HP Proliant DL360 Gen6 с контроллером P410i
HP Proliant DL360 Gen7 с контроллером P410i
HP Proliant DL360p Gen8 с контроллером P420i
Во всех конфигурациях контроллера используем кэш размером 256Mb. Стоит отметить отличие в пропускной способности PCI Express шины, посредством которой подключены контроллеры: P400i и P410i — 2GBps (гигабайта в секунду), P420 — 8 GBps (гигабайт в секунду).
Первый вопрос, который логично возникает в этом случае: в каких попугаях измерять производительность? Изучив статью уважаемого amarao, мы установили, что подобные измерения стоит проводить как минимум по двум параметрам: IOPS — количество дисковых Input/Output операций в секунду: чем их больше, тем лучше и Latency — время обработки операции: чем меньше, тем лучше.
Было решено произвести сравнение производительности различных конфигураций применительно к разным типовым задачам, поскольку эти задачи подразумевают различные варианты нагрузки на дисковую подсистему. Характер нагрузки определяется следующими параметрами: размер блока, соотношение операций чтение-запись, случайный/последовательный доступ.
Последовательный доступ к данным характерен для записи всевозможных логов, при трансляции и записи аудио/видео и тому подобного. Суть в том, что доступ характеризуется локализованной областью диска, без необходимости прыгать по всей поверхности.
Случайный доступ наиболее характерен для баз данных, веб и файловых серверов: большое количество запросов к разбросанным по диску секторам.
Комбинированный сочетает в себе оба выше описанных сценария, например функционирование БД с записью логов на тот же массив.
Тестируем непосредственно raw-device (прямой доступ, без оглядки на файловую систему), чтобы избежать влияния особенностей реализации файловых систем и всего, что с этим связано на разных платформах.
Под эту задачу были написаны правила для fio и IOMetter.
Конфигурационный файл IOmetter
[web-file-server4k]
blocksize=4k
чтение/записьmixread=95
чтение/записьmixwrite=5
чтение/запись=randчтение/запись
percentage_случайный доступ=75
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[web-file-server8k]
blocksize=8k
чтение/записьmixread=95
чтение/записьmixwrite=5
чтение/запись=randчтение/запись
percentage_случайный доступ=75
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[web-file-server64k]
blocksize=64k
чтение/записьmixread=95
чтение/записьmixwrite=5
чтение/запись=randчтение/запись
percentage_случайный доступ=75
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[decision-support-system-db]
blocksize=1024k
чтение/записьmixread=100
чтение/записьmixwrite=0
чтение/запись=randчтение/запись
percentage_случайный доступ=100
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[media-streaming]
blocksize=64k
чтение/записьmixread=98
чтение/записьmixwrite=2
чтение/запись=randчтение/запись
percentage_случайный доступ=0
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[sql-server-log]
blocksize=64k
чтение/записьmixread=0
чтение/записьmixwrite=100
чтение/запись=randчтение/запись
percentage_случайный доступ=0
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[os-paging]
blocksize=64k
чтение/записьmixread=90
чтение/записьmixwrite=10
чтение/запись=randчтение/запись
percentage_случайный доступ=0
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[web-server-log]
blocksize=8k
чтение/записьmixread=0
чтение/записьmixwrite=100
чтение/запись=randчтение/запись
percentage_случайный доступ=0
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[oltp-db]
blocksize=8k
чтение/записьmixread=70
чтение/записьmixwrite=30
чтение/запись=randчтение/запись
percentage_случайный доступ=100
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[exchange-server]
blocksize=8k
чтение/записьmixread=67
чтение/записьmixwrite=33
чтение/запись=randчтение/запись
percentage_случайный доступ=100
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[workstation]
blocksize=8k
чтение/записьmixread=80
чтение/записьmixwrite=20
чтение/запись=randчтение/запись
percentage_случайный доступ=80
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
[video-on-demand]
blocksize=512k
чтение/записьmixread=80
чтение/записьmixwrite=20
чтение/запись=randчтение/запись
percentage_случайный доступ=100
ioengine=libaio
direct=1
buffered=0
time_based
runtime=300
%%}}}
Очевидно, что для тестирования под Windows необходима установка данной ОС, а это, как минимум, еще один занятый порт и время, посвящённое установке на каждый сервер. Именно поэтому для работы мы выбрали Linux. Дело тут даже не в индивидуальных пристрастиях, а в наличии развитых средств автоматизации процесса «из коробки», позволяющих, к примеру, запустить тестирование сразу после загрузки ОС, а по окончанию тестов, отправить результаты по ssh, ftp или по email.
Было решено собрать небольшой Live-USB образ на базе Debian со всеми необходимыми утилитами. Желающие пересобрать его под свои потребности могут скачать архив. Для сборки потребуется Debian (скорее всего, подойдет и Ubuntu), multistrap, isolinux, squashfs-tools и xorriso. Внеся изменения и доустановив из chroot'a нужные пакеты, выполните скрипт build.sh.
Единственный пользователь в системе — root, пароль не задан. При загрузке генерируется, основанный на uuid, hostname, а при логине выдаётся краткая сводка о системе. Для запуска тестирования необходимо выполнить скрипт run.sh в каталоге fio, передав в качестве аргумента полное имя файла устройства, которое нужно протестировать, например, ./run.sh /dev/cciss/c0d0.
ВНИМАНИЕ! Делать это следует исключительно на пустом массиве, иначе вы потеряете данные!
Тем не менее, в одном из случаев мы провели тестирование и под Windows с использованием IOMetter для сравнения полученных результатов с fio.

