Введение
Неотъемлемой частью любой сложной системы является телеметрия (мониторинг). Она включает в себя сборку логов, сборку различных метрик из разных частей системы, межсервисную трассировку вызовов и в самых критических случаях, если это возможно, — ручное взаимодействие. В этой статье мы остановимся только на процедуре сбора метрик. Возможно, кому-то наш подход покажется архаичным и устаревшим, однако для нас он, как говорится, battleprоven и хорошо себя зарекомендовал в наших условиях.

В основе наших метрик лежит хорошо известная система Graphite. Здесь мы не будем останавливаться на базовых вещах его конфигурирования и первичной настройки, для этого существует достаточное количество материалов в интернете, скажем лишь то, что от самого проекта Graphite у нас нет практически ничего :). Все его компоненты заменены на более производительные аналоги. В этом, кстати, большое достоинство Graphite: он построен из кубиков, которые легко друг с другом комбинировать и заменять. Остановимся лишь на проблемах, с которыми мы столкнулись в ходе эксплуатации.
Проблема 1: Агрегация метрик
Так как наши проекты довольно динамичны, а именно рабочие фермы постоянно изменяются в размерах, узлы внутри них ротируются, возникает проблема того, что нужно представлять, как система себя ведет в комплексе. Да, можно с каждого отдельного узла слать метрики и пользоваться агрегирующими функциями самого графита совместно с выбором метрик по wildcard, но это очень неудобно. (Хотя есть и другая точка зрения со стороны ребят, сделавших prometheus, что нужно хранить все метрики, чтобы в случае чего было удобно разбираться. Но, на наш взгляд, в динамических средах, где контейнеры скалируются туда-сюда в больших количествах, этот подход скорее запутывает конечных пользователей, а также является неоправданно вычислительно сложным.) А на больших количествах метрик еще и медленно. Но человеческая мысль не стоит на месте, и ребята из
Etsy взяли и придумали statsd. Как читателям, наверное, хорошо известно, это агрегирующий сервер, который позволяет решить проблему, описанную чуть выше. У него есть период агрегирования, и по этому периоду для определенных типов метрик (timing) он считает несколько агрегирующих функций:- avg — среднее значение за период
- p99 — 99 персентиль за период
- min — минимальное зафиксированное значение за период
- max — максимальное значение зафиксированное за период
- mean — медианное значение за период
- stdev — стандартное отклонение
Их на самом деле больше (ознакомиться с полным их перечнем можно в соответствующем разделе документации), но в большинстве случаев мы используем эти. Уже имея их, можно примерно представлять, как система работает в общем, нет ли в ней сбойных узлов или каких-то аномалий. Тут можно сделать небольшую ремарку и сказать, что, когда трафик по экземплярам приложения разливается более менее равномерно, когда все хорошо и у нас нет аномальной загруженности, стандартное отклонение не колеблется в больших пределах.
