
С чем у вас ассоциируется Лернейская гидра из известных мифов и легенд? Наверное, с кучей ядовитых голов, приносящих одни проблемы. Отрубаешь одну, появляется другая. Наверное, поэтому плохой код ассоциируется у меня с тем же самым. Думаю, каждый, кому приходилось иметь дело с плохим кодом, сталкивался с кучей таких «хищных голов». А в связи с тем, что платформа 1С очень распространена на территории стран бывшего СССР (а сейчас уже и за пределами), то с плохим кодом конфигураций 1С встречался чуть ли не каждый первый ИТ-шник.
В статье я расскажу свой путь, которым я прошел, пытаясь комплексно решить проблемы тормозов 1с. И как, решая одну проблему, приходилось сталкиваться с двумя-тремя новыми. Ну и о том, каких помощников я встретил на этом нелегком пути.
Но давайте от лирики к практике. Сейчас моя разработка — это уже готовое решение, созданное с использованием современных подходов и технологий. Я разработал его для комплексного решения проблем с производительностью конфигураций на платформе 1С. В планах у меня это было еще много лет назад, но я не думал, что до релиза пройдет столько лет.
Часть первая. Сказ о том, как мечты мальчика воплощаются в реальность
«Опять все тормозит!»
«Настройте уже ваши компьютеры, работать невозможно!»
«Да сколько можно мотать мне нервы - у меня проводка делается уже час!»
«А программист мне сказал что проблема с базой данных!»
Знакомые фразы? Да, для любого инженера по инфраструктуре они очень знакомы. Вот я их слышал не раз, не два и даже не миллион за более чем 20 лет ИТ. Ситуацию осложняло то, что вычислить, на каком этапе происходит ошибка, было невозможно. Вот так выглядит стандартный алгоритм решения проблемы тормозов 1С:
Идем к разработчикам 1С.
Получаем ответ о вине отдела инфраструктуры.
Обвешиваем все системы мониторингом, собираем данные. Если повезло – находим проблему, устраняем.
Если не повезло - снова идем к разработчикам 1С.
И снова получаем ответ, что проблема в инфраструктуре.
Обвешиваем все что можно еще большим количеством метрик, и если повезет – решаем проблему. А если не повезет – то снова к разработчикам…
И так до бесконечности…
Хотя справедливости ради должен сказать, что разработчики 1С ходят к инженерам по инфраструктуре примерно с такими же результатами…
Тогда и зародилась идея разработки программного обеспечения, которое точно укажет источник ошибки и даст возможность быстрее исправить ее. Работа проводилась методом проб и ошибок – большооооого количества проб и огромного числа ошибок…
Вторая часть. Наивность и жестокая реальность - итоги столкновения…
Технологический журнал… Многие слышали, не многие видели, а еще меньше понимают, что это и как этим пользоваться… Таков был мой вывод после первый двух недель изучения вопроса. «А что это за зверь такой - технологический журнал?» - спросит меня дорогой читатель. Да нет, не спросит, на самом деле, ибо все, кто работает с 1С о нем слышали. В теории этот инструмент должен показывать и рассказывать кто и что болит. Но даже с моим многолетним опытом ИТ-инженера разобраться в нем было ну очень сложно. А ведь делать это нужно каждый раз… Нескончаемое количество раз.
«Бросить курить очень легко! Я сам уже бросал много раз» - эта фраза Марка Твена вспоминалась мне каждый раз, когда я в очередной раз начинал разбираться с технологическим журналом. А начинал я это делать много раз.
«Ну ладно, смысловая нагрузка придет походу!» - решил я и начать с малого - разобрать технологический журнал и сложить его в базу для дальнейшего анализа. И, вполне закономерно, потерпел фиаско - инструментария, описания и хоть какой-то информации не было. Так закончился мой первый заход, и история была отложена на долгих 3 года до тех пор, пока под моим началом не появились совсем уж крупные базы на тысячи пользователей и терабайтные базы. И тут жизнь меня окунула снова в этой волшебный мир производительности 1С.
Третья часть. История о том, как на собственном опыте убедиться, что больнее всего ходить по детским граблям…
Первым просветом в этом черном царстве незнания стала статья Юрия Пермитина (огромное ему спасибо за вклад в дело привнесения знаний в массы) с «почти полным описанием событий технологического журнала». Эта было первый раз, когда стало хоть что-то проясняться и обретать какой-то смысл. И была сделана вторая попытка разобрать технологический журнал и положить его в базу.
