

Рис. 1 — Загранпаспорт РФ с MRZ-зоной (Источник изображения: en.wikipedia.org/wiki/Russian_passport)
Здравствуйте, сегодня мы хотим рассказать вам об особенностях задачи распознавания документов, удостоверяющих личность, с помощью мобильного телефона. В качестве примера мы рассмотрим задачу распознавания машинно-читаемых зон MRZ на изображениях и на кадрах видеопотока, полученных с камеры мобильного устройства.
1. Что такое MRZ?
Машинно-читаемой зоной (MRZ — Machine-Readable Zone) называют часть документа, удостоверяющего личность, выполненную согласно международным рекомендациям, закрепленным в документе Doc 9303 — Machine Readable Travel Documents Международной Организации Гражданской Авиации.
Примером машинно-читаемой зоны, выполненной в соответствии с этими рекомендациями, является MRZ заграничных паспортов граждан Российской Федерации (Рис. 1 — внизу).
2. Распознавание MRZ при помощи сканеров (в т.ч. специализированных)
Рассмотрим особенности использования сканирующего оборудования в задаче оптического распознавания документов. При сканировании документ расположен в перпендикулярной оптической оси плоскости на фиксированном расстоянии от регистрирующей матрицы. Этим достигается гомотетичность исходного документа и его изображения, а незначительные искажения при небольших отклонениях от такого расположения легко детектируются и корректируются. В процессе сканирования документ неподвижен во время экспозиции, поэтому исключены связанные со смещением исходного документа дефекты (размытие) изображения. Освещение в сканере формируется специальными мощными лампами подсветки, которые гарантируют стабильные характеристики освещенности и отсутствие теней.
Особым случаем сканирующего оборудования являются специализированные документные считыватели и аппаратно-программные комплексы, в которых изображение получается по принципам планшетного, планетарного или щелевого сканера. Документ в таких устройствах либо прижимается к стеклу, либо вставляется в специальную щель (Рис. 2), что практически устраняет деформации сканируемой страницы документа.




Рис. 2 — Примеры расположения документа при использовании считывателей
Такого рода считыватели позволяют получать изображения документов в различных схемах освещения (белая, инфракрасная, ультрафиолетовая, белая на просвет). При этом для оптического распознавания может использоваться схема с белым и инфракрасным освещением, которая дает высококонтрастное изображение с низким уровнем помех от фонового заполнения и элементов защиты.

Рис. 3 — Сканирование паспорта Японии в белом и инфракрасном диапазонах (Источник изображения: bersisteknoloji.com.tr/index_htm_files/Regula%208703_en.pdf)
Известное взаимное расположение элементов освещения (лампы, светодиоды) относительно рабочей поверхности, на которой располагается документ, позволяет полностью устранить (в процессе проектирования прибора) или существенно упростить компенсацию бликов (в процессе работы).
В зависимости от модели такого рода специализированное оборудование позволяет получать изображения в разрешении от 200 DPI и выше, при этом большинство модификаций имеет возможность получения изображений достаточного для оптического распознавания текста разрешения (300-400 DPI).
Таким образом, сканирующие устройства предоставляют изображения высокого качества с минимальными искажениями, что позволяет осуществлять оптическое распознавание текста с высоким качеством и высокой надежностью.
3. Съемка малоформатными цифровыми камерами
3.1. Общие проблемы
По сравнению со сканерами, оптическая схема камеры является более сложной и сама по себе вносит больше искажений в следствии аберраций, бликов и отражений внутри оптической системы. Использование фотосенсоров (матриц) и аналоговой электроники устройствами для регистрации изображений неизбежно приводит к появлению искажений изображений, называемых цифровым шумом. Источниками цифрового шума является сам процесс оцифровки аналогового сигнала (ошибки квантования сигнала, тепловой шум и перенос заряда на матрице) и его дальнейшее усиление. Цифровой шум заметен на изображении в виде наложенной маски из пикселей случайного цвета и яркости. Шум более заметен на однотонных участках изображения, в особенности – на тёмных. В отличии от сканирования, когда гарантировано качественное освещение, при съемке цифровыми камерами часто возникает недостаточная освещенность, при этом влияние цифрового шума естественно многократно усиливается. Еще один источник искажений — алгоритмы сжатия изображений, что особенно характерно для кадров видеопотока.



