Привет, Хабр!
Сегодня я расскажу как с помощью DevOps-практик не только не помочь, но и навредить проекту.
DevOps родился для того, чтобы команды разработки и поддержки работали эффективно и слаженно. Но иногда использование его практик может привести к реальным провалам.
Зачем и кому нужен DevOps
Для начала немного истории. Самый первый компьютер в мире появился в 1936 году, его создал Алан Тьюринг. Тогда был ровно один компьютер и ровно один программист. Вычислительные машины существовали и до этого, но Алан Тьюринг сконструировал первый электронный компьютер, который похож на компьютер в нашем понимании, и написал первую строчку кода, который мы распознаём как код.
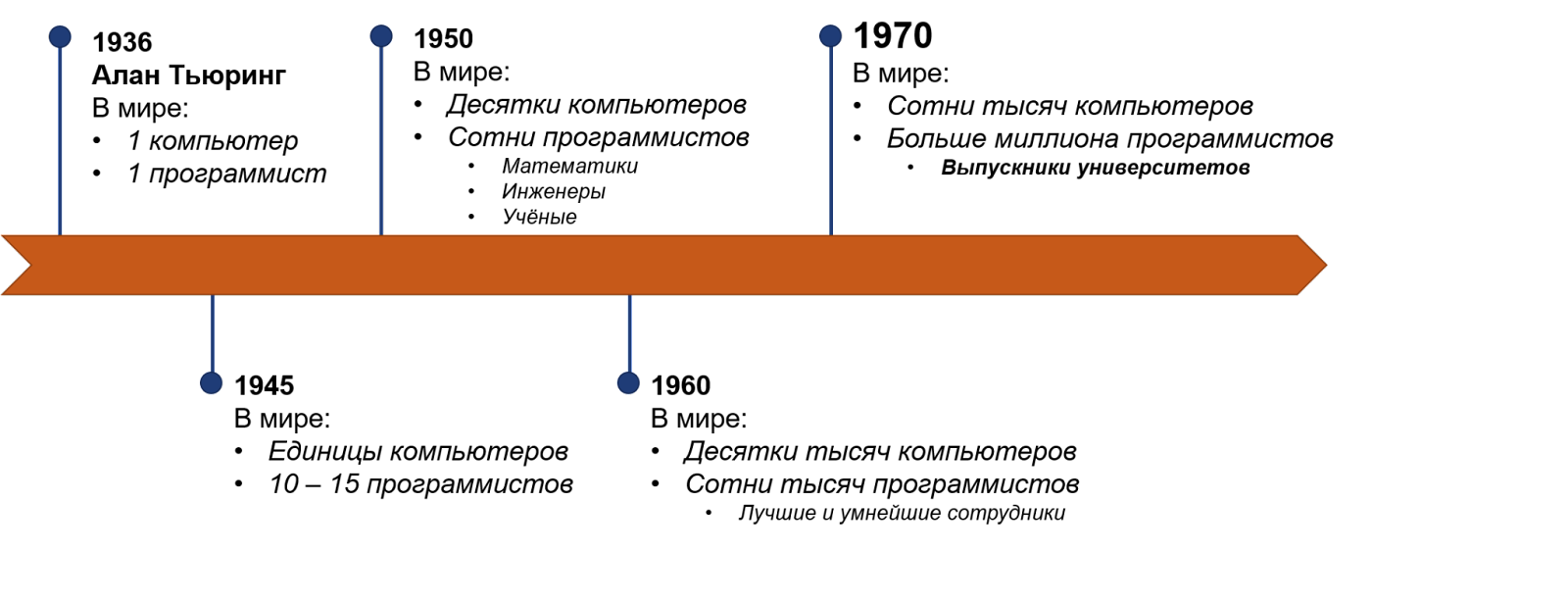
В течение следующих 30 лет количество компьютеров и программистов увеличится от единиц до десятков и сотен тысяч. После войны программистами стали люди, которые разрабатывали, собирали и чинили компьютеры. В 1950-х к ним присоединились учёные, математики, инженеры. В этот самый момент, примерно в 1953 году, появился первый в мире язык программирования — Fortran. И тогда же появилось то, против чего пытается бороться DevOps. В 1960-х компьютеры стали дешёвыми и компактными, а программистами стали не учёные и математики, а опытные сотрудники без специального образования, которым руководство могло доверить управление огромными дорогими машинами.
В 1970-х годах программистов было уже более миллиона, а необходимость в них всё росла и росла. К тому моменту университеты начали выпускать первых специалистов — молодых неопытных ребят. И вот ровно в этот момент что-то пошло не так.
До 70-х годов программисты были дисциплинированными профессионалами. Им не нужен был менеджмент — они знали, как распределить своё время, как работать друг с другом, как общаться с разными отделами. Они понимали, что такое бизнес, сроки, обещания, расписания. Они знали, что взять в работу сейчас, а что оставить на потом. Это были высококлассные опытные специалисты. Они творили чудеса: придумали IBM 360 Virtual Memory OS, отправили аппарат на Луну, изобрели структурное, функциональное и объектно-ориентированное программирование. Они придумали Fortran, Cobol, Algol, Lisp, Unix. Оказывается, они даже работали в чём-то, что напоминает современный Agile.
