
Прим. перев.: в этой статье инженеры онлайн-сервиса Cloudflare весьма популярно объясняют, что именно (технически) произошло с недоступностью Facebook минувшим вечером (4-го октября 2021), а также затрагивают тему того, как этот сбой повлиял на более глобальные процессы в интернете.
«Разве Facebook может упасть?» — задумались мы на секунду…
Сегодня в 16:51 UTC (в 19:51 MSK — прим. перев.) у нас был открыт внутренний инцидент под названием «Facebook DNS lookup returning SERVFAIL» («DNS-поиск для Facebook возвращает SERVFAIL»). Мы решили, что это с нашим DNS-ресолвером 1.1.1.1 что-то не так. Однако к моменту размещения соответствующего обновления на публичной статус-странице стало ясно, что здесь что-то серьёзное.
Социальные сети уже разрывались от сообщений о том, что быстро подтвердили и наши инженеры: Facebook и связанные с ним сервисы WhatsApp и Instagram действительно упали. Их DNS-имена больше не ресолвились, а IP-адреса инфраструктуры были недоступны. Выглядело так, как будто кто-то буквально выдернул кабели разом во всех их дата-центрах, отключив от интернета.
Как такое вообще возможно?
Встречайте BGP
BGP — это «протокол граничного шлюза» (Border Gateway Protocol). Это механизм для обмена информацией о маршрутизации между автономными системами (AS) в интернете. У больших роутеров, благодаря которым работает интернет, есть постоянно обновляемые списки возможных маршрутов, используемых для доставки каждого сетевого пакета до мест их назначения. Без BGP интернет-роутеры не знают, что делать, и интернет просто не будет работать.
Интернет — это буквально сеть из сетей, связанных между собой с помощью BGP. BGP позволяет одной сети (скажем, Facebook) объявлять о своём присутствии другим сетям, которые в конечном счёте формируют весь интернет. На момент написания этой статьи Facebook не сообщал о своём присутствии, поэтому интернет-провайдеры (ISP) и другие сети не могут найти сеть Facebook — она недоступна.
У индивидуальных сетей есть свой ASN — номер автономной системы (Autonomous System Number). Автономная система (AS) — это индивидуальная сеть с унифицированной политикой внутренней маршрутизации. AS может порождать специальные префиксы (означающие, что они контролируют группу IP-адресов), а также транзитные префиксы (они знают, как добраться до определённых групп IP-адресов).
Например, ASN у Cloudflare — AS13335. Каждая ASN должна объявить интернету о своих prefix routes с помощью BGP. В ином случае никто не узнает, как к ней подключиться и где найти её.
В онлайн-центре обучения Cloudflare есть отличный обзор того, что такое BGP, ASN и как они работают.
В этой упрощённой схеме можно увидеть шесть автономных систем в интернете и два возможных маршрута, по которым один пакет может пройти от начала (Start) до конца (End). Самый быстрый маршрут — это AS1 → AS2 → AS3. Самый медленный — AS1 → AS6 → AS5 → AS4 → AS3; он используется в случаях, когда первый не срабатывает.

В 16:58 UTC мы заметили, что Facebook перестал анонсировать маршруты для своих DNS-префиксов. Это означало, что по меньшей мере DNS-серверы Facebook были недоступны. По этой причине DNS-ресолвер Cloudflare (уже упомянутый 1.1.1.1) не мог отвечать на запросы, требующие выдать IP-адрес для домена facebook.com или instagram.com.
route-views>show ip bgp 185.89.218.0/23
% Network not in table
route-views>
route-views>show ip bgp 129.134.30.0/23
% Network not in table
route-views>Хотя другие IP-адресы Facebook и имели маршруты в то же самое время, в них не было особого смысла, потому что DNS-службы Facebook и связанных сервисов были недоступны:
route-views>show ip bgp 129.134.30.0
BGP routing table entry for 129.134.0.0/17, version 1025798334
Paths: (24 available, best #14, table default)
Not advertised to any peer
Refresh Epoch 2
3303 6453 32934
217.192.89.50 from 217.192.89.50 (138.187.128.158)
Origin IGP, localpref 100, valid, external
Community: 3303:1004 3303:1006 3303:3075 6453:3000 6453:3400 6453:3402
path 7FE1408ED9C8 RPKI State not found
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
route-views>Мы следим за всеми обновлениями и анонсами в BGP, какие появляются в глобальной сети. Собираемые таким образом данные позволяют увидеть глобальные связи в интернете и понять, откуда и куда должен ходить весь трафик.
UPDATE-сообщение от BGP информирует роутер о любых изменениях, сделанных в префиксе, или о полном отзыве этого префикса. Проверяя базу данных BGP, основанную на временных рядах, мы можем точно увидеть количество обновлений, поступивших от Facebook’а. Обычно этот график довольно ровный: Facebook не будет постоянно делать большое количество изменений для своей сети.
Но около 15:40 UTC был замечен резкий всплеск изменений в маршрутах Facebook’а. Именно здесь и начались проблемы.

Ещё лучше будет видно, что же произошло, если разбить этот график на анонсы маршрутов и их отзывы. Маршруты были отозваны, DNS-серверы Facebook ушли в offline, а минутой позже возникла проблема: инженеры Cloudflare сидели и недоумевали, почему 1.1.1.1 не может получить IP для facebook.com, обеспокоенные каким-то сбоем в своих системах.

