Дженерики, или параметризованные типы, позволяют писать более гибкие функции и интерфейсы. Чтобы зайти дальше, чем параметризация одним типом, нужно понять лишь несколько общих принципов составления дженериков — и TypeScript раскроется перед вами, как шкатулка с секретом. AlexandrNikolaichev объяснил, как не бояться вкладывать дженерики друг в друга и использовать автоматический вывод типов в ваших проектах.
— Всем привет, меня зовут Александр Николаичев. Я работаю в Yandex.Cloud фронтенд-разработчиком, занимаюсь внутренней инфраструктурой Яндекса. Сегодня расскажу об очень полезной вещи, без которой сложно представить современное приложение, особенно большого масштаба. Это TypeScript, типизация, более узкая тема — дженерики, и то, почему они нужны.
Сначала ответим на вопрос, почему TypeScript и при чем тут инфраструктура. У нас главное свойство инфраструктуры — ее надежность. Как это можно обеспечить? В первую очередь — можно тестировать.

У нас есть юнит- и интеграционные тесты. Тестирование — нужная стандартная практика.
Еще нужно использовать ревью кода. В довесок — сбор ошибок. Если все-таки ошибка случилась, то специальный механизм ее отсылает, и мы можем оперативно что-то пофиксить.
Как было бы хорошо вообще не совершать ошибок. Для этого есть типизация, которая вообще не позволит нам получить ошибку в рантайме. В Яндексе используется промышленный стандарт TypeScript. И так как приложения большие и сложные, то мы получим вот такую формулу: если у нас фронтенд, типизация, да еще и сложные абстракции, то мы обязательно придем к TypeScript-дженерикам. Без них никак.
Чтобы провести базовый ликбез, сначала рассмотрим основы синтаксиса.
Дженерик в TypeScript — это тип, который зависит от другого типа.
У нас есть простой тип, Page. Мы его параметризуем неким параметром <T>, записывается через угловые скобки. И мы видим, что есть какие-то строки, числа, а вот <T> у нас вариативный.
Кроме интерфейсов и типов мы можем тот же синтаксис применять и для функций. То есть тот же параметр <T> пробрасывается в аргумент функции, и в ответе мы переиспользуем тот же самый интерфейс, туда его тоже пробросим.
Наш вызов дженерика также записывается через угловые скобки с нужным типом, как и при его инициализации.
Для классов существует похожий синтаксис. Прокидываем параметр в приватные поля, и у нас есть некий геттер. Но там мы тип не записываем. Почему? Потому что TypeScript умеет выводить тип. Это очень полезная его фишка, и мы ее применим.
Посмотрим, что происходит при использовании этого класса. Мы создаем инстанс, и вместо нашего параметра <T> передаем один из элементов перечисления. Создаем перечисление — русский, английский язык. TypeScript понимает, что мы передали элемент из перечисления, и выводит тип lang.

Но посмотрим, как работает вывод типа. Если мы вместо элементов перечисления передадим константу из этого перечисления, то TypeScript понимает, что это не всё перечисление, не все его элементы. И будет уже конкретное значение типа, то есть lang en, английский язык.
Если мы передаем что-то другое, допустим, строку, то, казалось бы, она имеет то же самое значение, что и у перечисления. Но это уже строка, другой тип в TypeScript, и мы его получим. И если мы передаем строку как константу, то вместо строки и будет константа, строковый литерал, это не все строки. В нашем случае будет конкретная строка en.
Теперь посмотрим, как можно это расширить.

У нас был один параметр. Ничто нам не мешает использовать несколько параметров. Все они записываются через запятую. В тех же угловых скобках, и мы их применяем по порядку — от первого к третьему. Мы подставляем нужные значения при вызове.
Допустим, объединение числовых литералов, некий стандартный тип, объединение строковых литералов. Все они просто записываются по порядку.
Посмотрим, как это происходит в функциях. Мы создаем функцию random. Она рандомно дает либо первый аргумент, либо второй.
Первый аргумент типа A, второй — типа B. Соответственно, возвращается их объединение: либо тот, либо этот. В первую очередь мы можем явно типизировать функцию. Мы указываем, что A — это строка, B — число. TypeScript посмотрит, что мы явно указали, и выведет тип.
Но мы также можем воспользоваться и выводом типа. Главное — знать, что выводится не просто тип, а минимально возможный тип для аргумента.
Предположим, мы передаем аргумент, строковый литерал, и он должен соответствовать типу A, а второй аргумент, единичка, типу B. Минимально возможные для строкового литерала и единички — литерал A и та же самая единичка. Нам TypeScript это и выведет. Получается такое сужение типов.
Прежде чем перейти к следующим примерам, мы посмотрим, как типы вообще соотносятся друг с другом, как использовать эти связи, как получить порядок из хаоса всех типов.
Типы можно условно рассматривать как некие множества. Посмотрим на диаграммку, где показан кусок всего множества типов.

Мы видим, что типы в нем связаны некими отношениями. Но какими? Это отношения частичного порядка — значит, для типа всегда указан его супертип, то есть тип «выше» его, который охватывает все возможные значения.
Если идти в обратную сторону, то у каждого типа может быть подтип, «меньше» его.
Какие супертипы у строки? Любые объединения, которые включают строку. Строка с числом, строка с массивом чисел, с чем угодно. Подтипы — это все строковые литералы: a, b, c, или ac, или ab.
Но важно понимать, что порядок не линейный. То есть не все типы можно сравнить. Это логично, именно это и приводит к ошибкам несоответствия типов. То есть строку нельзя просто сравнить с числом.
И в этом порядке есть тип, как бы самый верхний, — unknown. И самый нижний, аналог пустого множества, — never. Never — подтип любого типа. А unknown — супертип любого типа.
И, конечно, есть исключение — any. Это специальный тип, он вообще игнорирует этот порядок, и используется, если мы мигрируем с JavaScript, чтобы не заботиться о типах. С нуля не рекомендуется использовать any. Это стоит делать, если нам на самом деле не важно положение типа в этом порядке.
Посмотрим, что нам даст знание этого порядка.
Мы можем ограничивать параметры их супертипами. Ключевое слово — extends. Мы определим тип, дженерик, у которого будет всего один параметр. Но мы скажем, что он может быть только подтипом строки либо самой строкой. Числа мы передавать не сможем, это вызовет ошибку типа. Если мы явно типизируем функцию, то в параметрах можем указать только подтипы строки или строку — apple и orange. Обе строки это объединение строковых литералов. Проверка прошла.

