Примечание переводчика: В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Мы уже рассказывали о дата-центре фотосервиса imgix, описывали детективную историю поиска проблем с SSD-дисками проекта Algolia, а сегодня представляем вашему вниманию адаптированный перевод заметки инженеров сервиса бронирования билетов Ticketmaster о поиске и устранении проблемы таймаутов соединений.
У себя в Ticketmaster мы очень много внимания уделяем мониторингу наших производственных систем. Иногда нам случается сталкиваться с интересными проблемами, влияющими на работу наших сервисов, которые очень легко не заметить, если не уделять им должного внимания. К сожалению, системы мониторинга способны выявить только симптомы, указывающие на причину неполадки, но не саму причину. Поиск корня проблемы – это задача совершенно другого уровня. Вот вам один такой пример.
Все началось, когда мы заметили, что один из запросов к нашему веб-сервису имеет необычно высокое число тайм-аутов. Это совершенно не нормально, потому что, обычно, веб-сервис отвечает на запрос в течение 50 миллисекунд, а время ожидания ответа клиентом составляет 1 секунду. В дополнение ко всему, метрики на уровне веб-узла показывали, что 99-й перцентиль времени отклика по-прежнему лежит в пределах 50 миллисекунд. Источник проблемы лежал где-то в сети, между клиентом и сервером.
Мы решили поподробнее изучить метрики на стороне клиента и увидели на временной диаграмме то, что упустили ранее:

Временная диаграмма времени ответа сервиса на стороне клиента
Для данного кластера тайм-ауты возникали каждую минуту примерно в одну и ту же секунду. Например, в кластере А тайм-ауты появились в 5:02:27, 5:03:27, 5:04:27, а в другом кластере – в 5:02:55, 5:03:55, 5:04:55. Озадаченные показаниями графика, мы ни на шаг не приблизились к разгадке. Пришло время для tcpdump.
Мы начали отслеживать переговоры на стороне клиента и на стороне веб-сервиса – терпеливо ждали секундной отсечки, на которой возникал тайм-аут.
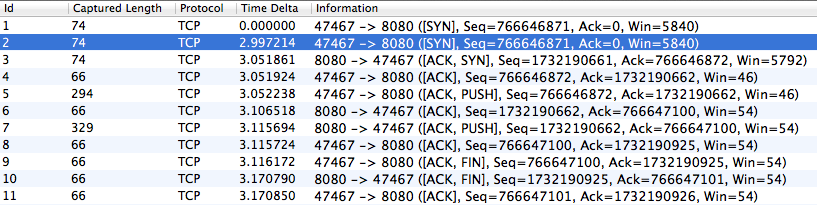
Пакеты, полученные клиентом
Пакеты, полученные сервером
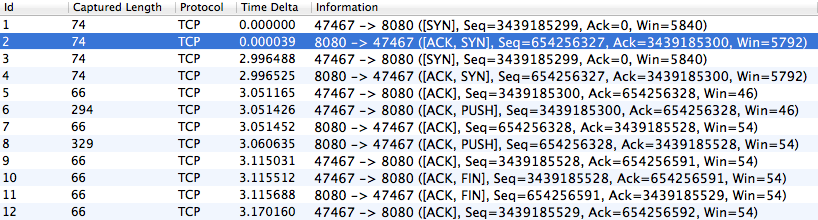
Заметьте, что клиент отправляет пакет SYN и ожидает SYN/ACK – сигнал подтверждения принятия данных от сервера, но не дожидается, поэтому отправляет пакет повторно через 3 секунды (3 секунды – это стандартный тайм-аут для повторной передачи). Однако сервер работает корректно и отправляет SYN/ACK вовремя, просто клиент его так и не получает. Пришло время задействовать «тяжелую артиллерию» – пригласить Аудина Эспинозу (Audyn Espinoza), нашего местного эксперта по сетям передачи данных.