Также агрегирующий сервер решает проблему, когда метрики поступают слишком часто. Тут следует немного сказать про устройство файла whisper, в котором в нашем случае и хранятся метрики. Как можно увидеть из дампа ниже:
maxRetention: 31536000
xFilesFactor: 0.10000000149
aggregationMethod: min
fileSize: 2680192
Archive 0
retention: 604800
secondsPerPoint: 10
points: 60480
size: 725760
offset: 64
Archive 1
retention: 1987200
secondsPerPoint: 30
points: 66240
size: 794880
offset: 725824
Archive 2
retention: 13219200
secondsPerPoint: 300
points: 44064
size: 528768
offset: 1520704
Archive 3
retention: 31536000
secondsPerPoint: 600
points: 52560
size: 630720
offset: 2049472
whisper файл состоит из секций, в каждой секции указывается интервал, через который идут разные точки
secondsPerPoint, и сколько по времени точка находится в текущей секции перед тем, как быть «схлопнутой» (это еще называется прореживанием или donwsampling’ом) и переместиться в следующую секцию. Становится понятно, что если метрики поступают чаще, чем secondsPerPoint в первой секции, то побеждать будет тот, чья точка придет последней в интервале secondsPerPoint, что, конечно же, будет приводить к потере данных.Все бы хорошо в оригинальном statsd, однако тот факт, что он реализован на
nodejs, дает о себе знать: он медленный и потребляет много памяти, особенно если это timing метрики. Это связано прежде всего с «наивным» способом подсчета персентилей. Поэтому мы заменили его более производительной версией statsite. Интересной его особенностью является то, что персентили он подсчитывает статистическим алгоритмом. Этот алгоритм считает их с определенной ошибкой, которая, впрочем, настраивается, благодаря чему расчет персетилей происходит очень экономно по памяти. Сам по себе statsite хоть и решает в какой-то степени задачи вертикального масштабирования (об этом можно говорить лишь отчасти, так как этот сервер однопоточный, потоки в нем используются лишь для отправки предагрегированных данных дальше уже в сам графит), все же хотелось бы иметь возможность горизонтального масштабирования. В нашем случае необходимость этого шага назрела вследствии того, что мы стали упираться в максимальное число пакетов, которое может приниматься сетевым интерфейсом в облаке aws для инстансов поколения c4, m4, r4 (справедливости ради можем отметить, что новые поколения с5, m5, r5 обладают порогами намного выше). Также на графиках мониторинга сетевого интерфейса было видно полку по числу пакетов в секунду (это около
50к/s), и, разумеется, как результат — мы получали неадекватные значения для графиков некоторых метрик.В сети мы нашли проект statsd-proxy, который, собственно, и делает то, что нам нужно, а именно объединяет бэкенды в