Таким образом удалось изучить производительность различных массивов на наших серверах по 12 типовым профилям нагрузки, выраженным в 3-х группах, сформированных по типу доступа.
Влияние аппаратного кэша
Как известно, кэш представляет собой промежуточный буфер быстрого доступа к информации, запрашиваемый с наибольшей вероятностью. В итоге доступ к данным осуществляется оперативнее, минуя выборку данных из удаленного источника.
Рассмотрим влияние наличия платы аппаратного кэша на примере конфигурации raid10, построенной на четырех 6Gbps дисках.
Операции последовательного доступа
Media Streaming: размер блока 64KB, 98%/2% чтение/запись, 100% последовательный доступ


Операции случайного доступа
OLTP DB: размер блока 8KB, 70%/30% чтение/запись, 100% случайный доступ


Операции комбинированного доступа
Workstation: размер блока 8KB, 80%/20% чтение/запись, 80%/20% случайный доступ/последовательный доступ


Как видно, при установленной плате кэша, производительность возрастает примерно до 40% на операциях как последовательного, так и случайного доступа. Также на гистограммах наглядно демонстрируется, что при включении кэша, колоссально (до нескольких порядков) сокращается время реакции (latency).
Стоит отметить, что использование кэша контроллером (P400i) сервера пятого поколения, мягко говоря, нерационально.
Контроллер сервера восьмого поколения наоборот, принудительно использует кэш, проигнорировав команду на отключение.
Разница между 3Gbps и 6Gbps дисками
Напомним, что параметр «Gbps» (гигабит в секунду) являет собой максимальную скорость передачи данных между диском и контроллером, то есть 3000Mbps и 6000Mbps. При надобности пересчитать в байты делим на 10: 300MBps и 600MBps соответственно. Теоретически, при количестве более шести 3G и более трех 6G дисков, бутылочным горлышком окажется скорость шины. Собственно, попробуем оценить ширину этого самого горлышка. Следует помнить, что жесткий диск является механической системой и указанная скорость передачи данных является предельной, то есть, по факту, в полной мере недостижимой. Напомним также, что контроллер P420i сервера восьмого поколения подключен через PCIe 3.0 (8GBps).
Сравнение проводим на raid10 с включенным кэшем.
Операции последовательного доступа
Media Streaming: размер блока 64KB, 98%/2% чтение/запись, 100% последовательный доступ


Операции случайного доступа
OLTP DB: размер блока 8KB, 70%/30% чтение/запись, 100% случайный доступ