После 70-х программистами стали молодые люди, которые совсем недавно вышли из университетов. Чаще всего — гики, которые интересовались компьютерами. Эти неопытные ребята, которые не понимали необходимости расписания, ответственности и дисциплины, нуждались в менеджменте сверху, чтобы компании получили от них то, чего хотят. Тогда родился Waterfall и руководил программистами ещё десятки лет. Всё потому, что вокруг не было достаточного количества учителей, которые могли объяснить, как нужно работать, и это положение сохраняется до сих пор. Проработав 20 лет и став опытными профессионалами, бывшие молодые ребята поняли, что в индустрии что-то не так, что программистов превращают в простых работников ручного труда, которые не понимают бизнес и не владеют критическим мышлением. Они просто закрывают свои задачи и делают то, что велит менеджмент. Инженеров, которые привыкли быть в роли интеллектуальных творцов, такой подход перестал устраивать.
Agile и что с ним случилось
Несколько таких ребят в 1995 году собрались и написали Agile Manifesto, в котором изначально было всего четыре пункта. Главной целью было исправить разрыв между бизнесом и программистами. Они хотели донести: мы профессионалы, мы должны быть ближе к бизнесу, нам не нужны Waterfall-ритуалы.
Вот эти пункты:

И вот Agile, родившийся в инженерной среде, чтобы помочь таким же инженерам, превратился в нечто другое. Сейчас это на 90% менеджерская история. Если посмотреть темы докладов любых Agile-конференций, вы не найдёте в них технических тем — только менеджерские истории о том, как руководить командой, и тому подобное. Почему мы как индустрия не смогли освоить и провалили Agile? Почему вместо нас им занимаются наши менеджеры? Наверное, мы были недостаточно зрелыми для того, чтобы впитать в себя набор практик и дисциплин, которые нам предлагали. Техническая экспертиза ушла в тень, и верх взяла сфера экспертизы менеджеров: ритуалы, практики, процессы, за которыми можно следить. Как инженерное движение Agile провалился.
DevOps и что с ним случилось
Проходит ещё несколько лет, и в 2008–2009 году возникает культура DevOps — она стала идеей, движением инженеров, целью которого было вылечить разрыв между операторами систем и программистами при создании и обновлении программных продуктов. Это методология, которая эффективно решает проблемы во взаимодействии команд разработки и эксплуатации за счёт автоматизации и интеграции усилий обеих сторон. На практике участников больше: вовлечены специалисты по безопасности, специалисты по платформам и инфраструктуре, нормативным требованиям и другие. Это движение создали те, кто настрадался, вырос в профессионалов и прошёл большой путь.
Что же происходит с DevOps сейчас? К сожалению, то же самое, что случилось в своё время с Agile: практики и инструменты берут верх. Появились DevOps-инженеры, DevOps-практики стали продавать и покупать, пробовать внедрять везде. И похоже, что мы с вами проваливаем движение, в очередной раз натыкаясь на прежние грабли. Мы опять не можем освоить дисциплину, которую нам предлагают. Мы опять скатываемся в практики, которые понятны в первую очередь менеджерам. DevOps стал галочкой в контрактах, в презентациях проектов заказчикам. Посмотрите на сегодняшних DevOps-инженеров: они берут то, что сделали программисты, и критикуют это вместо того, чтобы работать, сообща создавая качественные продукты. К чему это может привести, я сейчас и расскажу. Надеюсь, что на примерах провалов мы сможем в чём-то разобраться.
Провалы
А теперь время занимательных историй.
Infrastructure as Code
Первая история — про инфраструктуру как код.
Дано: У нас новый проект, мы двигаемся в облако. Делаем Infrastructure as Code и в 80% случаев используем для этого Terraform.
Действия: Взяли в руки Terraform, посмотрели документацию и пару видео, начали делать. Всё начиналось хорошо. Проекту нужно было одно окружение для программиста Васи — оно состояло из трёх виртуальных машин и сетей между ними. Это всё легко уместилось в один файлик Terraform. Потом пришёл программист Витя, которому понадобилось окружение, а также общее окружение, в котором будет постоянно деплоиться мастер-ветка нашего приложения.
Что сделали Terraform-гуру? Взяли изначальный файл и скопировали его, поменяли внутри имена: всё работает, все довольны. Проект растёт — появляется ещё программист Вова и команда QA, которым нужно отдельное окружение. Окружение становится сложнее: в нём появляются хранилища, балансировщики нагрузки и другие нетривиальные штуки. Управлять всем этим становится неудобно. К счастью, команда вовремя прочитала про Terraform-модули, отрефакторила всё в модули и создала все окружения, используя общие модули и убрав 80% копипасты. Всё здорово, всё замечательно. Пока.