hashring по алгоритму ketama. Но нам хотелось большего — добавить ему динамики, чтобы можно было легко добавлять и удалять бэкенды statsite без перезагрузок рабочего демона прокси и, разумеется, автодисковери. Что мы благополучно и сделали, а так же добавили поддержку TCP, так как из коробки statsd-proxy не умеет TCP, что для большого потока метрик не сильно заметно, однако дропы UDP пакетов в облаке aws все-таки случаются. Когда метрики идут не очень часто, можно увидеть странные (на первый взгляд необъяснимые) провалы в таких графиках, ситуацию исправляет переход на протокол TCP (в нем есть ретрансмиты, которые досылают потерянные по дороге данные). Это, конечно, не идеальное решение, и протокол TCP мы используем только для небольшого множества метрик.Следует отметить, что существует 3 подхода к тому, на каком этапе начать шардировать метрики, отправляемые в statsd:
- Можно и в самой библиотеке взаимодействия со statsd реализовать все, что нужно, однако этот подход самый трудоемкий, требует от разработки определенных усилий (элементарно, это надо ментейнить). Плюс подход чреват большим количеством ошибок, он не очень переносимый, так как требуется интеграция с механизмами автодисковери, коих на самом деле может быть не один десяток.
- Запускать прокси непосредственно на хосте с экземпляром приложения. В этом случае мы достигаем линейного масштабирования по числу узлов, добавленных в statd бекенд, но нам все равно нужно модифицировать клиента (хотя тут все просто — нужно просто поменять доменное имя, а можно и не менять, немного поиграв с кешем DNS). Помимо прокси нужно будет запускать и мониторящий демон. (Этот демон занимается взаимодействием с нашим механизмом автодисковери на основе
hashicorp consulи через реализованный api в proxy сообщает об этих изменениях самому statsd proxy.) - Шардировать непосредственно уже при приеме. Это существенно упрощает хосты, на которых крутятся приложения, и делает их более универсальными, однако масштабирование здесь получается далеко не линейное. Можно показать, что коэффициент масштабирования будет:
Где k — это количество узлов в stasite ферме, и видно, что при 9 узлах мы получаем лишь 20% на экземпляр вместо 11% от общего потока метрик, если бы масштабирование было линейным (1/k). Нелинейность легко объяснить, так как часть трафика, что мы получили при таком приеме, нужно отправить на соседей. Можно показать что такой способ в 2 раза хуже, чем линейный:
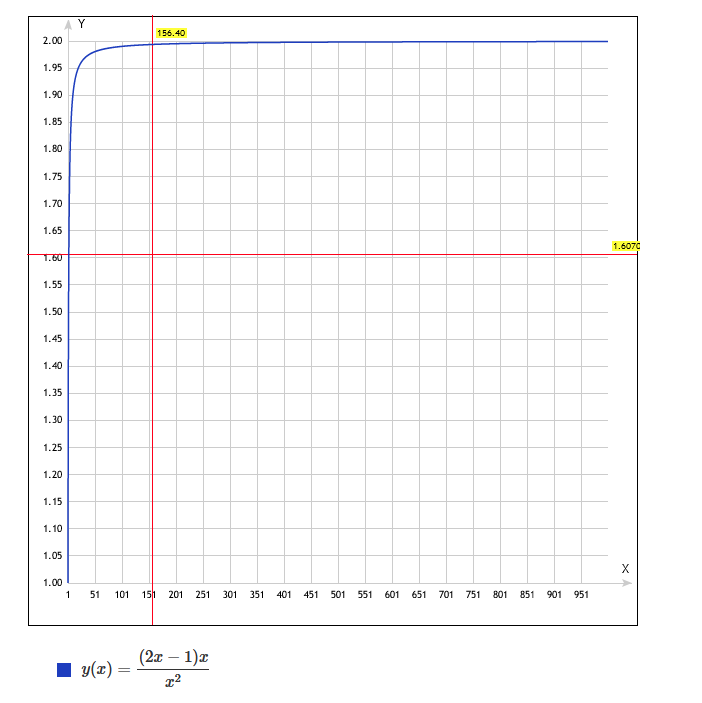
Мы пошли по 3 варианту и пока не уперлись в проблему нелинейности масштабирования, но помним про нее. Если она возникнет, нам не останется ничего лучше, чем идти по второму варианту.
Проблема 2: Доставка метрик