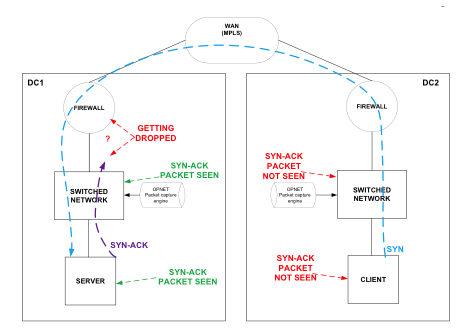
На основании уже собранной информации мы определили, что проблема проявляет себя в момент прохождения пакета через брандмауэр. Пакет терялся в обоих случаях: при его передаче в пределах одного дата-центра и при передаче между дата-центрами – такое поведение исключало MPLS из списка подозреваемых. Так как проблема связана с невозможностью установления TCP-соединения, то под подозрение попал сам брандмауэр. Факт того, что брандмауэры (и распределители нагрузки) – это единственные сетевые устройства, которые понимают преамбулы и способны определить окончание TCP-соединения, только подтверждал наши подозрения. Какова вероятность того, что маршрутизатор или коммутатор случайно теряют только пакеты SYN/ACK, при этом нормально передавая пакеты с данными, если они не видят между ними разницы? Такое возможно, но крайне маловероятно. Нужно было копнуть глубже и провести пакетный анализ на этих устройствах, чтобы найти виновника.
С этой мыслью мы начали захватывать сетевой трафик, идущий от одного дата-центра к другому, с помощью OPNET и Wireshark. Мы тут же заметили, как пакет SYN успешно миновал брандмауэр, но пакету подтверждения SYN/ACK этого сделать не удалось. Поток данных можно пронаблюдать на изображении ниже:
Схема обмена данными между клиентом и сервером в сети, в которой были замечены тайм-ауты
Тот же самый тест был проведен с пакетом, отправленным в другую сторону. Результат был идентичным. Мы видим, что система посылает сигнал о получении SYN/ACK, но он отсеивается брандмауэром. Разумеется, мы проверили, все ли в порядке с ACL, поэтому можно с уверенностью сказать, что потеря пакета не связана с политикой контроля доступа.
Пока что у нас не было веских доказательств того, что виновником проблемы является брандмауэр. Нам нужно было убедиться наверняка. Существовала очень низкая вероятность того, что проблема заключена в MPLS. Мы решили провести еще один тест, на этот раз в пределах одного дата-центра, где многопротокольная коммутация по меткам использоваться не будет. Вдобавок к этому мы провели сетевую трассировку в агрегированных каналах, которые напрямую подключены к физическому брандмауэру. Теперь клиенту из Сети 1 нужно было попытаться установить TCP-соединение с сервером в Сети 3. Если вы посмотрите на изображение ниже, то увидите, что на пути пакета от клиента к серверу стоят три отдельных VLAN, настроенных на коммутаторе третьего уровня, и два виртуальных брандмауэра.
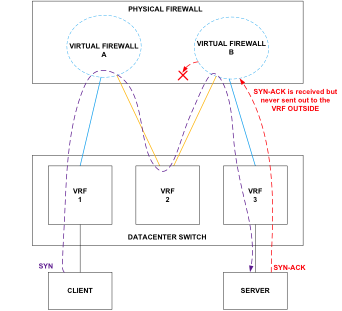
Схема сети при проведении детального пакетного анализа
Фиолетовая линия показывает схему движения пакета SYN, отправленного клиентом. Видно, что ему удалось успешно миновать все три сети – это подтвердили данные, перехваченные Wireshark.
Мы должны были увидеть три пакета SYN/ACK, проходящих через три сети, но в захваченных Wireshark данных мы видим только один, а это говорит нам о том, что виртуальный брандмауэр «B» не передал его дальше, в Сеть 2.
По истечении трех секунд (допустимое время простоя TCP-соединения) началась повторная передача пакета SYN. На этот раз, судя по перехваченным данным, TCP-соединение было успешно установлено, поэтому мы увидели, как пакеты SYN и SYN/ACK успешно прошли через все три сети.
Это было безоговорочным доказательством существования проблемы на уровне брандмауэра. Теперь, зная, что наш преступник – это брандмауэр, нам нужно было приложить последние усилия, чтобы по горячим следам разыскать все еще дымящийся пистолет.
