
Представим конечный автомат (КА), который традиционно состоит из триггеров, хранящих его состояние, и логики, которая эти триггера связывает и может состояние КА изменить. Сотояние триггеров при необходимости меняется по фронту тактового сигнала.
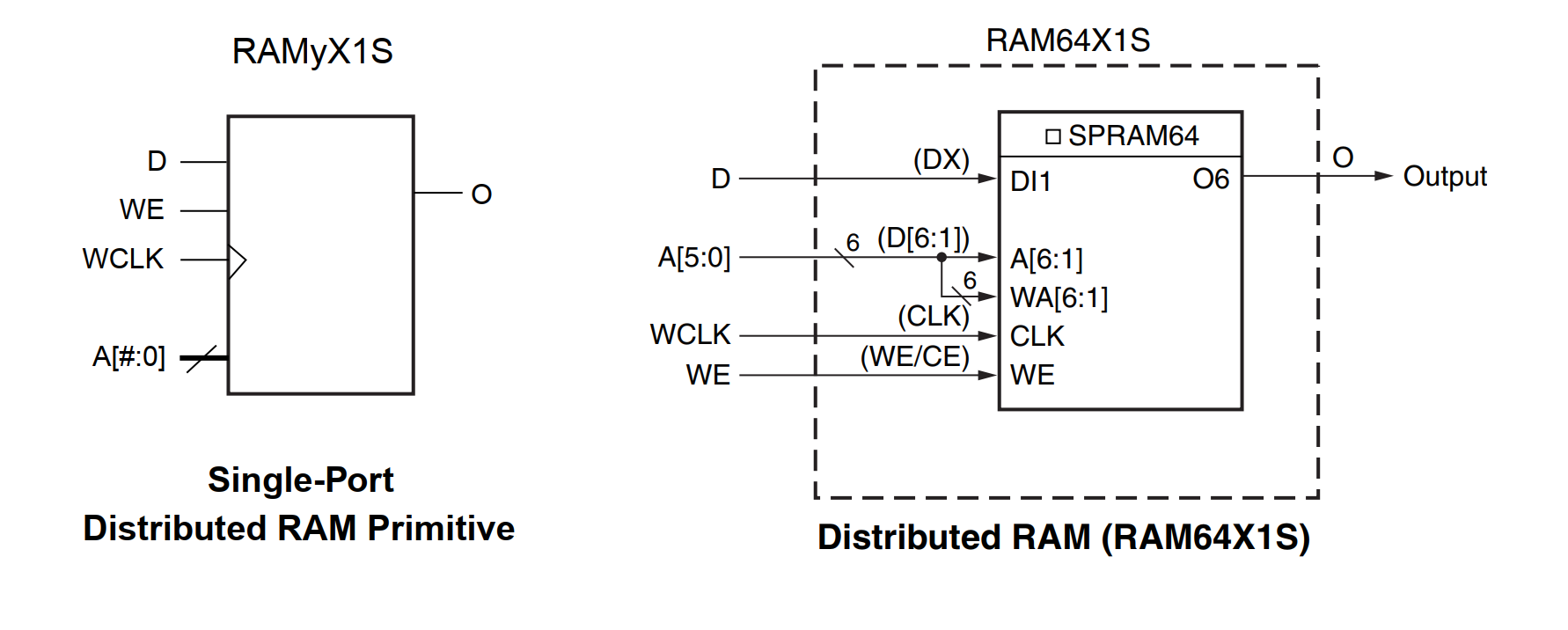
Логика в ячейках организована на LUT (look-up table), что-то вроде ПЗУ на 16 или 64 бит. Эти LUT могут работать ещё и в режиме синхронной памяти, запись в которую производится по фронту тактового сигнала. Ячейка для чтения/записи выбирается комбинацией на адресных линиях A[]. И если мы в КА подменим все триггера этой памятью и подадим на входы A[] какой-нибудь статичный адрес, то поведение самого КА останется прежним: точно так же новое состояние при необходимости будет записываться в эти "триггеры" (ячейки ОЗУ) по фронту тактового сигнала.
Далее останется сделать предпоследний шаг: адресные входы всех ячеек памяти подключим к одному источнику, который в соответствии с каким-то алгоритмом будет эти адреса менять - таким образом мы сможем переключать контекст. Получится такой "многослойный" (я не нашёл более подходящего слова) узел, который состоит из 16 или 64 одинаковых независимых КА, где в определённый момент времени работает только один выбранный.
В семействах Spartan-2, Spartan-3 есть LUT объёмом 16 бит, их можно использовать как синхронное ОЗУ, примитив носит название RAM16X1S. В Spartan-6 ёмкость составляет уже 64 бита, соответственный примитив называется RAM64X1S. Ими можно заменить триггеры (flip-flops) с некоторыми допущениями:
не будет входов асинхронного сброса/установки. Но я ими в своей практике не пользуюсь, и мне это не мешает.