Метрики мы собрали, все замечательно, теперь их нужно как-то доставить в наш сторейдж, а дополнительно, возможно, и добавить в систему алертинга. Казалось бы, все тут просто: бери carbon-c-relay, меняй конфиги, проблем с масштабированием не будет, если не пользоваться агрегацией.
Однако в нашем случае мы пересылаем метрики в другой датацентр, поближе, так сказать, к тем, кто эти метрики смотреть будет. И здесь мы сталкиваемся с проблемой сетевой устойчивости и отказа приемной стороны. Это может произойти по множеству причин: от человеческой ошибки до проблем на магистральных каналах. Например, когда мы пересылали метрики непосредственно в Российские ДЦ, это случалось очень часто.
Решение напрашивается очень простое: это буферизация исходящих метрик где-то, и под где-то мы подразумеваем диск, так как в нашем случае мы можем себе позволить даун приемной стороны до 1 суток. Идею мы изначально подсмотрели в проекте grafsy, большое спасибо его автору. Но первый же даун нашей приемной стороны показал, что проект просто не в состоянии обрабатывать большое количество входящих метрик. Результатом явился наш форк. Как все работает, можно увидеть на следующей схеме:

В исходном проекте мы изменили совсем чуть-чуть: хранилище метрик заменили на перcистентную очередь, сделали более интеллектуальный fallback, плюс добавили несколько метрик, которые характеризуют, как работает внутренняя очередь и насколько у нас все плохо или хорошо с отправкой метрик дальше. Для примера приводим текущую статистику:
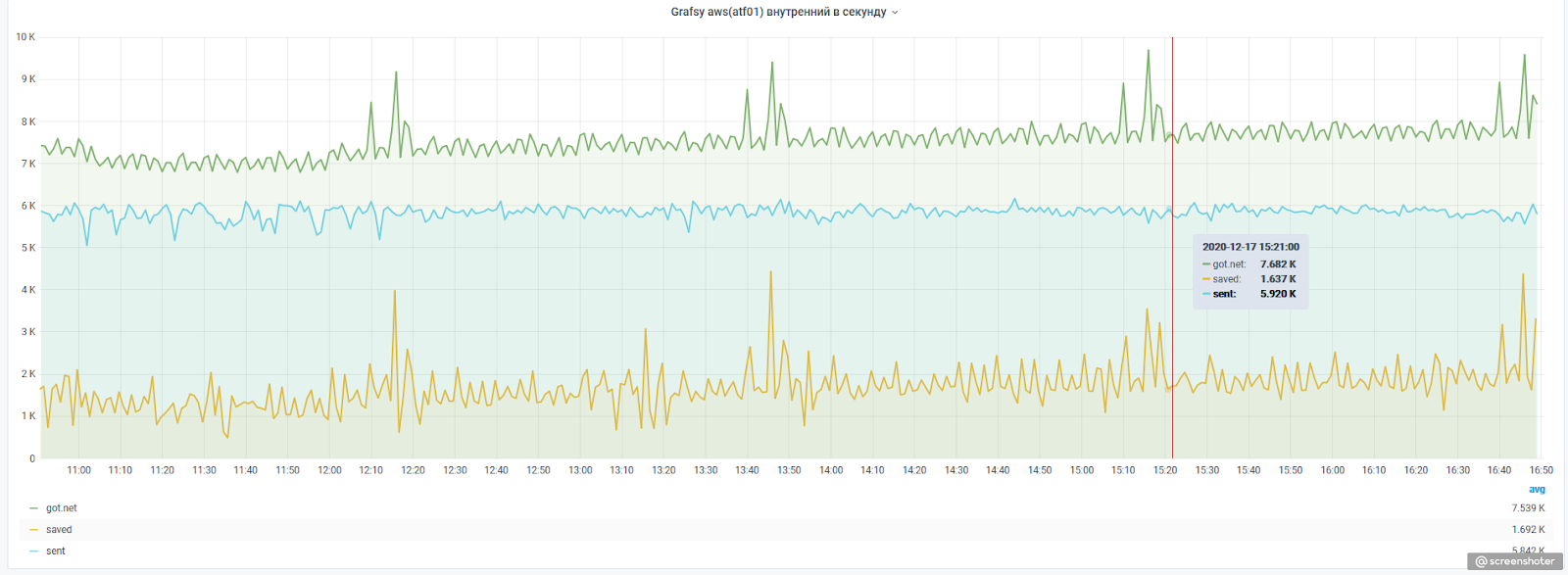
Здесь:
got.net— это количество агрегированных метрик в секунду, полученных на отправкуsaved— это метрики, которые нужно досылать, то есть они не отправились с первого разаsent— это метрики, которые успешно отправились с первого раза
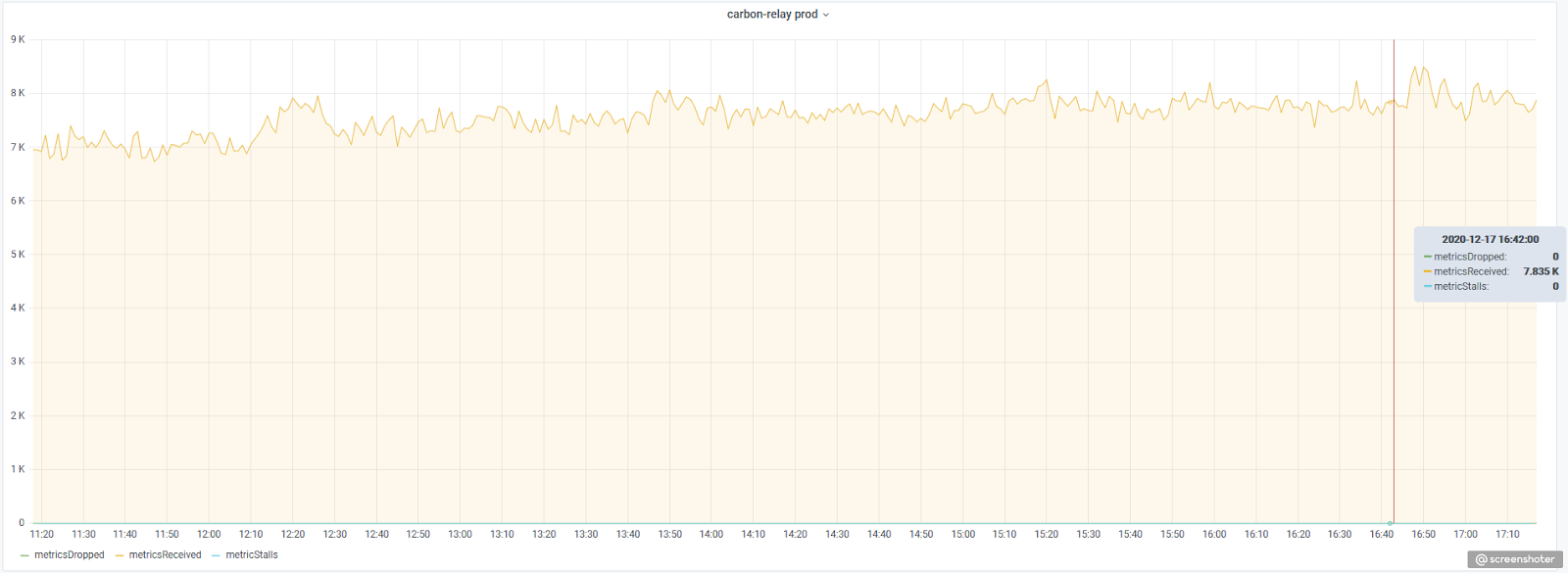
По представленному выше графику видно, что часть метрик приходится постоянно досылать. Можно было бы подумать, что метрики дропаются, например, на входе в caronb-c-relay, однако его статистика говорит нам об обратном:
Проблема 3: Хранение метрик
Все, теперь метрики добрались непосредственно до сторейджа, и их можно туда положить. В силу того, что 1 whisper файл соответствует 1 метрике, это требует довольно много дискового пространства, и, разумеется, их нужно шардировать. Тут нам на помощь приходят или carbonate, или buckytools. Последний позволяет полность автоматизировать ввод в строй нового шарда (ребаланс метрик), без ручного вмешательства, плюс он быстрее. Непосредственно самим шардированием в нашем случае занимается