Еще мы можем сами автоматически выводить типы, исходя из аргументов. Если мы передали строку литерал, то это тоже строка. Проверка сработала.
Посмотрим, как расширить эти ограничения.
Мы ограничились просто строкой. Но строка — слишком простой тип. Хотелось бы работать с ключами объектов. Чтобы с ними работать, мы сначала поймем, как устроены сами ключи объектов и их типы.
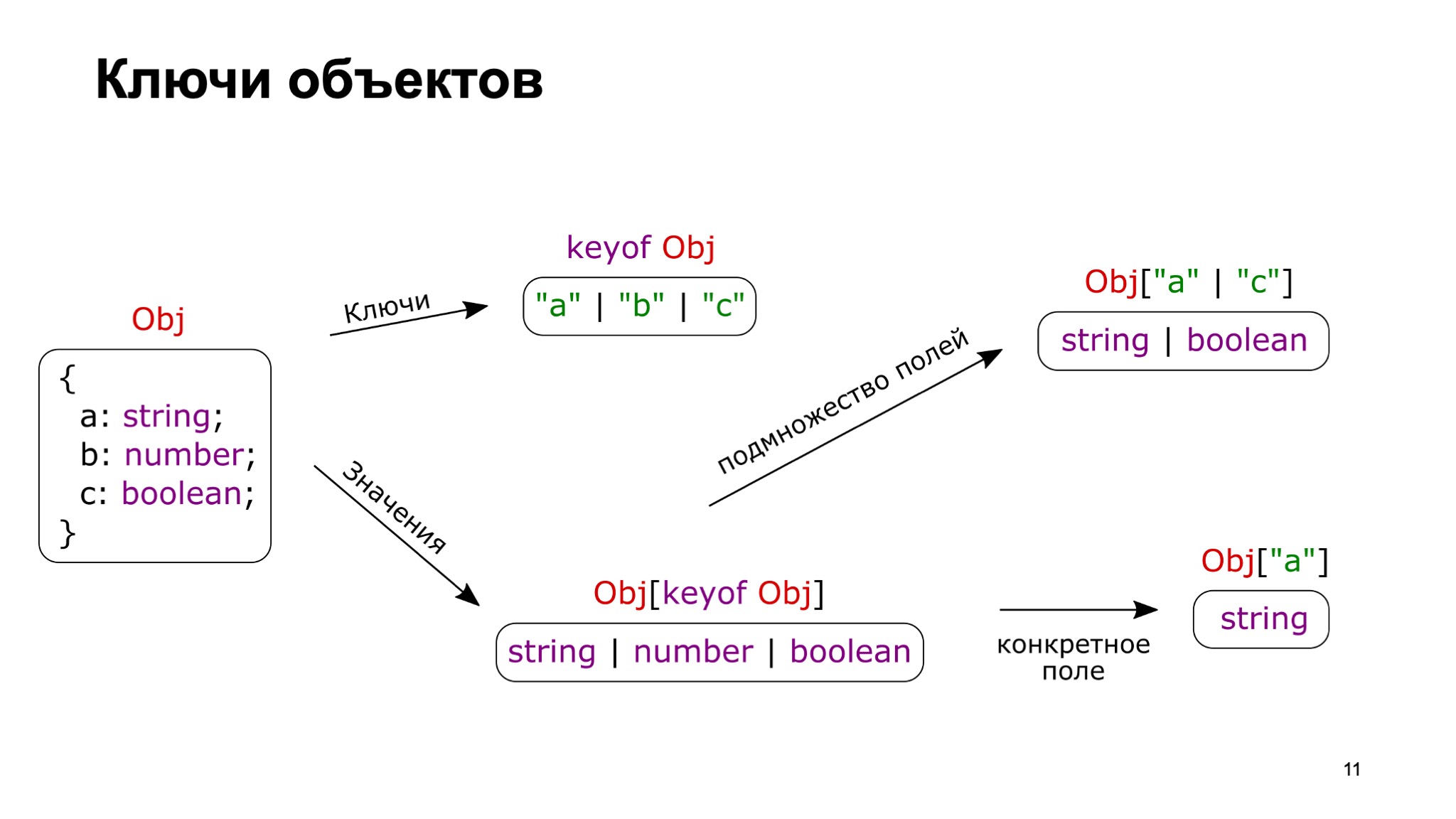
У нас есть некий объектик. У него какие-то поля: строки, числа, булевы значения и ключи по именам. Чтобы получить ключи, используем ключевое слово keyof. Получаем объединение всех имен ключей.
Если мы хотим получить значения, то можем сделать это через синтаксис квадратных скобок. Это похоже на JS-синтаксис. Только он возвращает типы. Если мы передадим все подмножество ключей, то получим объединение вообще всех значений этого объекта.
Если мы хотим получить часть, то мы можем так и указать — не все ключи, а какое-то подмножество. Мы ожидаемо получим лишь те поля, которым соответствуют указанным ключам. Если совсем всё редуцировать до одинарного случая, — это одно поле, и один ключ дает одно значение. Так можно получать соответствующее поле.
Посмотрим, как использовать ключи объекта.

Важно понимать, что после ключевого слова extends может быть любой валидный тип. В том числе и образованный из других дженериков или с применением ключевых слов.
Посмотрим, как это работает с keyof. Мы определили тип CustomPick. На самом деле это почти полная копия библиотечного типа Pick из TypeScript. Что он делает?
У него есть два параметра. Второй — это не просто какой-то параметр. Он должен быть ключами первого. Мы видим, что у нас он расширяет keyof от <T>. Значит, это должно быть какое-то подмножество ключей.
Далее мы для каждого ключа K из этого подмножества бегаем по объекту, кладем то же самое значение и специально убираем синтаксисом опциональность, минус знак вопроса. То есть все поля будут обязательными.
Смотрим на применение. У нас есть объект, в нем имена полей. Мы можем брать только их подмножество — a, b или c, либо все сразу. Мы взяли a или c. Выводятся только соответствующие значения, но мы видим, что поле a стало обязательным, потому что мы, условно говоря, убрали знак вопроса. Мы определили такой тип, использовали его. Никто нам не мешает взять этот дженерик и засунуть его в еще один дженерик.
Как это происходит? Мы определили еще один тип Custom. Второй параметр расширяет не keyof, а результат применения дженерика, который мы привели справа. Как это работает, что мы вообще в него передаем?
Мы в этот дженерик передаем любой объект и все его ключи. Значит, на выходе будет копия объекта со всеми обязательными полями. Эту цепочку вкладывания дженерика в другой дженерик и так далее можно продолжать до бесконечности, в зависимости от задач, и структурировать код. Выносить в дженерики переиспользуемые конструкции и так далее.
Указанные аргументы не обязательно должны идти по порядку. Вроде как параметр P расширяет ключи T в дженерике CustomPick. Но никто нам не мешал указать его первым параметром, а T — вторым. TypeScript не идет последовательно по параметрам. Он смотрит все параметры, что мы указали. Потом решает некую систему уравнений, и если он находит решение типов, которые удовлетворяют этой системе, то проверка типов прошла.
В связи с этим можно вывести такой забавный дженерик, у которого параметры расширяют ключи друг друга: a — это ключи b, b — ключи a. Казалось бы, как такое может быть, ключи ключей? Но мы знаем, что строки TypeScript — это на самом деле строки JavaScript, а у JavaScript-строк есть свои методы. Соответственно, подойдет любое имя метода строки. Потому что имя у метода строки — это тоже строка. И у нее оттуда есть свое имя.
Соответственно, мы можем получить такое ограничение, и система уравнений разрешится, если мы укажем нужные типы.