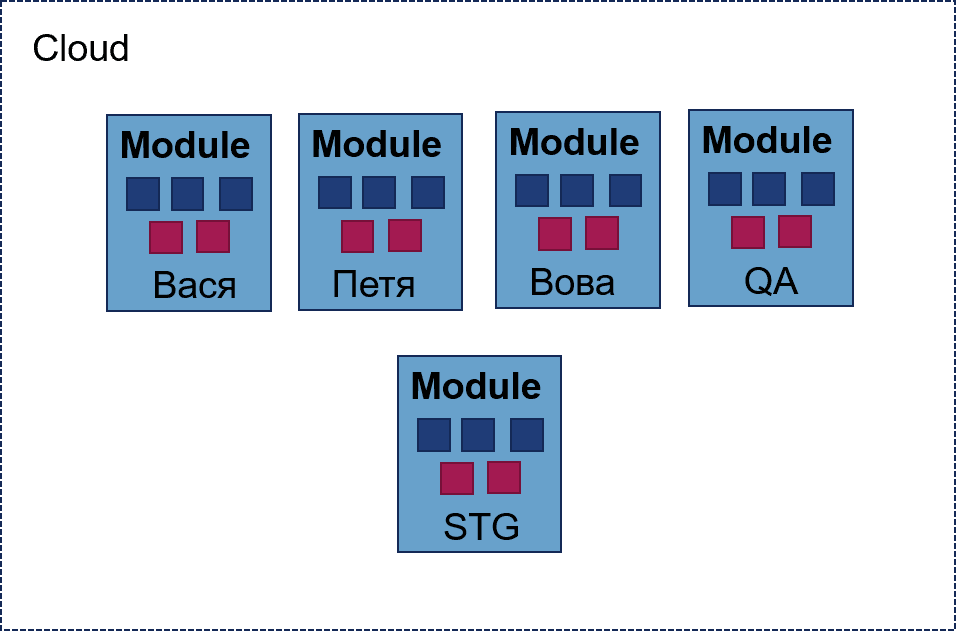
Возникает момент, когда нужно срочно клонировать виртуалку с QA-окружения на окружение Пети, чтобы срочно починить дефект. Потому что мы там на что-то закоммитились. Ребята, которые делают Terraform, разводят руками, говорят, что не знают, как клонировать виртуалку через Terraform, и берут пару дней, чтобы подумать. Но у нас этой пары дней нет.
Старший программист с боем забирает админский пароль от облака, за 30 секунд накликивает себе клон виртуальной машины, и всё едет. И в этот момент в команде возникает некий инсайт: они понимают, что Terraform не особо-то и нужен. В сложных случаях, когда команда Terraform не на связи, можно что-то сделать самим.
Последствия: Возникает дырявая история, когда кто-то чего-то не так наделал руками. В один момент у нас появляется продакшн-окружение, которое становится таким же дырявым. У нас есть модуль, его попытались привести к готовому виду, задеплоили, там что-то не заработало. Какой-нибудь ответственный человек, который заводил этот продакшн, зашёл в облако, поменял настройки, добавил что-то и, не дай бог, соединил каким-нибудь форвардингом с QA-окружением. И у нас был такой продакшн. Он работал достаточно долго, проект приносил деньги, и все были довольны.
До тех пор, пока не пришёл новый клиент. Он говорит: «У вас такой классный продукт. Я уже купил подписку, но меня не устраивает время отклика. Вы можете сделать нам инфраструктуру в Европе? Мне очень надо».
Что мы сделали? Взяли Terraform, поменяли одну переменную, накатили на соседний регион, установили окружение через наш суперавтоматизированный пайплайн, а оно не работает. Стали разбираться, почему не работает, сравнивать — и всё начало проясняться. Никто не знал, что у одного младшего тестировщика есть пароль от облака и он что-то менял в нём.

В итоге: Конечно же, окружение в Европе сделали, но через долгое время и без Terraform. Взяли CloudFormation, сгрузили в него инфраструктуру, чуть-чуть поправили файлы вручную и задеплоили в соседний регион. Ещё раз: мы взяли Terraform и вместо того, чтобы сделать что-то хорошее для проекта, сделали что-то плохое. Этот Terraform всем мешал, потому что не давал сделать то, что нужно. Плюс мы потратили много времени в никуда.
Возможное решение: Можно ли было что-то сделать иначе? Конечно.
Прежде чем брать какой-то инструмент, надо понять, какие проблемы он решает. Terraform — это код, и вести его нужно было как взрослый код. Там должны были быть пул-реквесты, CI, контроль, каждую ночь нужно было проверять соответствие облака коду Terraform.
Нужно было ввести правила работы с Terraform и либо рассказать о них и привить их, либо навязать дисциплину команде. Самое главное, что Terraform — это не единственный инструмент Infrastructure as Code, который вы должны применять. Почему у ребят не было политик? Почему они допустили ситуации, когда кто-то может прийти в облако, а они об этом не узнают? Infrastructure as Сode должен включать в себя не только ресурсы, но и политики, которые вы устанавливаете. Да, вы не сможете своими политиками выстроить защиту, как в Форт-Ноксе. Но вы можете поставить высокий деревянный забор, через который сложно будет перепрыгнуть. А если кто-то попробует, вы об этом узнаете.
Kubernetes
Следующая история — про Kubernetes.
