
Почему к DDD обычно подходят не с той стороны? А с какой стороны надо? Какое отношение ко всему этому имеют жирафы и утконосы?
Специально для Хабра — текстовая расшифровка доклада «Domain-driven design: рецепт для прагматика». Доклад был сделан на .NET-конференции DotNext, но может пригодиться не только дотнетчикам, а всем интересующимся DDD (мы верим, вы осилите пару примеров кода на C#). Видеозапись доклада также прилагается.
Всем привет, меня зовут Алексей Мерсон. Я расскажу, что такое Domain-Driven Design и в чём его суть, но прежде давайте разберёмся, зачем он вообще нужен.

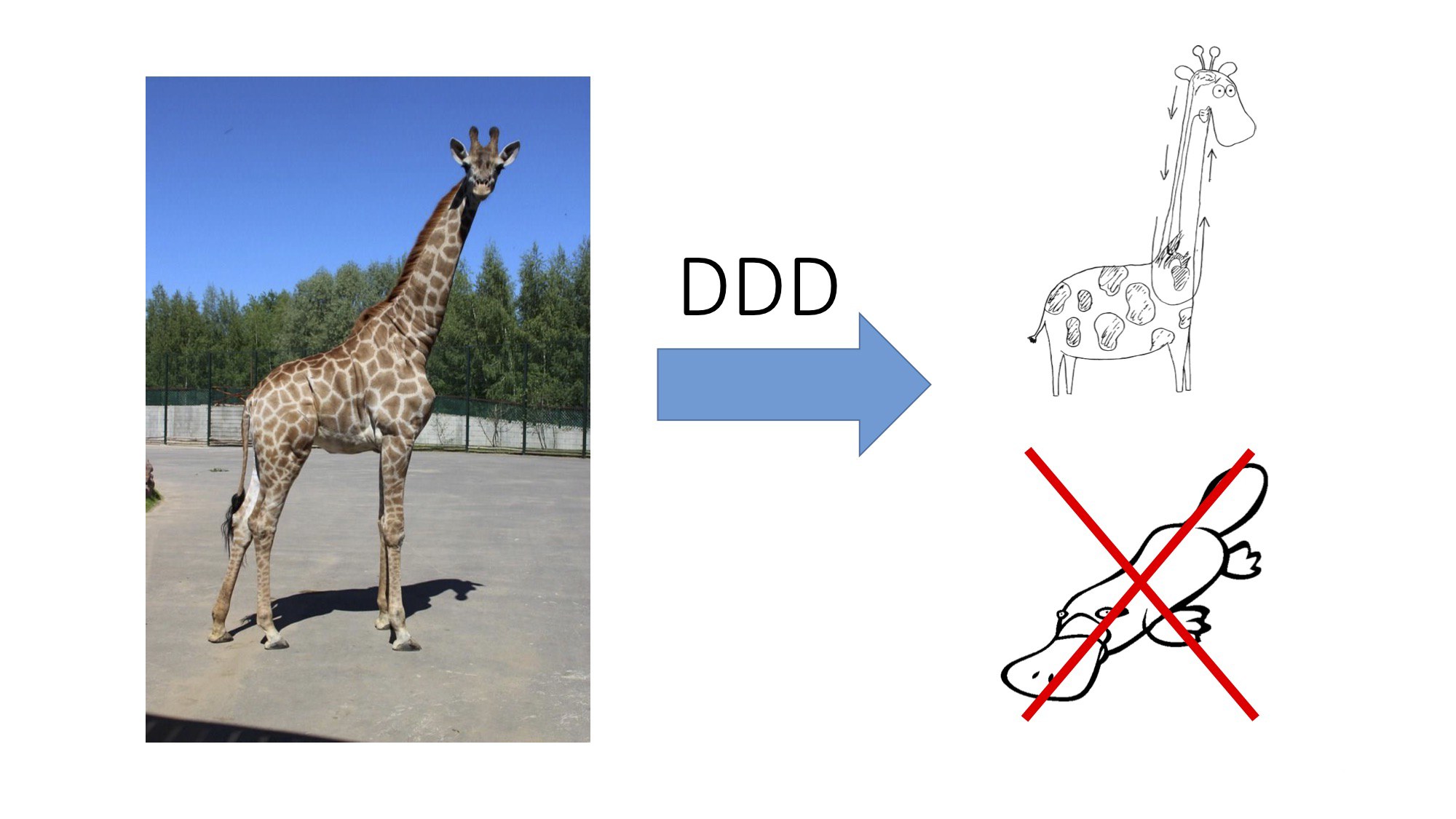
Мартин Фаулер сказал: «Немного есть вещей менее логичных, чем бизнес-логика». Жираф однозначно из этих немногих. Расстояние между мозгом и гортанью жирафа всего несколько сантиметров. Однако нерв, который их соединяет, достигает 4 метров. Сначала он идёт вниз через всю шею, там огибает артерию и потом практически тем же путём возвращается обратно.
На первый взгляд, логики действительно нет. Но это всего лишь дремучее легаси, оставшееся со времён древних рыб. У рыб, как известно, шеи нет, поэтому этот нерв проходит по оптимальной траектории. А когда после нескольких миллионов лет рефакторинга появились млекопитающие, нерв пришлось удлинить для сохранения обратной совместимости. Ну не переделывать же из-за какого-то жирафа?
Но жираф — это ладно, ведь есть утконос.

Вдумайтесь. Млекопитающее. С клювом. Живёт преимущественно в воде. Откладывает яйца. И к тому же ядовитое. Может показаться, что единственное логическое объяснение его существования — это то, что он из Австралии.
Но я думаю, что всё банальнее. Подрядчик просто подзабил на проектирование и накопипастил со StackOverflow, ну или что там было в те времена.

Я знаю, о чём вы сейчас думаете: «Алексей, ну вы же нам обещали Domain-Driven Design, а тут какое-то „В мире животных“!»
Коллеги, что такое разработка? Разработка — это когда мы берём какую-то часть реального мира, бизнес-процесса, и превращаем её в код, то есть строим программную модель. Какие проблемы нас поджидают на этом пути?
Первое — это сложность самих бизнес-процессов, то есть сложность понимания того, как работает бизнес, какие процессы там происходят, по какой логике они построены.
Вторая проблема — это реализация этих бизнес-процессов в виде кода, использование правильных паттернов, правильных подходов и так далее. Это тоже достаточно сложная тема.
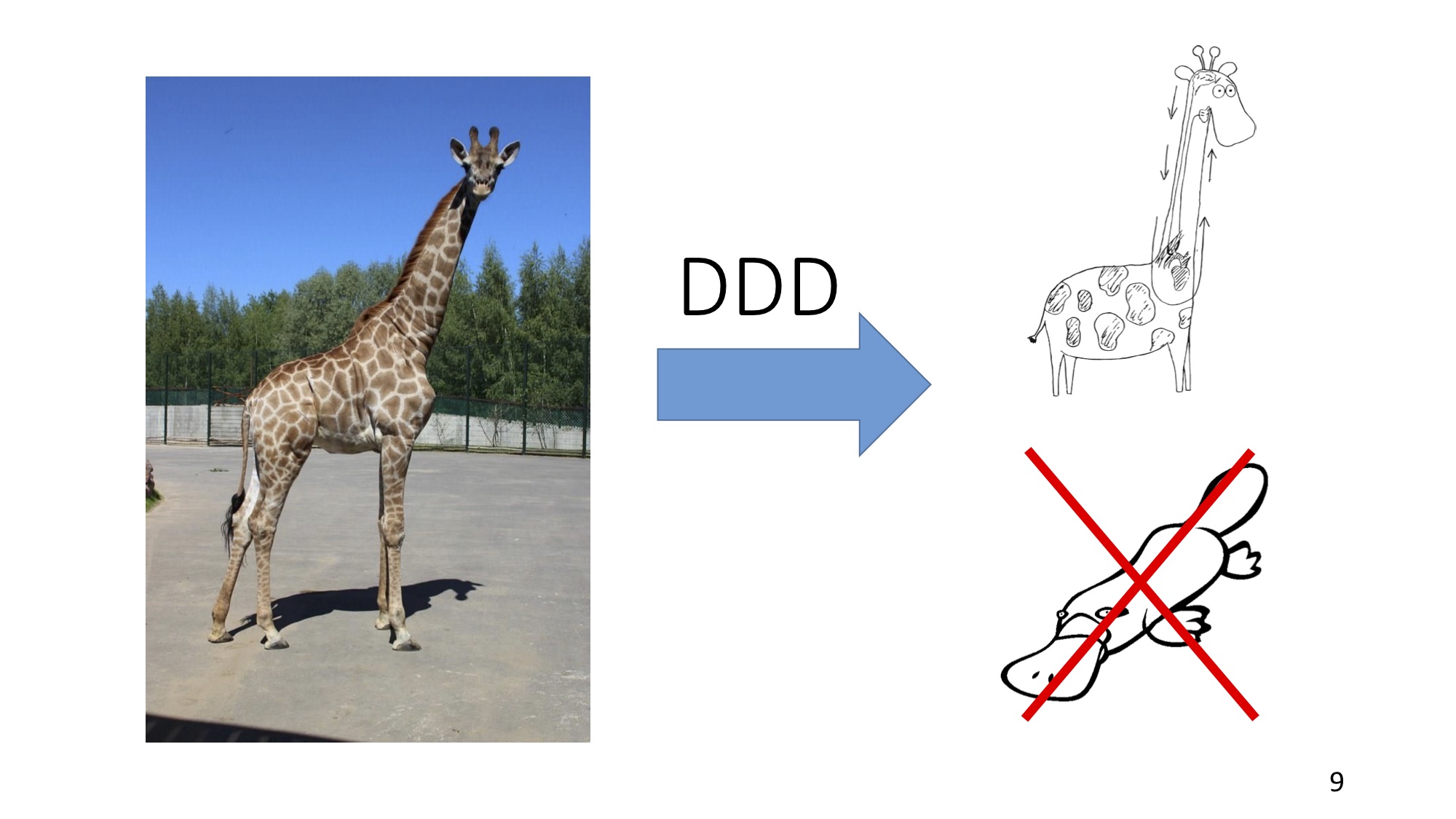
Смотрите, бизнес-процессы — они как тот жираф: начинались с простейших одноклеточных, а потом на вас смотрит «это», и никто уже не понимает ни «откуда оно взялось», ни «как оно работает».
Чтобы построить успешную модель такого процесса, нужно в первую очередь ответить на вопрос «зачем?». Зачем мы хотим построить эту модель? Каких целей мы хотим достичь? Ведь если заказчик хотел чучело жирафа, а получил кишки, то он огорчится, даже если пищеварение в этой модели реализовано на загляденье. И заказчик потеряет не только деньги и время, он потеряет доверие к нам как разработчикам, а мы потеряем репутацию и клиента.
Но даже если мы разобрались в целях, это ещё не гарантирует, что мы не получим утконоса в результате. Дело в том, что цель мало понять. Цель нужно достичь. И в этом нам помогает Domain-Driven Design.