После часа просмотра статистики брандмауэра мы обнаружили, что SNMP полностью захватывал ресурсы центрального процессора каждые 60 секунд. Мы даже могли проследить это на системном уровне брандмауэра (не на виртуальном). Время в точности совпадало с моментами появления пиков на графиках веб-сервиса.
Корнем проблемы оказался баг SNMP в коде брандмауэра. Чтобы полностью решить проблему с тайм-аутами TCP-соединения мы отключили SNMP-опрос обоих брандмауэров и SNMP-опросник.
Это отличный пример того, как пакетный анализ и мониторинговые инструменты помогли Ticketmaster выявить и разрешить проблему.
У себя в Ticketmaster мы очень много внимания уделяем мониторингу наших производственных систем. Иногда нам случается сталкиваться с интересными проблемами, влияющими на работу наших сервисов, которые очень легко не заметить, если не уделять им должного внимания. К сожалению, системы мониторинга способны выявить только симптомы, указывающие на причину неполадки, но не саму причину. Поиск корня проблемы – это задача совершенно другого уровня. Вот вам один такой пример.
Все началось, когда мы заметили, что один из запросов к нашему веб-сервису имеет необычно высокое число тайм-аутов. Это совершенно не нормально, потому что, обычно, веб-сервис отвечает на запрос в течение 50 миллисекунд, а время ожидания ответа клиентом составляет 1 секунду. В дополнение ко всему, метрики на уровне веб-узла показывали, что 99-й перцентиль времени отклика по-прежнему лежит в пределах 50 миллисекунд. Источник проблемы лежал где-то в сети, между клиентом и сервером.
Мы решили поподробнее изучить метрики на стороне клиента и увидели на временной диаграмме то, что упустили ранее:

Временная диаграмма времени ответа сервиса на стороне клиента
Для данного кластера тайм-ауты возникали каждую минуту примерно в одну и ту же секунду. Например, в кластере А тайм-ауты появились в 5:02:27, 5:03:27, 5:04:27, а в другом кластере – в 5:02:55, 5:03:55, 5:04:55. Озадаченные показаниями графика, мы ни на шаг не приблизились к разгадке. Пришло время для tcpdump.
Мы начали отслеживать переговоры на стороне клиента и на стороне веб-сервиса – терпеливо ждали секундной отсечки, на которой возникал тайм-аут.
tcpdump -i eth0 -s 0 -xX port 8080 src <client_address> and dst <service_address>
Пакеты, полученные клиентом
Пакеты, полученные сервером
Заметьте, что клиент отправляет пакет SYN и ожидает SYN/ACK – сигнал подтверждения принятия данных от сервера, но не дожидается, поэтому отправляет пакет повторно через 3 секунды (3 секунды – это стандартный тайм-аут для повторной передачи). Однако сервер работает корректно и отправляет SYN/ACK вовремя, просто клиент его так и не получает. Пришло время задействовать «тяжелую артиллерию» – пригласить Аудина Эспинозу (Audyn Espinoza), нашего местного эксперта по сетям передачи данных.
На основании уже собранной информации мы определили, что проблема проявляет себя в момент прохождения пакета через брандмауэр. Пакет терялся в обоих случаях: при его передаче в пределах одного дата-центра и при передаче между дата-центрами – такое поведение исключало MPLS из списка подозреваемых. Так как проблема связана с невозможностью установления TCP-соединения, то под подозрение попал сам брандмауэр. Факт того, что брандмауэры (и распределители нагрузки) – это единственные сетевые устройства, которые понимают преамбулы и способны определить окончание TCP-соединения, только подтверждал наши подозрения. Какова вероятность того, что маршрутизатор или коммутатор случайно теряют только пакеты SYN/ACK, при этом нормально передавая пакеты с данными, если они не видят между ними разницы? Такое возможно, но крайне маловероятно. Нужно было копнуть глубже и провести пакетный анализ на этих устройствах, чтобы найти виновника.