Дано: Нужно вывести легаси-приложение в облако. Команда изучила легаси, поговорила с его архитекторами, программистами, которые его поддерживают: приложение работает на устаревшем железе, его нужно перенести на x86 и на Linux. Оказалось, что это клиент-серверное веб-приложение, которое разбито на сервисы, и они такие маленькие, что можно назвать их микросервисами. Плюс там используется компонент, который масштабирует эти сервисы в зависимости от нагрузки.

Любой здравомыслящий DevOps-инженер скажет, что это нужно деплоить на Kubernetes.
Действия: По ходу проекта мы столкнулись с очень серьёзными проблемами. Сервисы были очень маленькими, занимали меньше 5 мегабайт. Но для того, чтобы работать, каждому нужно было 6Gb рантайм-зависимостей. Эти 6 гигов собирались очень долго: около четырёх–пяти часов на чистую сборку (в зависимости от фазы Луны). В итоге получались огромные гигантские образы (images), которые надо было где-то хранить. Время сборки стало очень длинным, появились огромные проблемы с масштабируемостью. Представьте себе: у вас 10 образов по 6 Гб, и Kubernetes в облаке вам добавляет ещё один сервер в кластер, чтобы туда выкатить дополнительную реплику сервиса. И вот все образы начинают туда выкачиваться ещё минут пять, а пользователи сидят и ждут.
Последствия: Нужно было следить за тем, чтобы все образы сохранялись на всех нодах, понять, как иметь какое-то количество горячих нод без рабочей нагрузки. И вообще полностью зафиксировать количество реплик сервисов для того, чтобы приложение поддерживало максимальную нагрузку на продакшн, и всё. Нужно было отказаться от масштабирования по pay-as-you-go модели облака и хранить где-то огромные образы. Мы добавили себе огромное количество головняка.
Позже выяснилось, что приложение у нас TСP/IP-based и мы потеряли половину плюшек, которые нам Kubernetes предоставляет просто из коробки. Мы не можем сделать url-based-роутинг, не можем положить рядом две версии приложения на разных ссылках. Мы не можем сделать header-based-роутинг, не можем пустить тестировщиков в соседнюю версию сервиса. Мы не можем себе позволить быстро и легко сделать blue/green-деплоймент или rollout-деплоймент в Kubernetes, потому что большая часть готовых фишек для этого заточена на http-трафик.
В итоге: Мы получили кластер из 10 дорогих нод, кучу обвязки вокруг, много необоснованных расходов. Никто не доволен, да ещё и мы не можем апдейтить приложение быстро.
Возможное решение: Можно ли было избежать этой ситуации? Да, можно. Надо было выбросить Kubernetes, забыть про контейнеры в том виде, в котором он их использует, прибегнуть к другой технологии изоляции процессов — какому-нибудь application-server — и задеплоить приложение просто в Linux. И вместо десяти нод с кучей обвязки мы бы получили три сервера и один балансировщик нагрузки. Вот такое тупое, но рабочее и дешёвое решение проблемы. Повторюсь, нужно понимать, что такое Kubernetes и для каких приложений он вам подходит. Надо разобраться в деталях: что за приложение? как оно будет работать? кто его будет писать? Это цена опыта. Ребята, которые работают и работали в этом проекте, в следующий раз не полезут сразу в Kubernetes. Я рекомендую вам почитать о нём побольше. Если кто-то ещё не работает и просто прошёл курсы, или планирует применить это ПО в новом проекте, пожалуйста, поймите точно, для каких приложений он подходит и какие задачи он решает. Может быть, у вас вообще нет таких проблем.
CI/CD/CT
Последняя история — про CI/CD/CT.
Дано: Есть существующий Big Data проект, который написали молодые ребята без поддержки учителей. Они не использовали никакую систему контроля версий — приложение лежит просто в файлах, в бакетах в облаке.
Когда им нужно проверить какую-то гипотезу, они делают полную копию приложения, меняют там код, из этой копии запускают процессинг. Если всё сработало, гипотеза успешная, то они мёржат это обратно в основную копию, и этот мёрж у них занимает два дня, ведь мёрджиться хотят многие. Вдобавок они выбрали ту технологию, которая у всех на слуху, Spark, вместо той, которая могла бы поддержать требования. И в итоге это всё работает шесть часов вместо требуемых бизнесом 20 минут.
Действия: наступает момент, когда нужно проект показывать клиенту — достаточно серьёзной технологической компании, которая этот бардак распознает и останется недовольна. Тогда к проекту подключаются ещё люди — так называемая «команда А». У них есть два месяца на то, чтобы всё взять и привести к виду, который привыкли видеть клиенты: внедрить контроль версий, починить процессы, сделать CI/CD/CT и починить код, чтобы время работы было оптимальным. Код быстро починили, программисты знают свою работу.