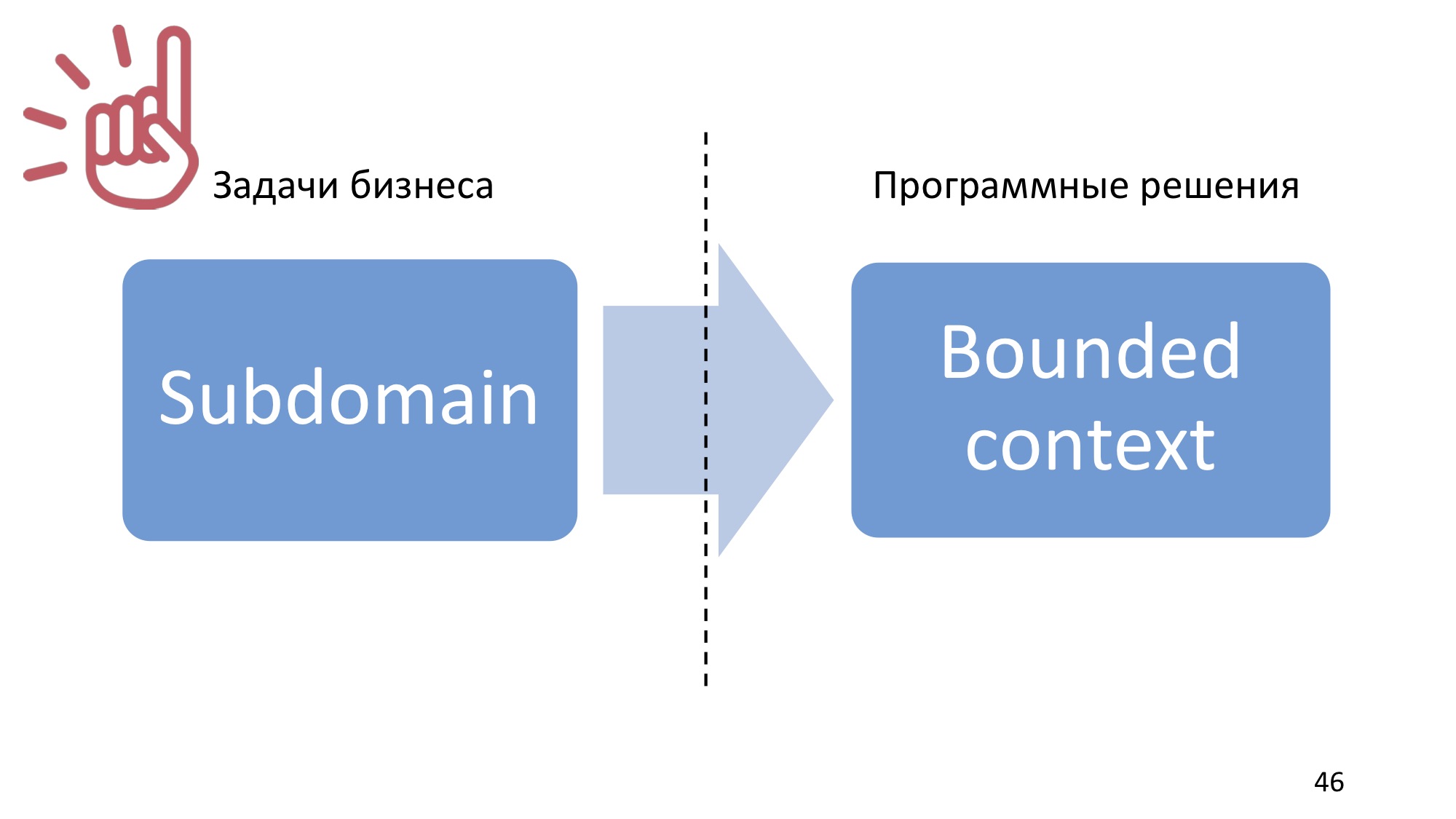
Основная цель Domain-Driven Design — это борьба со сложностью бизнес-процессов и их автоматизации и реализации в коде. «Domain» переводится как «предметная область», и именно от предметной области отталкивается разработка и проектирование в рамках данного подхода.
Domain-Driven Design включает в себя множество вещей. Это и стратегическое проектирование, и взаимодействие между людьми, и подходы к архитектуре, и тактические паттерны — это целый арсенал, который реально работает и реально помогает делать проекты. Есть только одно «но». Прежде чем начать бороться со сложностью с помощью Domain-Driven Design, нужно научиться бороться со сложностью самого Domain-Driven Design.

Когда человек начинает погружаться в эту тему, на него вываливается огромный объём информации: толстые книжки, куча статей, паттернов, примеров. Всё это сбивает с толку, и легко, что называется, не заметить за деревьями леса. Я когда-то это прочувствовал на себе, а сегодня хочу поделиться с вами опытом и помочь продраться через эти дебри, начав наконец применять Domain-Driven Design.

Сам термин Domain-Driven Design был предложен Эриком Эвансом в 2003-м в его книге с труднопроизносимым названием, которую в сообществе называют просто «Синяя книга» (Blue Book). Проблема в том, что первую половину книги Эванс рассказывает про тактические паттерны (вы все их знаете: это фабрики, сущности, репозиторий, сервисы), а до второй половины люди обычно уже не добираются. Человек смотрит: всё знакомо, пойду запилю приложение по DDD.

Справа — то, что получится, если безумно набрасывать на компилятор тактические паттерны. Слева — если использовать стратегические паттерны.

Со времени выхода «Синей книги» сформировалось довольно сильное DDD-комьюнити, многие вещи были переосмыслены. Да и сам Эванс признавался, что уже не понимает, как он мог поставить в конец такую важную вещь, как стратегическое проектирование.
И спустя 10 лет, в 2013 году, вышла «Красная книга», автор — Вон Вернон. И в этой книге изложение построено уже в правильном порядке: начинается со стратегического проектирования, с основ. А когда читателем получена необходимая база, тогда уже начинают рассказывать про тактические паттерны и детали реализации.
Обычно в докладах по DDD рекомендуют читать Эванса, в интернетах есть даже целые руководства, в каком порядке нужно прочитать главы для правильного погружения. Я рекомендую поступить проще: начать с «Красной книги», прочитать её, а уже потом переходить к «Синей».
И коль скоро стратегическое проектирование — такая важная вещь, давайте о его ключевых идеях и поговорим.
«Ключевые идеи стратегического проектирования»
В любом проекте по автоматизации бизнеса всегда есть доменные эксперты. Это люди, которые лучше всех понимают, как работают те бизнес-процессы, которые предстоит моделировать. Это могут быть ведущие разработчики, руководители, топ-менеджеры. В общем, это может быть кто угодно, лишь бы он разбирался в тех бизнес-процессах, с которыми нам нужно иметь дело.
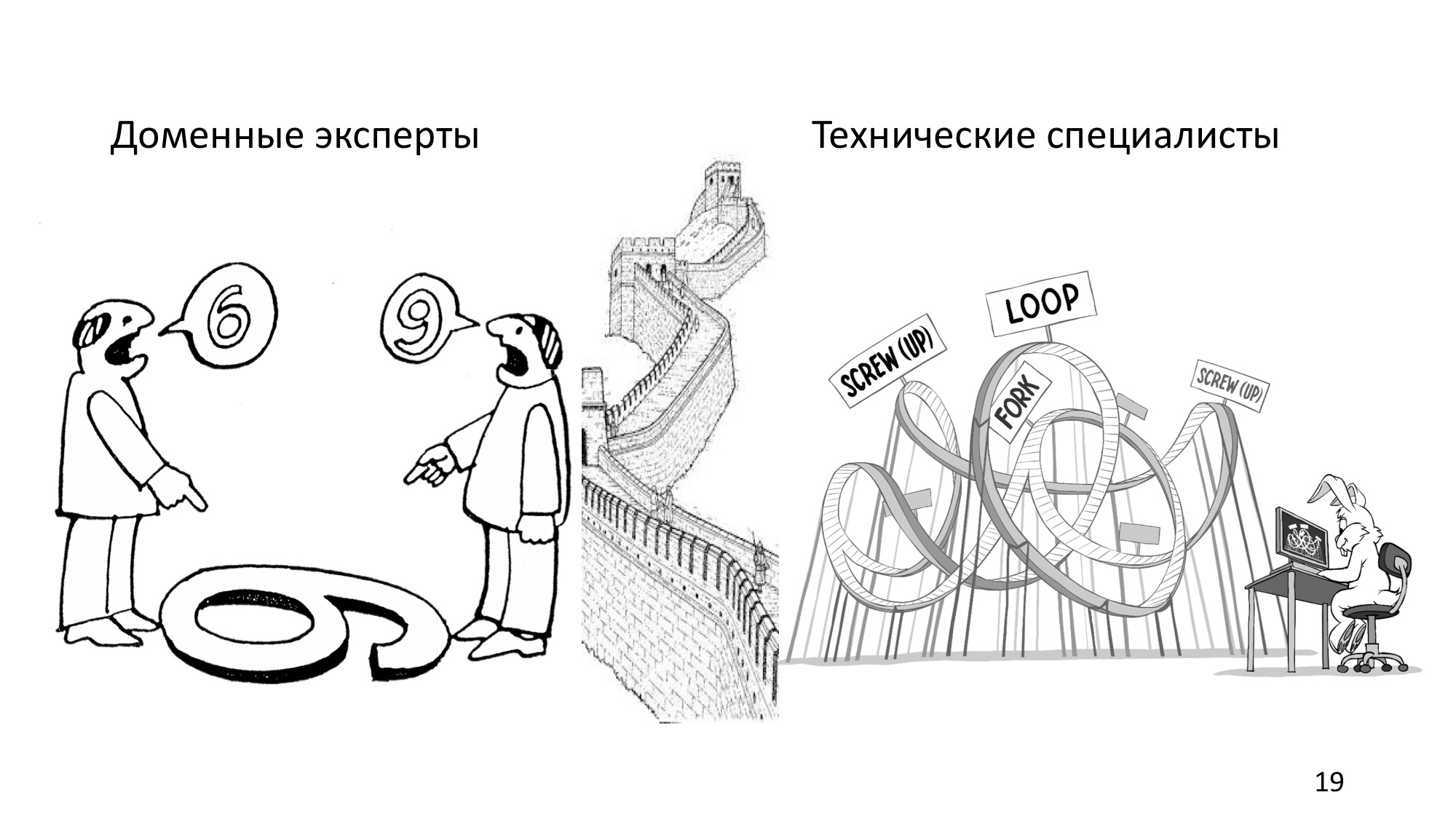
С другой стороны, есть технические специалисты: разработчики, архитекторы, которые занимаются непосредственно автоматизацией и реализацией приложений. В изображённом примере, наверное, заказчик хотел детскую железную дорогу, а получился эдакий монстр.
Почему так происходит? Потому что взаимодействие между техническими специалистами и доменными экспертами в типичной ситуации выглядит примерно так: между ними большая-большая стена, а по верху этой стены ходит менеджер и сначала пытается услышать, что ему орут с одной стороны стены, потом в меру связок пытается перекричать это на другую сторону стены, и так по кругу.
Иногда менеджер попадается глуховатый, тогда может выстраиваться целая цепочка таких менеджеров, что, естественно, не способствует успеху проекта. А как должно быть?
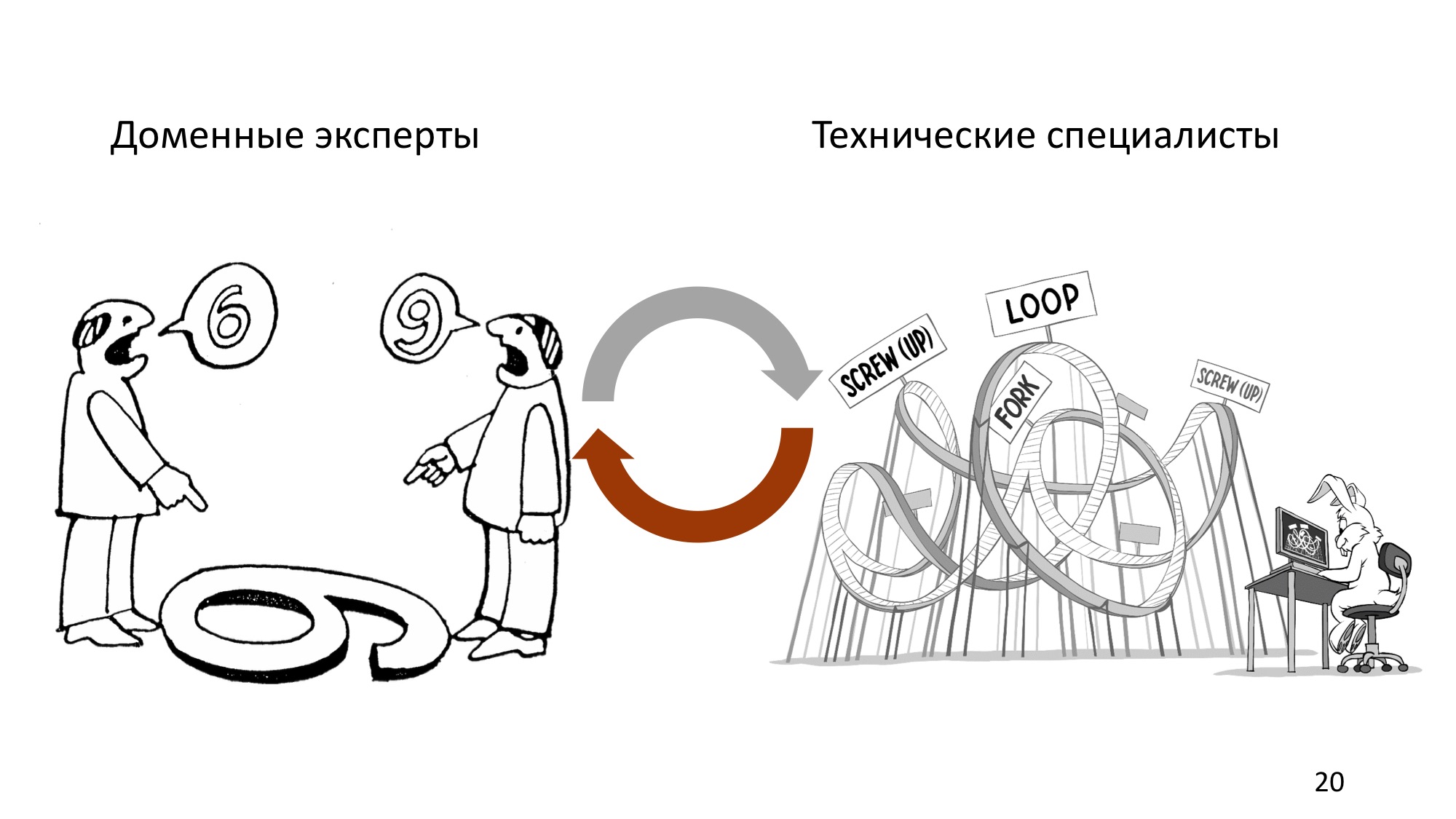
Должно быть постоянное взаимодействие. Технические специалисты, доменные эксперты — все участники проекта должны постоянно поддерживать общение, синхронизироваться, обсуждать цели, способы их достижения и зачем мы вообще всё это делаем.
И тут мы подходим к первому и, наверное, самому важному ключевому моменту и стратегического проектирования, и Domain-Driven Design вообще.