будут задействованы дополнительные LUT в CLB, а триггеры останутся неиспользованы. Таким образом схема будет занимать больше места, но за эту цену мы получаем "многоканальное" устройство внутри одного.
При использовании схемного редактора замена производится относительно просто - нужно создать символы, совпадающие по выводам со стандартными flip-flop и содержащие дополниительные адресные входы, внутри которых будут находится RAMnX1S. Далее создавать и заменять символы вверх по иерархии. В КА не должно остаться ни одного "настоящего" триггера!
Если поведение модуля описано на HDL, то здесь сложнее. Придётся придумывать и описывать его структуру, основанную на этих примитивах. Синтезатор понимает, например, что конструкцию reg [63:0] mem и можно превратить в RAM64X1. Но описать целиком "многослойные" вещи мне не удалось. Можно избавится от, например, сумматоров, заменив их одной строчкой кода, но "триггеры" придётся включать в виде модулей. Исходный код при этом сильно теряет в читабельности и понимаемости.
В качестве примера сделаем 8-битный 64-слойный счётчик (исходный код на verilog). В симуляторе мы заставим его считать сначала в контексте 0, потом последовательно пройдёмся по контекстам 1, 2, 1 и снова 0. На скриншоте симулятора видно, что после возврата к предыдущему контексту счётчик продолжает считать с того же места, на котором он был прерван.

И наконец, последний шаг, который нужно сделать - поставить мультиплексоры на входные сигналы и демультиплесоры с уже "обычными" триггерами на выходные.
Если необходимо узнать состояние какого-либо контекста, не переключаясь на него, то можно использовать двухпортовую версию памяти, например RAM64X1D. На линии DPRA подаём номер читаемого контекста, и на выходе DPO получаем его состояние.

На переключение рабочего контекста не тратится время. Можно в качестве генератора номера контекста использовать счётчик, который увеличивается на каждом такте. И таким образом 64-слойную схему, работающаю на частоте 64 МГц, можно представить как 64 независимые схемы, работающие на частоте 1 МГц.
Описанный метод был применён при разработке устройств, работающих с сигналами с временнЫм разделением каналов, и при создании многоканальных устройств, работающих на относительно низких частотах.
Несмотря на очевидность описанного способа, я не встречал в своей практике ни сторонних проектов, использующих его, ни описания. Это и полсужило поводом для создания статьи. Она получилась поверхностной, потому как неясно, какие моменты требуют детализации, и я буду рад замечаниям и предложениям по ней.
С уважением, Виктор.
old_bear
Хранение обновляемого контекста в памяти достаточно часто используется для экономии FF/LUT.
Например, пользуясь таким подходом можно запихать 512 64-разрядных счётчиков в 9*512 FF/LUT (для младшей части) + 1 блок памяти 64х512 (RAMB36 в случае Xilinx-а, в SDP режиме чтобы не морочиться с четнием-обновлением-записью за один такт) + ещё немного FF/LUT на (один) сумматор который обнавляет содержание очередного "слоя" в памяти, циклическое переключение слоёв, и сброс младшей части в момент обновления слоя. Итого немногим больше 4608 FF/LUT + 1 BRAM36 против 32768 с лишним, если реализовывать в явном виде.
Задачи такого типа частенько возникают в системах, где нужно события считать, например.
avitek Автор
Всё верно, можно и RAMB использовать, можно даже во внешней памяти хранить констекст (сам так делал), но тогда возникают накладные расходы на его переключение. Чем ёмче память - тем дольше ожидание.
Статья немножко не об этом.
YuriPanchul
Переключение контекстов (например при приеме потока сетевых пакетов из n портов, нарезанных на куски) применяется довольно часто, но это мало описано в статьях и тем более учебниках, потому что 1) разработчикам облом писать статьи, им верилог писать надо к сроку; 2) статьи такого рода для конференций типа snug нужно отправлять на утверждение компанейским юристам, что занимает пару недель и вообще муторная деятельность; 3) профессора в университетах часто оторваны от реальной жизни и даже в хорошем стенфордском учебнике такие микроархитектурные штучки почти не разбираются, только простые fsm и двойные буфера (skid buffers) итд.
Но было бы хорошо собрать сотню-две таких примеров в книжку типа "этюды для микроархитектора RTL/FPGA/ASIC"
Thealik
Уподоблюсь FSM и напишу по пунктам (ведь присущая FPGA параллельность здесь не рассматривается):
1) Возможно, переключаемые контексты описаны в одной из книг Самария Баранова, надо найти время почитать
https://www.synthezza.com/books
2) Ещё меньшее количество разработчиков интересуются "нано-архитектурой", а именно как сделан LUT или триггер. Я поинтересовался
https://eprints.ncl.ac.uk/file_store/production/276950/9F49E3C0-2DAC-490B-BBFA-6C880F2BED2B.pdf