
Это четвертая статья с этой картинкой для привлечения внимания. Она каким-то удивительным образом опять подошла по смыслу.
Мы делаем проект по управлению большими каталогами товаров, и нам потребовалось быстро искать товары по неточному совпадению.
Забегая вперед, скажу, что от идеи до рабочего решения на продакшене прошло пять часов.
Исходная ситуация такова: таблица в MS SQL базе, 50 миллионов записей, записи добавляются постоянно, удаляются или обновляются крайне редко. Средняя длина названия товара составляет 64 символа. Поиск по неточному совпадению работает, для этого используются триграммы и полнотекстовый индекс по столбцу с триграммами. Ранжирование результатов осуществляется при помощи функции CONTAINSTABLE. Результаты получаются релевантные, но поиск работает откровенно медленно, 2-5 секунд на запрос, в зависимости от длины запроса. Мы хотим ускорить его раз в 20, а лучше в 100 подручными средствами.
Оценим, что мы можем сделать
В дальнейшем я буду рассматривать решение конкретной прикладной задачи и связанные с этим ограничения, в частности, по времени, которое допустимо потратить на реализацию, поэтому буду делать некоторые допущения, связанные с предметной областью. В принципе, довольно просто перейти от условно “товаров” к более абстрактным “записям”, и решить задачу в общем виде.
Давайте прикинем, можем ли мы держать наши данные в памяти. Думаю, мы можем позволить себе сервер с 64 ГБ оперативной памяти для этой задачи. Будем считать с запасом на будущее, 100 миллионов товаров.
Чтобы просто хранить 6.4 миллиарда символов в памяти в двухбайтной кодировке, потребуется 13 гигабайт. Пока непонятно, как по ним искать, но в целом — повод для оптимизма. Если не сильно разбрасываться байтами, то можно и в каком-то более приспособленном для поиска виде всё уместить.
Если посчитать все буквы английского алфавита, цифры и все буквы русского алфавита, то получится 26 + 10 + 33 = 69 символов. Ещё один важный символ — “+”, бывает, что разные товары отличаются только плюсом в названии. Итого 70.
Чтобы на каждое сочетание из трех символов (триграмму) завести список товаров, где это сочетание встречается, потребуется 343000 списков. Вполне разумное число.
Каждый товар, если пренебречь вхождением одной и той же триграммы в название товара несколько раз, будет встречаться, в среднем, в 62 списках. Естественно, мы можем хранить только идентификатор товара, для наших целей достаточно 32-битного Id. Тогда нам потребуется хранить 6.2 миллиарда идентификаторов, это займет 25 гигабайт.
Для хранения списков выберем ArrayList, а не связный список. Даже с учетом того, что, в среднем, вместимость списка будет больше, чем фактическое количество элементов в нем, он все равно выигрывает по накладным расходам памяти. Давайте для грубой оценки предположим, что вместимость списка будет в полтора раза больше, чем фактическое количество элементов в нем. Получается 38 гигабайт.

Накинем 2 гигабайта на разные неучтенные вещи, и получим, что наш индекс должен занимать порядка 40 гигабайт.
Ура, всё помещается.
Давайте приступим к реализации.
Реализуем непосредственно поиск
Здесь и далее я буду приводить фрагменты кода, которые иллюстрируют идею работы поиска, намеренно упрощая некоторые моменты. В частности, все будет в одном проекте без пространств имен.
Определимся, что клиенты поиска будут использовать https для получения результатов поиска.
Давайте создадим новый ASP.NET Core Web Application проект.
