Дайте базу мне, базу мне дайте!
Всякой всячины там наваляйте!
Промунгуем, закнаймим, распишем.
Визуально (при помощи мыши).
В предыдущей статье я вкратце упомянул, что Knime умеет работать с базами данных, в том числе с NoSQL базой MongoDB. На мой взгляд, MongoDB является довольно простым и эффективным решением для хранения информации, представленной в виде коллекций документов, состоящих из различных наборов полей и, по сути, являющихся обычными JSON файлами. Мне показалась интересным попробовать связку Knime - MongoDB в действии. Именно этой связке и посвящена данная статья.
Будем считать, что MongoDB уже установлена на локальном компьютере или на отдельной машине, и к ней есть доступ. Рассмотрим варианты работы с этой базой, которые предоставляет Knime после установки расширения MongoDB Integration. Различные компоненты, предоставляющие доступ к MongoDB представлены в репозитории узлов в следующем составе:

Первым необходимым узлом является узел "MongoDB Connector". Именно этот узел обеспечивает подключение к локальной или удаленной базе данных. Из настроек узла здесь требуется задать только имя узла, на котором развернута наша база и порт. В самом простом случае, если база установлена локально, это будет localhost:27017.
Если база уже существующая, и в ней есть коллекции, то для обращения к ней используется узел "MongoDB Reader". Его использование достаточно удобно, так как в настройках узла сразу отображается содержимое всех баз и всех коллекций, присутствующих в используемой СУБД. Выглядит это так:
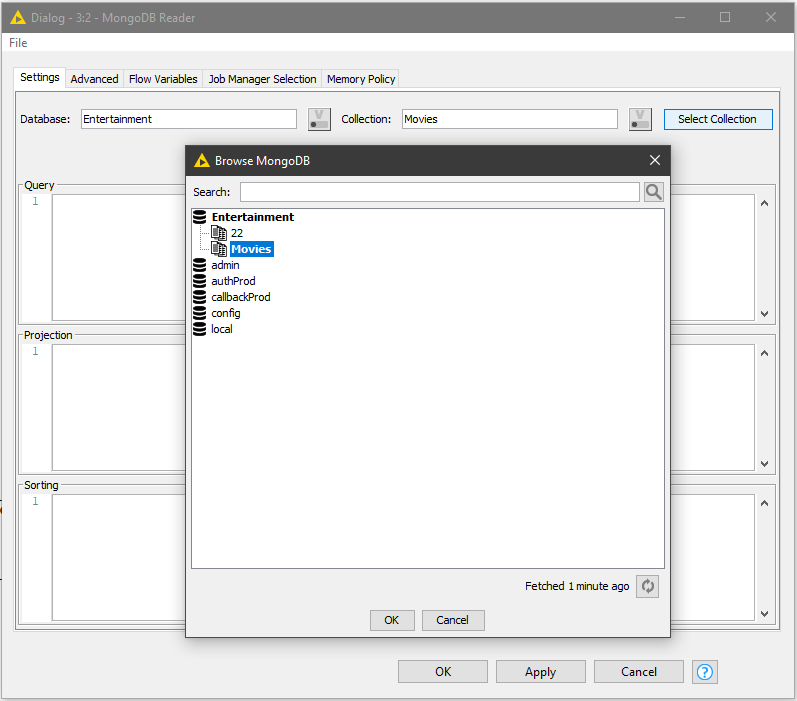
