Исследователи добились значительного прогресса в скорости конвергенции, точности и интерпретируемости решений визуального трансформера. За подробностями приглашаем под кат. Материалом из блога Google Research делимся к старту флагманского курса по Data Science.
В визуальном распознавании визуальный трансформер (ViT) и его вариации привлекают значительное внимание благодаря превосходной производительности во множестве основных визуальных приложений, таких как классификация изображений, обнаружение объектов и распознавание на видео.
Основная идея ViT — использовать возможности слоёв самовнимания, чтобы изучить глобальные отношения между фрагментами изображений. Однако с увеличением размера изображений количество связей между этими частями возрастает квадратично.
Такая конструкция неэффективна в точки зрения данных, хотя оригинальный ViT также может эффективно изучать визуальные представления и делает это лучше свёрточной нейронной сети с сотнями миллионов изображений в тренировочном наборе. Подобные требования к данным не всегда практичны, и трансформеры всё ещё отстают от свёрточных нейронных сетей, когда у них меньше данных.
Многие исследователи пытаются найти подходящие изменения архитектуры, которые смогут эффективно изучать визуальные представления, добавляя свёрточные слои и разрабатывая иерархические структуры с локальным самовниманием.
Принцип иерархической структуры — одна из основных идей в моделях машинного зрения, где нижние слои изучают более локальные структуры высокоразмерного пространства пикселей, а слои выше изучают более абстрактные и высокоуровневые пространства признаков низкой размерности.
Для достижения такой иерархии существующие методы на основе ViT сосредоточены на архитектуре различных модификаций внутри слоёв самовнимания и часто требуют существенного редизайна архитектуры. Более того, эти подходы не обладают интерпретируемым дизайном, поэтому внутреннюю работу обученных моделей трудно объяснить.
Для решения этих проблем мы представили переосмысление существующих, управляемых структурой дизайнов и новый, ортогональный подход — иерархически сгруппированный трансформер. Этот подход значительно упрощает дизайн.
Основная идея работы — разделить обучение признакам и компоненты абстрактных признаков (пулинг): сгруппированные идентичные слои трансформера отдельно друг от друга кодируют визуальную информацию о частях изображений, а затем агрегируют обработанную информацию.
Этот процесс повторяется в иерархии, что приводит к пирамидальной структуре. Полученная архитектура способна конкурировать с результатами на наборе ImageNet и показывает превосходные результаты в бенчмарках эффективности данных.
Мы показали, что такой дизайн может значительно улучшить эффективность данных, ускоряя конвергенцию и предоставляя преимущества интерпретируемости. Более того, мы создали GradCAT — новую технику интерпретации процесса принятия решений обученными моделями.
Диаграмма архитектуры
Общая архитектура реализуется просто — добавлением нескольких строк на Python к оригинальному ViT. Оригинальная архитектура делит входное изображение на меньшие прямоугольные части, проецирует пиксели на каждой такой части на вектор с определённым разрешением, а затем подаёт последовательности всех этих векторов архитектуре трансформера со множеством сгруппированных идентичных слоёв.
Пока каждый слой ViT обрабатывает изображение целиком, с помощью нового метода сгруппированные слои трансформера используются для обработки только области (блока) изображения, содержащего несколько смежных в пространстве участков изображения. Этот шаг независим для каждого блока, на этом же шаге происходит обучение признакам.
После вычислений слой вызывает агрегацию блоков, комбинируя последние в пространственно смежные. После агрегации блока соответствующие четырём смежным блокам признаки подаются на другой модуль трансформера со сгруппированными слоями, который обрабатывает объединение всех четырёх блоков.
Этот дизайн естественным образом выстраивает пирамидальную иерархическую структуру сети, где нижние слои сосредоточены на локальных признаках, таких как текстуры, а верхние — на глобальных, таких как форма объекта. Благодаря агрегации блоков понижается размерность.

Визуализация обработки изображения сетью. Получив входное изображение, сеть вначале делит его на блоки, каждый из которых содержит по 4 части изображения. Эти части в каждом блоке линейно проецируются как векторы и обрабатываются сгруппированными идентичными слоями.
