
Как и у многих, в нашей компании возник вопрос импортозамещения. В целом вопрос понятный, много раз обсужденный со всех точек зрения. И вот настал счастливый момент, когда слова трансформировались в конкретные задачи с конкретными сроками. И одна из них была о замене СУБД для 1С.
Ну и конечно же, первым делом был поднят вопрос о кластеризации этой истории. Никто подвоха особого не ожидал, ибо у нас есть уже зарекомендовавшее себя решение в виде связки pg_auto_failover версии 1.6 от Citus (далее PGAF для краткости) и keepalived. Это решение нас целиком и полностью устраивает, поэтому выбор наш был очевиден.
Но когда мы начали настраивать выяснился очень неприятный момент - обычная сборка PGAF просто не работает с версией СУБД от PostgresPro - все ломается из-за жестко прописанных зависимостей. Тут то и началось "веселье".
Был вариант игнорировать зависимости, но в таком случае мы получаем проблемы при обновлении. В итоге нашли альтернативу - собрать из исходников самим, настраивая пути и зависимости самостоятельно, о чем и расскажу. В моем повествовании нет какой-то особой магии, но пару дней сберечь точно поможет.
Кластер предполагается разворачивать используя продукты PostgresPro 14 в редакции 1C (14.2.1) и PGAF (1.6.4)
В соответствии с архитектурой системы разворачиваем минимально необходимые 3 ноды (схема из гита проекта):
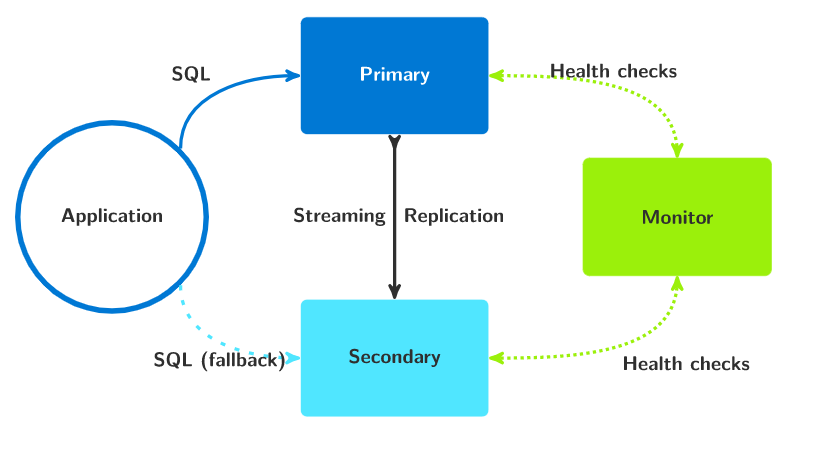
У нас это будет 3 чистых (с набором минимально необходимого для комфортной работы) сервера Ubuntu Server 20.04 LTS (Focal Fossa) и называем их, например так:
serv-pg-mon.local - сервер, который будет выполнять роль монитор-сервера. Для его полноценной работы будет достаточно выделить всего 1 ядро и 1 ГБ оперативной памяти, 20 Гб медленного дискового пространства.
serv-pg-data1.local - первый дата-сервер, который будет хранить базы и выполнять роль primary или secondary в процессе репликации - конфигурацию железа следует подбирать исходя из ваших потребностей.
serv-pg-data2.local - второй дата-сервер, который будет хранить базы и выполнять роль primary или secondary в процессе репликации - конфигурацию железа следует подбирать исходя из ваших потребностей - она должна совпадать с конфигурацией первого дата-сервера.
Настройку имён хостов, сети, фаервола и доступа к хостам по ssh оставим за рамками этой статьи - будем считать, что это всё уже сделано. Важно, чтобы серверы могли обращаться друг к другу по указанным именам - всё взаимодействие в конфигах ниже построено на их DNS-именах, а не их IP-адресах.