Общение между участниками проекта формирует то, что в Domain-Driven Design называется «единый язык» (ubiquitous language). Единый он не в том смысле, что он один на все случаи жизни. Как раз наоборот. Единый он в том смысле, что все участники общаются на нём, всё обсуждение происходит в терминах единого языка и все артефакты максимально должны быть в терминах единого языка, то есть начиная от ТЗ и заканчивая кодом.
Бизнес-сценарии
Для дальнейшего изложения нам нужен какой-нибудь бизнес-сценарий. Давайте представим себе такую ситуацию:

Приходит к нам директор JUG.ru Group и говорит: «Ребята, растёт поток докладов, людей, в общем, замучились всё делать вручную… Давайте автоматизируем процесс подготовки конференции». Мы отвечаем: «Окей!» — и принимаемся за работу.
Первый сценарий, который мы автоматизируем: «Докладчик подаёт заявку на доклад на конкретном мероприятии и добавляет информацию о своём докладе». Что мы видим в этом сценарии? Что есть докладчик, есть событие и есть доклад, а значит, уже можно построить первую доменную модель.

Вот у нас получается доменная модель: Speaker — докладчик, Talk — доклад, Event — мероприятие. Но доменная модель не может быть безграничной, не может охватывать всё, иначе она станет размытой и потеряет фокус, поэтому доменная модель должна быть чем-то ограничена. Это следующий ключевой момент.

И доменная модель, и ubiquitous language ограничены контекстом, который в Domain-Driven Design называется bounded context. Он ограничивает доменную модель таким образом, чтобы все понятия внутри него были однозначными, и все понимали, о чём идёт речь.
Если говорят «User», то всё сразу должно быть понятно, у него должна быть понятная роль, понятное значение, это не должен быть какой-то абстрактный пользователь с точки зрения IT-индустрии.
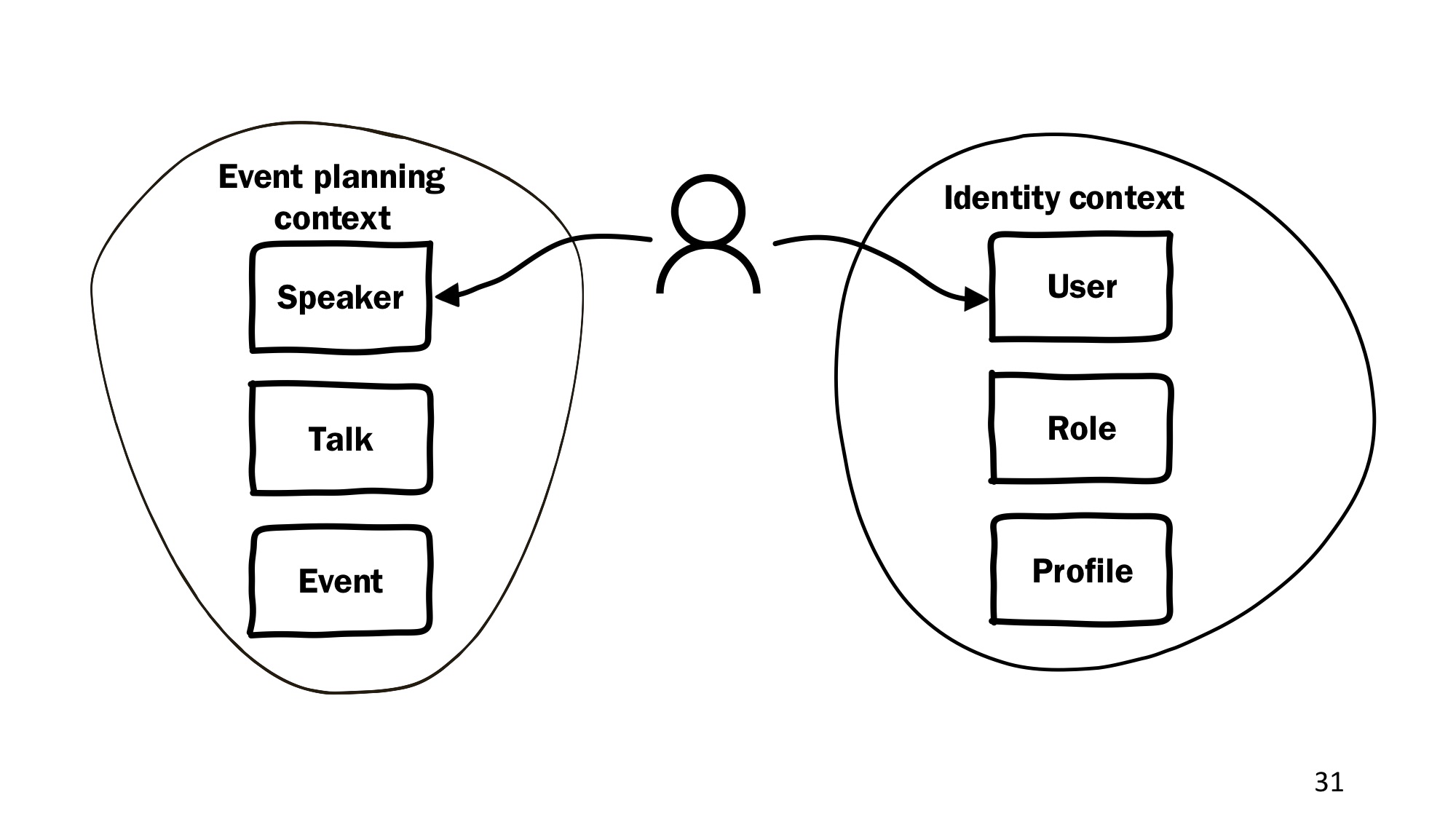
В нашем случае эта доменная модель справедлива для контекста подготовки конференции, так что находится в контексте, который мы назовём «Event planning context». Но чтобы докладчик что-то добавлял, изменял информацию, он должен как-то авторизовываться, ему нужно выдать какие-то права. И это уже будет другой контекст, «Identity context», в котором будут какие-то свои сущности: User, Role, Profile.
И смотрите, в чём здесь штука. Когда человек авторизуется в системе и собирается вносить какую-то информацию, физически это один и тот же человек, но в разных контекстах он представлен разными сущностями, и эти сущности не связаны между собой напрямую.
Если бы мы взяли и, например, отнаследовали Speaker от User, то мы смешали бы вещи, которые нельзя смешивать, и какие-то атрибуты могли бы перемешаться логикой. И модель потеряла бы фокус на конкретном значении, которое она имеет, будучи разделённой на несколько контекстов.
Демо: Sales service
Немного отвлечёмся от сухой теории и посмотрим в код.
Конференция — это не только подготовка контента, но ещё и продажи. Давайте представим, что уже был написан сервис для продажи билетов, а к нам приходит sales-менеджер и говорит: «Ребят! Когда-то кто-то написал этот сервис, давайте разберёмся, что-то мне непонятно, как скидка для постоянных клиентов считается».
Пообщавшись с менеджером, мы выясняем, что в целом сценарий этого сервиса такой: по нажатию на Checkout считается окончательная цена билета с учётом скидки постоянного клиента, и заказ переходит в состояние «Ожидание оплаты».
Код, который мы сейчас разберём, можно отдельно посмотреть в репозитории.
Открываем Solution, смотрим структуру:
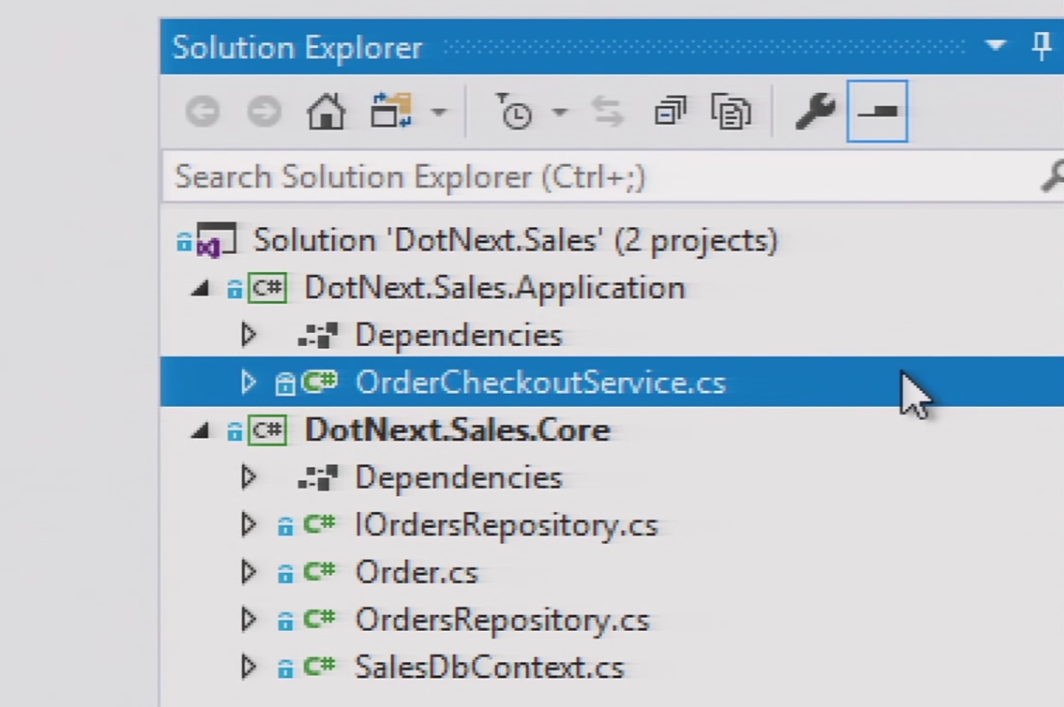
Вроде всё выглядит неплохо: есть Application и Core (видимо, про слои человек знает), Repository… Видимо, первую половину Эванса человек осилил.
Открываем OrderCheckoutService. Что мы там видим? Вот такой код:
public void Checkout(long id)
{
var ord = _ordersRepository.GetOrder(id);
var orders = _ordersRepository.GetOrders()
.Count(o => o.CustomerId == ord.CustomerId
&& o.StateId == 3
&& o.OrderDate >= DateTime.UtcNow.AddYears(-3));
ord.Price *= (100 - (orders >= 5 ? 30m : orders >= 3 ? 20m : orders >= 1 ? 10m : 0)) / 100;
ord.StateId = 1;
_ordersRepository.SaveOrder(ord);
}
Смотрим на строчку с Price: здесь меняется цена. Зовём нашего sales-менеджера и говорим: «Вот, короче, здесь считается скидка, всё понятно»:
ord.Price *= (100 - (orders >= 5 ? 30m : orders >= 3 ? 20m : orders >= 1 ? 10m : 0)) / 100;
Он заглядывает через плечо: «О! Так вот как выглядит Brainfuck! А мне вроде говорили, что ребята на C# пишут».
Очевидно, что разработчик этого кода хорошо ответил на собеседовании про алгоритмы и структуры данных. Я на школьных олимпиадах примерно в таком же стиле писал. Через какое-то время с помощью форматирования и
Думаю, многие читали книгу «Чистый код» Боба Мартина. Там он говорит про правило бойскаутов: «Место стоянки после того, как мы его покинем, должно быть чище, чем было до того, как мы туда пришли». Поэтому давайте этот код отрефакторим так, чтобы он выглядел по-человечески и соответствовал тому, о чём мы говорили чуть ранее, про ubiquitous language и его использование в коде.
Вот отрефакторенный код.
public class DiscountCalculator
{
private readonly IOrdersRepository _ordersRepository;
public DiscountCalculator(IOrdersRepository ordersRepository)
{
_ordersRepository = ordersRepository;
}
public decimal CalculateDiscountBy(long customerId)
{
var completedOrdersCount = _ordersRepository.GetLast3YearsCompletedOrdersCountFor(customerId);
return DiscountBy(completedOrdersCount);
}
private decimal DiscountBy(int completedOrdersCount)
{
if (completedOrdersCount >= 5)
return 30;
if (completedOrdersCount >= 3)
return 20;
if (completedOrdersCount >= 1)
return 10;
return 0;
}
}
Первое, что мы делаем — это выносим расчёт скидки в отдельный DiscountCalculator, в котором появляется метод CalculateDiscountBy customerId. Читается всё по-человечески, всё понятно: что, почему и как. Внутри этого метода мы видим, что у нас есть глобально два шага расчёта скидки. Первый: мы что-то получаем из репозитория заказов, тут всё по юзкейсу, можно даже не лезть внутрь, если это не та деталь, которая вас интересует сейчас. Факт, что мы получаем количество каких-то законченных заказов, после чего вторым шагом непосредственно скидку считаем по этому количеству.
Если мы хотим посмотреть, как она считается, мы идём в DiscountBy, и тут практически человеческим английским языком написано всё то же, что до этого было нашим «типа брейнфаком», всё ясно и четко.
Единственный вопрос, который мог бы возникнуть — в каких единицах измеряется скидка. Можно было бы в названии метода добавить слово «проценты», чтобы было понятно, но из контекста и фигурирующих чисел, наверное, большинство догадается, что это проценты, и для краткости это можно опустить. Если же мы хотим посмотреть, что там за количество заказов было, то мы пойдём в код Repository и посмотрим. Сейчас мы этого делать не будем. В наш Service мы должны добавить новую зависимость DiscountCalculator. И посмотрим, что у нас в итоге получилось во второй версии метода Checkout.
public void CheckoutV2(long orderId)
{
var order = _ordersRepository.GetOrder(orderId);
var discount = _discountCalculator.CalculateDiscountBy(order.CustomerId);
order.ApplyDiscount(discount);
order.State = OrderState.AwaitingPayment;
_ordersRepository.SaveOrder(order);
}
Смотрите, метод Checkout получает orderId, дальше получает по orderId заказ, по CustomerId этого заказа считает скидку с помощью калькулятора скидки, применяет скидку к заказу, ставит статус AwaitingPayment и сохраняет заказ. У нас на слайде был сценарий на русском языке, а здесь мы практически читаем перевод этого сценария на английский и всё понятно, всё очевидно.
Понимаете, в чём прелесть? Этот код можно показывать кому угодно: не только программистам, а QA, аналитикам, заказчикам. Им всем будет понятно, что происходит, потому что всё написано человеческим языком. Я использую это в нашем проекте, у нас реально QA может посмотреть некоторые куски, сверить с Wiki и понять, что там какой-то баг. Потому что в Wiki написано так, а в коде немножко по-другому, но ему понятно, что там происходит, хотя он не разработчик. И точно так же мы можем с аналитиком обсуждать код и обсуждать его предметно. Я говорю: «Смотри, вот так это работает в коде». Последняя инстанция у нас не Wiki, а код. Всё работает так, как написано в коде. Очень важно использовать ubiquitous language при написании кода.

