
Maksym Kaharlytsky on Unsplash
Команда VK Cloud Solutions перевела историю о том, как инженеры PayPal столкнулись с проблемой обработки данных. Если пользователю требовалось получить определенную строку или выполнить многострочный запрос, данные нужно было дублировать, а для их обработки использовать отдельный стек технологий.
Чтобы этого избежать, в PayPal разработали новую Open-source-библиотеку, которая позволяет быстрее выполнять многострочные и однострочные выборки из больших данных. Во время работы над библиотекой они создали новый формат хранения индексов Avro B-Tree и для пользователей Spark реализовали API на Scala и Python.
Вводные
Spark, Hive и HDFS (Hadoop Distributed File System) — технологии для интерактивной аналитической обработки данных (OLAP). В основном они предназначены для обработки гигантского объема данных, при этом чаще всего с использованием паттерна Full scan, когда мы вычитываем все или большую часть данных, даже если нам нужны только несколько строк.
Но время от времени у пользователей возникают ad-hoc-задачи:
-
Многострочные запросы (Multi-row load) — исследование небольших наборов (около 1%) данных по некоторым ID (неслучайным идентификаторам).
-
Однострочная выборка (Single-row fetch) — получение определенной строки, например, по запросу REST API.
Обычно такие задачи решают с помощью выделенных хранилищ или отдельного стека технологий: HBase, Cassandra и других, что приводит к дублированию данных и росту расходов на эксплуатацию.
Расскажем, как мы в PayPal решили эти задачи, используя только HDFS и Spark. Начнем с описания задачи, затем сформулируем требования к продукту, подберем альтернативы и представим свое решение.
Пример и задача
Платформу PayPal используют более 30 миллионов продавцов. Чтобы выявлять потенциальных мошенников и фиксировать нарушения правил сервиса, мы периодически собираем общедоступную и неконфиденциальную информацию с сайтов клиентов. У многих из них сайты крупные, поэтому при сканировании получаем большой объем информации.
После сканирования данные (и метаданные) за день сохраняем в таблицы в Hive, которые партиционированы по датам. В конкретном примере это около 150 Тбайт сжатых файлов — около двух миллиардов веб-страниц со средним размером страницы 100 Кбайт.
Приложения сервиса PayPal получают доступ к этим данным тремя способами:
-
Полное сканирование. Вычитываем весь объем данных — например, для кластеризации похожих продавцов — на это уходят часы.
-
Многострочная загрузка. Иногда нашим специалистам нужны специфичные подмножества веб-страниц — например, чтобы создать дата-сет для обучения моделей. Ожидаемое время выполнения подобного запроса — несколько минут.
-
Однострочная выборка. В некоторых случаях требуется получить определенную страницу по ее URL. Это должно занимать несколько секунд.

Наша задача — сделать сценарии удобными для пользователей. Тем более, мы заметили, что подобным паттерном доступа к данным пользуются специалисты из разных направлений бизнеса: анализ рисков (транзакции, попытки входа в систему), аналитика по кредитам, маркетологи и другие.
Какие готовые решения мы рассматривали
Таблицы в Hive
Первым очевидным решением было создать таблицы в Hive поверх данных и читать их с помощью Spark. Такой метод отлично сработал при Batch-обработке и полном сканировании — в подобных сценариях Spark проявляет себя лучше всего. Но когда пользователи пытались получить многострочную выборку URL-адресов (обычно 0,1–1% от всех строк), процесс занимал гораздо больше времени, чем ожидаемые несколько минут.
Причины:
- Shuffle — в распределенных системах самая тяжелая операция с точки зрения загрузки процессора и сети. Для небольшого дата-сета URL-адресов Spark использует Shuffle Join (Hash-join или Sort-merge Join). При этом передаются все данные веб-страниц, даже если большинство строк будут отфильтрованы после Join с небольшой выборкой.
- Десериализация: Spark десериализует все данные веб-страниц, даже при Broadcast-join.
Результаты извлечения одной конкретной веб-страницы по запросу REST API оказались еще хуже. Пользователю приходилось ждать несколько минут, пока Spark отсканирует все данные.