После отзыва этих маршрутов Facebook и его сайты были отключены от интернета.
DNS тоже в деле
Прямым последствием этого события стала невозможность для DNS-ресолверов со всего мира получать IP для связанных с проектами доменных имён:
➜ ~ dig @1.1.1.1 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @1.1.1.1 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
➜ ~ dig @8.8.8.8 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @8.8.8.8 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN AЭто происходит по той причине, что в DNS, как и во многих других системах в интернете, используется свой механизм маршрутизации. Когда кто-то набирает https://facebook.com в веб-браузере, DNS-ресолвер, ответственный за перевод доменного имени в реальный IP-адрес для фактического подключения, сначала проверяет, есть ли что-то в его кэше. Если кэш есть — он используется. Если кэша нет — производится попытка получить ответ от DNS-сервера, обычно расположенного где-то поблизости.
Если DNS-серверы недоступны или не могут дать ответ по какой-то другой причине, возвращается ответ SERVFAIL, а браузер показывает пользователю ошибку.
Опять же, в онлайн-центре обучения Cloudflare есть хорошее объяснение, как работает DNS.

Из-за того, что Facebook перестал анонсировать свои DNS prefix routes через BGP, наш и любой другой DNS-ресолвер не мог подключиться к DNS-серверам проекта. Поэтому, 1.1.1.1, 8.8.8.8 и другие крупные публичные DNS-ресолверы начали выдавать (и кэшировать) ответы SERVFAIL.
Но это ещё не всё. Теперь в дело включается человеческий фактор и логика работы приложения, что в совокупности приводит к экспоненциальному эффекту. От пользователей обрушивается огромная волна дополнительного DNS-трафика.
Отчасти это происходит по той причине, что приложения не расценивают ошибку как подходящий пользователю ответ и начинают делать повторные запросы, причем иногда очень активно. А отчасти — потому что конечные пользователи тоже не воспринимают ошибку за правильный для них результат и начинают обновлять страницы, убивать/перезапускать свои приложения, порой тоже весьма активно.
Всё это привело к резкому росту трафика (по количеству запросов), что мы наблюдали на 1.1.1.1:

Из-за того, что Facebook и его сайты так популярны, мы получили 30-кратную нагрузку на DNS-ресолверы по всему миру, а это может вызывать задержки и таймауты для других платформ.
К счастью, 1.1.1.1 был создан как бесплатный, приватный, быстрый (убедиться в этом можно в DNSPerf) и масштабируемый сервис, так что мы продолжали обслуживать своих пользователей с минимальными проблемами.
Скорость ответов на подавляющую часть DNS-запросов оставалась в диапазоне менее 10 мс. В то же время небольшая часть перцентилей p95 и p99 показали повышенное время ответов — вероятно, из-за истекших TTL при обращении к DNS-серверам Facebook и вызванных таймаутов. 10-секундный таймаут для DNS — значение, которое пользуется популярностью среди инженеров.

Влияние на другие сервисы
Люди ищут альтернатив, хотят знать и обсуждать, что происходит. Когда Facebook упал, мы увидели растущее число DNS-запросов к Twitter, Signal и другим социальным сетям и платформам для обмена сообщениями.
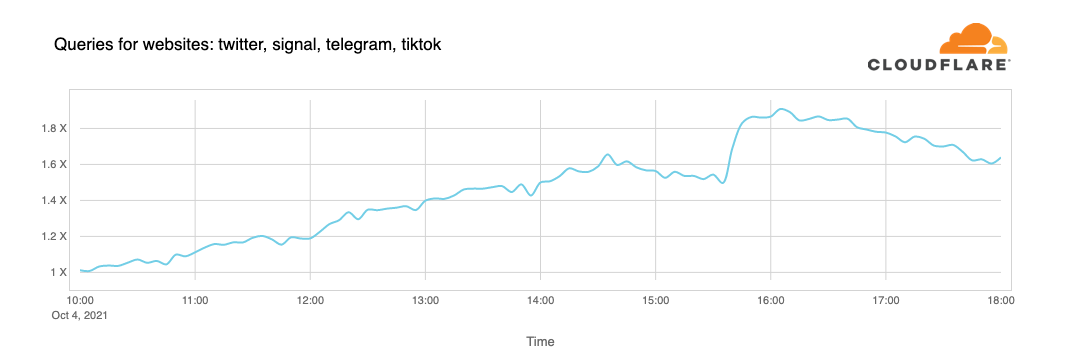
Также недоступность проявилась в статистике по WARP-трафику от и к автономной сети Facebook’а (ASN 32934). Эта карта показывает, как трафик изменился в интервале с 15:45 UTC до 16:45 UTC по сравнению с тремя часами до этого в каждой стране. По всему миру WARP-трафик от и к сети Facebook практически исчез.

Интернет
Сегодняшние события служат мягким напоминанием о том, что интернет — это очень сложная и взаимозависимая система из миллионов систем и протоколов, взаимодействующих друг с другом. Доверие, стандартизация и кооперация между задействованными в нём организациями — ключ к его работоспособности для почти пяти миллиардов активных пользователей со всего мира.
Обновление
Около 21:00 UTC (полночь в MSK — прим. перев.) мы увидели новую BGP-активность в сети Facebook, пик которой пришёлся на 21:17 UTC:

График ниже показывает доступность DNS-имени 'facebook.com' на DNS-ресолвере 1.1.1.1. Она пропала около 15:50 UTC и вернулась в строй в 21:20 UTC:

Несомненно, сервисам Facebook, WhatsApp и Instagram ещё понадобится некоторое время, чтобы полностью вернуться в строй, но по состоянию на 21:28 UTC Facebook уже доступен в глобальном интернете, а его DNS снова функционирует.
P.S. от переводчика
Читайте также в нашем блоге:
Комментарии (160)

major-general_Kusanagi
05.10.2021 08:38+4А из-за чего двери у сотрудников заблокировались и они не могли попасть в свои офисы?