Пункт 1: Первоначальная настройка хостов и установка софта из репозиториев
На всех нодах настраиваем русскую локаль (пригодится для корректной работы 1С).
Для начала смотрим текущую локаль:
locale
Если в выводе не ru_RU.UTF-8, то делаем следующее:
sudo locale-gen ru_RU.UTF-8
sudo localectl set-locale LANG=ru_RU.UTF-8 LC_TIME=ru_RU.UTF-8 LC_COLLATE=ru_RU.UTF-8Если всё прошло без ошибок, то для всех новых сессий кодировка будет ru_RU.UTF-8 - проверяем, перелогинившись.
На всех нодах подключаем репозиторий PostgresPRO:
bash -c 'curl https://repo.postgrespro.ru/pg1c-14/keys/pgpro-repo-add.sh | sudo bash'На всех нодах устанавливаем пакеты:
sudo apt install postgrespro-1c-14 postgrespro-1c-14-devПакет postgrespro-1c-14-dev нам пригодится из-за входящей в его состав утилиты pg_config, которая требуется для работы PGAF
PostgresPRO по дефолту установится по пути /opt/pgpro/1c-14/ - в дальнейшем это будет важно.
На всех нодах создаём папки, в которых у нас будут размещаться файл PostgreSQL, например, папку "/data/postgres/". В нашем случае это просто отдельный диск, но и там где это не требуется, все равно делаем такую папку - это наши договоренности внутри команды. Если же необходимости в этом нет, можно использовать стандартный путь /var/lib/postgresql/ - в таком случае этот шаг можно пропустить и перейти сразу к подключению репозитория.
sudo mkdir -p /data/postgres/
sudo chown -R postgres. /dataОбратите внимание, что права юзеру postgres нужно выдавать не на папку /data/postgres/, а на папку выше (/data) - в ней PGAF должен иметь возможность при необходимости создавать и удалять папку backup и совершать операции с самой папкой /data/postgres.
На всех нодах задаём переменные окружения (чтобы облегчить себе жизнь - потом меньше параметров передавать PGAF вручную) создаём файл /etc/profile.d/02-pgenv.sh со следующим содержимым (указываем, где у нас будут файлы PostgreSQL и где его бинарники):
export PGDATA="/data/postgres"
export PATH="$PATH:/opt/pgpro/1c-14/bin"Если же мы не создавали отдельную папку, то содержимое файла будет:
export PGDATA="/var/lib/postgresql/"
export PATH="$PATH:/opt/pgpro/1c-14/bin"Пункт 2: Сборка PGAF из исходников
Ставим необходимые для сборки пакеты:
sudo apt install libssl-dev libkrb5-dev libncurses6 libselinux1-dev liblz4-dev libxslt1-dev libpam0g-dev libreadline-dev gitСкачиваем из гита проекта, собираем и устанавливаем PGAF (ставим наиболее свежую на момент написания статьи версию 1.6.4 - тестировалось всё на ней и всё работает, если хотите, можете попробовать на других):
cd /tmp
git clone https://github.com/citusdata/pg_auto_failover -b v1.6.4
cd pg_auto_failover/
make
sudo make installСоздаём отдельную службу в systemd, которая будет производить управление Postgres-ом через pgaf - создаём файл /etc/systemd/system/pgautofailover.service с правами root:root 0644 и со следующим содержимым:
[Unit]
Description = pg_auto_failover
[Service]
WorkingDirectory = /var/lib/postgresql
Environment = 'PGDATA=/data/postgres/'
User = postgres
ExecStart = /opt/pgpro/1c-14/bin/pg_autoctl run
Restart = always
StartLimitBurst = 0
[Install]
WantedBy = multi-user.targetОбратите внимание, что в поле Environment нужно вписать своё значение. Без корректного значения служба нормально стартовать не будет.