Рис. 4 — Примеры искаженных изображений символов MRZ документа
В зависимости от характеристик объектива и положения документа относительно плоскости наводки на резкость часть или все изображение документа может быть «размыто». Если из-за движения самого документа или камеры происходит смещение во время экспозиции, то появляется «смазывание» (Рис. 5), которое усиливается в условиях недостаточной освещенности.





Рис. 5 — Примеры «смазанных» изображений символов
3.2. Проективные и нелинейные искажения
В отличии от сканеров при съемке камерой сам документ расположен в произвольной плоскости относительно плоскости сфокусированного изображения. Отклонение от перпендикулярной оптической оси плоскости приводит к проективному искажению изображения документа. При незначительных углах отклонения можно распознавать машиночитаемую зону без дополнительного проективного исправления, но в общем случае необходимо оценить параметры проективного базиса и производить оптическое распознавание для проективно исправленного изображения. При этом возможны ошибки в определении параметров проективного исправления, что приводит к геометрическим искажениям изображений символов. Более того, как объект физического мира исходный документ подвержен механическим деформациям. Например, выполненные на бумаге документы подвержены «изгибам» и «скручиванию» (чаще всего вдоль или поперек основного направления чтения), причем иногда возникают «волны», когда изгибы в разных местах страницы разнонаправленны. При съемке камерой обеспечить отсутствие деформаций такого рода сложно или просто невозможно (Рис. 6).



Рис. 6 — Различные варианты деформаций
Механическая деформация страницы документа комбинируется с проективным искажением изображения. Выровненные в параллельные строки на исходном документе символы на изображении даже после проективной нормализации могут не иметь базовых линий. Более того, искажению подвергаются не только сами строки, но и изображения отдельных символов. То есть даже после правильной проективной нормализации всего документа изображение символа из физически деформированной на исходном документе области будет отличаться от изображения этого же символа из недеформированной области.
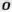
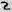
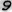
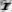
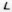
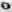
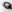
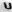

Рис. 7 — Примеры искаженных изображений символов из-за проективных и нелинейных деформаций
3.3. Проблемы фона
Для машиночитаемой зоны ICAO 9303 устанавливает, что печать текста должна быть визуально разборчивой и иметь черный цвет (на длинах волн В425–В680 согласно стандарту ИСО 1831), а так же краска должна хорошо поглощать в ближней части инфракрасного диапазона (в диапазоне В900 в соответствии со стандартом ИСО 1831). Таким образом, требования к контрастности налагаются только для инфракрасной области спектрального диапазона. На практике это приводит к тому, что при соблюдении стандарта некоторые страны используют для печати фонового заполнения машиночитаемой зоны краски, которые “прозрачны” в инфракрасном диапазоне и в тоже время довольно “плотны” в оптическом (Рис. 8).

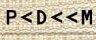


Рис. 8 — Примеры зон с «темным» и «пестрым» заполнением в оптическом диапазоне
Для малоформатных камер мобильных устройств съемка в инфракрасном диапазоне невозможна, поэтому неоднородный фон существенно усложняет процесс оптического распознавания зоны, особенно, в условиях “неудачного” освещения.
Схема освещения документа в сканерах минимизирует появление теней и бликов даже для «глянцевых» страниц документов. При съемке камерой в естественных сценах на изображениях часто возникают перепады яркости (тени, отражения, рефлексы и т.д.) и цветовые искажения, которые усложняют задачи анализа изображений и распознавания, например, за счет потери существующих или появления фальшивых границ объектов. Страницы большинства документов с машиночитаемой зоной либо изготовлены из специального пластика, либо покрыты защитной пленкой и обладают хорошими отражающими свойствами. Такие физические свойства объектов съемки приводят к появлению на документе бликов (Рис. 9). Дополнительно элементы защиты документа часто содержат области с «голографическими» элементами, которые тоже искажают изображение.