Djeux
05.10.2021 08:48+9Как вариант, система пропусков тоже использовала инфраструктуру мордокниги и не могла достучаться для проверки допуска.
Грубо говоря, чтобы поднять упавшую систему надо чтобы упавшая система была не упавшей.

Rohan66
05.10.2021 09:48+3Интересно, а как разблокируется в случае стихийного бедствия? Должна же быть у охраны "тревожная" кнопка.

khabib
05.10.2021 10:07+3Возле дверей, изнутри комнат есть что то вроде пожарной кнопки, которая разблокирует дверь. Но и охрана получает сигнал, что дверь разблокирована аварийно.

andreishe
05.10.2021 10:18+8По правилам пожарной безопасности изнутри двери должны открываться безо всяких кнопок. Сигнализацию, конечно, это не отменяет.
khabib
05.10.2021 10:44+2Там два блока на стене, первый "красный пожарный" - про спуск лифтов на первый этаж, разблокировку всей дверей в здании и сирену. Второй - зеленый, который аварийно разблокирует конкретную дверь.
UPD. "Там" это не FB, это в нашем кампусе другой конторы
vtitans
06.10.2021 04:27Это касается пожарных выходов, а не входов и это российские правила. В других странах все по своему

cepera_ang
06.10.2021 08:19+3В штатах ещё строже — там выходы вообще датчиком движения оснащаются, который открывает двери при любом движении внутри.
И иногда 'движение' может быть из очень неожиданных источников:



anonymous
00.00.0000 00:00
F0iL
05.10.2021 09:26+5Например, в конфигурации устройств СКУД управляющий сервер или сервер БД был прописан не по IP, а по доменному имени... А DNS-а то нету из-за испорченного BGP, и все.
Ну или просто сам сервер был внутри сети, к которой пропал доступ из-за косяка в том же BGP. Вариантов довольно много, на самом деле.

Maksmsk
05.10.2021 08:44+20Больше интересно, почему анонсы по BGP пропали.

shurup Автор
05.10.2021 08:46+5Согласен, что интересно… Для этого нужно ждать информацию от самой Facebook. Им явно придётся выдать на публику какой-то отчёт. Пока есть только такое.

ermouth
05.10.2021 09:16+1Информация от ФБ исходит из пиар-департамента, так что это или лукавство для отвода глаз, или просто прямая ложь, чаще последнее. Уверен, в этот раз будет точно так же, признаки уже есть типа заявлений ФБ в Тви, что падение затронуло «некоторых» пользователей.
Так что как раз не от ФБ.

Revertis
05.10.2021 16:11От самого ФБ не лучше: https://engineering.fb.com/2021/10/04/networking-traffic/outage/

tyomitch
05.10.2021 16:36+2Вероятно, подпись под постом -- "Santosh Janardhan, VP Infrastructure" -- объясняет больше, чем сам пост.
ermouth
05.10.2021 16:48Да, по три that в одном предложении – это, конечно, не пиар-департамент готовил текст. Тем не менее, любой сотрудник ФБ обязан согласовывать такие штуки, это прямо сказано вот тут https://developers.facebook.com/devpolicy/, ищите «PR Guidelines» на странице.
Revertis
05.10.2021 19:12+1Я скорее о том, что там никаких подробностей. Пост построен по такому принципу:
Извините, что у нас получилась ошибочка, ведь нашими сервисами пользуются сотни миллионов.
Мы всё поняли, научились, такого больше не будет.
Нашими сервисами пользуются сотни миллионов (опять), и вам лучше не думать о плохом, ведь сотни миллионов мух не могут ошибаться.

Clasen01
06.10.2021 05:19+2там деталей завезли https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/

Aleksandr-JS-Developer
05.10.2021 18:27-1или лукавство для отвода глаз, или просто прямая ложь
Тошно от лжи уже. Особенно когда она такая прямая и очевидная. Они просто всех дураками выставляют

select26
05.10.2021 18:24+3У нас много ребят в FB работают. На перерыве коллега встречался с одним и вот что написал:
So a friend told me that someone did a change on TF or other automation system that changed some config on all of the routers and withdraw the routes, also like everyone knows its the same infra as all of their internal tools bu they have an emergency infra just for these cases that they can fail over all of their internal system to this infra.. apperantly 90% of the company was not familliar with this infra :sweat_smile:So no one knew how to fail over to it and most of them did not even know it exists.

v1000
05.10.2021 09:05+4Второй закон Вейнберга: если бы строители строили здания так же, как программисты пишут программы, первый залетевший дятел разрушил бы цивилизацию.
в последнее время похожее все чаще можно сказать и про администраторов, которые настраивают роутеры.

HenryPootle
05.10.2021 18:26+4Как человек, первую половину нулевых проработавший в Тир-1 провайдере, могу сказать, что так было всегда.

bolk
05.10.2021 21:37+2Этот второй закон очень слабая аналогия. Здания не обладают такой внутренней сложностью, как программы.

gudvinr
05.10.2021 22:31+3Так может это не причина, а следствие. Чем проще структура, тем сложнее её поломать.
Ну и на любой замок поглядите — средневековый или наших дней. Там такие кубернетесы внутри порой бывают. А обычные человейники — это как сайты на CMS, их делают для массового потребления.
bolk
05.10.2021 22:43Не понял вашу мысль. Вы полагаете, что программы надо писать гораздо проще, чем пишутся сейчас? Вряд ли их можно писать существенно проще, кроме того, это серьёзно замедлит время разработки, что никого не устроит.

dissable
06.10.2021 04:28+2В целом, программы едва ли не всегда должны быть написаны проще, но есть нюанс... как говорится.