Структура технологического журнала вообще достаточно специфична - много параметров, пробелы, кавычки и прочие разные прелести в значениях, ключи с одинаковыми именами. А еще объем данных. Нужен был инструмент, который бы умел работать со всем этим. И что скажет среднестатистический инженер? Правильно - стек ELK (Elasticsearch, Logstash, Kibana). И я тоже был не оригинален - выбрал ELK за основу. Я даже успел порадоваться, правда не очень долго, и «через каких-то полгода» у меня получилось хоть что-то. Первый прототип состоял из:
filebeats - разбирал на сервере технологический журнал на отдельные сообщения
logstash - разбирал сообщение на key-value
plugin для logshash для записи в clickhouse
«Ну и что тут сложного?» - спросите вы. На первый взгляд – ничего. Но дьявол, как известно, кроется в деталях.
-
Многострочность. Все вроде бы просто и очевидно – в filebeats есть настройка много строчных записей, но тут возникает два момента:
Длина строчки. У меня попадались экземпляры более 100 мегабайт в одну строку.
Скорость записи. Если запись не успевала закончиться между двумя опросами – строчка терялась.
Одинаковые названия ключей с разными значениями. О, эти «чудеснейшие» каскады if-ов, эти зубодробительные регулярные выражения, различные варианты запитых и их отсутствие или присутствие.
Отсутствие возможности собирать ошибки разбора и записи. Вернее, они в теории были, но воспользоваться ими в нормальном режиме мне так и не удалось.
Ресурсы. Java не самый лучший выбор для работы с текстом в потоке. Периодически я получал просто зависшую виртуальную машину, где все 8 процессоров были съедены процессами java разбирающими технологический журнал.
Место на дисках. Elasticsearch отличный инструмент, но вот дисковое пространство он потребляет без всякого зазрения совести. По итогу неделя технологического журнала занимала 3 терабайта места. И это только одна база.
Так появился мой первый универсальный разборщик для технологического журнала. Ну вроде как все получилось, но разве это конец? Нет — это только самое начало.
Часть четвертая. И тут Алиса начала осознавать, насколько глубока эта кроличья нора
Ну что ж… Технологический журнал разобрали, в нем можно что-то искать, и даже без особых усилий. И снова «голова Гидры»: как из полученных в разборщике данных вывести четкую аналитику с указанием конкретной ошибки?
Задача, я вам скажу, не из легких. И хороших специалистов в этой области раз, два и все. А человеку «не из тусовки» так вообще не понятно, где начинать искать. Но в одном из сообществ мне посчастливилось познакомиться с Никитой Федькином (ранее Грызловым). Он то и начал стал моим первым сенсеем на пути получения сакрального знания о производительности 1С.
Началось все очень банально – я в наглую постучался к нему в телеграмме, благо Никита, человек публичный, и найти его контакты не составило больших проблем. Описал задачу, рассказал про свою задумку и, о чудо, Никита меня поддержал! (Спойлер – Никита один из первых получил мое приложение, и сейчас активно использует его в своей работе давая бесценные советы по его улучшению). Мы собрались в Zoom-е, я показал наработки, Никита дал советы и я ушел думать – как это все реализовать.
И тут в полный рост встал вопрос с показом данных. Ну и как обычно выбор был сделан в пользу общеизвестных инженерных инструментов - Grafana. Все там нарядно, и графики есть красивые, и источник данных в виде Elasticsearch поддерживается. Но вот уже на 3-м графике стало понятно - не то. Не получается делать логику только на одних запросах, нужен еще промежуточный слой.
Так появилось понимание, что нужно писать свой интерфейс. И понеслась - 5 месяцев жизни - и он все-таки появился.
