В этой статье мы разберемся, как работает типичная защита от роботов, рассмотрим подходы к автоматическому парсингу сайтов с такой защитой, и разработаем свое решение для её обхода. В конце статьи будет ссылка на гитхаб.
Речь не идет о каком-либо виде "взлома" или о создании повышенной нагрузки на сайт. Мы будем автоматизировать то, что и так можно сделать вручную. Если говорить конкретно о нас, то мы собираем характеристики товаров.

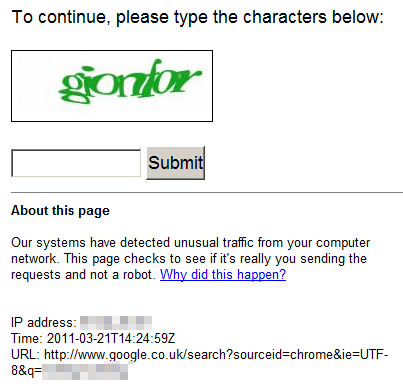
Думаю, иногда при серфинге вы встречали такие страницы-заглушки. Их цель — удостовериться, что посмотреть на страницу хочет кто-то относительно живой, и пропустить его, и в то же время заблокировать различного рода роботов и парсеров. По сути, перед нами капча, но автоматическая, не требующая взаимодействия с пользователем.
Как работает защита от автоматических запросов?
Вряд ли кто-то знает наверняка в деталях, кроме разработчиков конкретного решения. Но мы можем сделать некоторые обоснованные предположения. По крайней мере, можем понять, какие принципы для этого могут быть использованы.
Давайте попробуем классифицировать способы, которые используют сайты, чтобы отфильтровать автоматические запросы.
Самописные решения.
Готовые модули для веб-cервера. По запросу “nginx bots protection module” находится много разных решений, и платных, и бесплатных, и открытых.
Сторонний сервис, специализирующийся на фильтрации автоматического трафика.
Для начала, давайте разберемся, что о нас известно серверу на той стороне, вне зависимости от того, каким из способов реализована проверка.
IP-адрес. По нему можно определить страну, город, провайдера. В большинстве случаев, по нему нельзя определить конкретное устройство или конкретного абонента, потому что абоненты находятся за NAT.
Заголовки HTTP. По ним можно определить браузер, используемый язык интерфейса, и некоторые другие параметры. В них же передаются Cookies, с их помощью которых можно сопоставить запросы из одного браузера. Так же с их помощью можно определить, выполняется ли на клиенте код на JavaScript.
Особенности реализации TCP, TLS и HTTP/2. Суть в том, что HTTP — это прикладной, самый последний уровень модели OSI, а на уровнях ниже используются протоколы, реализация которых в разных программах может иметь особенности.
Последнее утверждение получилось весьма неконкретным, поэтому давайте установим какой-нибудь анализатор трафика и посмотрим, что происходит на самом деле.
Я не являюсь сетевым инженером, поэтому могу допускать ошибки в рассуждениях о сетевых протоколах и трактовке полученных данных, но считаю тему важной и поэтому достойной попытки в ней разобраться.
Я установил Microsoft Network Monitor и посмотрел, как выглядят запросы из разных инструментов в виде кадров канального уровня. Примерно так:
Кадр из Microsoft Network Monitor
Frame: Number = 306, Captured Frame Length = 277, MediaType = WiFi
- WiFi: [Unencrypted Data] .T....., (I)
- MetaData:
Version: 2 (0x2)
Length: 32 (0x20)
- OpMode: Extensible Station Mode
StationMode: (...............................0) Not Station Mode
APMode: (..............................0.) Not AP Mode
ExtensibleStationMode: (.............................1..) Extensible Station Mode
Unused: (.0000000000000000000000000000...)
MonitorMode: (0...............................) Not Monitor Mode
Flags: 4294967295 (0xFFFFFFFF)
RemData: Outbound
TimeStamp: 01/14/2023, 14:02:35.627425 UTC
- FrameControl: Version 0,Data, Data, .T.....(0x108)
Version: (..............00) 0
Type: (............10..) Data
SubType: (........0000....) Data
DS: (......01........) STA to DS via AP
MoreFrag: (.....0..........) No
Retry: (....0...........) No
PowerMgt: (...0............) Active Mode
MoreData: (..0.............) No
ProtectedFrame: (.0..............) No
Order: (0...............) Unordered
Duration: 32768 (0x8000)
BSSID: 2C9D1E DC642C
SA: E470B8 CF3A50
DA: 2C9D1E DC641F
- SequenceControl: Sequence Number = 0
FragmentNumber: (............0000) 0
SequenceNumber: (000000000000....) 0
- LLC: Unnumbered(U) Frame, Command Frame, SSAP = SNAP(Sub-Network Access Protocol), DSAP = SNAP(Sub-Network Access Protocol)
- DSAP: SNAP(Sub-Network Access Protocol), Individual DSAP
Address: (1010101.) SNAP(Sub-Network Access Protocol)
IG: (.......0) Individual Address
- SSAP: SNAP(Sub-Network Access Protocol), Command
Address: (1010101.) SNAP(Sub-Network Access Protocol)
CR: (.......0) Command Frame
- Unnumbered: UI - Unnumbered Information
MMM: (000.....) 0
PF: (...0....) Poll Bit - No Response Solicited
MM: (....00..)
Type: (......11) Unnumbered(U) Frame
- Snap: EtherType = Internet IP (IPv4), OrgCode = XEROX CORPORATION
OrganizationCode: XEROX CORPORATION, 0(0x0000)
EtherType: Internet IP (IPv4), 2048(0x0800)
- Ipv4: Src = 192.168.100.24, Dest = 49.12.20.235, Next Protocol = TCP, Packet ID = 3626, Total IP Length = 213
- Versions: IPv4, Internet Protocol; Header Length = 20
Version: (0100....) IPv4, Internet Protocol
HeaderLength: (....0101) 20 bytes (0x5)
- DifferentiatedServicesField: DSCP: 0, ECN: 0
DSCP: (000000..) Differentiated services codepoint 0
ECT: (......0.) ECN-Capable Transport not set
CE: (.......0) ECN-CE not set
TotalLength: 213 (0xD5)
Identification: 3626 (0xE2A)
- FragmentFlags: 16384 (0x4000)
Reserved: (0...............)