Muzzy0
05.10.2021 23:00+4здания не перепроектируют заново по мере возведения каждого этажа. Или сроки горят: сдаём MVP без водопровода.
DonAgosto
06.10.2021 09:56полностью не перепроектируют конечно, но например добавить пару этажей в проект к уже строящемуся дому — это вполне распространенная вещь на самом деле
Muzzy0
10.10.2021 10:33добавить пару этажей в проект к уже строящемуся дому
А как насчёт несущие конструкции подвинуть, чтобы планировку изменить? ;)

gavk
06.10.2021 06:00+3Уважаемый строитель, перенесите-ка здание на 5 метров влево. А можно ещё такое же здание, только на 50 метров дальше? Как нужны ещё ресурсы?


rumatavz
05.10.2021 09:08+7В 16:58 UTC мы заметили, что Facebook перестал анонсировать маршруты для своих DNS-префиксов.
Это происходит по той причине, что в DNS, как и во многих других системах в интернете, используется свой механизм маршрутизации.
Автор оригинальной статьи зачем то(может для упрощения) смешал в одну кучу 7 и 4 урони модели OSI. Маршрутизация это 4, DNS 7. И связаны они в этой истории тем, что DNS сервер, как и любой другой сервер тоже находится в сети и взаимодействует в тч на 4 уронве. И в DNS нет ни маршуртизации(в строгом смысле этого слова) ни анонсирования маршрутов.
Maksmsk
05.10.2021 09:18+11Но остальная мысль правильная нет смысла говорить о доступности dns если нет маршрутизации.

chilicoder
05.10.2021 09:13+4И никакие микросервисы не спасли.
ekrokhin
05.10.2021 12:18+13А как микросервисы должны спасти от поломки маршрутизации? Монолит бы не сломался?


bulatsir
05.10.2021 09:18+12В статье нет ответа что именно сломалось у Facebook, то что DNS серверы Facebook не отвечали, разве что.

FedorovDimulya
05.10.2021 15:49+1так вроде официального отчета от самой фб и не было, вот, вся инфа, что есть представлена
Revertis
05.10.2021 16:15+2Так все подсети (ASN) Фейсбука просто пропали из Интернета. А для юзеров это было заметно по неработающему DNS, так как первое, что мы делаем при открытии ссылок это резолвим домен.

myz0ne
05.10.2021 16:33+1Там похоже не только DNS для внешних клиентов отваливался, т.к. если прописать в hosts ip facebook.com он все равно не открывался.
Отвалились не все подсети, как минимум анонсы ipv6 были доступны (судя по ripestat). Но при этом эти сервера не отвечали на пинги и на днс запросы.

Calc
11.10.2021 23:01Ну так автономная система отвалилась, а IP у них в собственности. Вот и привет
myz0ne
12.10.2021 18:55Что вы подразумеваете под "автономная система отвалилась"? Изначально подразумевалось что связанность роутеров с миром осталась, просто пропала часть анонсов.
В подтверждение: их static.xx.fbcdn.net (сервера, обслуживающие этот ип) оставался доступен и вполне отдавал статику для клиентов у кого не протух кеш днс (или есть запись в hosts).
AS у серверов статики (31.13.84.0/24 is announced by AS32934) и у ДНС (129.134.30.0/24 is announced by AS32934) одинаковые, т.е. получается что роутеры связанность имели. Как минимум в части ДЦ. И соответственно возник вопрос - почему анонс по ipv6 для серверов обслуживающих ДНС был, но при этом сами сервера не отвечали.

MartiniStar
05.10.2021 09:22Кто-то хорошо заработал на этом;)
Даже если не было атаки, а всего лишь рученки влезли куда не надо...

DarkGenius
05.10.2021 09:28+2Каким образом заработал?

mi76554
05.10.2021 10:07+1"В 16:58 UTC мы заметили, что Facebook перестал анонсировать маршруты для своих DNS-префиксов" -- вот тут мой мозг сломался. =)) DNS и BGP в одну кучу.
Для тех кто не в курсе, в протоколе BGP есть только апдейты маршрутов соседней автономной зоны. DNS это этажом выше, и никак не пересекаются.
Это такой перевод, или там действительно такие чапаевские птицы?tyomitch
05.10.2021 10:20+9Перевод в порядке. Вероятно, это место следует читать как "В 16:58 UTC мы заметили, что Facebook перестал анонсировать маршруты для префиксов серверов своих DNS-зон."
Calc
11.10.2021 23:03Ну автономная система анонсирует айпишники в глобальную сеть. Днс сервера у них свои и на своих айпишниках (странно что нет резерва в другой AS). Ну а дальше просто каскад. Нет ИП, нет ДНС, нет КЭША, нет данных

askv
05.10.2021 10:13-13Похоже, Цукерберг предал идеалы демократии и завязал все сервисы на себя лично, без резервирования...