Bucketing
Bucketing (бакетирование, кластеризация) — верный путь, по крайней мере для многострочных запросов. Это разделение таблицы на части (бакеты) на основе хэш-функции по колонке, что помогает ускорить join. При этом Bucketing позволяет избежать повторяющихся Shuffle-операций одних и тех же данных. Такой метод требует связи между метаданными и самими данными — а значит, пользователи не смогут добавлять данные напрямую непосредственно в директории, где хранятся данные.
При таком подходе нам нужно использовать Hive или Spark для сохранения данных в бакеты. При использовании Bucketing данные сохраняются в файлах, каждый из которых содержит только определенные ключи и сортируется по ним. Это помогает значительно ускорить операции Multi-row Join.
Но у такого подхода много подводных камней:
- иногда приходится дублировать данные;
- поддерживается только один ключ на таблицу;
- нет готового решения для поддержки однострочных запросов с необходимым нам SLA в несколько секунд;
- реализации bucketing в Spark и Hive несовместимы (SPARK-19256);
- в Spark есть проблема при использовании bucketing и чтении из нескольких файлов (SPARK-24528).
Требования к продукту
Мы поняли, что не существует готового решения, которое позволит реализовать все необходимые сценарии доступа к данным. Поэтому взялись за разработку собственного решения, которое должно было покрыть как можно больше сценариев доступа. На основе своего опыта мы сформулировали такие требования:
-
Размер. Потенциально объем данных огромен — миллиарды строк, каждая из которых может содержать множество столбцов. А в этих столбцах могут храниться большие массивы данных, например веб-страницы.
-
Модификация. Данные только дополняются, но не изменяются. Например, каждый день представляет собой новую партицию с данными — классический сценарий партиционирования данных по дням.
-
Ключи. Данные имеют естественные ключи, и пользователи могут их запрашивать. Ключей может быть несколько, они не обязаны быть уникальными.
-
Владение данными. Данные могут принадлежать другой команде, и мы не сможем изменить их формат, расположение и другие характеристики.
Наши требования:
- Пользователи должны взаимодействовать с данными тремя способами: пакетная аналитика, многострочная и однострочная выборки в соответствии с SLA.
- Необходимо избегать дублирования данных, чтобы не повышать стоимость хранения и операций вычисления.
- Требуется поддерживать несколько ключей.
- Желательно использовать тот же стек технологий.
Почему нам не подошли существующие решения по индексации
Сформулировав требования, мы поняли: нужен другой подход. Естественно, в голову пришла индексация. Смысл в том, чтобы создать некий тонкий слой с метаданными и указателями на «реальные» данные: так мы перенесли бы на него основную нагрузку и избежали бы работы с данными напрямую.
Технологию индексирования широко используют почти во всех доступных базах данных, даже в среде Big Data. Например, в Teradata, Netezza, Google BigQuery и многих других. Было бы здорово добавить эту возможность в экосистему Spark.
Мы исследовали предыдущие попытки других команд действовать в этом направлении и нашли Hyperspace от Microsoft — наработки по интеграции подсистемы индексирования в Spark. У продукта были общие черты с тем, что нам нужно, но текущая функциональность не соответствовала ожидаемым сценариям использования.
Тогда мы продолжили создавать свою систему индексации и интегрировать ее в Spark, Hive или HDFS.
Что было не так с сервисами на основе «ключ-значение»
Для оптимизации много- и однострочных запросов нам нужен быстрый способ выполнения запросов «ключ-значение». Для этого логично использовать сервисы на основе «ключ-значение» (Key-value). На выбор есть много вариантов: HBase, Cassandra, Aerospike и другие. Но у такого подхода четыре недостатка:
- Для нашей задачи он избыточен. Такие технологии используют для обработки куда более сложных сценариев с меньшей задержкой.
- Такие системы хранят данные внутри себя, а следовательно, вам нужно «владеть» данными или дублировать их, хранить в исходной системе и в Key-value store.
- Это отдельные сервисы, они требуют специальных ресурсов и предполагают расходы на поддержку, настройку, мониторинг и другие операции.
- Подобные системы используются Real-time критическими приложениями. Значительная аналитическая Batch-нагрузка снизит общую производительность системы, вызывая задержку в критически важных Real-time-приложениях.