Затем обработанный слой агрегации блоков объединяет информацию из каждого блока и сокращает его пространственный размер в 4 раза. На верхнем уровне количество блоков уменьшается до одного, классификация проводится после вывода этого блока.
Интерпретируемость
Эта архитектура обладает независимым на каждом узле механизмом обработки информации без перекрытий. Дизайн напоминает древовидную структуру принятия решений, которая показывает единственные в своём роде возможности интерпретации: каждый узел дерева содержит независимую информацию о блоке изображения, которая принимается родительским узлом.
Чтобы понимать важность каждого признака, можно отследить поток информации по узлам. Иерархическая структура сети сохраняет пространственную структуру изображений на всех слоях сети, что приводит к эффективному с точки зрения интерпретации изучению карт пространственных признаков.
Мы представили метод интерпретации обученной модели на тестовых изображениях — GradCAT (gradient-based class-aware tree-traversal — обход дерева на основе градиента с учётом класса). В иерархической структуре GradCAT сверху вниз отслеживает важность признаков каждого блока (узла дерева).
Основная идея — найти самый ценный обход от узла на верхнем слое к дочерним узлам нижних слоёв, которые вносят наибольший вклад в результаты классификации. Поскольку каждый узел обрабатывает информацию из определённой области изображения, такой обход может быть легко отображён в пространство изображений для интерпретации (это показано линиями и точками на изображении ниже).
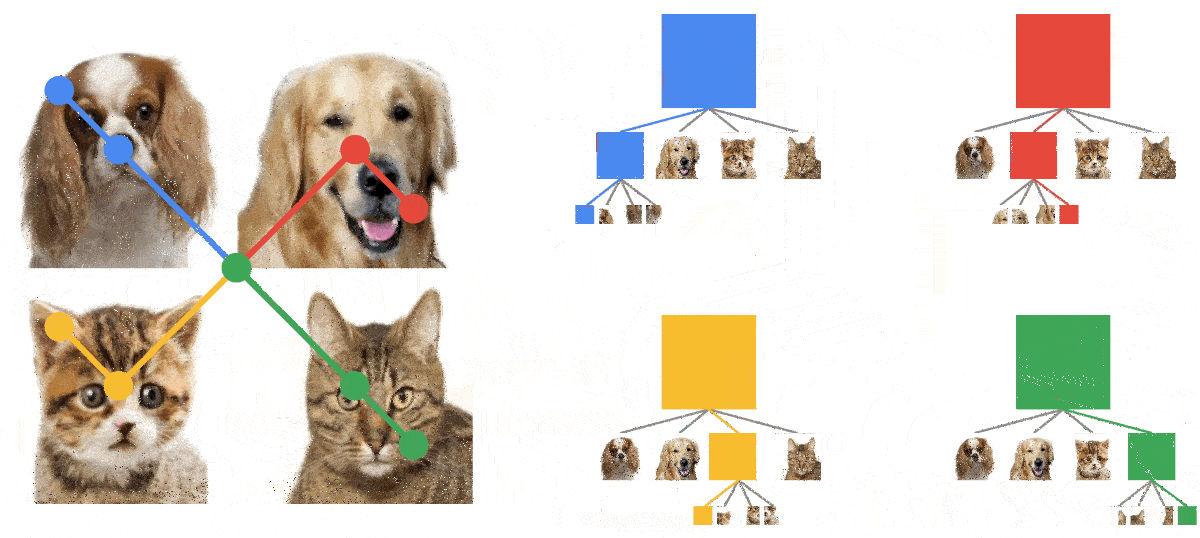
Приведём пример 4 лучших прогнозов и связанные с ними результаты интерпретации на входном изображении слева (с четырьмя животными). Как показано ниже, GradCAT выделяет путь к решению рядом с иерархической структурой и даёт визуальные подсказки в локальных областях изображений.

Возьмём изображение слева с 4 объектами. Рисунок визуализирует интерпретируемые результаты для четырёх прогнозируемых классов. Обход находит путь принятия решений вдоль дерева и соответствующую часть изображения, которая имеет наибольшее влияние на прогноз (эта часть показывается пунктирной линией на изображении).
