

Цикл статей о крупных и успешных пользователях Kubernetes продолжается рассказом про популярный онлайн-сервис для распространения аудиоконтента — SoundCloud. В прошлом году эту компанию собиралась купить Spotify AB (имеет шведские корни, как и SoundCloud), а совсем недавно — китайский интернет-гигант Tencent. Даже обслуживая ~175 миллионов активных пользователей в месяц, SoundCloud в последнее время испытывает финансовые проблемы, о чём стало известно благодаря крупному сокращению (173 сотрудников) минувшим летом, однако, если верить последним данным, ситуация наладилась. Так или иначе, куда больше нас интересует технологическая сторона вопроса, а точнее — применение Kubernetes, и вот что известно о SoundCloud из публичных источников…
Начало миграции на Kubernetes
Ещё на первой ежегодной конференции Kubernetes — KubeCon 2015, проходившей в ноябре 2015 года в Сан-Франциско, — выступил Tobias Schmidt, инженер SoundCloud, который рассказал про путь компании к микросервисной архитектуре (это произошло к 2014 году), а впоследствии — к Kubernetes:

В SoundCloud начинали с монолитного приложения («4-5 лет назад») на Ruby on Rails (+ MySQL, + RabbitMQ), для выкатывания которого использовался Capistrano, а для описания инфраструктуры — Chef. Среди основных проблем того времени были: медленное масштабирование, болезненность и нестабильность схемы деплоя, трудоёмкое развёртывание новых приложений. По этим причинам в компании пришли к созданию своей системы — Bazooka, которую окрестили как «PaaS в стиле Heroku». Управляя контейнерами (на базе LXC), она предоставляла разработчикам простые команды для деплоя приложений и их масштабирования. На тот момент у компании было 400-500 сервисов (не все из них находились в production), и с Bazooka удалось решить проблемы быстрого выката и отката релизов приложений, их масштабирования, а также независимости команд (разработчикам больше не нужно было обращаться к специалистам эксплуатации для получения новых ресурсов).
За время этих экспериментов специалисты SoundCloud однозначно полюбили контейнеры и язык Go. В то же время созданная внутри Bazooka перестала подходить для работы со значительно разросшимися микросервисами, которые превратились из простых обработчиков HTTP-запросов в сложные и требовательные к ресурсам приложения (они уже были написаны на Scala, Clojure, JRuby). Вдобавок, поддерживать и развивать Bazooka дальше становилось всё более затруднительно при имеющихся ресурсах компании, а в мире контейнеров заметную популярность снискал Docker (и разработчики SoundCloud уже полюбили его, начав использовать в CI/CD). Всё это побудило инженеров к решению перейти на какую-то стороннюю систему для оркестровки.
Почему Kubernetes?
В SoundCloud сравнили Kubernetes с «родной» Bazooka и другими доступными в мире DevOps продуктами вроде Mesos, а также сопоставили возможности этой системы со своими актуальными требованиями. Выбору в пользу Kubernetes объясняется в докладе следующими причинами:
- Простые и понятные основные объекты, которых достаточно пользователям/разработчикам для работы: контейнеры, поды, сервисы, Replication Controller.
- Мощные сетевые возможности: гибкая конфигурация разных приложений с разным трафиком и ресурсами на сетевом уровне, удобный аудит пользовательских подключений, безопасное распределение трафика.
- Планирование на уровне подов, в которые можно поместить разные контейнеры, связанные общим жизненным циклом.
- Система лейблов для группировки ресурсов, их обнаружения и установки ограничений на них.
- Большое и живое сообщество, а также доступность коммерческой поддержки.
- В понимании инженеров SoundCloud проект Kubernetes по своей сути расширял те идеи, что были заложены в Bazooka.