Это и есть третий ключевой момент.
Есть очень много путаницы в Domain-Driven Design в таких вещах, как Domain, Subdomain, Bounded context, как они соотносятся, что они означают. Вроде все чего-то ограничивают, все какие-то кругленькие. Но непонятно тогда, в чём разница, зачем они такие разные придуманы.

Domain — это глобальная штука, это глобальная предметная область, в которой данный конкретный бизнес зарабатывает деньги. Например, для DotNext — это проведение конференции, для «Пятёрочки» — это розничная торговля товарами.
У больших корпораций может быть несколько Domain’ов. Например, Amazon занимается как продажей товаров через интернет, так и предоставлением облачных сервисов, это разные предметные области.
Тем не менее, это нечто глобальное и не может быть автоматизировано напрямую, даже исследовать это сложно. Для анализа Domain неизбежно делится на Subdomains, то есть на поддомены.

Поддомены — это части бизнеса, которые, говоря нашим языком, обладают высокой связностью, то есть это какие-то обособленные логические процессы, которые взаимодействуют между собой на каком-то крупном уровне.
Например, если мы берём интернет-магазин, то это будет формирование и обработка заказов, это будет доставка, это работа с поставщиками, это маркетинг, это бухгалтерия. Вот примерно такие куски — это то, на что делится бизнес.

С точки зрения DDD, Subdomain’ы делятся на три типа. И тут я хочу сказать ещё вот что: часто в книгах и в статьях Subdomain сокращают просто до Domain, но обычно в случае, когда это в совокупности с типом Subdomain. То есть, говоря «Core domain», имеют в виду Core Subdomain, не путайтесь, пожалуйста, в этом. Мне это взрывало мозг поначалу.
Subdomain’ы делятся на три типа.
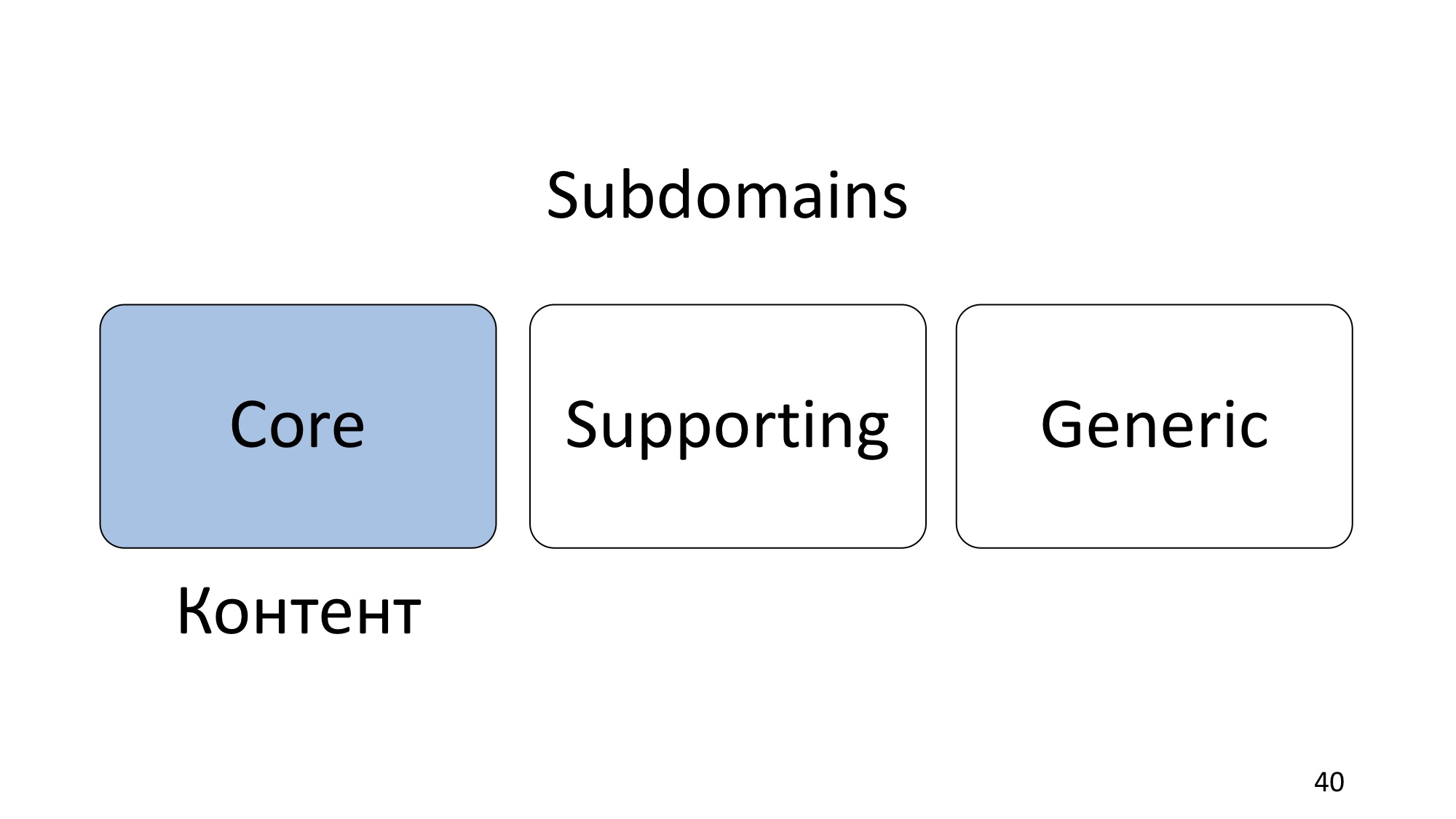
Первый и самый главный — это Core. Core — это основной Subdomain, это конкурентное преимущество компании, то, на чём эта компания зарабатывает деньги, чем она отличается от конкурентов, её ноу-хау, как ни назови. Если мы возьмём конференцию DotNext, то это контент. Вы все пришли сюда за контентом, если бы такого контента здесь не было, то вы бы не пошли или пошли на другую конференцию. Не было бы DotNext в том виде, в котором он есть.