Последствия: А вот с CI произошла очень интересная история. Внедрили гит, потом стали делать Continuous Integration. Обычно Continuous Integration не делают trunk-based, — обычно делают на пул-реквестах: пул-реквесту делают премёрдж-чеки, а после прохождения всех стадий проверки код вливают в основную ветку. Когда приступили к этому этапу, выяснилось, что в проекте ровно один тест, который идёт те самые шесть часов, и других тестов нет, и сделать их невозможно. Приложение быстро оптимизировали, время прохождения сократилось до четырёх часов, что, конечно, тоже очень много для пул-реквеста. Самое главное, что тесты почти сразу начали падать не по причинам изменения кода, а по независимым причинам. Пробовали привлекать QA, фиксировать входящий набор данных и много чего ещё — всё равно стабилизировать тест не удалось. В общем, невозможно было автоматически сделать критерии успешности прохождения теста. И вот у нас пул-реквесты висят по четыре часа, а нужного результата нет. Тогда решили выбросить тестирование пул-реквестов вообще и подключить туда хотя бы линтер. Его включили — он показывал, куда обратить внимание, и эти баги чинили.
Но в какой-то момент линтер просто сломался. Как это случилось: внесли изменение, в результате которого у линтера внутри возникала бесконечная рекурсия, и он просто выпадал с километровым стектрейсом. Пробовали это починить, отвлекали разработчиков. Починить не получилось. В итоге линтер как был красный, так и остался. Что произошло? Никто не стал смотреть в CI, потому что он постоянно был красным. Помимо этого стектрейса, который обвалил наши проверки, зачастую возникали и реальные дефекты, которые потом превращались в продакшн-дефекты, но никто этого не замечал, хотя линтер их находил. Отключать тогда не стали, думали, что починим — так и не починили. В итоге список замёрженных пул-реквестов выглядел ужастно - все билды провалены.
Дальше дело встало за выкаткой кода на окружение. Деплой приложения был предельно тривиален — просто перекладывание файлов из гита в облако, даже никакой конфигурации не нужно было делать. Конфигурация содержалась в данных. Такой Continuous Deployment автоматизировать очень просто, что и было сделано. Continuous Testing сначала шёл в пул-реквестах, а потом стал ночным. С ним было то же самое, что и с тестированием внутри пул-реквестов. Нельзя было просто взять и запустить тесты, а потом понять, успешно они прошли или нет. Во-первых, они шли долго, во-вторых, результаты нужно было анализировать вручную.
В итоге: Мы сделали очень много работы, но не достигли никаких положительных результатов. Наоборот: мы мешали другим людям работать.
Возможное решение: Узнать, что такое CI и для чего он нужен, прежде чем делать Continuous Integration под копирку. Вспомните, как обычно мы делаем CI? У нас есть заготовленные пайплайны, появляется новый проект — мы берём эти пайплайны и адаптируем, говорим: я DevOps-инженер, свою работу сделал, пользуйтесь. В этой ситуации этого не стоило делать, потому что не было проблемы, которую решает такой CI. Были другие проблемы.
Что требовалось в этом проекте? Найти места, где команде действительно нужна помощь, даже если вам прямо говорят: иди и делай CI. В данном проекте не хватало системы запуска DEV-прогонов в изолированном окружении. Разработчикам был нужен скрипт, который всё подготовит, скопирует данные, запустит приложение так, чтобы запуск не пересекался с запуском другого разработчика. Желательно, чтобы эта функция запускалась с лэптопа и не надо было куда-то коммитить код, чтобы он там запустился (а потом упал). В итоге мы это сделали, надёргали кусков из нашего недо-CI, и работа пошла. Но то, что мы в итоге сделали, и то, что нас просили сделать изначально, — разные вещи.
Как не провалиться
Как не допустить подобных провалов? Кто-то может сказать: это не провалы, а реальная рабочая атмосфера. Решайте сами, но я такую атмосферу не люблю. Как показала практика, самым простым и верным шагом будет как следует изучить предлагаемые решения на берегу. Необходимо понимать функциональность инструментов со всех сторон, разобраться в их использовании на конкретном проекте. Возможно, то, что нам говорит опыт или подсказывает статистика применения, неверно. Постройте внутри команды дисциплину, обсудите правила игры.
Посмотрите вокруг себя, поговорите с другими людьми, попробуйте работать сообща внутри проекта с разработчиками и сделайте так, чтобы всем было хорошо. Всем добра!
Комментарии (34)

0vercoming
21.10.2021 18:14+8Так сложилось что топ менеджмент периодически думает что внедрение систем CI\DI придаёт продукту "шика" просто указывая на то что инфраструктура приложения соответствует современным тенденциям, пряча за этим старую архитектуру приложения которая в текущих реалиях скорее соответствует прошлому веку, или разработка нового приложения идёт под эгидой "Мы напишем современное приложение в облаке на микросервисах" не подобрав людей с опытом этого.
В итоге как под копирку все последствия описанные в статье.
Ну я бы хотел отметить те факты что:
1 - ОПСы не ставят себе задачи, эти задачи ставит менеджмент и согласует с остальными отделами, как и все предложения от позиции DevOPS.
2 - Основная проблема которая нитью идёт через статью что люди занимающие позиции DevOPS не являются инженерами IT, ведь сваливая на ОПС-ов вину вы забываете про то что в процессе настройки и выбора инструментов инфраструктуры DevOPS-у надо учесть: Метод разработки, методики тестирования продукта, методики тестирования окружения, соответствие продукта с предоставляемыми сервисами окружения и их инструментами, учесть и соответственно знать путь развития компании и приложения, обслуживания приложения сторонними лицами или саппортами и прочее.