carbon-c-relay, а самим хранением — go-carbon, так как оригинальный сервер carbon, написанный на python, отличается крайне низким быстродействием и повышенным потреблением ресурсов. Однако и в этом, казалось бы, простом процессе есть свои подводные камни:- Если метрика хоть раз появилась, она никогда не исчезнет и будет лежать мертвым грузом, даже если давным давно не используется. Соответственно, мы удаляем метрики, которые не обновляются в течение месяца, и это время является для нас разумным компромиссом. Хотя у нас и заложена возможность настраивать персистентность в зависимости от имени метрики, увы, эта фича пока еще не потребовалась.
- Метрики могут поступать с различной скоростью, и, например, схема данных, подходящая для точек, которые идут раз в 5 секунд, не подходит для точек, которые идут со скоростью раз в 30 секунд. Описать сразу для каждой метрики необходимые схемы — задача очень трудоемкая, поэтому мы подошли к этому процессу в лоб и в имени метрики кодируем схему, по которой она будет сохранена в whisper файле. Приведем небольшой кусочек нашего конфига для описания схем метрик:
[10s] pattern = .*\.10s.* retentions = 10s:7d,30s:23d,300s:153d,600s:1y [20s] pattern = .*\.20s.* retentions = 20s:7d,60s:23d,300s:153d,600s:1y [30s] pattern = .*\.30s.* retentions = 30s:7d,60s:23d,300s:153d,600s:1y [1m] pattern = .*\.1m.* retentions = 60s:30d,300s:153d,600s:1y [2m] pattern = .*\.2m.* retentions = 120s:30d,600s:1y
Из него, наверное, несложно понять суть: за счет добавления суффикса в имени метрики мы определяем схему хранения. Это, конечно, не идеальный подход, так как названия метрик становятся не очень красивыми, но это нас избавляет от проблем неправильных агрегаций при схлопывании метрик (более подробно этот процесс описан по ссылке). Также это избавляет нас от некорректного отображения графиков, когда идет решардирование кластера graphite. Тут следует сделать небольшое пояснение и немного углубиться в то, как работает графит. Если сами по себе метрики при сохранении по хешу раскидываются по шардам, то, когда они оттуда извлекаются, graphite-web делает запрос на все шарды, получает с них данные, склеивает друг с другом и отдает готовый результат. Этот результат может как рисоваться в виде графиков, так и получаться в виде сырых данных. Однако если для одной и той же метрики, полученной с разных шардов, не будут совпадать схемы хранения, это приведет к тому, что никаких графиков мы не получим. - Так как шардов у нас несколько, и они динамические (то есть они довольно легко могут путешествовать по кластеру), нам нужно как-то централизованно управлять задаваемыми схемами данных и схемами агрегации. Но тут все просто: go-carbon позволяет по сигналу перечитывать эти конфиги, получается, у нас нет пенальти по restart или graceful restart, и нам достаточно лишь положить эти файлики в consul и на шардах следить за их изменениями. Конечно, для этой задачи можно использовать полноценный consultemplate, но нам показалось, что это «из пушки по воробьям», и мы написали более легковесный демон для этой цели, благо это совсем несложно.