Более того, следующие рисунки — визуализация результатов на наборе данных валидации ImageNet. Они показывают, как этот подход позволяет сделать некоторые интуитивные наблюдения.
Определённо интересен пример с зажигалкой в левом верхнем углу, потому что класс наблюдаемой истины — зажигалка/спичечный коробок — определяется правым нижним коробком.
При этом наиболее заметными визуальными признаками (с наибольшим значением узлов) на самом деле обладает красный свет в левом верхнем углу, который концептуально имеет общие с лазерной указкой визуальные подсказки. Это видно по красным линиям, которые обозначают части изображений с наибольшим влиянием на прогноз.
Таким образом, несмотря на ошибки в подсказках, выходной прогноз правильный. Кроме того, четыре дочерних узла изображения деревянной ложки ниже имеют похожую важность признаков (посмотрите на количество визуализированных узлов; чем их больше, тем больше важность). Это объясняется тем, что текстура деревянного стола похожа на текстуру ложки.
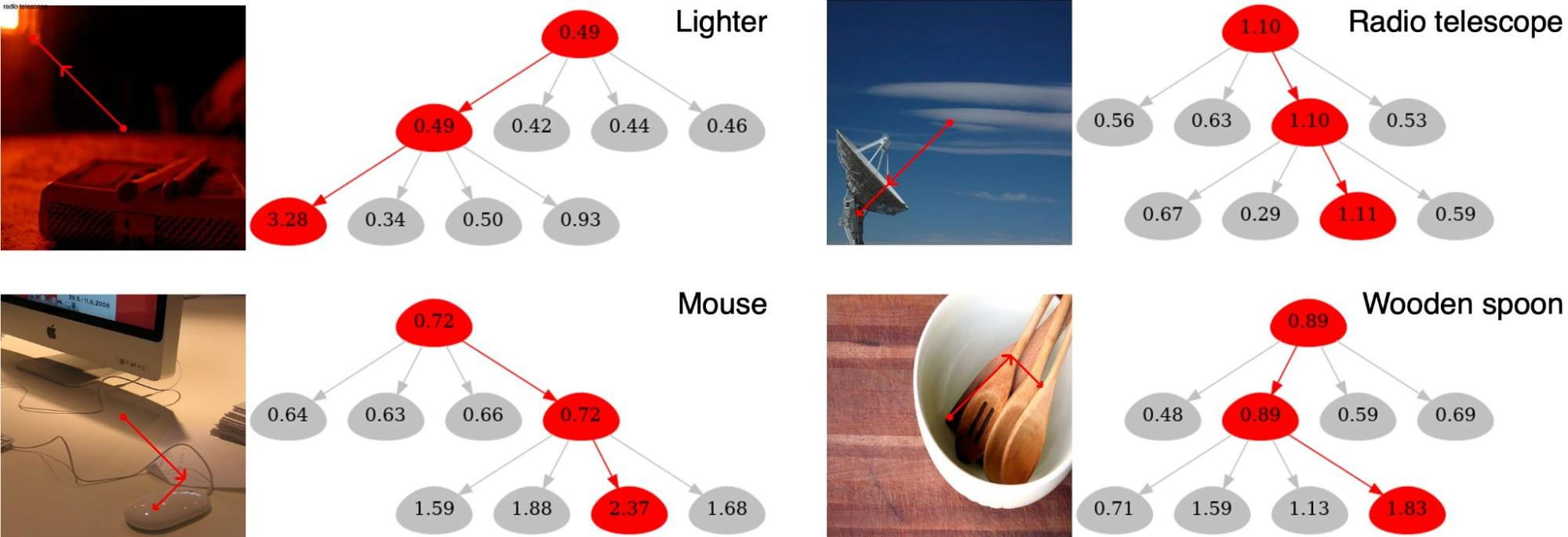
Визуализация полученных GradCAT результатов. Изображения из набора валидации ImageNet
В отличие от оригинального ViT наша иерархическая структура сохраняет пространственные отношения изученных представлений. Вывод верхних слоёв — это карты признаков низкого разрешения из входных изображений, позволяющие модели легко выполнить интерпретацию на основе внимания, применяя к изученным представлениям CAM (class attention map — карта внимания класса; [в публикации по ссылке вы увидите class activation map — карта активации класса]).