И тут вопрос: Ему эту инфу самому собирать или ему напишут? Недостающие решения по соответствию методики разработки сам примет? Предугадает ли он какие решения могут быть приняты в разработке продукта? Он ли должен рассказывать как правильно проводить тестирование продукта в окружениях? Должен ли убедиться понял ли программист написавший для AWS Lamda код как по факту работает Lambda? Анализ метрик, обработки данных, изменение инфрастуктуры в случае когда приложении обнаружился боттлнэк в неожиданном месте, и к примеру в том которое изменить без изменения общей архитектуры приложения невозможно? А кто виновен если боттлнэк в инфраструктуре которую требовала архитиктура приложения?3 - На выходе вы получите требования к сертифицированному DevOPS ((Cloud)Infrastructure engineer) позиции Sinor со стажем не менее пяти лет и минимум — два крупных проекта за спиной и ценником 6+ у.е. А судя по примерам то брали за 2к для галки по принципу - "Что такое CI\DI знаешь? Расскажи про виртуализацию, скрипты на чём пишешь ?".
Да, по итогу так и получаться что в фантик с названием DevOPS вложили все проблемы с менеджментом, разработкой, тестированием, обслуживанием и залили всё соусом - "Ну вы же ароматизируете процессы".
Вы привели очень хорошие примеры, но они скорее говорят о не профессиональном подходе к разработке продукта, неправильном коллективном решении возлагая всецело вину на позицию DevOPS, и конечно в ответ вы будите слышать от ОПС-ов критику.
А я прям гадал как же это всё изложить без мата - Спасибо за статью, атмосфера действительно не очень, помните что всегда есть выбор.devops_man Автор
21.10.2021 18:22Да, все верно.
И в первой части статьи я как раз пытался показать что тот подход что есть сейчас в индустрии - изначально провален, мы просто видим это в истории.
Все что нужно - это таки взять на себя ответственность и наконец стать самодостаточными командами, вместо того чтобы набирать девопсов по 6к которые "сами должны все понять" :)
Что до провалов - то это всего лишь иллюстрация того как не надо, и в них во всех в общем то проблема одна - нет коммуникации между "девопсами" и "разрабами". Еще раз хочу подчеркнуть что DevOps это про взаимоотношения людей в первую очередь.
У меня достаточное количество очень положительных кейсов, но читать о таком скучно как мне кажется, поэтому выбрали вот эти :)
vainkop
22.10.2021 02:04+1Все что нужно - это таки взять на себя ответственность и наконец стать самодостаточными командами, вместо того чтобы набирать девопсов по 6к которые "сами должны все понять" :)
Пожалуй не соглашусь с вами. Вы делаете акцент на 6к, а он должен быть на "Senior" DevOps. Это вот "Senior" подразумевает наличие опыта, в том числе в архитектуре, в том числе в планировании, в том числе в налаживании связей в команде и во многом другом, что позволило бы избежать ваших факапов. И нет самодостаточность команды и коллективная безответственность это не то, что помогает успешно реализовывать проекты подобные тем, что вы описали.

vitaly_il1
22.10.2021 13:13+2проблема одна - нет коммуникации между "девопсами" и "разрабами".
В общем-то DevOps и родился, чтобы это исправить.
devops_man Автор
22.10.2021 14:06Конечно!
Более того, в статье прямым текстом об этом говорится :)
И так же говорится о том что "DevOps инженер" не может вывести всю девопс тему на своих плечах :)

smarthomeblog
22.10.2021 12:25Есть и другая крайность - хотфиксы прямо на проде, гит - для галочки, миграции для ленивых - мы все руками поправим, новый сервер - не беда, поднимем руками даже без бумажки. Карго-культ конечно тоже добавляет проблем. А насчет менеджмента. По моему опыту ему абсолютно все равно, есть ли там CI/CD или нет, есть ли инфраструктура как код или нет, в докере все крутится или прямо на VPS. Ему главное, чтобы работало и деньги приносило.

ALexhha
22.10.2021 13:10А насчет менеджмента. По моему опыту ему абсолютно все равно, есть ли там CI/CD или нет, есть ли инфраструктура как код или нет, в докере все крутится или прямо на VPS
Если менеджменту абсолютно все равно, что происходит у него в компании, то все очень печально. И рано или поздно плохо закончится, имхо
Так и представляю разговор с CIO - так мы запускаем в docker/kubernetes или bare metal? И его ответ - да мне все равно, делайте как хотите :D
ALexhha
21.10.2021 20:19+1Возникает момент, когда нужно срочно клонировать виртуалку с QA-окружения на окружение Пети, чтобы срочно починить дефект. Потому что мы там на что-то закоммитились. Ребята, которые делают Terraform, разводят руками, говорят, что не знают, как клонировать виртуалку через Terraform, и берут пару дней, чтобы подумать. Но у нас этой пары дней нет.
так это вообще не задача tf, а то когда в руках молоток, все кажется гвоздями ))
Этот Terraform всем мешал, потому что не давал сделать то, что нужно
возможно вы просто не правильно его используете
devops_man Автор
21.10.2021 20:37Да, все верно!