Операции комбинированного доступа
Workstation: размер блока 8KB, 80%/20% чтение/запись, 80%/20% случайный доступ/последовательный доступ
При использовании на данной конфигурации 3Gbps и 6Gbps дисков с 10K оборотов, какой-либо принципиальной разницы нет как по параметру IOPS, так и по Latency. А вот рост производительности при использовании 6Gbps 15K весьма значителен и лучше всего заметен на операциях случайного доступа. Вывод: количество оборотов имеет значение.
К вопросу о PCIe 2.0 и 3.0: на примере конфигурации серверов Gen6, Gen7 и Gen8 с 6Gbps дисками, разница в IOPS составляет максимум 10%, по Latency и вовсе не больше 2%. Вывод: «бутылочное горлышко» PCIe 2.0 достаточно широко для конфигурации из четырех 6Gbps (600MBps) дисков.
Любопытно, что сервер седьмого поколения на конфигурации 3G 10Krpm дал худшую производительность, чем Gen 6 на этих же дисках. С чем это связано, в данном случае, сказать трудно и, возможно, будет выявлено при комплексном тестировании серверов.
Использование в сервере пятого поколения 6Gbps 15K дисков дало некоторый прирост в быстродействии, в основном за счет большего количества оборотов в секунду. Разницы между 6G и 3G десятитысячниками, ожидаемо, практически нет.
Разница между поколениями серверов
В принципе, все видно выше, но все-таки проиллюстрируем на примере raid10, построенном на четырех 6Gbps дисках.
Операции последовательного доступа
Media Streaming: размер блока 64KB, 98%/2% чтение/запись, 100% последовательный доступ


Операции случайного доступа
OLTP DB: размер блока 8KB, 70%/30% чтение/запись, 100% случайный доступ


Операции комбинированного доступа
Workstation: размер блока 8KB, 80%/20% чтение/запись, 80%/20% случайный доступ/последовательный доступ


Как видно на графиках разница не существенная, особенно между серверами DL360Gen6, DL360Gen7 и DL360Gen8. В типовой нагрузке (профиль workstation) есть небольшая разница и с DL360Gen5. Старенький контроллер P400i в сервере DL360G5 сильно подкачал лишь на операциях последовательного доступа как по количеству IOPS, так и по времени реакции (latency), что не удивительно.
Желающие ознакомиться с детальными результатами тестирования (конфигурации raid5 и raid10 на трех, четырех и восьми дисках), могут скачать csv файл
Последовательный доступ.
SQL Server Log: размер блока 64KB, 0%/100% чтение/запись, 100% последовательный доступ


Web Server Log: размер блока 8KB, 0%/100% чтение/запись, 100% последовательный доступ


Media Streaming: размер блока 64KB, 98%/2% чтение/запись, 100% последовательный доступ


Случайный доступ. Базы данных OLTP и Exchange.
OLTP DB: размер блока 8KB, 70%/30% чтение/запись, 100% случайный доступ


Decision Support System DB: размер блока 1MB, 100% Read, 100% случайный доступ


Exchange Server: размер блока 4KB, 67%/33% чтение/запись, 100% случайный доступ


Video On Demand: размер блока 512KB, 100%/0% чтение/запись, 100% случайный доступ


Комбинированный доступ.
Workstation: размер блока 8KB, 80%/20% чтение/запись, 80%/20% случайный доступ/последовательный доступ


Web File Server64k: размер блока 64KB, 95%/5% чтение/запись, 75%/25% случайный доступ/последовательный доступ


Web File Server8k: размер блока 8KB, 95%/5% чтение/запись, 75%/25% случайный доступ/последовательный доступ


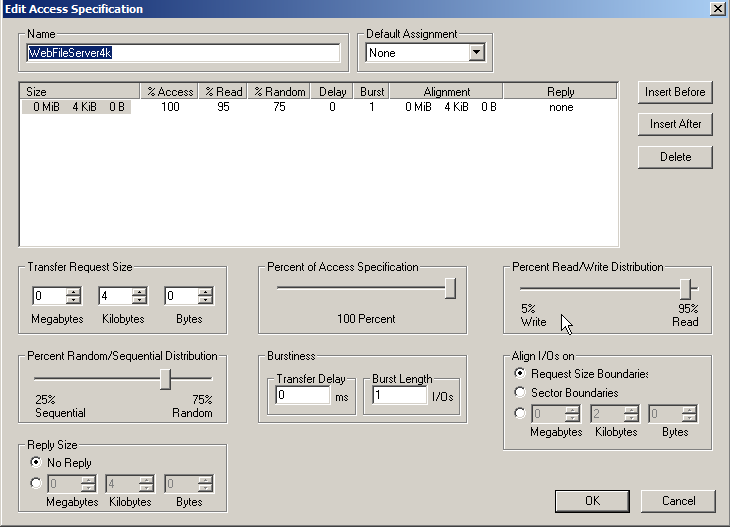
Web File Server4k: размер блока 4KB, 95%/5% чтение/запись, 75%/25% случайный доступ/последовательный доступ