DF: (.1..............) Do not fragment
MF: (..0.............) This is the last fragment
Offset: (...0000000000000) 0
TimeToLive: 128 (0x80)
NextProtocol: TCP, 6(0x6)
Checksum: 33089 (0x8141)
SourceAddress: 192.168.100.24
DestinationAddress: 49.12.20.235
- Tcp: Flags=...AP..., SrcPort=51677, DstPort=HTTPS(443), PayloadLen=173, Seq=3595707432 - 3595707605, Ack=850844191, Win=512 (scale factor 0x8) = 131072
SrcPort: 51677
DstPort: HTTPS(443)
SequenceNumber: 3595707432 (0xD6522428)
AcknowledgementNumber: 850844191 (0x32B6DA1F)
- DataOffset: 80 (0x50)
DataOffset: (0101....) 20 bytes
Reserved: (....000.)
NS: (.......0) Nonce Sum not significant
- Flags: ...AP...
CWR: (0.......) CWR not significant
ECE: (.0......) ECN-Echo not significant
Urgent: (..0.....) Not Urgent Data
Ack: (...1....) Acknowledgement field significant
Push: (....1...) Push Function
Reset: (.....0..) No Reset
Syn: (......0.) Not Synchronize sequence numbers
Fin: (.......0) Not End of data
Window: 512 (scale factor 0x8) = 131072
Checksum: 0xF528, Disregarded
UrgentPointer: 0 (0x0)
TCPPayload: SourcePort = 51677, DestinationPort = 443
TLSSSLData: Transport Layer Security (TLS) Payload Data
- TLS: TLS Rec Layer-1 HandShake: Encrypted Handshake Message.
- TlsRecordLayer: TLS Rec Layer-1 HandShake:
ContentType: HandShake:
- Version: TLS 1.2
Major: 3 (0x3)
Minor: 3 (0x3)
Length: 168 (0xA8)
- SSLHandshake: SSL HandShake
EncryptedHandshakeMessage: Binary Large Object (168 Bytes)Канальный уровень нас не интересует, данные о нем до удаленного сервера не дойдут. Нас интересуют инкапсулированные в кадре канального уровня пакеты сетевого уровеня и уровни выше.
Первое интересное наблюдение: IP-пакет содержит параметр TTL. Начальное значение этого параметра для TCP протокола отличается в разных операционных системах. Мне удалось найти такие значения для современных версий:
Windows |
128 |
Linux |
64 |
MacOS |
64 |
iOS |
64 |
Android |
64 |
Теоретически, можно проверить, соответствует ли значение заголовка User-Agent значению TTL IP-пакетов.
Второе интересное наблюдение: разные программы используют разные версии TLS для доступа к одному и тому же ресурсу. В частности, в моих экспериментах Вивальди всегда использовал версию 1.0, а Fiddler — версию 1.2.
Уверен, что опытный сетевой инженер найдет и другие закономерности.
Промежуточный вывод: да, особенности реализации сетевых протоколов в различных программах можно использовать для косвенного определения, был запрос сделан из браузера или нет.
Теперь рассмотрим наши пункты подробнее.
Самописные решения
В этом пункте может быть что угодно, от простой проверки User-Agent до требования аппаратного ключа для доступа к запрашиваемым ресурсам.
Самое простое. Некоторые сайты проверяют заголовок User-Agent, и не обрабатывать запросы, если такого заголовка нет в запросе, либо если в нем передается нетипичное для браузера значение.
Чуть сложнее. Могут быть разные вариации непосредственно алгоритма, но суть состоит в проверке того, что заголовки корректно передаются и обрабатываются клиентом. В частности, может проверятся обработка клиетом заголовка Set-Cookie. Может проверяться соответствие значений заголовков User-Agent, Accept и Accept-Encoding. Браузер, не принимающий gzip, — возможно, не браузер.
Также может быть реализована проверка того, что на клиенте включен JavaScript.
Может использоваться самописная капча. Использование готовых библиотек для генерации картинки с искажениями тоже определим в этот пункт.

Может быть установлено ограничение по количеству запросов с одного IP-адреса за единицу времени.
Может отслеживаться соотношение запросов к страницам и запросов к другим ресурсам. Если с какого-то IP-адреса регулярно запрашиваются HTML-страницы, но не запрашиваются изображения — это подозрительно.
Готовые модули для веб-cервера
Случайный сайт в интернете, которому у нас нет оснований не доверять, говорит, что на рынке веб-серверов сложилась такая ситуация:

Nginx на первом месте, и он поддерживает сторонние модули. Apache на втором месте, и он тоже поддерживает сторонние модули. Часто они работают вместе, Nginx работает как reverse proxy и обрабатывает запросы к серверу на 80 и 443 портах, отдает статику и занимается кэшированием, а запросы на динамические страницы передаёт Apache.
В принципе, всё, что может быть реализовано как самописное решение, может быть реализовано и как готовый модуль для веб-сервера.
Но давайте найдем пару готовых модулей и попробуем по их документации понять принцип работы.
Первым результатом Гугл выдал DataDome Nginx module. Документация говорит следующее: при получении запроса модуль сделает запрос к DataDome API, и, в зависимости от ответа, заблокирует запрос или продолжит его обработку. Модуль может сочетаться со скриптом, который добавляется на все страницы сайта. Скрипт выполняет дополнительные проверки на клиенте.
В общем, пока мы увидели принцип “держать алгоритм детектирования ботов в секрете”.
Следующие несколько результатов из поисковой выдачи работают по такому же принципу.
Следующий результат — Nginx Bad Bot and User-Agent Blocker, Spam Referrer Blocker, Anti DDOS, Bad IP Blocker and Wordpress Theme Detector Blocker. Тут уже доступен исходный код, и можно разобраться, как модуль работает. Если кратко — то работает на основе черных и белых списков. Анализируются не только IP-адреса, но и значения заголовков User-Agent, Refferrer и других. Возможно, дополнительно используются некоторые эвристики, но я в процессе беглого просмотра их не нашел.