В этом кейсе взяли terraform, сами не знали зачем и как его нужно готовить.
saboteur_kiev
22.10.2021 03:40+1Так а какое отношение DevOps и тем более DevOps инженеры имеют к тому, что вы взяли инструмент, которым не умеете пользоваться и сами себе все поломали, при этом ругая и девопсов и инструменты?

syakimov
21.10.2021 20:36+4Погоня за модными технологиями, как мне кажется, -- бич IT сейчас, потому что многое пытаются использовать только из-за хайпа и красивой презентации продажникам.

syakimov
21.10.2021 21:29Хотя есть и другая крайность, когда сидят на диком легаси, которое, вроде и работает, но тормозит развитие компании в целом

jurikolo
21.10.2021 22:29+4Мне кажется проблема не в DevOps как таковом, а в людях, кто решал задачи, либо самом проекте.
История 1: взяли терраформ, потом кто-то наговнякал руками, выкинули терраформ и переписали на CloudFormation
Вы один IaC заменили на другой, где решение проблемы-то? Не уверен, что проблема полностью осознана командой.
История 2: взяли монолит, раздробили без рефакторинга, залили в K8S и ужаснулись
Всё верно, нельзя просто взять и закинуть код в K8S. Если идёт проект миграции в облако, то либо делаете lift-and-shift, когда софт деплоится на схожие виртуалки в облаке, либо грамотный рефакторинг, а это целый проект.
История 3
Извините, не читал. Я, конечно, не знаю всех деталей, но планировать и обдумывать действия надо старательнее, чтобы не было таких ляпов.
devops_man Автор
22.10.2021 14:03Использование CloudFormation не преподносится как решение проблемы в статье. Тут лишь описание действий команды в сложившейся ситуации.
Возможные пути решения проблемы описаны в соответствующей секции.Можно. Но это трудный путь и не ко всем продуктам подходит. И уж точно решение не должно приниматься только "DevOps инженерами".
У меня на памяти была как минимум одна очень успешная со всех сторон миграция адового и очень развесистого легаси "как есть" в кубернетис.Извиняю.
Идея статьи - показать к чему приводит тупое следование за хайпом, модными технологиями и словами. Это не туториал и не гайд как решить вот такие проблемы :)
vainkop
22.10.2021 02:19+3Ребята, которые делают Terraform, разводят руками, говорят, что не знают, как клонировать виртуалку через Terraform, и берут пару дней, чтобы подумать. Но у нас этой пары дней нет.
Понимаю, что видимо кейс был сложнее, но как описали его вы, гугл не работал? :) https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/ami_from_instance
Конечно же, окружение в Европе сделали, но через долгое время и без Terraform. Взяли CloudFormation, сгрузили в него инфраструктуру, чуть-чуть поправили файлы вручную и задеплоили в соседний регион.
Один инструмент заменили на другой не осознав проблемы. Например, вам понадобится сделать что-то более менее сложное уже с CF, а вы и его толком скорее всего не знаете.
vitaly_il1
22.10.2021 13:09Да, я тоже не понял чем в этом случае CF лучше чем TF.
ALexhha
22.10.2021 13:29Да, я тоже не понял чем в этом случае CF лучше чем TF.
<sarcasm>перед руководством, все можно свалить на криворуких devops :D</sarcasm>
devops_man Автор
22.10.2021 13:51Нигде в статье не написано что CF лучше чем TF :)
Там лишь описано то как команда проекта решила задачу в сложившейся ситуации.
Никакой "замены" не произошло - все чем выгодно отличился CF от TF - это возможностью взять существующую инфраструктуру как есть и сделать из нее код который с некоторыми правками можно использовать для создания такой же инфраструктуры в другом регионе. Для Terraform такое тоже есть, но на момент событий инструменты не давали необходимого результата.
Более того, размышления насчет "решения проблемы" в этом кейсе есть в отдельной секции (Возможное решение)vainkop
22.10.2021 14:24У вас во всех вышеописанных кейсах по-моему одна проблема: недостаток опыта как в планировании, в архитектуре и т.д. Как будто с наскока что-то нагуглили и поехали внедрять.
Выбор использовать как вы называете "хайповые" или "легаси" решения тут вообще ни при чём. Имея опыт планирования, архитектуры и хороший уровень владения любым стеком и реализовали бы и на нём.
Но и новые "хайповые" решения появляются и становятся популярны не просто так: часто они реально более удобно, быстро, безопасно и т.д. решают задачи, которые конечно можно решить и легаси стеком, но менее удобно, медленнее, не так безопасно и т.п. Конечно многим хочется просто поиграться с новыми технологиями, но для начала серьёзного проекта изначально подключается адекватный специалист или группа специалистов, который как раз и решает какой стек использовать в том числе с учётом имеющегося в команде опыта.
devops_man Автор
22.10.2021 14:17Понимаю, что видимо кейс был сложнее, но как описали его вы, гугл не работал? :) https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/ami_from_instance
Насколько мне известно - снятие правильного ami с ес2 предполагает выполнение sysprep и отключение родительского ес2. Что не входило в планы.