Посмотрим, как это можно использовать в реальности. Используем для API. Есть сайт, на котором деплоятся приложения Яндекса. Мы хотим вывести проект и сервис, который ему соответствует.
В примере я взял проект для запуска виртуальных машин qyp для разработчиков. Мы знаем, что у нас в бэкенде есть структура этого объекта, берем его из базы. Но помимо проекта есть и другие объекты: черновики, ресурсы. И у всех есть свои структуры.
Более того, мы хотим запрашивать не весь объект, а пару полей — имя и имя сервиса. Такая возможность есть, бэкенд позволяет передавать пути и получить неполную структуру. Здесь описан DeepPartial. Мы его чуть попозже научимся конструировать. Но это значит, что передается не весь объект, а какая-то его часть.
Мы хотим написать некоторую функцию, которая бы запрашивала эти объекты. Напишем на JS. Но если присмотреться, видны опечатки. В типе какой-то «Projeact», в путях тоже опечатка в сервисе. Нехорошо, ошибка будет в рантайме.
Вариант TS, казалось бы, не сильно отличается, кроме путей. Но мы покажем, что на самом деле в поле Type не может быть других значений, кроме тех, что есть у нас на бэкенде.
Поле путей имеет специальный синтаксис, который просто не позволит нам выбрать другие отсутствующие поля. Мы используем такую функцию, где просто перечисляем нужные нам уровни вложенности и получаем объект. На самом деле из этой функции получить пути — забота нашей реализации. Секрета тут нет, она использует прокси. Нам это не столь важно.
Посмотрим, как получить функцию.

У нас есть функция, ее использование. Есть вот эта структура. Сначала мы хотим получить все имена. Мы записываем такой тип, где имя соответствует структуре.
Допустим, для проекта мы где-то описываем его тип. В нашем проекте мы генерируем тайпинги из protobuf-файлов, которые доступны в общем репозитории. Далее мы смотрим, что у нас есть все используемые типы: Project, Draft, Resource.
Посмотрим на реализацию. Разберем по порядку.
Есть функция. Сначала смотрим, чем она параметризуется. Как раз этими уже ранее описанными именами. Посмотрим, что она возвращает. Она возвращает значения. Почему это так? Мы использовали синтаксис квадратных скобок. Но так как мы передаем в тип одну строку, объединение строковых литералов при использовании — это всегда одна строка. Невозможно составить строку, которая одновременно была бы и проектом, и ресурсом. Она всегда одна, и значение тоже одно.
Обернем все в DeepPartial. Необязательный тип, необязательная структура. Самое интересное — это параметры. Задаем их с помощью еще одного дженерика.
Тип, которым параметризуется дженерик параметров, также совпадает с ограничением на функцию. Он может принимать только тип имени — Project, Resource, Draft. ID — это, конечно, строка, она нам не интересна. Вот тип, который мы указали, один из трех. Интересно, как устроена функция для путей. Это еще один дженерик — почему бы нам его не переиспользовать. На самом деле все, что он делает, — просто создает функцию, которая возвращает массив из any, потому что в нашем объекте могут быть поля любых типов, мы не знаем каких. В такой реализации мы получаем контроль над типами.
Если кому-то это показалось простым, перейдем к управляющим конструкциям.
Мы рассмотрим всего две конструкции, но их хватит, чтобы покрывать практически все задачи, которые нам нужны.
Что такое условные типы? Они очень напоминают тернарки в JavaScript, только для типов. У нас есть условие, что тип a — это подтип b. Если это так, то возврати c. Если это не так — возврати d. То есть это обычный if, только для типов.

Смотрим, как это работает. Мы определим тип CustomExclude, который по сути копирует библиотечный Exclude. Он просто выкидывает нужные нам элементы из объединения типов. Если a — это подтип b, то возврати пустоту, иначе возврати a. Это странно, если посмотреть, почему это работает с объединениями.
Нам пригодится специальный закон, который говорит: если есть объединение и мы проверяем с помощью extends условия, то мы проверяем каждый элемент отдельно и потом снова их объединяем. Это такой транзитивный закон, только для условных типов.
Когда мы применяем CustomExclude, то смотрим поочередно на каждый элемент наблюдения. a расширяет a, a — это подтип, но верни пустоту; b это подтип a? Нет — верни b. c — это тоже не подтип a, верни c. Потом мы объединяем то, что осталось, все плюсики, получаем b и c. Мы выкинули a и добились того, что хотели.
Ту же технику можно использовать, чтобы получить все ключи кортежа. Мы знаем, что кортеж — это тот же массив. То есть у него есть JS-методы, но нам это не нужно, а нужны только индексы. Соответственно, мы просто из всех ключей кортежа выкидываем имена всех методов и получаем только индексы.
Как нам определить наш ранее упомянутый тип DeepPartial? Тут впервые используется рекурсия. Мы пробегаемся по всем ключам объекта и смотрим. Значение — это объект? Если да, применяем рекурсивно. Если нет и это строка или число — оставляем и все поля делаем опциональными. Это все-таки Partial-тип.
Этот рекурсивный вызов и условные типы на самом деле делают TypeScript полным по Тьюрингу. Но не спешите этому радоваться. Он надает вам по рукам, если вы попытаетесь провернуть нечто подобное, абстракцию с большой рекурсивностью.
TypeScript за этим следит и выдаст ошибку еще на уровне своего компилятора. Вы даже не дождетесь, пока там что-то посчитается. А для таких простых кейсов, где у нас всего один вызов, рекурсия вполне подходит.