Итог: по состоянию на конец 2015 года в SoundCloud активно экспериментировали с Kubernetes в рамках Google Cloud Platform и своего кластера на bare metal в дата-центре. В ближайших планах на то время значились: завершение выстраивания CI pipeline (пока он был «в основном настроен»), полная интеграция с Prometheus для мониторинга, решение проблем с журналированием. История с Prometheus, упомянутого в этих планах, заслуживает отдельного внимания…
Prometheus
Вряд ли кто-то из инженеров, работающих сегодня с Kubernetes, не слышал про Prometheus — ведь это один из первых проектов организации CNCF (Clound Native Computing Foundation), формально стоящей и за самим K8s. На сегодняшний день этот Open Source-проект позиционируется как «система мониторинга для систем и сервисов», собирающая метрики из заданных устройств по заданным интервалам времени, применяющая к ним правила, демонстрирующая полученные результаты и вызывающая триггеры, если выполнились определённые условия для указанных значений. Основные компоненты Prometheus написаны на языке Go, а актуальная общая архитектура выглядит так (схема взята из документации):
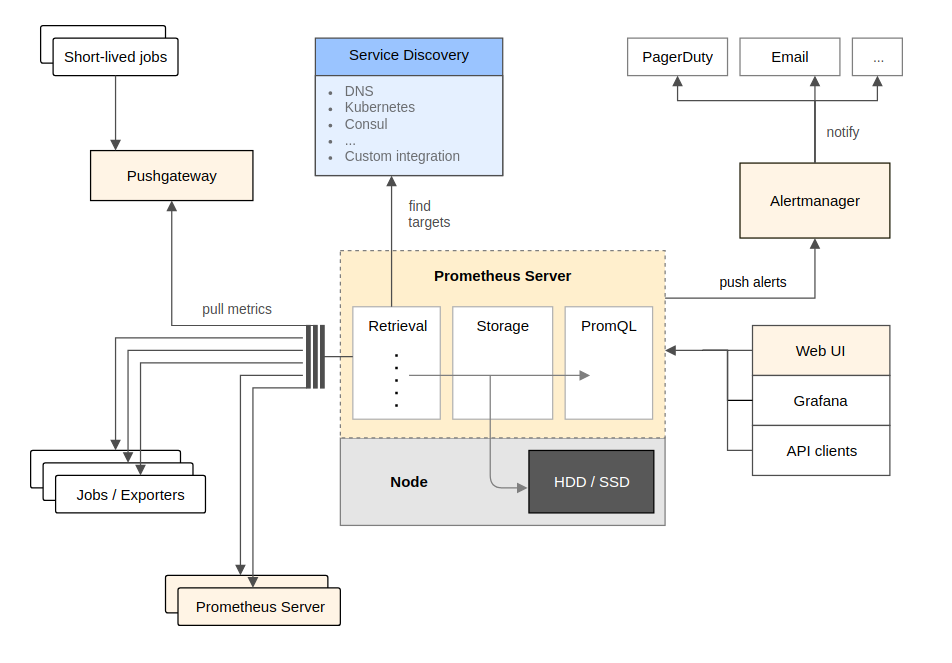
Почему же этому проекту CNCF уделяется особое внимание в статье про SoundCloud и Kubernetes? Дело в том, что его изначальной разработкой занималась именно эта компания, и происходило это ещё в 2012 году — задолго до того, как инженеры SoundCloud могли даже теоретически подумать о переходе на Kubernetes (его тогда просто не было). Со временем популярность применения Prometheus привела его в превращение в независимый проект, поддерживаемый широким сообществом, а в 2016 году он пополнил ряды CNCF, став вторым (после Kubernetes) проектом организации.
Что ещё интереснее, за Prometheus в SoundCloud стоит бывший сотрудник Google — Matt Proud. К 2012 году в SoundCloud оказались недовольны утилитами, используемыми для статистики и мониторинга (StatsD и Graphite), и начали поиски альтернативы. Присоединившийся в тот момент к компании инженер из Google не нашёл подходящих Open Source-продуктов, позволяющих хранить данные типа временных рядов (time series) в многомерном формате и использовать для выборки из них простой язык запросов. Так и начался проект Prometheus, создаваемый «под вдохновением о том, что он [Matt Proud] знал о Borgmon — спутнике менеджера кластеров и планировщика задач Google Borg [который, как все знают, стал прародителем Kubernetes]».
В итоге, Matt Proud, придя в SoundCloud всего на 2 года (покинул компанию в конце 2013 года, а в 2014 вернулся в Google), инициировал создание Prometheus, к которому присоединились и другие инженеры SoundCloud, продолжившие его развитие после ухода своего идеолога. Уже в 2012 году проект был опубликован на GitHub, а годом позже начал применяться в production у самой SoundCloud.
«Prometheus — прекрасный пример того, что было написано ещё до существования Kubernetes и что было написано для мира, в котором необходимо мониторить множество приложений различных типов. Prometheus — это не просто мониторинг для приложений в Kubernetes, он и для Mesos, Docker, OpenStack, других платформ. Многое ещё только будет появляться, и лично я убеждён, что основных платформ будет больше. Так что это действительно повсеместный и мощный инструмент. Мы стараемся выбирать хорошие инструменты, которые подойдут под различные случаи использования, а не единственный кейс. Необязательно это будут контейнеры — могут быть и виртуальные машины».
— Alexis Richardson, глава технического комитета CNCF и руководитель компании Weaveworks, в 2016 году, когда Prometheus получил официальный статус incubated project в CNCF.
Production в SoundCloud
Согласно интервью, данное в апреле 2016 года лидера команды Production Engineering в SoundCloud — Bjorn Rabenstein — в компании к тому времени уже применяли Prometheus и Kubernetes в production, называя эти продукты прекрасной комбинацией для решения инфраструктурных потребностей.
