаем в фазу, когда одна программа будет доказывать свою правоту другим программам.
Статья основана на следующих материалах:
How Did Software Get So Reliable Without Proof?
An Empirical Study on the Correctness of Formally Verified Distributed Systems
The misfortunes of a trio of mathematicians using Computer Algebra Systems. Can we trust in them?
The mathematical equation that caused the banks to crash
CWE-682: Incorrect Calculation
Experimental Errors and Error Analysis
Misplaced Trust: Kerberos 4 Session Keys
The Patriot Missile Failure
Чарльз Сейфе. «Ноль: биография опасной идеи»
Алекс Беллос. «Красота в квадрате»
Type I and Type II Errors and Their Application
Cryptographic Right Answers
Mathematical Modelling In Software Reliability
j_wayne
Кстати он написал книгу «A Man For All Markets» (на самом деле не только ее).
В ней он рассказывает, как они с Клодом Шенноном построили носимый компьютер (в 1960г!) для предсказания результата игры в рулетку и использовали на практике.
Sirikid
Это пост про унивалентные основы математики?
sotnikdv
Читается не очень легко и мелкие ошибки режут глаз, типа алгоритм шифрования MD5.
Ещё изредка встречаются примеры, не относящиеся к предыдущему абзаца.
Но статья очень достойная, автор большой молодец
AC130
Я дико извиняюсь, но быть может во второй формуле вы имели в виду X_{n + 1} = X_n^2 \mod M?
janatem
Да, только, занудства ради, точнее будет не \mod, а \bmod (именно бинарная операция вычисления остатка).
vasiliysenin
Разве это мало?
А если компьютер управляет ядерными ракетами, то какова вероятность ложного срабатывания?
А если за нажатие на «ядерную» кнопку отвечает человек, то это надёжнее? А если одновременно несколько человек в разных странах?
Xandrmoro
«Ядерные» компьютеры (и вообще военная электроника) работает на микропроцессорах циклопических техроцессов, которым на естественный фон глубоко фиолетово.
jigpuzzled
А Крым таки к себе на карте нарисовали...
AleXP3
По теме «Что на практике означают тексты, называющиеся математическими доказательствами», подкину линк на выступление профессора математики Н.А.Вавилова. Может кому-то будет полезно или интересно глянуть.
BlackJet
оператор goto? не ассемблер, чай. пошло само по себе.
Alex_v99
Проблема всё-таки не в goto, а в отсутствии фигурных скобок. Если бы программист не поленился после каждого if обрамлять блок в фигурные скобки, то скорее всего второй goto никогда не сработал бы.
rrrav
vlreshet
Наверное, имеется в виду тот факт что число пи, грубо говоря, статично, и имея некоторую последовательность вполне возможно найти следующее число, найдя позицию этой комбинации после запятой. То есть, если знать что было использовано число пи для рандомизации, и мы видим число «141592», то с большой вероятностью следующим числом будет «65». Из-за этого использовать число пи для истинно случайных комбинаций нельзя, потому что в случайной комбинации предыдущее число никак не зависит от следующего.
Ну, по крайней мере я предполагаю что автор имел ввиду именно это)
rrrav
Просто в аргументации речь шла о первой цифре после запятой (которая «1»), что ее вероятность всего 10%, а она таки выпала. А не анализ на рандомность.
Кстати, вспомнилось о числе пи — вроде это число содержит в своем составе любую наперед заданную последовательность, «Войну и мир» можно найти с какого-то места, если постараться ;-). То есть подобно белому шуму.
vvatest
В том смысле, что число имеет конкретную физическую природу и вы, зная эту природу, можете абсолютно достоверно предсказать следующую цифру по предыдущим. Ну т.е. я могу не знать, что в вашей реализации вы используете длину окружности L и диаметр D, но я возьму свои l и d вполне успешно.
kerekemes
Может не к теме, — подчиняются ли цифры в числе ПИ закону Бенфорда?
shuhray
Один мужик доходил до конца натурального ряда и говорит, что за триллионом ничего нет
http://www.mat.univie.ac.at/~neretin/esenin/volpin1.html
От нас многое скрывают.
slavae
наверное, это 2^20
randall
Вы правы, поправим
dimorphus
Посмотреть, как сегодня выглядят на практике идеи «безошибочного кода» на примере доказательств функций на языке Си можно, например, в книжке ACSL By Example либо у меня в github репозитории verker. Там доказывается корректность реализаций библиотечных функций ядра Linux, их соответствие формальным спецификациям на языке ACSL. Там же можно скачать виртуальную машину с установленными инструментами и попробовать что-то самостоятельно.
BenjaminB
Чтобы понять все основы взлома и алгоритмов шифрования необходимо потратить много времени и сил, без научной литературы, математики и анализа никуда, вот недавно набрел на викизнания по пен тестингу и они всегда как отправная точка отсчета. Правда на английском, но зато популярно даже для новичка: Pentesting Wiki
user4000
После прочтения статьи возникло чувство, что только что просмотрел популярную передачу на канале РенТВ.