Посмотрим, как это работает. Мы хотим решить задачу патчинга поля объекта. Для планирования выкатки приложений у нас используется виртуальное облако, и нам нужны ресурсы.
Допустим, мы взяли ресурсы CPU, ядра. Всем нужны ядра. Я упростил пример, и тут всего лишь ресурсы, только ядра, и они представляют собой числа.
Мы хотим сделать функцию, которая их патчит, патчит значения. Добавить ядер или убавить. В том же JavaScript, как вы могли догадаться, возникают опечатки. Здесь же мы складываем число со строкой — не очень хорошо.
В TypeScript почти ничего не изменилось, но на самом деле этот контроль еще на уровне IDE вам подскажет, что вы не можете передать ничего кроме этой строки или конкретного числа.
Посмотрим, как этого добиться. Нам надо получить такую функцию, и мы знаем, что у нас есть вот такого вида объект. Нужно понять, что мы патчим только число и поля. То есть надо получить имя только тех полей, где есть числа. У нас всего одно поле, и оно является числом.
Посмотрим, как это реализовывается в TypeScript.

Мы определили функцию. У нее как раз три аргумента, сам объект, который мы патчим, и имя поля. Но это не просто имя поля. Оно может быть только именем числовых полей. Мы сейчас узнаем, как это делается. И сам патчер, который представляет собой чистую функцию.
Есть некая обезличенная функция, патч. Нам интересна не ее реализация, а то, как получить такой интересный тип, получить ключи не только числовых, а любых полей по условию. Здесь у нас содержатся числа.
Вновь разберем по порядку, как это происходит.
Мы пробегаемся по всем ключам переданного объекта, потом делаем вот такую процедуру. Смотрим, что поле объекта — это подтип нужного, то есть числовое поле. Если да, то важно, что мы записываем не значение поля, а имя поля, а иначе вообще, пустоту, never.
Но потом получился такой странный объект. Все числовые поля стали иметь свои имена в качестве значений, а все не числовые поля — пустоту. Дальше мы берем все значения этого странного объекта.
Но так как все значения содержат пустоту, а пустота при объединении схлопывается, то остаются только те поля, которые соответствуют числовым. То есть мы получили только нужные поля.
В примере показано: есть простой объект, поле — единичка. Это число? Да. Поле — число, это число? Да. Последняя строка — не число. Получаем только нужные, числовые поля.
С этим разобрались. Самый сложный я оставил напоследок. Это вывод типа — Infer. Захват типа в условной конструкции.

Он неотделим от предыдущей темы, потому что работает только с условной конструкцией.
Как это выглядит? Допустим, мы хотим знать элементы массива. Пришел некий тип массива, нам бы хотелось узнать конкретный элемент. Мы смотрим: нам пришел какой-то массив. Это подтип массива из переменной x. Если да — верни этот x, элемент массива. Если нет — верни пустоту.
В этом условии вторая ветка никогда не будет выполнена, потому что мы параметризовали тип любым массивом. Конечно, это будет массив чего-то, потому что массив из any не может не иметь элементов.
Если мы передаем массив строк, то нам ожидаемо возвратится строка. И важно понимать, что у нас определяется не просто тип. Из массива строк визуально понятно: там — строки. А вот с кортежем все не так просто. Нам важно знать, что определяется минимально возможный супертип. Понятно, что все массивы как бы являются подтипами массива с any или с unknown. Нам это знание ничего не дает. Нам важно знать минимально возможное.
Предположим, мы передаем кортеж. На самом деле кортежи — это тоже массивы, но как нам сказать, что за элементы у этого массива? Если есть кортеж из строки числа, то на самом деле это массив. Но элемент должен иметь один тип. А если там есть и строка, и число — значит, будет объединение.
TypeScript это и выведет, и мы получим для такого примера именно объединение строки и числа.
Можно использовать не только захват в одном месте, но и сколько угодно переменных. Допустим, мы определим тип, который просто меняет элементы кортежа местами: первый со вторым. Мы захватываем первый элемент, второй и меняем их местами.
Но на самом деле не рекомендуется слишком с этим заигрываться. Обычно для 90% задач хватает захвата всего лишь одного типа.

Посмотрим пример. Задача: нужно показать в зависимости от состояния запроса либо хороший вариант, либо плохой. Тут представлены скриншоты из нашего сервиса для деплоймента приложений. Некая сущность, ReplicaSet. Если запрос с бэкенда вернул ошибку, надо ее отрисовать. При этом есть API для бэкенда. Посмотрим, при чем тут Infer.
Мы знаем, что используем, во-первых, redux, а, во-вторых, redux thunk. И нам надо преобразовать библиотечный thunk, чтобы получить такую возможность. У нас есть плохой путь и хороший.
И мы знаем, что хороший путь в extraReducers в redux toolkit выглядит так. Знаем, что есть PayLoad, и хотим вытащить кастомные типы, которые нам пришли с бэкенда, но не только, а плюс еще информация про хороший или плохой запрос: есть там ошибка или нет. Нам нужен дженерик для этого вывода.
Про JavaScript я не привожу сравнение, потому что оно не имеет смысла. В JavaScript в принципе нельзя никак контролировать типы и полагаться только на память. Здесь нет плохого варианта, потому что его просто нет.
Мы знаем, что хотим получить этот тип. Но у нас же не просто так появляется action. Нам нужно вызвать dispatch с этим action. И нам нужен вот такой вид, где по ключу запроса нужно отображать ошибку. То есть нужно поверх redux thunk примешивать такую дополнительную функциональность с помощью метода withRequestKey.
У нас, конечно, есть этот метод, но у нас есть и исходный метод API — getReplicaSet. Он где-то записан и нам надо оверрайдить redux thunk с помощью некоего адаптера. Посмотрим, как это сделать.
Надо получить функцию вот такого вида. Это thunk с такой дополнительной функциональностью. Звучит страшно, но не пугайтесь, сейчас разберем по полочкам, чтобы было понятно.

