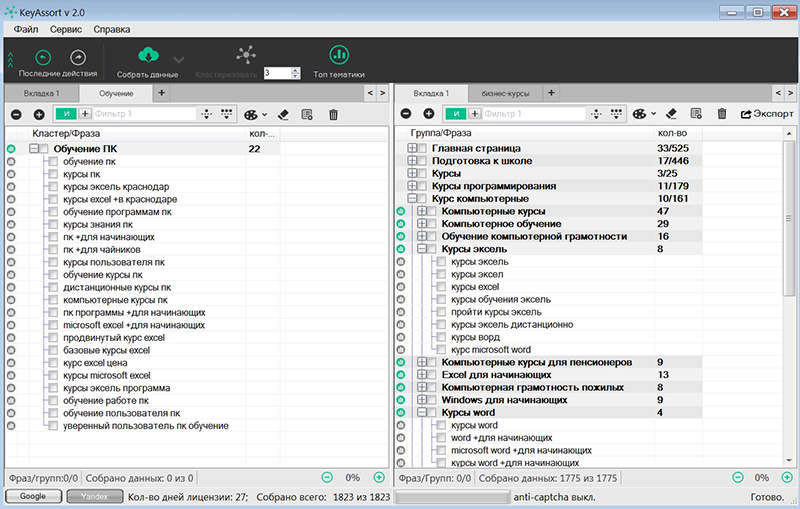
 На Хабре уже были темы про автоматическую группировку ключевых фраз и составление семантического ядра.
На Хабре уже были темы про автоматическую группировку ключевых фраз и составление семантического ядра. Кластеризация помогает скорректировать структуру сайта и распределить ключевые фразы по страницам так, чтобы получить максимум поискового трафика.
В этой статье я покажу на примерах возможности KeyAssort — одного из лучших, на мой взгляд, десктопных решений, которое кроме создания кластеров позволяет работать и со структурой сайта (вновь создаваемого или уже существующего).
В конце материала поделюсь списком облачных решений и обычного софта для ПК.
Буквально полстранички теории.
Виды кластеризации
Это способы группировки ключевиков. Каждая группа запросов, полученных в результате кластеризации, соответствует странице на сайте. Кластеры используются для подготовки текстов, заточенных под алгоритмы поисковиков с учетом интересов посетителей…
Обычно говорят о hard и soft кластеризации. Но у KeyAssort есть еще и middle.
Группировка осуществляется на основе сравнения совпадений URL в топах поисковой выдачи по разным запросам.