Добавим класс, в котором будет реализован наш поиск. Назовем его Index. Поскольку мы уже примерно определились с тем, как он должен работать, сразу заведем поле с индексируемыми символами и словарь для хранения списков с идентификаторами.
using System.Collections.Generic;
public class Index
{
private readonly string indexedCharacters = "abcdefghijklmnopqrstuvwxyz01234567890+абвгдежзиклмнопрстуфхцчшщуыьъэюя";
private readonly Dictionary<string, List<int>> buckets;
}Давайте теперь проинициализируем наш словарь пустыми списками:
public Index()
{
buckets = CreateBucketsDictionary();
}
private Dictionary<string, List<int>> CreateBucketsDictionary()
{
var dict = new Dictionary<string, List<int>>();
foreach (var first in indexedCharacters)
{
foreach (var second in indexedCharacters)
{
foreach (var third in indexedCharacters)
{
var key = "" + first + second + third;
dict[key] = new List<int>();
}
}
}
return dict;
}А также реализуем метод по добавлению значения в наш индекс:
public void Add(string key, int value)
{
var trigrams = ListTrigrams(key);
foreach (var trigram in trigrams)
{
buckets[trigram].Add(value);
}
}Нам понадобился метод по получению триграмм по строке, реализуем его. Код предельно простой, думаю, пояснения требует только один момент. Для нормализации строки мы используем метод ToLower. Это вполне годится для нашей задачи и нашего набора символов, но в общем случае Юникод не так прост.
private List<string> ListTrigrams(string value)
{
value = value.ToLower();
var chars = value.Where(indexedCharactersSet.Contains).ToArray();
var trigrams = new List<string>();
for (var i = 0; i < chars.Length - 2; i++)
{
var trigram = "" + chars[i] + chars[i + 1] + chars[i + 2];
trigrams.Add(trigram);
}
trigrams = trigrams.Distinct().ToList();
return trigrams;
}Для ускорения проверки, содержится ли символ в списке наших разрешенных символов, мы используем HashSet. Добавим его в поля класса, а его инициализацию — в конструктор класса.
private readonly HashSet<char> indexedCharactersSet;public Index()
{
indexedCharactersSet = indexedCharacters.ToHashSet();
///
}Не прошло и 10 минут, как у нас готова структура данных, о которой мы рассуждали вначале. Мы даже уложились в 60 строк кода, включая пустые строки и строки с конструкцией using.
Код, что у нас есть на данный момент, полностью
using System.Collections.Generic;
using System.Linq;
public class Index
{
private readonly string indexedCharacters = "abcdefghijklmnopqrstuvwxyz01234567890+абвгдежзиклмнопрстуфхцчшщуыьъэюя";
private readonly HashSet<char> indexedCharactersSet;
private readonly Dictionary<string, List<int>> buckets;
public Index()
{
indexedCharactersSet = indexedCharacters.ToHashSet();
buckets = CreateBucketsDictionary();
}
private Dictionary<string, List<int>> CreateBucketsDictionary()
{
var dict = new Dictionary<string, List<int>>();
foreach (var first in indexedCharacters)
{
foreach (var second in indexedCharacters)
{
foreach (var third in indexedCharacters)
{
var key = "" + first + second + third;
dict[key] = new List<int>();
}
}
}
return dict;
}
public void Add(string key, int value)
{
var trigrams = ListTrigrams(key);
foreach (var trigram in trigrams)
{
buckets[trigram].Add(value);
}
}
private List<string> ListTrigrams(string value)
{
value = value.ToLower();
var chars = value.Where(indexedCharactersSet.Contains).ToArray();
var trigrams = new List<string>();
for (var i = 0; i < chars.Length - 2; i++)
{
var trigram = "" + chars[i] + chars[i + 1] + chars[i + 2];
trigrams.Add(trigram);
}
trigrams = trigrams.Distinct().ToList();
return trigrams;
}
}Структура данных для поиска готова. Теперь давайте реализуем поиск. Это действительно просто. Но сначала отвлечемся и подумаем вот над чем. В данных, которые мы индексируем, не все слова встречаются с одинаковой частотой. Например, слово “телевизор” встретится десятки или сотни тысяч раз, а сочетание символов “65U710KB” — скорее всего, намного меньшее количество раз, скажем, счет идет на десятки или сотни. Количество значений, которые содержат определенную триграмму, тоже будет распределено неравномерно по всем возможным триграммам (это никак прямо не следует из рассуждения про частоту слов, но вполне очевидно).