Применяем изменения, включаем службу PGAF и отключаем запуск стандартной службы postgrespro-1c-14.service:
sudo systemctl daemon-reload
sudo systemctl disable --now postgrespro-1c-14.service
sudo systemctl enable pgautofailover.serviceПовторяем на остальных серверах.
Пункт 3: Настройка монитор-ноды
Внимание! Команды настройки кластера PGAF выполняются от имени локального пользователя postgres - чтобы начать в консоли сеанс этого пользователя выполните:
sudo su - postgresСоздаём конфигурацию монитор-ноды, выполнив в консоли:
pg_autoctl create monitor --auth md5 --ssl-mode require --ssl-self-signed --pgport 5432 --hostname serv-pg-mon.localОбъясняю, что мы только что сделали - мы создали монитор-ноду:
используем метода аутентификации md5
шифруем траффик между нодами (с использованием самоподписанных сертификатов)
используем FQDN хоста в качестве имени ноды
В данном примере мы используем конкретные настройки, которые подойдут большинству. Для ознакомления с альтернативными настройками обратитесь к документации - https://pg-auto-failover.readthedocs.io/en/v1.6.3/
Результатом выполнения команды станет инициализация БД в каталоге, который мы указали в PGDATA и сообщения такого вида
Если всё так и прошло, можно двигаться дальше. В случае возникновения ошибок, обратитесь к документации.
Теперь запускаем службу PGAF (обратите внимание, что команды выполняются с sudo, а пользователя postgres обычно таких прав не имеет - переключитесь на нужного пользователя):
sudo systemctl enable --now pgautofailover.service
sudo systemctl status pgautofailover.serviceНа выходе должны получить картину типа такой:

Теперь нужно задать пароль служебного пользователя autoctl_node (см. документацию). Пусть у нас это будет пароль, например, "BeLL1ss1m0PaSSw0rd1ss1m0".
(Этот пароль будет использоваться для аутентификации между нодами и монитором. Позднее нужно будет также задать ещё один пароль для авторизации дата-нод между собой - пароль репликации. Удобно использовать одинаковый пароль для обеих операций - в этой инструкции мы рассматриваем именно такую схему. Но вы при желании можете задать отдельные пароли.)
Для этого выполняем от имени локального пользователя postgres:
psql -c "alter user autoctl_node password 'BeLL1ss1m0PaSSw0rd1ss1m0'"Переопределяем стандартные настройки частоты проверок хостов на более приближённые к реальным требованиям - добавляем в конфиг postgresql.conf следующие строки:
#время задается в миллисекундах
pgautofailover.health_check_period = 500
pgautofailover.health_check_retry_delay = 300
pgautofailover.health_check_timeout = 500
pgautofailover.node_considered_unhealthy_timeout = 3000
pgautofailover.primary_demote_timeout = 6000Значения выведены эмпирически и могут быть изменены в зависимости от ваших потребностей или предпочтений - значения указываются в мс (см. документацию по PGAF).
Перезапускаем службу для применения всех изменений:
sudo systemctl restart pgautofailover.serviceТеперь можно приступать к настройке дата-нод.