Источник: https://keyassort.com/instructions.html#instr2_2
Hard
Ключевые слова в кластере связаны с базовой фразой и между собой.
Они объединяются в группу, когда есть общий набор URL для всех запросов, который показан по всем этим запросам в топ-10.
Здесь имеет смысл упомянуть “силу связи” или “порог кластеризации”. Это число совпадений URL сравниваемых запросов в топ-10 поисковой выдачи. Например, если это 3, то минимум 3 URL в топ-10 для всех ключей, входящих в кластер, должны совпасть.
Т.е., чем выше порог кластеризации, тем меньше ключевых слов попадает в кластер семантического ядра. Тем точнее группировка, но сложнее внедрение семантики (количество групп получается обычно большим).
Используется в коммерческих проектах и проектах с высокой конкуренцией.
Soft
Ключевые слова в кластере связаны как минимум с одним другим ключевым словом в этом же кластере. Тут нет одного базового запроса. Поэтому может получиться, что в кластер попадут фразы, которые в случае точной hard-кластеризации попадут в разные группы.
Основной плюс в том, что в результате получается гораздо меньше кластеров для создания посадочных страниц, чем для hard.
Обычно используется для информационных проектов и тематик с невысокой конкуренцией. Кроме того, soft-кластеризацию используют на сайтах, для которых нет возможности создать 100500 посадочных страниц (небольшие ресурсы либо магазины с маленьким ассортиментом).
Middle
Берётся один центральный запрос А (см. картинку) и с ним сравниваются остальные фразы на предмет совпадения URL. Этот метод подходит для информационных сайтов с высоким уровнем конкуренции либо для коммерческих сайтов с низким уровнем конкуренции.
Ниже на примерах я покажу отличия результатов кластеризации для hard, soft и middle с помощью KeyAssort.
А пока кратко об особенностях сбора исходной информации и ее обработке, которые в подобных статьях редко упоминаются.
Проблемы сбора и точности автоматической группировки
Выдача не является инертной, и кластеризация актуальна на момент сбора информации, плюс у Яндекс и Google есть масса отличий в работе. Это приводит к тому, что уже на этапе сбора мы получаем искаженные данные для анализа.
Например:
- Часть решений использует Яндекс.XML, который работает с API и является официально поддерживаемым Яндексом. Но результаты органического поиска Яндекса и Яндекс.XML иногда заметно отличаются. Да, практически весь софт дает возможность работать с живой выдачей, но нормальные рабочие прокси в большом количестве сейчас тоже проблематично найти (в этом случае на выручку может прийти XMLRiver, про который уже писал здесь).
- Выдача в Google и Яндекс по одним и тем же ключевым фразам тоже отличается.
- А есть еще персонализация, региональная выдача…
- Даже при обновлении выдачи в Яндексе через F5 можно получить совсем другую картинку.
Что со всем этим делать?
- Попробовать использовать несколько инструментов или потратить время на поиск оптимальной комбинации параметров кластеризатора.
- Проверять выборочно выдачу вручную.
- Определить, что важнее — точность (в узких нишах с небольшим количеством запросов) или скорость внедрения. И сместить акцент в сторону ручной или автоматической обработки.
- Обратиться к специалистам по сборке семантики, которые понимают особенность работы поисковиков и сервисов.
С теоретическими вопросами разобрались, перейдем к практике.
Программа для кластеризации семантического ядра KeyAssort
Этим софтом пользуются многие профессиональные оптимизаторы, например, Сергей Кокшаров. Кроме группировки запросов вы получите готовую структуру сайта и списки сайтов-лидеров по каждому запросу.
Что мне еще нравится:
- Быстрая работа: сборка информации из выдачи Google и Яндекс на рекомендуемых параметрах для примерно 2 000 запросов составила меньше 20 минут. Сама кластеризация заняла около полуминуты.
- Сбор данных через прокси или XML (я работаю через XMLRiver).
- Выгрузка в Excel и KeyCollector.
- При объединении фраз в группы учитываются синонимы, транслитерация и похожие написания.
- Перекластеризовать одни и те же фразы можно бесконечно, играясь с настройками.
- Импорт с параметрами (частотка и т.п.) из KeyCollector.
- Импорт выдачи (топов по запросам) из KK. Есть особенность: если нужно импортировать и частотки из КК и URL топов — сначала импортируем частотки, а потом URL. Вместе это сделать не получится через эксель, однако можно импортировать проект Key Collector целиком, тогда импортируются и выдача и дополнительные параметры (частоты и т.д.).
- Импорт готовой структуры сайта для распределения семантики.
- Расширение семантики (ядро уже собрано, сайт уже работает, но хочется актуализировать и дополнить список ключевых фраз).
- Ручная доработка результатов кластеризации.
Еще одна классная штука, которая заслуживает отдельной иллюстрации — миграция запросов, которая заметно повышает точность кластеризации.
KeyAssort при проверке использует не только “силу связи”, но и схожесть запросов. Пример на рисунке ниже. Без миграции запрос 1 и запрос 2 попадают в один кластер, т.к. у них 3 общих URL (сила связи 3).
С миграцией будет осуществлена проверка на максимальную схожесть, а не только на минимальное совпадение. В этом случае будет учтено, что у запроса 2 с запросом 3 общих 7 URL, и запрос 2 будет объединён с запросом 3, а не с 1.