Думаю, логично предположить, что используя для поиска фразу “телевизор 65U710KB” мы в первую очередь хотим получить все записи, которые содержат оба слова в таком же порядке, потом — те записи, которые содержат оба слова, следующими должны быть результаты, которые содержат “65U710KB” и не содержат ”телевизор”, и только потом очередь доходит до результатов, содержащих “телевизор” и не содержащих “65U710KB”. Другими словами, чем реже встречается некоторое слово, тем ценнее оно для поиска. Поскольку в нашем индексе уже нет слов, нам остается применить этот вывод для триграмм. Пусть это и не эквивалентно, но должно сработать.
Давайте построим график функции

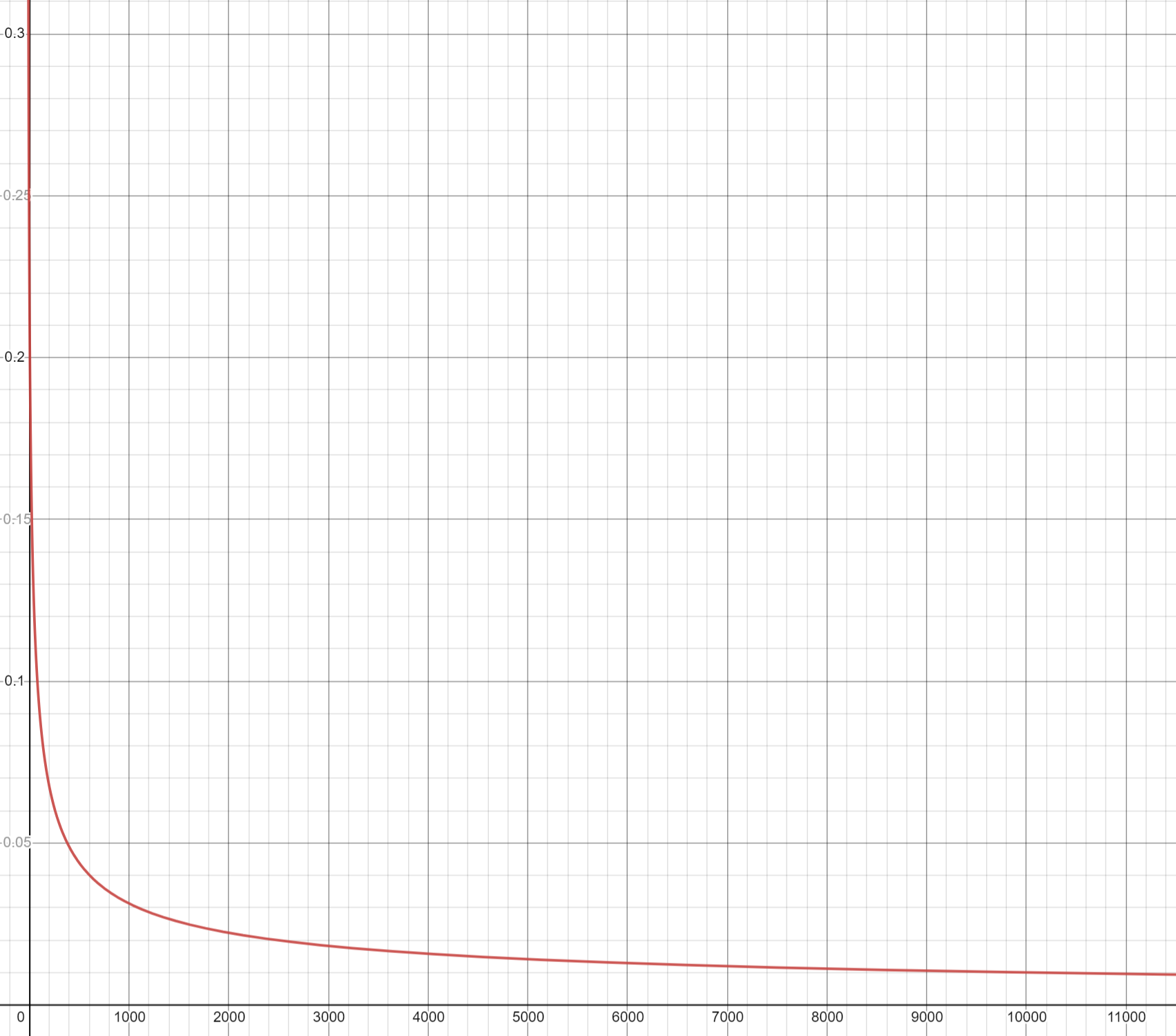
Если мы будем присваивать триграммам ценность по формуле выше, то получится, что при уменьшении частоты встречаемости триграммы в 10 раз её ценность будет увеличиваться примерно в три раза. Слагаемое 20 добавили под корень, чтобы редкие триграммы не перевешивали все остальные, на результаты при аргументах функции порядка тысяч оно почти не влияет. Для начала сойдет, а детально будем разбираться потом, если потребуется.