Пункт 4: Настройка первой дата-ноды
# очищаем дефолтные настройки
rm -f /etc/default/postgrespro-1c-14
# инициализируем PostgreSQL, создавая дефолтную пустые базы из шаблонов - указание ru-локали обязательно для дальнейшей работы 1С
sudo /opt/pgpro/1c-14/bin/pg-setup initdb -D /data/postgres/ --locale=ru_RU.UTF-8
# создаём служебную папку backup, которая будет использоваться PGAF для хранения временных файлов при репликации и восстановлении БД в случае сбоя
sudo mkdir /data/backup
# выдаём на неё нужные права
sudo chown -R postgres. /data/backup
# переключаемся на пользователя postgres
sudo su - postgres
# регистрируем дата-ноду на монитор-ноде
pg_autoctl create postgres --hostname serv-pg-data1.local --name serv-pg-data1 --auth md5 --ssl-self-signed --monitor 'postgres://autoctl_node:BeLL1ss1m0PSSw0rd1ss1m0@serv-pg-mon.local:5432/pg_auto_failover?sslmode=require' --pgport 5432 --pgctl /opt/pgpro/1c-14/bin/pg_ctlПосле выполнения последней команды должны получить примерно такую картину:

Произошла регистрация и последующая остановку сервиса. При этом на монитор-ноде выполнение команды:
sudo su - postgres -c "pg_autoctl show state"должно показать примерно такую картину:
Name | Node | Host:Port | TLI: LSN | Connection | Reported State | Assigned State
--------------+-------+------------------------------+----------------+--------------+---------------------+--------------------
serv-pg-data1 | 1 | serv-pg-data1.local:5432 | 1: 0/1755380 | read-write ! | single | singleТеперь задаём основные параметры репликации (всё на той же первой дата-ноде):
# переключаемся на пользователя postgres
sudo su - postgres
# указываем пароль репликации - он запишется в конфиг pgaf и будет использован в случае, если эта нода станет standby
pg_autoctl config set replication.password 'BeLL1ss1m0PSSw0rd1ss1m0'
# задаём тот же пароль для пользователя БД
psql -c "alter user pgautofailover_replicator password 'BeLL1ss1m0PaSSw0rd1ss1m0';"
# выставляем значения таймаутов - опять же выведены эмпирически и могут быть изменены в зависимости от ваших потребностей или предпочтений - значения указываются в секундах (см. документацию по PGAF)
pg_autoctl config set timeout.network_partition_timeout 3
pg_autoctl config set timeout.prepare_promotion_catchup 6
pg_autoctl config set timeout.prepare_promotion_walreceiver 3
pg_autoctl config set timeout.postgresql_restart_failure_timeout 6
pg_autoctl config set timeout.postgresql_restart_failure_max_retries 2
# ограничение на максимальную скорость репликации - значение 1024M это 1 Гигабит/c - может быть полезно, если Вы реплицируете большую базу и ограничены в пропускной скорости сети. В более ранних версиях PGAF (например, версии 1.4) скорость 1024М была максимально возможной, которую можно быть установить - значение по умолчанию - 100M (то есть 100 Мбит/c)
pg_autoctl config set replication.maximum_backup_rate 1024MТеперь можно запускать службу PGAF:
sudo systemctl enable --now pgautofailover.service
sudo systemctl status pgautofailover.serviceПолучаем примерно такую картину:

Теперь можно приступать к настройке второй дата-ноды.
Пункт 5: Настройка второй дата-ноды
После выполнения последней команды должно начаться копирование БД с первой ноды - в логе мы должны получить примерно такую картину:
Если всё пройдёт успешно, далее увидим примерно вот такое:

При этом на монитор-ноде выполнение команды
sudo su - postgres -c "pg_autoctl show state"должно показать примерно такую картину:
Name | Node | Host:Port | TLI: LSN | Connection | Reported State | Assigned State
--------------+-------+------------------------------+----------------+--------------+---------------------+--------------------
serv-pg-data1 | 1 | serv-pg-data1.local:5432 | 1: 0/8000060 | read-write | wait_primary | wait_primary
serv-pg-data2 | 2 | serv-pg-data2.local:5432 | 1: 0/8000000 | read-only ! | catchingup | catchingupЭто означает, что обе ноды успешно зарегистрированы, вторая нода находится в состоянии catchingup и пока что недоступна (службу pgautofailover мы ещё не запустили).