Как уточняется в этом интервью, при выборе замены для Bazooka победа Kubernetes случилась «с небольшим опережением» других решений, причиной чему была относительная молодость проекта, которому ещё только предстояло получить/развить многие из своих возможностей.
На европейских DevOps-мероприятиях 2016 года (JAX DevOps в Лондоне, CoreOS Fest в Берлине, DevOpsCon 2015 в Берлине) Bjorn выступал вместе с Fabian Reinartz, одним из основных разработчиков Prometheus и инженером из CoreOS, ранее работавшим в SoundCloud, рассказывая о том, как мониторить Kubernetes с помощью Prometheus:
Описанный в этом докладе опыт уже опирался на production-окружение в SoundCloud, а вскоре был дополнен выступлением всё тем же инженером компании Tobias Schmidt — на ContainerDays NYC 2016 в ноябре 2016 года. (Те, кого заинтересует пример описанной в докладе конфигурации Prometheus для Kubernetes, могут найти его в специальном репозитории на GitHub.)
К сожалению, подробностей о самой инфраструктуре SoundCloud снова практически нет. Однако есть скриншот, который, по словам автора, взят из реальной инфраструктуры. В частности, на нём можно увидеть показатель в 19 тысяч для RPS от входящих запросов (HTTP + Thrift):

Из вакансии SoundCloud на позицию Production Engineer известно, что в инфраструктуре задействованы «такие технологии, как Kubernetes, Kafka, Distributed Storage и Prometheus», а из позиции Backend Engineer — что в компании по-прежнему используются языки Scala, Java и Go для бэкенда, а также технологии Spark и Hadoop. (К слову, об использовании Go в production-инфраструктуре SoundCloud есть отдельная статья, но скорее всего уже частично устаревшая.)
Наконец, известно, что в production-инфраструктуре SoundCloud:
- микросервисы используют Open Source-фреймворк Finagle, разработанный в Twitter как «расширяемая RPC-система для JVM, используемая для создания серверов с активной параллельной обработкой»;
- часть данных хранится в memcached, Redis и MySQL;
- облачные сервисы AWS (S3 и Glacier) применяются для хранения данных, измеряемых петабайтами, а также — для транскодирования (Amazon EC2) и анализа пользовательского поведения (Amazon Redshift);
- Elasticsearch обслуживает поисковые запросы многочисленных пользователей в реальном времени.
- Для балансировки нагрузки задействованы IPVS (L4) и HAProxy (L7), а для service discovery — Consul.
Пусть особенности эксплуатации Kubernetes и конкретные цифры по production-окружению SoundCloud публично не афишируются (возможно, связано с тем, что инженеры компании больше заняты популяризацией выращенного у себя средства мониторинга Prometheus), факты его применения не только налицо, но и делают из этого онлайн-сервиса одного из ранних пользователей Kubernetes в по-настоящему масштабном production.
Другие статьи из цикла
Комментарии (6)
Hixon10
11.10.2017 22:00stackshare.io/soundcloud/soundcloud
А тут что-то нет кубернетоса. Хотя это, конечно же, ничего не значит.
shurup Автор
12.10.2017 05:53О, не знал про такой ресурс — спасибо! Попутно нашёл ещё github.com/soundcloud/haskell-kubernetes — правда, выглядит уже заброшенным.
YarickR
Где тот саундклауд? история ли это успеха?
shurup Автор
История успеха в смысле инфраструктуры (с ней что-то не так?), а не коммерческой составляющей (об этом есть немного в начале статьи).
YarickR
Опять же, в чём успех инфраструктуры, «подробностей о самой инфраструктуре SoundCloud снова практически нет»? В поддержке 20К РПС? Так это немного. В том, что они наизобретали велосипедов, исходя, видимо, из NIH-принципа? Ну тоже довольно сомнительно. Я действительно хотел бы увидеть числа, подтверждающие успехи инфраструктуры; пока что описана довольно развесистая клюква, а описание деталей работы этой клюквы под зонтиком k8s, к сожалению, пропущено. Не вами, вестимо, а саундклаудовцами.
Прошу прощения, critical mood mode on
shurup Автор
NIH — это вы про Prometheus? У авторов достаточно много пояснений, почему это не велосипед, а необходимость. И время, и рынок это подтвердили (тем, как индустрия «признала» этот проект, как распространён он стал и сколько сторонних разработчиков к нему подключились). А от Bazooka они как раз ушли в сторону K8s.
Успех же инфраструктуры в том, что это production общеизвестного (посещаемого), крупного и сложного проекта, который работает и масштабируется, а также в закрытии потребностей разработчиков (CI/CD).