Теперь мы готовы написать функцию поиска по нашему индексу.
public int[] SearchFlexible(string query, int count)
{
var trigrams = ListTrigrams(query);
var orderedBuckets = trigrams
.Select(t => buckets[t])
.Where(b => b.Count > 0)
.OrderBy(b => b.Count)
.ToList();
var scores = new Dictionary<int, double>();
foreach (var bucket in orderedBuckets)
{
foreach (var value in bucket)
{
scores.TryGetValue(value, out var score);
if (scores.Count < 10000 || score > 0)
{
scores[value] = score + 1 / Math.Sqrt(bucket.Count + 20);
}
}
}
var result = scores
.OrderByDescending(p => p.Value)
.Select(p => p.Key)
.Take(count)
.ToArray();
return result;
}Да, вот настолько все просто. Давайте разберемся, как она работает.
Преобразуем запрос в список триграмм:
var trigrams = ListTrigrams(query);Для каждой триграммы из запроса возьмем список Id, которым она соответствует. Получим список списков. Выберем только непустые списки. Отсортируем список списков по количеству элементов во вложенном списке.
var orderedBuckets = trigrams
.Select(t => buckets[t])
.Where(b => b.Count > 0)
.OrderBy(b => b.Count)
.ToList();Создадим переменную (и объект) для хранения промежуточных результатов — словарь, ключом коорого будет Id товара, а значением — оценка его релевантности.
var scores = new Dictionary<int, double>();Посчитаем релевантность товаров. Ограничим размер промежуточного результата магическим числом 10000. Поскольку мы уже отсортировали списки Id, соответствующие триграммам, по количеству элементов в возрастающем порядке, для каждого Id слагаемые оценки его релевантности отсортированы в убывающем порядке. Таким образом, ограничение на размер промежуточного результата не должно сильно влиять на конечный результат — самые большие слагаемые точно будут учтены. Перенос магических чисел в константы оставим за рамками этой статьи.
foreach (var bucket in orderedBuckets)
{
foreach (var value in bucket)
{
scores.TryGetValue(value, out var score);
if (scores.Count < 10000 || score > 0)
{
scores[value] = score + 1 / Math.Sqrt(bucket.Count + 20);
}
}
}Отсортируем результаты по убыванию релевантности и возьмем нужное их количество
var result = scores
.OrderByDescending(p => p.Value)
.Select(p => p.Key)
.Take(count)
.ToArray();Вернем результат
return result;Тут есть один неочевидный момент. Сортировка в .NET, в общем случае, имеет сложность N*log(N), и на первый взгляд кажется, что мы сортируем все элементы чтобы взять только несколько первых. С другой стороны, мы имеем дело с IOrderedEnumerable и рекурсивным алгоритмом сортировки, который в каждой своей итерации делит элементы, полученные на вход, на те, которые больше некоторого опорного элемента, и те, которые меньше опорного элемента. Таким образом, правильно реализованный метод GetEnumerator (или MoveNext) может не делать сортировку целиком, а проделать только столько итераций, сколько требуется для определения первых count элементов.