Есть адаптер, который расширяет исходный библиотечный тип. Мы к этому библиотечному типу просто примешиваем дополнительный метод withRequestKey и кастомный вызов. Посмотрим, в чем основная фишка дженерика, какие параметры используются.
Первое — это просто наш API, объектик с методами. Мы можем делать getReplicaSet, получать проекты, ресурсы, неважно. Мы в текущем методе используем конкретный метод, а второй параметр — это просто имя метода. Далее мы используем параметры функции, которую запрашиваем, используем библиотечный тип Parameters, это TypeScript-тип. И аналогично для ответа с бэкенда мы используем библиотечный тип ReturnType. Это для того, что вернула функция.
Дальше мы просто прокидываем свой кастомный вывод в AsyncThunk-тип, который нам предоставила библиотека. Но что это за вывод? Это еще один дженерик. На самом деле он выглядит просто. Мы сохраняем не только ответ с сервера, но и наши параметры, то, что мы передали. Просто чтобы в Reducer за ними следить. Дальше мы смотрим withRequestKey. Наш метод просто добавляет ключ. Что он возвращает? Тот же адаптер, потому что мы можем его переиспользовать. Мы вообще не обязаны писать withRequestKey. Это просто дополнительная функциональность. Она оборачивает и рекурсивно нам возвращает тот же самый адаптер, и мы прокидываем туда то же самое.
Наконец, посмотрим, как выводить в Reducer то, что нам этот thunk вернул.