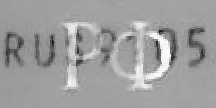

Рис. 9 — Фрагменты зоны: блик от протяженного источника света, голографические элементы защиты
3.4. Проблемы использования шрифта OCR-B
Рассмотрим влияние вышеперечисленных сложностей при использовании малоформатных цифровых камер на распознавание одиночных символов.
Для печати строк текста машиносчитываемой зоны ICAO 9303 устанавливает допустимое подмножество символов шрифта OCR-B, при этом некоторые символы имеют схожие начертания.
Наиболее трудными для различения между собой являются буква «О» и цифра ноль, изображения которых отличаются только пропорциями и небольшим различием в “кривизне”. Незначительность различий в начертаниях в условиях даже незначительных искажений или не очень высоко разрешения приводит к тому, что даже человек либо различает их с большим трудом, либо вообще не может различить (Рис. 10).

 — — — — —
— — — — — 

Рис. 10 — Примеры трудно различимых символов 0 (ноль, слева) и O (буква, справа)
Таким образом, при использовании для получения изображений документов малоформатных цифровых камер, в общем случае, невозможно гарантировать высокое качество изображения символа. Это приводит к существенно более низкому качеству и надежности результатов распознавания отдельных символов, а механизмы контекстной обработки начинают играть существенно более важную роль (по сравнению со сканированием).
4. Проблемы языковой модели
В современных системах распознавания и идентификации структурированных документов для улучшения точности распознавания используются механизмы статистической коррекции. Эти механизмы используют информацию о структуре документа, о “контексте” распознавания, и опираются на языковую модель распознаваемого документа (либо распознаваемого поля). Известны алгоритмы подобной статистической коррекции, или пост-обработки, опирающиеся на группу родственных методов, таких как скрытые марковские модели (Hidden Markov Models, HMM), конечные автоматы, N-граммные и словарные методы, а также механизмы, использующие взвешенные конечные преобразователи (Weighted Finite-State Transducers, WFST).
4.1. Мощность контекста
Рассмотрим некоторое текстовое поле F. С точки зрения структуры документа поле F обладает некоторой семантической структурой. С точки зрения представления документа поле F также обладает некоторой синтаксической структурой. На основе семантики документа и синтаксической структуры представления документа для поля можно определить некоторую модель языка. К примеру, пусть F — это поле “дата рождения держателя” машинно-читаемой зоны заграничного паспорта Российской Федерации. Тогда согласно семантической структуре в F содержится информация о годе, месяце и дне рождения держателя. Так как MRZ заграничного паспорта РФ выполнена в соответствии с рекомендациями ICAO 9303, в структуре данных MRZ для поля F выделена отдельная фиксированная позиция (вторая строка MRZ, символы 14-19, с контрольной суммой в 20-м символе) и для него определена синтаксическая структура: дата записывается в формате YYMMDD, где YY — последние две десятичных цифры года, MM — десятичное представление номера месяца, DD — десятичное представление номера дня в месяце, либо в виде строки “<<<<<<” из шести символов-заполнителей, если дата рождения неизвестна. Контрольная сумма представляется в виде одной десятичной цифры и ее значение вычисляется по алгоритму, специфицированному рекомендациями ICAO 9303.