Второй тип — это Supporting Subdomain. Это тоже важная вещь для зарабатывания денег, это тоже то, без чего нельзя, но это не является каким-то ноу-хау, реальным конкурентным преимуществом. Это то, что поддерживает Core Subdomain. С точки зрения применения Domain-Driven Design это означает, что на Supporting Subdomain тратится меньше усилий, все основные силы бросаются на Core.
Пример для того же DotNext — это маркетинг. Без маркетинга нельзя, иначе о конфренции бы никто не узнал, но без контента маркетинг не нужен.
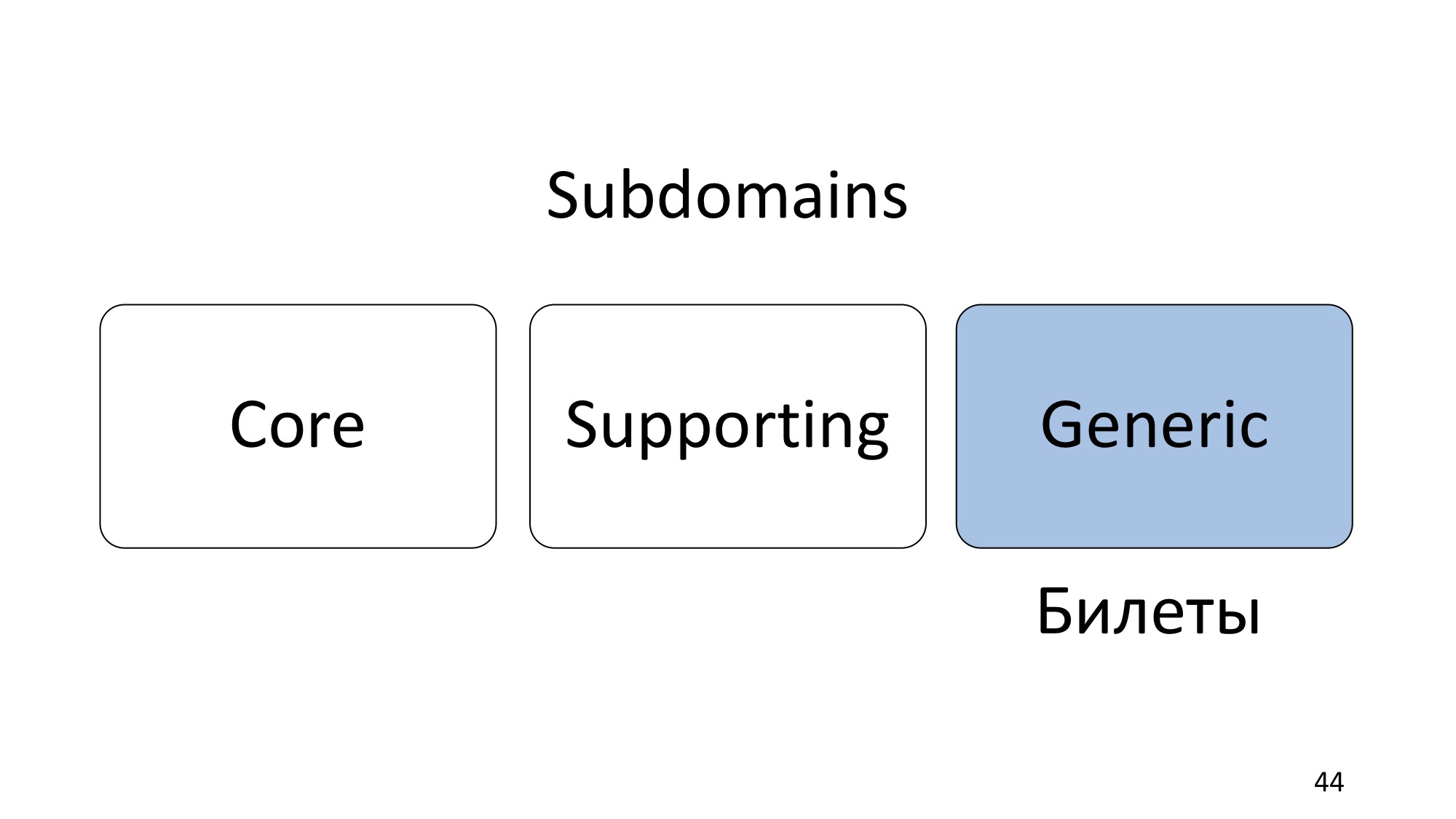
И, наконец, Generic Subdomain. Generic — это некоторая типовая бизнес-задача, которая, как правило, может быть автоматизирована готовыми продуктами или отдана на аутсорс. Это то, что тоже нужно, но уже не обязательно требует самостоятельной реализации нами, и даже более того, обычно будет хорошей идеей использовать third-party продукт.
Например, продажа билетов. DotNext продаёт билеты через TimePad. Этот Subdomain прекрасно автоматизируется TimePad’ом, и не нужно самому писать второй TimePad.
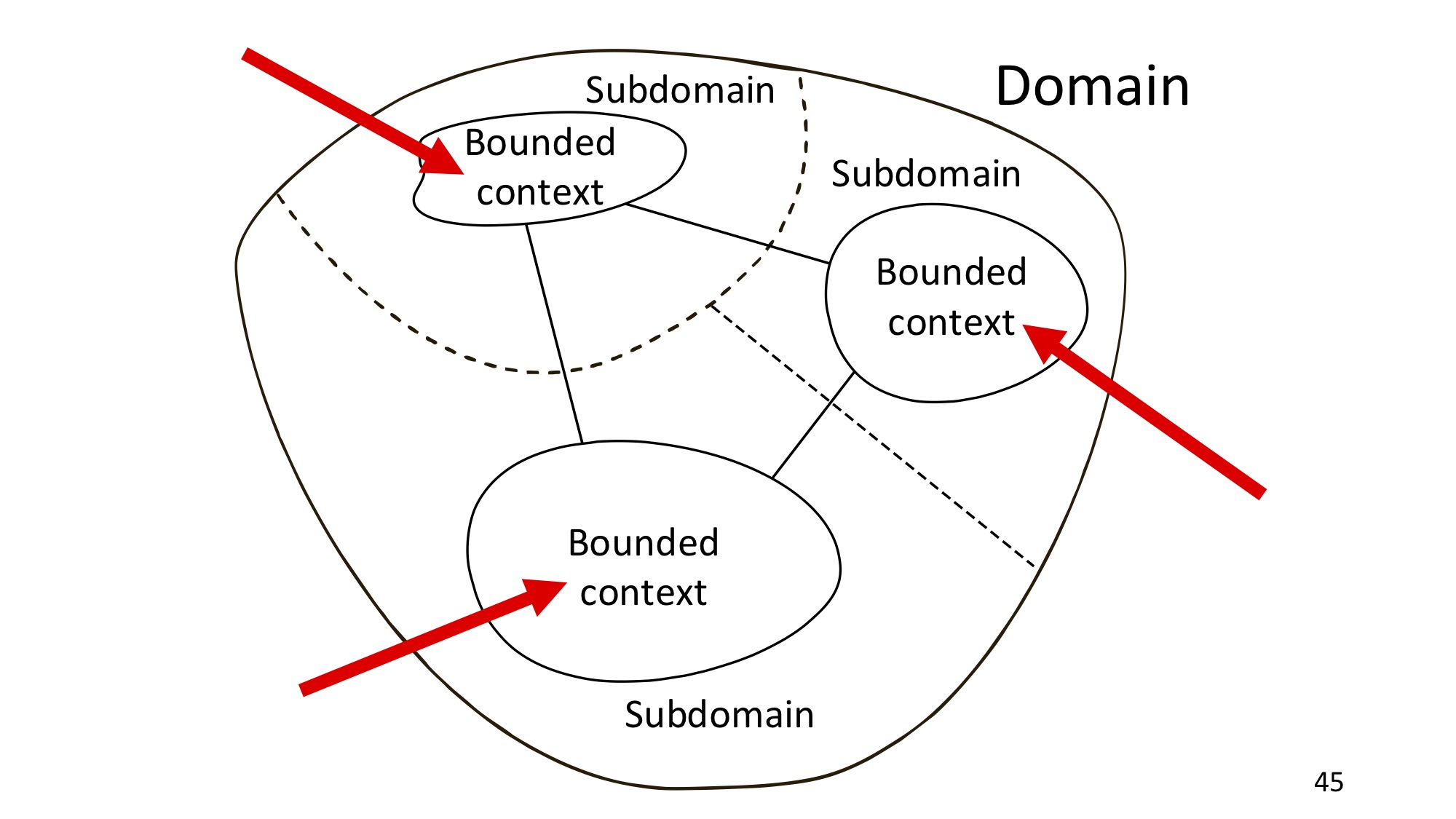
И наконец, bounded context. Bounded context и Subdomain всегда где-то рядом, но между ними есть существенная разница. Это очень важно.
На StackExchange есть вопрос, чем отличается bounded context от Subdomain’а. Subdomain — это кусочек бизнеса, кусочек реального мира, это понятие пространства постановки задачи. Bounded context ограничивает доменную модель и ubiquitous language, то есть то, что является результатом моделирования, и соответственно, bounded context — это понятие пространства решения. В процессе выполнения проектов происходит некий маппинг Subdomain’ов на bounded context’ы.

Классический пример: бухгалтерия как Subdomain, как процесс маппится, автоматизируется, например, 1С Бухгалтерией, Эльбой или «Моим делом» — так или иначе автоматизируется каким-то продуктом. Это будет bounded context бухгалтерии, в котором будет свой ubiquitous language, своя терминология. Вот такая между ними разница.

Если мы вернёмся к DotNext, то, как я уже сказал, билеты маппятся на TimePad, а контент, который является нашим Core Subdomain’ом, маппится на кастомное приложение, которое мы разрабатываем для управления контентом.
Размер bounded context
Есть такой момент, который вызывает много вопросов. Как выбрать правильный размер для bounded context? В книгах можно найти такое определение: «Bounded context должен быть ровно таким, чтобы ubiquitous language был полным, непротиворечивым, однозначным, консистентным». Классное определение, в стиле математика из известного анекдота: очень точное, но бесполезное.
Давайте обсудим, как же нам понять всё-таки: то ли это должен быть Solution, то ли Project, то ли namespace — какую шкалу нужно приложить к bounded context?

Первое, что можно практически везде прочитать: в идеале один Subdomain должен маппиться на один bounded context, то есть автоматизироваться одним bounded context. Звучит логично, потому что и там, и там есть ограничения какого-то обособленного бизнес-процесса, в обоих случаях какие-то бизнес-термины, фигурирует единый язык. Но здесь надо понимать, что это идеальная ситуация, у вас не обязательно будет так, и не обязательно пытаться этого достичь.
Потому что, с одной стороны, Subdomain может быть достаточно крупным, и может получиться несколько приложений или сервисов, которые будут его автоматизировать, поэтому может получиться, что одному Subdomain будет соответствовать несколько bounded context.
Но бывает и обратная ситуация, как правило, это характерно для легаси. То есть когда сделали большое-большое приложение, которое автоматизирует всё на свете на этом предприятии, тогда получится наоборот. Одно приложение — это один bounded context, там модель наверняка будет какая-то неоднозначная, но Subdomain’ы от этого никуда не делись, соответственно, нескольким Subdomain’ам будет соответствовать один bounded context.
Когда стала модной микросервисная архитектура, появилась другая рекомендация (хотя они друг другу не противоречат): один bounded context на один микросервис. Опять же, звучит логично, люди так реально делают. Потому что микросервис должен брать на себя какую-то чёткую функцию, которая внутри обладает высокой связностью, а с другими сервисами общается через какое-то взаимодействие. Если вы используете микросервисную архитектуру, можете брать для себя эту рекомендацию.
Но и это не всё. Ещё раз напомню, что Domain-Driven Design про очень многое: про язык, про людей. И нельзя абстрагироваться от людей и обойтись только техническими критериями в этом вопросе. Поэтому я написал так: один контекст равен икс человек. Раньше я думал, что икс примерно равен 10, но мы немножко подискутировали с Игорем Лабутиным (twitter.com/ilabutin) и вопрос остался открытым.
Здесь важно понять вот что: единый язык остаётся единым, пока все участники на нём разговаривают, обсуждают и все понимают его однозначно. Понятно, что бесконечное количество людей не может говорить на одном языке. Наша история человечества наглядно это показывает. В любом случае появляются какие-то диалекты, какие-то свои значения, сейчас можно даже мемы добавить и так далее. Так или иначе язык размоется.
Поэтому надо понимать, что количество людей, которые используют данный единый язык и, соответственно, принимают участие в разработке, в автоматизации, ограничено. В книгах ещё говорится о каких-то политических причинах: если две команды работают под руководством разных менеджеров и будут работать на одном bounded context’е, а эти менеджеры почему-то друг с другом не дружат, начнутся конфликты и фокус потеряется. Поэтому гораздо проще и правильнее будет сделать два bounded context’а на каждую команду и не пытаться совместить то, что не совмещается.
Архитектура и управление зависимостями
С точки зрения Domain-Driven Design, абсолютно всё равно, какую архитектуру вы выберете. Domain-Driven Design не про это, Domain-Driven Design про язык и про общение.