Посмотрев исходный код OrderedEnumerable, я ничего сходу не понял (по крайней мере, намеки на оптимизации там есть), и решил проверить гипотезу опосредованно, через замеры времени для одного и того же списка, но разных аргументов метода Take. Вывод — все ок, время, затрачиваемое на выполнение, растет с ростом аргумента в методе Take, и этот рост на порядок больше, чем время, затрачиваемое на создание массива нужного размера.
Считайте, с самой сложной частью мы справились. Весь поиск уложился в 90 строк кода.
Добавим инфраструктуру
Теперь напишем код, который будет инициализировать наш индекс и добавлять туда элементы по мере их появления в базе данных.
Идея проста: делаем сервис, при старте создаем индекс и начинаем заполнять его данными из базы небольшими порциями до тех пор, пока очередной запрос в базу не вернет меньшее количество записей, чем мы запросили. С этого момента мы можем считать индекс проинициализированным и начать обрабатывать поисковые запросы.
Дополнять индекс новыми данными будем каждую минуту.
SQL - запросам в сервисе, конечно, не место, но в демонстрационных целях — можно. Ошибки тоже можно игнорировать.
Код сервиса напрямую не касается решаемой задачи, я спрячу его под спойлер.
Код сервиса
using System;
using System.Collections.Generic;
using System.Data.SqlClient;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Hosting;
public class SearchBackgroundService : IHostedService
{
private static Index index;
private static bool initialized;
private bool started;
private string connectionString;
private static long maxId;
private static int batchSize = 10000;
public SearchBackgroundService(IConfiguration configuration)
{
connectionString = configuration.GetConnectionString("Parsing");
if (index == null)
{
index = new Index();
}
}
public Task StartAsync(CancellationToken cancellationToken)
{
started = true;
Task.Run(UpdateIndex, cancellationToken);
return Task.CompletedTask;
}
private async Task UpdateIndex()
{
while (started)
{
var batch = await ListItemsFromDatabaseAsync(maxId + 1, batchSize);
foreach (var pair in batch)
{
index.Add(pair.Value, pair.Key);
}
maxId = batch.Keys.Count > 0 ? batch.Keys.Max() : maxId;
if (batch.Keys.Count < batchSize)
{
initialized = true;
await Task.Delay(60000);
}
}
}
private async Task<IDictionary<int, string>> ListItemsFromDatabaseAsync(long startId, int count)
{
var result = new Dictionary<int, string>();
var query = "select p.Id Id, p.Name Name \r\n" +
"from Products p \r\n" +
"where m.Id >= @startId \r\n" +
"order by m.Id \r\n" +
"offset 0 rows fetch next @count rows only";
await using var connection = new SqlConnection(connectionString);
var command = new SqlCommand(query, connection);
command.Parameters.Add(new SqlParameter("@startId", startId));
command.Parameters.Add(new SqlParameter("@count", count));
try
{
connection.Open();
var reader = await command.ExecuteReaderAsync();
while (reader.Read())
{
var id = Convert.ToInt32(reader["Id"]);
var name = Convert.ToString(reader["Name"]);
result[id] = name;
}
await reader.CloseAsync();
}
catch (Exception ex)
{
}
return result;
}
public async Task StopAsync(CancellationToken cancellationToken)
{
started = false;
}
public static int[] SearchFlexible(string query, int count)
{
if (!initialized)
{
throw new InvalidOperationException("Index is not initialized");
}
var result = index.SearchFlexible(query, count);
return result;
}
public static bool IsInitialized()
{
return initialized;
}
}Добавим контроллер, который будет обрабатывать HTTP запросы.
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
public class SearchController : Controller
{
public async Task<IActionResult> Index(string query, int count = 20)
{
if (!SearchBackgroundService.IsInitialized())
{
return StatusCode(503);
}
var result = SearchBackgroundService.SearchFlexible(query, count);
return Ok(result);
}
}Теперь воспользуемся в других проектах нашим новым поиском и сравним результаты с тем, что было.
Оценим результаты
Для пользователя время ожидания результатов поиска уменьшилось с 3-6 секунд до 120-150 миллисекунд. Непосредственно наш алгоритм занимает меньшую часть этого времени, меньше 10 миллисекунд. Остальное время занимает обогащение результатов текстом и изображениями, а также время на передачу запроса и ответа по сети (учитывая физическое расстояние до сервера в несколько тысяч километров, несколько десятков миллисекунд на это точно уходит).