Теперь задаём параметры репликации - в этот раз уже на второй ноде (да, на каждой ноде эти параметры задаются в конфиге отдельно)
sudo su - postgres
pg_autoctl config set replication.password 'BeLL1ss1m0PSSw0rd1ss1m0'
pg_autoctl config set timeout.network_partition_timeout 3
pg_autoctl config set timeout.prepare_promotion_catchup 6
pg_autoctl config set timeout.prepare_promotion_walreceiver 3
pg_autoctl config set timeout.postgresql_restart_failure_timeout 6
pg_autoctl config set timeout.postgresql_restart_failure_max_retries 2
pg_autoctl config set replication.maximum_backup_rate 1024M Теперь можно запускать службу PGAF и на ней:
sudo systemctl enable --now pgautofailover.service
sudo systemctl status pgautofailover.serviceПри этом на монитор-ноде выполнение команды
sudo su - postgres -c "pg_autoctl show state"должно показать примерно такую картину:
Name | Node | Host:Port | TLI: LSN | Connection | Reported State | Assigned State
--------------+-------+------------------------------+----------------+--------------+---------------------+--------------------
serv-pg-data1 | 1 | serv-pg-data1.local:5432 | 1: 0/8000230 | read-write | primary | primary
serv-pg-data2 | 2 | serv-pg-data2.local:5432 | 1: 0/8000230 | read-only | secondary | secondaryЭто означает, что всё прошло успешно, ноды синхронизированы и всё работает, как часы.
Пункт 6: Кластерный IP-адрес
Теперь, когда всё настроено и работает, можно приступить к настройке коннектов к серверу БД - удобнее, когда не приходится перенастраивать свои коннекты в случае смены мастер-ноды в кластере.
Можно воспользоваться балансировщиком нагрузки типа HAProxy (или прочими), а можно выделить кластеру IP-адрес, который будет всегда "привязан" к primary-ноде.
Для этого воспользуемся утилитой keepalive.
На обеих дата-нодах устанавливаем нужный пакет:
sudo apt install keepalivedСоздаём скрипт /etc/keepalived/pg_auto_check.sh который проверяет, запущен ли на хосте ноде и какую роль она выполняет в кластере.
#!/bin/bash
if [ "`pidof pg_autoctl`" ]; then
if [ "`su - postgres -c 'pg_autoctl show state --pgdata /data/postgres | grep $HOSTNAME | grep -e primary -e single -e stop_replication'`" ]; then
exit 0
else
exit 1
fi
else
exit 1
fiДаем разрешение на запуск этого скрипта:
sudo chmod +x /etc/keepalived/pg_auto_check.shПриводим настройки /etc/keepalived.conf к следующему виду (предполагается, что у нас на серверах основной сетевой интерфейс eth0, мы присвоили этому кластеру virtual_router_id 66, мы выделили кластеру IP-адрес 172.16.6.66 и задали пароль '123qwe-1A'):
! Configuration File for keepalived
global_defs {
# notification_email {
# admin@example.com
# }
# notification_email_from admin@example.com
# smtp_server mail.example.com
# smtp_connect_timeout 10
#
}
vrrp_script chk_pg_auto {
script "/etc/keepalived/pg_auto_check.sh"
interval 3
timeout 2
weight 100
rise 3
fall 3
user root
}
vrrp_instance <имя_вашего_сервера> {
state BACKUP
interface eth0
dont_track_primary
track_script {
chk_pg_auto
}
virtual_router_id 66
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 123qwe-1A
}
virtual_ipaddress {
172.16.6.66 dev eth0 label eth0:1
}
# smtp_alert
}Не забудьте вписать имя своего сервера в конфиг там где "vrrp_instance".
Если хотите получать почтовые оповещения о переходе IP-адреса с одной ноды на другую, раскомментируйте закомментированные строки и укажите свои актуальные данные.
Теперь стартуем сервис keepalived:
sudo systemctl enable --now keepalived.serviceПроверяем, что на primary-ноде появился наш кластерный IP, если так - мы великолепны, если нет - курим мануалы.
Пункт 7: Создание базы 1С
Здесь сложностей возникнуть не должно - мануалов, как создать базу 1С на сервере PostgreSQL средствами самой 1С, более чем достаточно в интернете.