johnfound
05.10.2021 10:27+13Сегодняшние события служат мягким напоминанием о том, что интернет — это очень сложная и взаимозависимая система из миллионов систем и протоколов, взаимодействующих друг с другом. Доверие, стандартизация и кооперация между задействованными в нём организациями — ключ к его работоспособности для почти пяти миллиардов активных пользователей со всего мира.
...
В 1968 году Министерство обороны США посчитало, что на случай войны Америке нужна надёжная система передачи информации, и предложило разработать для этого компьютерную сеть.
А потом, что-то пошло не так.
tyomitch
05.10.2021 10:40+35Да в общем-то всё так: несмотря на отключение куска сети, через который ходила существенная часть мирового трафика — весь остальной интернет продолжал работать.
Сравните это, например, с историей Evergreen весной, когда затор в одной точке поставил раком мировую логистику на пару недель.
Kvakosavrus
05.10.2021 13:39+4Тем не менее что-то в архитектуре явно сделано нехорошо.
Это же огромная контора с серверами по всему миру. Так почему он упал весь, а не для какой-то части пользователей?
Построили недостаточно отказоустойчивым.

up40k
05.10.2021 14:38+9Есть одна древняя рекомендация - не держать все авторитативные NS в одной IP-сети класса C.
По хорошему, со времён внедрения CIDR она должна звучать как "не держать все авторитативные NS в одной AS".

hiewpoint
05.10.2021 15:56+8Для отказоустойчивости надо иметь DNS в разных ASN, которые должны управляться отдельно, т.е. так, чтобы такие проблемы с BGP анонсами не становились глобальными.

1A1A1
05.10.2021 17:32+1Я так неверной строчкой в Ansible продовые сервера положил разом. Кластер, вся фигня, но не спасло от обычной ошибки в конфиге.
xeonz
05.10.2021 12:03+9>А потом, что-то пошло не так.
А потом все стали переходить от децентрализованной модели изначальной сети к централизованной, где есть выделенные точки управления всей сетью. Руками ходить на каждое отдельное устройство всем надоело, решили разливать изменения всякими модными зумерскими ansible'ами, использовать REST API, NET CONF и прочие централизованные вещи. И вот одно неосторожное движение и вместо единичного отказа лежит уже вся инфраструктура.
booyakacrew
05.10.2021 14:29+5netconf и rest api не имеют никакой связи с централизацией. rest api может вызываться/выставляться наружу микросервисами, конфиги по netconf тоже заливаются/принимаются микросервисами.
Руками никто никуда не ходит, потому что рук не хватит в энтерпрайзе и хайлоаде. Для этого используется ETSI NFV MANO. Другое дело, что внешний/внутренний периметр доступа есть в любой системе, хоть централизованной, хоть нет и если положить его весь, то может оказаться сложным удаленно его поднять обратно. Это я вам как ответственный бумер сообщаю.
Другое дело, что "положить его весь" не должно быть доступно одной группе людей, это факт. Проблема, похоже, действительно в централизации, но не архитектуры инфраструктуры, а ролей доступа к настройкам BGP. Возможно также частично проблема, а точнее задержки в её решении, заключаются и в децентрализованности BGP.
Revertis
05.10.2021 16:20+1Можно было просто разные подсети анонсить из разных ASN, да ещё и с разных точек и ДЦ. Плюс, иметь DNS-серверы в разных ДЦ, в разных подсетях.
xeonz
06.10.2021 11:32+2У них все так и было. Но судя по последнему отчету, они потеряли всю backbone network между дата центрами из за ошибки внесения изменений в конфигурацию роутеров (то самое централизованное управление скорее всего, про которое я писал выше). А их днс настроены так, что если теряют связь с основными сервисами, то убирают анонсы по BGP для своих адресов (считается, что данный ДЦ сломался и не надо роутить на него пользователей). И вот так получилось, что все их ДНСы во всех ДЦ потеряли связь по внутренней Backbone сети с каким то центральными сервисами и отозвали BGP анонсы.
В целом моя мысль подтверждается - виной всему излишняя централизация, которая смывает границы "домена проблемы". Сетевые протоколы всегда строились так, чтобы "домен проблемы" (объем затрагиваемых сервисов и устройств в случае точечного сбоя) был как можно меньше. Но централизованное управление ломает этот принцип и раздувает "домен проблемы" до максимальных значений, вопреки изначальному принципу.


FlashHaos
05.10.2021 11:19Интересно, как скоро государства захотят себе право авторизации запросов на инфраструктурные работы для критически важных сервисов? Сейчас почти в любой крупной конторе есть какой-либо комитет с большими шишками, которые пускают или не пускают крупные работы и тормозят тем самым процесс. Представил себе в этой роли условный Роскомнадзор - и стало страшно.
quwy
05.10.2021 14:26+20У меня через 15 минут после падения фейсбука на время пропал проводной интернет от местечкового провайдера. Причем не просто трафик ходить перестал, а даже линки на оборудовании погасли.
Сначала думал, что у них какая-то завязка на сервисы фб, и только после прочтения этой статьи появилась уверенность, что админы, похоже, настолько не верили в столь масштабное падение, что не найдя у себя никаких видимых причин сбоя, просто на всякий случай ребутнули все железо в своей сети.
Aleksandr-JS-Developer
05.10.2021 17:15+4админы, похоже, настолько не верили в столь масштабное падение
Чуваки из Cloudflare тоже первым делом полезли проверять со своей стороны. Правда их сервисы не так просто ребутнуть "на всякий случай".
Кстати, вспомнил, у меня тоже кабельный исчез на пару минут примерно в тоже время, что и лёг фейсбук

anonymous
00.00.0000 00:00
Krasnoarmeec
05.10.2021 19:14С 18:30 (по московскому) пропал проводной интернет с диагнозом "DNS lookup error". Перезагрузки роутера не помогали. Закончилась вся эта свистопляска где-то в 22-23 по московскому. Провайдер правда тоже так себе.
Место: ГДР, Дрезден.
hiewpoint
05.10.2021 20:35+4Вероятно, DNS серверы провайдера просто легли от массовых запросов от всех FB приложений его клиентов, которые ожесточённо пытались найти дорогу домой.