На самом деле самый главный вопрос это который никто не задал:
"А зачем вообще вам клонировать виртуалку?" :)
Чего это там такого уникального что нельзя просто задеплоить/мигрировать/сгененрировать в других окружениях?
И если там действительно что то настолько уникальное что у виртуалки есть имя и ее все боятся трогать - то я даже не наю кого тут ругать :)
Совершенно очевидно что в этом проекте OPS не транслировал свою экспертизу в DEV и наоборот, поэтому получилось то что получилось.vainkop
22.10.2021 14:32Опытный DevOps на проекте когда к нему бы пришли с такой задачей естественно бы поставил под сомнение необходимость клонировать уникальную виртуалку.
Но если уже решили, что это нужно, то и решение для этого в терраформе существует и давно и известно как это правильно делать в тех или иных случаях. Но это известно тем, у кого есть серьёзный опыт работы с этим инструментом + хорошеньку умеет гуглить, потому что никто из нас не может знать всего . А тут условно говоря даже нагуглить доку, которая первая ссылка в гугле не смогли...

Bedal
22.10.2021 09:51-2Общая неграмотность втаскивает слова в неправильные ниши. Больше всего, наверно, от этого страдает «эпицентр» (да и «центр», который, наверно, вообще скоро исчезнет. Эпи- и только эпи!), а вот теперь и «карго-культ». Никакого отношения карго-культ к тому, о чём Вы пишете, не имеет же, печаль.
devops_man Автор
22.10.2021 14:19+1Я тут пишу про то к чему приводит бездумное применение инструментов техник и практик DevOps, в ожидании того что сам факт этого приведет к впечатляющим положительным результатам.
На мой взгляд, очень похоже на «карго-культ» :)vainkop
22.10.2021 14:40бездумное применение инструментов техник и практик DevOps
Нет вы не использовали "практики", а только некоторые инструменты, да и то плохо. DevOps это вообще не только практики и инструменты - это целая философия, как бы напыщенно это не звучало.
Проблема многих проектов, что они берут DevOps инструменты в отрыве от всего остального и думают, что у них уже DevOps, хотя это совершенно не так и потом жалуются, что DevOps у них "не сработал".
devops_man Автор
22.10.2021 14:43Все правильно.
А чем это отличается от того что написано в первой части статьи?vainkop
22.10.2021 15:32Сегодня я расскажу как с помощью DevOps-практик не только не помочь, но и навредить проекту.
...
Но иногда использование его практик может привести к реальным провалам.
Повторюсь: нет вы не использовали "практики", а только некоторые инструменты, да и то плохо.

HellWalk
22.10.2021 15:39+2Есть существующий Big Data проект, который написали молодые ребята без поддержки учителей. Они не использовали никакую систему контроля версий — приложение лежит просто в файлах, в бакетах в облаке.
Мы сделали очень много работы, но не достигли никаких положительных результатов. Наоборот: мы мешали другим людям работать.
Подозрительный кейс. CI/CD сильно упрощает разработку, и после него сложно работать на проектах, где его нет.
Подозреваю, что реальная ситуация была немного не такой, как подано в статье - мол были классные ребята, которые делали хороший проект без всех этих новомодных штук, а потом пришли нехорошие дяди и все испортили.
Чаще всего бывает так: начинается проект неопытными разработчиками, в спешке. Никаких тебе авто-тестов, красивого ООП, никакого CI/CD. Внезапно проект выстреливает, нагрузка вырастает тысячекратно, деньги начинают идти рекой - и бизнес хочет еще и больше.
И вдруг оказывается, что на костылях ехать дальше очень проблематично. И мне кажется, что именно в этот момент, в описанной истории, попытались внедрить CI/CD - пошли ошибки, и имено на CI/CD их свалили. Хотя в таких проектах (где даже git'а нет) - все рано или поздно превращается в комок легаси-костылей, которые как-то работают, но никто не понимает как.

WASD1
22.10.2021 18:13Есть единственный тест и он идёт 4 часа, разделить его нельзя, написать другие нельзя - по-моему достаточный признак для классификации проекта как "дендрофекальный DataScience".
ПС
Когда у нас были проблемы с большим тестом (разумеется до того проходило достаточно много небольших тестов, с не очень большой глубиной зависимостей) при не очень длинной очереди вливов) с - сделали асинхронное тестирование после пуша в мастер.
Мне даже как-то раз пришло пиьсмо счастье: ваш пул-реквест поломал длинный асинхронный тест, идите разбирайтесь.


RarogCmex
25.10.2021 23:11+1Похоже нужно написать статью "можно ли быть DevOps инженером на технологиях нулевых годов, т.е. без Docker'а, Kubernetes и прочих новомодных штук". Поскольку никто просто не понимает, что это такое.
Что характерно, я DevOps джуниор, и содержимое статьи для меня не новость. Я это ещё полгода назад понял.
К сожалению, многим компаниям по описаниям вакансий нужны сисадмины со знанием кубера.
XaBoK
Хорошие фейлы - бесценный опыт для компании. К следующему клиенту идут в обход известных грабель.