Из тонкостей:
- рекомендуется создать отдельного пользователя для баз 1С
- в параметрах подключения в качестве адреса сервере БД нужно указывать IP-адрес нашего кластера Keepalived
Пункт 8: Тюнинг настроек Postgres
Рекомендуем ознакомиться со статьёй https://postgrespro.ru/docs/postgrespro/14/config-one-c и выставить параметры в соответствии с указанными там.
Что же касается настроек типа shared_buffers, work_mem,effective_cache_size и параметров autovacuum - то можно немного расслабиться - эти параметры pgaf задаёт сам, рассчитывая их по формуле исходя из текущей конфигурации железа сервера. То есть, стоит вам накинуть памяти вашей виртуалке - и при первом же старте значения будут пересчитаны. Текущие параметры можно посмотреть в файле конфига postgresql-auto-failover.conf в корне вашей Postgres.
Пункт 9: Траблшутинг
Логи работы службы pgautofailover можно просмотреть через:
sudo journalctl -u pgautofailover.serviceЛоги событий в кластере:
su - postgres -c "pg_autoctl show events"Логи самого PostgreSQL находятся в папке $PGDATA/log/
Послесловие:
не забывайте везде в конфигах и командах изменить значения из примера на свои актуальные
Комментарии (21)

kakoka
08.05.2022 18:17+1А вы как-то решили проблему с тем, что в случае выхода узла кластера из строя, или новый инстанс инициализируется путём снятия резервной копии с мастера и это pg_basebackup, что в случае большой базы может привести к неприятным эффектам? pg_auto_failover в отличие от patroni не умеет автоматически создавать реплики из последнего актуального бекапа не нагружая при этом мастер.

Dr_Wut Автор
08.05.2022 18:21-1Я не очень понял вопрос если честно, но попытаюсь ответить. Основная решаемая задача - это высокодоступное решение. Соответственно, если мастер-нода падает - ее подменяет слейв-нода, на время пока чиним старую мастер-ноду. Тут все стандартно.
kakoka
08.05.2022 20:52Да все в порядке, я понял ваш подход, который в целом верный, есть автоматический фейловер, а чинить зовём инженера, который работает руками. Для 1-10 кластеров это приемлемо. Но когда их 100+ уже затруднительно. Спасибо вам за статью. Действительно для PostgresPro его нужно пересобирать, благо разработчик любезно предоставляет для таких целей дев пакеты. Pg_auto_failover вполне пригодное решение, особенно мне нравится монитор, который, будучи один, может обслуживать довольно много кластеров.

denisromanenko
08.05.2022 18:51Вы молодец! Что удивительно, за долгие годы развития русских «облаков» никто так и не вышел с доступным по стоимости решением для managed базы 1С
Ну ладно, может и есть доступные, но ценники конские все равно

Vitaly2606
08.05.2022 20:28К слову PostgresPro автоматизировать развертывание кластеров тоже умеем - https://github.com/vitabaks/postgresql_cluster/issues/38
Dr_Wut Автор
08.05.2022 22:03+1У себя в компании мы собираем собственный deb-пакет, кладем его в локальную репу и катим ансиблом. Но тут была задача рассказать как это можно сделать в базовом варианте. Мануалов как это сделать мы так и не нашли (под наш набор утилит)
bykvaadm
10.05.2022 12:43-2Выучите уже ansible и пишите роли. Будет на порядок полезнее и откроете для себя новый дивный мир galaxy. узнаете, что вот это вот всё там уже давно есть и куда более отлаженное и испробованное тысячами людей.
Dr_Wut Автор
10.05.2022 19:25Во-первых, я бы хотел обратить ваше внимание на мое сообщение буквально сразу же над вашим. Там описан как сделано у нас.