Подведение итогов
Разница между G8 (P420i) и G6/G7 (с одинаковым контроллером P410i) составляет не более 10% на всех типах задач. Напрашивается вывод, что если исходить исключительно из соотношения «производительность дисковой системы/стоимость», G6 или G7 будут более выгодным приобретением. Комплексное сравнение производительности этих серверов мы проведем в одной из следующих статей.
Gen5 же несколько отстает: напомним, что его контроллер P400i обменивается данными с дисками на скорости 3Gbps. Видно, что на операциях случайного доступа отставание не так велико. С ростом количества операций последовательного доступа, разница растет. В принципе, компенсировать ее можно наращиванием числа дисков в массиве. Таким образом, этот сервер можно рекомендовать, как бюджетное решение для небольшой компании из 10-15 человек.
А теперь попробуем ответить на вопрос: а сколько же мне потребуется IOPS под такую-то задачу? Простой ответ: чем больше, тем лучше. С latency, соответственно, наоборот.
В первую очередь, стоит разобраться, какая именно нагрузка предвидится (что именно будет работать на сервере) и попробовать соотнести с приведенными выше результатами, имитирующими «потолок» для той или иной конфигурации.
Лучше всего — посмотреть какую нагрузку дают ваши приложения. В Linux это можно сделать с помощью программы iostat, входящей в состав пакета sysstat, которая показывает текущее состояние дисковой подсистемы.

r/s и w/s — IOPS на чтение и запись
r/await и w/await — соответственно latency.
util — уровень загруженности сервера. В наших тестах значение колеблется от 80% до 100%.
В случае Windows, замеры можно произвести утилитой perfmon.
Если пиков нагрузки, принимающих значения близкие к нашим результатам будет много и параметр util длительное время колеблется в районе 80-100% — это хороший повод задуматься над оптимизацией дисковой системы.
Возвращаясь к вопросу о выборе конфигурации под потребности небольшой компании: файловый сервер, *SQL и завязанные на нем сервисы, мы бы рекомендовали рассматривать сервер не ниже Gen 6 с контроллером P410i с массивом уровня 10 (минимум 4 диска) из соображений сочетания быстродействия и надежности (raid10 имеет гораздо меньшее время перестроения массива в случае сбоя диска) на 6Gbps 15Krpm носителях. Отметим, что экономить на плате кэша крайне не рекомендуется.
Вообще, для нас результаты тестирования оказались неожиданными. Разница в производительности дисковых подсистем ожидалась гораздо большая, особенно в случае Gen8 с его PCIe 3.0 контроллером, в сравнении с серверами шестого и седьмого поколения. Маркетинг есть, а разницы почти нет — забавно.
Комментарии (8)

datacompboy
14.10.2015 13:41Судя по графику, надо обязательно чтение и запись разнести на разные шкалы (слева чтение, справа запись), так как разницы не видно из-за разных масштабов.
Ну а так, общее замечание читателям, полагаться на аппаратный кеш чревато большими проблемами в случае помирания батарейки.
Если ваш проект без аппаратного кеша не живёт — вы сидите на мине.
d7s2di
14.10.2015 13:47С масштабами замечание, конечно резонное, но тут такая штука: на той же записи встречается разброс эдак от 0.2 до 7 msec и разнесение ничего не даст.
В принципе, можно добавить — там пара строчек в gnuplot. А так, специально приложили csv'шку, по которой построить какие-нибудь свои гистограммы.