Решение: разработать свою библиотеку
Поскольку готовые методы не соответствовали нашим требованиям, мы решили разработать новую Open-source-библиотеку — Dione. Основная ее идея в том, что индекс представляет собой «теневую» таблицу исходных данных. Он содержит только столбцы с ключами и указатели на данные. Таблицы сохраняются в специальном формате, который был разработан нами на основе идей Avro и Bucketing-подхода. Благодаря таким индексам библиотека позволяет группировать, объединять и извлекать данные в рамках наших сценариев и требуемых SLA.

У индекса те же номера строк, что и у оригинальных данных, но он содержит только столбцы с ключами и ссылки. И сохраняется в специальном формате Avro B-Tree
Основные преимущества:
- Взаимодействие только со Spark, Hive и HDFS — никаких внешних сервисов.
- Мы не изменяем, не дублируем и не перемещаем исходные данные.
- Можно использовать несколько индексов для одних и тех же данных.
- Индексы представляют собой стандартные Hive-таблицы.
- Наш специальный формат Avro B-Tree поддерживает однострочную выборку, которая выполняется за секунды, что соответствует SLA.
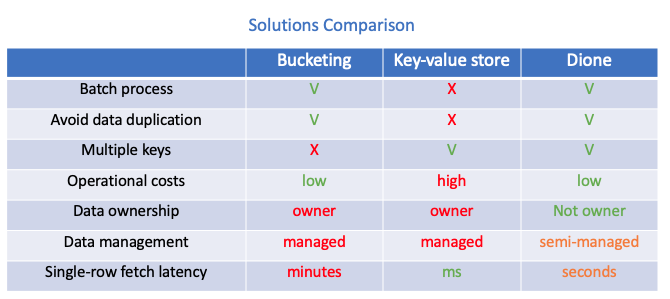
Сравнение предложенных выше решений с Dione
Dione решает две основные задачи: как быстро получить данные и организовать хранение таблицы с индексами, чтобы соответствовать SLA. Для этого мы разработали два основных компонента: Indexer и AvroBtreeFormat. Итоговое решение работает на основе взаимодействия между Indexer и AvroBtreeFormat, хотя, в принципе, каждый из них может работать отдельно.
Indexer
Основная цель Indexer — решить вопрос с многострочной загрузкой. У компонента две основные функции.
1. Создание индекса. Он сканирует данные один раз и извлекает соответствующие метаданные. Индекс сохраняется в виде стандартной таблицы в Hive, доступной пользователям для чтения. Сейчас мы поддерживаем индексирование данных в форматах Parquet, Avro и SequenceFile и планируем поддерживать больше форматов в будущем.

Indexer сканирует данные и сохраняет нужные метаданные в каждой строке, чтобы мы могли обратиться к ним позднее
2. Использование индекса. Чтобы быстро извлекать исходные данные, мы предоставляем API на основе метаданных. Благодаря этому пользователи могут читать таблицу с индексами как обычную таблицу Hive, фильтровать ее, используя стандартный Hive/Spark Join со своей выборкой данных, и использовать API для чтения исходных данных на основе получившегося в результате join дата-сета. Так мы избегаем Shuffling и десериализации всех данных.
Avro B-Tree
Сами по себе Spark и Indexer не решают задачу выборки одной строки за несколько секунд. Поэтому мы решили использовать еще одно доступное нам средство — формат хранения индексов. Вдохновленные Avro SortedKeyValueFile, Bucketing-подходом и традиционными системами индексации баз данных, мы решили создать «новый» формат файлов — Avro B-Tree.
С технической точки зрения это просто файл, совместимый с любой программой для чтения форматов Avro. Но мы добавили в каждую строку еще одно поле со ссылкой на другую строку в этом же файле. А еще отсортировали строки в каждом файле в B-tree-порядке. Теперь, когда нам нужно выполнить случайный поиск и достать данные по ключу, мы минимизируем количество переходов при чтении файла.

Мы используем блоки Avro в качестве узлов B-дерева. Каждая строка может указывать на начало другого узла
Чтобы понять, как мы используем такой формат файла в нашей системе, давайте посмотрим на результат работы компонента Indexer. Данные индекса сохраняются как «теневая» таблица исходной таблицы данных. Файл имеет такую структуру:
-
Каталоги. Каждый каталог содержит конкретные данные — например, за определенную дату (стандартное партиционирование).