По результатам двух месяцев, прошедших с момента реализации поиска таким способом, все хорошо. Поиск ни разу не сбоил и надежно работает. Потребление памяти в своих рассужденях из начала статьи мы оценили очень точно (тут 50 миллионов товаров в индексе). И да, .NET 5 на Линуксе прекрасно работает.

Вместо вывода
Иногда более эффективно разобраться в структурах данных, чем в конфигурации Эластика. А иногда — наоборот.
А добавить поиск по точному совпадению не составит совершенно никакого труда.
Комментарии (18)

vagon333
16.09.2021 03:50Может что-то упустил, но чем не подошел стандартный "sql server full text search" с их CONTAINS, NEAR, RANK, etc.?
Используем на больших массивах. Скорость высокая. Хотя, изначально тоже что-то пытались создавать свое через CLR-ки.

Razoomnick Автор
16.09.2021 04:11Нам нужно искать слова с опечатками и просто похожие варианты, и поиск не ограничивается только словами русского / английского языка. Например, на запрос "65U710KB" нужно предложить вариант "65U790KB", если ничего лучшего не было найдено.
Это поиск не для пользователей интернет-магазина, а для администраторов, и такой поиск упрощает их работу.

alisichkin
16.09.2021 09:43+2А почему нельзя хранить уже разбитые на NGram данные в MS SQL (что позволяет исключить этап загрузки) и выполнять поиск на стороне сервера - внутри stored procedure ?
Я в свое время именно так реализовал нечеткий поиск по справочнику лекарственных средств.
Razoomnick Автор
16.09.2021 13:54+1Можно, на протяжении года так и работало. Потом нас перестала устраивать скорость работы такого подхода.

rPman
16.09.2021 12:58Эээ, разве слов, используемых в названиях товаров так много? При добавлении товара, название должно разбиваться на слова, куда войдут все используемые слова (ошибки можно исключить заранее готовым словарем) и индексы и коды товаров, их будет явно меньше 50кк, и уже потом поиск проводить по этим словам, хочешь четкий, хочешь не четкий, если нужно больше (расстояние и порядок слов) доводились уже результат
Razoomnick Автор
16.09.2021 14:07По сути, мы именно это и сделали, только на уровне триграмм, а не слов.

avrusanov
17.09.2021 17:14+1buckets можно инициализировать по мере появления информации - уменьшит потребление памяти в части пустых списков которые никогда не используется - много кстати таких?
Razoomnick Автор
17.09.2021 17:53Хорошее замечание, спасибо.
Я даже не знаю, сколько пустых, но давайте попробуем посчитать потенциальную экономию.
public class List<T> : IList<T>, IList, IReadOnlyList<T> { private const int DefaultCapacity = 4; internal T[] _items; // Do not rename (binary serialization) internal int _size; // Do not rename (binary serialization) private int _version; // Do not rename (binary serialization) private static readonly T[] s_emptyArray = new T[0]; ........ }Это фрагмент исходного кода .NET 5
Для хранения пустого списка на 64-битной системе потребуется 8 + 4 + 4 = 16 байт. Плюс хранение ссылки на этот список потребует 8 байт, итого 24 байта без учета выравнивания. Потребление памяти с выравниванием я сходу не посчитаю, к сожалению, поэтому оставим так.
Всего у нас 343 000 списков, это дает 8 232 000 байт потенциальной экономии для случаев, когда индекс создали, а использовать не стали.
Думаю, в нашем случае, когда индекс создается в одном экземпляре, экономией 8 мегабайт памяти можно пренебречь ради упрощения кода. С другой стороны, если бы речь шла про переиспользуемую библиотеку, учесть это обязательно нужно.
Возможно, я найду время и оформлю эту идею в виде nuget - пакета, и тогда сделаю ленивую инициализацию.