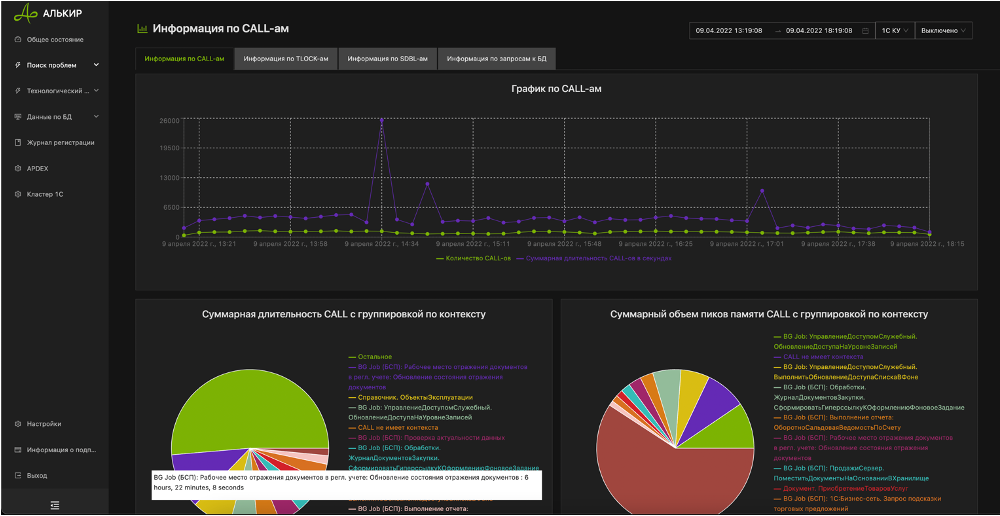
В это же время мне удалось найти решение проблемы хранилища. Я был не в восторге от работы с Elasticsearch как с хранилищем логов – занимает много, ищет не так быстро, как хотелось бы, нет возможность работать с данными в обычными sql-запросами. И в один прекрасный момент на одном из проектов я познакомился с БД от Яндекса – ClickHouse. Уже через неделю я понял, что это то, что мне нужно и перевел туда запись данных. И не пожалел. Вместо 1,2 терабайт логи стали занимать 87 гигабайт. Меня это очень порадовало.
Следующим шагом стало написания своего разборщика технологического журнала на golang. И это оказалось верным решением. Потребление ресурсов существенно сократилось, появилась возможность обработки ошибок и повторного проигрывания проблемных сообщений, возможность быстрой доработки под мои требования – получилось хорошо.
Потом стало понятно, что нужно прикручивать сбор данных с консоли кластера. Прошелся я, как водится, по GitHub-у и понял, что все варианты - это разбор вывода консольной утилиты rac от 1С. Ну и еще один проект на golang, с реверсом протокола. Опечалился. Пришел к Никите и говорю – «Никита, ты ж умный, что делать?» А он мне – «Не кручинься друг, сделаю тебе волшебную утилиту, на java написанную, на базе библиотеки от производителя, и будет он тебе данные поставлять.» И не обманул, написал. И не только со сбором данных о текущих сессиях и параметрах rphost-ов, но и с возможностью управлять базой – создавать, блокировать, удалять сессии пользователей. И все это без необходимости каждый раз перерегистрации dll! Я был в восторге.
После все этого доделать сбор информации о работе MSSQL было уже совсем просто - сделали хранимую процедуру, со всеми необходимыми запросами, выдали ей нужные права, создали отдельного пользователя с минимальными правами - и готово. Данные о работе MSSQL появились в моем приложении.
На все это у меня ушло достаточное количество времени, нервов, сил. Но главное, все было не напрасно. Я видел результат, и он мне нравился.
Смог или не смог? Анализ конкурирующих подвигов
После получения готового продукта мне стало интересно просмотреть похожие предложения на рынке. Ведь аналоги моего продукта есть, но везде свои нюансы. Их оказалось не так много.
Система 1С КИП. Выполняет весь тот функционал, что и мое приложение, но вот написана на базе 1С. И на выходе мы получаем опять сложную для понимания утилиту, в которой затруднена работа с большими объемами данных и сделана разработчиками для разработчиков.
Давно известные сервисы Гилева. Долгие годы этот продукт был одним из лидеров. Но как же без минусов. Основной – это невозможность внедрить утилиту во внутреннее облако компании, что для многих сейчас может стать непреодолимым препятствием.
Продукт компании Softpoint - специализированный программный комплекс «PERFEXPERT». Отличный продукт, но для работы требуется исключительно Microsoft, установка агентов, изменение кода конфигурации, данные только через консоль (никакого web-а). И разбор ведется в основном со стороны БД, поэтому некоторые нюансы работы 1С упускаются. Это уже из другая история.