Пример кластеризации и работы с настройками программы
Для теста я использовал готовую семантику с частоткой (регион Пенза, тематика — комбикорм), и стандартные настройки:

Для сбора — сервис XMLRiver (можно использовать Яндекс.XML, если у вас достаточно лимитов):

Кластеризацию будем делать по Яндексу с учетом региона.
Для объективности возьмем 2 варианта семантики для сайта по комбикорму — “грязную” (3257 ключей с инфозапросами и прочим мусором) и чистую (208 коммерческих запросов, весь мусор удалили вручную).
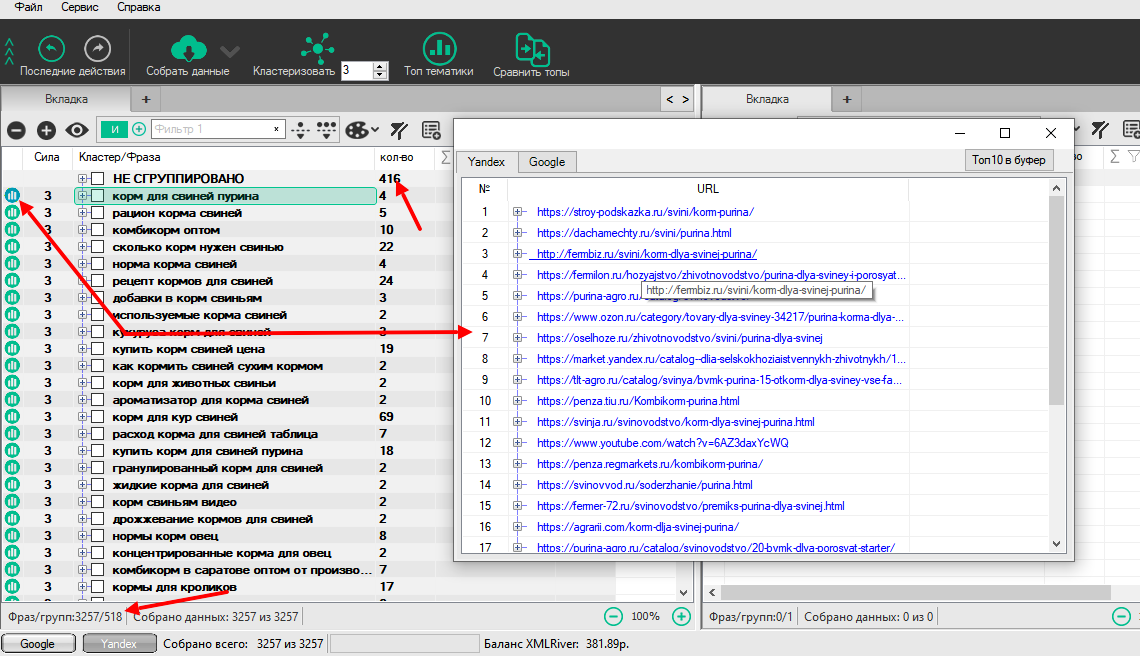
Hard кластеризация грязной семантики
Выбираем нужный вариант, настройки, жмем “Собрать данные” и ждем результаты.

После этого нажимаем “Кластеризовать” (без миграции запросов).

Получаем готовые кластеры, количество запросов в кластере и состав топа, по которому делался анализ.
Количество кластеров — 518 (в нижнем левом углу картинки). 416 запросов не были отнесены ни к одной группе. О том, что с ними делать, опишу в следующем разделе.
Посмотрим отличия результатов кластеризации с включенной опцией миграции:

Меньшее число кластеров, меньшее число несгруппированных запросов. При детальном изучении заметно, что точность группировки выше, чем без миграции.
Большая часть несгруппированных запросов — это мусор:

Soft кластеризация грязной семантики
Количество кластеров меньше, их размер — больше. Несгруппированных фраз стало тоже меньше.

При этом получилось, что в один кластер (опт) попало большее число ключевиков (все подряд, включая информационку):

Middle кластеризация грязной семантики
Промежуточный вариант стал ближе к hard кластеризации, но при этом в группу “опт” попали запросы, которые к интенту (потребности пользователя) имеют отдаленное отношение.