Обратите внимание, что в настройках узла имеются разделы Query - для ввода фильтра отбора документов из выбранной коллекции, Projection для задания интересующих полей в выбранных документах и Sorting - разумеется для сортировки отобранных документов. Эти разделы соответствует аналогичным, которые мы можем увидеть в MongoDB Compass, классическому GUI для доступа к MongoDB:
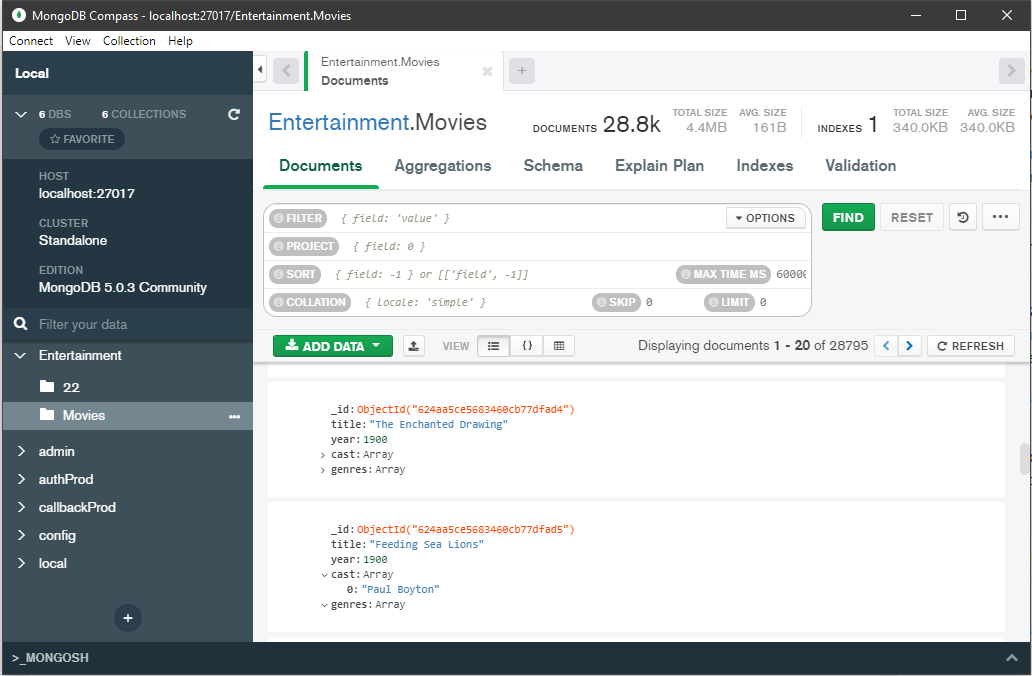
Опции Skip и Limit, которые видны на рисунке Compass, в Knime находятся на вкладке настройки узла "Advanced".
Проблема MAX TIME MS
К сожалению, мне не удалось найти способ использовать в Kniime опцию MAX TIME MS, которая ограничивает время обработки запроса к базе. Если кто-то разберется, как это сделать - буду очень признателен. Ибо в некоторых случаях это очень полезная штука. Потому, что если "зависает" запрос к MongoDB, то это не прерывается кнопкой "отменить выполнение". В принципе, проблема "зависания" здесь все равно решается: надо просто закрыть и открыть снова проект. Система уведомит, что не может записать выполняющийся узел, но все остальное корректно сохранится и откроется снова.
Если поле Query оставить пустым, то данный узел считает всю коллекцию целиком. И представит ее в виде таблицы Knime с полями типа JSON.

Давайте попробуем сразу при обращении сформировать требуемый нам фильтр запроса. Отладку запроса удобно производить в Compass, а потом просто перенести его в Knime. Например, я хочу выбрать наиболее полные записи, убрать служебное поле и отсортировать в обратном порядке данные из коллекции документов о фильмах:
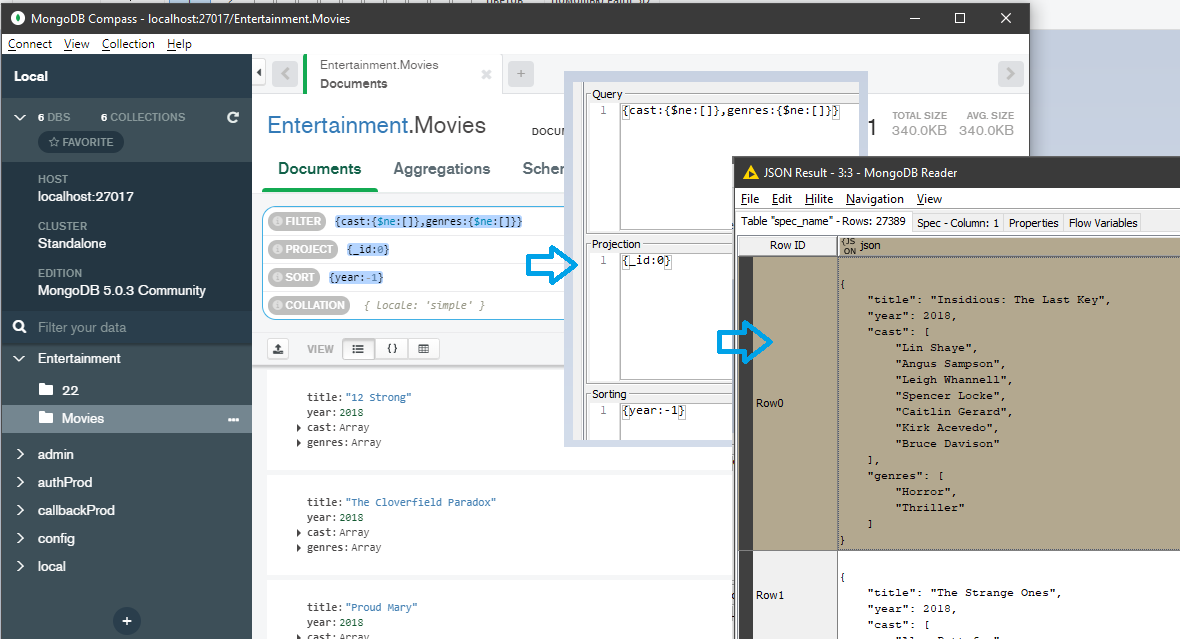
Делаем три копипаста и Knime корректно отрабатывает запрос, считывая необходимые нам записи.