У нас есть этот адаптер. Главное — помнить, что там четыре параметра: API, метод API, параметры (вход) и выход. Нам надо получить выход. Но мы помним, что выход у нас кастомный: и ответ сервера, и параметр запроса.
Как это сделать с помощью Infer? Мы смотрим, что на вход подается этот адаптер, но он вообще любой: any, any, any, any. Мы должны вернуть этот тип, выглядит он вот так, ответ сервера и параметры запроса. И мы смотрим, на каком месте должен быть вход. На третьем. На это место мы и помещаем наш захват типа. Получаем вход. Аналогично, на четвертом месте стоит выход.
TypeScript основывается на структурной типизации. Он эту структуру разбирает и понимает, что вход находится здесь, на третьем месте, а выход на четвертом. И мы возвращаем нужные типы.
Так мы добились вывода типов, у нас есть доступ к ним уже в самом Reducer. В JavaScript сделать такое в принципе невозможно.
— Всем привет, меня зовут Александр Николаичев. Я работаю в Yandex.Cloud фронтенд-разработчиком, занимаюсь внутренней инфраструктурой Яндекса. Сегодня расскажу об очень полезной вещи, без которой сложно представить современное приложение, особенно большого масштаба. Это TypeScript, типизация, более узкая тема — дженерики, и то, почему они нужны.
Сначала ответим на вопрос, почему TypeScript и при чем тут инфраструктура. У нас главное свойство инфраструктуры — ее надежность. Как это можно обеспечить? В первую очередь — можно тестировать.
У нас есть юнит- и интеграционные тесты. Тестирование — нужная стандартная практика.
Еще нужно использовать ревью кода. В довесок — сбор ошибок. Если все-таки ошибка случилась, то специальный механизм ее отсылает, и мы можем оперативно что-то пофиксить.
Как было бы хорошо вообще не совершать ошибок. Для этого есть типизация, которая вообще не позволит нам получить ошибку в рантайме. В Яндексе используется промышленный стандарт TypeScript. И так как приложения большие и сложные, то мы получим вот такую формулу: если у нас фронтенд, типизация, да еще и сложные абстракции, то мы обязательно придем к TypeScript-дженерикам. Без них никак.
Синтаксис
Чтобы провести базовый ликбез, сначала рассмотрим основы синтаксиса.
Дженерик в TypeScript — это тип, который зависит от другого типа.
У нас есть простой тип, Page. Мы его параметризуем неким параметром <T>, записывается через угловые скобки. И мы видим, что есть какие-то строки, числа, а вот <T> у нас вариативный.
Кроме интерфейсов и типов мы можем тот же синтаксис применять и для функций. То есть тот же параметр <T> пробрасывается в аргумент функции, и в ответе мы переиспользуем тот же самый интерфейс, туда его тоже пробросим.
Наш вызов дженерика также записывается через угловые скобки с нужным типом, как и при его инициализации.
Для классов существует похожий синтаксис. Прокидываем параметр в приватные поля, и у нас есть некий геттер. Но там мы тип не записываем. Почему? Потому что TypeScript умеет выводить тип. Это очень полезная его фишка, и мы ее применим.
Посмотрим, что происходит при использовании этого класса. Мы создаем инстанс, и вместо нашего параметра <T> передаем один из элементов перечисления. Создаем перечисление — русский, английский язык. TypeScript понимает, что мы передали элемент из перечисления, и выводит тип lang.
Но посмотрим, как работает вывод типа. Если мы вместо элементов перечисления передадим константу из этого перечисления, то TypeScript понимает, что это не всё перечисление, не все его элементы. И будет уже конкретное значение типа, то есть lang en, английский язык.
Если мы передаем что-то другое, допустим, строку, то, казалось бы, она имеет то же самое значение, что и у перечисления. Но это уже строка, другой тип в TypeScript, и мы его получим. И если мы передаем строку как константу, то вместо строки и будет константа, строковый литерал, это не все строки. В нашем случае будет конкретная строка en.
Теперь посмотрим, как можно это расширить.
У нас был один параметр. Ничто нам не мешает использовать несколько параметров. Все они записываются через запятую. В тех же угловых скобках, и мы их применяем по порядку — от первого к третьему. Мы подставляем нужные значения при вызове.
Допустим, объединение числовых литералов, некий стандартный тип, объединение строковых литералов. Все они просто записываются по порядку.
Посмотрим, как это происходит в функциях. Мы создаем функцию random. Она рандомно дает либо первый аргумент, либо второй.
Первый аргумент типа A, второй — типа B. Соответственно, возвращается их объединение: либо тот, либо этот. В первую очередь мы можем явно типизировать функцию. Мы указываем, что A — это строка, B — число. TypeScript посмотрит, что мы явно указали, и выведет тип.
Но мы также можем воспользоваться и выводом типа. Главное — знать, что выводится не просто тип, а минимально возможный тип для аргумента.
Предположим, мы передаем аргумент, строковый литерал, и он должен соответствовать типу A, а второй аргумент, единичка, типу B. Минимально возможные для строкового литерала и единички — литерал A и та же самая единичка. Нам TypeScript это и выведет. Получается такое сужение типов.
Прежде чем перейти к следующим примерам, мы посмотрим, как типы вообще соотносятся друг с другом, как использовать эти связи, как получить порядок из хаоса всех типов.
Отношение типов
Типы можно условно рассматривать как некие множества. Посмотрим на диаграммку, где показан кусок всего множества типов.
Мы видим, что типы в нем связаны некими отношениями. Но какими? Это отношения частичного порядка — значит, для типа всегда указан его супертип, то есть тип «выше» его, который охватывает все возможные значения.
Если идти в обратную сторону, то у каждого типа может быть подтип, «меньше» его.
Какие супертипы у строки? Любые объединения, которые включают строку. Строка с числом, строка с массивом чисел, с чем угодно. Подтипы — это все строковые литералы: a, b, c, или ac, или ab.
Но важно понимать, что порядок не линейный. То есть не все типы можно сравнить. Это логично, именно это и приводит к ошибкам несоответствия типов. То есть строку нельзя просто сравнить с числом.
И в этом порядке есть тип, как бы самый верхний, — unknown. И самый нижний, аналог пустого множества, — never. Never — подтип любого типа. А unknown — супертип любого типа.
И, конечно, есть исключение — any. Это специальный тип, он вообще игнорирует этот порядок, и используется, если мы мигрируем с JavaScript, чтобы не заботиться о типах. С нуля не рекомендуется использовать any. Это стоит делать, если нам на самом деле не важно положение типа в этом порядке.
Посмотрим, что нам даст знание этого порядка.
Мы можем ограничивать параметры их супертипами. Ключевое слово — extends. Мы определим тип, дженерик, у которого будет всего один параметр. Но мы скажем, что он может быть только подтипом строки либо самой строкой. Числа мы передавать не сможем, это вызовет ошибку типа. Если мы явно типизируем функцию, то в параметрах можем указать только подтипы строки или строку — apple и orange. Обе строки это объединение строковых литералов. Проверка прошла.
Еще мы можем сами автоматически выводить типы, исходя из аргументов. Если мы передали строку литерал, то это тоже строка. Проверка сработала.
Посмотрим, как расширить эти ограничения.
Мы ограничились просто строкой. Но строка — слишком простой тип. Хотелось бы работать с ключами объектов. Чтобы с ними работать, мы сначала поймем, как устроены сами ключи объектов и их типы.
У нас есть некий объектик. У него какие-то поля: строки, числа, булевы значения и ключи по именам. Чтобы получить ключи, используем ключевое слово keyof. Получаем объединение всех имен ключей.
Если мы хотим получить значения, то можем сделать это через синтаксис квадратных скобок. Это похоже на JS-синтаксис. Только он возвращает типы. Если мы передадим все подмножество ключей, то получим объединение вообще всех значений этого объекта.
Если мы хотим получить часть, то мы можем так и указать — не все ключи, а какое-то подмножество. Мы ожидаемо получим лишь те поля, которым соответствуют указанным ключам. Если совсем всё редуцировать до одинарного случая, — это одно поле, и один ключ дает одно значение. Так можно получать соответствующее поле.
Посмотрим, как использовать ключи объекта.