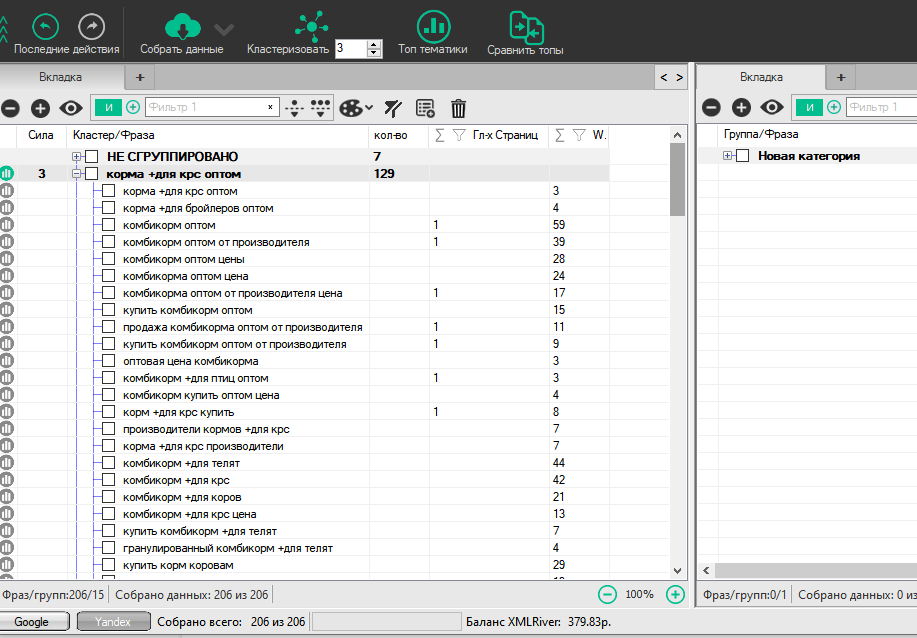
Soft кластеризация чистой семантики
Очень чистенькие кластеры. В малом количестве:

За страшным названием “корма для крс оптом” кроется просто оптовое направление:
Hard кластеризация чистой семантики
Видим, что число кластеров по сравнению с soft-группировкой заметно больше, но и точность тоже стала гораздо выше:

Middle кластеризация чистой семантики
Здесь мне сложно определить качество результата. Все-таки склоняюсь к мнению, что middle — это вариант для информационных ресурсов.

Кластеризация по сайту
В KeyAssort есть возможность привязки к структуре существующего сайта.
Я взял для теста грязную семантику, т.к. 208 запросов распределять по небольшому сайту для теста не сильно интересно. И попробовал сделать софт-кластеризацию.
Структура сайта:
- Главная
- Каталог комбикорма
— Комбикорм для бройлеров
— Комбикорм для перепелов
— Комбикорм для несушек
— Комбикорм для индеек
— Комбикорм на заказ - Состав комбикорма
- Цены и доставка
- Контакты
Для большой семантики все же следует загружать чистый список ключевиков, т.к. результат придется чистить и дорабатывать долго и нудно ручками.

Кластеризация по сайту чистой семантики с теми же параметрами (предварительно собрали выдачу):

Главный вывод: на вход нужно подавать чистые данные и пробовать разные варианты кластеризации, чтобы найти в ходе экспериментов подходящий для вашего проекта. Плюс лучше потратить время на чистку семантики, чем потом вдвое больше на распределение между кластерами вручную.
Что делать с несгруппированными фразами?
Часто в несгруппированные попадают фразы, содержащие название города. Например, “комбикорм оптом в саратове”. Если для нашего проекта такой ключ подходит, и его частота позволит получить трафик — я бы вручную определил такой запрос в один из кластеров. Например, использовал бы на странице для оптовиков для сайта комбикорма.
Второй вариант — попробовать изменить “силу связи” или тип кластеризации, чтобы найти компромисс.
Если же несгруппированные фразы невозможно отнести ни к одной группе, их можно использовать в контекстной рекламе для более полного охвата аудитории.
Расширение семантики
С течением времени формулировка запросов пользователей и состав ключевых фраз в статистике меняется. Поэтому актуализировать семантику — необходимость.
Переработка уже существующей структуры — довольно сложная работа, которая может повлечь за собой множество ошибок. Но в KeyAssort есть возможность автоматизировать этот процесс. Мы загружаем готовый проект (правая колонка), а в левую импортируем новые запросы (или полностью обновленное ядро).