Сторонние сервисы
Существуют сторонние сервисы, которые позволяют блокировать автоматические парсеры. Как правило, их функциональность этим не ограничивается, и они предлагают и другие полезные вещи: CDN, защиту от DoS и DDoS, кэширование, управление DNS, хостинг. Самым популярным таким сервисом является Cloudflare.
Сам Cloudflare даёт такую схему работы своего сервиса:

По сути, происходит следующее: владелец сайта в панели управления доменом меняет значения NS-записей на DNS-сервера Cloudflare. После этого запросы на преобразование имени (символьного адреса) хоста в его IP-адрес возвращают IP-адреса серверов Cloudflare. Соответственно, и запросы к сайту направляются на сервера Cloudflare.
Получив HTTP-запрос, сервер Cloudflare решает, заблокировать его, выполнить автоматическую проверку на клиенте на предмет “бот — не бот”, выполнить проверку, которая требует взаимодействия с пользователем (капча), либо продолжить обработку запроса.
Что касается процесса первоначального анализа запроса, то серверу Cloudflare доступна вся информация о запросе, которую мы рассматривали выше. Кроме того, доступны разного рода статистические данные по всем запросам к серверам Cloudflare, а не только запросам к сайту одного клиента.
Рассматиривая Cloudflare, мы обязательно должны рассмотреть и проверку на клиенте. Это то, что в при обсуждении сервиса принято называть словом “challenge”. Суть его такова: в ответ на запрос к сайту Cloudflare отдает специальным образом сформированную страницу, где есть какой-то обфусцированный JavaScript. Этот JavaScript реализует обращения к разным API браузера, включая возможность делать ajax-запросы, производит вычисления, проверяет наличие Selenium-драйвера, в общем, проверяет, что браузер ведет себя как браузер, а не как другая реализация интерпретатора JavaScript. В зависимости от результатов этой проверки, разрешается или блокируется доступ к запрошенной странице. Конкретный алгоритм проверки меняется со временем.
Разрабатываем парсер
Учитывая все, сказанное выше, думаю, оптимальными будут такие особенности нашей системы парсинга:
Будем использовать готовые решения для работы с HTTP запросами и DOM.
Будем использовать распространенные и согласованные заголовки Accept, Accept-Encoding, User-Agent.
Будем использовать сессии, под ними подразумевается корректная обработка заголовка Set-Cookie и хранение значнеия Cookie между запросами.
В случае, если запросы к конкретному сайту блокируются, будем использовать браузер для получения HTML-кода страниц с этого сайта. Весь остальной процесс не изменяется.
Поскольку основная наша платформа — .NET, в качестве основного инструмента для работы с запросами и DOM будем использовать AngleSharp. Эту часть я опишу в виде псевдокода, потому что в этой статье мы не изучаем AngleSharp, а разбираемся, как пройти проверку Cloudflare.
Мы собираемся парсить разные сайты. Логично, что в таком случае каждый из парсеров лучше реализовать в виде отдельного класса. Но мы не хотим писать повторяющийся код раз за разом во всех этих классах, поэтому давайте вынесем переиспользуемые методы в базовый класс. Можно и аггрегирование использовать, но у нас будет старое доброе наследование.
Наш базовый класс в таком случае может выглядеть примерно так. Вопросы асинхронности опустим. Псевдокод, похожий на C#:
public abstract class BaseParser
{
private readonly ILogger logger;
private readonly string solverProxyEndpoint;
private bool useBrowserProxy = false;
private IBrowsingContext context;
protected BaseParser(
ILogger logger,
IConfiguration configuration)
{
this.logger = logger;
solverProxyEndpoint = configuration["SolverProxyEndpoint"];
context = CreateContext();
}
private IBrowsingContext CreateContext()
{
var config = GetAngleSharpConfiguration();
var context = BrowsingContext.New(config);
return context;
}
private AngleSharp.IConfiguration CreateAngleSharpConfiguration()
{
var requester = CreateHttpRequester();
var config = AngleSharp.Configuration.Default
.With(requester)
.WithCookies()
.WithDefaultLoader();
return config;
}
private IRequester CreateHttpRequester()
{
var requester = new DefaultHttpRequester();
// Добавить заголовки запроса
return requester;
}
private IDocument LoadDocumentWithSolverProxy(string url)
{
// Сделать запрос на сервис, который обойдет блокировку.
// Открыть ответ как документ AngleSharp.
// Назначить корректный базовый адрес, это понадобится
// для корректной работы с относительными адресами.
// Вернуть документ.
}
protected virtual bool ChallengeExists(IDocument document)
{
// Проверить, что на странице присутствуют элементы,
// которые ассоциированы с выполнением автоматической проверки.
// Например, элемент с аттрибутом id равным "challenge-running".
}
protected IDocument LoadDocument(string url)
{
try
{
IDocument document = null;
if (!useBrowserProxy)
{
document = context.Open(url);
useBrowserProxy = ChallengeExists(document);
}
if (useBrowserProxy)
{
document = LoadDocumentWithSolverProxy(url);
}
return document;
}
catch (Exception e)
{
logger.Log(e, url);
return null;
}
}
}Что же, несколькими строками кода мы решили вопрос с сессией и заголовками. Но больше всего нас интересует метод LoadDocumentWithSolverProxy(string url). Он должен каким-то образом пройти проверку Cloudflare. На самом деле, не только проверку Cloudflare, но и другие подобные проверки.
Способы обхода блокировки
Пройти проверку Cloudflare сложно, но возможно. Способы это сделать сводятся к следующим:
Слать запросы непосредственно на сервер, обслуживающий сайт, в обход Cloudflare. Просто, но не всегда возможно. Подразумевается, что тот, кто настраивал защиту от ботов, поленился, ошибся или не до конца разобрался, и не запретил обращения к серверу мимо Cloudflare.
Забирать страницы из кэша Гугла.
Воспользоваться готовым программным решением для прохождения проверки. Например, FlareSolverr.