magzimko
15.10.2015 08:24-3Что за некрофилия )))
И где, интересно, вы найдете для покупки G6 G7 сегодня? С учетом того, что все, кроме Gen9 снято с проивзводства, то покупка и поддержка устаревшего оборудования может быть совсем не выгодной (суппорт и запчасти старого всегда дороже).Megapolice
15.10.2015 09:47+4При чём тут некрофилия? Странный сарказм, который не имеет ничего общего с определением этого слова. Да и даже на жаргоне «мёртвый» сервер — сервер сломанный и не подлежащий восстановлению.
Вообще-то в статье даны ссылки где взять подобные серверы и запчасти. Да собственно и статья о том, что можно сэкономить на железе посредством приобретения оборудования refurbished с гарантией. Поэтому про Gen9 ни словом никто не обмолвился.
И даже если вы противник приобретения восстановленного оборудования, вопрос где его взять звучит странно: будто статью и не читали.
amarao
В SATA используется кодирование 8/10, так что делить надо на 10 (3Гбит/с = 300МБ/с). В SAS, насколько я знаю, тоже.
Далее, это не «чистая» скорость канала данных, т.к. запросы ходят через него же, плюс если есть enclosure, то всё это ограничено числом каналов, то есть пиковая производительность SAS-подсистеме равна числу phy внутри линка, умноженной на скорость диска по передаче данных, минус расходы на сами команды. На практике = 4x300 => должно быть 1200, в жизни — порядка 900, 8х300 — должно быть 2400, в жизни — 1900+.
У SAS дуплекс, так что на чтение запись транспорт показывает почти двухкратный прирост (в сравнении с SATA-той же скорости).
Почему-то все вендоры упорно не хотят показывать тесты с 4к блоками, а они довольно часто просыпаются от плохой нагрузки файловых систем (виртуалок).
На всех графиках «без кеша» для gen8 мне не понятно, почему latency не меняется. Если у вас latency на запись меньше latency на чтение, то либо у вас какой-то новый носитель которого никто не видел (фотонные кубиты с хранением информации в виде куперовских пар взаимно запутанных очаровательного и ароматного кварков), либо у вас есть там снизу writeback.
Ни на одном современном носителе нет технологии в железе, которая позволяет иметь запись быстрее чтения. Единственный метод, это writeback (принимаем запрос, говорим «записали», а пишем потом асинхронно) — обычно даёт latency порядка 10-50µs (при latency чтения за 100µs).
Writeback может быть на уровне кеша контроллера или кешей дисков. В контексте SSD включение writeback'а обычно увеличивает производительность примерно на два порядка (прописью: в сто раз) и снижает latency до значений сильно меньше latency на чтение.
Так что мое предложение — перепроверить тесты gen8, у вас где-то writeback закрался.
d7s2di
>На всех графиках «без кеша» для gen8 мне не понятно, почему latency не меняется.
У него контроллер шибко умный: попросту игнорирует команду на отключение. Можно, конечно, было плату вытащить, но поняли это все уже когда протестили.
С блоками 4K оттестили, но большие и перегруженные гистограммы упрятали под спойлер.
C SSD'шниками было б интересно потестить. Думаю, организуем.
Про writeback'и спасибо, поразмыслим.
amarao
(оставляя в стороне побухтеть в тредике про неподходящее под (мои) нужды железо).
Вот это одна из главных причин моей внутренней нелюбви к любым умным фирмварям. Что гигантские промышленные шкафчики для хранения голых сисек с комплайенс уведомлений, что даже скромные LSI'ные рейды. Они СЛИШКОМ УМНЫЕ. При этом закрытые. И когда русский мужик таки находит рельс, то умную систему чинить получается тольком методом чёрного ящика.
В более тупых системах умная часть отдаётся на откуп пользователю, пользователь её отдаёт на откуп софту, а у софта сырцы открыты (да, я понимаю, windows и всё такое). Но стандартный софт обычно имеет большую пользовательскую базу и легче в сопровождении.
d7s2di
>(оставляя в стороне побухтеть в тредике про неподходящее под (мои) нужды железо).
А это ничего, у нас есть планы потестить интирпрайзный интирпрайз, но начать решили с малого, отработать инструмент, автоматизировать процесс…
Закрытые технологии у меня тоже не вызывают приятных эмоций: черный ящик и черный ящик, а о его каком-то функционировании можно судить по каким-то внешним признакам.
Так, лет так N назад, когда админил небольшую конторку, подох адаптек на собранном непонятно кем и когда серваке — вот это было приключение. Потом как-то все на софтварном рейде собирал, проще собирать, если (скорей, когда) развалится по кусочкам.
Особо много приятных эмоций доставляли всякие недодевайсы типа псевдоаппаратных рейдов, завязанных на хитрые драйверы с поддержкой известно какой системы. Сейчас то ли ситуация на рынке изменилась, то ли я стал меньше сталкиваться.