Но есть один важный момент, с точки зрения критериев выбора архитектуры, который нас интересует с позиции Domain-Driven Design: наша цель — максимально избавить бизнес-логику от сторонних зависимостей. Потому что, как только появляются сторонние зависимости, появляется терминология, появляются слова, которые не входят в единый язык и начинают замусоривать нашу бизнес-логику.

Разберём классический пример архитектуры: всем известная трёхслойная архитектура. Доменный слой как только не называют (здесь Business layer): и business, и core, и domain — всё это одно и то же. В любом случае, это слой, в котором располагается бизнес-логика, и если она зависит от слоя данных, значит, какие-то концепции из слоя данных перетекут так или иначе в доменный слой и будут его замусоривать.
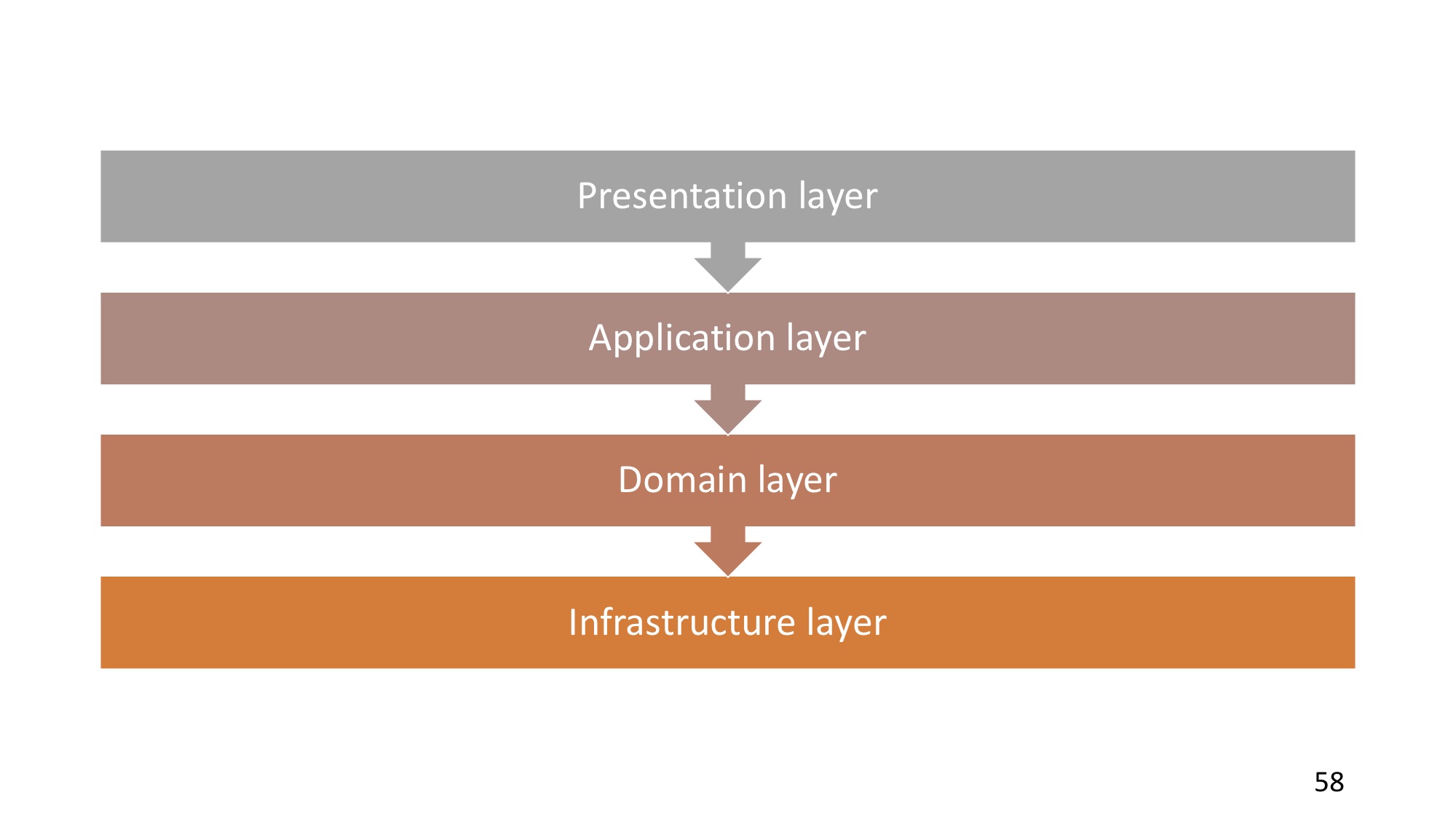
Четырёхслойная архитектура — суть примерно та же, доменный слой всё равно зависит, и раз он зависит, к нему проберутся сторонние, ненужные зависимости.

И в этом смысле есть архитектура, которая позволяет этого избежать, — это onion-архитектура («луковая»). Её отличие в том, что она состоит из концентрических слоёв, зависимости идут снаружи в центр. То есть внешний слой может зависеть от любых внутренних, внутренний слой не может зависеть от внешних.
Самый внешний слой — это пользовательский интерфейс в глобальном смысле (то есть это не обязательно человеческий UI, это может быть и REST API, и что угодно). И инфраструктура, которая зачастую в общем тоже выглядит как ввод/вывод, та же база данных, фактически, слой данных. Все эти вещи оказываются во внешнем слое. То есть то, за счёт чего приложение так или иначе получает какие-то данные, команды и так далее, выносится вовне, и доменный слой избавляется от зависимости от этих вещей.
Дальше идёт Application layer — довольно холиварная тема, но это слой, в котором располагаются сценарии, юзкейсы. Этот слой использует доменный слой для реализации своих концепций.
В центре находится доменный слой. Как видим, он уже не зависит ни от чего, он становится вещью в себе. И именно поэтому доменный слой часто называется «Core», потому что это ядро, это то, что находится в центре, то, что не имеет зависимостей от сторонних вещей.

Один из вариантов реализации такой onion-архитектуры — это гексагональная архитектура, или «порты и адаптеры». Такую картинку я привёл для устрашения, рассказывать про это я не буду. В конце поста есть ссылочка на одну из миллиона статей про эту архитектуру, можно будет почитать.
Немного про тактические паттерны: Separated Interface
Как я уже говорил, во-первых, большинство тактических паттернов всем знакомы, а во-вторых, весь смысл моего доклада в том, что не в них суть. Но паттерн Separated Interface мне нравится отдельно, и я хочу про него сказать отдельно.
Давайте вернёмся к коду нашего микросервиса и посмотрим, что же там было с репозиторием.

В доменном слое был интерфейс репозитория IOrdersRepository.cs и его реализация OrdersRepository.cs.
using System.Linq;
namespace DotNext.Sales.Core
{
public interface IOrdersRepository
{
Order GetOrder(long id);
void SaveOrder(Order order);
IQueryable<Order> GetOrders();
#region V2
int GetLast3YearsCompletedOrdersCountFor(long customerId);
#endregion
}
}
Вот мы добавили сюда некий метод для получения заказов за последние три года GetLast3YearsCompletedOrdersCountFor.
И реализовали его в каком-то виде (в данном случае через Entity Framework, но это может быть что угодно):
public int GetLast3YearsCompletedOrdersCountFor(long customerId)
{
var threeYearsAgo = DateTime.UtcNow.AddYears(-3);
return _dbContext.Orders
.Count(o => o.CustomerId == customerId
&& o.State == OrderState.Completed
&& o.OrderDate >= threeYearsAgo);
}
Смотрите, в чём проблема. Репозиторий оказался в доменном слое, его реализация в доменном слое, но код, начиная с DateTime.UtcNow.AddYears(-3), по своей сути не принадлежит доменному слою, и не является бизнес-логикой. Да, LINQ делает его более-менее очеловеченным, но если бы здесь, например, были SQL-запросы, всё было бы совсем печально.
Смысл паттерна Separated Interface в том, что интерфейс сервисов, которые мы используем в доменной логике, объявляются в доменном слое. Речь идёт о репозиториях и тому подобных сервисах, в которых детали реализации этих сервисов не являются бизнес-логикой. Бизнес-логикой является сам факт существования этих сервисов и факт их вызова и использования в доменном слое. Поэтому интерфейс репозитория остается в доменном слое, а реализация переезжает в инфраструктурный.
Я подготовил другой вариант. Интерфейс репозитория остаётся в сборке Core, а вот реализация переезжает в Infrastructure.EF.

Таким образом, те понятия, которые не были свойственны для доменного слоя, мы вынесли в инфраструктуру. В качестве побочного эффекта мы можем подменять эту инфраструктуру какой-то другой реализацией. Но основная цель не в этом, основная цель в том, чтобы, как я уже говорил, избавить доменную логику от сторонних зависимостей.
Ещё раз о языке
Давайте поговорим ещё раз, и ещё раз, и ещё раз о языке.
В самом начале мы построили доменную модель «speaker — talk — event». Я думаю, что ни у кого она не вызвала особых вопросов.
А вот сценарий, на основе которого мы строили эту доменную модель:

Смотрите, сценарий на русском, а доменная модель получилась на английском.
Для неанглоязычных разработчиков это то, с чем приходится жить постоянно.
Каждый из вас, скорее всего, постоянно делает такой процесс: переводит с русского на английский и обратно. Тем, кто работает с англоязычными заказчиками и проектами, немножко проще, потому что требования на английском, обсуждение с заказчиками на английском, как правило, все сценарии на английском, код на английском, и остается только общение внутри команды на русском, которое быстро обрастает англицизмами (клиент — кастомер, заказ — ордер). И та когнитивная нагрузка, тот оверхед, который создаётся постоянным переводом, немножко отступает.
Но для тех, кто работает с русскоязычными доменами, особенно которые очень сложно переводятся на английский язык, этот перевод становится проблемой. Я с этим сталкивался, и это действительно проблема.
С этой точки зрения становится понятнее логика компании 1С, когда они сделали свой язык программирования на русском. Потому что бухгалтерия, финансы — это сложная предметная область, в которой очень много терминов, и усложнять её дополнительно постоянным переводом было бы очень жёстко.

Поэтому вот так выглядит код 1С. PascalCase добавляет веселья, но в целом это то, что может прочитать любой человек, который понимает всю эту
Они выкрутились, но мы-то чем хуже?