Производить парсинг с помощью браузера, управляемого кодом. По сути, использовать инструменты для автоматического сквозного тестирования: Puppeteer, Playwright, Selenium.
Воспользоваться платным сервисом, который умеет проходить проверки.
Разобраться, как работает защита, провести реверс-инжиниринг, и проходить её наиболее оптимальным способом, не запуская ресурсозатратные браузеры.
Я попробовал почти все, и сейчас расскажу о результатах.
Возможность слать запросы в обход проверки нельзя рассматривать как надежное и воспроизводимое решение. Повезет — получится, не повезет — не получится. Скорее всего, не получится. Не рассматриваем как универсальное решение. Мне не удалось найти сайт, который можно было бы распарсить таким образом. С другой стороны, я не особо старался и потратил на поиск минут пять.
Возможность забирать страницы из кэша Гугла или другого поисковика тоже не выглядит надежным решением. Во-первых, не все нужные страницы могут быть в кэше Гугла. Во-вторых, Гугл тоже может забанить. Такое уже бывало, когда провайдер использовал один публичный IP-адрес для слишком большого числа абонентов. Тогда мы видели такую страницу при каждой попытке открыть поисковик:
Но способ рабочий. Шаблон адреса такой: https://webcache.googleusercontent.com/search?q=cache:{url_of_requested_page_here}
Что касается готовых решений, я попробовал следующие:
CloudflareSolverRe. Подход, примененный автором, не использует браузерный движок. Ответ сервера разбирается средствами C#, и на C# воспроизводится алгоритм решения задачи. К сожалению, не работает с 2020 года, когда Cloudflare поменяла алгоритм проверки. Он стал более сложным, и теперь состоит из нескольких шагов, и кроме того использует не только вычисления на JavaScript, но и взаимодействие с API браузера. Подход не оправдал себя, потому что любое изменение в алгоритме проверки приводит к необходимости менять алгоритм её обхода, а то и полностью его переписывать.
FlareSolverr. На первый взгляд выглядит рабочим. Есть свежие (вчерашние на момент написания статьи) коммиты и живой баг-трекер. Когда я его скачал и запустил, он не прошел проверку на первом же сайте. Я пошел разбираться и выяснил, для разработки используется Python, а для прохождения проверок — Selenium. В процессе я обнаружил такой код:
ACCESS_DENIED_SELECTORS = [
# Cloudflare
'div.cf-error-title span.cf-code-label span'
]
CHALLENGE_TITLE = [
# Cloudflare
'Just a moment...',
# DDoS-GUARD
'DDOS-GUARD',
]
CHALLENGE_SELECTORS = [
# Cloudflare
'#cf-challenge-running', '.ray_id', '.attack-box', '#cf-please-wait', '#challenge-spinner', '#trk_jschal_js',
# Custom CloudFlare for EbookParadijs, Film-Paleis, MuziekFabriek and Puur-Hollands
'td.info #js_info'
]Ниже производится поиск элементов по селектору на странице, этот код я не привожу. Элемент есть — ждем, элемента нет — возвращаем результат.
Так я узнал, что страницу-заглушку можно настраивать, и она на разных сайтах может быть разной. К сожалению, на первом же тестируемом сайте проверка не прошла. Для построения универсального решения для обхода защиты потребуется менять исходный код. Поддерживать код на питоне лично мне не хочется, но это решение уже можно рассматривать как основу для надежной системы парсинга.
Следующим я попробовал Selenium. Это уже посложнее, чем скачать и запустить, речь про код на C#, который обрабатывает запросы вида “http://localhost/proxy?url=https://nowsecure.nl”, загружает нужный адрес в запущенном браузере, ждет, пока пройдет проверка, и возвращает результат. Взаимодействие с браузером осуществляется при помощи Selenium-драйвера.
Что же, на этом этапе выяснилось, что
Проверка Cloudflare понимает, что браузер управляется драйвером.
Это на самом деле несложно

Алгоритм определения этого, который используется Cloudflare, сложнее, чем просто проверка свойства navigator.webdriver.
Существует версия драйвера, которая, теоретически, не детектируется.
Версия, которая, теоретически, не детектируется, не определяется при первом посещении сайта запущенным браузером, но детектируется со второго посещения. Почему — непонятно. Браузер нужно постоянно перезапускать.
Алгоритм детектирования Selenium меняется с течением времени, и иногда драйвер начинает определяться. Тогда нужно ждать выхода следующей версии.
В общем, я почти повторил функциональность FlareSolverr на C#. Соответственно, недостатки решения на Selenium относятся и к FlareSolverr, но они дали о себе знать только при более тесном знакомстве с используемым подходом.
Из платных сервисов я попробовал scrapingbee.com и остался вполне доволен результатом. Возможно, для парсинга небольшого количества страниц это оптимальное решение. По крайней мере, стоит оценить затраты на платный сервис и затраты на собственную разработку и сравнить их. С другой стороны, я сделал с десяток запросов, этого мало, чтобы сделать обоснованные выводы. Вариант однозначно стоит рассмотреть, но мы в рамках нашей статьи его пропустим, потому что о простой интеграции с API стороннего сервиса неинтересно писать и неинтересно читать.
Почему не стоит рассматривать реверс-инжиниринг и прохождение проверки без запущенного браузера, уже красочно ответил CloudflareSolverRe. Потому что сложно, и в случае изменений в алгоритме проверки, скорее всего, придется переписать все с нуля.
Обходим блокировку
Думаю, мы достаточно погрузились в тему, чтобы приступить к реализации собственного решения.
Оно у нас будет состоять из двух частей. Серверная часть будет реализована на языке C# и платформе .NET Core, а клиентская — в виде расширения для браузера Chrome. Выбор C# обусловлен личными предпочтениями, объективно, подойдет почти любой язык. Опыт использования Selenium для этой цели говорит о том, что расширение для браузера будет более надежным решением. Кроме того, мы будем контролировать весь процесс, и у нас не будет промежуточного черного ящика в виде Selenium драйвера.