Важно понимать, что после ключевого слова extends может быть любой валидный тип. В том числе и образованный из других дженериков или с применением ключевых слов.
Посмотрим, как это работает с keyof. Мы определили тип CustomPick. На самом деле это почти полная копия библиотечного типа Pick из TypeScript. Что он делает?
У него есть два параметра. Второй — это не просто какой-то параметр. Он должен быть ключами первого. Мы видим, что у нас он расширяет keyof от <T>. Значит, это должно быть какое-то подмножество ключей.
Далее мы для каждого ключа K из этого подмножества бегаем по объекту, кладем то же самое значение и специально убираем синтаксисом опциональность, минус знак вопроса. То есть все поля будут обязательными.
Смотрим на применение. У нас есть объект, в нем имена полей. Мы можем брать только их подмножество — a, b или c, либо все сразу. Мы взяли a или c. Выводятся только соответствующие значения, но мы видим, что поле a стало обязательным, потому что мы, условно говоря, убрали знак вопроса. Мы определили такой тип, использовали его. Никто нам не мешает взять этот дженерик и засунуть его в еще один дженерик.
Как это происходит? Мы определили еще один тип Custom. Второй параметр расширяет не keyof, а результат применения дженерика, который мы привели справа. Как это работает, что мы вообще в него передаем?
Мы в этот дженерик передаем любой объект и все его ключи. Значит, на выходе будет копия объекта со всеми обязательными полями. Эту цепочку вкладывания дженерика в другой дженерик и так далее можно продолжать до бесконечности, в зависимости от задач, и структурировать код. Выносить в дженерики переиспользуемые конструкции и так далее.
Указанные аргументы не обязательно должны идти по порядку. Вроде как параметр P расширяет ключи T в дженерике CustomPick. Но никто нам не мешал указать его первым параметром, а T — вторым. TypeScript не идет последовательно по параметрам. Он смотрит все параметры, что мы указали. Потом решает некую систему уравнений, и если он находит решение типов, которые удовлетворяют этой системе, то проверка типов прошла.
В связи с этим можно вывести такой забавный дженерик, у которого параметры расширяют ключи друг друга: a — это ключи b, b — ключи a. Казалось бы, как такое может быть, ключи ключей? Но мы знаем, что строки TypeScript — это на самом деле строки JavaScript, а у JavaScript-строк есть свои методы. Соответственно, подойдет любое имя метода строки. Потому что имя у метода строки — это тоже строка. И у нее оттуда есть свое имя.
Соответственно, мы можем получить такое ограничение, и система уравнений разрешится, если мы укажем нужные типы.
Посмотрим, как это можно использовать в реальности. Используем для API. Есть сайт, на котором деплоятся приложения Яндекса. Мы хотим вывести проект и сервис, который ему соответствует.
В примере я взял проект для запуска виртуальных машин qyp для разработчиков. Мы знаем, что у нас в бэкенде есть структура этого объекта, берем его из базы. Но помимо проекта есть и другие объекты: черновики, ресурсы. И у всех есть свои структуры.
Более того, мы хотим запрашивать не весь объект, а пару полей — имя и имя сервиса. Такая возможность есть, бэкенд позволяет передавать пути и получить неполную структуру. Здесь описан DeepPartial. Мы его чуть попозже научимся конструировать. Но это значит, что передается не весь объект, а какая-то его часть.
Мы хотим написать некоторую функцию, которая бы запрашивала эти объекты. Напишем на JS. Но если присмотреться, видны опечатки. В типе какой-то «Projeact», в путях тоже опечатка в сервисе. Нехорошо, ошибка будет в рантайме.
Вариант TS, казалось бы, не сильно отличается, кроме путей. Но мы покажем, что на самом деле в поле Type не может быть других значений, кроме тех, что есть у нас на бэкенде.
Поле путей имеет специальный синтаксис, который просто не позволит нам выбрать другие отсутствующие поля. Мы используем такую функцию, где просто перечисляем нужные нам уровни вложенности и получаем объект. На самом деле из этой функции получить пути — забота нашей реализации. Секрета тут нет, она использует прокси. Нам это не столь важно.
Посмотрим, как получить функцию.
У нас есть функция, ее использование. Есть вот эта структура. Сначала мы хотим получить все имена. Мы записываем такой тип, где имя соответствует структуре.
Допустим, для проекта мы где-то описываем его тип. В нашем проекте мы генерируем тайпинги из protobuf-файлов, которые доступны в общем репозитории. Далее мы смотрим, что у нас есть все используемые типы: Project, Draft, Resource.
Посмотрим на реализацию. Разберем по порядку.
Есть функция. Сначала смотрим, чем она параметризуется. Как раз этими уже ранее описанными именами. Посмотрим, что она возвращает. Она возвращает значения. Почему это так? Мы использовали синтаксис квадратных скобок. Но так как мы передаем в тип одну строку, объединение строковых литералов при использовании — это всегда одна строка. Невозможно составить строку, которая одновременно была бы и проектом, и ресурсом. Она всегда одна, и значение тоже одно.
Обернем все в DeepPartial. Необязательный тип, необязательная структура. Самое интересное — это параметры. Задаем их с помощью еще одного дженерика.
Тип, которым параметризуется дженерик параметров, также совпадает с ограничением на функцию. Он может принимать только тип имени — Project, Resource, Draft. ID — это, конечно, строка, она нам не интересна. Вот тип, который мы указали, один из трех. Интересно, как устроена функция для путей. Это еще один дженерик — почему бы нам его не переиспользовать. На самом деле все, что он делает, — просто создает функцию, которая возвращает массив из any, потому что в нашем объекте могут быть поля любых типов, мы не знаем каких. В такой реализации мы получаем контроль над типами.
Если кому-то это показалось простым, перейдем к управляющим конструкциям.
Управляющие конструкции
Мы рассмотрим всего две конструкции, но их хватит, чтобы покрывать практически все задачи, которые нам нужны.
Что такое условные типы? Они очень напоминают тернарки в JavaScript, только для типов. У нас есть условие, что тип a — это подтип b. Если это так, то возврати c. Если это не так — возврати d. То есть это обычный if, только для типов.
Смотрим, как это работает. Мы определим тип CustomExclude, который по сути копирует библиотечный Exclude. Он просто выкидывает нужные нам элементы из объединения типов. Если a — это подтип b, то возврати пустоту, иначе возврати a. Это странно, если посмотреть, почему это работает с объединениями.
Нам пригодится специальный закон, который говорит: если есть объединение и мы проверяем с помощью extends условия, то мы проверяем каждый элемент отдельно и потом снова их объединяем. Это такой транзитивный закон, только для условных типов.
Когда мы применяем CustomExclude, то смотрим поочередно на каждый элемент наблюдения. a расширяет a, a — это подтип, но верни пустоту; b это подтип a? Нет — верни b. c — это тоже не подтип a, верни c. Потом мы объединяем то, что осталось, все плюсики, получаем b и c. Мы выкинули a и добились того, что хотели.
Ту же технику можно использовать, чтобы получить все ключи кортежа. Мы знаем, что кортеж — это тот же массив. То есть у него есть JS-методы, но нам это не нужно, а нужны только индексы. Соответственно, мы просто из всех ключей кортежа выкидываем имена всех методов и получаем только индексы.
Как нам определить наш ранее упомянутый тип DeepPartial? Тут впервые используется рекурсия. Мы пробегаемся по всем ключам объекта и смотрим. Значение — это объект? Если да, применяем рекурсивно. Если нет и это строка или число — оставляем и все поля делаем опциональными. Это все-таки Partial-тип.
Этот рекурсивный вызов и условные типы на самом деле делают TypeScript полным по Тьюрингу. Но не спешите этому радоваться. Он надает вам по рукам, если вы попытаетесь провернуть нечто подобное, абстракцию с большой рекурсивностью.
TypeScript за этим следит и выдаст ошибку еще на уровне своего компилятора. Вы даже не дождетесь, пока там что-то посчитается. А для таких простых кейсов, где у нас всего один вызов, рекурсия вполне подходит.
Посмотрим, как это работает. Мы хотим решить задачу патчинга поля объекта. Для планирования выкатки приложений у нас используется виртуальное облако, и нам нужны ресурсы.