Вот я перевёл, это тот же самый use case, который мы обсуждали, только теперь он на русском. Это реальный код, который реально компилируется. Смотрится забавно в комбинации с ключевыми словами C#, которые перевести, к счастью, нельзя. Вы можете реально показать этот код тому, кто не знает английский, и он поймёт, что происходит.
У нас летом в Петербурге был круглый стол, посвященный архитектуре, там зашла речь и про Domain-Driven Design. Мы обсуждали в том числе вопрос, связанный с языком, и там был человек, сказавший, что они в компании реально пишут на C# доменный слой на русском. Им это позволяет снизить порог входа в проект для новых разработчиков и в принципе снизить оверхед в понимании доменной логики.
Меня очень интересовало, сталкиваются ли они с проблемами где-нибудь на Continuous Integration. Потому что, хотя всё везде уже прекрасно с локализацией, Юникод и всё такое, где-нибудь обязательно вылезет какая-нибудь проблема. Но они сказали, что только один раз что-то такое встречали, сейчас не помню, где именно. Скажем так, в 95% случаев у них всё работало прекрасно, хотя у них не ручная сборка, а Continuous Integration, всё настроено, TeamCity есть. Это всё работает.
Я не призываю с сегодняшнего дня выйти с доклада и писать сразу же на русском, причём даже старые проекты отрефакторить и сделать всё на русском. Нет. Но надо понимать, что есть определённое предубеждение против русского языка в среде не 1С-программистов, и понимать, что это именно предубеждение. И если в вашем случае польза для «пациента» превышает вред, то технически так можно делать. И даже есть люди, которые так делают, и у них получается.

Давайте подытожим и получим тот самый рецепт для прагматика, который изучает Domain-Driven Design.
Первое — это общение, общение и общение. Domain-Driven Design — это штука про язык, а не про технологию. Технология — это решение тех проблем, которые возникают, когда вы хотите свой код сделать человеческим в терминах ubiquitous language. Вы сталкиваетесь с техническими проблемами, и они решаются техническими паттернами, но не наоборот. То есть репозиторий не ради репозитория, репозиторий ради того, чтобы вынести реализацию из доменного слоя, а в доменном слое всё было бы читабельно.
Дальше. Всё имеет свои пределы, свои рамки. Все модели ограничены какими-то контекстами, как только вы пытаетесь объять необъятное, у вас будет фейл, потому что потеряется однозначность терминов, все запутаются, начнут называть одни вещи так, другие эдак, или наоборот, название одно, а один понимает под этим то, другой — это. И это приведёт к проблемам.
У доменной модели должно быть минимум зависимостей. Все лишние зависимости нужно выжигать огнём. Но это как стопроцентное покрытие тестами. Здесь не надо проявлять излишний фанатизм. Это не значит, что нужно добиться того, чтобы ни одной зависимости не было. Потому что тогда вам придётся писать свой DSL-язык. У вас всё равно есть зависимость от .NET-фреймворка, у вас есть ещё какие-то вещи, поэтому достичь стопроцентной чистоты, скорее всего, не получится, но это нормально. Вам нужно стремиться, чтобы этих зависимостей было минимум.
Наконец, бизнес-логика должна писаться выразительным языком. Она пишется для человека, а не для компилятора, поэтому вам нужно использовать ubiquitous language для бизнес-логики. И вы придёте к успеху.
Полезные ссылки напоследок
- Хабраблог Максима marshinov Аршинова. У него много статей, он очень хорошо пишет про DDD: например, «Как мы попробовали DDD, CQRS и Event Sourcing и какие выводы сделали». Я рекомендую его почитать, это очень будет полезно, у него очень много реальных историй.
- Блог Джимми Богарда, автора AutoMapper и фреймворка MediatR. И блог Александра Бындю, он пишет на русском и про Domain-Driven Design, как это работает в русскоязычных проектах.
- Дальше есть такой интересный сайт «F# for fun and profit», там про то, как использовать F# в Domain-Driven Design. Написано интересно, хотя местами, на мой взгляд, там шарп гнобят незаслуженно.
- И наконец, обещанная статья про порты и адаптеры, про гексагональную архитектуру.
На этом всё, спасибо, и вот ещё раз ссылочка на GitHub.
От организаторов DotNext:
Как заметил Алексей, «если бы на конференции не было такого контента, вы бы сюда не пришли». Сейчас на сайте следующего DotNext (состоится 15-16 мая в Петербурге) уже появились описания первых докладов. Полная программа будет позже, но с 1 марта билеты подорожают, так что с решением пойти выгоднее определиться уже сейчас.
Комментарии (27)

Vogr
19.02.2019 17:57(Не в плохом смысле, я даже скорее одобряю) Мне внезапно поплохело(автоматом) и появился нервный смешок от того, что я увидел код на C# на русском(точнее названия).
Так что вы правы — эти предрассудки...
Я понимаю, что доклад был больше про суть и про людей(стратегию), а не про подходы к реализации(хоть и об этом тоже говорили). Но интересны и технические подробности.
По поводу связности: (вольный перевод) вы говорили, что при работе разработчиков над архитектурой график связности объектов стремится к нулю и (очевидно) не может им быть достигнут. Говорится также с точки зрения прагматика о "минимальной связности", который достижим(в примерах это были интерфейсы).
(Я понимаю что это пример, но я сейчас говорю о примере как реальном кейсе)
В моем понимании на практике даже такой способ, когда интерфейс выносится в Layer_1, а Layer_2 его реализует(и мы общаемся с Layer_2 через интерфейс, который находится в Layer_1), ведет к сильной связности, т.к может вполне меняться Layer_2, а за ним должны поменяться интефрейсы(в том числе и интерфейс в Layer_1). А изменения интерфейса влечет изменение реализации Layer_1, ибо он использует тот самый интерфейс.
Да, есть соглашение о том, что когда такие вещи происходят, то меняется реализация, а интерфейс класса(назовем его контрактом) не менятеся(т.е публичный методы не меняются, меняются только private). Но опять же случаи бывают разные и далеко не всегда удается избежать этой цепочи.
Вопрос: какой уровень связности вы в продакшене считаете приемлемым(что работает для вас)?(пример есть пример) И я понимаю ответ то, что работает для меня, то и хорошо. Но вопрос состоит том, как именно Вы боретесь с подобным. Что считаете идеалом минимальной связности(скорее теоретический и недостижимый). Про DSL слышал, но все имеется ввиду возможно реализуемый на практике, но не достижимый по каким-либо причинам (денежным, временным и т.д), конечно в рамках адекватного.
P.S. И да, как писал amarao выше. По-моему мнению, Очень серьезную когнитивную нагрузку несет в себе объяснение архитектурный подходов на простых примерах. Я понимаю, это доклад, времени мало и донести мысль нужно. Мне всегда казалось, что необходим серьезный большой проект с вкраплением вики и ссылками на фрагменты кода для пояснения той или иной точки зрения. Не видели ли вы подобного проекта на просторах необъятного интернета?(именно по DDD) Если нет такого, не хотели бы начать разработку сложного open-source проекта, который показывал сложное на сложном? Если да, то не против к нему присоединиться.