Давайте начнем с серверной части. Подразумевается такой сценарий работы:
Сервер получает запрос на загрузку некоторой страницы. В параметрах запроса передается адрес страницы и, опционально, css-селекторы элементов, сигнализирующих о том, что выполняется автоматическая проверка. Кроме того, в параметрах можно передать селектор элемента, по которому нужно эмулировать щелчок мыши. Соответственно, запрос должен выглядеть примерно так: https://proxy.loader/load?url=https%3A%2F%2Fexample.com&waitSelector=%23challenge&clickSelector=%23click-here
Запрос ставится в очередь необработанных запросов.
Расширение запрашивает адрес для загрузки. Соответственно, сервер обрабатывает этот запрос и возвращает информацию опервом в очереди адресе, который необходимо загрузить. Адрес удаляется из очереди и перемещается в список адресов, которые находятся в процессе загрузки. Расширение переходит по полученному на какой-нибудь из вкладок (давайте пока не будем конкретизировать это поведение).
Расширение ждет, пока проходит автоматическая проверка. При необходимости, эмулирует нажатия мыши.
Расширение преобразует загруженный документ в HTML-разметку и отправляет его на сервер с помощью POST запроса.
Сервер возвращает ответ на запрос из пункта 1.
Давайте напишем сервер. Версия приведенная здесь, будет отличаться от версии в git. Я удалил несущественные в контесте обсуждения обхода блокировки проверки аргументов и обработки ошибок. Итак, файл Program.cs:
using BrowserProxy;
var syncRoot = new object();
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
using var pageLoader = new PageLoader();
app.MapGet("/load", LoadUrlAsync);
app.MapGet("/task", GetUrlToLoad);
app.MapPost("/result", SetResultAsync);
app.Run();
async Task<IResult> LoadUrlAsync(string url, string? waitSelector = null, string? clickSelector = null)
{
try
{
var result = await pageLoader.LoadUrlAsync(url, waitSelector, clickSelector);
return Results.Content(result, "text/html; charset=utf-8");
}
catch (TimeoutException e)
{
return Results.Problem("Timeout", "", 408);
}
catch (OverflowException e)
{
return Results.Problem("Too many requests", "", 429);
}
catch (Exception e)
{
return Results.Problem("Internal error", "", 500);
}
}
IResult GetUrlToLoad()
{
var urlToLoad = pageLoader.GetUrlToLoad();
var result = urlToLoad != null
? Results.Json(urlToLoad)
: Results.NoContent();
return result;
}
async Task<IResult> SetResultAsync(string url, Stream stream)
{
using var streamReader = new StreamReader(stream);
var result = await streamReader.ReadToEndAsync();
pageLoader.TrySetResult(url, result);
return Results.Accepted();
}Что же, мы реализовали три метода, которые могут обрабатывать HTTP запросы.
LoadUrlAsync принимает запрос на загрузку страницы, пытается ее загрузить и возвращает результат, если получилось. Если нет — возвращает код состояния, соответствующий ошибке.
GetUrlToLoad возвращает информацию об адресе из очереди, который необходимо загрузить в браузере. Он будет обрабатывать запросы от нашего расширения.
Возможно, идея возвращать в одном и том же методе json в случае, если в очереди что-то есть, и код состояния 204 без тела ответа в случае, если очередь пуста, кому-то покажется немного нелогичной, и я соглашусь с его доводами. Но в данном случае мы будем обходиться необходимым минимумом сущностей.
SetResultAsync будет обрабатывать запросы от расширения с результатом загрузки страницы.
Непосредственно загрузку страниц мы делегировали классу PageLoader. Давайте сначала схематично набросаем его структуру.
public class PageLoader
{
public async Task<string> LoadUrlAsync(string url, string? waitSelector = null, string? clickSelector = null)
{
// Проверить, что в очереди на загрузку есть место.
// Добавить адрес в очередь на загрузку.
// Ждать, пока страница не будет загружена,
// либо не истечет время, отведенное на её загрузку.
}
public UrlToLoad? GetUrlToLoad()
{
// Проверить, что очереди не пуста.
// Взять первый адрес из очереди и удалить его из очереди.
// Добавить адрес в список адресов, которые находятся в процессе загрузки.
// Вернуть адрес.
}
public void TrySetResult(string url, string result)
{
// Сообщить методу LoadUrlAsync, что страница загружена.
}
private void MainLoop(object cancelationToken)
{
// Адреса, которые находятся в очереди либо в процессе загрузки,
// проверить на предмет истечения времени, отведенного на загрузку.
// Если время истекло, уведомить об этом метод LoadUrlAsync.
// Подождать.
// Повторить.
}
}
Теперь давайте воплотим это в коде. То, что получилось у меня, будет под спойлером.