Во-вторых, далеко не всем нужен такой инструмент как Ansible. Есть достаточное количество компаний где в принципе 1-2 БД развернуто. Они потратят на порядок больше времени на освоение инструмента, который им нужен будет один раз в год, а то меньше.
В-третьих, хочу обратить ваше внимание, что ваша последняя статья тоже рассказывает про достаточно базовые вещи и там тоже нет упоминания про Ansible. Мне кажется что не совсем красиво упрекать других в том, что делаешь сам.
Pochemuk
Скитания «инженера со счастливым концом» — это пять!!! :)
Dr_Wut Автор
Немного юмора никогда еще не вредило )
capitannemo
Вспоминается... для счастливого начала сводите девушку в кафе, а для счастливого конца купите презерватив.
Круто что разобрались. Плюсанул конечно.
ИМХО для 1С скорее важно архивирование, чтобы откатиться если косякнут пользователи, но не знаю какое у вас SLA, тогда надо и кластера 1С поднимать.
Что касается
Тоже всегда так делал, пока мне не рассказали и сам не проверил по тж - последняя платформа 1С дает команду analyze самостоятельно при создании временных таблиц.
Я не знаю встречаются ли разработчики платформы и постгрес про, но получается нет смысла в этом расширении.
capitannemo
План перехода на PostgreSQL. Подводные камни и отказоустойчивость - 1C-RarusTechDay 2020
нашел ссылку в своих записях
Dr_Wut Автор
Да, но огромное количество компаний работают на далеко не самых новых версиях платформы, так что этот совет будет актуален еще 3-5 лет думаю
capitannemo
Мы же на техническом сайте, давайте фразы огромное количество, подавляющее большинство и в едином строю оставим другим ресурсам.
Для всех типовых конфигураций есть минимальная версия платформы на которой они запустятся MinAppVersion.txt.
Вот из ЗУП пример
Версия 3.1.17 предназначена для использования с версией платформы 8.3.16.1814 (и более поздних 8.3.16), 8.3.17.1851 (и более поздних 8.3.17), или 8.3.18.1289 (и более поздних).
А вот из бухгалтерии
Текущая версия конфигурации "Бухгалтерия предприятия" предназначена
для использования с версией системы 1С:Предприятие 8.3 не ниже 8.3.17.1851, 8.3.18.1741, 8.3.19.1467.
Рекомендуется использовать версию 1С:Предприятие 8.3 не ниже 8.3.18.1741.
Dr_Wut Автор
Хорошо, это технический сайт. Я переформулирую - по моему личному опыту в проде все еще много старых платформ.
По поводу вашего аргумента - на мой взгляд он не показательный, так как эти базы часто обновляются из-за изменений в форме отчетности, а 1С принудительно заставляет обновлять вместе с ними и платформу.
Я лично не знаю надежных источников, где бы можно было посмотреть статистику по используемым платформам.
capitannemo
Я к этому и веду. Что все кто используют ЗУП (читайте все у кого больше 20 сотрудников) обновляют платформу регулярно.
Dr_Wut Автор
Да, с ЗУП или Бухгалтерией никто не спорит. Но другие конфигурации, особенно самописные или сильно кастомизированные обновляются как правило через боль и страдания, поэтому делается это когда уже совсем припечет.
А их, по моему мнению, сильно больше чем ЗУП/Бух
capitannemo
Вы под них держите особую старую платформу?
LiveMan
Очень ценный комментарий, но к сожалению не указана версия платформы.
Нигде тут не нашел упоминания что такое "последняя платформа", просьба указать версию(Например (8.3.17.2316) (z) ), где вы проверяли такое поведение платформы.
capitannemo
Да, ваше замечание принимается полностью, в последних версиях платформы точно, но если конкретно, то например 8.3.20.1674
Проверить легко, нужно настроить технологический журнал на событие DBPOSTGRS в нем можно будет увидеть Sql=ANALYZE pg_temp
И что еще загадочнее SET enable_mergejoin=off