m_a_d Автор
19.02.2019 18:541. Про уровень связности: я отталкиваюсь от текущей обстановки. Если начинаю чувствовать, что дальнейшее упорство в разделении зависимостей становится слишком дорогим, то останавливаюсь. Естественно, что со временем появляется интуитивное чувство, которое сразу говорит, когда хватит. В каких единицах измерить уровень связности, я не знаю, поэтому количественно затрудняюсь ответить.
2. Про разнесение интерфейсов по слоям: тут важно понимать, где начало графа, а где конец. И, соответственно, кто (какой слой) диктует изменения, а кто подстраивается. Если интерфейс в доменном слое, а реализация в инфраструктуре, то от изменения инфраструктуры интерфейс в домене меняться не должен. Потому что он описывает доменную логику, причина для изменения которой — бизнес-процессы. Понятно, что в реальном мире бывает по-другому (например, были все методы синхронными, а стали асинхронными), тогда да, придется по всей вертикали проводить изменения.
3. Про примеры. На самом деле есть ровно один способ посмотреть на серьезный большой проект: пойти работать на такой проект. Вариант немного хуже — читать книги. Книжный объем уже позволяет обрисовать довольно масштабную картину, хотя до реального проекта все равно будет далеко. Еще как вариант мастер-классы от мэтров типа тех же авторов книг. В интернетах нормальных примеров я не встречал. Там обычно загоняются на тактические паттерны, но без реальной предметной области и соответствующих процессов они не имеют смысла (с точки зрения ддд). С опен-сорсом (а точнее с крауд-сорсом, вы же это имеете в виду, да?) та же проблема: нету тех самых бизнес-задач и бизнес-процессов, от которых отталкивается разработка в коммерческих проектах.
Danik-ik
19.02.2019 22:06+2Гипотетически интерфейс в layer1 предназначен не для "показать все возможности layer2", а для обслуживания интересов layer1. Поэтому он поменяется только тогда, когда изменятся потребности layer1, как бы ни менялся layer2. Нет здесь сильной связности. Не должно быть.
Практически, на этапе экспериментов, если мы ещё не поняли задачу, или если задача изменяется по ходу, или если мы определяем потребности через возможности — тогда да, слои потребностей и возможностей испытывают сильное взаимовлияние и взаимопроникновение.
Но по мере конкретизации целей границы обретают очертания, и их реализация в коде уже начинает нести больше пользы, чем боли и нелепых телодвижений. И вот тут уже надо тщательно убирать из интерфейса всё то, что определяется в layer2, оставляя в нём только задачи и определения из layer1. И аминь, всё по классике и на пользу делу.
poxvuibr
19.02.2019 18:03Но надо понимать, что есть определённое предубеждение против русского языка в среде не 1С-программистов, и понимать, что это именно предубеждение.
Какое ещё предубеждение? Я ничего не имею против русского языка в коде, я имею много чего против предложения переключать язык каждый раз, как понадобилось написать ключевое слово. Я не хочу мучительно вспоминать, где у меня сейчас точка с запятой и куда жать, чтобы на экране появилась двойная кавычка. Или одинарная. Чем в первую очередь хороша работа на англоязычного заказчика? Да тем, что раскладку нужно переключать только, когда заходишь в чатик к друзьям. Ну, или на хабр.
m_a_d Автор
19.02.2019 18:09Я, кстати, выяснил, когда готовил примеры к докладу, что решарпер (кажется это он, а не студия) умеет автоматически распознавать комбинации с ключевыми словами, независимо от раскладки. То есть пишете «зкшмфеу», а оно само превращается в private.
khim
19.02.2019 18:25На самом деле ключевая фраза «вы можете реально показать этот код тому, кто не знает английский, и он поймёт, что происходит» — потому что парная к ней «зато вы не сможете показать этот код тому, кто не знает русского — ибо для него это будет, как китайские иероглифы».
То есть всё зависит от специфики того, с чем вы работаете: если у вас задачка тривиальная вот именно с точки зрения программирования, главное — уметь выпытать из заказчика чего он, собственно, хочет — то можно использовать русские имена: C#, Java и даже C++ (по крайней мере clang) их понимают. Но вот тот факт, что у вас после этого возникнут сложности с использованием stackoverflow… об этом не стоит забывать…m_a_d Автор
19.02.2019 18:30Конечно. Поэтому я и говорил, что нужно принимать такое решение исходя из соотношения пользы и вреда. Главное знать, что «так можно было» (с)
mayorovp
20.02.2019 08:57+1Сложности с использованием stackoverflow возникнут только если вывалить туда сырой код. Если делать как полагается — готовить MCVE — то сложностей не будет.
khim
20.02.2019 14:16Вы по ссылке ходили? Если вы работаете с кем-то подготовленным файлом руссиыикации C++, скажем, то вы можете не знать даже что «целое» на StackOverflow — это «int», а «повторить» — это «for».
Подготовка MCVE в таких условиях окажется сложнее, чем попытки понять «что происходит» самому — и, главное, большой шанс, что поиск похожих, уже отвеченных, вопросов находить не будет.mayorovp
20.02.2019 14:24Ну извините, не разглядел я ссылку на godbolt там где ожидал увидеть ссылку на changelog или кусок документации…
Да, согласен: если переопределять ключевые слова языка — то пользоваться stackoverflow будет трудно. Причём, что характерно, трудно будет пользоваться даже русскоязычным разделом…
poxvuibr
19.02.2019 18:46То есть пишете «зкшмфеу», а оно само превращается в private.
А потом пишете cf[hfybnm, а обратно оно не возвращается. Или возвращается, но не всегда, или переключается в неподходящий момент. В общем проблемы с переключением никуда не денутся.
maslyaev
19.02.2019 21:45Спасибо. Интересная тема, хороший доклад.
Немножко вставлю свои пять копеек.
берём какую-то часть реального мира, бизнес-процесса, и превращаем её в код, то есть строим программную модель
Ну, не знаю… Весьма распространённый взгляд на то, чем мы занимаемся, но это никак не уменьшает его ущербность. Чтобы понять, в чём подвох, взгляните на аналогичное рассуждение: берём доску и гвоздь, и превращаем их в молоток, то есть в натурную модель доски и гвоздя. Абсурд ведь, разве нет? Модельерский подход к проектированию систем не менее абсурден, просто его бредовость мы привыкли не замечать.
Моделирование как вспомогательный инструмент мы, конечно, все применяем. Порисовать квадратики со стрелочками в разных нотациях — святое дело. Пользуясь приведённой аналогией, нам при создании молотка полезно понимать, как гвоздь может быть загнан в доску. Но боже упаси буквально переносить модель в программную систему. Программа, предназначенная для удовлетворения каких-то нужд, не является ни самими этими нуждами (точно так же, как молоток не является гвоздём), ни ситуацией удовлетворения нужд. Это самостоятельная сущность. Инструмент. И части этого инструмента совсем не обязаны один-в-один логически мэппиться на предметную область. Что-то, конечно, естественным образом смэппится, но что-то и нет. Это абсолютно нормально.
Мне, например, неоднократно удавалось выкручиваться из сложных ситуаций при помощи дизайна, основанного на метафорах (MDD?). То есть не пытаемся «отразить» в программе сущности реального мира (это всё равно невозможно, потому что реальный мир бесконечно разнообразен, холистичен и постоянно изменчив), а задумываемся над тем, какими инструментами пользователю было бы понятно, как решать его задачи. Текстовый редактор, например, использует метафору (не модель!!!) листа бумаги, мэйл — метафору почтового ящика, файловая система — полки с папками.
И ещё маленький момент. При использовании всяких модных методик дизайна самое главное — не скатиться в Pattern Driven Design. Невозможно думать книжкой готовых рецептов. Думать можно только головой.
forsyte
20.02.2019 11:52+1Если моделирование абсурд, то человеческое мышление в принципе абсурд.
maslyaev
20.02.2019 13:58Нам бы сейчас не скатиться в схоластику. А то увязнем в рассуждениях о том, является ли капля воды моделью Вселенной, а Луна моделью Солнца.
Давайте немножко посмотрим на примеры, приведённые в докладе. Классический модельный подход подразумевает, что мы должны построить модель предметной области и заложить её в конструкцию создаваемой системы. Допустим, при исследовании задачи у нас нарисовались понятия «Speaker», «Talk», «Event». В нашей модели это у нас классы объектов. Объект — это некая сущность, «живущая» внутри системы, имеющая некие свойства и обладающая неким поведением. То есть в реальном мире спикеры делают толки на эвентах, и внутри программы есть тоже «спикеры», «делающие» «толки» на «эвентах». Считается, что чем точнее объекты программы повторяют (обычно говорят «отражают») поведение объектов реального мира, тем полезнее программа, но это справедливо только для симуляторов. Имитационная модель — да, она как раз предназначена для того, чтобы прогнать ситуацию внутри компьютера, и для имитационной модели действительно важно, чтобы объекты в программе «отражали» объекты реального мира. Теперь ответьте честно, много ли из того, чем приходится лично Вам заниматься, является имитационными моделями в полном классическом смысле этого понятия? Вангую, что примерно 0%. Это очень узкая ниша, хоть и весьма уважаемая.
Даже если заходить на задачу со стороны структуры базы данных, гораздо полезнее оказывается не пытаться своими таблицами воспроизводить реальный мир, а озаботиться поиском ответов на вопросы типа таких:
— Какого рода факты мы желаем хранить в своей базе?
— О чём эти факты? (именно из ответов на такие вопросы у нас появляются entities)
— Как эти факты между собой логически связаны? (здесь у нас появляются constraints)
— Как должен быть организован процесс добавления фактов в базу?
— Какие производные факты мы желаем получать на основе первичных?
(Можно заметить, что здесь у нас базовым понятием странным образом является не «объект», а «факт». Впрочем, ничего удивительного, ещё со времён старика Кодда математической основой баз данных служит исчисление предикатов, которое по своей сути не про объекты, а про факты.)
Если мы занимаемся моделированием, то сразу нас выносит на то, что Speaker имеет фамилию и имя, а Talk имеет дату/время. И мы радостно запихиваем атрибуты в таблички. А потом оказывается, что спикером может быть компания, которая пока не решила, кто конкретно из её сотрудников будет докладываться. А рядом с докладом появляются такие реально отсутствующие в грешном физическом мире вещи, как «отмена», «перенос», «замена» (уведомление об отмене в реальности существует, а сама отмена — как-то не очень). И нам, оказывается, полезно вместо атрибута TalkDateTime таблицы Talks иметь отдельным потоками назначения, переносы, замены и отмены, а TalkDateTime вычислять на их основе.
Когда у нас первичны модели и их объекты, мы обречены вляпаться в не имеющую ни одного до конца нормального решения проблему ORM, об которую вся индустрия убивается уже несколько десятков лет. А если отречься от глупостей (ну или хотя бы снизить уровень догматичной упёртости в них), то можно помочь себе тем, что взглянуть на вопрос с альтернативного ракурса. Например, вместо ORM поиметь ROM. То есть база — это набор фактов, а в набор объектов она транслируется в зависимости от угла зрения. То есть факт «Алексей Мерсон далает доклад про ДДД продолжительностью 1 час» оказывается реляционно-объектно отмэппленым на объекты «Алексей Мерсон», «доклад про ДДД», и ещё на расписание эвента. С какой стороны на набор фактов посмотрели, такой набор объектов получили.
Ой, что-то я слишком много ереси написал… ;)mayorovp
20.02.2019 14:01Моделирование поведения — это моделирование поведения. А DDD — оно про моделирование предметной области.
maslyaev
20.02.2019 14:22Предметную область вполне бывает полезно моделировать в нотации IDEF0, в которой функции (поведение) — это квадратики, а сущности — всего лишь стрелочки. В EPCшной нотации (aka ARIS) основные квадратики — это события (тоже поведение), а сущности пасутся вокруг основных квадратиков во вспомогательных прямоугольничках с закруглёнными краями.
Можно провести параллель с функциональным стилем в программировании, где функция — это тоже объект.
Вообще, мне кажется, в своей основе DDD — не только и не столько про моделирование, сколько про учёт контекстов при работе с понятийным аппаратом. Весьма здравая, кстати, идея.mayorovp
20.02.2019 14:31Какая разница где ещё бывает полезно моделировать предметную область? DDD — это не программирование ради моделирования, а моделирование ради программирования.
maslyaev
20.02.2019 14:59А программирование ради решения бизнес-задачи, которая обычно немножко шире, чем программирование.
Если DDD — это моделирование, то почему оно тогда не DDM? Откуда тогда там слово «дизайн»?
Жаль, что мне так и не удалось донести светлую мысль, что моделирование и дизайн — это совсем разные вещи. Что первое может быть подпроцессом второго, а может и наоборот. Народ привык трактовать понятие «моделирование» глобально, смешивая в одну кучу вообще всё. Даже пример с гвоздём, доской и молотком не помогает, хотя казалось бы куда нагляднее :(

superyateam
20.02.2019 14:23Я наверно из тех, кто прочитал только первую половину синей книги. На самом деле, не заметил в вашем докладе того, что я не знал. Мне кажется, в самых первых главах автор очень много говорит про ubiquitous language.
Пример с 1С очень хороший. Сам по малолетке считал программирование на русском языке полным «зашкваром», но только после этой книги понял, насколько это правильно в русскоязычной предметной области программировать на русском. Единственная проблема — постоянное переключение раскладки. Напрягать будет.
p.s. Шутка про сиськи неудачная, я бы даже сказал глупая и пошлая. Но она и не зашла — в зале никакой реакции, несмотря на ожидание докладчика. Он даже взял паузу.

fetis26
21.02.2019 23:03интересная статься. начинаю читать Синию книгу и вот размышления нужно ли это вообще привели меня сюда. Луковую архитектуру впервые увидела у Роберта Мартина "Чистая архитектура", он тоже топит за то, чтобы доменная логика была независима. Паттерн Separated Interface у него называется Dependency Inversion и он широко его применяет и показывает на разных уровнях от кода до архитектурных решений.
amarao
Зачем в качестве примера используют простые вещи? Для объяснения БОЛИ от СЛОЖНОСТИ не надо показывать простую вещь и говорить «вот тут вот было сложно» (на самом деле просто) ...«и мы сделали проще» (на самом деле чрезмерно развели воды).
Показывайте настоящие примеры. Желательно, не из мира продаж, где весь процесс тривиален и всем известен.
aensidhe
В мире продаж, где есть слово "скидка", процесс тривиален и всем известен?
amarao
Да. Потому что вы только что назвали всем понятную вещь. «Скидка». Ваш язык, которым вы описываете продажу, он же всем понятен. Покупатель, продавец, агент, реселлер, скидка, цена, сумма, etc.
Настоящая же боль происходит в тот момент, когда часть участников не знает части слов или использует их неправильно.
Я сейчас подумал о примере… Предположим, мы делаем face recognition. Есть эксперт по нейронным сетям и линейной алгебре, есть эксперт по криминалистике, есть эксперт по программированию (хехе), DBA, сисадмина даже как devops'а притянули.
… Теперь, представим, что у нас всплывает проблема: классификационная сеть не может правильно начать работать, потому что микросервис, вычисляющий эйгенвекторы для разреженных матриц использует неправильную локаль при записи ответа в json из-за того, что переменные среды окружения на машине для автоматизированной сборки undercloud'ных image'ей запускаются из-под пользователя у которого локаль случайно была настроена в нетривиальное значение по geoip потому что при вендоринге кукбуки шефа забыли припинить версию (а в новой революция и geoip).
… Скажите, какова вероятность, что эта проблема будет правильно сформулирована (как написал выше) любым из участников процесса?
Спец по нейронным сетям: эйгенвекторы неправильные
Сисадмин (который должен догадаться, что запятая вместо точки это зло) угу, да, и?
Сисадмин: кривой пининг вендоринга кукбуки и в одном из регионов у нас по геоip прилетает локальная локаль на андерклаудный imagebuilder.
Спец по нейронным сетям (который должен догадаться, что json на входе кривой): угу, да, и?
Это я ещё не приводил пример, когда никто в команде не знает как назвать эту very very thingy thing with do things with things to make things do things.
aensidhe
Ретроскидка тоже знакомая (и тривиальная) вещь?
Не, такого точно никогда в продажах не бывает.
amarao
Преимя за объём предыдущей закупки? А что с ней сложного?
aensidhe
Ну, я пока не понял, что сложного в вашем кейсе с нейросетями.
В ретроскидке, когда вы в теме, тоже ничего сложного. Ну, кроме того, что ретроскидка может быть не за один период, а за Н, оконная, етс.
oogl
где я сейчас работаю «скидка» может означать:
Кейсы могут комбинироваться. Поэтому вариантов того, что может скрываться под словом скидка n!(4).