Целесообразно в ходе анализа данных основную часть "рутины" поручить именно MongoDB, а для Knime оставить уже более "интеллектуальную" часть анализа. Это связано с тем, что Mongo сама по себе лучше оптимизирована для исполнения поиска, отбора, сортировки собственных записей и может использовать при этом заранее созданные поисковые индексы.
Под "интеллектуальной" частью анализа я здесь подразумеваю различного рода подсчеты, группировки, сортировки, состыковки данных из разных источников и тому подобное. В принципе, часть этого процесса тоже можно предоставить MongoDB при помощи механизма агрегации, который представлен узлом MongoDB Aggregation, но мне такой подход не очень понравился так как требует составления и отладки сложных запросных конструкций. А это уже вовсе не так оперативно, как хотелось бы.
В общем, на текущем шаге мы считали нужные данные из базы документов в формате JSON. Для удобства работы хорошо бы перевести его в формат таблиц Knime.
Для работы с JSON Knime также предлагает множество узлов в репозитарии.

Простейший способ, который не требует практически никаких настроек узла, это использование "JSON to Table". В этом случае, просто получаем таблицу всех полей JSON (включая списковые). Для более избирательного преобразования, можно использовать узел JSON Path, в котором уже присутствуют более тонкие настройки выбора, включая доступ к элементам многоуровневых массивов, назначение типов считываемых полей, добавление только нужных полей JSON. Так мы получим уже классическую таблицу для дальнейшего анализа средствами Knime.
Давайте попробуем определить пока простые вещи, которые доступны из имеющейся у нас небольшой и несложной таблицы. Например, воспользуемся узлом GroupBy, подсчитаем количество фильмов, выпущенных в каждом году и отобразим полученные результаты в виде таблицы и графика.