PageLoader.cs
using System.Collections.Concurrent;
using DateTime = System.DateTime;
namespace BrowserProxy;
public class PageLoader : IDisposable
{
private readonly int queueSize = 10;
private readonly TimeSpan maxWaitTime = TimeSpan.FromSeconds(30);
private ConcurrentQueue<QueueItem> pendingQueue;
private HashSet<QueueItem> queueItemsInProgress;
private CancellationTokenSource mainLoopCancellationTokenSource;
public PageLoader()
{
pendingQueue = new ConcurrentQueue<QueueItem>();
queueItemsInProgress = new HashSet<QueueItem>();
mainLoopCancellationTokenSource = new CancellationTokenSource();
Task.Factory.StartNew(MainLoop, mainLoopCancellationTokenSource.Token);
}
public async Task<string> LoadUrlAsync(string url, string? waitSelector = null, string? clickSelector = null)
{
if (pendingQueue.Count >= queueSize)
{
throw new OverflowException("Too many requests");
}
if (string.IsNullOrEmpty(url))
{
throw new ArgumentException("Url can't be null");
}
var taskCompletionSource = new TaskCompletionSource<string>();
var queueItem = new QueueItem()
{
Url = url,
WaitSelector = waitSelector,
ClickSelector = clickSelector,
StartTime = DateTime.Now,
TaskCompletionSource = taskCompletionSource
};
pendingQueue.Enqueue(queueItem);
var result = await taskCompletionSource.Task;
return result;
}
public UrlToLoad? GetUrlToLoad()
{
pendingQueue.TryDequeue(out var queueItem);
if (queueItem == null)
{
return null;
}
queueItemsInProgress.Add(queueItem);
var urlToLoad = new UrlToLoad
{
Url = queueItem.Url,
WaitSelector = queueItem.WaitSelector,
ClickSelector = queueItem.ClickSelector
};
return urlToLoad;
}
public void TrySetResult(string url, string result)
{
var itemsInProgressToSet = queueItemsInProgress
.Where(i => i.Url == url)
.ToList();
foreach (var queueItem in itemsInProgressToSet)
{
TrySetResult(queueItem.TaskCompletionSource, result);
queueItemsInProgress.Remove(queueItem);
}
}
private void MainLoop(object cancelationToken)
{
var token = (CancellationToken)cancelationToken;
while (!token.IsCancellationRequested)
{
HandleRequestTimeouts();
Thread.Sleep(2000);
}
}
private void HandleRequestTimeouts()
{
var discardRequestsStartedBefore = DateTime.Now.Add(-maxWaitTime);
HandlePendingRequestsTimeouts(discardRequestsStartedBefore);
HandleInProgressRequestsTimeouts(discardRequestsStartedBefore);
}
private void HandlePendingRequestsTimeouts(DateTime discardRequestsStartedBefore)
{
pendingQueue.TryPeek(out var queueItem);
while (queueItem != null && queueItem.StartTime < discardRequestsStartedBefore)
{
TrySetTimeoutException(queueItem.TaskCompletionSource);
pendingQueue.TryDequeue(out _);
pendingQueue.TryPeek(out queueItem);
}
}
private void HandleInProgressRequestsTimeouts(DateTime discardRequestsStartedBefore)
{
var itemsInProgressToDiscard = queueItemsInProgress
.Where(i => i.StartTime < discardRequestsStartedBefore)
.ToList();
foreach (var item in itemsInProgressToDiscard)
{
TrySetTimeoutException(item.TaskCompletionSource);
queueItemsInProgress.Remove(item);
}
}
private void TrySetTimeoutException(TaskCompletionSource<string> taskCompletionSource)
{
var exception = new TimeoutException("Timeout expired");
Task.Run(() => taskCompletionSource.TrySetException(exception));
}
private void TrySetResult(TaskCompletionSource<string> taskCompletionSource, string result)
{
Task.Run(() => taskCompletionSource.TrySetResult(result));
}
public void Dispose()
{
mainLoopCancellationTokenSource.Cancel();
}
private class QueueItem
{
public string Url { get; init; }
public string? WaitSelector { get; init; }
public string? ClickSelector { get; set; }
public DateTime StartTime { get; init; }
public TaskCompletionSource<string> TaskCompletionSource { get; init; }
}
}Перейдем к клиентской части. Документацию по разработке расширений можно найти здесь.
Для расширения потребуется файл манифеста. Там нет ничего интересного, описание расширения, запрос разрешений, ссылки на иконки и так далее. Его спрячу под спойлер.
manifest.json
{
"name": "BrowserProxy",
"description": "Allows to bypass cloudflare checks",
"version": "1.0",
"manifest_version": 3,
"action": {
"default_title": "BrowserProxy"
},
"background": {
"service_worker": "background.js"
},
"permissions": [
"tabs",
"webNavigation",
"storage",
"scripting"
],
"host_permissions": [
"http://*/*",
"https://*/*"
],
"icons": {
"19": "icon19.png",
"38": "icon38.png",
"48": "icon48.png",
"128": "icon128.png"
}
}Перейдем к основному файлу, background.js. Он будет выполнять всю работу. У нас будет основной цикл, в котором мы будем обрабатывать текущее состояние. Давайте схематично накидаем его структуру.
(async function () {
async function handleTick(){
await ensureTabsOpen();
await handleOpenTabs();
await handleQueue();
}
async function ensureTabsOpen(){
// Проверить, что открыто необходимое количество вкладок,
// которые принадлежат расширению.
// Количество задается в настройках либо как переменная в коде.
// Открыть новые вкладки, если требуется
}
async function handleOpenTabs(){
var tabs = await getAvailableTabs();
for (var i = 0; i < tabs.length; i++){
await handleTabState(tabs[i]);
}
}
async function handleTabState(tab){
var hasResult = await checkIfHasResult(tab);
if (hasResult){
await returnResultToApi(tab);
await freeTab(tab);
return;
}
var shouldFree = checkIfShouldFree(tab.id);
if (shouldFree){
await freeTab(tab);
return;
}
await performClicks(tab);
}
async function performClicks(tab){
// Проверить, что на странице есть элементы,
// для которых нужно эмулировать нажатие мыши.
// Произвести нажатия для таких элементов.
}
function checkIfShouldFree(tabId){
// Проверить, что не истекло время, отведенное на загрузку страницы
}
async function freeTab(tab){
// Запомнить, что вкладка освободилась и может быть переиспользована.
}
async function checkIfHasResult(tab){
// Проверить, что на вкладке пройдены проверки
// и загружена запрашиваемая страница.
}
async function returnResultToApi(tab){
// Получить HTML код страницы.
// Отправить код страницы на сервер с помощью POST запроса
}
async function handleQueue(){
// Проверить, что есть свободные вкладки.
// Запросить для свободных вкладок новый адрес для загрузки.
// Открыть полученный адрес на свободной вкладке.
}
async function getAvailableTabs(){
// Вернуть список вкладок, принадлежащих расширению.