На основе определенных семантической и синтаксической структур поля можно определить языковую модель, которая будет кодировать множество возможных значений поля. Представлять такую языковую модель можно несколькими способами, например при помощи БНФ-грамматики, либо в виде регулярного языка, кодируемого конечным автоматом. Один из возможных способов представления языковой модели является построение проверяющей грамматики G на множестве всевозможных строк, составленных из символов алфавита, основанной на предикате принадлежности слова P. Т.е. слово S соответствует языковой модели G, если предикат P принимает на слове S истинное значение. Так как в документе ICAO 9303 для каждого поля предусмотрены некоторые правила, ограничивающие множество возможных значений поля (т.е. усиливающие предикат P), а также механизм контрольной суммы, представление языковой модели поля в виде проверяющей грамматики G достаточно удобно.
Задача статистической коррекции результата распознавания поля F с проверяющей грамматикой G ставится достаточно просто: во взвешенном множестве возможных альтернативных значений поля F найти значение с максимальным весом, на котором предикат P выполняется. Если количество всевозможных значений F конечно (к примеру, максимальная длина поля ограничена), можно определить “мощность контекста” как отношение мощности области ложности предиката P к мощности множества всевозможных значений F. Чем больше это отношение, тем “мощнее” контекст поля, и, соответственно, тем больше вероятность успешного исправления результата распознавания. К примеру, из всевозможных строк длины 7, состоящих из десятичных цифр, менее 0.4% являются действительными датами (учитывая контрольную сумму), соответственно мощность контекста для этого поля превышает 99.6%.
4.2. Код MRZ-документа
Поле “код документа” (document code) является двухсимвольным идентификатором типа MRZ-документа. Код документа располагается в самом начале первой строки MRZ-зоны, вне зависимости от типа MRZ-документа, и алфавит его первого символа строго зафиксирован (‘P’ для паспортов, ‘V’ для виз, ‘A’, ‘C’ или ‘I’ для других документов, удостоверяющих личность), что позволяет построить для этого символа достаточно надежную процедуру коррекции результата распознавания. Однако второй символ кода документа оставлен на усмотрение организации, выдающей документ. Так как общая контрольная сумма (см. п. 4.7) на поле “код документа” не распространяется, языковую модель (помимо общего ограничения на алфавит) для второго символа типа документа в общем случае построить нельзя. Стоит также отметить, что существуют организации, осуществляющие выпуск специальных документов, которые по своей синтаксической структуре напоминают MRZ-документы, но таковыми не являются. В таких документах может встречаться первый символ кода документа, не предусмотренный стандартом ICAO 9303. Примером таких документов является MRZ-подобная зона на водительских правах Республики Молдова образца 1995-2010 годов (Рис. 11). Структура MRZ-подобной зоны на данном типе документов совпадает со структурой документов типа TD-2, предусмотренных документом ICAO 9303, за исключением поля “код документа”.