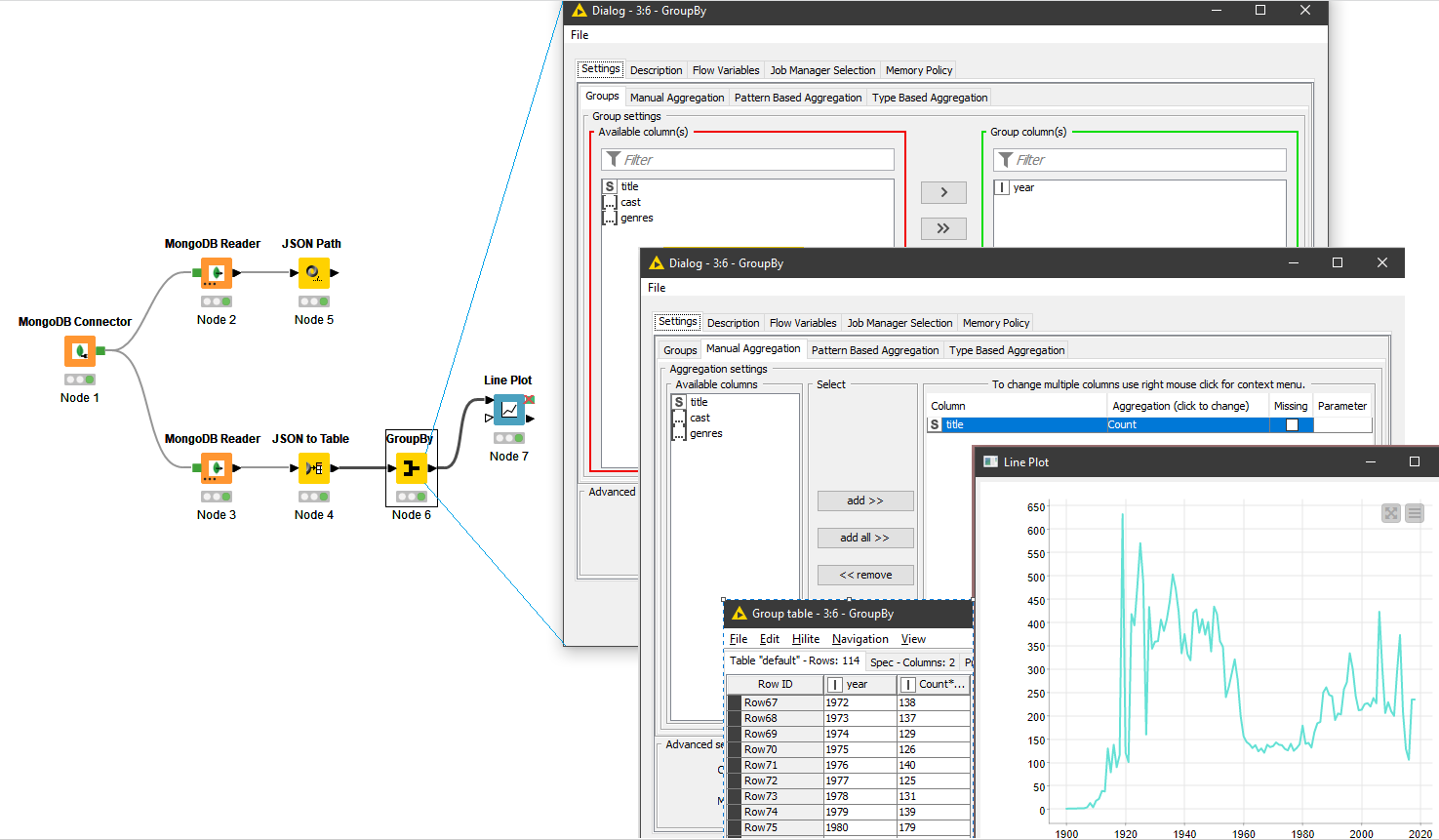
Чуть более сложный вариант - попробуем найти современных актеров, которые снимаются чаще всего. В чем тут сложность? В том что в нашей таблице имена актеров представлены для каждого фильма в виде списка. Для подсчета их придется преобразовать. Общая схема обработки будет выглядеть так:
Преобразовать столбец-список "актеры" в набор независимых столбцов (Split Collection Column);
Продублировать строки упоминаемых фильмов для всех упоминаемых актеров путем "разворачивания" таблицы (Unpivoting);
Произвести группировку по актерам (GroupBy);
Отфильтровать по количеству участия в фильмах
Отсортировать по году последнего фильма, в котором актер принимал участие.

В итоге такой цепочки анализа выясняется, что наиболее востребованными и снимающимися до сих пор актерами (по имеющимся данным на 2018 год) являются, в частности, товарищи Брюс Уиллис, Алек Болдуин и Семюэль Джексон. С чем мы их и поздравляем.

Можно продолжать анализ дальше, придумывать новые запросы и визуализации, однако для текущей статьи приведенного примера вполне достаточно.
Основной вывод, который делаю я, заключается в том, что использование связки MongoDB - Knime достаточно эффективно и удобно как минимум, в случае использования MongoDB в качестве неизменяемого хранилища и Knime для обработки выборок из этого хранилища. Альтернатива такой связке - это, например, стандартное хранение данных в виде CSV-файлов и их загрузка в Knime соответствующими узлами. Но такой вариант требует больше места для хранения файлов и оставляет всю нагрузку обработки для Knime.
Практика, также, показала, что совершенно спокойно и достаточно быстро обрабатываются коллекции MongoDB объемом под 500 000 000 документов (при условии корректного формирования индексов и выполнения грамотных запросов/фильтров).
Связка - работает!