Sap_ru
06.10.2021 00:24+3На сотовых от хуавея новых тоже погас инет,так как телефоны проверяли его наличие пингуя что-то FB. Многие телефоны проверяют наличие инета пингуя 1.1.1.1. Вот если он погаснет...
А он погаснет, так как Роскомнадзор уже мечтает его заблокировать.
hiewpoint
06.10.2021 13:45Роскомнадзору не обязательно же блокировать пинги до 1.1.1.1, достаточно закрыть доставку tcp пакетов на 443 порт, чтобы перестал работать DoH.
ermak0ff
06.10.2021 15:34Аналогичная ситуация была на телефоне huawei p30. Мобильный интернет не работал. При попытке подключиться к WiFi телефон писал что сеть якобы без доступа в интернет, хотя с другого телефона от WiFi интернет был. Так что очевидно что проверка наличия интернета как то завязана на сервисах FB.
Teokar
06.10.2021 04:29У меня провайдер локальный (довольно крупный) вообще умер на сутки! Ровненько одновременно с падением Фейсбука. По телефону - автоответчик "у нас авария, исправляем". Через час пришла смс "авария на магистральном кабеле". И только сегодня в обед кое-как заработало.
Киев.





saaivs
05.10.2021 14:38+21В стародавние времена, когда миллениалы ещё не пребывали в эйфории от удалёнки, а зумеры только начали появляться на свет, у бородатых сисадминов уже в ходу была такая примета: "Удалённая настройка сети - это к дальней дороге..." :)
6 часов даунтайма как раз очень похожи на типичный экстренный перелёт :)

johnfound
05.10.2021 14:40+1Может быть, я не понимаю, но BGP, это протокол прикладного уровня, поверх TCP. Он служит для динамического обновления маршрутов. Отсутствие BGP пакетов не должно сразу валить всю сеть.
Может быть через некоторое время, когда последние маршрутные таблицы не обновятся и перестанут соответствовать реальной конфигурации сети. Да и тогда, должны упасть только те части сети, которые поменялись.
Или я не понимаю как работает Интернет?
Elsajalee
05.10.2021 14:51+2Написано: "маршруты были отозваны" (=удалены) - были сообщения обновления.

YaDr
05.10.2021 16:32+5Нет, интернет работает не так.
Нет keepalive = сессия падает по hold time = всё принятое из нее удаляется. Hold time обычно секунд 180.
Как сессии упадут - всем с кем есть BGP разошлются апдейты, те своим пирам разошлют и тд.
Минут 10 - и префиксов фейсбука как бы и не было никогда :-)
johnfound
05.10.2021 17:34А это всегда так работало? Потому что мне кажется, что коммуникации на нижних уровнях, как-то не должны зависеть от протокол прикладного уровня.
YaDr
05.10.2021 18:07+5Я так понимаю, вы сейчай про модель OSI говорите. Она концептуально-условная, служит только для для разделения "слоёв". Никаких реальных зависимостей там нет.
В реальности оказалось удобно обмениваться маршрутами через прокотокол построенный на TCP. Перенос BGP ниже - если, например, накостылять какой-нить MAC-BGP где будут только MAC-адреса в заголовках - смысла не имеет. Что так апдейты пропадут и l3 уйдёт, что так.

mayorovp
05.10.2021 22:56+2Они и не зависят в том смысле, что если согласованно остановить демон, который отвечает за BGP, на всех роутерах сети — маршруты сохранятся и сеть продолжит работу.
Но пока этот самый демон активен — он управляет маршрутами, и может эти самые маршруты вовсе удалить. Что и делает при исчезновении партнёра, который эти маршруты передал.
johnfound
06.10.2021 01:38-1Ну, так гораздо понятнее. Выходит, что они себе сепуку сделали. Ведь, после падения сети, TCP тоже работать не будет. И восстановить маршруты не получится, так как BGP работает поверх TCP.
tyomitch
06.10.2021 09:06BGP -- не единственный способ управлять маршрутами. Достаточно задать маршрут вручную, и TCP поднимется. (Что, по-видимому, и было сделано.)
hiewpoint
06.10.2021 13:49Нет, они именно починили BGP, а не руками загружали на магистральные маршрутизаторы партнёров статические маршруты до своих IP диапазонов.

Balling
06.10.2021 09:13+1Вас не смущает, что DHCP тоже происходит до работы сети? Разумеется TCP работать будет. И они всего-то обрушили DNS. Кого-то до сих пор волнует DNS? Есть же facebookcorewwwi.onion и facebookwkhpilnemxj7asaniu7vnjjbiltxjqhye3mhbshg7kx5tfyd.onion
Все нормальные приложения тоже обязаны иметь ip fallback.
mayorovp
06.10.2021 10:13В нормальной конфигурации BGP не управляет теми маршрутами, через которые сам работает: внешние соединения BGP работают между соседними роутерами, а внутренние работают через сеть, управляемую другими протоколами или тоже статикой.
А вот что и правда у них наверняка отвалилось, это SSH и SNMP.
Calc
11.10.2021 23:07+1Вот вы пошли в IANA и купили айпишники. Вам надо сообщить миру о том, что они у вас есть. Тут включается AS + BGP. Вот кто то что то сделал и по таймауту эти связи ушли + спецы не могли достучаться до серверов (через интернет ходят?).
Тут либо надо было находиться внутри сети L2/L3 с наличием IP, либо топать в офис пешком