Я выделил на мой взгляд, сильные стороны своего приложения:
-
Минимальное влияние на боевую инфраструктуру:
доступ к технологическому журналу и журналу регистрации происходит через файловую шару
данные о структуре БД и APDEX-е собираются через устанавливаемое расширение конфигурации
-
Вопросы информационной безопасности:
доступ требуется только до http-сервиса – для этого можно сделать отдельную учетную запись
не требуется прав на базу данных – все данные получаются через хранимую процедуру. Пользователю выдаются права только на запуск это хранимой процедуры. (права администратора БД требуются только на момент создание хранимой процедуры и это может сделать сотрудник компании)
все данные хранятся в периметре компании
Единый интерфейс для многих конфигураций
Сбор и анализ данных работы самого кластера 1С
Как показало это небольшое исследование, подобных моему приложению продуктов, которые бы совмещали в себе и БД, и специфику 1С, и удобство пока нет. Я уважаю и ценю труд моих коллег, каждая программа уникальная по-своему, и в каких-то задачах им нет равных. Но и мой продукт оказался востребованным. Уже сейчас мы внедряем его в тестовом режиме. И мы не останавливаемся на достигнутом. Дальнейшее развитие предполагает еще более упрощенную систему получения информации об ошибках, проблемах, причем без временных задержек. Так что новые подвиги на подходе!
А мне то это зачем? Проблемы, которые решает мое приложение
Я думаю, что большинство прочитав этот текст спросят: «Ну и? Мне чем может помочь мое приложение? Много красивых слов – профит то какой?». Вопрос весьма уместный и вот что я по этому поводу могу рассказать:
Разбор технологического журнала, с группировками и предварительной обработкой событий. К примеру, у нас реализован механизм показа информации о модулях, запущенных в рамках БСП (ДлительныеОперации.ВыполнитьСКонтекстомКлиента)
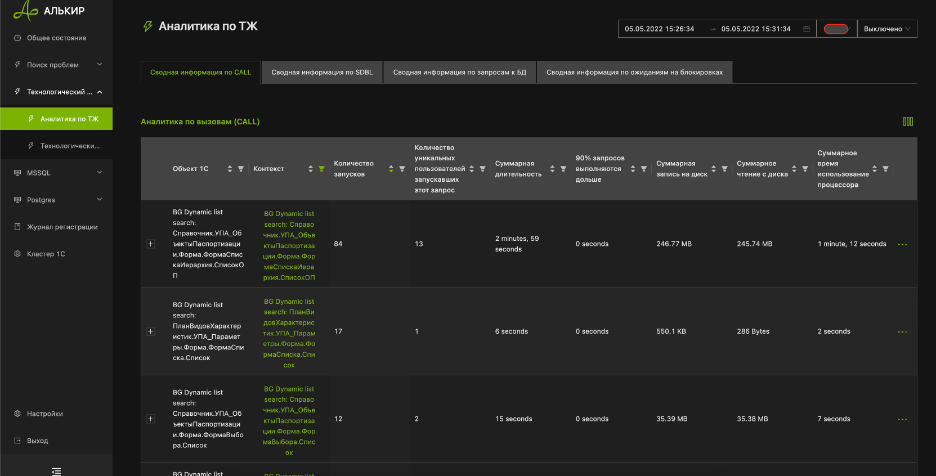
Реализован автоматический поиск виновников блокировок 1С с показом контекста, области и параметра блокировки
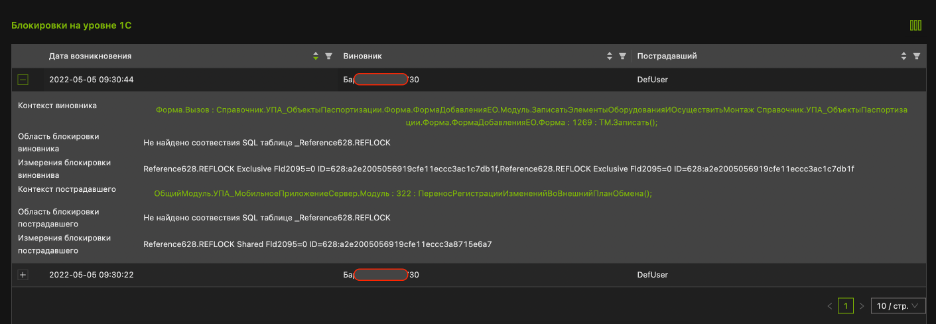
Реализован показ модулей, запущенных в фоновых заданиях в реальном времени

Реализована интеграция с APDEX-ом
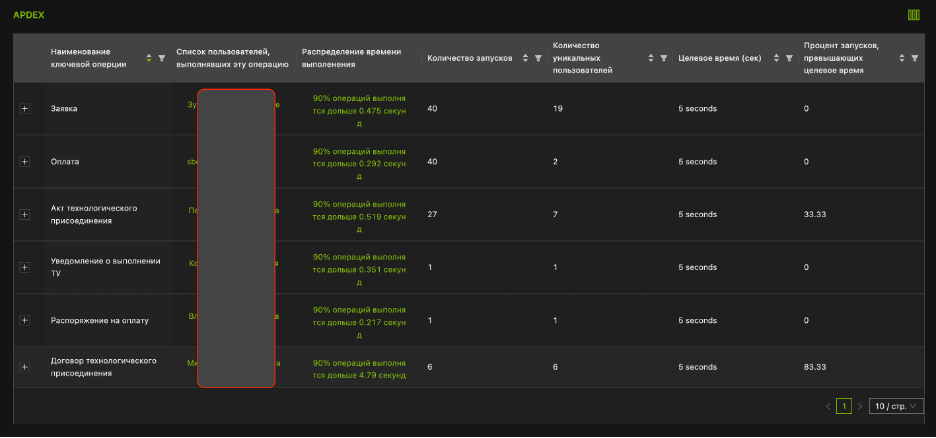