}
setInterval(handleTick, mainLoopIntervalMs);
})();Теперь можно реализовать методы в соответствии с тем, что мы задумали. Результат получился на две с лишним сотни строк, поэтому я спрячу его под спойлер.
background.js
(async function () {
var nextUrlApiAction = 'http://xx.xx.xx.xx/task';
var resultApiAction = 'http://xx.xx.xx.xx/result';
var tabsOpenedByExtensionIds = new Set();
var timeoutMs = 20000;
var maxExtensionTabs = 4;
var mainLoopIntervalMs = 2000;
var defaultWaitSelectors = [
'#id_captcha_frame_div',
'.botsPriceLink',
'#challenge-running',
'#challenge'];
var defaultClickSelectors = [
'#otv3_submit',
'#otv3 .button__orange:visible'];
var tabInfos = {};
async function handleTick(){
await ensureTabsOpen();
await handleOpenTabs();
await handleQueue();
}
async function ensureTabsOpen(){
await ensurePersistentTabOpen();
var tabs = await getAvailableTabs();
for (var i = tabs.length; i < maxExtensionTabs; i++){
var tab = await chrome.tabs.create({
url: 'about:blank',
active: false
});
tabsOpenedByExtensionIds.add(tab.id);
}
}
async function ensurePersistentTabOpen(){
var url = chrome.runtime.getURL("persistent.html")
var tabs = await chrome.tabs.query({});
var persistentTab = tabs.find(t => t.url == url);
if (!persistentTab){
persistentTab = await chrome.tabs.create({
url: url,
active: false
});
}
return persistentTab;
}
async function handleOpenTabs(){
var tabs = await getAvailableTabs();
for (var i = 0; i < tabs.length; i++){
await handleTabState(tabs[i]);
}
}
async function handleTabState(tab){
var hasResult = await checkIfHasResult(tab);
if (hasResult){
await returnResultToApi(tab);
await freeTab(tab);
return;
}
var shouldFree = checkIfShouldFree(tab.id);
if (shouldFree){
await freeTab(tab);
return;
}
await performClicks(tab);
}
async function performClicks(tab){
if (tab.status != 'complete'){
return;
}
var tabInfo = tabInfos[tab.id];
if (!tabInfo){
return false;
}
var currentClickSelectors = tabInfo.clickSelector
? [tabInfo.clickSelector]
: defaultClickSelectors;
for (var i = 0; i < defaultClickSelectors.length; i++){
var selector = defaultClickSelectors[i];
await performClicksBySelector(tab.id, selector);
}
}
function checkIfShouldFree(tabId){
var tabInfo = tabInfos[tabId];
if (!tabInfo){
return false;
}
var now = new Date();
var waitTimeMs = now - tabInfo.startTime;
return waitTimeMs > timeoutMs;
}
async function freeTab(tab){
await chrome.tabs.update(tab.id, { url: 'about:blank' });
delete tabInfos[tab.id];
}
async function checkIfHasResult(tab){
if (tab.status != 'complete'){
return false;
}
var tabInfo = tabInfos[tab.id];
if (!tabInfo){
return false;
}
var hasResult = true;
var currentWaitSelectors = tabInfo.waitSelector
? [tabInfo.waitSelector]
: defaultWaitSelectors;
var currentClickSelectors = tabInfo.clickSelector
? [tabInfo.clickSelector]
: defaultClickSelectors;
var noResultSelectors = [...new Set([...currentWaitSelectors, ...currentClickSelectors])];
for (var i = 0; (i < noResultSelectors.length) && hasResult; i++){
var selector = noResultSelectors[i];
var html = await getSourceBySelector(tab.id, selector);
if (html){
hasResult = false;
}
}
return hasResult;
}
async function returnResultToApi(tab){
var html = await getSourceBySelector(tab.id, 'html');
var tabInfo = tabInfos[tab.id];
if (!tabInfo){
return;
}
var originalUrl = tabInfo.originalUrl;
await fetch(resultApiAction + '?url=' + encodeUriComponent(originalUrl),
{
method: 'POST',
headers: {
'Content-Type': 'text/html;charset=utf-8'
},
body: html
});
}
async function handleQueue(){
var tabs = await getAvailableTabs();
var continueTabsHandling = true;
for (var i = 0; (i < tabs.length) && continueTabsHandling; i++){
var tab = tabs[i];
var tabInfo = tabInfos[tab.id];
if (!tabInfo){
continueTabsHandling = await loadNextUrlOnTab(tab.id);
}
}
}
async function loadNextUrlOnTab(tabId)
{
var response = await fetch(nextUrlApiAction);
if (response.status == 200){
var urlToLoad = await response.json();
if (urlToLoad){
chrome.tabs.update(tabId, { url: urlToLoad.url });
tabInfos[tabId] = {
startTime: new Date(),
originalUrl: urlToLoad.url,
waitSelector: urlToLoad.waitSelector
};
return true;
}
}
return false;
}
async function getAvailableTabs(){
var tabs = await chrome.tabs.query({});
availableTabs = tabs.filter(t => tabsOpenedByExtensionIds.has(t.id));
return availableTabs;
}
function getSourceBySelectorInjected(selector){
var element = document.querySelector(selector);
return element ? element.outerHTML : null;
}
async function getSourceBySelector(tabId, selector){
try {
var source = await chrome.scripting.executeScript({
target: {tabId: tabId},
func: getSourceBySelectorInjected,
args: [selector]
});
return source[0].result;
} catch (e) {}
}
function performClicksBySelectorInjected(selector){
var elements = [...document.querySelectorAll('#otv3 .button__orange')]
.filter(e => !!(e.offsetWidth || e.offsetHeight || e.getClientRects().length));
for (var i = 0; i < elements.length; i++){
elements[i].click();
}
}
async function performClicksBySelector(tabId, selector){
try {
await chrome.scripting.executeScript({
target: {tabId: tabId},
func: performClicksBySelectorInjected,
args: [selector]
});
} catch (e) {}
}
function handleConnection(port){
if (port.name === 'keepAlive') {
setTimeout(() => port.disconnect(), 250e3);
port.onDisconnect.addListener(ensurePersistentTabOpen);
}
}
chrome.runtime.onConnect.addListener(handleConnection);
setInterval(handleTick, mainLoopIntervalMs);
})();Думаю, стоит указать на еще один момент. Не весь код из файла предназначен для непосредственно загрузки страниц. Дело в том, что Chrome прекращает выполнение кода расширения через примерно пять минут. Для того, чтобы обойти это ограничение, мы открываем специально сформированную вкладку и устанавливаем с ней соединение. Соединение тоже живет не более пяти минут, поэтому мы рвем соединение и устанавливаем новое примерно раз в четыре минуты.