Визуализация результатов CAM на наборе валидации ImageNet. Чем теплее цвета, тем выше внимание
Преимущества в конвергенции
При таком дизайне обучение признакам происходит независимо, только в локальных областях, и абстрагируются внутри функции агрегации. Его, а также простой реализации в основном достаточно для других типов задач визуального распознавания за пределами классификации. Подход также сильно ускоряет конвергенцию, значительно сокращая время обучения и достигая максимальной точности.
Мы проверили эти достижения двумя способами:
Cравнили точность структуры ViT на наборе ImageNet с разным количеством эпох обучения. Результаты в левой части рисунка ниже показывают конвергенцию, которая гораздо быстрее, чем в оригинальном ViT. Это около 20% улучшения при 30 эпохах обучения.
Изменили архитектуру, чтобы выполнить задачи безусловной генерации изображений, поскольку обучение моделей на основе ViT из-за проблем со скоростью конвергенции — это вызов. Создание такого генератора прямолинейно просто: мы транспонировали новую архитектуру. Входное изображение стало векторным представлением, а выводом стало полноценное изображение с каналами RGB.
Агрегацию блоков мы заменили на компонент деагрегации, поддерживаемый Pixel Shuffing [перестановка пикселей — операция, используемая в моделях сверхразрешения для реализации эффективных субпиксельных свёрток с определённым шагом].
Удивительно, но мы обнаружили, что наш генератор легко обучаем и демонстрирует как ускорение конвергенции, так и метрику FID (расстояние Фреше по Interception v3) лучше, чем у SAGAN. FID измеряет, насколько изображения похожи на реальные.
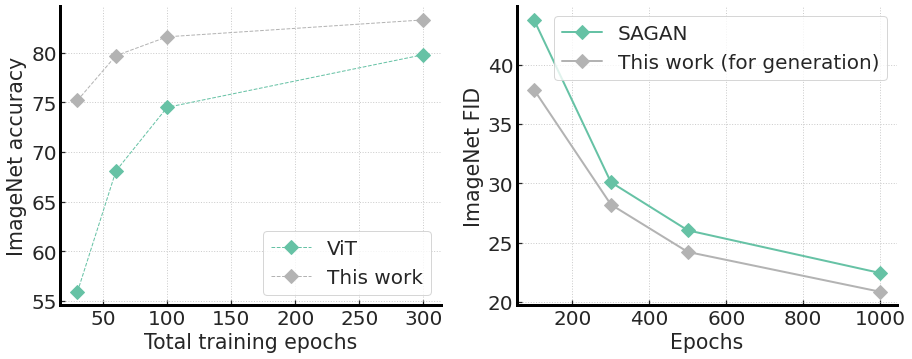
Слева: точность стандартной архитектуры ViT на ImageNet с разным суммарным количеством эпох обучения. Справа: FID при генерации изображений (чем меньше, тем лучше) с единственным обучением в тысячу эпох
В обеих задачах наш метод показывает лучшую скорость конвергенции.
Заключение
В этой работе мы продемонстрировали простую идею разделения обучения признакам и извлечения информации из признаков в иерархически сгруппированном дизайне, улучшающую интерпретируемость посредством метода обхода дерева на основе градиента с учётом класса. Эта архитектура ускоряет конвергенцию не только в задачах классификации.
Предложенная идея сосредоточена вокруг функции агрегации и, таким образом, ортогональна к усовершенствованному дизайну архитектуры самовнимания [не влияет на этот дизайн]. Мы надеемся, что это исследование послужит поощрением для дизайнеров архитектуры, чтобы они исследовали ещё более интерпретируемые и эффективные в смысле данных модели визуального распознавания, например адаптацию этой работы для генерации изображений высокого разрешения. Мы также выпустили исходный код части работы, которая связана с классификацией.
Продолжить изучение Python и нейронных сетей, чтобы научиться решать проблемы бизнеса, вы сможете на наших курсах:
Выбрать другую востребованную профессию.

Сокращённый каталог курсов и профессий
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также