Добавляем новые фразы (в данном случае просто из буфера обмена). Можно загружать все собранные фразы (дубли отсеиваются на этапе импорта):

Новые фразы отмечаем цветом, чтобы видеть, какие кластеры были расширены.

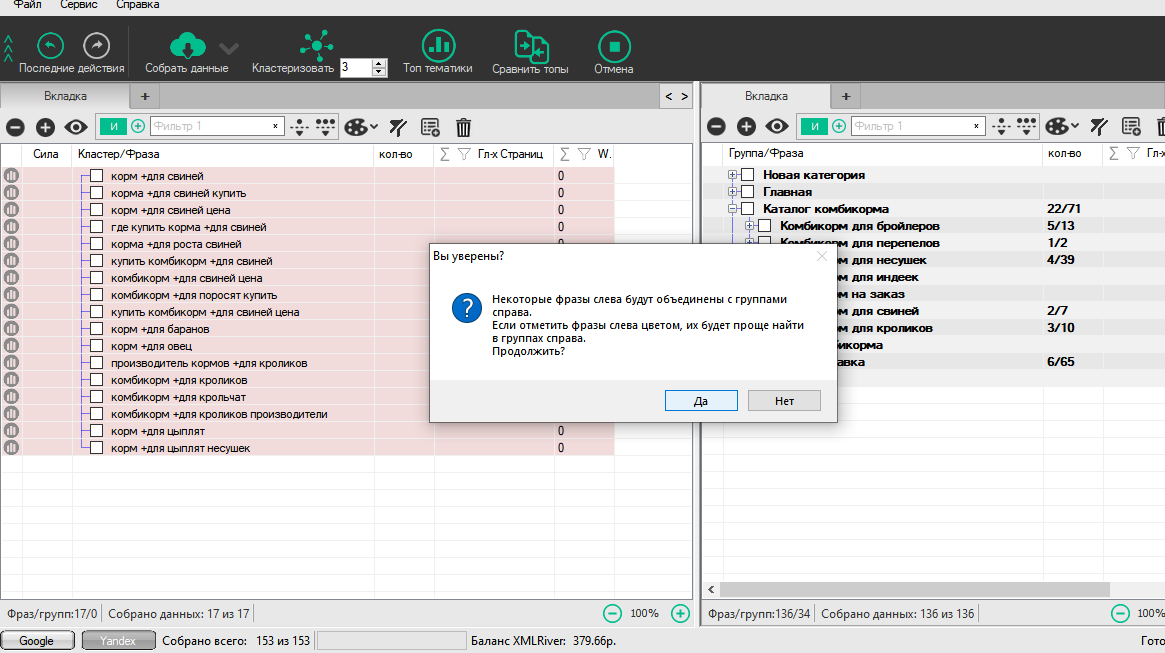
После кластеризации справа выбираем цвет, и видим группы, которые были расширены.

Существующие группы нарушены не были.
Импорт готовой структуры сайта
Можно разделы добавить и в самой программе (правая колонка). Но не всегда это делать удобно.
Файл структуры готовим в блокноте или Notepad++. Табуляцией отбиваем вложенность разделов.