yushkin
05.10.2021 16:38Падение BGP для внешних операторов - следствие какой-либо внутренней проблемы внутри ЦОД ФБ.
Такое часто бывает при редистрибьюции full view в IGP. Ложится вся сеть и определение первопричины занимает очень много времени (т.к. тасктрекеры тоже лежат).
Maksmsk
05.10.2021 19:59+1При редистрибьюции в igp не пропадут анонсы. С чего бы….
yushkin
05.10.2021 21:19Правда?
Maksmsk
06.10.2021 10:06Ну если только BGP роутер узнавал об этой сети из IGP, не имел интерфейсов в этой сети и не было прописано типа ip route x.x.x.x/x null 0. То да сеть пропадёт если роутеры igp отвалятся.
Я бы сделал ставку на «автоматизацию» как писали выше.
yushkin
06.10.2021 13:01При случайной редистрибьюции full view в IGP (к примеру ospf) железка умирает на пересчете топологии, и все остальные - тоже. Может она, конечно, пристрелит процесс ospf - но это случается не всегда, да и маршруты из IGP перестают поступать - bingo!
Calc
11.10.2021 23:05Автономная сеть перестала анонсировать себя в глобальной сети, пул айпишников выпал по таймауту.
yesasha
05.10.2021 22:39У меня подгрузка ленты на фб перестала работать ещё за день до полного падения.

lamer84
05.10.2021 23:05У меня дежавю. Такое ощущение, что буквально недавно - не больше года-двух - была статья про сбой в интернете и тоже связанный с BGP. И что-то с настройкой и обновлением роутеров. Не помню, что это было, и найти не могу.

JediPhilosopher
05.10.2021 23:38+2Да такое регулярно случается. То по глупости, то по умыслу и глупости (как кто-то там пытался через BGP у себя на территории блочить ютуб, в итоге заблочил его для половины мира). Все следствие того, что все эти протоколы разрабатывались давно, когда веб был уделом профессионалов и работал на доверии, в итоге корневые протоколы не содержат никаких адекватных защит от дураков и хакеров.

DevAdv
06.10.2021 00:49+3Год назад сам Cloudflare частично лежал из-за неправильного обновления BGP:
https://blog.cloudflare.com/cloudflare-outage-on-july-17-2020/
Diamos
06.10.2021 10:56Схема потому и идеальна, что концов не найдешь! Ну пожурят ответственного инженера, «допустившего» ошибку «где вы были с 8 до 11?» (Райкин). А тот, кому надо — купит акции по хорошей цене через различные хедж-фонды и концов не найдешь.
«Мой план прост и потому гениален» (Большой Лебовски) ))
Maxim_Q
06.10.2021 19:52Ради инетерса нужно будет через несколько дней посмотреть на рынок акций и цену Facebook.

{kind=link}
Diamos
06.10.2021 01:00+1А ведь это же гениально простая схема воздействия на рынок акций. К примеру, кое-кто заинтересованный решил закупиться по хорошей цене и пролил цену таким способом.