-
Файлы. Каждый файл содержит строки с одним и тем же хэш-значением, как при Bucketing.
-
Формат. Строки в файле сохраняются в структуре B-дерева.
Когда пользователь инициирует API-запрос на выборку одной строки, мы можем по заданной дате перейти прямо к запрошенной папке, затем по хэшу ключа к нужному файлу, и далее внутри файла используем B-tree, пока не найдем запрошенный ключ. Этот процесс занимает около одной секунды и соответствует нашим требованиям.
Преимущества такого решения:
- совместимость с форматами Avro;
- хорошая поддержка Random-access-чтения из файла;
- B-дерево минимизирует количество переходов при поиске по индексу;
- Avro сохраняет данные в блоках, поэтому мы установили каждый блок равным размеру узла дерева.
API Dione для пользователей Spark
И Indexer, и Avro B-Tree File Format — независимые библиотеки, основанные только на HDFS. Пользователи могут сохранить любую таблицу в формате Avro B-tree, чтобы она была доступна для пакетной аналитики (Batch) с помощью Spark и однострочной выборки. В нашем решении мы используем оба пакета для полной индексации.
Чтобы пользователям Spark было проще, мы разработали высокоуровневый интерфейс для работы с индексами. API доступен на Scala и Python.
Примеры кода для создания и обновления индекса
Определить индекс для таблицы
crawl_data. Запускаем один раз: from dione import IndexManager
IndexManager.create_new(spark,
data_table_name="crawl_data",
index_table_name="crawl_data_idx",
keys=["url"],
more_fields=["status_code"])Сканируем таблицу данных и обновляем индекс. Запускаем при обновлении таблицы данных:
im = IndexManager.load(spark, "crawl_data_idx")
im.append_missing_partitions()Примеры кода с использованием индекса
Многострочная загрузка:
query_df = spark.table("crawl_data_idx").where("status_code=200")
im.load_by_index(query_df, fields=["id", "content"])
Однострочная выборка:
im.fetch(key=["http://paypal.com"],
partition_spec=[("dt", "2021-10-04")],
fields=["content"])Вывод
Мы создали Dione — библиотеку индексирования Spark, чтобы пользователи могли в равной степени пользоваться одно- и многострочной выборкой. Мы открыли исходный код этой библиотеки, чтобы поделиться с сообществом функциональностью и получить отзывы.
У нас уже есть много открытых вопросов с интересными функциями и направлениями, которые мы можем добавить к основной функциональности, включая оптимизацию join-операций, улучшенную интеграцию со Spark, возможность резервного копирования и многое другое.
Команда VK Cloud Solutions тоже развивает экосистему для построения Big-Data-решений. На платформе доступна Open-source-сборка от Hortonworks, а также Enterprise-ready-решение на основе дистрибутива Hadoop от Arenadata. Вы можете попробовать любую из этих сборок. Новым пользователям мы начислим 3000 бонусных рублей на тестирование сервисов.
Что почитать по теме:
sshikov
Сама идея очевидна и не нова, и даже простое хранение данных в колоночном формате типа паркета уже позволяет вычитывать только ключ вместо всей строки, и это уже дает приличное преимущество при выборке.
Но индекс, который не обновляется при добавлении и обновлении данных, будет работать ровно до этого обновления. Судя по тексту, обновление индексов реализовано. Но самое важное опущено — это время этого обновления, то, насколько оно эффективно. А также то, является ли оно атомарным, потому что таблицы в Hive, в общем случае, не транзакционны.
>Этот процесс занимает около одной секунды
Хм. А данных-то при этом сколько?
И судя опять же только по тексту, построение индекса — это тот самый фуллскан, как минимум — на добавленные/изменившиеся данные, то есть это может быть совсем даже не быстро. А если изменившиеся данные не сосредоточены в одной партиции — то просто фуллскан всей таблицы. Так что, данных по производительности де факто ноль, потому что приведенные циферки не указывают объема данных, и потому правильно интерпретированы быть не могут.
Без циферок по производительности — пока в значительной степени маркетинговый текст. И еще не хватает данных о том, какие версии (например Spark, Hive) поддерживаются.