С этой мыслью мы начали захватывать сетевой трафик, идущий от одного дата-центра к другому, с помощью OPNET и Wireshark. Мы тут же заметили, как пакет SYN успешно миновал брандмауэр, но пакету подтверждения SYN/ACK этого сделать не удалось. Поток данных можно пронаблюдать на изображении ниже:
Схема обмена данными между клиентом и сервером в сети, в которой были замечены тайм-ауты
Тот же самый тест был проведен с пакетом, отправленным в другую сторону. Результат был идентичным. Мы видим, что система посылает сигнал о получении SYN/ACK, но он отсеивается брандмауэром. Разумеется, мы проверили, все ли в порядке с ACL, поэтому можно с уверенностью сказать, что потеря пакета не связана с политикой контроля доступа.
Пока что у нас не было веских доказательств того, что виновником проблемы является брандмауэр. Нам нужно было убедиться наверняка. Существовала очень низкая вероятность того, что проблема заключена в MPLS. Мы решили провести еще один тест, на этот раз в пределах одного дата-центра, где многопротокольная коммутация по меткам использоваться не будет. Вдобавок к этому мы провели сетевую трассировку в агрегированных каналах, которые напрямую подключены к физическому брандмауэру. Теперь клиенту из Сети 1 нужно было попытаться установить TCP-соединение с сервером в Сети 3. Если вы посмотрите на изображение ниже, то увидите, что на пути пакета от клиента к серверу стоят три отдельных VLAN, настроенных на коммутаторе третьего уровня, и два виртуальных брандмауэра.
Схема сети при проведении детального пакетного анализа
Фиолетовая линия показывает схему движения пакета SYN, отправленного клиентом. Видно, что ему удалось успешно миновать все три сети – это подтвердили данные, перехваченные Wireshark.
Мы должны были увидеть три пакета SYN/ACK, проходящих через три сети, но в захваченных Wireshark данных мы видим только один, а это говорит нам о том, что виртуальный брандмауэр «B» не передал его дальше, в Сеть 2.
По истечении трех секунд (допустимое время простоя TCP-соединения) началась повторная передача пакета SYN. На этот раз, судя по перехваченным данным, TCP-соединение было успешно установлено, поэтому мы увидели, как пакеты SYN и SYN/ACK успешно прошли через все три сети.
Это было безоговорочным доказательством существования проблемы на уровне брандмауэра. Теперь, зная, что наш преступник – это брандмауэр, нам нужно было приложить последние усилия, чтобы по горячим следам разыскать все еще дымящийся пистолет.
После часа просмотра статистики брандмауэра мы обнаружили, что SNMP полностью захватывал ресурсы центрального процессора каждые 60 секунд. Мы даже могли проследить это на системном уровне брандмауэра (не на виртуальном). Время в точности совпадало с моментами появления пиков на графиках веб-сервиса.
Корнем проблемы оказался баг SNMP в коде брандмауэра. Чтобы полностью решить проблему с тайм-аутами TCP-соединения мы отключили SNMP-опрос обоих брандмауэров и SNMP-опросник.
Это отличный пример того, как пакетный анализ и мониторинговые инструменты помогли Ticketmaster выявить и разрешить проблему.
Комментарии (4)

Ivan_83
22.10.2015 20:14Тоже мне проблема :)
У меня домашний сервер-роутер как то начал чудить: tcp соединения тормозили/лагали.
Оказалось интеловая сетевушка (PCI-E дешёвая десктопная, em) дропала ACK пакеты считая езернет фреймы битыми, от того счётчик битых пакетов на сетевухе рос. На коммутаторе ошибок не было на портах, при переходе на встроенный рылотек всё прошло.
Сетевуха повалялась пару лет и сейчас когда иногда использую для тестов проблем нет.
А брандмауэр явно корявый, даже если у него там локи на считывании статы он должен пакеты складывать в буфер/очередь и потом обрабатывать.
TimsTims
Это проблема конкретно какого-то брендмауэра? И что поставили вместо SNMP? Или он вам был и так не нужен?
lostpassword
Мне почему-то думается, что они отписали производителю, а тот поправил баг и выпустил новую прошивку, которую потом накатили на межсетевой экран.
TimsTims
Судя по количеству постов от 1cloud, они бы о таком квесте непременно написали бы)