После импорта можно распределять кластеры в готовую структуру сайта:
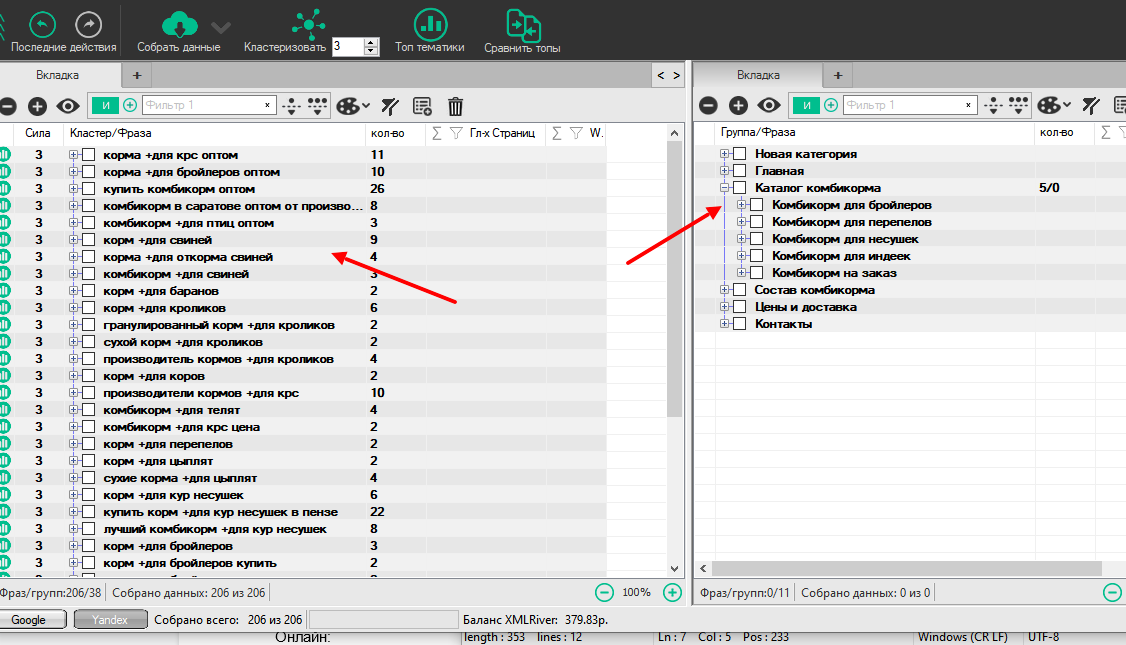
Есть и другие особенности. Рекомендую обратиться к официальному сайту с подробным мануалом.
В любом случае, если еще не знакомы с этой программой — советую скачать хотя бы демо-версию и попробовать.
А как же онлайн-сервисы?
Да, все решения делятся на две большие группы — облачные сервисы и десктопные программы (причем, под Мак решений практически нет).
Как и обещал, даю списки наиболее популярных.
Онлайн:
- Rush Analytics (soft + hard)
- Just Magic (hard)
- Topvisor (soft + hard)
- MOAB.Tools Cluster
Десктоп:
- KeyCollector (не столько кластеризация, сколько “комбайн”)
- KeyAssort (soft + hard + middle)
Основной минус десктопных вариантов — требуется установка, покупка антикапчи, прокси, создание аккаунтов пользователей поисковиков. Это нужно для ускорения сбора данных из поиска (в несколько потоков через технические аккаунты пользователей поисковых систем).
Онлайн инструменты берут указанную выше головную боль на себя. Однако, мне приходилось сталкиваться с ситуациями, когда облачные сервисы после обновления поисковиков не работали несколько дней, и срочно приходилось искать альтернативу в виде софта. Поэтому специалисты, как правило, используют и онлайн-сервисы и компьютерные программы.
В любом случае, главный плюс автоматизации — скорость обработки информации и минимизация ошибок ручной обработки на первом этапе. Вряд ли владелец бизнеса будет ждать год, пока вы разберете качественно несколько тысяч ключей (и не факт, что специалист сделает действительно лучше машины).
Резюме. На что обратить внимание при подготовке семантики для кластеризации
Напомню, что идеальной кластеризации не бывает, но “соломку подстелить” вполне возможно.
Особенности работы с подготовкой семантики:
- На обработку отправляем только чистую семантику, иначе, на выходе будут кластеры с мусором.
- Количество кластеров при hard и soft видах отличается на порядок. Первый вариант наиболее точен, и для коммерческого сайта я бы выбрал именно его.
- Пробуйте разные варианты кластеризации и выбирайте результат, который сможете внедрить, исходя из времени, наличия специалистов по контенту и разработке.
- Обязательна ручная доработка готового результата. Очень заметно, что кластеризаторы не умеют работать с цифрами и числами. Даже при hard-кластеризации в одну группу могут попасть фразы с интентом совершенно разных аудиторий (2021 год, стоимость 2000000 и 5000 рублей).
Буду рад ответить на вопросы в комментариях.
Кстати, поделитесь, какие сервисы используете вы и почему?