Базы данных представлены в виде таблиц и индексов, которые понятны пользователям
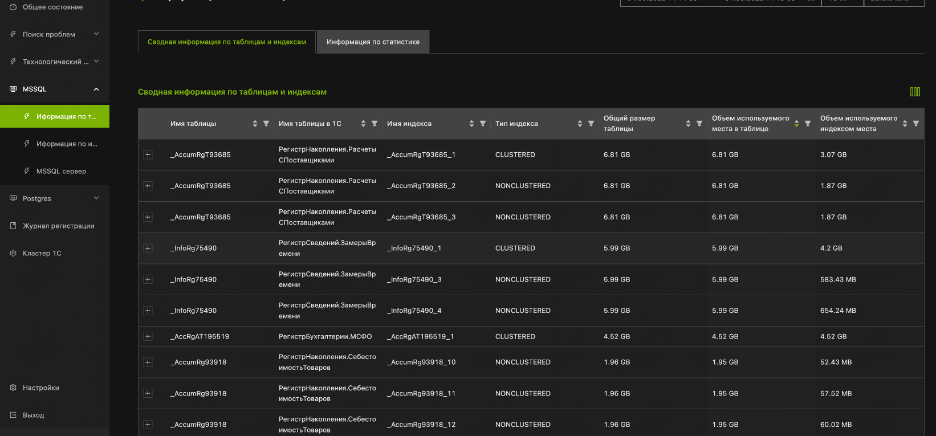
Можно легко источники проблем используя различные выборки
Реализован быстрый и удобный поиск по журналу регистрации и технологическому журналу
Долгосрочное хранение, поиск, анализ, использование данных никак не отражается на производительности или целостности платформы 1С.
Комментарии (6)

edo1h
07.05.2022 05:13Давно известные сервисы Гилева. Долгие годы этот продукт был одним из лидеров. Но как же без минусов. Основной – это невозможность внедрить утилиту во внутреннее облако компании, что для многих сейчас может стать непреодолимым препятствием.
помимо возможности локальной установки у вашего решения есть какие-то преимущества?

Dr_Wut Автор
07.05.2022 13:29Возможность долго хранить логи - кликхаус их очень хорошо сжимает.
Более комплексный взгляд на вопрос производительности (на мой взгляд).
Поддержка не только mssql, но postgres.
И самое главное (опять же, на мой взгляд) - это желание развивать продукт. Из моего опыта общения с конкурентами у них нет какого четкого понимания куда дальше двигаться.

Kolosoff
07.05.2022 20:53+1Всё-таки не хватает ссылок хотя бы на демку. Продукт действительно интересный, если ещё и внедряется несложно ( запуск КИП та ещё задачка), то продукт определенно займет своё место под солнцем. Если нужны будут Java-руки со знанием 1С - буду рад помочь. Удачи в развитии!
Dr_Wut Автор
08.05.2022 01:47Внедряется он реально очень просто:
включается ТЖ
Включается ЖР в файлах
Расширвается папка с ТЖ и ЖР
Ставится хранимка на скуль
Ставится расширение в конфигурацию (для структуры базы и для Апдекса)
На Ubuntu генерируется специальной софтиной compose файл
Дальше все это стартуется и все - все готово для работы и данные собираются
У меня запуск занял с нуля занял 2 часа
контакты ушли в личку
Andreyc4d
Интересная статья, но не хватает ссылок на github, инструкций и например ссылок на "статья Юрия Пермитина "... Или это статья "я пиарюсь"?
Dr_Wut Автор
Добрый день
Да, это статья "я пиарюсь", но ближайшее время планирую рассказать и выложить в общий доступ отдельные интересные инструменты, появившиеся в ходе разработки. Например, будет открыт код rac-клиента, на базе которого можно сделать много интересных штук.