Допустим, мы взяли ресурсы CPU, ядра. Всем нужны ядра. Я упростил пример, и тут всего лишь ресурсы, только ядра, и они представляют собой числа.
Мы хотим сделать функцию, которая их патчит, патчит значения. Добавить ядер или убавить. В том же JavaScript, как вы могли догадаться, возникают опечатки. Здесь же мы складываем число со строкой — не очень хорошо.
В TypeScript почти ничего не изменилось, но на самом деле этот контроль еще на уровне IDE вам подскажет, что вы не можете передать ничего кроме этой строки или конкретного числа.
Посмотрим, как этого добиться. Нам надо получить такую функцию, и мы знаем, что у нас есть вот такого вида объект. Нужно понять, что мы патчим только число и поля. То есть надо получить имя только тех полей, где есть числа. У нас всего одно поле, и оно является числом.
Посмотрим, как это реализовывается в TypeScript.
Мы определили функцию. У нее как раз три аргумента, сам объект, который мы патчим, и имя поля. Но это не просто имя поля. Оно может быть только именем числовых полей. Мы сейчас узнаем, как это делается. И сам патчер, который представляет собой чистую функцию.
Есть некая обезличенная функция, патч. Нам интересна не ее реализация, а то, как получить такой интересный тип, получить ключи не только числовых, а любых полей по условию. Здесь у нас содержатся числа.
Вновь разберем по порядку, как это происходит.
Мы пробегаемся по всем ключам переданного объекта, потом делаем вот такую процедуру. Смотрим, что поле объекта — это подтип нужного, то есть числовое поле. Если да, то важно, что мы записываем не значение поля, а имя поля, а иначе вообще, пустоту, never.
Но потом получился такой странный объект. Все числовые поля стали иметь свои имена в качестве значений, а все не числовые поля — пустоту. Дальше мы берем все значения этого странного объекта.
Но так как все значения содержат пустоту, а пустота при объединении схлопывается, то остаются только те поля, которые соответствуют числовым. То есть мы получили только нужные поля.
В примере показано: есть простой объект, поле — единичка. Это число? Да. Поле — число, это число? Да. Последняя строка — не число. Получаем только нужные, числовые поля.
С этим разобрались. Самый сложный я оставил напоследок. Это вывод типа — Infer. Захват типа в условной конструкции.
Он неотделим от предыдущей темы, потому что работает только с условной конструкцией.
Как это выглядит? Допустим, мы хотим знать элементы массива. Пришел некий тип массива, нам бы хотелось узнать конкретный элемент. Мы смотрим: нам пришел какой-то массив. Это подтип массива из переменной x. Если да — верни этот x, элемент массива. Если нет — верни пустоту.
В этом условии вторая ветка никогда не будет выполнена, потому что мы параметризовали тип любым массивом. Конечно, это будет массив чего-то, потому что массив из any не может не иметь элементов.
Если мы передаем массив строк, то нам ожидаемо возвратится строка. И важно понимать, что у нас определяется не просто тип. Из массива строк визуально понятно: там — строки. А вот с кортежем все не так просто. Нам важно знать, что определяется минимально возможный супертип. Понятно, что все массивы как бы являются подтипами массива с any или с unknown. Нам это знание ничего не дает. Нам важно знать минимально возможное.
Предположим, мы передаем кортеж. На самом деле кортежи — это тоже массивы, но как нам сказать, что за элементы у этого массива? Если есть кортеж из строки числа, то на самом деле это массив. Но элемент должен иметь один тип. А если там есть и строка, и число — значит, будет объединение.
TypeScript это и выведет, и мы получим для такого примера именно объединение строки и числа.
Можно использовать не только захват в одном месте, но и сколько угодно переменных. Допустим, мы определим тип, который просто меняет элементы кортежа местами: первый со вторым. Мы захватываем первый элемент, второй и меняем их местами.
Но на самом деле не рекомендуется слишком с этим заигрываться. Обычно для 90% задач хватает захвата всего лишь одного типа.
Посмотрим пример. Задача: нужно показать в зависимости от состояния запроса либо хороший вариант, либо плохой. Тут представлены скриншоты из нашего сервиса для деплоймента приложений. Некая сущность, ReplicaSet. Если запрос с бэкенда вернул ошибку, надо ее отрисовать. При этом есть API для бэкенда. Посмотрим, при чем тут Infer.
Мы знаем, что используем, во-первых, redux, а, во-вторых, redux thunk. И нам надо преобразовать библиотечный thunk, чтобы получить такую возможность. У нас есть плохой путь и хороший.
И мы знаем, что хороший путь в extraReducers в redux toolkit выглядит так. Знаем, что есть PayLoad, и хотим вытащить кастомные типы, которые нам пришли с бэкенда, но не только, а плюс еще информация про хороший или плохой запрос: есть там ошибка или нет. Нам нужен дженерик для этого вывода.
Про JavaScript я не привожу сравнение, потому что оно не имеет смысла. В JavaScript в принципе нельзя никак контролировать типы и полагаться только на память. Здесь нет плохого варианта, потому что его просто нет.
Мы знаем, что хотим получить этот тип. Но у нас же не просто так появляется action. Нам нужно вызвать dispatch с этим action. И нам нужен вот такой вид, где по ключу запроса нужно отображать ошибку. То есть нужно поверх redux thunk примешивать такую дополнительную функциональность с помощью метода withRequestKey.
У нас, конечно, есть этот метод, но у нас есть и исходный метод API — getReplicaSet. Он где-то записан и нам надо оверрайдить redux thunk с помощью некоего адаптера. Посмотрим, как это сделать.
Надо получить функцию вот такого вида. Это thunk с такой дополнительной функциональностью. Звучит страшно, но не пугайтесь, сейчас разберем по полочкам, чтобы было понятно.
Есть адаптер, который расширяет исходный библиотечный тип. Мы к этому библиотечному типу просто примешиваем дополнительный метод withRequestKey и кастомный вызов. Посмотрим, в чем основная фишка дженерика, какие параметры используются.
Первое — это просто наш API, объектик с методами. Мы можем делать getReplicaSet, получать проекты, ресурсы, неважно. Мы в текущем методе используем конкретный метод, а второй параметр — это просто имя метода. Далее мы используем параметры функции, которую запрашиваем, используем библиотечный тип Parameters, это TypeScript-тип. И аналогично для ответа с бэкенда мы используем библиотечный тип ReturnType. Это для того, что вернула функция.
Дальше мы просто прокидываем свой кастомный вывод в AsyncThunk-тип, который нам предоставила библиотека. Но что это за вывод? Это еще один дженерик. На самом деле он выглядит просто. Мы сохраняем не только ответ с сервера, но и наши параметры, то, что мы передали. Просто чтобы в Reducer за ними следить. Дальше мы смотрим withRequestKey. Наш метод просто добавляет ключ. Что он возвращает? Тот же адаптер, потому что мы можем его переиспользовать. Мы вообще не обязаны писать withRequestKey. Это просто дополнительная функциональность. Она оборачивает и рекурсивно нам возвращает тот же самый адаптер, и мы прокидываем туда то же самое.
Наконец, посмотрим, как выводить в Reducer то, что нам этот thunk вернул.
У нас есть этот адаптер. Главное — помнить, что там четыре параметра: API, метод API, параметры (вход) и выход. Нам надо получить выход. Но мы помним, что выход у нас кастомный: и ответ сервера, и параметр запроса.
Как это сделать с помощью Infer? Мы смотрим, что на вход подается этот адаптер, но он вообще любой: any, any, any, any. Мы должны вернуть этот тип, выглядит он вот так, ответ сервера и параметры запроса. И мы смотрим, на каком месте должен быть вход. На третьем. На это место мы и помещаем наш захват типа. Получаем вход. Аналогично, на четвертом месте стоит выход.
TypeScript основывается на структурной типизации. Он эту структуру разбирает и понимает, что вход находится здесь, на третьем месте, а выход на четвертом. И мы возвращаем нужные типы.
Так мы добились вывода типов, у нас есть доступ к ним уже в самом Reducer. В JavaScript сделать такое в принципе невозможно.
poisons
Господи, логопедов уже вывели всех и оптимизировали? Ну тебе то самому не противно так картавить?
П.С. у нас уже дикторы картавые есть. Куда мы все катимся? Я картавил, шепелявил, всего год потребовался штатному логопеду это исправить. Позорище. Яндекс, ты за разнообразие и прочую шелуху?