ncr
06.10.2021 01:18Не хочется уподобляться сторонникам теории заговора, но какое интересное совпадение с определенными событиями.
TakashiNord
06.10.2021 07:09+1я счастливый человек. Абсл не заметил проблем с Интернетом и сервисами FB.
Машина стояла на качке торрентов. DNS в роутерах прописан Google, Яндекс, и че то еще бесплатное, провайдерское стер от греха. FB - зареган, но не пользуюсь. WA - раз в неделю. Insta ? меня там 3 раза банили. на 4-ый раз голых котиков постить, было как не с руки, на время сбоя.
А так. Когда кто-то мне начинает грить, что Интернет невозможно откл, я тихонько посмеиваюсь, и напоминаю, что погранзона 30 км, а где то и целые районы с областями.
idelgujin
Ну встала у СММ-щиков работа ненадолго, ну какие-то бизнес-механизмы легли. А вот что будет если лягут подключенные облачно jQuery или bootstrap например. Кажется мне, больше половины сайтов перестанут работать корректно.
esc
Уверен, сервисы FB посещают гораздо больше людей, чем все сайты, которые получают ключевые библиотеки с одного какого-то публичного CDN. Будет повод перенести библиотеки к себе, ведь межсайтовое кэширование уже сломано и толку от единых CDN стало гораздо меньше.
ivanezko
"межсайтовое кэширование уже сломано" поясните пожалуйста
willyd
Если сайты abc.com и cba.com запрашивают одинаковые файлы cdn.com/script.js и cdn.com/style.css. То браузер будет качать эти файлы лишь однажды.
подозреваю, что теперь эта фича кеширования изменена.
dartraiden
Да, теперь браузер скачает файл дважды и будет хранить две копии. Именно так работает Network Partitioning. С ростом пропускной способности каналов связи польза от общего кэша уменьшилась настолько, что лучше отказаться от него в пользу большей приватности.
NikitchenkoSergey
В современных браузерах кеш разделяется по доменам для того, чтобы нельзя было отследить, посещали ли вы другой сайт. Например, я могу разместить скрипт с уникальным названием на сайте А, и посмотреть, загружали ли вы этот ресурс при открытии сайта Б.
bolk
Каким образом?
matshch
Сайт Б может своими скриптами подключить тот самый уникальный скрипт с сайта А и замерить время, сколько он будет грузиться. Если этот скрипт загрузится практически мгновенно — значит он уже был в кэше.
bolk
Так и думал, спасибо.
rafuck
Плюс к этому еще навскидку performance.now и :visited.
x512
А почему нельзя сохранить время загрузки этого скрипта с сайта А и отдавать сайту Б с такой же задержкой?
matshch
Сайт Б может попробовать сначала много раз реально запросить скрипт с сайта А (добавляя незначащие GET-параметры), построить текущее распределение времени загрузки данного скрипта, а потом запросить тот же скрипт ровно таким образом, как это делает сайт А, и проверить статистическую вероятность того, что время загрузки этого скрипта подходит под построенное распределение. Учитывая, что интернет сущность весьма динамичная, вполне может оказаться, что записанная заранее задержка не сойдётся с текущей реальностью, и опять же вскроется, что пользователь уже был на сайте А.
Semen55338
Толк от хранения библиотек в CDN пропал с массовым переходом на http/2.
izogfif
Но ведь CDN снижает нагрузку на собственный сайт и уменьшает время, за которое грузится ресурс, из-за того, что этот самый ресурс грузится с более близкого к конечному пользователю узла CDN. Разве нет?
johnfound
Так утверждают. Но мой опыт ясно говорит – все сайты, которые используют CDN, медленные. И наоборот, все быстрые сайты, CDN не используют.
Да, может причина и следствие перепутаны, но я бы сказал – делайте сайты, которые в CDN не нуждаются.
hiewpoint
Да-да. Если у них нет хлеба, пусть едят пирожные.
Gugic
В целом утверждение не совсем корректное. Взрослые быстрые сайты конечно же используют CDN, только они используют CDN как часть своей "собственной" облачной инфраструктуры, со своими собственными доменами, а не как какую-то левую публичную зависимость.
Cloudflare там, Google Cloud CDN, Cloudfront и иже с ними.
khegay
Я думаю, тут разные сущности CDN.
Например, я писал сервис на Angular. В нем есть возможность деплоя на другой УРЛ. Был выбрал AWS.
Никто другой не будет использовать эти скрипты на своих сайтах. А вот для пользователей скорость загрузки сайта уменьшается, так как запрос идет к ближайшему для них серверу.
Wendor
Знали бы вы, как спасает CDN, когда твои сервера раздают hls-видео на тысячи людей
Semen55338
Это тоже влияет, но основной эффект снижения нагрузки предполагался за счет уменьшения количества запросов в веб-серверу, которые не могли выполнятся параллельно в рамках одного TCP соединения, что стало не актуальным с появлением http/2, который поддерживает мультиплексирование.
select26
Повод перенести библиотеки к себе был всегда. Именно из за ненулевой вероятности такого случая.
И даже частичная потеря связности для клиента (например РКН) запросто обрушит сайт при недоступности того же jquery.
Никогда не понимал почему оставляют внешнюю ссылку. И никогда не принимал работу с внешними ссылками на ресурсы.
Gugic
Помнится когда под горячую руку РКН при попытках блокировки телеграмма попали гугловские айпишники, огромное количество сайтов встало колом от того, что использовало блокирующую загрузку шрифтов с гуглового fonts.google.com. (браузер ждал таймаута и только после него загружал сайт).
VitalKoshalew
Не оправдывая завязку на внешние ресурсы, замечу, что по стандарту browser не должен создавать много одновременных соединений с одним доменом. А с разными — может. Поэтому, положив библиотеки на другие домены, можно добиться их параллельной загрузки. Если бы ещё и про fallback кто-нибудь думал при этом, то это было бы не худшим решением.
Во многих случаях, как уже заметили выше, HTTP/2 нивелирует выигрыш, при условии нормальной ширины канала между сервером и пользователем.
select26
Даже если и так, никто не мешает использовать, например, домен static.yourdomain.com, который вы контролируете, для хранения зависимостей.
kost
Можно чуть подробнее об этом?
Ссылку на стандарт? И «много» — это сколько?
VitalKoshalew
RFC2616 §8.1.4
На практике в последние годы без прокси-сервера лимит у некоторых browser-ов можно было повысить или даже был повышен по умолчанию, с прокси-серверами было максимум 2, когда я проверял в последний раз.
johnfound
RFC-2119:
Если очень хочется, то можно.
Akuma
Уже ложилось, помню. Про быстренько перенесли к себе те, кто умел, остальные дождались поднятия, ничего особенного.
Acuna
Заскриню этот коммент чтобы запостить этот скрин когда уже совсем скоро эта страна будет отрезана от интернета в рамках т. н. "суверенного интернета". Ничего ведь особенного не произошло.
grumbler66rus
В описываемом вами сценарии все сайты, размещённые на зарубежных хостингах, будут недоступны
Acuna
Плохо что до сих пор остались люди, не понимающие сарказм, живя в этой стране, у них же все нормально и "ничего особенного" не произошло.
Ansud
Ага, плюс встала работа везде, где есть "Login with Facebook"
fishHook
а эти ресурсы должны же кэшироваться браузером?
Acuna
Должны, только вначале же для этого их нужно откуда-то получить чтобы закэшировать уже в браузере юзера
susnake
У меня в последние несколько месяцев bootstrap отрыгивается на некоторых сайтах
pavelsc
Принцип Парето в отношении сайтов еще более перекошенный. Как правило это легаси недобложики в своей массе с околонулевым траффиком, сейчас любой уважающий себя июнь даже калькулятор запихивает в вебпак, а веб проекты, в которые не стыдно кидать свое резюме, используют route 53.