Рис. 11 — MRZ-подобная зона на водительских правах Молдовы образца 1995-2010 годов (Источник изображения: www.skyscrapercity.com/showthread.php?t=1540248)
4.3. Код выдающего органа и гражданство
Поля “код выдающего органа” (issuing state/authority) и “гражданство” (nationality) определяют, соответственно, уникальный код организации, выдавшей документ, содержащий MRZ-зону, и гражданство держателя документа. Данные коды базируются на трехбуквенных кодах государств согласно ISO 3166-1 с некоторыми расширениями (добавлены коды, соответствующие специальным неправительственным организациям, уполномоченным выдавать документы, удостоверяющие личность, и коды для лиц без определенного гражданства). Языковой моделью обоих полей может являться словарь — т.е. просто конечное множество всевозможных трехбуквенных кодов. Доля допустимых кодов из всевозможных трехбуквенных слов составляет ~1.4%, следовательно мощность контекста такой языковой модели достаточно высока — ~98.6%.
4.4. Имя держателя документа
Поле “имя” (name) является одним из самых сложных полей с точки зрения стандартизации, принимая во внимание разнообразие структуры имени в разных странах и в разных языках. В документе ICAO 9303 описаны некоторые требования к оформлению имени, на основе которых можно составить первичные проверочные правила: поле “имя” может состоять из одной либо двух секций, разделенных двумя символами-заполнителями (“<”), каждая секция может состоять из одного или нескольких слов, разделенных одним символом-заполнителем. Каждое слово должно состоять только из букв латинского алфавита. Никаких дополнительных механизмов проверки документом ICAO 9303 не предусмотрено (общая контрольная сумма MRZ-документа на поле “имя” не распространяется). Для поля “имя” можно использовать известные методы пост-обработки подобных полей, такие как N-граммные модели и словарные методы.
4.5. Номер документа и персональный номер
Поля “номер документа” (document number) и “персональный номер” (personal number/optional data) являются полями со слабо закрепленной синтаксической структурой, в связи с чем построить достаточно мощный механизм статистической коррекции затруднительно. Алфавит у этих полей не ограничен (т.е. ограничен только символами, возможными в MRZ-документе). Если для поля “номер документа” есть рекомендация, согласно которой номер не должен содержать символов-заполнителей в начале и середине номера (т.е. поле можно дополнять символами-заполнителями до нужной длины, но только в конце), то синтаксическая структура поля “персональный номер” полностью оставлена на усмотрение организации, выдающей документ. У обоих полей предусмотрена контрольная сумма, но даже с ее использованием эффективность механизма пост-обработки недостаточно высока: так как в алфавите присутствуют как буквы так и цифры, эффективность пост-обработки падает из-за особенностей вычисления контрольной суммы по алгоритму, описанному в ICAO 9303 (см. п. 4.7). Мощность контекста для обоих полей можно увеличить, используя результат других полей, таких как “код выдающего органа”. Некоторые организации, выдающие документы, удостоверяющий личность, определяют собственную синтаксическую структуру полей “номер документа” и “персональный номер”. Соответственно, после того, как результат распознавания поля “код выдающего органа” получен (и исправлен, см. п. 4.3), синтаксическую структуру полей “номер документа” и/или “персональный номер” можно уточнить, если ограничения выдающей организации заранее известны.
4.6. Даты рождения и окончания срока действия документа
Синтаксическая структура полей “дата рождения” (birth date) и “дата окончания срока действия” (expiry date) описана выше в пункте (4.1). Эти поля являются самыми удачными с точки зрения языковой модели — алфавит их символов жестко зафиксирован (только цифры, за исключением отдельно рассматриваемого случая неизвестной даты) и на основе семантической структуры поля даты можно построить языковую модель с достаточно мощным контекстом. При построении алгоритма комбинированной пост-обработки нескольких полей можно также учитывать тот факт, что срок окончания действия документа не может быть раньше, чем дата рождения держателя, поэтому мощность контекста для совместного рассмотрения этих полей можно еще сильнее увеличить.
4.7. Контрольные суммы
Согласно документу ICAO 9303 контрольная сумма предусмотрена для полей “номер документа”, “дата рождения”, “дата окончания срока действия” и “персональный номер”. Предусмотрена также так называемая “общая контрольная сумма” (composite check digit), при помощи которой происходит повторная валидация этих четырех полей. Однако, общая контрольная сумма предусмотрена не во всех типах документов (она отсутствует в так называемых MRV-A и MRV-B — в вариантах машинно-читаемых виз). Контрольная сумма занимает один символ MRZ-зоны для каждого поля, и вычисляется следующим образом:
- Каждому символу поля назначается его вес. Первому символу назначается вес 7, второму — 3, третьему — 1. Четвертому — 7, пятому — 3, и т.д. циклично повторяя веса 7, 3 и 1.
- Код каждого символа умножается на его вес. Код символа-заполнителя (‘<’) равен нулю, код каждой десятичной цифры равен значению этой цифры, код каждой буквы латинского алфавита равен 9 + <номер буквы в алфавите> (Код буквы ‘A’ равен 10, код ‘B’ — 11 и так далее. Код буквы ‘Z’ равен 35).
- Полученные произведения суммируются. Значением контрольной цифры является остаток полученной суммы по модулю 10.
Так как финальная сумма взвешенных кодов символов берется по модулю 10, возникает значительное количество коллизий. Особенные трудности вызывают коллизии на парах символов, которые трудно различимы механизмами распознавания одиночных символов в условиях распознавания с камеры мобильных устройств (см. пп. 3.1, 3.2). Так, одинаковые коды (взятые по модулю 10) имеют символы ‘F’ и ‘P’, ‘H’ и ‘R’, ‘G’ и ‘6, ‘S’ и ‘8’. В таких полях, как “номер документа” и “персональный номер”, могут встречаться как цифры, так и буквы латинского алфавита, и основным способом валидации является именно контрольная сумма. Однако, если на этапе распознавания одиночных символов один из символов, из приведенных выше пар, ошибочно распознался как другой член этой пары, то контрольная сумма при этом не изменится, и вероятность того, что после пост-обработки результат распознавания поля исправится сильно понижается.
Веса, на которые умножаются коды символов проверяемого поля, также вызывают вопросы. К примеру, веса 7 и 3, применяемые к соседствующим символам, дают в сумме 10. Это значит, что стоящие рядом одинаковые символы (или разные символы, но с одинаковыми кодами по модулю 10) с весами 7 и 3 будут вместе давать нулевой вклад в контрольную сумму, вне зависимости от того, какие это символы. Это в свою очередь означает, что если на фотографии или на кадре видеопотока, на котором происходит распознавание MRZ-документа, наблюдается локальное искажение, из-за которого два соседних символа распознались с ошибкой (например, пара цифр ‘00’ распозналась как пара букв ‘OO’), и эти два символа находятся в позициях поля с весами 7 и 3, то при помощи контрольной суммы их исправить не удастся. Особенно выражено это касается полей “номер документа” и “персональный номер”, так как у этих полей самый широкий алфавит из всех полей MRZ-документа (в их записи допускаются как цифры, так и буквы).
Для повышения надежности механизма валидации чувствительных данных в документе ICAO 9303 для некоторых типов MRZ-документов предусмотрена общая контрольная сумма. Однако общая контрольная сумма распространяется не на весь MRZ документ, а только на те его поля, которые уже защищены собственной контрольной суммой.
В итоге, с точки зрения моделирования языка с целью построения механизмов коррекции результатов распознавания MRZ-документа, некоторые поля, предусмотренные ICAO 9303, позволяют построить достаточно мощные контексты. Однако для отдельных полей (таких как “номер документа”, “персональный номер”) определение более строгой синтаксической структуры позволило бы увеличить качество распознавания, как в системах, работающих с камерами мобильных устройств, так и в традиционных системах на основе сканеров. Также повысить качество и надежность распознавания MRZ-документов позволило бы введение контрольных сумм на все значимые поля, или общих контрольных сумм, распространяющихся на весь документ.
5. Заключение
Мы описали вам основные проблемы, с которыми нам пришлось столкнуться при разработке нашего программного продукта Smart 3D OCR MRZ — Software Developer Kit для автономного распознавания MRZ-документов на мобильных устройствах. В дальнейшем мы планируем представить вам обзорную статью по архитектуре и ряд статей по алгоритмам, которые мы используем в наших разработках, связанных с распознаванием документов в видеопотоке.
dzigoro
Это все интересно очень. Вот только в статье ссылки нет, примера апи на сайте нет, цен тоже нет. Не скажете хотя бы порядок? Или не определились еще с лицензионной моделью?
SmartEngines Автор
Нашу демо-программу можно скачать в App Store и Google Play. Информация по лицензированию и цене пока что предоставляется по запросу. Если у вас есть вопросы, мы с удовольствием на них ответим, наш адрес указан на сайте.