Zaphkiel
19.09.2021 06:17+1Сколько времени занимает первоначальное заполнение индекса при старте сервиса? Рассматривали ли какие-нибудь готовые движки полнотекстового поиска?
Razoomnick Автор
19.09.2021 19:08Первоначальное заполнение занимает около 20-30 минут.
Что касается готовых движков, то те, с которыми я работал раньше, не умели искать по подстроке, то есть, были не способны найти "65U790KB" по запросу "65U790K", а это в нашем случае важно. По сути, такое поведение понятно, они создавались для поиска по тексту на естественном языке. Возможно, сейчас кто-то уже так может, но я положился на свой прошлый опыт.
Второй вариант - использовать готовый движок, но с индексом не по словам, а по триграммам. И сначала у нас был именно такой подход, но в какой-то момент перестала устраивать скорость работы.
Есть еще два аргумента против готового:
Свой поиск получился довольно простым по устройству, и его мы полностью контролируем, а не ограничены настройками готового движка. С другой стороны, мы ограничены своими возможностями, и, например, морфологии у нас никогда не будет.
Мы стараемся минимизировать количество инфраструктурных зависимостей. Сейчас такая зависимость только одна - SQL Server. В общем, такой вот keep it simple.
Zaphkiel
20.09.2021 11:3020-30 минут для 100 (или всё-таки 50?) миллионов документов это отличный результат.
По поводу префиксного поиска, тот же самый ElasticSearch это прекрасно умеет. Но с другой стороны это инфраструктурная зависимость, возможно есть смысл рассмотреть какой-нибудь LuceneNet?Razoomnick Автор
20.09.2021 23:50Все-таки пока 50, и 20-30 минут - это для 50. Но ради заголовка я попробовал и 100, просто продублировав товары с разными Id - работает.
Что касается LuceneNet, то определенно стоит изучить возможности. Но я люблю работать с алгоритмами больше, чем с конфигурациями, а тут такая возможность появилась.
Поиск для конечных пользователей, когда до него дойдет очередь, будем строить на сторонних библиотеках, скорее всего. А требования (или пожелания) к поиску для администраторов как раз лучше закрываются самописным алгоритмом.
sshikov
Идея описана интересная. Но это же прям случай, когда очевидно напрашивается горизонтальное масштабирование. Не очень понятно, почему вы не посмотрели в эту сторону, тогда ведь можно было бы не пытаться влезть в ограничения памяти одного сервера?
Razoomnick Автор
Все просто, горизонтальное масштабирование позволит хранить больше данных, но не позволит MS SQL Server быстрее искать по полнотекстовому индексу. Вызов функции Containstable на таком объеме данных занимает 98% времени обработки запроса, то есть, по сути те 2-5 секунд, о которых я писал вначале, и принципиально его не ускорить. Вместо этого мы сделали метод, который работает за 10 миллисекунд, эта часть ускорилась в 200-500 раз.
А что до ограничений памяти сервера, то аренда сервера с 64 гигабайтами стоит 50 евро в месяц. И ещё запас для роста в 2 раза остался.
Я не знаю, при помощи какого инструмента можно добиться такого результата "из коробки".
sshikov
Я имел в виду масштабирование уже вашего решения, а не MS SQL. Ну т.е. того, которое за 10 микросекунд, но ограничено памятью сервера. Вот тут можно поставить рядом еще один такой же — и не париться о том, что данные не влезут в 64 гигабайта. Данные же не меняются — так что параллелить должно быть можно.
Razoomnick Автор
Простите, не так вас понял. Да, это можно. Конкретно в нашей ситуации сначала проще докупать память на одном сервере, чем делать масштабирование. До 256 ГБ можно докупить, дальше упираемся в ограничения используемого железа.
Если же делать из этого публичное решение, то конечно, масштабирование необходимо.
sshikov
Ну да, 64 уже давно не предел, у нас в кластерах сервера стоят в и 10 раз больше местами, и по терабайту уже в принципе можно. Тут уже скорее вопрос цены, и что будет загружено — память или же ядра.
Razoomnick Автор
Мы пока загрузили 20 ГБ памяти, и ядра практически никак не загружены.