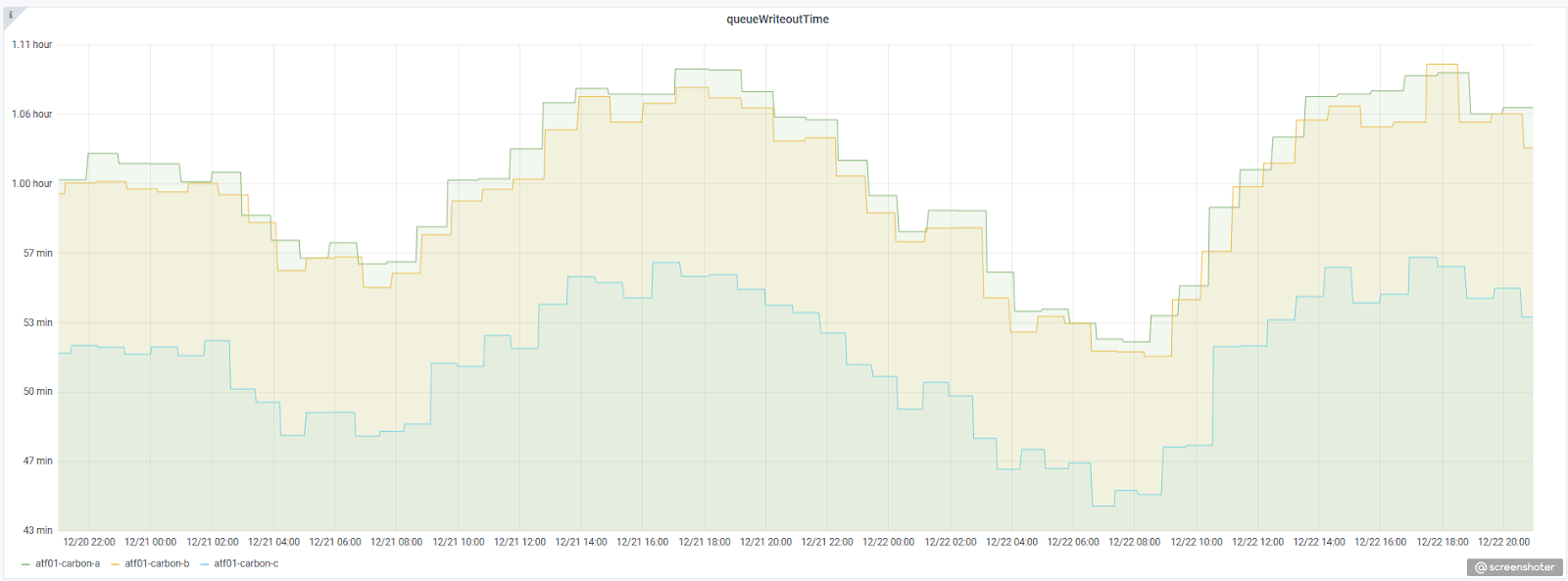
Если подытожить, то в настоящий момент мы имеем масштабируемую систему приема и хранения метрик, которая в большинстве случаев нас устраивает, однако она не лишена недостатков, главным из которых является хранение метрик в whisper файлах. Помимо того, что этот способ весьма прожорлив по дисковому пространству, есть еще и проблема вновь создаваемых метрик: они не сразу появляются в перечне, и это время определяется метрикой queueWriteoutTime, которую ведет go-carbon. В нашем случае это время составляет около часа и колеблется в зависимости от интенсивности поступления метрик:
Также не можем не отметить, что все наши попытки заменить graphite-web на его более производительную версию carbonapi у нас не увенчались успехом. Мы наблюдали пропадание метрик на ровном месте, проблема имела плавающий характер, а отлаживать и искать реальную причину на момент внедрения у нас не нашлось ресурсов, и мы, увы, отложили это в долгий ящик.
И все же, несмотря на некоторые сложности и нерешенные проблемы, на наш скромный взгляд, графит все еще является отличнейшей системой мониторинга (да, в нем нет встроенного алертинга, но это решаемо), которую очень легко скалировать, она неприхотлива, а благодаря ее архитектуре можно легко заменять одни части подсистемы другими без ущерба для общего функционирования.