За этот процесс отвечает код:
async function ensurePersistentTabOpen(){
var url = chrome.runtime.getURL("persistent.html")
var tabs = await chrome.tabs.query({});
var persistentTab = tabs.find(t => t.url == url);
if (!persistentTab){
persistentTab = await chrome.tabs.create({
url: url,
active: false
});
}
return persistentTab;
}
function handleConnection(port){
if (port.name === 'keepAlive') {
setTimeout(() => port.disconnect(), 250e3);
port.onDisconnect.addListener(ensurePersistentTabOpen);
}
}
chrome.runtime.onConnect.addListener(handleConnection);Файл persistent.html выглядит следующим образом:
<!doctype html>
<html>
<head>
<title>Cloudflare bypass</title>
</head>
<body>
Don't close this tab. It is used to perform websites parsing.
</body>
<script src="persistent.js"/>
</html>Этот файл ссылается на persistent.js. Его содержимое:
(function connect() {
chrome.runtime.connect({name: 'keepAlive'})
.onDisconnect.addListener(connect);
})();Думаю, на этом рассмотрение кода можно закончить. Код доступен на GitHub.
Настраиваем окружение
Ниже пойдет речь о настройке окружения в Линуксе. Я, к сожалению, не эксперт в этом вопросе, поэтому текст ниже стоит воспринимать как мой личный опыт, а не как пошаговую инструкцию, как оптимальным способом получить оптимальную конфигурацию.
Теперь встает вопрос хостинга. Серверная часть нашего решения сможет работать на почти любом виртуальном хостинге, одного гигабайта оперативной памяти будет достаточно. Можно использовать Nginx как reverse proxy, но в данном случае я бы не стал, у нас нет типичных для него задач, Kestrel и сам справится.
Файл с конфигурацией сервиса для systemd может выглядеть примерно так:
[Unit]
Description=Browser proxy web service
[Service]
ExecStart=/usr/local/browser-proxy/BrowserProxy --urls "http://0.0.0.0:80"
WorkingDirectory=/usr/local/browser-proxy/
User=user
Restart=on-failure
SyslogIdentifier=browser-proxy
PrivateTmp=true
[Install]
WantedBy=multi-user.target Что касается окружения для запуска браузера, то потребуется больше памяти, можно начать с 3-4 гигабайт.
Итак, мы создали новую виртуальную машину с установленным Линуксом у какого-нибудь хостинг-провайдера. Установить Хром сразу не получится. Насколько я смог разобраться, проще всего сначала установить какое-нибудь окружение рабочего стола. Я установил XFCE.
sudo apt install xfce4Теперь можно попробовать установить Хром.
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.debВ процессе установки увидим, что не хватает некоторых пакетов. Мне помогла команда
sudo apt --fix-broken installМожно запускать. Пишем google-chrome в консоли и получаем ошибку
Missing X server or $DISPLAYМне удалось найти, что виртуальный монитор можно сделать при помощи утилиты Xvfb.
sudo apt install xvfbПосле этого мне удалось запустить Хром.
Xvfb :10 -ac -screen 0 1366x768x24 &
export DISPLAY=:10
google-chromeЗапустить хром с загруженным расширением можно при помощи следующего ключа:
google-chrome --load-extension=/usr/local/browser-proxy-extension/chrome/Можем посмотреть, что происходит на нашем виртуальном экране:
xwd -display :10 -user -out /tmp/pic.xwdКак сделать так, чтобы Хром запускался при старте системы и перезапускался в случае падения, я оставлю за рамками статьи. Я использовал systemd сервис.
Использование совместно с прокси-серверами
К сожалению или к счастью, у меня нет такого опыта. В рамках нашей задачи — а мы собираем информацию о характеристиках товаров — мы не делаем много запросов к сайтам, которые парсим, и по IP нас пока не банили.
Заключение
Разобрались, как работает детектирование роботов.
Разработали сервер и браузерное расширение для обхода блокировок. Ссылка на GitHub.
Запустили браузер в графическом режиме из консоли Линукса.
Комментарии (10)


kale
17.01.2023 10:41+1На linux можно обойтись без X-ов и танцев с фейковым монитором просто используя chrome-headless https://chromium.googlesource.com/chromium/src/+/lkgr/headless/README.md

Razoomnick Автор
17.01.2023 11:12Спасибо за ссылку.
Возможно, я делаю что-то не так, но проверку cloudflare такой метод у меня не проходит.


sden77
17.01.2023 13:54Насколько я помню , там по умолчанию в headless режиме устанавливается свойство
navigator.webdriver, которое и определяют системы защиты от ботовRazoomnick Автор
17.01.2023 14:28Возможно, установить этот параметр в false будет достаточно для headless режима. А вообще, есть такая возможность? Протестирую, когда будет возможность.
Когда я исследовал работу Selenium, то дело было не в этом, там в контексте страницы появляется глобальная переменная вида "cdc_*", и требуется патч для драйвера.


alex1478
17.01.2023 19:18Версия, которая, теоретически, не детектируется, не определяется при
первом посещении сайта запущенным браузером, но детектируется со второго
посещения. Почему — непонятно. Браузер нужно постоянно перезапускать.Я видел пример такой реализации. Там код вебдрайвера загружался при первом обращении к его api, а не сразу при старте браузера. На самом деле самое эффективное прохождение cloudflare
t38c3j
Субъективно, но по опыту ничего проще чем puppeteer + extra-plugin-stealth не нашел, очень редко срабатывали защиты, и то они срабатывали скорее из-за нетипичного поведения, для быстрого прототипирования самое то, можно сосредоточиться на результате и не думать о палках в колесах
Razoomnick Автор
Думаю, да, в определенных ситуациях это и есть оптимальное решение.
Я puppeteer не пробовал, но попробовал Selenium, насколько я знаю, у них примерно одинаковый принцип работы. Добиться стабильной работы в связке с C# не получилось, и я пошел делать расширение. Если бы получилось — остановился бы на нем.
Elementirex
В puppeteer имеется аналог selenoid или selenium hub?